基于WGAN-GP 和Mean Teacher 的WiFi 使能跨域人體行為識別
2024-12-26 00:00:00史心癑夏文超趙海濤楊麗花阮欣雨常天水
無線電通信技術 2024年6期
關鍵詞:模型


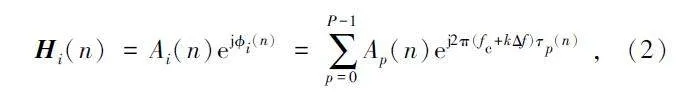
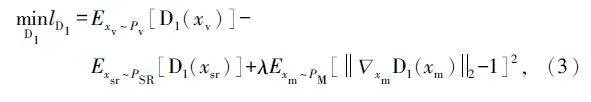
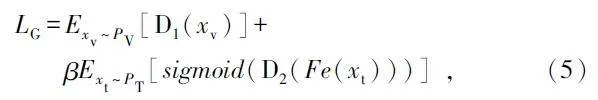
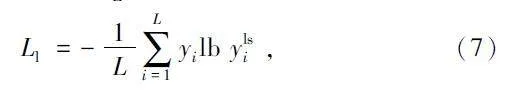

摘 要:人體行為識別(Human Activity Recognition,HAR)是當前眾多研究工作的基石,對于推動人機交互和智能數字化轉型具有巨大潛力。由于目標域樣本較難采集,現有方法在跨域識別方面表現不佳。為解決這一問題,提出一種新的WiFi 使能跨域HAR 方法,從WiFi 信號中獲取信道狀態信息(Channel State Information,CSI)并轉化為圖像,在基于Wasserstein 距離和梯度的生成對抗網絡(Wasserstein Generative Adversarial Network with Gradient Penalty,WGAN-GP)中引入雙判別器,通過與源域樣本和單目標域樣本特征聯合對抗,生成同時帶有雙域特征的虛擬樣本。該方法還結合基于Mean Teacher 的半監督學習設計識別分類(Recognition and Classification,RC)模塊,通過對有標記樣本與無標記樣本分別構造損失函數,進行整體一致性損失的評估,實現對目標域樣本的識別。實驗結果證明了所提方法能夠在減輕目標域樣本采集壓力的同時,實現較高的檢測精度,在手勢與動作的數據集上測試準確率分別達到92. 71% 和86. 65% 。
關鍵詞:人體行為識別;生成對抗網絡;Mean Teacher 模型;跨域識別
中圖分類號:TN92 文獻標志碼:A 開放科學(資源服務)標識碼(OSID):
文章編號:1003-3114(2024)06-1192-08
0 引言
隨著移動通信與物聯網的飛速發展,各種業務類型層出不窮。其中,全息遠程呈現、無人駕駛、多感官互聯等新型業務對感知的需求愈發迫切,特別是人類活動。區別于剛性物體例如汽車和建筑物,人類活動對信號的傳播存在著更加復雜的影響[1]。相比于傳統感知方式,例如使用穿戴式傳感設備、對攝像內容進行分析檢測等,通感協同的方式能夠節約成本,減少隱私的泄露。這一技術在當下蓬勃發展的人機交互領域有著廣泛的應用前景,也可以在醫療告警及其他方面提供有力的技術支持,因此成為了當前至關重要的一項研究。
目前,WiFi 信號是最常見的室內無線信號[2],可用于感知周圍環境。人體對無線信號有較好的反射特性,因此能夠穿墻的WiFi 信號在人體行為識別(Human Activity Recognition,HAR)這一領域有諸多優勢,包括方便性、簡易性、隱私保護性以及設備的低成本。
通常來說,WiFi 信號主要用于通信,可以采用接收信號強度指示器(Received Signal Strength Indi-cator,RSSI)[3]或信道狀態信息(Channel State Infor-mation,CSI)[4]進行信道狀態分析。不過RSSI 信號為粗粒度,且穩定性不高,受具體設備型號及其他影響較大。CSI 信號優勢在于能夠提供關于信道狀態相對精確的信息,當人類在檢測范圍內活動,人體對WiFi信號進行的反射通常會在WiFi 接收器上產生獨特的CSI 變化。例如,在多載波系統中,對于其中的每個子信道,發射器與接收器天線上都能夠測量傳播的無線信號,并提供不同子信道的幅度與相位失真,從而分析其在時域的變化對不同的人和活動所呈現出的不同模式,這已經足夠滿足當前的HAR 需求[5]。
