用于計算和傳輸的動態星間路由策略
2024-12-26 00:00:00許柳飛羅志勇
無線電通信技術 2024年6期
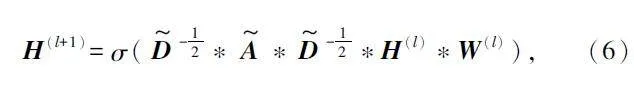
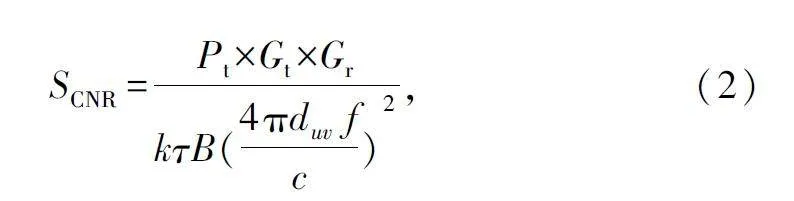



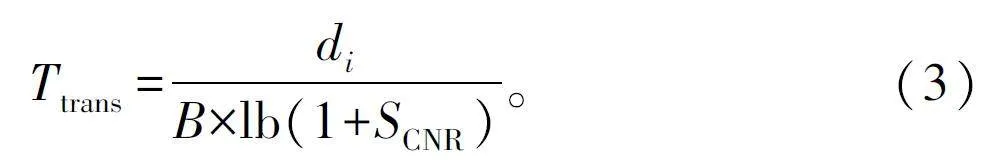


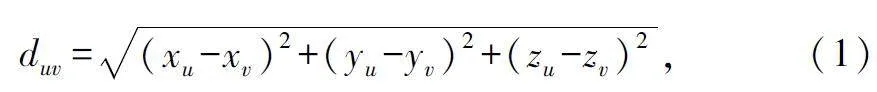
摘 要:針對低地球軌道(Low Earth Orbit,LEO)衛星網絡具有拓撲變化快、網絡節點多和節點資源狀態變化等特點,提出了一種用于計算和傳輸的星間路由策略。該策略使用改進的圖卷積網絡(EnhancedGraph ConvolutionalNetwork,EGCN)提取衛星網絡的時空特征并生成節點的隱藏狀態。將其作為深度強化學習(Deep ReinforcementLearning,DRL)模型的輸入,DRL 智能體感知下一跳節點的關鍵信息,從而更好地做出決策。仿真結果表明,與以前的方法相比,提出的方法提高了網絡的總吞吐量,降低了端到端傳輸延遲。
關鍵詞:星間路由策略;動態衛星網絡;深度強化學習;圖卷積神經網絡
中圖分類號:TN919. 23 文獻標志碼:A 開放科學(資源服務)標識碼(OSID):
文章編號:1003-3114(2024)06-1153-07
0 引言
目前,多個國家正在部署低地球軌道(LowEarth Orbit,LEO)衛星巨型星座,即擁有數百到數萬顆LEO 衛星以提供全球低時延高帶寬互聯網。隨著星上技術的飛速發展,衛星將擁有更強大的計算資源來支持在軌數據處理,以在軌道上提供公共云服務。
衛星計算的概念是計算資源部署在衛星上以實現在軌自主、遙感、邊緣計算等新范式,因此具備計算資源的衛星組成的網絡又稱為星云算網。首先,星云算網中具有計算能力的衛星能夠實現在軌自主操作,減少對地面段的依賴。其次,隨著星座規模的增大,太空原始數據呈爆炸式增長,又因為星地鏈路帶寬有限而導致數據無法及時下載。具有計算能力的衛星可以對原始數據進行處理,識別并傳輸感興趣的特征,從而提高傳輸效率并降低星地鏈路的帶寬利用率。最后,先進的星載計算平臺將衛星轉化為復雜的數據處理基礎設施,并使太空中的公共云服務能夠像在地面上一樣提供服務。
