基于大數據的審計案件線索分類研究
2024-11-06 00:00:00莊曉明
數字通信世界 2024年10期
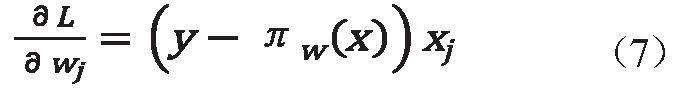
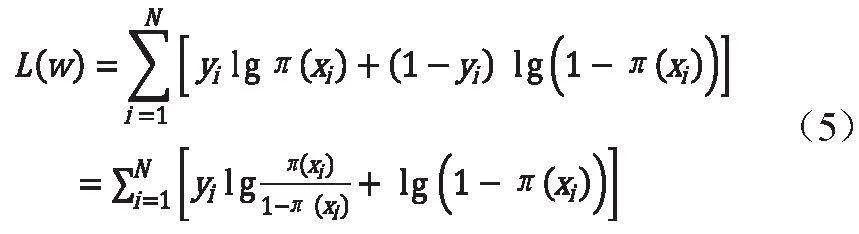

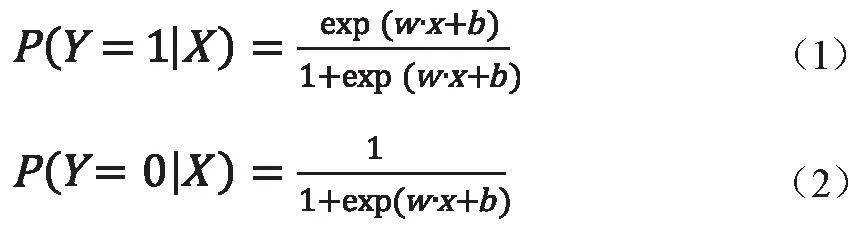
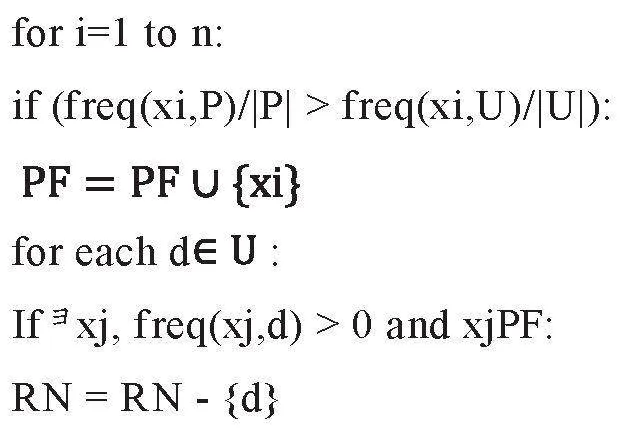
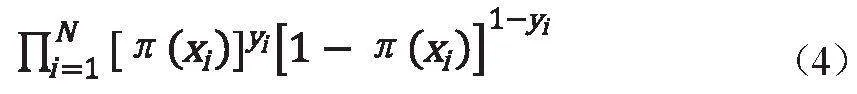
摘要:隨著大數據技術的迅速發展與應用,審計案件線索分類面臨著諸多挑戰,如數據質量與準確性不高、數據處理與分析難度增加、數據隱私與保密性需強化、缺乏標準與規范等。針對這些問題,該文提出了相應的策略,旨在提高審計案件線索分類的效率與準確性。同時,本文也可以為其他領域的數據分析提供一定的借鑒與參考。
關鍵詞:大數據;審計案件線索;分類策略
doi:10.3969/J.ISSN.1672-7274.2024.10.014
中圖分類號:F 239;TP 3 文獻標志碼:A 文章編碼:1672-7274(2024)10-00-04
Research on the Classification of Audit Case Clues Based on Big Data
Abstract: With the rapid development and application of big data technology, the classification of audit cas+4dTfC3n6nO/QR3SwPGjHUpriYT1IBeqJCB2Sz4mSOg=e clues faces many challenges, such as low data quality and accuracy, increased difficulty in data processing and analysis, need to strengthen data privacy and confidentiality, and lack of standards and norms. In response to these issues, this article proposes corresponding strategies aimed at improving the efficiency and accuracy of audit case clues classification. At the same time, this article can also provide some reference for data analysis in other fields.