目前,已有許多工作集中討論了使用WiFi 信號的CSI 數據進行HAR[6-11]。在這些工作中,大致可以分為相同環境和跨環境兩方面來進行研究。早期的研究大多集中在相同環境下的檢測問題,例如,文獻[8]展示了基于WiFi CSI 數據的室內定位和日常生活中的活動檢測。文獻[9]通過去除噪聲和冗余,對原始CSI 測量進行處理,然后使用卷積神經網絡和長短期記憶網絡模型結合執行HAR。文獻[10]將CSI 信號轉化為無線電圖像,并通過深度稀疏自動編碼器學習HAR 的區分特征。文獻[11]發現兩個天線上CSI 相位差相比于幅值更加敏感,能夠更可靠地區分活動,與時頻域的急劇功率分布下降模式結合,并使用支持向量機進行檢測分類。
而近期的研究和應用表明,WiFi 信號實際上受環境影響較大,傳統的檢測模型在新環境下容易變得不再適用,識別效果較差[12-13]。因此,近年來這一領域的研究重點主要轉向能夠適應環境變化的檢測方法,比如提取環境無關特征和域適應方法。文獻[14]采用差異化的速度特征來區分跌倒與日常生活動作,從而規避了不同環境對識別的干擾。文獻[15]采用遷移學習網絡,通過提取源域和目標域中共享的特征來實現環境穩健的HAR。文獻[16-17]分別使用少樣本學習網絡和元學習。
盡管這些方法在一定程度上實現了與環境無關的行為識別,但也存在一些局限性。尤其是源域樣本的質量會很大程度地影響訓練后模型識別的精度,當源域樣本多樣性不足時,模型性能急劇下降。因此,生成對抗網絡(Generative Adversarial Network,GAN)被引入,通過生成大量類目標樣本來增強模型的泛化能力[18]。但GAN 通常不夠穩定,容易生成不同質量水平的樣本,這對模型的訓練會造成不良的影響。
針對以上的問題,在現有研究工作基礎上,提出了一種基于改進的基于Wasserstein 距離和梯度的生成對抗網絡(Wasserstein Generative AdversarialNetwork with Gradient Penalty,WGAN-GP )[19] 和Mean Teacher[20]的行為檢測模型,主要貢獻如下:
① 提出了帶有雙判別器的虛擬樣本生成(Virtual Sample Generation,VSG)模塊,在傳統的GAN 中增設一個判別器用于目標域樣本評分,能夠在與源域樣本對抗生成的同時,引導生成器生成與目標域樣本含有相似特征的虛擬樣本。
② 提出了針對有標簽樣本與無標簽樣本分別構建的樣本集和損失函數,基于兩個樣本集聯合訓練,實現整體訓練的一致性損失評估,完成對目標域樣本的識別。
數值結果驗證了所提方法可以在降低采集目標域樣本難度的前提下,實現較高的檢測精度,在手勢與動作的數據集上測試準確率分別能夠達到92. 71% 和86. 65% 。
1 系統模型
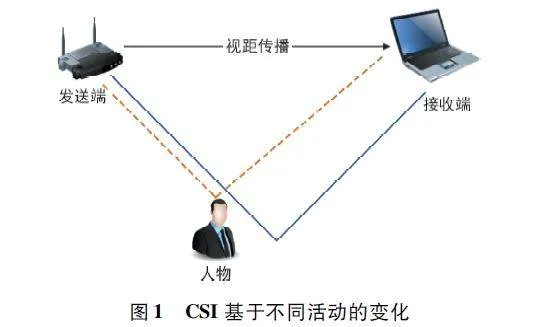
WiFi 信號除了用于通信,也可以解決HAR 問題,這是因為在WiFi 信號覆蓋范圍內人體移動會影響多徑傳播。本文考慮典型的室內環境,家用WiFi路由器位置是靜態的,發送端與接收端間存在視距傳播與非視距傳播,可借助CSI 隨著人體活動的變化來推斷人的當前活動狀態,具體如圖1 所示。
傳統的半監督方法在每一個輪次都需要更新參數,當使用數據量較大的數據集時,參數更新緩慢。為解決這一問題,本文使用Mean Teacher 模型來改善這一情況。Mean Teacher 模型能夠對模型的權重進行滑動平均,可以用來估計變量的局部均值,使得變量更新與一定時間內的歷史值相關。但MeanTeacher 在跨域進行目標識別時,由于目標域數據樣本采集通常比較困難、可用樣本數量少,導致訓練出的模型容易產生偏差。換言之,基于Mean Teacher方法訓練出來的模型泛化性差。
