基于Transformer 的煤礦爆破塊度分析
2024-11-29 00:00:00鹿丙振安文勇吳長偉
電腦知識與技術 2024年27期




摘要:準確量化爆破后巖石的破碎程度對于優化爆破設計和提高采礦作業的生產效率至關重要。傳統的圖像分析方法通常耗時耗力,且準確性較低。文章提出了一種名為BBDFiT的框架,能夠自動分析爆破后圖像中的巖石破碎分布。BBDFiT可以高效提取巖石塊度分布和內部裂隙結構,為優化爆破設計和質量控制提供數據驅動的見解。在專用的煤礦爆破塊度數據集上,BBDFiT實現了81.5%的top-1準確率,比當前最先進的視覺轉換器模型高出約1.8%,而推理速度相當。這種人工智能驅動的方法為采礦企業提供了一種新的數字化工具,有望提高生產效率和經濟效益,在礦山工程圖像分析領域具有廣闊的應用前景。
關鍵詞:Transformer;爆破設計;圖像分析;煤礦爆破塊度;礦山工程
中圖分類號:TP18 文獻標識碼:A
文章編號:1009-3044(2024)27-0023-04
1 背景
近年來,采礦業與多學科技術融合,推動了礦山智能化建設。實現對露天礦爆破效果的實時智能評價需要自動、快速且準確地統計爆破后大塊率[1-3]。由于傳統人工目視統計大塊率效率和精度較低,研究人員提出了利用圖像分割算法自動統計爆破后大塊率的新方法[4],該方法已在多個礦山現場得到廣泛應用。
在過去十年中,計算機視覺領域主要采用了基于卷積神經網絡的深度神經架構[5-6]。不同于此,Transformer 是一種主要基于自注意力機制的神經網絡,可處理特征之間的關系。Transformer被廣泛應用于自然語言處理(NLP) 領域,如著名的GPT-3模型[7]L2OP1gt7zIjTer0TqlLEI13BI4jYKsdNgn5+3PLN2wQ=。為將Transformer 結構用于視覺任務,研究人員探索了如何表示來自圖像和視頻數據的序列信息。Dosovitskiy 等人[8] 開發了Vision Transformer(ViT),通過將圖像分成局部patches作為視覺序列輸入,如今,Transformer已廣泛應用于圖像識別[9-10]、目標檢測[11]和圖像分割[12-13]等任務。
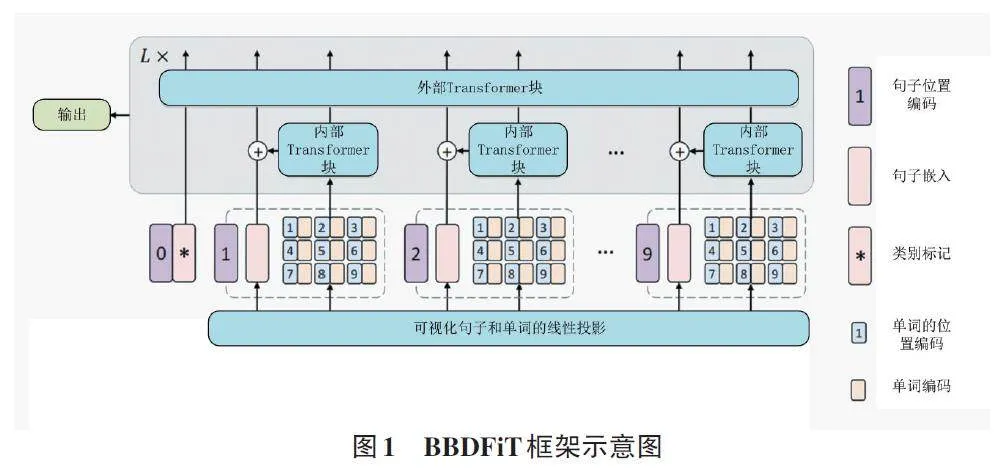
現有工作在處理復雜多樣的自然圖像時可能顯得過于簡單。因此,本文提出了一種新的Transformer架構——Blast Block Detection Frame?work in Transformer (BBDFiT),如圖1 所示。該方法首先將輸入圖像分割為較大的“視覺句子”,再將每個句子進一步分割為較小的“視覺詞”。除常規Transformer塊用于捕捉句子級特征外,本文還嵌入了子Transformer模塊,以細致挖掘視覺詞的細粒度特征。通過這種分層表示,BBDFiT能夠提取更加細致和豐富的視覺信息。