Keywords: big data; audit case clues; classification strategy
在當今社會,大數據技術的迅速發展與廣泛應用為各個領域帶來了巨大的機遇與挑戰。審計作為一項涉及大量數據與復雜分析的經濟監督活動,如何有效利用大數據技術進行審計案件線索分類,提高審計效率與準確性,是當前審計行業面臨的重要問題[1]。通過本研究,我們希望能夠為審計行業提供有益的參考,推動審計技術的創新與發展,提高審計工作的效率與準確性。
1 審計案件線索分類相關技術發展現狀
1.1 數據質量與準確性不高
在大數據環境下,數據的來源與類型多種多樣,這使得數據的質量與準確性成為一個重要的問題。由于數據可能包含各種主觀與客觀的錯誤,如遺漏、誤解與錯誤,這可能導致審計線索的誤導與不準確[2]。此外,不同數據源之間的數據差異也可能導致審計線索分類的不準確。
1.2 數據處理與分析難度增加
大數據的規模與復雜性要求審計師具備更高的數據處理與分析能力。他們需要使用更高級的技術工具與算法來處理與分析這些數據,以便準確地識別與分類審計線索[3]。然而,目前許多審計機構缺乏這方面的技術與人才,這限制了1Ycw0ViFupgHdBTvXvLYSqSpkFcgU1S2smIXtC1TBO8=大數據在審計中的應用與發展。
1.3 數據隱私與保密性需強化
在大數據背景下,數據的隱私與保密性成為一個重要的問題。審計師需要采取措施保護個人與企業的敏感信息,防止數據泄露與濫用。然而,如何在保護數據隱私與保密性的同時,有效地利用大數據技術進行審計案件線索分類,是一個亟待解決的問題。
2 基于大數據的審計案件線索分類策略
2.1 提高數據質量與準確性
第一,建立數據質量標準:根據審計需求,建立一套完善的數據質量標準,包括數據的完整性、準確性、一致性與真實性等方面。通過數據清洗、驗證等手段,提高數據的準確性與質量。第二,定期評估數據質量:定期對數據進行質量評估,發現數據中存在的問題與錯誤并及時進行糾正與修復。同時,通過評估數據質量,可以發現數據來源與數據采集等方面存在的問題,進一步優化數據采集與數據處理流程。第三,強化數據質量監控:在數據處理與分析過程中,需要不斷監控數據質量,及時發現與處理數據異常與錯誤。通過建立數據質量監控機制,可以實時監測數據的質量與準確性,保證數據的準確性與可靠性。
2.2 優化數據處理與分析流程
首先,數據預處理:在進行數據處理與分析之前,需要對數據進行預處理。數據預處理包括對數據進行清洗、去重、填充缺失值等操作,以保證數據的準確性與可靠性。其次,數據分組與分類:根據數據的特征,將數據進行分組與分類。通過分組與分類,能夠將數據劃分為不同的類別與組別,以便后續的數據分析與挖掘。再次,數據聚合與匯總:將數據進行聚合與匯總,將分散的數據整合成整體的數據。通過數據聚合與匯總,可以發現數據中隱藏的規律與趨勢,為審計案件線索的分類提供有力的支持。最后,數據可視化與分析:通過數據可視化與分析工具,將數據進行可視化展示與分析。通過可視化展示,能夠更加直觀地展示數據的分布與特征,便于發現數據中存在的問題與異常。
2.3 強化數據隱私與保密性
首先,建立數據隱私與保密性政策:制定明確的數據隱私與保密性政策,對數據的采集、存儲與使用等方面進行規范與管理。同時,加強對數據使用人員的監管與教育,防止數據泄露與濫用。其次,數據加密與加密存儲:采用數據加密技術,對敏感數據進行加密處理。同時,將加密數據存儲在加密存儲設備中,防止數據被非法獲取與利用。再次,數據訪問權限控制:對數據的訪問權限進行嚴格控制,只有經過授權的人員才能訪問敏感數據。同時,采用多層次的安全審計機制,對數據的訪問與使用進行實時監控與記錄。最后,數據備份與恢復:對數據進行定期備份與恢復操作,以防止數據丟失與損壞。同時,采用災備恢復機制,確保備份數據的可用性與完整性。
3 審計案件標簽管理系統設計方案
3.1 案件線索標簽設計及重要性計算
使用種子線索覆蓋率作為標簽重要性的量化指標,基本步驟如下:
