基于堆疊自編碼器的出口NOx濃度預測研究
2024-12-19 00:00:00饒永華
中國新技術新產品 2024年23期





摘 要:本文旨在利用堆疊自編碼器(SAE)預測工業排放中的NOx濃度,探索其在環境監測與控制中的應用潛力。研究人員通過篩選關鍵影響參數,確定對出口NOx濃度影響顯著的因素,使用SAE建立了一個有效的出口NOx濃度預測模型,具備較高的預測精度。此外,本文還提出了基于在線學習的模型參數自更新方法,實現了模型的動態調整以及適應性優化。對模型自適應更新效果進行分析,驗證了其在不斷變化的環境條件下的有效性。本文不僅為環境管理決策提供了科學依據,還在工業生產過程中提供了一種新的智能化預測方法,具有重要的理論及實際價值。
關鍵詞:堆疊自編碼器;NOx濃度預測;SAE網絡結構
中圖分類號:X 734 " 文獻標志碼:A
在環境保護需求下,準確預測并有效控制工業排放中的NOx濃度顯得尤為重要。傳統的監測方法通常依賴物理化學分析以及經驗模型,但這些方法往往受限于實時性以及數據處理復雜性,難以滿足復雜工業環境下的實時監測需求。而機器學習以及深度學習技術的發展為環境監測與預測提供了新的解決方案。堆疊自編碼器在特征學習以及非線性建模方面表現出色,被廣泛應用于各種數據預測以及處理任務中。其能夠通過無監督學習自動從數據中學習特征表示,具備較強的數據抽象能力與泛化能力,適用于復雜的工業過程數據分析。
1 出口NOx濃度關鍵影響參數篩選
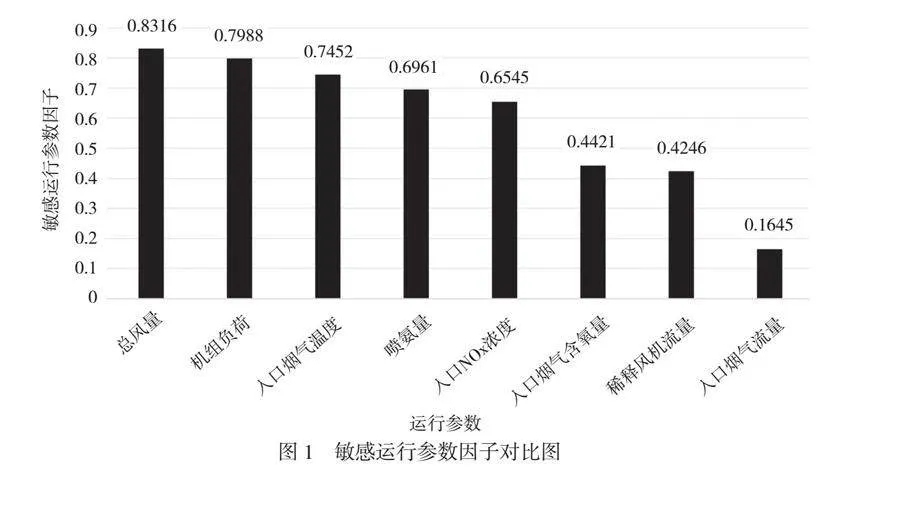
在燃煤機組的SCR系統中,運行參數數據量巨大,涵蓋了進料氨水流量、煙氣溫度、催化劑層厚度等多個方面。由于參數眾多,如果不加篩選地全部納入模型,不僅會導致模型復雜化,還會大幅提升計算成本以及操作難度。因此,本文采用敏感變量優選法,旨在篩選與SCR系統出口NOx濃度關聯性最強的關鍵影響參數。在篩選過程中,研究人員利用Spearman相關系數來量化每個運行參數與出口NOx濃度的相關性。Spearman相關系數的優勢在于,它不依賴變量的線性關系,能夠更好地捕捉變量間的非線性關系,這對SCR系統這類復雜系統的參數分析尤為重要。通過計算各運行參數的Spearman相關系數,研究人員得出了每個參數與出口NOx濃度的敏感運行參數因子[1]。通過這種敏感運行參數因子的對比分析,研究人員能夠更精確地識別對NOx濃度影響最顯著的參數,從而構建出一個更高效、簡潔的SCR系統預測模型(如圖1所示)。
2 基于堆疊自編碼器的出口NOx濃度預測建模
2.1 堆疊自編碼器介紹