實驗結果顯示,與Transformer網絡相比,該模型在ImageNet 及下游任務上表現更優。本文提出的BBDFiT在精度和計算效率之間取得了更好的平衡。在采礦領域,BBDFiT架構為高效分析煤礦爆破殘渣圖像提供了新的可能。
2 方法
2.1 爆破塊度檢測架構
給定一張二維圖像,本文將其均勻分割為n 個patch ? = [ X1,X2,...,XN ]?Rn × p × p × 3,在ViT[8]模型中,這些圖像被劃分成多個patch,每個patch都具有固定的分辨率( p,p)。本文提出了Blast Blockiness DetectionFrame in Transformer(BBDFiT)架構,用于學習煤礦爆破塊度分析圖像中的全局塊度和局部塊度信息。在BBDFiT中,本文將一個patch定義為代表煤礦爆破塊度圖像的視覺句子。隨后,再將每個patch進一步分割為m 個子patch,即一個視覺句子Xi 由一系列視覺單詞(子patch) 組成:
Xi → [ xi,1,xi,2,...,xi,m ] (1)
式中:xi,j ?Rs × s × 3 為第i 個視覺句子的第j 個視覺單詞,(s,s) 為子patch的空間大小,j = 1,2,...,m。通過線性投影,本文將視覺詞Y i轉換為一系列詞嵌入:
Y i → [ yi,1,yi,2,...,yi,m ] (2)
yi,j = FC (Vec(xi,j )) (3)
公式(3) 中,yi,j ?Rc 為第j 次詞嵌入,c 為詞嵌入的維數,Vec(?)為向量化運算。
在BBDFiT中,本文設計了兩個數據流,其中一個流用于處理視覺句子,另一個流用于處理每個句子中的視覺單詞。對于詞嵌入,本文使用Transformer塊來探索視覺詞之間的關系:
Y il′ = Y il - 1 + MSA(LN (Y il - 1 )) (4)
Y il = Y il′ + MLP (LN ( Y il′ )) (5)
其中,l = 1,2,...,L 為第L 個塊的索引,L 為堆疊塊的總數。第一個區塊的輸入Y i0 即為公式(2)中的Y i。
變換后圖像中的所有詞嵌入γl = [Y 1 l ,Y 2 l ,...,Y nl ]可以看作是一個內部Transformer塊,表示為Tin。這個過程通過計算任意兩個視覺詞之間的相互作用來建立視覺詞之間的關系。
對于句子級,本文創建句子嵌入記憶?0 來存儲句子級表示序列:?0 = [ Zclass,Z10,Z20,...,Zn0 ]?R(n + 1) × d。其中,Zclass 為類令牌,與ViT[8]類似,均初始化為0。在每一層,通過線性投影將詞嵌入序列轉換到句子嵌入域,并加入句子嵌入中:
Zil - 1 = Zil - 1 + FC (Vec(Y il )) (6)
式中,Zil - 1?Rd 和全連通層FC用于使維度匹配加法。通過上述加法運算,句子嵌入?l 的表示得到了詞級特征的增強。本文使用標準的Transformer塊來轉換句子嵌入:
?′l = ?l - 1 + MSA(LN (?l - 1 )) (7)