①獲得種子線索CID列表CID_SEED,共計N個CID。
②將標簽案件線索表與種子線索CID列表內關聯,獲得種子線索標簽案件線索表TAG_SEED。
③設當前標簽管理系統中基礎標簽個數為M,在TAG_SEED中對每個標簽的最新業務版本計算CID個數CNT(i),i=1…M。
④每個標簽在種子群體上的覆蓋率為X(i)=CNT(i)/N,i=1…M,覆蓋率越高,重要性越高。
將標簽按照重要性進行可視化,即確定從標簽覆蓋率圖像尺寸空間的一個單增映射,以體現重要性和覆蓋率正相關的關系。
典型的映射F有線性函數AX+B(A>0,B>0)、指數函數AX(A>0)和N次函數XN(N>1)等。最終上線版本可考慮提供多種函數接口,呈現不同分布種類的云圖(映射的梯度越大,標簽重要性的區分度越大)。
3.2 模型設計
3.2.1 模型定義
采用帶正例的無標記樣本學習(PU Learning),正例即種子線索。可定義,種子線索(記為P,即Postive)相對于未標注的對照案件線索群體(記為U,即Unlabled)來說,規模要小得多。PU學習的主要步驟有:
①根據P線索在U中找出可靠的負樣本集合RN(Reliable Negative),以便將PU問題轉換為經典的二分類問題。
②使用P和RN分別作為正負樣本,訓練分類模型。
3.2.2 確立可靠負樣本
常用的算法有樸素貝葉斯、Rocchio、SPY、1-DNF等。綜合考慮基礎標簽定義形式和當前標簽管理系統存儲結構,優先考慮1-DNF算法。
1-DNF算法基本思想是:對于每個特征,如果其在P集合中的出現頻次大于N集合,記該特征為正特征(Positive Feature,PF),所有滿足該條件的特征組成一個PF集合。對U中的每個樣本,如果其完全不包含PF集合中的任意一個特征,則該樣本應加入RN。算法步驟描述如下:
①PF置空,RN=U。
②設的特征集為。
實現方法及主要問題。從上一步做完獨熱編碼的模型寬表出發進行上述算法操作,一個可行的通過基本數據轉換(查詢語句)實現的步驟如下:
①設寬表字段為CID,X1,…,XN,IS_P。其中X1到XN為N個0-1特征,IS_P為是否正例的0-1標記。生成如下2N個新列:Pi=Xi*IS_P, Ui=Xi*(1-IS_P),i=1 to N。
②對P1,…,PN和U1,…,UN字段全表Group By求和得到一個維度為1*2N的橫表,結構為SUM_P1,…,SUM_PN,SUM_U1,…,SUM_UN。
③使用寬轉長操作將上表轉成N*3維的豎表,字段為FEATURE_INDEX,SUM_P,SUM_U,其中FEATURE_INDEX值為“X1,…,XN”。
④對豎表通過條件SUM_P/|P|>SUM_U/|U|進行過濾,留下的FEATURE_INDEX用來表征PF特征集,假設剩下n個特征。
⑤將上一步的FEATURE_INDEX做長轉寬操作變為維度為1*n的寬表,列名為Xa1,Xa2,…,Xan。其中a1到an為1到N的一個子集,n≤N。表的值為常數0。
將原始寬表和第c229a2df00bd77be5fa52c86f6084266cfb1269e6ccdd0c083f463c313d13471⑤步中的橫表用(Xa1,Xa2,…,Xan)組合鍵做內關聯,關聯所得的CID即為RN集合。
與特征集轉換過程一樣,該步驟的主要問題還是需要確保編碼的參數泛化問題,如上述過程中的N。
3.2.3 模型訓練及算法選擇
確定可靠負樣本之后,將其作為負樣本與種子線索所代表的正樣本合并即可使用分類器訓練模型。我們分別嘗試邏輯回歸和Xgboost算法。最終上線版本(或者均上線提供模型選項)取決于平臺實際情況和后續測試結果。
3.2.3.1 邏輯回歸
邏輯回歸屬于經典的廣義線性模型,我們的問題屬于二項邏輯回歸模型:
式中,X∈R是自變量;Y∈0,1是輸出;w為權值向量;b為偏置;w·x是w和的內積。
設訓練集中有N個樣本。假設:
則似然函數為:
對其求對數似然函數有:
從而對求得極大值,得到w的估計值。求極值的方法可以是梯度下降法、梯度上升法等。
