運用ChatGPT實現長慶油田網絡安全數據自動化提取的路徑研究
2024-12-31 00:00:00王旭?竇敬?李晨琛
信息系統工程 2024年10期
關鍵詞:網絡安全


摘要:隨著智慧油氣田建設的不斷深入,網絡安全問題日益凸顯。為了解決長慶網絡安全態勢感知平臺無法直接提供數據接口的問題,采用Python編寫數據接口,將部分數據提取、解析并寫入網絡安全可視監控平臺數據庫。通過ChatGPT的智能輔助,進行大規模的代碼修正和優化,顯著提高開發效率和代碼質量。值得強調的是,在這一過程中,ChatGPT在代碼修正和問題解決中發揮了至關重要的作用。成功實踐了ChatGPT在代碼修正中的技術路徑。為智慧油氣田建設中的網絡安全保障提供了創新的技術思路和可靠的解決方案。
關鍵詞:智慧油氣田建設;網絡安全;ChatGPT;API數據提取
一、前言
隨著數字化油田發展和智慧油氣田的大力推進[1],包括網絡安全在內的油田六大數智化業務領域出現了大量信息化系統。為實現各項業務的集中統一監控、智能輔助決策,數智事業部建立了數智事業部信息資產監控平臺(以下簡稱信息資產監控平臺)[2]。平臺建立的目的是對數智事業部的在線設備與業務服務實現自動化、智能化的實時監控、自動報警、故障信息推送、大屏監控等功能,需要與現有的各業務系統實現數據對接[3]。
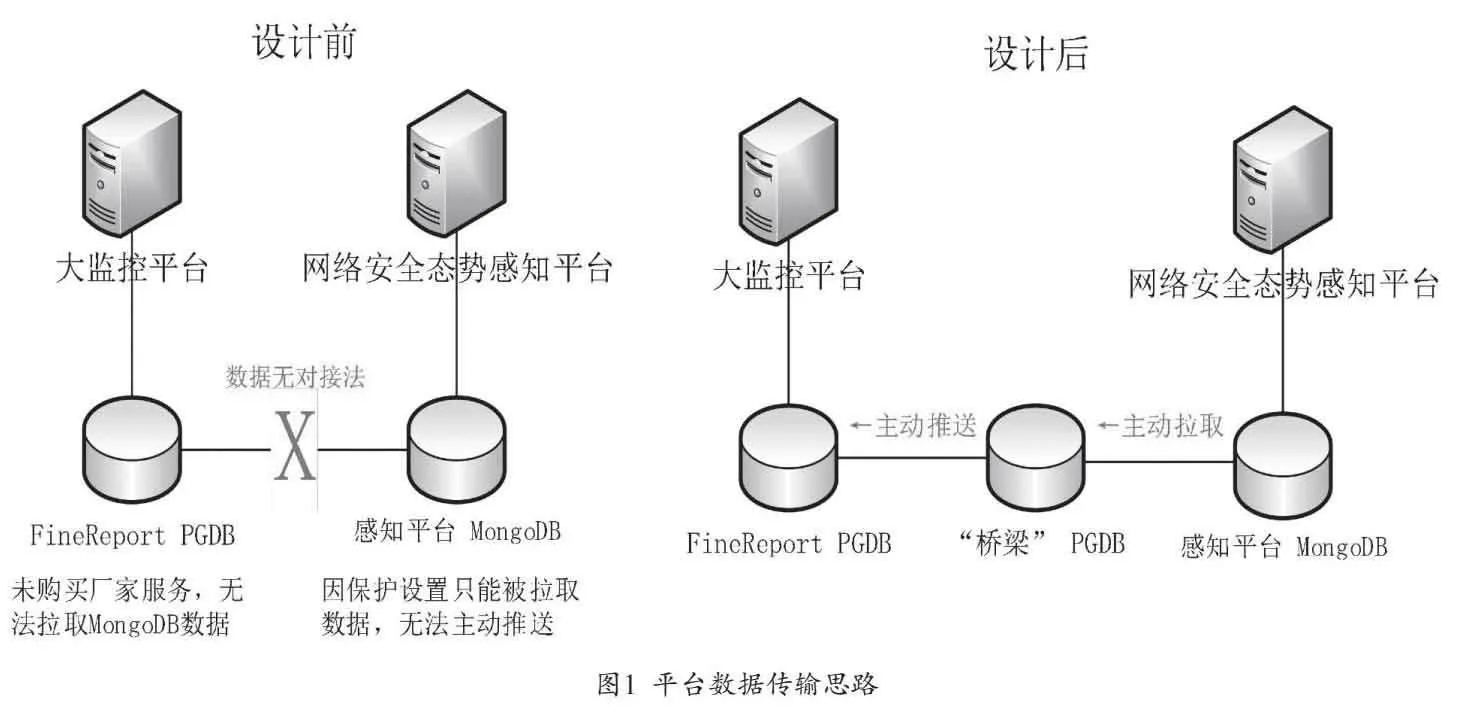
長慶油田網絡安全態勢感知平臺(以下簡稱感知平臺)是長慶內網的安全分析大腦,平臺上所分析研判出的各類網絡安全相關數據,也需要與信息資產監控平臺對接進行監控、展示[4]。由于感知平臺自身安全性及完整性要求,所用的Mongo數據庫存在一些保護措施,即便開啟了通用API接口,相關安全數據也無法主動推送至信息資產監控平臺PostgreSQL數據庫中,要想展示相關數據,只有靠人工錄入的方式,這違背了數智化發展的方向,也不符合信息資產監控平臺建設的初衷[5]。如何打破系統間的不可能,讓數據對接的自動化、智能化變為可能,便成了網絡安全中心需要解決的問題[6]。
此外,ChatGPT在Python腳本編寫中的應用也越來越廣泛,通過利用ChatGPT編寫和優化腳本,可以顯著提高開發效率和代碼質量。例如,ChatGPT可以幫助生成函數文檔字符串、處理和轉換數據,以及集成API接口等任務[7],為智慧油氣田建設中的數據自動化傳輸和處理提供了新的技術手段和方法。
二、設計思路
以數字化轉型、智能化發展為指導思想,結合迎難而上的拼搏理念,以自主學習和自主建設、鍛煉隊伍、培養技術力量為目的,合理利用ChatGPT等先進的技術手段(向ChatGPT輸入的內容全部經過脫敏處理),打破感知平臺接口限制,實現數據的自動化傳輸。
(一)核心思路