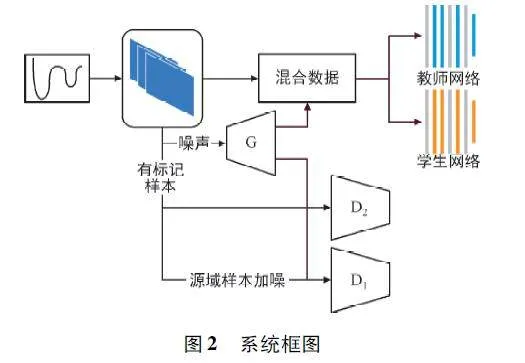
針對上述問題,提出了基于WGANGP 和MeanTeacher 的WiFi-GAN-based Mean Teacher (WGMT)模型,主要分為3 個部分:數據預處理(Data Prepro-cessing,DP )、VSG 和識別分類(Recognition andClassification,RC)模塊,其框架如圖2 所示。
其中,基于改進WGANGP 的VSG 模塊,針對每個行為動作,結合大量帶標簽的源域樣本和單目標域樣本生成虛擬樣本,通過與兩個判別器聯合對抗,生成同時帶有源域動作信息和目標域環境信息的類目標樣本,提高模型對目標域的適應性。此外,為提高模型的魯棒性,本文嘗試對源域樣本進行隨機加噪,然后再輸入模型,增強了網絡的抗噪能力。該模型能夠運用單目標域標記樣本進行更好的目標域行為識別。
2 本文方法
如上所述,本文所提方法包括3 個模塊,即DP、VSG 和RC。DP 模塊用于獲取圖像,將生成圖像輸入VSG 模塊生成類目標樣本。使用真實樣本與虛擬樣本進行Mean Teacher 的模型訓練,接下來將依次介紹這3 個模塊。
2. 1 DP 模塊
信道沖激響應(Channel Impulse Response,CIR)是信號在時域上的響應,矩陣的行代表信道的響應在不同時間點上的取值,列代表不同的傳播路徑對信號的影響。通過對CIR 矩陣進行頻域轉換,并分析其頻域響應的幅度部分,即可提取出對應的CSI信息。
CSI 幅度可以根據人體反射特定多徑信號的程度來描述人體活動,而相位則反映了路徑長度變化導致的延遲。從圖1 中可以看出,當人體進入傳播路徑時,信號從原本的地面反射變為人體反射,傳播路徑變短,接收端所收到的CSI 信號發生變化。
在無線信道上,接收信號Y 與發射信號X 的關系可以表示為:
Y=HX+N, (1)
式中:H 為信道增益矩陣,N 為噪聲矩陣。矩陣H中每個元素代表CSI 值。通常情況下,對于位置固定、發射角度為θ 的WiFi 發射器而言,其信道矩陣可建模為:
式中:i∈{1,2,…,K}、n∈{1,2,…,N}、p∈{1,2,…,P}分別為子載波、分組和多徑數索引,fc 為主載波頻率,Δf 為符號頻率,τp(n)為第p 個子載波上第n 個分組的時延。
使用巴特沃茲濾波器對CSI 數據濾波,通過短時傅里葉變換可以得到圖像數據[21]。
2. 2 VSG 模塊
傳統方法中,通常通過大量采集數據并標注的方式來得到目標域有標記樣本,這些樣本的數量會直接影響模型的訓練效果。然而,數據需要通過對照已知類型的方式確定標簽并進行人工標注,人力與時間的消耗和樣本的數量成正比。這也意味著,當環境發生變化時,需要重新采集新環境下的樣本,這會帶來非常巨大的資源消耗。在資源有限的前提下,目標域內通常只能獲得數量非常有限的有標記樣本。而通過生成虛擬樣本,能夠有效緩解真實樣本缺失造成的問題。
因此,本文引入WGANGP 模型并加以改進僅需在目標域批量采集樣本,并確保每個類型能篩選一個樣本,其余樣本均無需標記,即可用來生成類目標樣本。
