基于SVM的粉煤灰壓實特性指標預測
2024-12-05 00:00:00李陽陽趙鴻哲
科技風 2024年33期
摘要:粉煤灰既是一種固體廢棄物,也是一種優(yōu)良的巖土材料。作為巖土材料,最大干密度和比重是其最重要的兩個工程特性指標。本文利用支持向量機這一個軟計算技術(shù),建立了粉煤灰最大干密度和比重的預測模型。研究結(jié)果表明,支持向量機模型比現(xiàn)有的人工神經(jīng)網(wǎng)絡模型更為有效。
關(guān)鍵詞:粉煤灰;最大干密度;比重;預測模型;支持向量機
粉煤灰在建材、農(nóng)業(yè)、環(huán)保和精細化利用等方面均具有良好的應用前景[1]。如在建材工程方面,除可用于生產(chǎn)粉煤灰混凝土、粉煤灰水泥、粉煤灰磚、墻體材料等用途之外,由于粉煤灰有著干密度低、透氣性大、黏結(jié)性小、活性高、壓實最佳含水量高等特點,還可作為建筑、水利、市政、道路以及采空區(qū)等各類工程的優(yōu)質(zhì)回填料。將粉煤灰作為回填材料,其最大干密度(MDD)和比重(G)是最重要的兩個壓實特性指標。
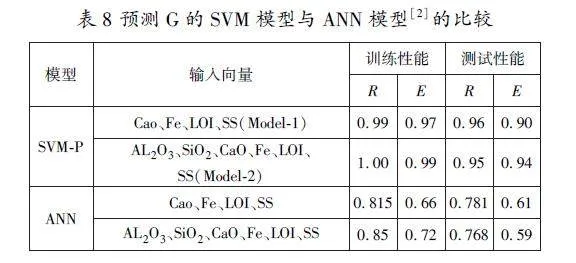
在機器學習中,支持向量機(SVM)是一種帶相關(guān)學習算法的監(jiān)督學習模型,可以分析數(shù)據(jù)和識別模式,用于分類和回歸分析。AsadKhan[2]建立了預測粉煤灰MDD和G的人工神經(jīng)網(wǎng)絡(ANN)模型。預測MDD的最佳模型為:(1)輸入向量分別為Fe2O3(Fe)、燒失量(LOI)和G;(2)輸入向量分別為Fe、LOI、G和最佳含水量(OMC)。對G的預測,最好的模型是:(1)輸入向量分別為CaO、Fe、LOI和比表面積(SS);(2)輸入向量分別為Al2O3、SiO2、CaO、Fe、LOI和SS。但采用支持向量機對粉煤灰的MDD和G進行預測,在現(xiàn)有文獻中鮮見報道。本研究旨在建立預測粉煤灰MDD和G的SVM模型,并與現(xiàn)有ANN模型的預測效果相比較。
1預測MDD的SVM模型的建立
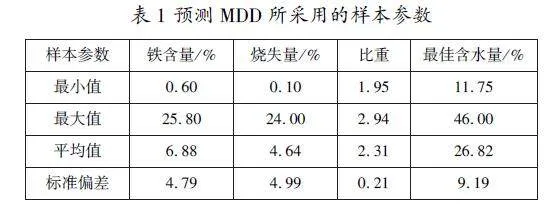
利用文獻[2]建立預測粉煤灰MDD的人工神經(jīng)網(wǎng)絡模型的數(shù)據(jù),所采用的樣本總數(shù)為40個,其中25個用作學習樣本,15個用作檢驗樣本,建立了支持向量機模型。表1給出了用于開發(fā)支持向量機模型的數(shù)據(jù)的最小值、最大值、平均值和標準偏差。
