基于深度學習的遠程醫療公共價值評價體系
2024-12-31 00:00:00王一敏梁治鋼栗源宏
中國新通信 2024年20期

摘要:本文研究深度學習在遠程醫療公共價值評價體系中的應用。對遠程會診病人的診療結果文本數據挖掘中,利用深度學習神經網絡模型進行數據分析和處理,結合公共價值理論體系,從而更好地為基層患者提供合理的治療方案。該方法不但降低了醫療成本,而且達到各方多贏的局面。經過分析,該方法在既定規則的指導下,自主學習生成公共價值知識庫,為患者提供優質的診療服務。
關鍵詞:深度學習;公共價值;數據挖掘
一、引言
為實施健康中國戰略,建設健康城市、健康鄉村以及健康社區已經成為其有力的保障,對于醫療機構而言,如何利用好各類醫療資源去實現是眼前著重考慮的問題。遠程醫療體系已經經過這些年的發展,已經在各個地區落地建設,有了不少成功的經驗和案例。但是目前仍然存在優質的醫療資源利用率不高,分布不合理的問題,在基層醫療機構,醫療人才的匱乏,醫療人才的嚴重流失,已經成為深化醫改和保障生命健康的短板。
公共價值理論的核心是公共價值創造,它提出政府和團體設計開發出滿足公眾需求與期望的公共服務或產品。本研究引入公共價值理論,包括公共價值、合法性與支持、運作能力,來研究探索我國遠程醫療的發展現狀和問題,對于遠程醫療發展和方向的提出分析思考。
二、公共價值
公共價值理論是哈佛大學馬克莫爾教授在1995年出版的《創造公共價值:公共部門的戰略管理》一書中提出,是指同一客體或同類客體同時能滿足不同主體甚至是公共民眾需要所產生的效用和意義,它的內涵包括三個方面:一是指客體的公共效用,二是指主體的公共表達,三是指規范的公益導向[1]。在醫療領域,公共價值體現在醫療機構為患者提供最合理的診療服務,而不是以盈利和增值為目標。
三、遠程醫療的公共價值
(一)遠程醫療的重要意義
遠程醫療的開展對于優化醫療資源結構布局是非常有利的,它可以有效的促進了醫療機構之間的工作重心和資源合理分配。在擴大上級醫院診治疑難重癥的同時,也可以提高基層醫院的服務水平。通過提升整體醫療服務效率和質量,更好的實施分級診療。
遠程醫療體系借助雙向轉診通道推動上下連通,形成基層首診、雙向轉診、上下聯動、急慢分治的分級診療格局。通過分級診療,學科能力強的醫院發揮學科優勢,診治疑難雜癥,人才培養;基層醫院解決常見病和慢病管理,形成對患者在家門口協同連續的服務整合型醫療服務模式[2]。
借助公共價值服務理論,結合公共價值和遠程醫療,探究多方共贏的模式,挖掘遠程醫療發展的可行路徑。
