人工智能時代個人信息保護的困境與路徑研究
2024-11-06 00:00:00楊真
數字通信世界 2024年10期
摘要:隨著人工智能技術的廣泛應用,從智能家居到在線購物,再到健康監測,大量個人數據被收集和分析以提供定制化服務。這使得個人信息在不知不覺中被記錄并存儲在各種云和數據中心,進而產生個人信息泄露和被盜取的風險。該文以人工智能時代個人信息保護的困境與路徑為主要研究對象,首先概括了人工智能時代個人信息泄露的途徑;其次分析了人工智能時代個人信息保護的困境;最后從技術層面、倫理層面和政策層面提出了人工智能時代個人信息保護的具體策略。
關鍵詞:個人信息;保護困境;保護路徑;人工智能
doi:10.3969/J.ISSN.1672-7274.2024.10.069
中圖分類號:G 252.7;TP 3 文獻標志碼:A 文章編碼:1672-7274(2024)10-0-04
Research on the Challenges and Paths of Personal Information Protection
in the Era of Artificial Intelligence
Abstract: With the widespread application of artificial intelligence technology, from smart homes to online shopping, and then to health monitoring, a large amount of personal data is collected and analyzed to provide customized services. This makes personal information unknowingly recorded and stored in various clouds and data centers, thereby creating risks of personal information leakage and theft. This article focuses on the challenges and paths of personal information protection in the era of artificial intelligence, and first summarizes the ways in which personal information is leaked in the era of artificial intelligence; Secondly, the