高職院校Hive 數據倉庫技術課程教學案例分析
2024-12-01 00:00:00宋志偉劉天宇
電腦知識與技術 2024年32期





摘要:Hive數據倉庫技術是高職院校中大數據技術相關專業的核心課程之一。為了更好地幫助學生學習、理解課程內容,在教學實踐過程中匯總積累了學生在各個階段的實操過程中存在的典型問題案例,從學生角度出發,追溯問題案例根源,為課程設計的更新優化提供參考。
關鍵詞:Hive;數據倉庫技術;高職學生;案例分析;大數據技術
中圖分類號:G642 文獻標識碼:A
文章編號:1009-3044(2024)32-0156-03 開放科學(資源服務)標識碼(OSID) :
0 引言
隨著大數據時代的到來,數據倉庫技術已成為企業數據存儲、分析、預測的重要工具之一[1]。Hive作為一種基于Hadoop分布式系統的數據倉庫工具,因其強大的海量數據處理和數據分析能力,在大數據分析領域中的熱度一直居高不下,也備受企業青睞[2]。為了適應大數據技術的發展趨勢,高職院校紛紛開設Hive數據倉庫技術這門課程,旨在讓學生理解并掌握Hive的基本原理、核心操作及其應用方法,為學生未來從事大數據相關工作打下堅實基礎。相比于MySQL、SQL Server等常用數據庫工具在高職院校中多年的使用基礎,Hive在高職院校的引入和教學面臨一些特殊的挑戰和差異,尤其是Hive的教學需要包含Hadoop分布式生態的基礎原理、Hive的架構、海量數據清洗、數據分析等多個方面的內容,相對于傳統關系型數據庫更加復雜和深入。本文基于高職學生的學習特點,針對Hive數據倉庫技術在實際教學實踐過程中出現的典型問題案例,進行分析討論,幫助學生更好地理解和掌握Hive 數據倉庫技術,提升專業水平。
1 問題案例分析
在高等職業教育中,Hive數據倉庫技術課程應基于高職學生的實際需求、未來職業發展的導向以及教學過程中的有效性。在教學過程中,需緊密貼合實際應用,強調Hive在實際項目開發中的應用和操作[3],避免過于理論化或脫離實際的教學內容,確保學生能夠學以致用。以下分別從Hive的環境配置、Hive的部署、數據庫與數據表的定義、查詢、自定義函數、優化等6個教學內容進行典型問題案例展示,通過分析學生在實踐中所出現的共性問題,動態優化課程設計、更新教學方法。
1.1 Hive 環境配置問題案例
Hive是建立在Hadoop之上的數據倉庫工具,利用Hadoop 的分布式存儲和計算能力來處理海量數據。因此,Hive的環境配置需要嚴格遵守Hadoop生態模型[4]。對于初學者來說,Hadoop的安裝和配置具有一定挑戰性,需要提前學習實踐,夯實基礎。下面列舉Hive在安裝配置中的常見問題。
(1) 虛擬機的網絡配置。Hadoop 的部署需要在Linux系統運行,因此需要提前準備虛擬機,課程中采用VMware軟件作為虛擬機的載體。部分學生在配置虛擬機的過程中,無法在虛擬機中聯網,這是虛擬機的網絡配置錯誤導致。正確的做法應該是網絡適配器設置中選擇NAT模式,依次填寫子網IP、子網掩碼和網關IP,保存設置后即可聯網,在虛擬機中輸入“ping www.baidu.com”,若顯示如圖1中的結果,則表示聯網成功。
(2) 虛擬機的克隆與時間同步。Hadoop完全分布式集群至少需要三臺虛擬機,因此,需要對虛擬機進行底層克隆操作,構建三臺虛擬機。很多學生在克隆虛擬機的過程中,沒有同步時間,導致集群存在數據不一致、任務調度等問題。可分別在三臺虛擬機中執行“ntpdate ntp4.aliyun.com”命令,同步集群時間,保持集群中節點的一致性。
(3) JDK的安裝。Hadoop集群需要Java環境來運行,若沒有在Liunx中安裝Java環境,則無法部署Ha?doop集群。少部分學生因忘記安裝JDK,導致Hadoop 集群啟動失敗。正確做法是從Java官網中下載JDK 安裝包,在Linux環境中完成安裝,并配置環境變量。
在三臺虛擬機中輸入代碼“java -version”,若出現如圖2中的Java版本,則JDK配置成功。