(二)公共價值治理三角模型
該模型主要由“公共價值—合法性支持—運作能力”構成。
公共價值:在遠程醫療范圍內,政府、醫療機構和患者都有一個共同的價值目標追求,以患者的健康為根本目標,提供可靠和安全以及持續的醫療服務,開展各類形式診療服務,遠程醫療可以遵循社會公共價值理論,由政府和衛健部門牽頭,基層醫療機構和公眾參與,進行遠程醫療體系建設。
合法性與支持:對于遠程醫療涉及到的醫療機構和患者,他們之間行為受到公共價值約束,獲得來自政府、醫院、患者三方的支持才能實現為患者提供優質的診療服務這個目標,合法性才能得以體現。醫療機構在開展遠程醫療服務過程中應當嚴格遵守相關法律、法規、信息標準和技術規范,建立健全遠程醫療服務相關的管理制度,確保遠程醫療相關業務的正常展開。
運作能力:公共價值三角模型中的運作能力指達成價值目標的能力,強調公共價值的實現需要強有力的組織能力和資源。在遠程醫療過程中,通過整合醫療資源,優化醫療服務和人力資源配置,使得基層醫療機構和三甲醫院之間公共資源共享。
四、公共價值知識庫
(一)深度學習
深度學習(Deep Learning)是機器學習的一個分支,采用多層神經網絡(稱為深度神經網絡)來模擬人腦的復雜決策能力。它是基于深層神經網絡模型的機器學習技術。它是在傳統機器學習、人工神經網絡等模型基礎上,結合大數據和大算力發展出來的,它是具有學習和提取特征的能力,采用多層復雜結構或者采用多重非線性變換構成的多個層進行數據處理[3]。
NLP是自然語言處理(Natural Language Processing)的縮寫,它是計算機科學領域中專注于研究如何使計算機理解、生成和處理人類語言的學科。NLP涉及的技術包括但不限于分詞、詞性標注、句法分析、語義分析、機器翻譯、情感分析、信息抽取、文本生成等。
文本挖掘(Text Mining)是自然語言處理(NLP)領域中的一項重要技術,它涉及從大量非結構化文本數據中提取有用信息和知識的過程。文本挖掘的目標是幫助人們從文本數據中發現隱藏的模式、趨勢和關系,以便更好地理解和利用這些數據。
(二)分類流程
患者從遠程會診病歷獲取會診數據,其中記錄了基本信息、醫保性質、地區、歷次會診數據、檢查檢驗結果等數據,將這些數據經過數據清洗和標準化處理后作為輸入數據。系統將這些數據在特定規則下進行分析和處理,將公共價值嵌入到系統分析規則中,最后得到相應的輸出結果,結果以知識庫的形式存在于系統中,整個過程按照既定的算法完成 [3]。
(三)基于卷積神經網絡的文本挖掘