dilemma of personal information protection in the era of artificial intelligence was analyzed; Finally, specific strategies for personal information protection in the era of artificial intelligence were proposed from the technical, ethical, and policy perspectives.
Keywords: personal information; protection dilemma; protecting the path; artificial intelligence
人工智能時代個人信息泄露的影響范圍和深度遠超以往,這種泄露主要對用戶的經濟安全、信用安全以及個人隱私安全造成嚴重影響。在經濟上,被泄露的個人信息可被用于冒用身份辦理信用卡、網絡貸款等金融活動,導致原信息所有者蒙受巨大經濟損失和債務糾紛。個人信用受損可能會影響個人的就業、銀行信貸等方面的正常權利。個人隱私的泄露還會導致住址等敏感信息暴露,進而增加個人遭受網絡暴力、跟蹤、猥褻或恐嚇的風險,嚴重危及人身及財產安全。許多公司和機構在數據保護措施上存在缺陷,無法確保用戶個人數據不被外界非法訪問。加之缺乏嚴格的數據保護法規和監管機制,這使得許多非法訪問和轉賣個人信息的違法行為難以得到有效遏制,為不法分子留下了可乘之機。由此可見,人工智能時代加強數據安全保護措施,完善相關法律法規,提高公眾的隱私保護意識,是保護用戶個人信息安全的必要手段。
1 人工智能時代個人信息保護的困境
1.1 技術困境
當前運用非常廣泛的人工智能算法會通過持續學習用戶行為和偏好,為用戶提供高度個性化的內容和服務。盡管這種看似有益的技術進步為人們檢索自己所感興趣的信息提供了很大的便捷,實際上卻又可能導致“信息繭房”現象,即用戶會被限定在由算法決定的信息氣泡中,無法接觸到更多元、更有效的信息內容。很多時候人工智能算法的設計還會忽視用戶的知情權,例如為了提高服務的個性化程度,許多算法會對用戶數據進行深度挖掘,而這種挖掘過程往往伴隨著對用戶隱私的侵犯[1]。
算法歧視是人工智能技術應用中的另一重大問題,它指的是由于算法設計者的偏見或算法本身的不完善而導致的對某些用戶群體不公平的對待。這不僅在道德上令人質疑,而且在商業實踐中可能出現“大數據殺熟”的現象,即對于有相似消費行為的用戶群體,根據其支付意愿進行價格歧視,或者根據用戶手機型號提供不同的票價等。這類技術算法可能短期內會為企業帶來利益,但從長遠來看會侵害消費者權益,破壞市場公平。由此可見,人工智能技術為用戶帶來便捷的同時,其在個人信息保護方面存在的問題亟待解決。這要求技術開發者完善算法的設計,確保算法的公正性和透明度,保護用戶的個人信息不被濫用或泄露,維護公平健康的網絡環境。