LEO 衛星巨型星座是一種新型的基礎設施,由數千顆衛星組成,每顆衛星相對于地球和其他衛星都以高速移動。例如,在550 km 高度的衛星必須保持27 000 km/ h 的速度才能維持其軌道。然而,星云算網仍面臨以下挑戰:① 受發射因素和體積限制,單顆衛星的計算資源存在上限;② 由于地表用戶分布存在差異,業務請求分布不均勻;③ LEO 衛星相對地面高速移動,因此其網絡拓撲結構具有快速變化的特點;④ 星地和星間傳播時延較大,如何降低業務延遲引起了網絡研究者的極大興趣。
基于上述挑戰分析,考慮可能存在業務分布不均、單顆衛星算力較低導致時延過大甚至擁塞的情況,學術界對此提出了用于計算和傳輸的動態星間路由機制[1],通過星間鏈路將業務從資源緊張的衛星轉移到其他衛星來輔助計算。由于衛星網絡快速變化的拓撲結構和星間傳播時延不可忽略,星間傳輸計算業務要考慮動態拓撲和時延以及星上算力對業務性能的影響[2]。如何在高動態的星云算網中高效地處理計算業務,是實現大規模星上計算和多星協作需要解決的重要問題之一,具有較高的研究價值。
1 相關工作
面對星云算網,如何基于計算和傳輸對業務性能進行優化,學術界展開了廣泛研究。文獻[3-5]利用了啟發式解決方案。張茜[3]考慮動態時變衛星網絡的資源約束和可見時間窗約束等,并提出基于遺傳算法的星間計算任務卸載算法,以提高計算效能。呼延?等[4]將傳統的衛星數據傳輸系統與星上智能處理相結合,提出一種遙感衛星高速數據傳輸框架。馬步云等[5]針對當前星地數據處理模式中存在的高傳輸時延問題,提出將基于算力路由的低時延在軌協同計算問題轉化為業務圖到網絡圖的映射問題。然而,這些基于規則的啟發式方法無法捕捉到網絡環境的復雜特征,因此難以進一步改進[6]。為突破上述局限,深度強化學習(Deep Reinforcement Learning,DRL)得到了廣泛應用,并對其展開了越來越多的研究[7-10]。曹素芝等[11]針對星地融合網絡面臨的復雜路由問題,提出了基于DRL 的星上路由機制訓練與部署方案。唐斯琪等[12]針對強化學習方法在星云算網領域的局限性和面臨的挑戰,提出了一種基于微調的模型遷移機制。汪昊等[13]考慮衛星網絡拓撲和星間鏈路的可用帶寬、傳播時延等約束,構建衛星網絡狀態用于基于強化學習的LEO 衛星網絡動態路由算法。由于DRL 是一種通過與環境(如動態衛星網絡)交互來優化策略(如星間路由策略)[14]的工具,與基于規則的啟發式相比,它應該能夠捕獲更多的環境特征[15],從而輔助DRL 智能體做出更好的決策。
2 LEO 衛星網絡系統
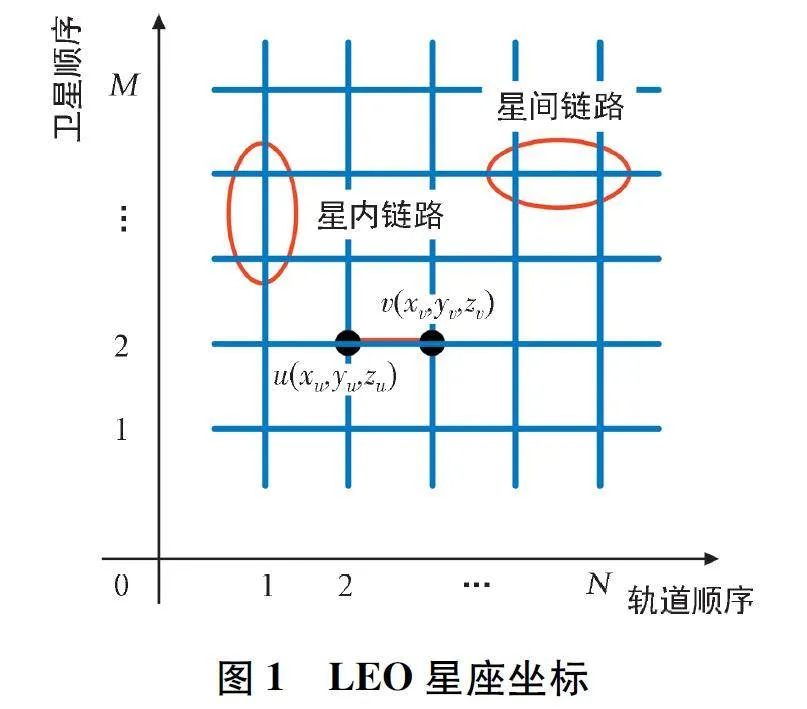