(4) HDFS的初始化。在第一次使用Hadoop集群之前,需要對Hadoop中的HDFS組件進行初始化,以創建Hadoop集群中必要的目錄結構和配置信息。有學生沒有進行初始化就開啟Hadoop,終端中提示系統錯誤,無法開啟集群。還有學生在HDFS集群開啟的情況下進行初始化操作,導致數據丟失或損壞。正確做法應該如下所示:
① 找到Hadoop 安裝路徑中的bin 目錄,并進行定位。
② 確保當前Hadoop集群處于關閉的基礎上,在bin目錄下,執行命令“HDFS namenode -format”,此命令會格式化HDFS的名稱節點(NameNode) ,清空已存在的HDFS數據。
③ 在HDFS 名稱節點格式化完成后,執行命令“start-all.sh”,啟動Hadoop進程。
需要注意的是,少部分學生對Hadoop分布式技術使用不熟練,導致Hive環境配置任務進程緩慢,對于此類學生,需要積極關注,引導其“笨鳥先飛”,打好良好的學習基礎。Hive的執行過程需要在Hadoop生態的基礎上進行,若學生沒有吃透Hadoop的基本原理,后續的實踐學習將舉步維艱。
1.2 Hive 部署問題案例
(1) Hive啟動失敗。有許多學生在嚴格執行Hive 環境配置流程后仍無法啟動Hive,檢查其虛擬機后,發現Hadoop集群尚未啟動。因Hive的運行必須基于Hadoop生態,因此需要在執行Hive之前部署Hadoop 集群。在虛擬機中輸入“start-all.sh”命令開啟Hadoop 集群中的HDFS組件與yarn組件。以主節點為例,若出現如圖3中的組件信息,則此時可順利啟動Hive。
(2) 防火墻影響Hive正常啟動。少數學生在啟動Hive時,明明之前能夠成功使用,突然啟動失敗。究其原因,發現是虛擬機防火墻的攔截所致。在啟動Hive之前,要確保Hive所在的服務器或Hadoop集群的防火墻允許設置Hive運行所需通信,可以通過打開特定的端口(如HiveServer2的端口)以允許遠程連接。同時,也需要保證Hive能夠與其他系統進行通信,如Hadoop集群、MySQL數據庫等,防止因連接受阻導致Hive無法正常啟動。
(3) 元數據問題。Hive使用元數據服務(metastore) 來存儲數據庫、數據表等元數據信息。若metastore服務未正確配置或啟動,可能導致Hive無法正常工作。目前hive中自帶的metastore為derby,但derby并不穩定,因此許多學生在使用過程中,常常出現hive崩潰的情況。通常的解決方法是,將Hive自帶的derby數據庫,更換為更加穩定的MySQL,利用MySQL的高可用性與高拓展性,可以確保數據的完整性和一致性。
1.3 Hive 數據庫與數據表的定義問題案例
Hive 中定義了簡單的類SQL 查詢語言,稱為HQL,它允許熟悉SQL的用戶查詢Hive中的數據。因HQL語句與SQL語句在語法上較為類似,因此學生在MySQL的學習基礎上,能夠較快上手。但Hive的執行需要在Hadoop集群上將任務轉化為mapreduce作業,和傳統關系型數據庫存在較大差異,因此在Hive中構建數據庫、數據表也存在著一些新的問題,下面進行列舉。
(1) 語法差異問題。HQL和SQL在語法上存在一些區別,許多學生習慣使用SQL語句查詢數據庫,將其硬套入HQL中,運行代碼提示報錯。在課程實踐過程中,整理學生所出現的此類問題,主要有以下幾個方面:
① 查詢對象不同。在SQL語句中,查詢的是數據庫中的表和表中的列;而在HQL語句中,所查詢的是對象與對象中的屬性。
② 關鍵詞大小寫敏感性。SQL語句對大小寫不敏感,因此在書寫過程中表名、字段名、關鍵詞可以自由組合;而HQL語句雖然對關鍵詞不敏感,但類名、屬性名需要區分大小寫。
③ 語法結構差異。在SQL語句中,FROM后面跟著的是表名,WHERE后面接的是表中的條件查詢;而在HQL語句中,FROM 后跟的是類名+類的對象,而WHERE后面用對象的屬性作為條件。
根據上述典型問題,需要反復做針對性的實踐練習,讓學生在編碼中理解SQL和HQL的語法差異內容,減少類似錯誤的發生。
(2) 注釋亂碼問題。注釋屬于Hive元數據的一部分,存放在Hive的metastore庫(一般是MySQL) 中,如果metastore庫中的字符集不支持中文,就會導致Hive 的中文顯示亂碼。解決此問題,需要確保修改metas?tore庫的字符集為UTF-8,同時確保URL所連接的編碼也指定為UTF-8。