理想情況下,GAN 應當在訓練后達到對抗的納什均衡。但在實際訓練中,傳統GAN 中判別器的訓練效果通常遠遠好于生成器,導致虛擬樣本與真實樣本易被區分。WGAN 引入Wassertein 距離解決了這一問題,通過從虛擬樣本與真實樣本所有可能的聯合分布中采樣計算二者的期望距離,并對該期望值向取下界的方向優化,使虛擬樣本盡可能地接近真實樣本。但在優化過程中,為避免梯度波動引入的截斷方式又帶來了新的問題。具體而言,在各類GAN 中判別器希望區分出虛擬樣本與真實樣本,真實樣本會得到更高的分數,而虛擬樣本則只能得到低分。這意味著判別器希望損失函數盡可能大,則其計算梯度會沿著損失函數變大的方向優化,這會導致參數都會被截斷限制,最終停留在閾值邊界,使得判別器傳輸給生成器的梯度變差甚至消失。針對該問題,WGANGP 模型通過引入梯度懲罰項來緩解梯度消失問題。具體而言,使用梯度懲罰代替截斷,通過在損失函數中添加一個額外的正則化項,懲罰判別器在輸入樣本處的梯度模長使其偏離1,在強制判別器保持Lipschitz 連續性的同時,避免了截斷可能導致的不穩定性問題。
為更好地實現跨域工作,同時考慮到目標域標記樣本采集的困難性,提出了基于WGANGP 的VSG 模塊。VSG 模塊有兩個判別器D1 和D2,目的是指導生成器G 盡可能地生成與真實樣本相似的虛擬樣本。VSG 通過給真實樣本高評分,給虛擬樣本低評分來實現。
為了免生成結果與真實樣本過度相似而失去生成虛擬樣本的意義,不同于GAN,預先對真實樣本添加高斯噪聲z。定義源域樣本為xs,目標域樣本為xt,生成的虛擬樣本為xv。引入常數α∈(0,1)權衡樣本數據與噪聲的比例,則輸入D1 的樣本為xsr =αxs +(1-α)z。判別器D1 的目標可以定義為:
式中:xm =εxsr +(1-ε)xv,ε ~ U(0,1)為一隨機常數變量,PV、PSR、PM 分別為樣本xv、xsr、xm 服從的分布。
判別器D2 的輸入來自目標域樣本xt,D2 的設計目的是引導生成器G 生成與目標域樣本特征相似的樣本。D2 的損失函數可相應求得:
式中:PT 為樣本xt 服從的分布,與D1 類似,D2 的目標也是最小化其損失函數min D2 LD2。
生成器G 通過與判別器對抗來學習已知活動分類的特征信息,并生成與真實樣本相似的虛擬樣本。則生成器G 的優化目標為min G LG,其中損失函數LG 定義為:
式中:常數β 為用于平衡源域與目標域特征的權重參數。
2. 3 RC 模塊
RC 模塊旨在基于采集到的樣本與上述步驟生成的虛擬樣本實現對已知類中的行為樣本識別。需要指出的是,傳統的Π 模型[22]在訓練前期僅使用標記數據,要求損失函數中的無監督分量必須緩慢增長,否則網絡會快速收斂,導致訓練得到無效解。在實際應用中,這一要求極大地限制了模型訓練的運算速度。Temporal Ensembling(TE)[22]則是在Π的基礎上采用當前與歷史模型預測結果的均值做均方差計算,保留歷史信息的同時有效地消除了擾動并保持穩定,但仍舊存在面對大數據集時需要對每個輪次進行標簽更新,導致訓練緩慢的問題。針對上述問題,本文提出了改進的Mean Teacher 模型用于動作識別分類。
Mean Teacher 通過將模型假定為兩種角色,即學生模型和教師模型,來解決這一問題。這兩個模型架構相同,與TE 的區別在于,該方法對模型權重而不是預測結果進行加權平均,有效地減少了對有標簽數據的需求,減少了運算負擔。本文提出的基于Mean Teacher 的RC 模塊也分為教師模型和學生模型。對于學生模型而言,本文使用真實樣本與VSG 模塊得到的虛擬樣本作為輸入。學生模型對輸入樣本提取特征,計算得到模型預測值與真實標簽之間的損失,從而更新學生模型的參數,教師模型則用于對無標記樣本生成偽目標標簽來指導學生模型學習。
為避免教師模型生成錯誤的偽標簽,導致無監督部分的損失遠大于監督部分的損失,從而使模型的性能變差,本文使用學生模型權重的指數移動平均(Exponential Moving Average,EMA)來更新教師模型的參數,即:
