大語言模型賦能圖書館知識服務:基礎、模式
2024-12-31 00:00:00劉長輝
信息系統工程 2024年7期
摘要:自OpenAI授權微軟使用GPT-3模型開始,以大語言模型為代表生成式人工智能發展日新月異,在各行各業的應用隨之展開了討論研究。大語言模型以海量數據為基礎,通過人類反饋強化學習技術、Transformer、CoT、AIGC等技術融合應用,為圖書館服務賦能,使圖書館滿足讀者不斷變化的需求。嘗試從數據基礎、技術基礎角度出發去探討智慧圖書館的新知識服務模式。
關鍵詞:大語言模型;智慧圖書館;知識服務
一、前言
大語言模型是一種可使用大量文本數據訓練的深度學習模型,可以用于生成自然語言文本或理解語言文本的含義。2000年9月,出現了最初的大語言模型應用,OpenAI授權微軟使用GPT-3模型,以此為標志,以大語言模型為代表的人工智能領域獲得重大突破。2023年3月,OpenAI發布了更先進的多模態預訓練大模型GPT4.0。2023年2月,百度正式宣布推出大語言模型“文心一言”,3月上線[1]。
2022年中共中央、國務院印發的《關于推進實施國家文化數字化戰略的意見》強調要建立具備情感計算、深度學習、模式識別的區域性智能計算中心,構建一體化的文化計算服務體系[2]。隨著科技的進步和國家政策的引導,大數據鏈、人工智能等技術正融入智慧圖書館的建設。特別是大語言模型的出現,將推動圖書館知識服務與人工智能技術的緊密結合產生全新服務模式,使知識服務更加大眾化。
在以ChatGPT為代表的大語言模型問世后,圖情領域對其廣泛關注,認為在LLM技術加持下,圖書館將提升知識服務能力并對其進行了初步研究。例如,郭亞軍等學者深入研究了ChatGPT如何融合咨詢服務、科研服務及資源建設。張曉林研究了大語言模型下技術與人才面臨的變革。趙瑞雪等人針對圖書館如何有效整合大數據與人工智能,以提升知識服務水平進行了深入研究[3]。
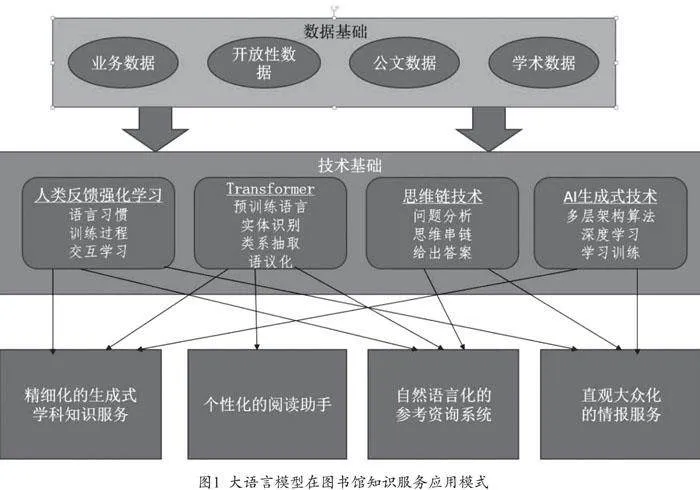
針對以上背景,本文從數據來源方面分析大語言模型優化知識服務的數據基礎。從知識生成式技術、思維鏈、多層變換器架構、人類反饋強化學習等技術層面分析大語言模型賦能圖書館知識服務的技術基礎。從參考咨詢系統、資源助手、學科知識服務、情報服務等角度對大語言模型在圖書館知識服務可能的應用模式進行探討,如圖1所示。
二、大語言模型賦能圖書館知識服務的基礎
(一)賦能的技術基礎
1.強化交互,使其類人化的人類反饋強化學習技術
人類反饋強化學習(RLHF)是一種將強化學習與人類反饋相結合的技術,人類的偏好被用作獎勵信號,用于引導模型生成高質量的語言輸出。其作用是將人類的反饋原理融入訓練中,在互動學習中,為機器營造一個自然且人性化的過程,就像人類從另一個專業人士身上學習專業知識的方式一樣。RLHF是大語言模型應用的基礎核心技術。人類反饋強化學習技術使大語言模型生成的內容越發貼合自然語言。經過強化學習訓練的模型系統能夠更精準地捕捉用戶的意圖,分析用戶情感。
智慧圖書館中,大語言模型優化后的機器人與虛擬助手服務已不可或缺[4-5]。在融合人類反饋強化學習技術后,大語言模型在互動、學習及技術應用上展現出更強大的能力,不僅提升了對用戶需求的感知與理解,更在情感識別上取得了顯著進步。大語言模型在大體掌握用戶輸入自然語言的規則和偏好下,可以生成符合日常用語習慣的語義規則,適應多角色、多風格的長文本生成,在表述方面呈現出類人化特征。大語言模型不僅反應速度遠超人類,更具備豐富的情感立場,為參考咨詢服務帶來了創新。