1.2 倫理困境
人工智能時代個人信息保護所面臨的倫理困境也比較突出,特別是在未成年人使用互聯網過程中“賦權”和“保護”之間的平衡上。未成年人作為社會的弱勢群體,需要得到充分的保護以防止信息被濫用和泄露。但隨著人工智能和智能設備逐漸成為未成年人日常生活重要組成部分,很多時候未成年人不知道如何與人工智能系統互動、如何管理和保護個人信息。盡管法律和政策對未成年人提供了較為嚴格的保護,但在實際操作中許多平臺會忽視對未成年人在處理個人信息方面的“賦權”,導致未成年人在人工智能環境中不懂如何安全合理地享受平臺服務。
此外,現實世界中的歧視和不平等問題也會在人工智能時代通過數據和算法被放大。由于大部分人工智能系統的訓練數據來自于現實世界,數據會包含現實世界里存在的偏見和歧視,使得一些“邊緣群體”受到人工智能技術帶來的情感傷害。例如,美國亞馬遜公司所開發的人臉識別系統Amazon Rekognition曾因難以識別膚色較深者的性別、存在種族歧視等受到倫理審查[2]。算法工程師的個人偏見和設計中的不足會加劇這一問題,使得人工智能系統在無意中復制并加劇不平等和歧視情況。因此,人工智能時代個人信息的保護不僅需要嚴格的法律法規來約束,還需要在算法設計和數據處理過程中引入更多倫理考量,確保技術應用不會加劇社會不公現象。
1.3 政策困境
為應對個人信息保護的挑戰并保障數字經濟的健康有序發展,我國已制定并實施了諸多與個人信息保護相關的法律法規,例如《個人信息保護法》明確了國家對個人信息保護的總體要求和監管架構,指定國家網信部門負責統籌協調個人信息保護工作及相關監督管理任務。《刑法修正案(七)》和《刑法修正案(九)》進一步完善了個人信息的保護機制。《常見類型移動互聯網應用程序必要個人信息范圍規定》則明確了各類App在收集個人信息時的界限條件。這些法律法規的出臺標志著中國在個人信息保護領域的法規體系正在逐步完善。
但是個人信息的界定非常復雜,對在日常應用中用戶的行為數據如瀏覽歷史、購買記錄等是否屬于個人信息往往存在爭議,這使得在實際認定何為個人信息泄露時存在法律適用困難[3]。盡管法律規定了嚴格的個人信息保護要求,但在實踐中許多互聯網公司通過復雜的用戶協議和隱私政策,使得用戶在不完全理解的情況下同意了個人信息被該平臺收集,當信息泄露發生時用戶很難證明信息收集和使用的非法性,因為用戶確實在技術上給與了個人信息授予權。此外,對于違法行為的監管和懲處也面臨諸多挑戰,如證據收集困難、技術追蹤難度高等問題都會制約現有個人信息保護法律法規的實施效果。因此,如何強化法律執行力、明確技術和法律的界限,以及如何提升公眾對個人隱私信息的保護意識等,都需要從政策層面探索解決之道。