自編碼器是一種神經網絡模型,將輸入數據壓縮到潛在空間(編碼),然后再重建原始輸入(解碼)來學習數據。其主要由2個部分組成。1)編碼器。將輸入數據映射到潛在空間中的表示。編碼器網絡層的輸出被稱為編碼(或隱藏)層。2)解碼器。將編碼后的表示映射回重建的輸入空間,盡可能還原原始輸入,自編碼器的訓練目標是最小化輸入與重建輸出之間的重建誤差。堆疊自編碼器通過堆疊多個自編碼器層來增加模型的深度。每個自編碼器層都被訓練,以學習數據的不同層次的表示,每一層的編碼器輸出成為下一層的輸入。本次研究中,研究人員為了預測出口NOx濃度,使用堆疊自編碼器。每一層都負責學習數據的不同抽象層次的特征表示,與編碼器對應的解碼器層,負責將編碼的數據逐層解碼還原為原始輸入,如公式(1)所示。
=fNN(g2(g1(x;θ1);θ2)) (1)
式中:為預測的出口NOx濃度;x為輸入的運行參數向量,包括上述8種用于預測的特征;g1(;θ1)為第一層堆疊自編碼器的編碼器部分,用于將輸入向量x映射到第一層特征空間;g2(;θ2)為第二層堆疊自編碼器的編碼器部分,接收第一層特征空間的輸出作為輸入,并將其映射到第二層特征空間;fNN(?)為神經網絡模型,用于預測最終編碼后的特征[2]。
具體實踐中,工作人員輸入x的具體參數,此時第一層自編碼器開始運行,將x映射到第一層的特征空間。第二層自編碼器接收第一層的編碼特征作為輸入,將其進一步映射到第二層的特征空間,通過這種方式獲得最終編碼特征(見表1)。
2.2 基于SAE的出口NOx濃度預測模型建立
當研究人員建立基于SAE的出口NOx濃度預測模型時,全面考慮每個步驟的細節,以確保最終模型的準確性與可靠性。研究人員嘗試構建一個能夠精確預測火電機組出口NOx濃度的模型。此模型旨在通過應用先進算法,為燃煤火電機組的環保與高效運行提供有力支持。研究人員從多個運行中的火電機組中收集了足夠的數據,確保模型能夠廣泛適用于不同條件下的燃煤火電機組。數據包括800組實際運行數據,涵蓋了各種運行參數以及環境條件,主要的輸入變量包括總風量、機組負荷、入口煙氣溫度、噴氨量、入口NOx濃度。當構建SAE模型時,研究人員設計一整套完整的網絡結構,包括輸入層、多個隱層以及輸出層的層次結構[3]。每個自編碼器層都經過精心設計,以最大化模型對數據復雜關系的捕捉能力。
本文中,為了評估SAE模型的預測能力,研究人員引入了2個主要的評估指標,即均方根誤差(RMSE)以及確定系數R2。基于這2項指標幫助研究人員量化模型預測值與實際觀測值之間的差異,并評估模型的擬合程度以及泛化能力(見表2)。
3 基于在線學習的模型參數自更新
具體實踐中,SCR系統的運行條件容易在外部環境的影響下發生改變,影響其工作狀態。針對這一問題,研究人員嘗試搭建基于在線學習模型的參數自適應更新框架,通過分析歷史數據與實時反饋數據,使模型能夠持續改進優化,從而更好地應對復雜的數據環境。研究人員先進行離線訓練,從數據庫、數據倉庫或實時數據流等多個來源收集數據,并對數據進行清洗、歸一化處理,以確保數據質量。根據任務需求,選擇合適的模型架構與算法。在離線訓練的初始階段,模型參數通常會使用初始值進行初始化。在此基礎上,通過優化損失函數,模型調整其參數,以最大程度地擬合歷史數據集,利用反向傳播算法等優化技術來更新模型的權重與偏差,過程如公式(2)所示。