2.語義化資源的多層變換器架構技術
對知識服務來說,資源的組織至關重要。2017年,谷歌研究人員提出的多層變換器架構模型(Transformer)是大語言模型的基本組件[6]。Transformer架構下的預訓練語言模型摒棄了人工標注,能深度揭示資料的信息。資源中長距離依賴關系的精準捕捉能力,使大語言模型擁有強大的自然語言理解與生成能力。Transformer使大語言模型輕松駕馭大型語料庫,并展現出卓越的計算和資源組織能力。大語言模型對于圖書館海量的數據能夠進行有效整理和優化,為用戶提供更豐富和全面的資源服務。借助大語言模型技術,圖書館資源從表象化的組織方式,逐漸轉變為以語義內容為核心的組織方式。通過對文本數據進行深入分析,如實體識別、關系抽取、知識圖譜構建等,實現細粒度知識對象的組織和揭示。例如,大語言模型能自動化地對圖書的標題、關鍵信息等進行提取和分析,自動分類為不同的主題和情感類型[7]。
圖書館可借助其強大功能,從訓練中學習語言規律構建自已的語言模型。通過微調、預訓練語言模型以適應圖書館的數據集,能夠顯著提升館藏數字資源的數據組織水平。Transformer憑借其卓越的技術適用性,還能有效地預訓練音視頻等多模態館藏資源,為用戶帶來了全新的服務體驗。
3.賦能咨詢應答的思維鏈技術
通過讓大模型逐步參與將一個復雜問題分解為一步一步的子問題,并依次進行求解的過程可以顯著提升大模型的性能,這一系列推理的中間步驟就被稱為思維鏈(Chain of Thought,CoT)。強大的邏輯推理是大語言模型“智能涌現”的核心能力之一,好像AI有了人的意識一樣。CoT技術的引入徹底改變了傳統的“問題-答案”模式,創新性地采用“問題-思維鏈-答案”的方式,讓用戶能夠直觀地了解答案背后的推理過程。這個推理過程從改變語境、調整句子結構以及替換詞匯等方面增強大語言模型,進一步優化自然語言模型的性能。這些訓練使大型語言模型具有上下文理解能力,準確領悟并理解自然語言請求,能夠更精確地解答用戶提出的問題。
大語言模型擁有強大的邏輯推理,可以更高效、準確地理解人類提出的復雜語義問題。智能問答、文本生成等應答對話成為未來咨詢系統重要部分。這種“智能涌現”對話,顛覆了舊信息咨詢的方式。用戶以自然語言的方式輸入需求,系統嘗試自動分析輸入的文本并生成適當的響應。經過大量文本數據的預訓練,大語言模型已在各種自然語言處理任務中展現出卓越的性能,支持多種來源、不同類型的知識表達方式,通過多次交互為用戶提供更智能化的問答體驗。當用戶通過接入大語言模型的參考咨詢系統向它提問時,實際上是和一個經過深度學習訓練的“圖書館專家”進行對話。
4.讓檢索專業度大眾化的人工智能生成式技術
生成式人工智能(AIGC)是一種革命性的技術,它結合了機器學習模型和深度學習技術,通過深入分析歷史數據的內在規律,能夠創造出全新的文本、圖像、音頻和視頻內容。生成式AI不是根據給定的規則或數據生成輸出,而是自主生成全新內容,類似于人類的創造。大語言模型能夠利用海量數據進行計算,持續推動內容創新。它融合了“機械反饋-智能識別-深度學習”的核心理念,使得人機交互方式從被動反饋逐漸演變為多維交互,最終實現學習交互的飛躍。
通過處理后的資源組織覆蓋了圖書館自有及開放性資源,能為用戶檢索提供有深度和智能的數據基礎。檢索是知識服務的前提,在大語言模型賦能下的生成式信息獲取途徑中,不需要用戶選擇專業關鍵詞和根據檢索結果進行判別,無論是需求明確還是需求不明確的復雜任務都被納入簡潔明了的對話交互。用戶通過日常化語言表述咨詢需求即可。檢索結果中可能存在大量無關內容,要想對所提供的信息進行再檢索,只需用戶輸入新需求再次生成即可,大大地提高了用戶的體驗,并且在創造性生成任務當中展現出深度,滿足用戶查全、查準的需求。這種語義理解和文本生成的能力為學科服務的轉變提供了基礎。