θ′t =γθ′t-1 +(1-γ)θt, (6)
式中:θt 為學生模型在t 時刻的參數,θ′t 為教師模型在t 時刻的參數,常數γ∈(0,1)用于調節訓練期間參數的權衡。即教師模型基于歷史模型參數與最新學生模型參數給出偽標簽,保證了模型參數的穩定性。在訓練初期,學生模型通過訓練提升較快,因此γ 的值相對較小,便于教師模型更快地過濾之前不好的參數。在訓練后期,學生模型參數趨于穩定,γ的值也相應增大,從而避免某次錯誤參數更新影響整體訓練,得到更加穩定的模型。
在本文所提方法中,源域樣本與VSG 模塊生成的類目標樣本為有標記樣本,將其定義為樣本集XL ={(xli,yi)|Li},其中,xli代表有標記樣本,yi 代表對應樣本的標簽,L 為該樣本集內的樣本數量;目標域樣本為無標記樣本,將這部分樣本定義為樣本集XU ={xui|Ui},其中,xui代表無標記樣本,U 為該樣本集內的樣本數量。
針對有標記樣本XL,構造其分類損失函數為:
式中:ylsi 代表學生模型對樣本xli的預測結果,通過與真實標簽對比來更新學生模型的參數。對于未標記樣本XU,學生模型和教師模型對同一個輸入進行預測,通過計算學生模型預測結果與教師模型預測結果之間的均方誤差(MeanSquare Error,MSE)構建一致性損失函數:
式中:yuti 代表教師模型對樣本xui的預測結果,yusi 代表學生模型對樣本xui的預測結果。本文使用Lu 懲罰教師模型和學生模型之間的預測結果差異,引導學生模型訓練出更佳的參數。需要注意的是,教師模型在此處只起到一個提供預測偽標簽的作用,其參數不依靠損失函數的反向傳播來更新。
學生模型整體的損失函數可以定義為:
L=Ll +Lu。(9)
據此可完成對目標的識別與分類。
2. 4 復雜度分析
對所提方法進行復雜度分析。類似地[23],VSG模塊的復雜度為O(nV ×mV ×kV),其中nV 為VSG 迭代次數,mV 為一次迭代中的總訓練步驟,kV 為一個訓練步驟內的反向傳播要求,即對抗樣本生成與網絡參數更新的總要求,由于存在兩個判別器,在最壞的情況下,一個訓練步驟中包括兩次判別器評分與3 次參數更新,即kV≤5。
同理,RC 模塊的復雜度為O(nR ×mR ×kR ),其中nR 為RC 的迭代次數,mR 為一次迭代中的總訓練步驟,kR 為一個訓練步驟內的反向傳播要求,即學生模型與教師模型參數更新的總要求,在最壞的情況下,一次訓練步驟中存在4 次參數更新,即kR≤4。
綜上,所提WGMT 模型的總復雜度為O(nV ×mV ×kV +nR ×mR ×kR)。
3 仿真分析
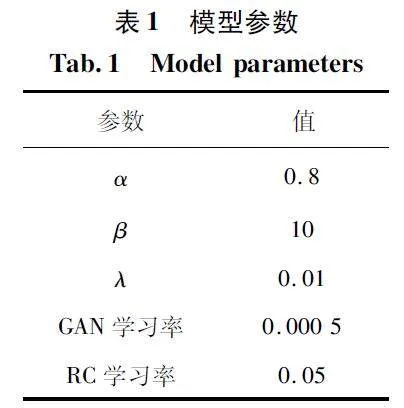
本節將通過實驗仿真對所提的WGMT 模型性能進行評估,使用平均準確率作為評估指標。文中所用的參數設置如表1,其中GAN 和Mean Teacher模型均使用Adam 優化器,但學習率不同。
本文使用兩個公開數據集Signfi[24]和WiAR[25]進行實驗,其中Signfi 數據集是由5 個用戶執行的150 個手語手勢數據,每個手勢各10 條;WiAR 數據集是由10 個用戶執行的16 個行為動作,每個動作各30 條,本文選用其中的5 個用戶數據。由于在HAR 領域,不同的人的人體形態及動作習慣均有區別,即可以視為每個人的數據均為不同的域內數據。因此,在本文所設的實驗環境中,采用其中一人的數據作為測試數據,其他人的數據作為訓練數據。同時,選取大量目標域未標記樣本用于訓練,以滿足Mean Teacher 模型的需求。
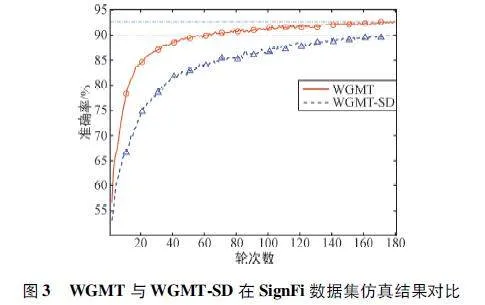