既然無法實現數據自動化傳輸,是因為感知平臺Mongo數據庫因保護無法主動推送數據,且信息資產監控平臺FineReport無法主動拉取MongoDB數據,那么設想基于通用的API接口和統一的開發標準,建立一個中間PostgreSQL數據庫作為“橋梁”,一方面主動拉取感知平臺數據,一方面主動推送至信息資產監控平臺,實現兩個平臺的數據對接,如圖1所示。
(二)解決思路
通過其他途徑獲取感知平臺的數據,并將數據解析后寫入PostgreSQL數據庫中,以便在FineReport大屏上進行展示。因此,需要考慮如何通過感知平臺提供的API接口進行部分數據提取,以及如何將提取解析后的數據寫入信息資產監控平臺數據庫中。
三、實驗設計
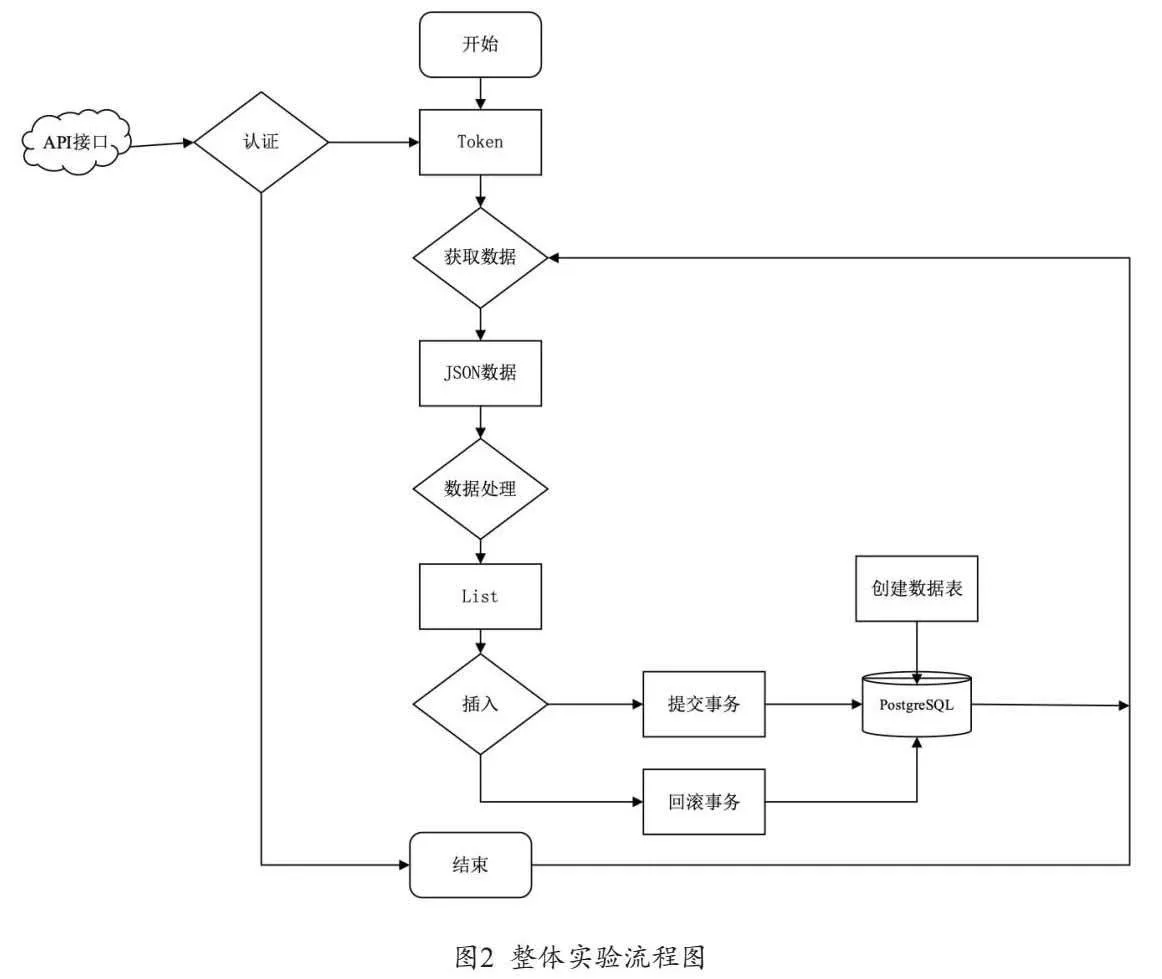
由于專業領域不同,網絡安全中心技術人員對API接口間的調用方法及流程等相關知識鮮有涉獵,從頭學起將無法滿足信息資產監控平臺的上線時限,于是使用ChatGPT,詢問相關技術關鍵點,運用到實驗中,再將實驗時的報錯信息,反饋至ChatGPT,尋找解決方法,再運用到實驗中,如此反復,直至運行成功。
(一) 感知平臺數據的獲取
在感知平臺無法對外提供數據的情況下,依照ChatGPT指導,通過平臺提供的API接口進行部分數據提取。具體方案如下:
1.認證和token獲取
在ChatGPT編寫API數據提取腳本之前,需要進行認證和token獲取。認證通常需要提供用戶名和密碼,而token獲取則需要提供認證后獲得的token(token有有效期,到期后將失效,失效后需要重新獲取token值)。這些信息可以通過Python編寫的腳本進行自動化獲取。
2.數據提取
通過API接口獲取網絡安全態勢感知平臺的數據,包括安全事件、分類、風險等級、發現、分析、研判、下發處置通報等數據。這些數據通常以JSON格式呈現。
(二)感知平臺數據的解析
數據解析:通過Python編寫的腳本對JSON格式的數據進行解析,將需要的數據提取,然后將它們寫入中間的PostgreSQL數據庫中。
(三)信息資產監控平臺FineReport的數據寫入
數據庫調用:使用FineReport的數據庫集數據調用功能,將PostgreSQL數據庫中的數據集成到FineReport大屏中,這樣就可以在FineReport大屏上實時監控網絡安全狀況。整體實驗流程圖如圖2所示。
四、利用ChatGPT的Python腳本編寫
(一) ChatGPT的腳本編寫
Python編寫API數據提取腳本的過程具體如下:
首先,需要編寫代碼獲取用戶名和密碼,并通過API接口進行認證,獲取token。這個過程可以通過Python的requests庫實現。
其次,通過API接口獲取感知平臺的數據,以JSON格式呈現。這個過程也可以通過requests庫實現。