(二)賦能的數據資源基礎
大語言模型信息獲取的方式加速了圖書館資源建設智能化。大語言模型在資源建設方面展現出了顯著的優勢,相較于傳統方式,它能夠高效地完成自動化資源采集和處理任務。該模型能夠從眾多的數據源中收集相關的數據,并對其進行規范整理和自動化標注。學術數據庫、公文數據、開放性數據以及業務系統數據等包含其中。這樣的獲取方式不僅節省了圖書館人員大量的時間和精力,還提升了資源建設的效率和準確性。
大語言模型具備強大的資源整合能力,能夠將圖書館內的各種非結構化資源進行整合利用。它密切關注用戶的信息行為,深入挖掘用戶的需求,從而進行有針對性的研究。模型可以構建多功能專屬圖譜,實現圖書館服務中各場景的協調與交互,提升圖書館的高效性、協調性和針對性感知功能,為用戶提供更加精準、個性化的服務體驗。
三、大語言模型賦能圖書館知識服務可能的應用模式
大語言模型的技術和理念優勢將在圖書館產生新的知識服務模式。大語言模型將在參考咨詢系統自然語言化、資源助手個性化、學科服務精細化和生成化,情報服務直觀化和大眾化等方面產生更加積極的影響。
(一)使用自然語言的參考咨詢系統
大語言模型憑借強大的上下文學習能力、多輪對話功能以及思維邏輯推理能力,為參考咨詢服務注入了新的活力。新咨詢系統在自然語言對話匹配和內容生成方面展現出卓越的性能,能夠精準捕捉用戶的提問,并提供滿意的回答。
圖書館可以提供微調訓練好的線上LLM參考咨詢服務系統或虛擬數字人館員助手,隨時隨地為用戶提供咨詢服務。用戶在進行問答時只需輸入照自然語言指令即可。LLM參考咨詢服務系統或虛擬數字人館員助手在接收到指令時,會根據上下文進行實時分析,識別出用戶的用意,無須用戶從檢索結果中進行判別,直接在檢索結果中呈現出最準確的選項,并且可以在連續的對話中保持上下文理解,借用多輪長對話的方式為用戶提供精準的智能問答。
(二)新型的資源推廣-個性化的閱讀推廣方式
大語言模型憑借強大的語義化整理能力,能夠深入剖析圖書館資源間的內在聯系,自動生成館內資源的摘要,還能協助用戶對海量信息進行有序整理和歸納,從而顯著提升知識獲取的效率。更值得一提的是,大語言模型打造的個性化閱讀助手能夠結合用戶的興趣偏好,精準捕捉用戶的潛在需求與情緒、意愿,并自主挖掘知識資源,進行推理和自我優化。用戶借助自然語言輕松表達查詢需求,閱讀助手則依據用戶的個性化喜好和閱讀習慣進行精確檢索與摘要,自動生成多模態信息以輔助閱讀。當用戶鎖定目標文獻后,閱讀助手更是憑借文本挖掘、機器學習和文本分類等先進技術,協助用戶迅速提煉和總結文獻的核心內容。此外,它還能對文章進行批量深度分析,揭示其中的結構、演變和難點,探索潛藏的現象關聯與科學規律,為用戶帶來前所未有的閱讀體驗。
(三)精細化的生成式學科知識服務
圖書館的核心目標是提供“知識服務”。技術的進步催生了用戶需求服務類型的多樣化與個性化趨勢,舊的圖書館學科知識服務確實已經難以滿足當今用戶的復雜需求。
資源組織語義化后,圖書館資源中的文本、圖像和視頻形成有效鏈接,實現了跨模態聯合,自動形成主題化、專題化的分類體系。學科知識服務借此完成更高效、精準且多樣的蛻變。文獻資源的深層內容也被大語言模型強大的學習能力剖析出來,圖書館資源描述從表面信息組織方式向語義內容組織方式轉變,知識組織得到精細化管理。此外,大語言模型還能構建內容豐富、檢索便捷的知識庫系統。該系統只需自然語言就能進行多模態檢索,自動生成答案并補充相關材料,可根據用戶需求進行智能推薦,并以對話的形式進行交互體驗,從而顯著提升用戶的知識服務體驗[8]。