利用MATLAB軟件包建立支持向量機模型。采用徑向基函數(shù)核、多項式核和樣條核函數(shù)分別建立不同的支持向量機模型,所建立的SVM模型分別命名為SVMR、SVMP和SVMS。兩組模型的輸入向量分別包括:(1)Fe、LOI、和G;(2)Fe、LOI、G和OMC。這兩組模型分別被命名為模型1(Model1)和模型2(Model2)。
2預測G的SVM模型的建立
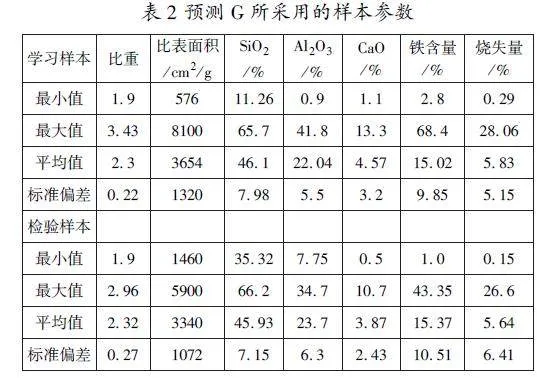
利用文獻[2]預測粉煤灰G的ANN數(shù)據(jù),建立了兩種G的支持向量機預測模型:模型1(Model1)的輸入向量為CaO、Fe、LOI和比表面積(SS);模型2(Model2)的輸入向量為Al2O3、SiO2、CaO、Fe、LOI和SS。表2給出了學習和檢驗所采用樣本值的最小值、最大值、平均值和標準偏差。樣本總數(shù)為113個,其中80個作為學習樣本,33個為檢驗樣本。
3預測結(jié)果的分析和討論
3.1粉煤灰MDD的預測
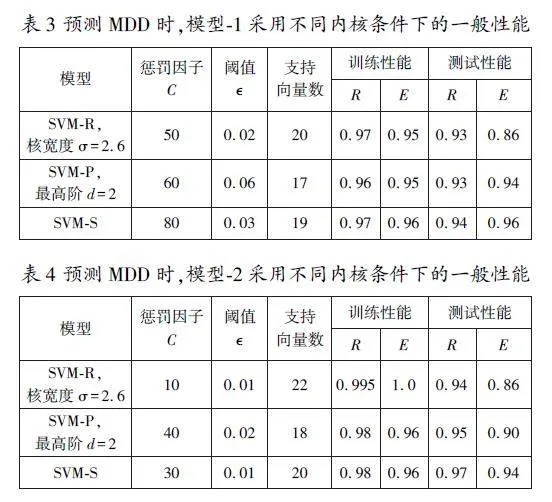
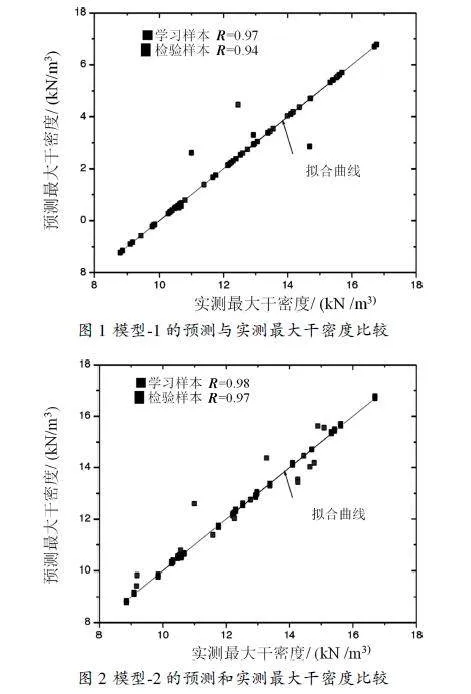
表3、表4分別給出了支持向量機模型1和模型2的預測結(jié)果。以相關(guān)系數(shù)(R)和效率系數(shù)(E)作為評判模型預測精度的指標可以看出,SVMS比SVMP、SVMR具有更高的效率。圖1和圖2分別給出了模型1和模型2的實測最大干密度值和預測最大干密度值之間的比較。結(jié)果表明,模型2比模型1需要更多的輸入向量,但是二者的統(tǒng)計性能是相當?shù)摹DP?由于采用了較少的輸入向量,因此,可以認為模型1比模型2更為有效。
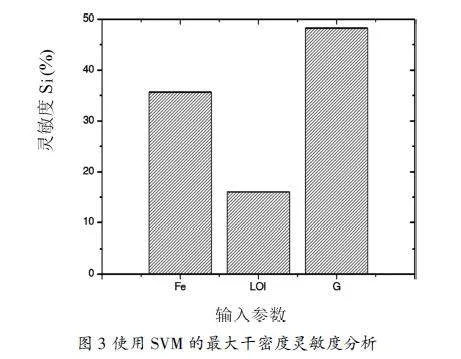
(1)靈敏度分析。采用文獻[3]的程序,對支持向量機模型(模型1)的輸入和輸出之間的因果關(guān)系進行了靈敏度分析。最大干密度的靈敏度分析如圖3所示,預測MDD最重要的輸入?yún)?shù)是G,其次是Fe和LOI。
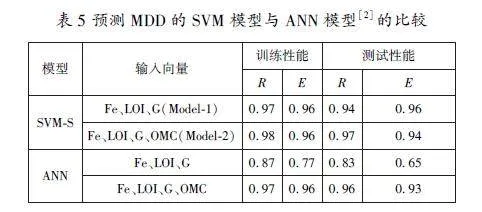
(2)預測MDD的SVM模型與ANN模型的比較。表5比較了基于不同輸入向量的SVMS支持向量機和人工神經(jīng)網(wǎng)絡ANN模型。從表5中可以看出,支持向量機是一個略好于人工神經(jīng)網(wǎng)絡模型的模型。
3.2粉煤灰G值的預測
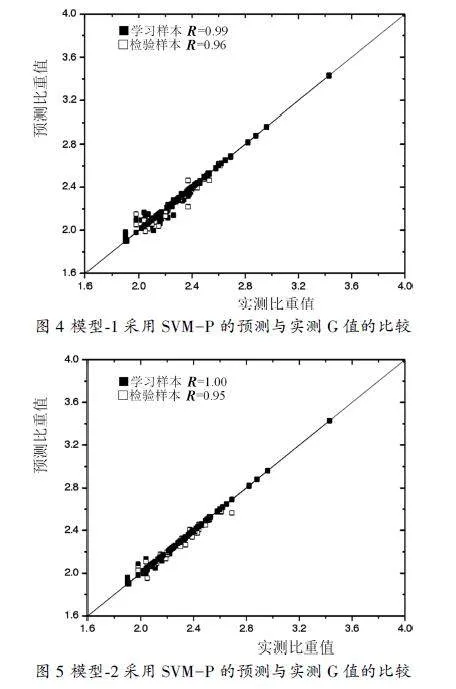
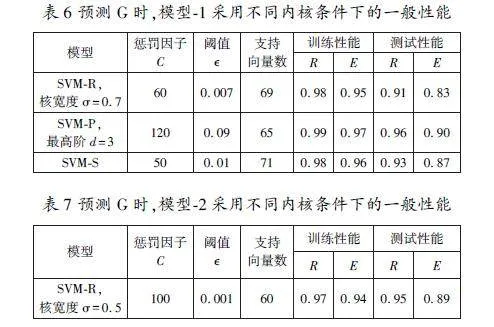