LEO 星座坐標如圖1 所示。考慮到動態衛星網絡場景,LEO 衛星網絡(LEO Satellite Network,LSN)系統的網絡拓撲用有向圖G(V,E)表示,V 和E 分別表示衛星和星間鏈路的集合。整個衛星網絡由N 個圓形軌道組成,每個軌道上有M 顆衛星。軌道上的LEO 衛星以及同一軌道上的衛星均勻分布。在該系統中,每顆LEO 衛星通過星內鏈路連接同一軌道的前一顆和后一顆衛星,通過星間鏈路連接相鄰軌道的衛星。星座兩側的衛星運動方向相反,導致星間鏈路連接的兩顆衛星之間的距離變化迅速,星間鏈路的連接斷斷續續。
2. 1 流量模型
LSN 系統中存在隨機加入的計算請求[16],并且每個請求的到達滿足參數為λ 的泊松過程[17]。將第i 個請求定義為元組TR(src,ci,di),其中src 表示源節點;ci 表示計算能力,即計算1 bit 所需要的計算資源,單位為周期/ 比特;di 表示請求的數據大小,單位為bit。計算請求被定義為傳輸和計算的最小單元,并被路由到計算節點進行處理,因此每條路徑上只有一個計算節點。另外,計算請求必須在一定時間內被處理,然后離開網絡;否則,該請求被視為拒絕處理。
2. 2 時延模型
星間鏈路的傳輸延遲由傳輸時延、傳播時延和計算時延組成。在動態LSN 系統中,如果兩兩衛星,即{u,v| u,v∈V}滿足建立星間鏈路的條件,則該衛星對之間的歐幾里得距離表示為:
式中:(xu,yu,zu)表示節點u 的空間位置。
由于衛星間通信主要受自由空間路徑損耗和加性高斯白噪聲的影響,兩兩衛星之間的載噪比可表示為:
式中:Pt 為發射功率,Gt 和Gr 分別為發射天線增益和接收天線增益,k 為玻爾茲曼常數,τ 為熱噪聲,單位K;B 為信道帶寬,單位Hz;f 為載波頻率,c 為光速。因此,計算請求無干擾環境的星間鏈路上的傳輸時延定義為:
忽略傳輸過程中較小的距離變化,計算請求在星間鏈路上的傳播時延定義為:
Tprop =duv/c 。(4)
計算節點處的計算時延定義為:
Tcom = ci/Cn, (5)
式中:Cn 為計算節點為每個請求提供的最大計算能力。
2. 3 優化問題
動態星間路由策略的目的在于找到從源節點u到計算節點v 的最優路徑,從而降低計算請求的平均傳輸延遲并提高總吞吐量。整個過程[18]可以劃分為:① 尋找從源節點到下一跳節點的傳輸邊,用于傳輸計算請求的數據;② 如果下一跳節點的計算資源滿足請求需要,則將該節點視為計算節點并處理數據,否則重復過程①。這樣,動態星間路由策略的優化過程就是找到與特定計算節點相關聯的最短傳輸路徑,并找到與該優化傳輸路徑相對應的最優計算節點。