?l = ?′l + MLP (LN ( ?′l )) (8)
綜上所述,BBDFiT塊的輸入和輸出包括如圖1所示的視覺詞嵌入和句子嵌入。因此,BBDFiT可以表示為:
γl,?l = BBDFiT (γl - 1,?l - 1 ) (9)
在本文的BBDFiT塊中,該模型采用了分層結構:內層Transformer塊用于挖掘patch內部的局部特征,而外層Transformer塊則聚焦于捕捉不同patch之間的全局關聯。通過L 次堆疊這種分層BBDFiT模塊,模型能夠高效地融合局部和全局視覺信息,從而構建一個Transformer-Transformer 網絡。最后,使用分類令牌作為圖像表示,并通過全連接層進行分類處理。本文為句子嵌入和詞嵌入添加了位置編碼,以保留空間信息。如圖1所示,使用了可學習的一維位置編碼。每個句子?0被分配了一個位置編碼:
?0 ← ?0 + Esentence (10)
其中,句子Esentence ?R(n + 1) × d 為句子被分配位置編碼,句子中的每個視覺詞也被分配位置編碼,在每個詞Y i0 嵌入中加入一個詞位置編碼,以確保模型能夠保留和利用空間信息。
Y i0 ← Y i0 + Eword,i = 1,2,…,n (11)
其中,單詞位置編碼Eword ?Rm × c 是跨句子共享的。這樣,句子位置編碼用于保持全局空間信息,而單詞位置編碼用于保持局部相對位置信息,兩者編碼相互補充。這種設計確保了模型在處理視覺信息時,既能捕捉到整體的空間布局,又能關注到局部的細節關系。
2.2 網絡體系結構
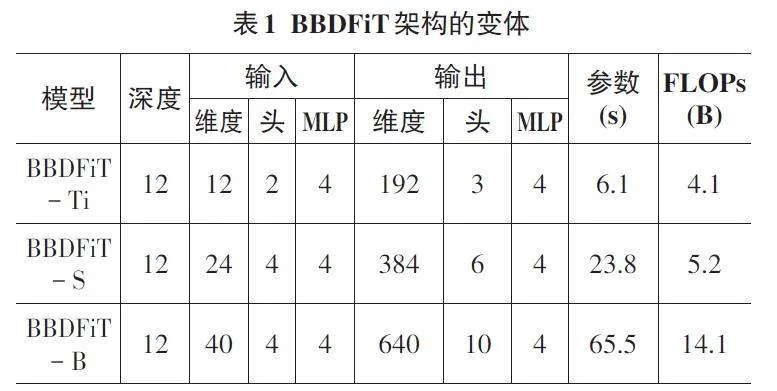
本文在ViT[8]的基本配置上構建了BBDFiT架構。圖像的patch 大小設為16 × 16,每個patch 被劃分為m = 4 × 4 = 16 個子patch。表1 列出了BBDFiT 的3 種不同模型尺寸變體,分別是BBDFiT-S、BBDFiT-B 和BBDFiT-L。這3種模型規模不同,參數量分別為6.1 M、23.8 M和65.6 M。在處理224×224分辨率圖像時,對應的計算量(FLOPs) 分別為1.4 B、5.2 B 和14.1 B。
在模型名稱中,Ti表示Tiny(很小),S表示Small (小),B表示Base(基礎)。FLOPs的計算是基于輸入圖像分辨率為224 × 224。
3 實驗與分析
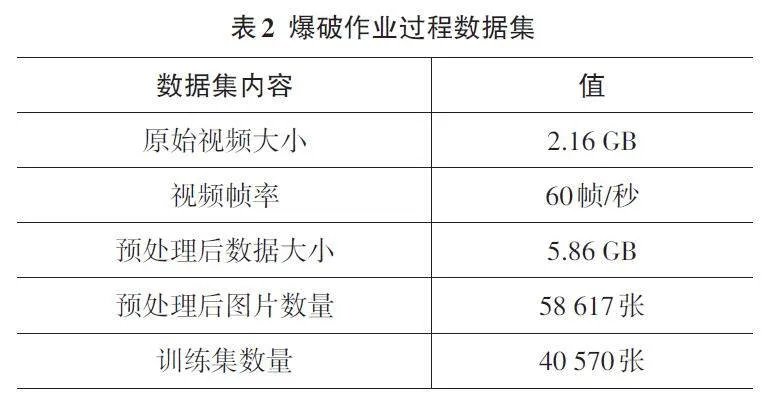
本文的實驗基于采集到的爆破作業過程視頻數據集。數據集包含37個時長為一分鐘的爆破作業視頻,整體大小為2.16 GB,涵蓋多個拍攝角度,包括爆破現場后現場石塊的左側、右側、正前方以及左下方、右下方等。經過抽幀、打標簽等預處理后,共獲得大小為5.86 GB的58 617張圖片數據的數據集。
根據表2可知,訓練集包含40 570張爆破現場石塊圖片,涵蓋多個拍攝角度;測試集則包含12 047張爆破現場石塊圖片,也覆蓋了這些拍攝角度。