表6和表7分別給出了支持向量機模型1和模型2對G的預測結(jié)果。通過對模型1和模型2預測精度指標R和E值的比較可知,SVMP比SVMR和SVMS更有效。圖4、圖5分別給出了模型1和模型2的預測比重值與實測值的比較,可以看出,與模型1相比,采用模型2時散射較小。支持向量機模型具有很好的相關(guān)性,特別是對于模型1,它比模型2采用了較少的輸入向量,但是兩個模型的統(tǒng)計性能是相當?shù)模虼四P?具有較好的簡潔性。
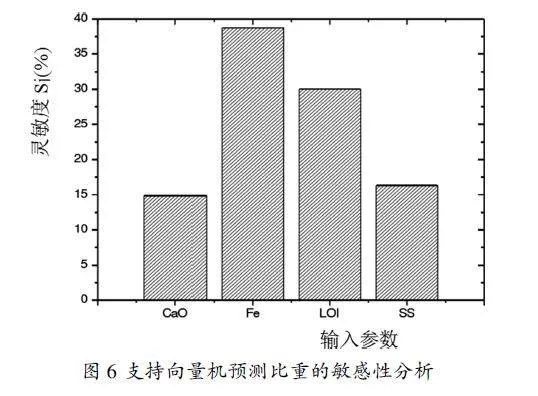
(1)靈敏度分析。采用文獻[3]的程序,對支持向量機模型(模型1)的輸入和輸出之間的因果關(guān)系進行了靈敏度分析,結(jié)果見圖6。從中可見,鐵含量是用于預測粉煤灰比重的最重要的參數(shù),其次是燒失量、比表面積和氧化鈣。
(2)預測G的SVM模型與ANN模型的比較。表8給出了支持向量機的最佳模型SVMP與早期ANN模型的比較結(jié)果。從表8中可以看出,SVM模型略優(yōu)于之前的最佳ANN模型。
結(jié)語
本文建立了預測粉煤灰最大干密度和比重的SVM模型,并與現(xiàn)有ANN模型的預測效果進行了比較,所得主要結(jié)論如下:
(1)當預測粉煤灰的最大干密度時,SVMS比SVMP和SVMR更有效;
(2)當預測粉煤灰的比重時,SVMP比SVMR和SVMS更有效;
(3)根據(jù)支持向量機模型的靈敏度分析,預測最大干密度的最重要參數(shù)是比重,其次是鐵含量和燒失量,預測比重的最重要參數(shù)是鐵含量,最后是燒失量、比表面積和氧化鈣;
(4)通過對SVM模型與已有ANN模型的有效性比較,發(fā)現(xiàn)SVM模型優(yōu)于ANN模型。
參考文獻:
[1]楊星,呼文奎,賈飛云,等.粉煤灰的綜合利用技術(shù)研究進展[J].能源與環(huán)境,2018(04):5557.
[2]AsadKhan.PredictionofmaximumdrydensityandspecificgravityofFlyAshbyNeuralNetworks[J].Boletíntécnico,2017,55(6):4248.
[3]MuhammadKamran.RiverstageforecastinginPakistan:neuralnetworkapproach[J].Complexity,2004,14(1):1118.
作者簡介:李陽陽(1991—),男,漢族,河北邯鄲人,碩士研究生,工程師,主要從事水利水電工程施工。