1.4 Hive 查詢操作問題案例
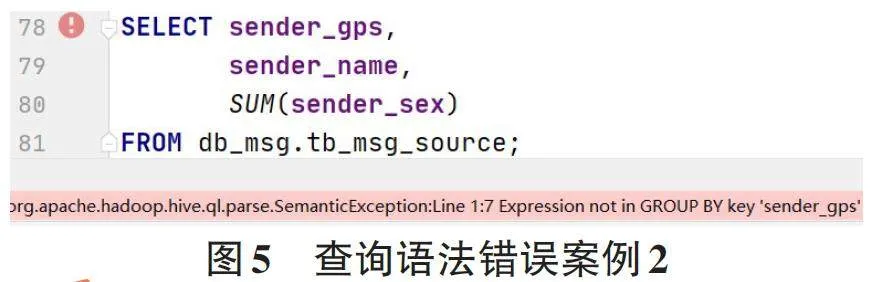
(1) 查詢語法錯誤。語法錯誤是學生在Hive學習過程中最常見的問題。如圖4所示,一位學生在使用select語句查詢多個字段時,在最后一個字段后多寫了一個逗號,造成代碼運行提示報錯。如圖5所示,一位學生在使用SUM()聚合函數時,沒有在GROUP BY 子句中指定此列,造成代碼運行提示報錯,正確做法是在字段后加上GROUP BY字句,并選擇需要聚合指定的列。
(2) 查詢速度緩慢。有多位學生在查詢過程中產生疑問,Hive作為海量數據的處理分析工具,其查詢速度并不快,甚至部分語句查詢效率低于MySQL。要搞清楚這個問題的解決方案,首先需要熟悉Hive查詢的基本原理。Hive查詢的基本原理是將HQL查詢轉換為mapreduce任務,并在Hadoop集群上并行執行。mapreduce在執行過程中存在map切片和reduce合并兩個階段,需要花費一定時間,因此Hive主要用于海量數據的離線分析,在線查詢分析速度偏慢。如果要改善Hive查詢的速度,可以采用DISTRIBUTE BY和CLUSTER BY分組查詢語句,通過將數據均勻分布到不同的Reducer中,以減少因數據傾斜帶來的影響。
1.5 Hive 自定義函數問題案例
Hive 自定義函數(UDF, User-Defined Functions) 允許用戶獨立擴展 Hive 的 SQL 功能,通過編寫具有指向性作用的函數來處理數據。UDF 可以用于數據格式轉換、字符串操作、數理計算等場景。由于MySQL中并沒有直接內置UDF的概念,對于學生來說UDF是一個全新的知識點,因此許多學生在UDF的實際操作過程中出現較多問題,下面進行典型問題案例的分析:
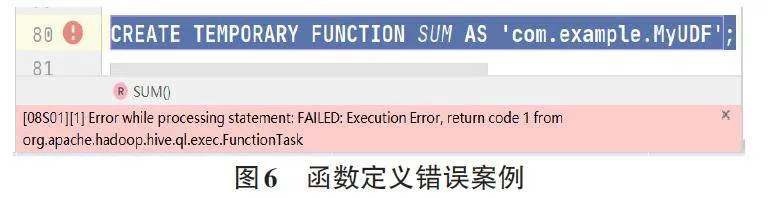
(1) 函數定義錯誤。許多學生在進行UDF的定義時,所起函數名稱與已有的函數沖突,或者函數參數的類型定義發生錯誤,如有學生定義一個具有計算功能的UDF,起名為SUM(),因SUM()函數已經是Hive當中的內置函數,因此在定義時發生錯誤,如圖6所示。正確做法是在定義UDF時,選擇一個與已有函數不沖突的名稱。需要注意的是,在Hive中,函數的名稱是不區分大小寫的,所以禁止通過更改大小寫的方式規避已有的內置函數名。
(2) JAR包管理問題。UDF的定義在Java中進行,完成定義后,需要將 Java 代碼編譯成一個 JAR 文件,可以通過使用Maven、Gradle 等其他構建工具來完成打包任務,以確保 在JAR 文件中包含必要的依賴項。許多學生在操作過程中省略了此步驟,導致函數無法被定義及調用。因此,在Hive中使用UDF之前,必須確保所有依賴的庫或JAR包都已成功添加至Hive的類路徑中。
(3) 版本兼容性問題。如果UDF與當前Hive版本的API或行為不兼容,也無法使用UDF。如果是UDF 依賴的庫版本與當前系統安裝的庫版本發生沖突,導致UDF無法正常運行,解決方法是使用pip、conda或相應的包管理工具更新或降級依賴庫到與UDF所兼容的版本,或在UDF的代碼中去指定一個依賴庫的版本,確保在不同環境中都能使用正確版本的庫。如果是Hive 運行環境不兼容,特別是在定義UDF時指定了某一個Hive的版本,需要升級或降級運行環境到與UDF兼容的版本。若無法更改當前的運行環境版本,則嘗試修改UDF代碼以適應當前Hive版本的運行環境。
1.6 Hive 優化問題案例
相比于傳統MySQL對于CPU、內存和磁盤I/O的利用特點的優化,Hive的優化既包含Hive在建表的設計過程,對HQL語句自身的優化,同時也包含Hive的配置參數和Hadoop生態中底層引擎mapReduce方面的調整[5]。這通常涉及mapReduce作業的初始化、數據傾斜問題的解決以及合理的分區與分桶策略等。這一塊內容是Hive學習的難點,也是大部分學生在學習過程中的共性問題,下面對學生在實操過程中的普遍問題進行講解。