3.1 參數設置
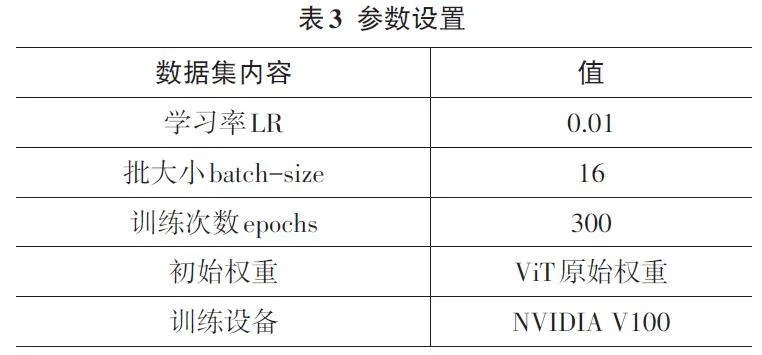
訓練參數的設置如表3 所示:學習率(LR) 設為0.01,批大小(batch size) 為16,訓練次數(epochs) 為300,初始權重使用ViT 的原始權重,訓練設備為GPU。
3.2 實驗內容
本文通過對不同數據集和模型進行組合,驗證自建數據集和模型的有效性。實驗設置遵循控制變量原則,組合方式如下:1) 公開數據集+模板匹配模型;2) 自建數據集+模板匹配模型;3) 自建數據集+BBDFiT模型。
根據以上組合方式,本文設計了兩個對照實驗:1) 比較公開數據集+模板匹配模型與自建數據集+模板匹配模型,以驗證自建數據集在提升實際應用中識別率方面的有效性;2) 比較自建數據集+模板匹配模型與自建數據集+BBDFiT模型,以驗證BBDFiT模型的有效性。
3.3 實驗結果分析
3.3.1 數據集訓練模板匹配模型對比
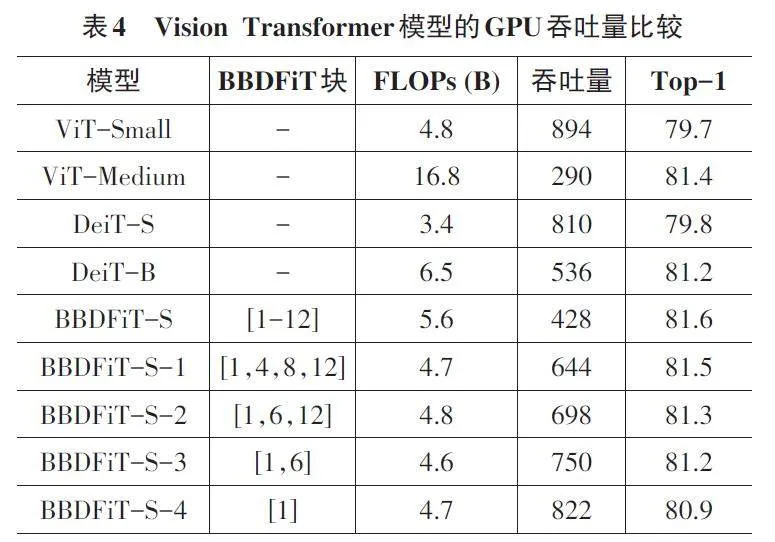
本研究評估了BBDFiT模型在NVIDIA V100 GPU 和PyTorch環境下、輸入尺寸為224×224時的推理速度性能。結果表明(見表4) ,與ViT 和DeiT 相比,BBDFiT在相似的推理速度下獲得了更高的準確率。雖然BBDFiT塊增加了一些計算和內存開銷,但增幅有限,它能夠有效捕捉局部結構信息,在精度和復雜度之間取得了更好的平衡。
3.4 消融實驗
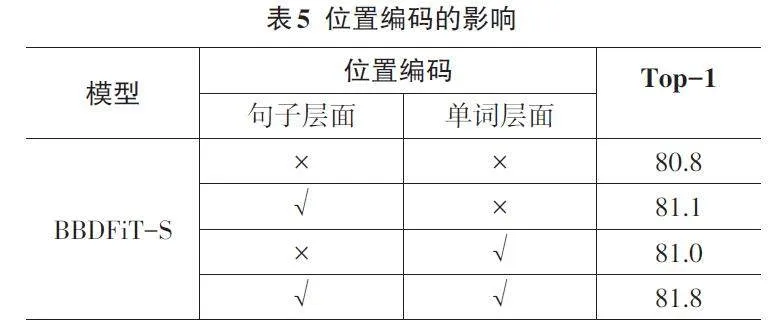
3.4.1 位置編碼的影響
位置信息對圖像識別至關重要。在BBDFiT結構中,句子位置編碼用于保留全局空間信息,而詞位置編碼則保持局部相對位置信息。實驗驗證了它們的有效性(見表5) 。在使用兩種位置編碼時,BBDFiT-S 取得了81.8%的最佳top-1準確率。移除句子位置編碼或詞位置編碼后,準確率分別下降了0.8%和0.7%。若去除所有位置編碼,則準確率嚴重下降1%。結果表明,BBDFiT中的位置編碼方案能夠很好地融合全局和局部位置信息。
3.4.2 頭部個數
在本文中,外部Transformer塊采用了64的頭寬度。而內部Transformer塊中的頭數量則是另一個需要研究的超參數。通過表6中的評估結果可以看出,適當的頭數量(例如2或4) 可以達到最佳性能。
3.4.3 視覺單詞的數量
在BBDFiT 中,輸入圖像被分割成若干個16 × 16patch,每個圖像patch 進一步劃分為m 個子patch(也可稱為視覺單詞),其大小為(s,s),以增加計算效率。本文測試了超參數m 對BBDFiT-S結構的影響。當調整m 時,嵌入維度c 相應調整以控制FLOPs。根據表7的結果顯示,m 的變化對性能產生了輕微影響。本文默認使用m = 16來提高其效率。
3.5 可視化
3.5.1 特征圖的可視化
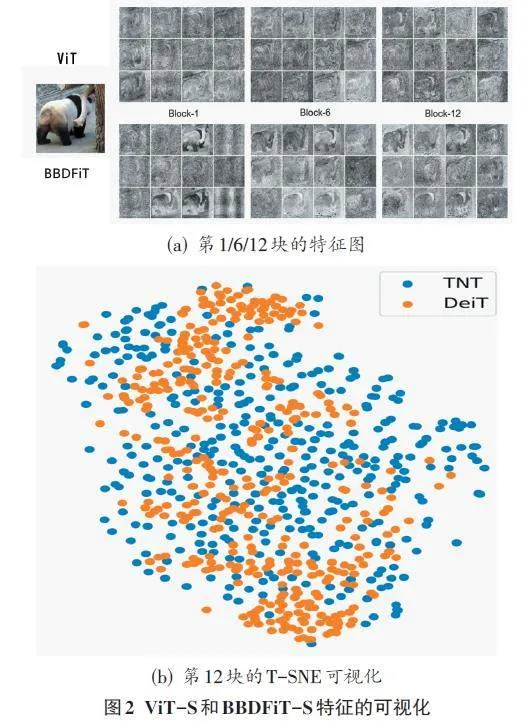