再次,將獲取的JSON格式數據解析為Python對象,然后提取需要的數據。在解析JSON數據時,使用Python內置的json庫。
最后,將提取的數據寫入PostgreSQL數據庫中。在Python中,可以使用psycopg2庫連接并操作PostgreSQL數據庫。
(二)代碼修正
ChatGPT是一種基于GPT-3.5架構的大型語言模型,具有強大的自然語言處理能力和智能的文本生成能力,但現階段的AI編程水平有限,在編寫Python API數據提取腳本的過程中難免會遇到一些問題,如API接口調用失敗、數據解析錯誤等。針對這些問題,需要通過人工干預。
首先,在系統中運行生成的腳本,進行調試。在實際運行生成的腳本時,可能會遇到各種問題,如API接口調用失敗或數據解析錯誤。記錄這些錯誤信息非常重要,以便后續修正。
其次,將記錄下的錯誤信息及有問題的代碼段輸入ChatGPT中,利用其強大的自然語言處理能力,生成修正后的代碼。例如:
#將錯誤信息輸入ChatGPT中,獲取修正建議
error_info = \"Traceback (most recent call last):\nFile 'script.py', line 10, in
chatgpt_response = chatgpt_api.get_response(error_info)
print(chatgpt_response)
最后,根據ChatGPT提供的修正建議,修改腳本并再次運行。如此反復,直到腳本能夠正常運行并正確提取和處理數據。
(三)具體實例
以下是一個具體實例,展示了如何通過ChatGPT生成和優化代碼,實現從API提取數據并插入PostgreSQL數據庫:
1.編寫初始腳本,通過API接口進行認證和數據提取。
import requests
import json
import psycopg2
#API認證
auth_url = \"https://api.example.com/auth\"
auth_payload = {'username': 'user', 'password': 'pass'}
auth_response = requests.post(auth_url, json=auth_payloadBY
token = auth_response.json().get('token')
#獲取數據
headers = {'Authorization': f'Bearer {token}'}
data_url = 'https://api.example.com/data'
data_response = requests.get(data_url, headers=headers)