(1) 數據傾斜問題。數據傾斜是Hive執行中最常見的性能問題,它指的是某個Reduce任務處理的數據量遠遠超過其他任務,導致在作業執行過程中其他任務必須等待最大數據量任務結束后,才能順利完成作業。學生在執行真實項目時,因數據樣本過多,加上對數據內容不敏感,常常會導致數據傾斜問題,浪費大量運行時間。數據傾斜可能由key分布不均勻、null 值過多等原因導致。針對Hive中產生的數據傾斜問題,可以采取如下優化策略:
① 數據預分區。根據key的分布情況對整個數據進行預分區,使得相同key的數據盡可能分布在同一節點上,從而減少跨節點數據的開銷。
② 空值處理。對于null值過多引起的數據傾斜問題,可以通過在查詢數據之前,對數據進行預處理工作。通過將null值替換為某個特定值(如統一定義一個不存在的值),或者在查詢過程中就將包含空值的記錄過濾掉。
③ Salting技術。對于傾斜比較嚴重的key,可以在數據中添加上隨機數前綴(也稱為salting) ,讓原本傾斜的key分散到不同的reduce任務當中。在reduce 階段中再刪除這些隨機數前綴,保持各任務中數據的分散性。
(2) 處理小文件問題。Hive在處理大量小文件數據時,由于每個小文件都需要一個Map任務,因此會消耗大量mapreduce的資源。許多學生在操作過程中忽略了小文件數據,直接調用mapreduce任務,造成任務效率低下。此問題的優化策略是當目標數據寫入Hive 之前,通過Hadoop 集群中的CombineFileInput?Format或者Hive中的merge()函數將小文件合并成大文件。
(3) Map和Reduce的任務數量問題。因Hive的任務執行是依靠maprecude引擎,map和Reduce任務數的設置會直接影響Hive作業的執行效率。如果任務數設置不合理,會導致系統資源浪費或性能下降。大部分學生在運行任務時,忽略此問題,常常導致在Map階段花費大量的時間進行任務劃分,影響整體效率。正確的優化策略是根據待處理數據的量合理設定任務數,確保每個Map任務處理的數據量適中(每一個Map中的數據盡量不超過128M) 。
以上只是授課過程中常見的一些問題案例及其優化策略,實際上Hive的優化是一個復雜的過程,需要具體問題具體分析,根據具體的業務場景和目標數據的特點進行優化和調整。
2 結論
Hive數據倉庫技術是實踐性、創新性很強的一門課程,課程內容較為新穎,融合liunx系統、Hadoop集群等多門課程,需要教師合理地安排教學內容、聚焦重難知識點。高職學生的基礎較為薄弱,但學習熱情較高,能夠以飽滿的熱情投入項目的開發過程中。然而,一旦遇到如上述問題,部分學生會產生挫敗感,知難而退,降低學習的熱情。還有少部分學生會鉆牛角尖,卡在某一個子任務中停滯不前,效率低下。因此對于Hive數據倉庫技術的教學,需要及時跟進學生在實踐過程中出現的各類問題,及時分析總結學生的共性問題案例,優化課程設計與教學方法。本文分別從Hive的環境配置、Hive的部署、數據庫與數據表的定義、查詢、自定義函數、優化等6個教學部分中出現的典型問題進行了總結,為Hive數據倉庫技術這門課的教學內容、教學方法的有效改進提供思路。
參考文獻:
[1] 劉強. 試論數據倉庫與大數據融合[J]. 電腦知識與技術,2020,16(10):7-9.
[2] 王科《. 實戰HADOOP》課程教學改革與探索[J].電腦知識與技術,2020,16(16):147-148.
[3] 云桂桂,杜彬,劉淑梅.三全育人背景下師生數據倉庫建設研究與實踐[J].中國管理信息化,2023,26(1):180-184.
[4] 張黎平,段淑萍,俞占倉.基于Hadoop的大數據處理平臺設計與實現[J].電子測試,2022(20):74-75,83.
[5] 荊忠航,張偉,王佳慧,等.面向Hive查詢的存儲優化技術[J]. 北京信息科技大學學報(自然科學版),2021,36(6):93-100.
【通聯編輯:王力】
基金項目:2023 年度江蘇省教育科學規劃課題(重點課題)“高職院校SPOC 教學評價體系構建研究”(課題編號:B/2023/02/114)