在本文中,筆者將ViT和BBDFiT學習到的特征進行了可視化,以了解所提出方法的效果。輸入圖像的尺寸被調整為1024×1024,并根據塊嵌入的空間位置重塑為特征映射。圖2(a)展示了不同塊的特征圖,結果顯示BBDFiT 相比ViT 能夠更好地保留局部信息。圖2(b)展示了使用T-SNE[14]對第12塊384個特征圖進行可視化的結果,BBDFiT的特征圖更多樣且豐富,這歸因于內部Transformer用于建模局部特征。
圖3展示了BBDFiT的像素級嵌入。每個patch的詞嵌入根據空間位置重構為特征映射,并沿通道進行平均。可以觀察到,淺層特征保留了更多的局部信息,而深層特征則逐漸抽象化。通過這樣的可視化分析,筆者發現BBDFiT相比ViT能夠更好地捕捉和利用圖像的局部結構信息。
3.5.2 注意力圖的可視化
本文的BBDFiT塊包含兩個自注意層,分別為內部自注意層和外部自注意層,用于建模視覺詞與句子之間的關系。圖4展示了內部Transformer中不同查詢的注意力映射。對于給定的查詢視覺詞,與其外觀相似的視覺詞具有更高的注意力值,這表明這些視覺詞的特征與查詢詞的交互更為相關。
4 總結
本文提出了一種名為BBDFiT(Blast Blockiness De?tection Frame Transformer) 的新型視覺識別網絡架構,專門用于評估煤礦爆破作業中的大塊率。與標準視覺Transformer直接對打平的patch序列進行建模不同,BBDFiT將輸入圖像劃分為patch(句子)和子patch(單詞),并通過內外兩個Transformer模塊分別對句子和單詞嵌入進行建模,從而融合局部信息。通過保留和利用圖像的局部結構信息,BBDFiT在評估爆破大塊率等視覺任務上取得了優異的表現。大量煤礦爆破現場圖像數據的實驗驗證了BBDFiT架構的有效性。
參考文獻:
[1] 謝先啟,黃小武,姚穎康,等.露天深孔臺階精細爆破技術研究進展[J].金屬礦山,2022(7):7-18.
[2] 汪旭光,吳春平.智能爆破的產生背景及新思維[J].金屬礦山,2022(7):1-6.
[3] 吳春平,汪旭光.智能爆破的基本概念與研究內容[J].金屬礦山,2023(5):59-63.
[4] BAHRAMI A, MONJEZI M, GOSHTASBI K, et al. Prediction of rock fragmentation due to blasting using artificial neural net?work[J]. Engineering with Computers, 2011, 27(2): 177-181.
[5] HAN K, WANG Y, TIAN Q, GUO J, et al. GhostNet: More fea?tures from cheap operations[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). 2020: 1580-1589.