data = data_response.json()
# 數據解析
required_data = data['key_of_interest']
#插入數據到PostgreSQL
conn = psycopg2.connect(
dbname='db',
user='user',
password='pass',
host='host',
port='port',
)
cursor = conn.cursor()
insert_query = 'INSERT INTO table (column1, column2) VALUES (%s, %s)
cursor.execute(insert_query,(required_data['fieldi'],required_data['field2']))
conn.commit()
cursor.close()
conn.close()
2.運行初始腳本,記錄錯誤信息并通過ChatGPT進行修正。
如果API返回的數據格式不正確,導致json.decoder.JSONDecodeError錯誤:
try:
data = data_response.json()
except json.JSONDecodeError:
print(\"Error decoding JSON\")
根據ChatGPT建議進行修正
data = {}
3.通過ChatGPT的多次迭代和優化,最終實現了數據的自動化提取和處理,并將其成功寫入PostgreSQL數據庫中。
五、應用效果
通過ChatGPT的協助,得以快速了解API對接的關鍵技術點,并且更加高效地完成腳本編寫及代碼修正工作,在有效解決了數據對接問題的同時,節省了大量的時間和精力。經過多次運行試驗,感知平臺的數據與FineReport自動對接成功,并展示在信息資產監控平臺 “網絡安全可視化監控”界面。
六、效益分析與評價
隨著數智事業部信息資產監控平臺在六大數智化業務領域的深入應用與持續推廣,將進一步對接更多的網絡安全應用,實現油田網絡多維度的安全數據監控。目前大多數網絡安全系統為第三方廠商標品,存在數據保護情況,如果找廠家二次開發進行數據對接,將產生一筆龐大的開發費用。幾乎所有的系統都開放了標準的API接口,此次利用ChatGPT將感知平臺的數據拉取并推送至FineReport試驗成功,說明該方法可行,后續可以沿用至其他系統與信息資產監控平臺的數據對接。