動態星間路由策略對于LSN 系統來說是一項具有挑戰的任務。有效的路由策略不僅要識別受時變傳輸延遲和計算資源波動影響的衛星網絡上的關鍵資源,還要處理未來請求生成中的不確定性。基于強化學習的方法適合處理這種復雜狀態,并考慮潛在的未來影響。故在DRL 框架中,有一個智能體,其目標是為每個計算請求實時選擇最優的下一跳節點。而智能體的學習過程是由一個目標函數控制的,該目標函數的目的是最小化傳輸延遲、最大化總吞吐量。
對于基于機器學習的問題,數據和特征決定性能上限,而模型和算法只能接近這個極限。因此,在基于強化學習的框架中,輸入狀態表示和特征提取必不可少,但在文獻中并沒有得到很好的研究。前文介紹了一些工作的簡單狀態表示和特征提取,然而,由于時變的LSN 拓撲結構和波動變化的星上計算資源,上述文獻的特征提取可能不足以用于DRL智能體的學習。因此,本文提出了一種基于改進的圖卷積網絡(EnhancedGraph Convolutional Network,EGCN)的感知狀態表示,通過捕捉衛星網絡結構的動態演變和計算資源波動的規律,從而確保DRL 智能體依據這些實時且精確的信息做出更加準確的決策。下面通過考慮星間路由問題的具體特征,設計動態衛星網絡的特征提取和強化學習框架的狀態表示。
3 基于DRL 的下一跳節點的選擇機制
本節詳細描述強化學習模型的關鍵元素(狀態、動作和獎勵)。由于神經網絡參數化的智能體被訓練來完成狀態到動作的映射。因此,狀態應該攜帶足夠的信息來學習這種映射。為了獲取足夠的信息,提出使用EGCN 來提取動態衛星網絡的特征。
3. 1 基于EGCN 的狀態表示
動態衛星網絡的狀態表示應該由星上鏈路的傳輸時延、節點的算力資源以及節點的發送容量和承載容量來定義。由于衛星網絡是一種拓撲結構,因此其節點和鏈路上的特征不能直接用向量或矩陣表示。
3. 1. 1 圖卷積網絡模型
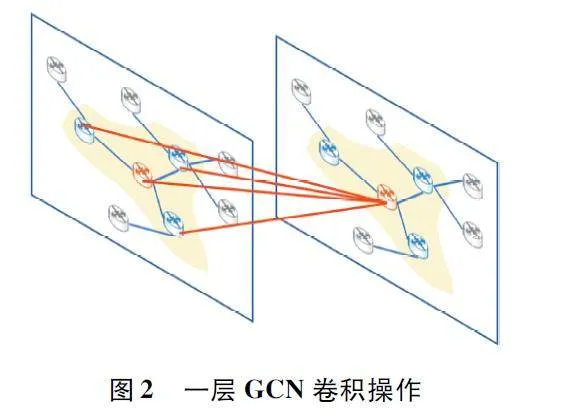
衛星網絡通常被建模為圖形,節點表示衛星,邊表示衛星之間的連接。鄰接矩陣為A,特征矩陣為X。一層圖卷積網絡(Graph Convolutional Network,GCN)卷積操作如圖2 所示,GCN 通過一階鄰域捕獲節點的空間特征,然后通過多個卷積層累加高階空間特征,可以表示為:
式中:A ~ = A+IN 表示加了自連接的鄰接矩陣,D ~ 為度矩陣,D ~ii = ΣNj = 1A ~ij ,D ~ - 12 ~A ~ ~D ~ - 12 表示預處理,W(l)為權重矩陣,σ 為激活函數,H(l)為第l 層的特征矩陣。