為更好地對比,設計了一個變體WiFi-GAN-basedMean Teacher with Single Discriminator(WGMT-SD)用于實驗。該變體使用單個判別器的生成網絡,即傳統未經過改進的WGAN-GP 作為VSG 模塊,其為制變量,本文將在WGMT 方法中將用于訓練VSG 模塊的所有樣本用于WGAN-GP 訓練。
由于WGMT 與WGMT-SD 區別在VSG 模塊,因此進一步分析該模塊復雜度。所提的VSG 模塊主要在損失函數層面改進,對模型的復雜性幾乎沒有影響。具體而言,前文所述WGMT 中VSG 模塊的復雜度為O(nV ×mV ×kV),kV ≤5。而WGMT-D 僅存在一個判別器,在最壞的情況下,一個訓練步驟中包括一次判別器評分與3 次參數更新,即kV ≤4。因此,WGMT-SD 中VSG 模塊的復雜度為O(nV ×mV ×kV),kV≤4。
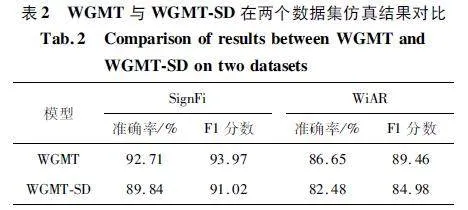
雖然所提方法的復雜度略高于對比方法,但WGMT 相對于WGMT-SD 提高了識別準確率,仿真結果如圖3 所示,可以看出,使用改進后VSG 模塊的WGMT 方法準確率為92. 71% ,使用傳統WGAN-GP 模塊的WGMT-SD 方法準確率為89. 84% ,即WGMT 方法比WGMT-SD 方法提升了2. 87% 的準確率。
此外,對二者在不同數據集中的平均準確率與F1 分數匯總如表2 所示,說明本文所提WGMT 方法在跨域的識別中,無論是在動作識別還是手勢識別上都有顯著優勢,這意味著對目標域樣本的合理利用,能夠有效地增強模型最后的識別性能。
不難看出,所提方法對手勢的識別精度比對行為動作的識別精度高,因為手勢通常具有較為明顯的模式和動態特征,而動作可能涉及更廣泛的時間范圍,模式更加復雜。
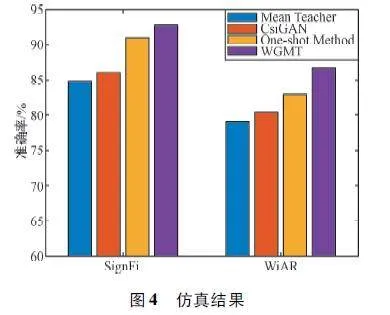
為更好地展示本文所提模型的有效性,引入以下幾種算法作為對比。
① Mean Teacher:基于純粹Mean Teacher 的半監督學習框架,使用學生模型權重的EMA 值定義教師模型的權重,通過最小化師生模型預測差異進行訓練。
② CsiGAN[26]:設計了補碼生成器,用于有限未標記數據產生新的虛擬樣本,從而提高判別器的魯棒性,并優化鑒別器的決策邊界,提出流形正則化方法穩定學習過程。
③ One-shot Bimodal Domain Adaptation Method(One-shot Method)[27]:通過源域與單目標域樣本線性變換和合成自動編碼器實現虛擬樣本的合成,并為幅度與相位設置融合模態,提高識別精度。
這些模型在兩個數據集上的性能匯總如圖4 所示。實驗結果表明,本文所提方法在跨域環境下的手勢識別及動作識別中都有較好性能,充分顯示了所提方法的優越性。
4 結束語
本文基于改進后的WGAN-GP 和Mean Teacher構建了一個名為WGMT 的跨域HAR 框架。通過對傳統GAN 結構進行調整,增設一個對目標域樣本特征進行評分的判別器,指導生成器生成與已知活動類別樣本有相似特征的樣本,有效地提高了模型對目標域的適應性,大大減輕目標域樣本采集難度的同時,保證了識別的準確性。通過在兩個公共數據集的實驗證明,所提的WGMT 方法能夠提高手勢及動作的識別精度,優于其他現有方法。
參考文獻
[1] LI X Y,CUI Y H,ZHANG J A,et al. Integrated HumanActivity Sensing and Communications[J]. IEEE Communications Magazine,2022,61(5):90-96.