(2)
式中:θ為模型參數集合;α為學習率;J(θ)為損失函數,用于衡量模型預測值與真實值之間的差異;L(y,hθ(x))為單個樣本的損失函數;m為訓練樣本的數量;δ(i)為第i個樣本的誤差項;z(i) 為第i個樣本的線性組合;x(i) 為第i個樣本的特征向量;y(i) 為第i個樣本的真實標簽;hθ(x)為模型的預測函數。
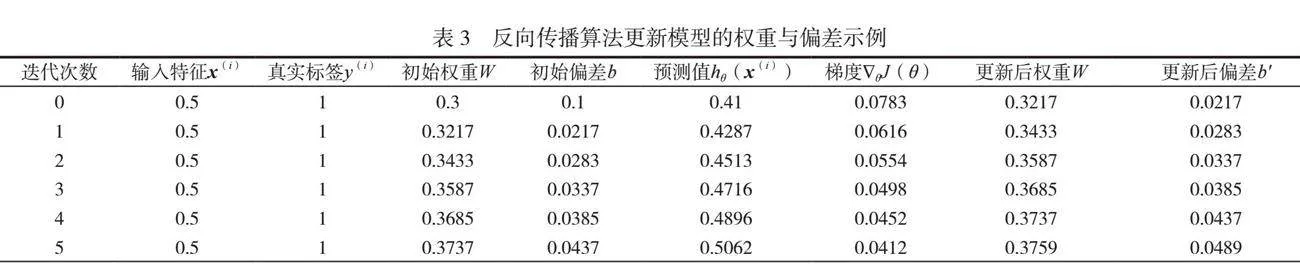
在訓練開始之前,需要初始化模型參數θ,包括權重W與偏差b,在前向傳播階段,輸入數據通過神經網絡各層進行計算,得到輸出預測值。針對每個訓練樣本i,計算線性組合z(i)=θTx(i)+b ,應用激活函數hθ(x(i))得到預測值。在此基礎上,利用反向傳播算法計算損失函數關于模型參數的梯度(見表3)。
4 模型自適應更新效果分析
本次研究中,為了驗證自適應更新策略對模型性能的改善程度,確保模型能夠持續適應新的數據特征以及環境變化,提高預測的準確性與魯棒性。研究人員進行模型自適應更新效果分析。研究人員采用了2種不同的預測模型。第一種是傳統的基于棧式自編碼器的出口NOx預測模型,該模型依賴固定的網絡結構與參數。第二種是采用自適應更新策略的SAE模型,該模型能夠在運行過程中動態調整網絡結構與參數,以適應數據變化。在訓練階段,為了保證對比的公平性,自適應更新SAE模型的離線版本在訓練集大小、數據分布以及網絡超參數等方面與原始SAE模型保持一致[4]。通過這種方式確保2種模型在相同條件下進行訓練,從而更準確地評估自適應更新策略的效果。實際測試后,研究人員采用了1組未參與訓練的數據集對2種模型進行效果評估。通過比較預測結果與實際測量值,分析2種模型的優缺點,見表4。
分析表4可以發現,原始SAE模型預測值與實際值之間的平均誤差為0.0678,而自適應更新SAE模型的RMSE為0.0455,這說明自適應更新后的模型預測值與實際值之間的平均誤差縮小了。通過比較2個RMSE值可以發現,自適應更新SAE模型的RMSE比原始SAE模型降低了約33.1%((0.0678-0.0455)/0.0678≈0.331),即自適應更新策略顯著降低了預測誤差。
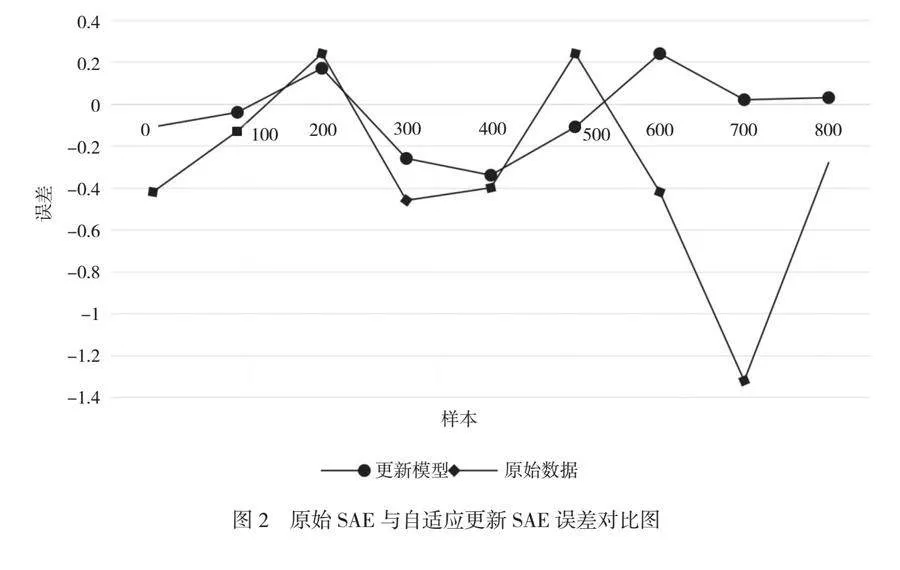