由式(6)可知,GCN 模型可以從網絡拓撲結構中學習空間特征。當前節點作為中心,一層的GCN卷積操作能夠獲取周圍鄰居節點的特征,GCN 可以通過疊加多個卷積層來捕獲多跳節點的空間特征。
3. 1. 2 改進方法
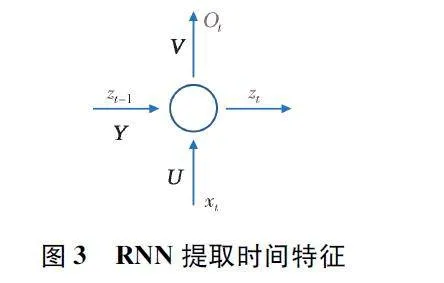
對于下一跳節點的選擇問題,星間鏈路上的傳輸時延與路由性能密切相關。而GCN 模型只能處理節點的特征信息、鏈路的連接關系以及鏈路的單一權重信息,無法對衛星網絡中鏈路的多屬性參數(即計算請求在不同時刻的同一衛星對之間的星間鏈路上的傳輸時延不同)進行分析。為了具體描述鏈路信息,本文根據節點間的關系增加“虛”節點來表示鏈路特征,通過聚合“虛”節點特征并合并到下一跳節點特征中。這樣,鏈路信息就成為節點特征向量的一部分。為了捕捉衛星網絡上節點和鏈路信息的時間特征,提出先在特征矩陣X 上使用遞歸神經網絡(Recurrent Neural Network,RNN)來有效學習星上資源以及星間鏈路傳輸時延的動態變化規律。RNN 通過考慮時間t-1 的隱藏狀態zt-1 和當前信息作為輸入xt 來計算時間t 的狀態并作為輸出ot,即:
zt =g1(U×xt +Y×zt-1), (7)
ot =g2(V×zt), (8)
式中:U、V、Y 為可訓練矩陣,g1、g2 為激活函數。
通過這種方式,模型能夠保留歷史信息并捕捉時間依賴性,同時仍結合當前時刻的信息。RNN 提取時間特征如圖3 所示。
3. 2 動作空間和獎勵函數
當計算請求到達當前節點時,智能體將根據K 個候選相鄰節點選擇下一跳節點。因此,動作被定義為at∈A={1,2,…,K},A 為候選相鄰節點的集合。即使在小型網絡中,候選節點的數量也會導致高維的動作空間。相關研究表明[15],K 個候選節點與性能的關系更大,所以K 的數量不需要很大。因此,每個當前節點從 Ko K=5p 個最近的節點中選擇下一跳節點(按每跳距離長度衡量)。
智能體根據從外部環境接收的獎勵不斷更新參數來提高性能。通常,一個成功的動作被認為是好的,因此環境返回一個正的即時獎勵,以加強當前動作被選擇的概率。并且,為了盡量減少失敗動作出現的概率,環境會返回一個負獎勵并讓智能體探索替代動作。然而,獎勵函數并不是“正確”行為的明確指標,而是向智能體反饋當前動作很好。智能體的目標是最大化長期獎勵,比如,折扣累積獎勵。為了實現這一點,智能體可能會放棄具有最佳瞬時獎勵的行為以獲得更好的長期績效,因此獎勵函數可以指導動態星間路由策略的優化方向。為了研究特征提取的重要性,將獎勵函數定義為一個二元變量rt∈{-1,1},本文提出的方法期望最小化傳輸延遲、最大化總吞吐量。