[2] ZOU H,YANG J F,DAS P H,et al. WiFi and VisionMultimodal Learning for Accurate and Robust DevicefreeHuman Activity Recognition[C]∥Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops. Long Beach:IEEE,2019:426-433.
[3] CUI W,ZHANG L,LI B,et al. Received Signal StrengthBased Indoor Positioning Using a Random Vector Functional Link Network[J]. IEEE Transactions on IndustrialInformatics,2017,14(5):1846-1855.
[4] ZHANG Y,LIU Q Q,WANG Y J,et al. CSIbased Locationindependent Human Activity Recognition UsingFeature Fusion[J]. IEEE Transactions on Instrumentationand Measurement,2022,71:5503312.
[5] MA Y S,ZHOU G,WANG S Q. WiFi Sensing withChannel State Information:A Survey[J]. ACM ComputingSurveys (CSUR),2019,52(3):1-36.
[6] WANG Y,LIU J,CHEN Y Y,et al. Eeyes:Devicefreelocationoriented Activity Identification Using Finegrained WiFi Signatures[C]∥ Proceedings of the 20thAnnual International Conference on Mobile Computingand Networking. New York:ACM,2014:617-628.
[7] WANG W,LIU A X,SHAHZAD M,et al. Devicefree Human Activity Recognition Using Commercial WiFi Devices[J]. IEEE Journal on Selected Areas in Communications,2017,35(5):1118-1131.
[8] YOUSEFI S,NARUI H,DAYAL S,et al. A Survey on Behavior Recognition Using WiFi Channel State Information[J]. IEEE Communications Magazine,2017,55 (10):98-104.
[9] HUANG S,WANG D,ZHAO R,et al. Wiga:A WiFibased Contactless Activity Sequence Recognition SystemBased on Deep Learning[C]∥2019 15th InternationalConference on Mobile AdHoc and Sensor Networks(MSN). Shenzhen:IEEE,2019:69-74.
[10]GAO Q H,WANG J,MA X R,et al. CSIbased Devicefree Wireless Localization and Activity Recognition UsingRadio Image Features[J]. IEEE Transactions on VehicularTechnology,2017,66(11):10346-10356.
[11]WANG H,ZHANG D Q,WANG Y S,et al. RTFall:ARealtime and Contactless Fall Detection System withCommodity WiFi Devices[J]. IEEE Transactions on MobileComputing,2016,16(2):511-526.
[12]FALLAHZADEH R,ASHARI Z E,ALINIA P,et al. Personalized Activity Recognition Using Partially AvailableTarget Data[J]. IEEE Transactions on Mobile Computing,2021,22(1):374-388.
[13]SHI Z G,ZHANG J A,XU R Y,et al. EnvironmentrobustDevicefree Human Activity Recognition with ChannelStateInformation Enhancement and Oneshot Learning[J]. IEEE Transactions on Mobile Computing,2020,21(2):540-554.
[14]HU Y Q,ZHANG F,WU C S,et al. A WiFibased PassiveFall Detection System[C]∥ICASSP 2020 -2020 IEEEInternational Conference on Acoustics,Speech and SignalProcessing (ICASSP). Barcelona:IEEE,2020:1723-1727.
[15]ZHANG J,TANG Z Y,LI M,et al. CrossSense:TowardsCrosssite and Largescale WiFi Sensing[C]∥Proceedingsof the 24th Annual International Conference on Mobile Computing and Networking. New York:ACM,2018:305-320.
