基于生成對抗網(wǎng)絡(luò)的網(wǎng)絡(luò)異常檢測及應(yīng)用
2024-12-09 00:00:00張培宇
中國新技術(shù)新產(chǎn)品
2024年17期


摘 要:本文探討生成對抗網(wǎng)絡(luò)(GAN)在網(wǎng)絡(luò)異常檢測中的應(yīng)用,提出了一種基于GAN的檢測方法。利用對抗訓(xùn)練捕捉網(wǎng)絡(luò)流量特征分布,對異常行為進(jìn)行精確檢測。算法包括網(wǎng)絡(luò)流量數(shù)據(jù)預(yù)處理和異常檢測模塊,前者用于轉(zhuǎn)換數(shù)據(jù)格式,后者基于GAN架構(gòu)生成并檢測異常流量。試驗(yàn)結(jié)果顯示,該方法在準(zhǔn)確率、召回率和F1分?jǐn)?shù)方面顯著優(yōu)于傳統(tǒng)規(guī)則和簽名檢測方法,具備更高的靈活性和適應(yīng)性,提升了網(wǎng)絡(luò)系統(tǒng)的安全性和穩(wěn)定性。
關(guān)鍵詞:生成對抗網(wǎng)絡(luò)(GAN);網(wǎng)絡(luò)異常檢測;異常事件生成;對抗訓(xùn)練
中圖分類號:TN 915" " " 文獻(xiàn)標(biāo)志碼:A
網(wǎng)絡(luò)安全是現(xiàn)代互聯(lián)網(wǎng)面臨的重大挑戰(zhàn),網(wǎng)絡(luò)攻擊手段不斷增加使異常檢測成為保障系統(tǒng)安全的關(guān)鍵。采用手工特征提取的傳統(tǒng)方法難以應(yīng)對復(fù)雜網(wǎng)絡(luò)環(huán)境[1]。生成對抗網(wǎng)絡(luò)(GAN)通過對抗訓(xùn)練學(xué)習(xí)數(shù)據(jù)分布捕獲高級特征,可提升檢測準(zhǔn)確性和魯棒性。GAN的生成器和判別器通過對抗訓(xùn)練生成并增強(qiáng)網(wǎng)絡(luò)流量數(shù)據(jù),發(fā)現(xiàn)潛在異常模式,解決訓(xùn)練數(shù)據(jù)不足問題[2]。本文提出結(jié)合注意力機(jī)制的GAN網(wǎng)絡(luò)異常檢測算法,以提升檢測準(zhǔn)確性和效率,保障網(wǎng)絡(luò)安全與穩(wěn)定。
1 基于生成對抗網(wǎng)絡(luò)的網(wǎng)絡(luò)異常檢測算法
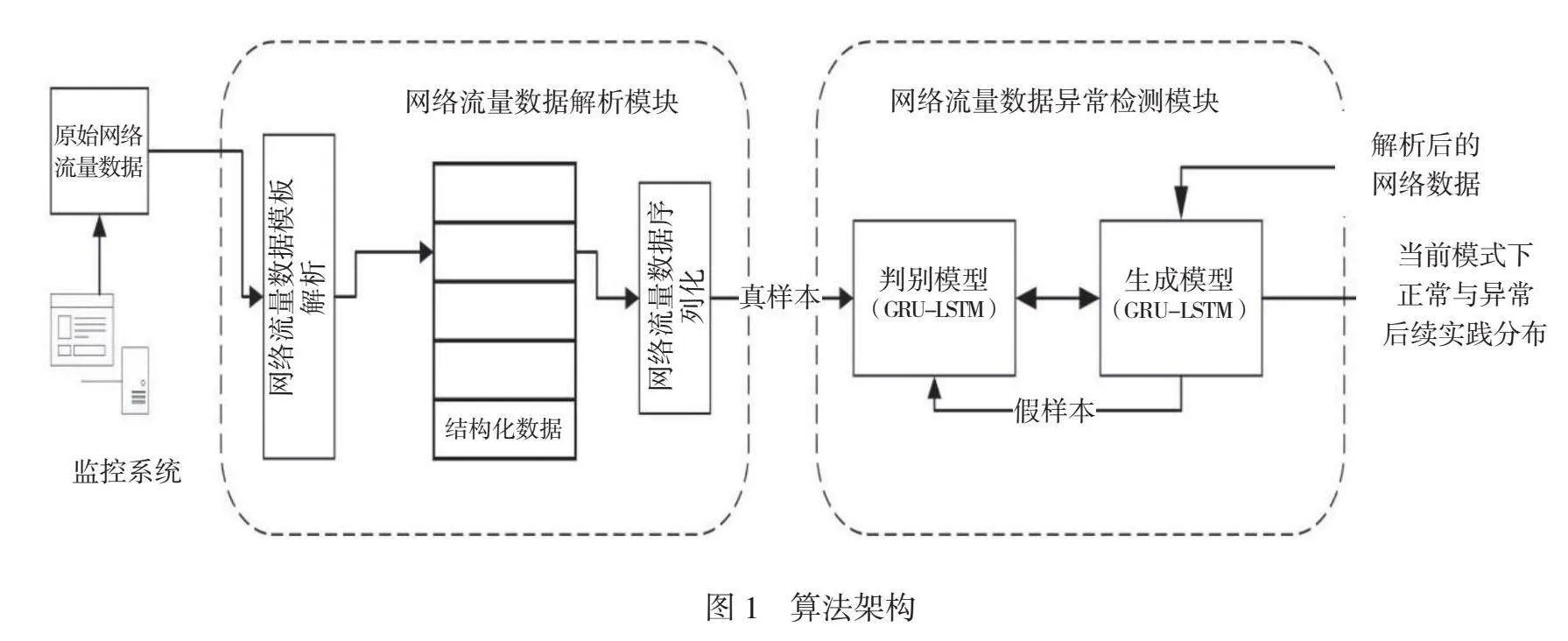
1.1 算法架構(gòu)
本文提出的基于生成對抗網(wǎng)絡(luò)的網(wǎng)絡(luò)異常檢測算法的整體框架如圖1所示。該算法主要包括網(wǎng)絡(luò)流量數(shù)據(jù)解析模塊、數(shù)據(jù)異常檢測模塊。在數(shù)據(jù)輸入階段,從監(jiān)控系統(tǒng)讀取原始網(wǎng)絡(luò)流量數(shù)據(jù),并將其傳遞到網(wǎng)絡(luò)流量數(shù)據(jù)預(yù)處理模塊中。……
登錄APP查看全文