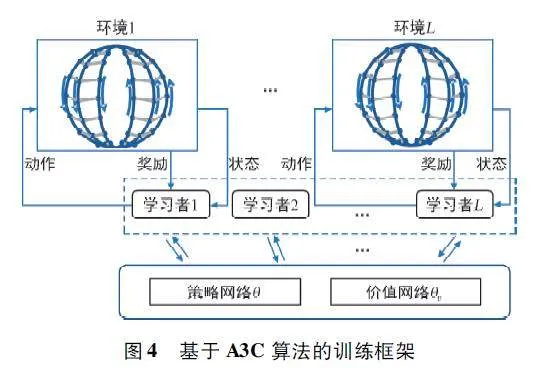
3. 3 基于A3C 的訓練過程
異步優勢動作評價(Asynchronous AdvantageActorCritic,A3C)算法屬于典型的DRL 算法,它有許多并行運行的局部學習者,如圖4 所示。其中,策略函數和值函數分別采用兩個神經網絡,即策略網絡π(at |st;θ)和價值網絡V(st;θv)。對每個學習者的策略網絡和價值網絡設置了特定的參數,分別為θ′和θ′v 。
策略函數和價值函數由每個學習者以異步方式更新。對于每個學習者,每集都進行更新,包括T 個連續動作(時間步長t0 ~ t0 +T-1)。局部學習者的參數首先由θ′←θ、θ′v ←θv 進行刷新。經過一集的訓練后,全局參數由式(10)給出的最小批量(批量大小為T)梯度上升或下降更新,即:
4 性能分析
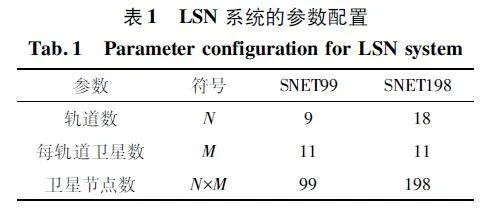
本文通過在SNET99 和SNET198 兩個衛星網絡上仿真對提出的方法進行評估,衛星網絡參數如表1 所示。
4. 1 仿真參數
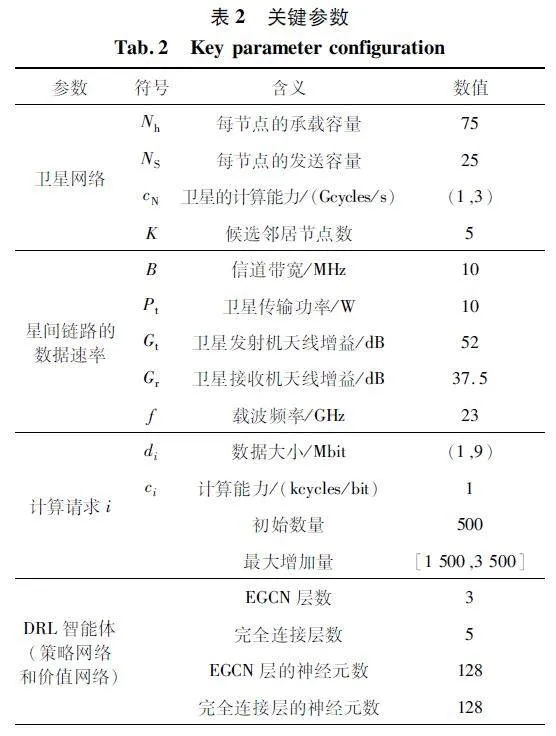
關鍵參數如表2 所示。計算請求根據泊松過程生成,源節點是從均勻分布的所有衛星節點中隨機選擇。
策略網絡使用softmax 輸出,價值網絡使用線性輸出,所有非輸出層都由ReLU 激活。在訓練過程中使用小批量梯度下降和Adam 優化器。
本文提出的方法被命名為“EGCN+DRL”。可比較的方法包括隨機路徑路由“RP”(即從鄰居節點集中隨機選擇下一跳)、最短路徑路由“SP”(即選擇最近的鄰居節點作為下一跳)和基于圖卷積神經網絡和強化學習模型的方法“GCN+DRL”。
4. 2 不同拓撲下的網絡吞吐量結果
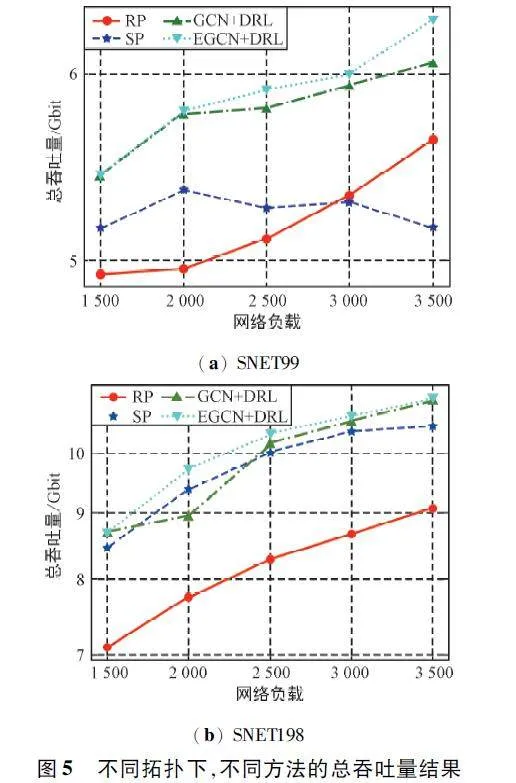
在兩個衛星網絡上進行仿真實驗,以驗證提出的方法在不同拓撲結果中的適用性。訓練過程中不同網絡負載下LEO 衛星網絡的總體吞吐量如圖5所示。
隨著網絡負載的增加,各種算法的總吞吐量也在增加。可以看出,所有基于DRL 的方法都優于基于啟發式的方法,顯示了基于強化學習方法的有效性。此外,“EGCN+DRL”在提高網絡吞吐量方面的性能優于其他3 種方法。將“EGCN+DRL”相對于比較方法的總吞吐量提升定義為:
P=SEGCN+DRL -S比較方法/S比較方法, (12)
式中:P 為一段時間內網絡的總吞吐量提升百分比。與圖5 (a)中的“RP”“SP”和“GCN +DRL”相比,“EGCN+DRL”的網絡吞吐量分別提高了13. 48% ,12. 27% 和1. 44% 。在圖5 (b)中進行了類似的觀察。
4. 3 不同拓撲下的平均傳輸延遲結果
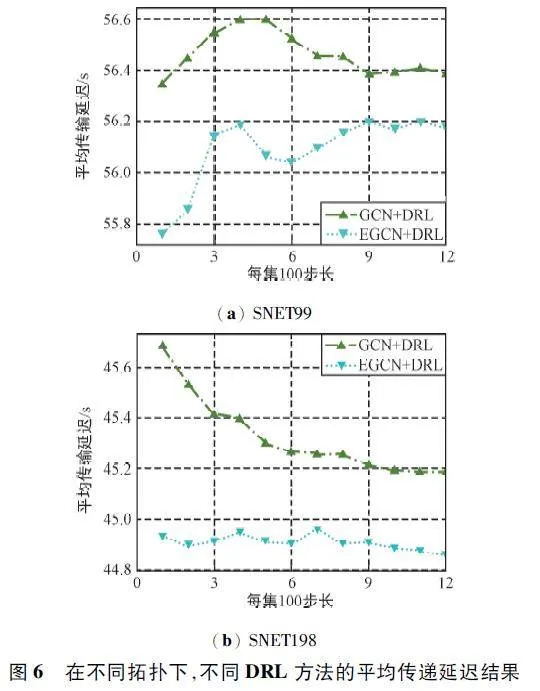
在不同拓撲下,不同DRL 方法的平均傳遞延遲結果如圖6 所示。
由圖6 可以看出,在訓練開始時,總體吞吐量較小,計算請求的平均傳輸延遲較小。隨著訓練的進行,總體吞吐量逐漸增加,請求的平均傳輸延遲先增大后減小。不同拓撲下的仿真結果相似,提出的方法達到了最佳性能。
此外,“EGCN+DRL”在網絡SNET99 中平均傳輸延遲降低幅度較小,在網絡SNET198 中平均傳輸延遲降低幅度較大。結合表1 的LSN 系統參數配置,總結可能的原因是網絡越發散和分布均勻,其傳輸延遲性能優化越好。
5 結束語
DRL 智能體需要經過長期的訓練才能達到可接受的性能,因此將算法直接應用于真實的衛星網絡環境不合理。就顯示情況而言,DRL 框架最好是在虛擬環境(比如數字孿生)中訓練,當性能變得可接受后再部署到現實環境中。因此,如何構建一個虛擬環境以盡量減少與現實環境的差異,如何設計一種在虛擬環境與真實環境具有差異的情況下仍可得到可接受性能的強化學習方法,這兩個問題值得探究。
本文研究了用于計算和傳輸的動態星間路由策略,提出利用改進的GCN 進行LSN 系統的環境狀態特征提取,將連接當前節點和下一跳節點的星間鏈路信息聚合到下一跳節點中,對GCN 模型的特征矩陣使用RNN 來有效學習星上資源波動和星間鏈路傳輸延遲的變化規律,由此捕捉衛星網絡上節點和鏈路信息的時間特征。又因為GCN 模型通過多層卷積操作可以得到當前節點與多跳節點的空間特征,通過二者結合,DRL 智能體可以感知與計算路由策略相關的關鍵信息,從而做出更好的決策。仿真結果驗證了該方法的有效性。
參考文獻
[1] ZHANG C,CHEN Q,TANG Z P,et al. Precoded InterSatellite Routing Algorithm with Load Balancing for MegaConstellation Networks[J]. Space:Science & Technology,2024,4:0103.