在預測精度分析方面,原始SAE模型的R2值為0.8672,說明模型能夠解釋大約86.72%的變量間相關性。自適應更新SAE模型的R2值為0.9403,即自適應更新后的模型能夠解釋大約94.03%的變量間相關性。通過比較2個R2值可以得出,自適應更新SAE模型的R2值比原始SAE模型提高了約7.81%((0.9403-0.8672)/0.8672≈0.081),說明自適應更新策略提高了模型在解釋變量間相關性方面的表現,從而提升了預測精度。因此,研究人員得出結論,自適應更新策略在降低預測誤差方面具有顯著優勢,因為自適應更新SAE模型的RMSE值比原始SAE模型小。而R2值的提高說明自適應更新模型在解釋變量間的相關性方面表現更優,預測精度得到了提升[5]。自適應更新策略有效地改善了模型的預測性能。此外,研究人員還對測試集上的原始SAE與自適應更新SAE之間的誤差進行對比,如圖2所示。
分析圖2可以發現,自適應更新能夠根據模型的實際表現動態調整更新頻率與更新量。當應用于自編碼器模型時,這種策略能夠使AE模型的誤差曲線具有更平穩的特性,同時波動幅度也相應減小。這種變化說明了預測誤差得到了有效控制,模型的預測效果因此變得更穩定。具體來說,自適應更新通過實時監測模型的預測性能,只在必要時進行更新,從而減少了不必要的模型調整,使模型能夠在較長時間內保持良好的預測性能,不易受到隨機噪聲的影響。
5 結語
本文成功地構建并優化了預測模型,驗證了其在實際應用中的有效性與可行性。通過深入探討關鍵影響參數篩選、模型建立及自適應更新策略,不僅為出口NOx濃度預測提供了新的技術方法,也為環境保護以及工業生產優化提供了有力支持。通過本次研究,研究人員得出以下結論。1)堆疊自編碼器(SAE)作為一種深度學習模型,具有強大的特征提取能力。在本文中,SAE的應用為出口NOx濃度預測提供了新的技術途徑。此外,研究人員還構建了一個基于SAE的預測模型,該模型能夠有效地從輸入數據中學習復雜的特征,并用于預測出口NOx濃度。2)為了適應不斷變化的數據環境,研究人員采用了在線學習策略對模型參數進行自更新。這種策略使模型能夠實時調整,以保持最佳的預測性能。3)通過試驗分析,研究人員發現自適應更新策略有效地改善了模型的預測性能,使其在出口NOx濃度預測方面具有更高的可靠性。
參考文獻
[1]李影,卓建坤,吳逸凡,等.可解釋的變負荷下燃煤機組SCR反應器入口NOx質量濃度預測模型[J].熱力發電,2024,53(7):119-128.
[2]張瑞方,張揚,張海.氨燃料在燃燒設備中的應用及展望[J].潔凈煤技術,2024,30(5):46-55.
[3]金秀章,暢晗,趙大勇,等.基于蜣螂優化-集成加權融合的NO_x濃度動態預測[J].計量學報,2024,45(4):600-608.
[4]何德峰,劉明裕,孫芷菲,等.基于LSTM-SAFCN模型的生物質鍋爐NOx排放濃度預測[J].高技術通訊,2024,34(1):92-100.
[5]劉樹成,張曉,劉加昂,等.重型柴油車NOx排放因子與其濃度相關性研究[J].環境科學研究,2024,37(3):545-553.