一是提升對接效率。今后的系統對接可以參考本次經驗,利用ChatGPT的分析能力,快速實現其他平臺的數據對接(應用必須具備開放通用API接口且開放接口調用功能)。二是實現數據自動化傳輸。將需要提取的數據字段提交給ChatGPT,生成提取腳本后,所有需要的數據將自動被提取、解析、推送,告別傳統的人工錄入時代。三是輸出可控,提升安全保障。可要求ChatGPT針對輸出項進行篩選,過濾掉不方便展示的敏感數據。四是創造經濟效益。前期經過咨詢,單一系統對接的二次開發報價接近30萬元,如果多個具有相同問題的應用系統運用此方法對接成功,將節省近百萬元的成本。
七、結語
介紹了在智慧油氣田建設中實現感知平臺監控數據提取的需求和解決思路,利用ChatGPT編寫API調用的Python腳本,成功地實現了兩個平臺的數據對接,并將網絡安全事件處置閉環數據展示到FineReport大屏中。同時,通過ChatGPT的幫助,實現了自主學習、自主建設的練兵目的。
在未來的研究方向上,可以進一步優化API數據提取腳本的效率和穩定性,提高數據解析的準確性和速度,并且可以考慮利用機器學習等技術來進行數據分析和預測。同時,可以考慮將ChatGPT等大型語言模型應用到更多的領域和場景中,從而提高效率和準確性,推動智慧油氣田建設的發展。
參考文獻
[1]王偉.數字化轉型下的油田智能化建設[J].中國石油學報,2020(12):4-6.
[2]李強.基于物聯網的智慧油氣田管理系統研究[J].計算機工程與應用,2019(08):10-12.
[3]劉建國,張立華.數字油田與智能油氣田建設探討[M].北京:石油工業出版社,2021(11):15-20.
[4]黃磊.智慧油氣田中網絡安全問題與對策[J].網絡安全技術與應用,2019(10):38-40.
[5]李娜.物聯網在智慧油氣田建設中的應用[J].物聯網技術,2020(06):15-16.
[6]張曉明.智慧油氣田建設中的大數據應用[J].大數據技術與應用,2018(12):20-21.
[7]陳剛.基于區塊鏈的油氣田數據安全管理[J].信息安全技術,2020(08):33-35.
作者單位:長慶油田分公司數智化事業部
■ 責任編輯:張津平、尚丹
猜你喜歡
兒童故事畫報·智力大王(2025年3期)2025-03-09 00:00:00
工會博覽(2023年27期)2023-10-24 11:51:28
科學大眾(中學)(2019年2期)2019-04-08 02:26:40
中國生殖健康(2019年10期)2019-01-07 01:21:04
信息安全研究(2018年12期)2018-12-29 11:01:46
小學生必讀(中年級版)(2018年4期)2018-07-05 06:00:48
湖北警官學院學報(2017年3期)2017-06-21 09:25:51
信息安全與通信保密(2016年3期)2016-08-23 01:23:32
互聯網天地(2016年1期)2016-05-04 04:03:20
信息安全研究(2015年3期)2015-02-28 20:18:17