2 人工智能時代個人信息保護的路徑
2.1 技術路徑
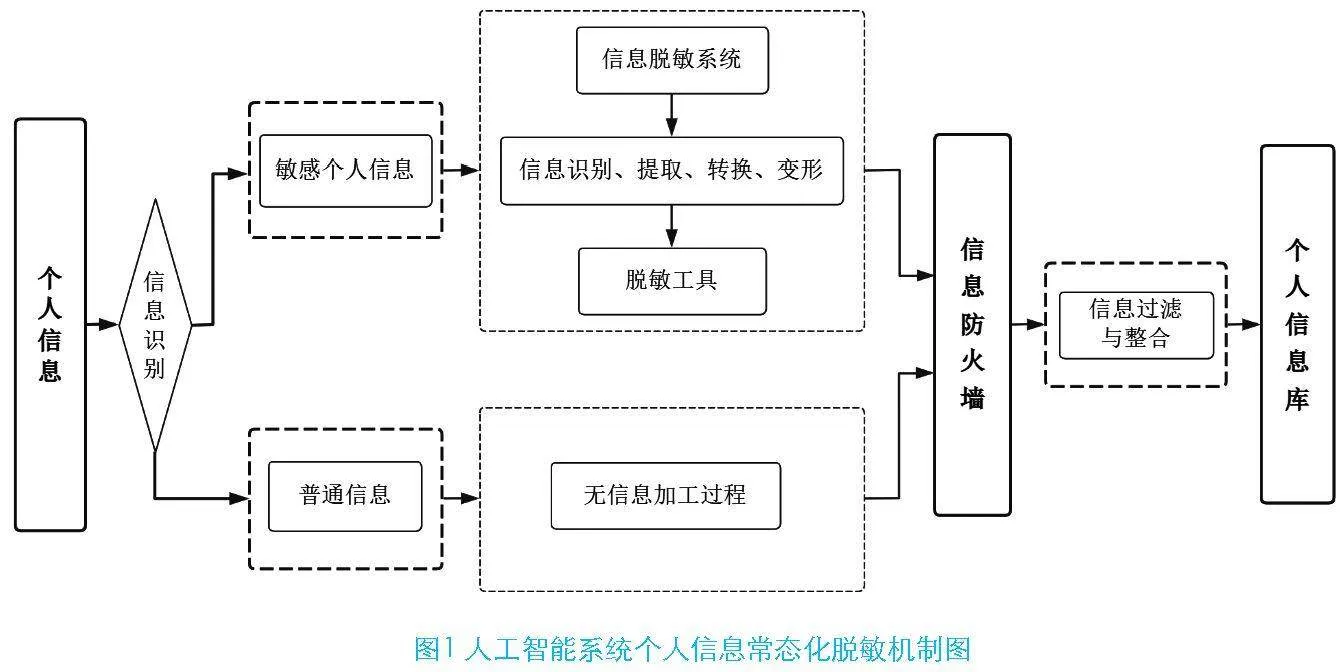
在人工智能時代背景下,保護用戶個人信息,可以通過建立常態化的信息脫敏機制來完成,即個人信息在進入人工智能系統前就經過了一系列的處理,包括信息的識別、提取、轉換和變形等步驟。這種個人信息脫敏機制可以有效降低信息數據的敏感程度,防止客戶隱私暴露,還可以規范應用平臺對用戶信息的處理。企業則可以通過設置信息安全防火墻,進一步防止外部攻擊者獲取和利用個人數據,信息安全防火墻的設置可對脫敏后的信息進行重復篩選過濾,為個人數據提供雙重保護。人工智能系統個人信息常態化脫敏機制如圖1所示。
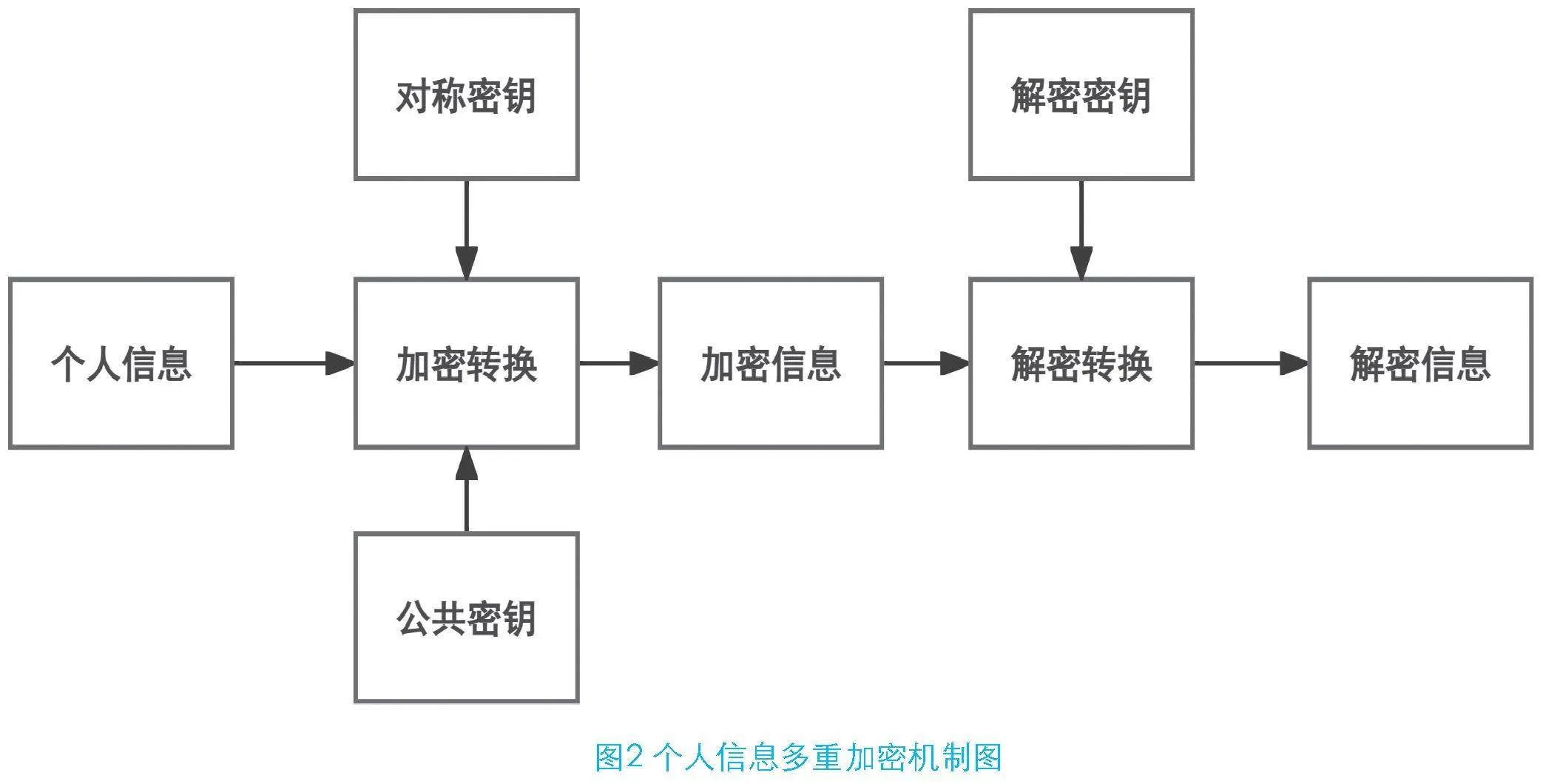
各類人工智能平臺還可以通過多重加密技術為個人信息安全提供保障。在人工智能系統收集、存儲或傳輸個人信息的各個階段,可以應用先進的加密技術,將敏感數據轉化為無法直接閱讀的格式,僅能通過特定的解密密鑰恢復原始內容。如果要對信息進行加密轉換可以使用對稱密鑰和公共密鑰這兩種方式,前者適用于需要快速處理的場景,因為對稱密鑰加密雖然速度快,但密鑰泄露的風險較高;而后者則可以在數據安全性要求更高的環境中提供更強的安全保障,公共密鑰可以通過分離加密和解密密鑰降低密鑰管理的風險,并由此增強數據保護的可靠性,具體個人信息多重加密機制如圖2所示。
2.2 倫理路徑
由于未成年人在互聯網和人工智能環境中的高度活躍,特別容易暴露于各類信息安全風險之下,所以,應從倫理角度針對未成年人群體和監護人群體普及人工智能應用知識。例如,學校可以通過信息科學課程將人工智能的算法思維、算法動機教授給學生,使未成年人群體可以根據一定的算法知識檢索信息,獲取互聯網資料。學校還可以通過對監護人進行宣講和培訓,使家長們認識到保護個人信息不被侵犯的重要性,充分履行監護人的義務,幫助未成年群體用好人工智能這把“雙刃劍”。而各類人工智能應用平臺則應制定更為細致的用戶協議和隱私政策,明確且詳細地告知未成年用戶個人信息可能被使用的具體方式,確保其在完全理解的基礎上做出同意的決定。
眾所周知,人工智能系統的決策能力高度依賴于訓練數據。如果訓練數據本身包含有關種族、性別或其他社會偏見的信息,那么由此訓練出的模型無疑會復制甚至放大這些偏見。為了從根本上減少這種風險,平臺應在算法的設計和數據的選擇過程中引入倫理審查機制,進行算法審核以識別和修改可能導致歧視的算法邏輯,采用多元化的數據源來訓練算法,確保系統的決策盡可能公正無偏。各類人工智能平臺還應積極踐行“以人為本”理念,將對人性的理解融入到技術的迭代中去,以減少偏見和歧視的發生,讓人工智能滿足“可知”和“可信”這兩個必要條件。