[6] HE K, ZHANG X, REN S, SUN J. Deep residual learning for image recognition[C]//Proceedings of the IEEE/CVF Confer?ence on Computer Vision and Pattern Recognition (CVPR).2016: 770-778.
[7] BROWN T B, MANN B, RYDER N, et al. Language models are few-shot learners[C]//Advances in Neural Information Process?ing Systems (NeurIPS), 2020(33): 1877-1901.
[8] DOSOVITSKIY A, BEYER L, KOLESNIKOV A, et al. An im?age is worth 16x16 words: Transformers for image recognition at scale[C]//International Conference on Learning Representa?tions (ICLR). 2021.
[9] TANG Y, HAN K, XU C, XIAO A, et al. Augmented shortcuts for vision transformers[EB/OL]. [2023-12-20]. arXiv preprint arXiv:2106.15941.
[10] YUAN L, CHEN Y, WANG T, et al. Tokens-to-token ViT:Training vision transformers from scratch on ImageNet[EB/OL].[2023-12-20].arXiv preprint arXiv:2101.11986.
[11] ZHU X, SU W, LU L, LI B, et al. Deformable DETR: Deform?able transformers for end-to-end object detection[C]//Interna?tional Conference on Learning Representations (ICLR). 2021.
[12] 呂林,尹君,胡振襄.基于圖像處理的巖體塊度分析系統[J].金屬礦山,2011(2):118-121.
[13] 荊永濱,馮興隆,張凱銘,等.基于塊體二維圖形的巖塊三維篩分尺寸研究[J].金屬礦山,2020(4):46-51.
[14] VAN DER MAATEN L, HINTON G. Visualizing data using t-SNE[J]. Journal of Machine Learning Research, 2008, 9(11):2579-2605.
【通聯編輯:唐一東】