(四)直觀化、大眾化的情報服務
圖書館信息檢索服務的效率和準確率對于提升用戶的檢索體驗至關重要。大語言模型在知識總結和輸出方面展現出了強大的能力,通過智能創作邏輯結構,對情報服務功能產生了深遠影響。大語言模型輕松應對代碼編寫、語言翻譯、文案撰寫,極大地豐富了情報服務的內容。大語言模型還能夠深入理解輸入內容,并精準反饋信息,有效實現定題服務的目標[9]。
大語言模型以其出色的文本生成創作能力,能夠精準地理解上下文,并流暢地進行多輪對話。圖書館可借助這一強大工具,迅速獲取直觀的答案,不僅提升了效率,還有效提高了圖書館情報服務的時效,提高了用戶的情報服務體驗。
四、結語
目前,以人工智能為代表的信息科技發日新月異,引入以ChatGPT為代表的大語言模型的科技成果將大大推動智慧圖書館建設進程。圖書館應加大科研資金投入,積極探索和研究大語言模型在圖書館服務中的應用,創造圖書館領域專屬的大語言模型應用產品,以更好地滿足用戶需求。
事情都有兩面性,面對大語言模型應用熱潮,圖書館需要謹慎、準確定位其在圖書館事業中的作用,避免圖書館服務的核心被忽視,失去自身的存在意義。如何避免用戶數據泄露、虛假數據傳播、知識產權糾紛等問題是圖書館人使用大語言模型要面臨的挑戰。謹慎面對,直面變化是當下應對以大語言模型為代表的人工智能發展的良策。
參考文獻
[1]郭亞軍,郭一若,李帥,等.ChatGPT賦能圖書館智慧服務:特征、場景與路徑[J].圖書館建設,2023(2):30-39+78.
[2]中國政府網.中共中央辦公廳國務院辦公廳印發《關于推進實施國家文化數字化戰略的意見》[EB/OL].http://www.gov.cn/xinwen/2022-05/22/content_5691759.htm.
[3]趙瑞雪,黃永文,馬瑋璐,等.ChatGPT對圖書館智能知識服務的啟示與思考[J].農業圖書情報學報,2023,35(01):29-38.
[4]郭亞軍,寇旭潁,馮思倩,等.大語言模型賦能圖書館參考咨詢服務:邏輯、場景與體系[J/OL].圖書館論壇.https://link.cnki.net/urlid/44.1306.G2.20240220.0947.004.
[5]郭利敏,付雅明.以大語言模型構建智慧圖書館:框架和未來[J].圖書館雜志,2023,42(11):22-30+133.
[6]郭亞軍,馬慧芳,張鑫迪,等.ChatGPT賦能圖書館知識服務:原理、場景與進路[J/OL].圖書館建設.http://kns.cnki.net/kcms/detail/23.1331.G2.20230713.1606.004.html.
[7]王翼虎,白海燕,孟旭陽.大語言模型在圖書館參考咨詢服務中的智能化實踐探索[J].情報理論與實踐,2023(08):96-103.
[8]羅飛,崔濱,辛小江,等.大語言模型嵌入圖書館知識服務的風險范式與管控策略[J].圖書與情報,2023(03):99-106.
[9]王毅,董怡婷.類ChatGPT人工智能在圖書館智慧服務中的應用與思考[J].圖書館理論與實踐,2023(06):129-136.
基金項目:福建商學院校級項目“高校思政課教學資源對教學目標達成研究”(項目編號:2023SJB01)
作者單位:福建商學院
■ 責任編輯:王穎振、鄭凱津