[2] DING C F,WANG J B,ZHANG H,et al. Joint Optimizationof Transmission and Computation Resources for Satelliteand High Altitude Platform Assisted Edge Computing[J].IEEE Transactions on Wireless Communications,2022,21(2):1362-1377.
[3] 張茜. 時變網絡下的多星協同計算方法[D]. 長沙:中南大學,2023.
[4] 呼延?,李映,周詮,等. 遙感衛星計算傳輸及其關鍵技術[J]. 天地一體化信息網絡,2022,3(2):63-71.
[5] 馬步云,任智源,郭凱,等. 基于算力路由的空間信息網絡低時延在軌協同計算策略[J]. 遙測遙控,2023,44(5):8-15.
[6] FENG C,SHEN Y,CAO G,et al. A Resource AllocationAlgorithm Based on GEO/ LEO Hierarchical ClusteringNetwork[C]∥Seventh Symposium on Novel PhotoelectronicDetection Technology and Applications. Kunming:SPIE,2021:1268-1272.
[7] 李京陽. 基于深度強化學習的衛星路由方法研究[D].石家莊:河北科技大學,2023.
[8] ZHANG S B,LIU A J,HAN C,et al. Graph NeuralNetwork and Reinforcement Learning Based Routing forMega LEO Satellite Constellations[C]∥2023 9th International Conference on Computer and Communications(ICCC). Chengdu:IEEE,2023:1-6.
[9] WANG H,RAN Y Y,ZHAO L,et al. GRouting:DynamicRouting for LEO Satellite Networks with GraphbasedDeep Reinforcement Learning[C]∥2021 4th InternationalConference on Hot InformationCentric Networking(HotICN). Nanjing:IEEE,2021:123-128.
[10]SHI Y J,WANG W A,ZHU X R,et al. Low Earth OrbitSatellite Network Routing Algorithm Based on GraphNeural Networks and Deep QNetwork[J]. Applied Sciences,2024,14(9):3840.
[11]曹素芝,孫雪,王厚鵬,等. 星地融合網絡智能路由技術綜述[J]. 天地一體化信息網絡,2021,2(2):11-19.
[12]唐斯琪,潘志松,胡谷雨,等. 深度強化學習在天基信息網絡中的應用———現狀與前景[J]. 系統工程與電子技術,2023,45(3):886-901.
[13]汪昊,冉泳屹,趙雷,等. 基于深度圖強化學習的低軌衛星網絡動態路由算法[J]. 重慶郵電大學學報(自然科學版),2023,35(4):596-605.
[14]PI J H,RAN Y Y,WANG H,et al. Dynamic Planning ofInterplane Intersatellite Links in LEO Satellite Networks[C]∥ICC 2022IEEE International Conference on Communications. Seoul:IEEE,2022:3070-3075.
[15]SORET B,RAVIKANTI S,POPOVSKI P,et al. Latencyand Timeliness in Multihop Satellite Networks[C]∥ICC2020-2020 IEEE International Conference on Communications (ICC). Dublin:IEEE,2020:1-6.
[16]WANG C,REN Z Y,CHENG W C,et al. TimeexpandedGraphbased Dispersed Computing Policy for LEO SpaceSatellite Computing[C]∥2021 IEEE Wireless Communications and Networking Conference (WCNC). Nanjing:IEEE,2021:1-6.
[17]ROSS S M. 應用隨機過程概率模型導論:第11 版[M].龔光魯,譯. 北京:人民郵電出版社,2016.
[18]TAO J H,NA Z Y,LIN B,et al. A Joint Minimum Hopand Earliest Arrival Routing Algorithm for LEO SatelliteNetworks[J]. IEEE Transactions on Vehicular Technology,2023,72(12):16382-16394.
作者簡介:
許柳飛 女,(1996—),博士研究生。主要研究方向:算力路由。
(*通信作者)羅志勇 男,(1973—),博士,教授,博士生導師。主要研究方向:衛星互聯網一體化融合、無線通感算融合賦能技術、通信人工智能應用。
基金項目:國家重點研發計劃(2023YFB2904701);廣東省重點研發計劃(2024B0101020006);廣東省區域聯合基金重點項目(2023B1515120093);深圳市自然科學基金重點項目(JCYJ20220818102209020)