獲取患者的相關醫療數據,通過標準化和臟數據清理,將這些數據作為輸入數據。文本特征過程分文本預處理、特征提取、文本表示三個部分,最終目的是把文本轉換成計算機可理解的格式,也就是以知識庫的形式存在于系統中。
1.文本預處理
文本預處理是自然語言處理(NLP)中的一種過程,旨在為進一步分析準備文本數據。它包括分詞、詞性標注、命名實體識別、文本向量化、數據分析、特征處理、數據增強等過程。在本文中,需要對原始的會診數據進行降噪和標準化處理,去掉一些無意義的詞。對于一些醫學專業用語全部采用了小寫方式,以免與一些關鍵字或者符號沖突,避免在后續的數據分析和處理中出現錯誤。
2.Skip-gram 模型
該模型是通過預測上下文詞來訓練詞向量,包括輸入層、投影層、輸出層,是在已知給定詞前提下預測該詞的上下文。
(1)輸入層:接收一個One-hot張量V∈R作為網絡的輸入,里面存儲著當前句子中心詞的One-hot表示。
(2)編碼映射層:對于輸入的每個詞Xt,編碼映射層將通過如下的線性變換映射成為一個低維空間的向量et,
et = W1Xt+c1;W1∈R,c1∈R" " " " " " " (1)
(3)解碼映射層:前一個編碼產生的輸出作為后一個解碼映射層的輸入。
Zt =W2et+c2;ht =softmax(Zt)" "W2∈R,c2∈R" " " (2)
其中W2和c2是解碼層的變換矩陣及偏置向量,Zt對應中間輸出結果,Softmax函數是將高維向量X映射成為同維度的向量Y,其作用是將高維向量轉換成一個概率分布[4]。
在本文中,數據集內容是由不同的會診患者病歷里面的各類檢驗檢查結果形成的患者診療意見和結論,患者診療已經和結論經過預處理和文本向量表示,使文本數據從高緯度高稀疏的矩陣形式轉換成了連續稠密數據[3]。
(四)數據挖掘規則
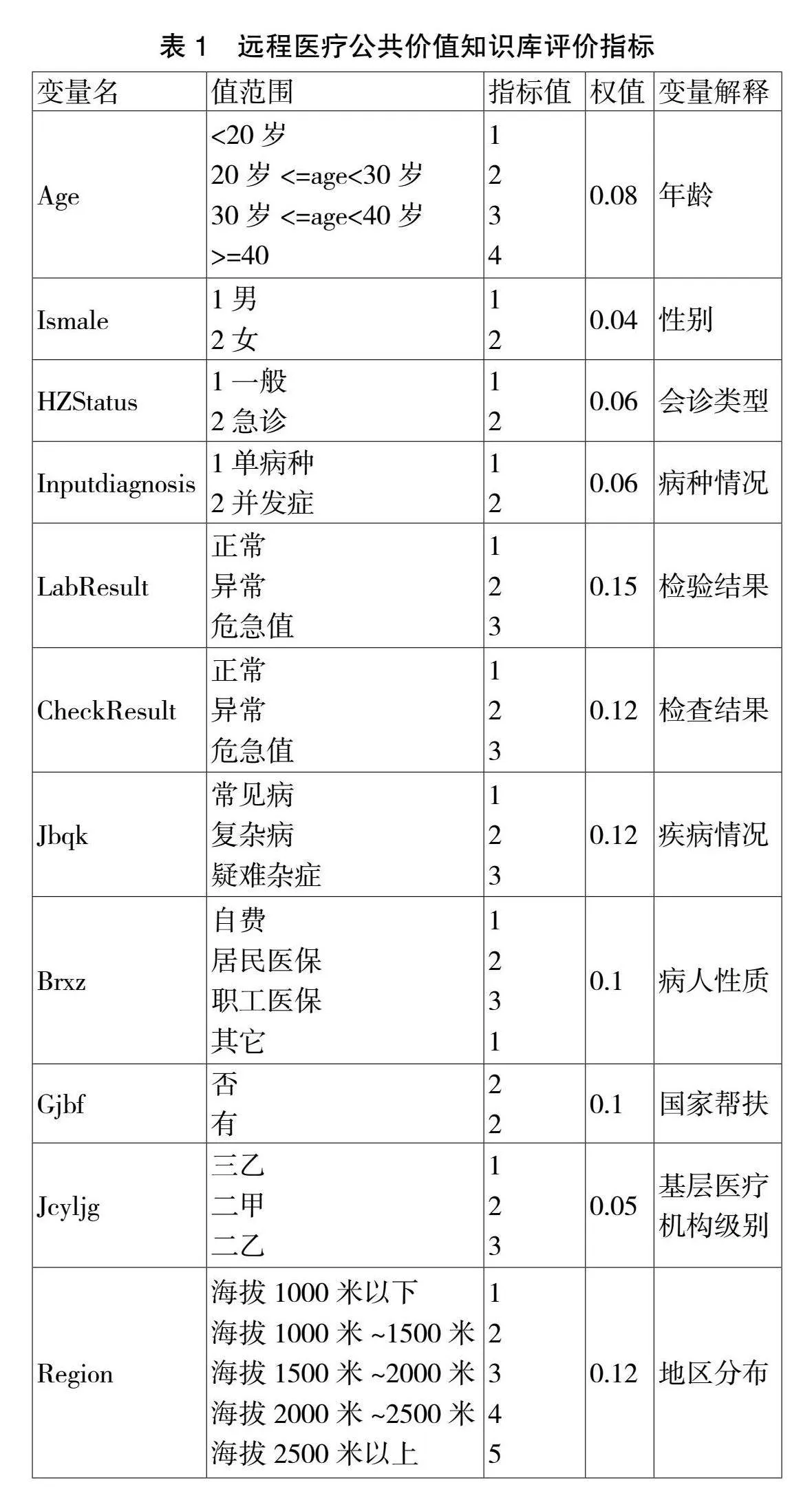
深度學習算法在本文中被引入來進行分類分析,通過建立公共價值知識庫和規則特征庫,從而尋求患者治療的最優解,使得政府、醫院、患者三方共贏。表1里面是各個變量名稱和指標值如表1所示。
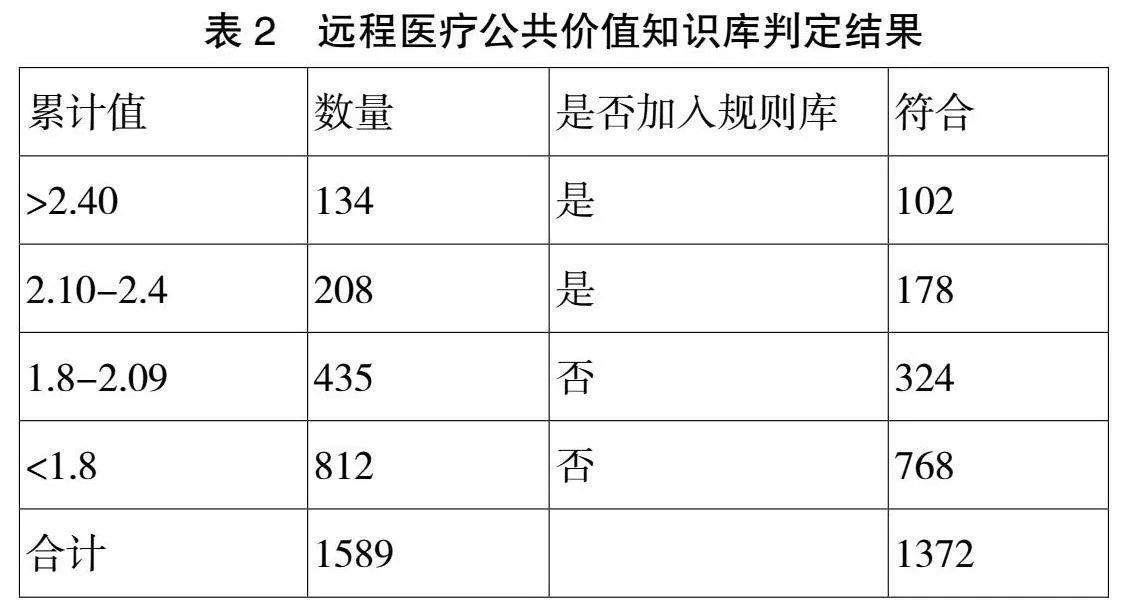
數據挖掘的目標對2023年一個月內的會診病人進行分析,結合公共價值理論,通過深度學習算法,讓患者在合理的成本控制下得到最佳的治療方案。每個患者的個體生理指標都有差異,診療方案沒有統一的標準,只能根據會診相關診療信息進行分析判斷,結合患者多種條件分析從而獲得最適合患者的特征庫。在創建知識庫的過程中,按照表1中的指標變量值進行總和判斷,具體判定標準是變量累計值gt;2.4,達到公共價值輔助決策第1級,變量累計值2.10-2.4達到公共價值輔助決策第2級,加入知識庫;變量累計值小于2.09不加入知識庫。