2.3 政策路徑
從政策層面制定個人信息保護的路徑應關注人工智能技術的快速發展,還要兼顧公眾的基本權利需求。監管部門和人工智能平臺是個人信息保護的兩大重要主體,二者如果能夠實現良性互動可以很好地保護用戶隱私。人工智能企業可以將“安全港制度”這種行業制定標準引入到平臺中,及時向個人信息管理部門報告用戶個人信息使用規范,由此將人工智能平臺轉變成主動保護客戶個人信息的積極角色。而政府監管部門則需要出臺具體監管方案,定期對人工智能平臺進行審核,確保其遵守既定的個人信息保護規則,如此用戶的個人信息便可以獲得更有效的保護。
隨著人工智能技術的飛躍式發展,開展個人信息保護方面的國際合作是必然趨勢,國際上許多人工智能非常發達的國家先后出臺了許多人工智能治理制度,例如美國的《人工智能權利法案藍圖》(2022年)、歐盟的《人工智能法案》(2023年)等,我國也出臺了《生成式人工智能服務管理暫行辦法》(2023年),這些政策法規均強調了人工智能環境下個人信息保護的重要性,但是對用戶個人信息保護理念、具體方式等暫未形成國際統一標準[4]。通過國際合作形成廣泛的共識和統一的標準是保護用戶個人信息的有效手段,各國應加強合作,通過行業組織或政府部門推動人工智能治理框架的標準化,使個人信息保護具備特定的規則和協議。如此有助于解決跨境數據流動帶來的個人信息泄露問題,也能確保在全球范圍內的個人信息得到國際合力保護。
3 結束語
人工智能時代人類在享受技術進步帶來的便利的同時,也面臨著個人信息被泄露的挑戰。科技發展不應以犧牲個人隱私為代價,構建既能利用人工智能優勢也能確保信息安全的環境十分必要,各類智能平臺可以通過建立常態化的信息脫敏機制和強化信息加密措施來保護個人信息不被濫用,倫理宣傳和政策法規也應與技術發展同步推進,以確保人工智能既具備技術先進性也保持倫理正當性。
參考文獻
[1] 錢燕娜.人工智能算法的法律問題與應對措施[J].喀什大學學報,2024,45(2):28-34.
[2] 亞馬遜人臉識別技術Rekognition被爆種族歧視[DB/OL].鳳凰網.https://finance.ifeng.com.2019-01-28.
[3] 徐夢瑤.大數據中的隱私流動與個人信息保護研究[J].東南大學學報(哲學社會科學版),2022,24(S1):46-49.
[4] 李陽春,楊曉偉.數據安全和個人信息保護角度下的國際合作研究[J].工業信息安全,2023(2):17-22.