[16]ZHANG Y,CHEN Y,WANG Y J,et al. CSIbased HumanActivity Recognition with Graph Fewshot Learning[J].IEEE Internet of Things Journal,2021,9(6):4139-4151.。
[17]ZHANG Y,WANG X Y,WANG Y J,et al. Human ActivityRecognition Across Scenes and Categories Based on CSI[J]. IEEE Transactions on Mobile Computing,2022,21(7):2411-2420.
[18]WANG D Z,YANG J F,CUI W,et al. Multimodal CSIbased Human Activity Recognition Using GANs[J]. IEEEInternet of Things Journal,2021,8(24):17345-17355.
[19]GULRAJANI I,AHMED F,ARJOVSKY M,et al. ImprovedTraining of Wasserstein GANs[C]∥NIPS’17:Proceedingsof the 31st International Conference on Neural InformationProcessing Systems. New York:ACM,2017:5769-5779.
[20]TARVAINEN A,VALPOLA H. Mean Teachers are BetterRole Models:Weightaveraged Consistency Targets ImproveSemisupervised Deep Learning Results[C]∥NIPS’17:Proceedings of the 31st International Conference on NeuralInformation Processing Systems. New York:ACM,2017:1195-1204.
[21]ANGELOV A,ROBERTSON A,MURRAYSMITH R,et al.Practical Classification of Different Moving Targets UsingAutomotive Radar and Deep Neural Networks[J]. IET Radar,Sonar & Navigation,2018,12(10):1082-1089.
[22]LAINE S,AILA T. Temporal Ensembling for Semisupervised Learning[EB/ OL]. (2017 -03 -15)[2024 -03 -20]. https:∥arxiv. org/ abs/1610. 02242. 2016.
[23]ZHAO W M,MAHMOUD Q H,ALWIDIAN S. Evaluationof GANbased Model for Adversarial Training [J ].Sensors,2023,23(5):2697.
[24]MA Y S,ZHOU G,WANG S Q,et al. SignFi:Sign Language Recognition Using WiFi[C]∥Proceedings of theACM on Interactive,Mobile,Wearable and UbiquitousTechnologies,2018,2(1):1-21.
[25]GUO L L,WANG L,LIN C,et al. Wiar:A Public Datasetfor WiFibased Activity Recognition [J]. IEEE Access,2019,7:154935-154945.
[26]XIAO C J,HAN D J,MA Y S,et al. CsiGAN:RobustChannel State Informationbased Activity Recognition withGANs[J]. IEEE Internet of Things Journal,2019,6(6):10191-10204.
[27]ZHOU B,ZHOU R,LUO Y,et al. Towards Cross DomainCSI Action Recognition Through Oneshot BimodalDomain Adaptation[C]∥International Conference on Mobile and Ubiquitous Systems:Computing,Networking,andServices. Cham:Springer,2022:290-309.
作者簡介:
史心癑 女,(1999—),碩士研究生。主要研究方向:通感一體化、無線信號識別、人體行為識別等。
夏文超 男,(1991—),博士,副教授。主要研究方向:邊緣智能無線通信、通感一體化、大規模MIMO 等。
趙海濤 男,(1983—),博士,教授。主要研究方向:衛星物聯網、智能車聯網、工業互聯網等關鍵技術及系統研發等。
楊麗花 女,(1984—),博士,副教授。主要研究方向:移動無線通信、通信信號處理、多載波通信系統等。
阮欣雨 女,(2003—)。主要研究方向:人工智能、無線通信等。
常天水 男,(2005—)。主要研究方向:人工智能、無線通信等。
基金項目:國家自然科學基金面上項目(62371250);國家自然科學基金青年基金項目(62201285);江蘇省基礎研究計劃(自然科學基金)前沿引領技術基礎研究專項(BK20212001);江蘇省自然科學基金杰出青年基金項目(BK20220054)
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
網絡安全與數據管理(2022年1期)2022-08-29 03:15:20
導航定位學報(2022年4期)2022-08-15 08:27:00
中學生數理化·中考版(2022年8期)2022-06-14 06:55:24
新世紀智能(數學備考)(2021年9期)2021-11-24 01:14:36
成都醫學院學報(2021年2期)2021-07-19 08:35:14
新世紀智能(數學備考)(2020年9期)2021-01-04 00:25:14
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