(五)驗證結果
在整個的系統運行過程中,結合本文中提出的算法,對2023某月的1589名會診患者進行自然語言分類分析,主要是將公共價值評價分析規則加入遠程醫療中,最終形成遠程醫療公共價值知識庫,最終的輸出結果如表2所示。
五、結束語
本文分析深度學習在遠程醫療公共價值評價體系中的應用,借助深度學習神經網絡進行研究,建立會診病人公共價值數據知識庫并進行知識發現。
根據規則和算法測試結果,深度學習在會診患者研究上,一定程度上可以幫助基層醫生對會診病人公共價值評價體系的實現,在政府、醫院、患者之間形成一個共贏局面,從而更加有效的利用現有的醫療資源為患者服務,對公共價值分析知識庫和規則庫可以進行有效更新,對其中的噪聲數據進行了處理,給患者的治療決策提供數據基礎。
作者單位:王一敏 梁治鋼 栗源宏 甘肅省人民醫院
參考文獻
[1]張敏.基層協商民主的公共價值管理:一個實踐路徑探索[J].探索,2018,(05):61-70.
[2]王雪,張磊,王文華,羅怡,袁瀟瀟.國內外遠程醫療發展演化及研究趨勢可視化分析[J].2023,(02):47-55.
[3]梁治鋼,王一敏.深度學習在電子病歷抗菌藥物使用方法分類中的應用[J].計算機系統應用.2019,28(08):71-77.
[4]張若非,付強,高斌,等.深度學習模型及應用詳解[M].北京:電子工業出版社,2019:53.
猜你喜歡
大眾投資指南(2021年35期)2021-02-16 01:06:26
電力與能源(2017年6期)2017-05-14 06:19:37
江蘇教育·中學教學版(2016年11期)2016-12-21 11:36:29
現代情報(2016年10期)2016-12-15 11:50:53
新教育時代·教師版(2016年23期)2016-12-06 06:02:38
法制與社會(2016年32期)2016-12-01 15:25:53
中國中醫藥信息雜志(2016年7期)2016-12-01 06:07:55
軟件導刊(2016年9期)2016-11-07 22:20:49
軟件工程(2016年8期)2016-10-25 15:47:34
信息通信技術(2015年6期)2015-12-26 01:16:46