主要實現步驟有:
(1)生成訓練數據。將正樣本集P與上一步中獲得的可靠負樣本集RN合并,統計正樣本率,即Target Rate。如果Target Rate過于不平衡(<1%或>99%)則應考慮重新抽樣使得正、負樣本平衡——當RN過大,則對RN集進行抽樣;當P過大則對P進行抽樣。邏輯回歸效果不受輕度樣本不均的影響,因其損失函數不是由正確率來決定的,而是計算最大似然值。這一步最終生成訓練數據。
將邏輯回歸算法進行編碼。一般的做法是將開源的算法包接入大數據平臺對訓練數據使用算法獲得模型參數,如spark的MLlib包即提供邏輯回歸的算法功能。
由于邏輯回歸模型參數計算的最大似然問題較為簡單,開發者直接使用編程語言也能輕易實現。例如,可采用隨機梯度上升法最大化,迭代函數為
其中為梯度向量,分量為的偏導,即
故隨機梯度上升迭代算法為
重復下面直到收斂
3.2.3.2 Xgboost
Xgboost是適用于大規模并行運算的提升樹開源工具包,大量數據挖掘競賽選手采用它,展現了強大的威力。同時該算法包的擴展性和可移植性強,便于工業界大規模問題的解決。在當前問題中的實現步驟與邏輯回歸方法類似,包括:
(1)生成訓練數據。由于Xgboost是多個回歸樹的“加法”,故對于樣本不平衡的處理方法與邏輯回歸類似。在極度不平衡的情況下需要進行重抽樣處理。
使用Xgboost算法包對訓練數據運行模型算法,生產成模型框架Object。使用何種語言編碼取決于大數據平臺的版本,并且需要仔細進行測試,保證算法包使用正確、結果可靠。無須算法層面的編碼,因為Xgboost包提供多種接口,包括C++、R、Python、Julia和Java。甚至,許多開源工作者開發了在多種分布式計算系統上直接能夠使用的API,通過正確的流程控制和API5CSKRcP4MPtNAcljfFof4A==使用編碼,能輕松地實現Xgboost算法快速和高效的功能。例如,Xgboost4J是一個能同時在Spark、Flink和Dataflow等JVM平臺上使用的便攜式API。通過它即可引用Xgboost包中的各種功能。
(2)模型打分。使用上一步生成的模型object對測試集上的樣本點進行打分。
之后投產的步驟需要在U集線索上進行打分,輸出的正例概率值可作為同P正例線索相似度的度量衡。
4 模型評估
由于該問題是半監督問題,只有正例的實際結果,無法在全量數據上進行模型和實際結果的對比驗證。不過,依然可以從以下兩方面入手,評估模型效果:
(1)評估帶“可靠負樣本”標簽的分類模型本身的效果。使用傳統的ROC曲線、AUC、KS值及混淆矩陣等。根據實際需求可以考慮在系統中開放相關指標的可視化接口,供業務人員參考。
(2)可以單純研究模型在“正例”上的分數分布。正例上的分布越一致地接近1,說明正例的統一性以及同其他樣本的區分度越高。
5 審計案件標簽管理系統技術效果
審計案件標簽管理系統使用了半監督的機器學習及算法來實現案件、線索的智能分類,隨著時間的推移和使用次數的增多,該分類模型將越來越精細,越來越準確。同時,該發明可協助企業廉政部門快速對案件進行分類,并能協助客戶系統快速羅列出歷史案件信息,并展示出歷史優秀案件辦理過程,提升案件辦理效果和線索采納效率。
總之,通過對大數據技術的深入分析與應用,我們提出了一系列策略與方法,旨在提高審計案件線索分類的效率與準確性。我們針對一系列問題,提出了相應的解決策略。然而,盡管我們在基于大數據的審計案件線索分類方面取得了一定的成果,但仍有許多問題需要深入研究與探討。總的來說,本文的研究為審計行業提供了有益的參考與指導,為推動審計技術的創新與發展、提高審計工作的效率與準確性做出了貢獻。同時,本研究也可以為其他領域的數據分析提供一定的借鑒與參考。
參考文獻
[1] 周海鷹.基于協同治理視角的審計案件線索移送機制研究[J].財會通訊,2021(19):120-124.
[2] 謝秋玲.審計證據鏈在經濟案件中的司法運用[J].審計文摘,2022(11):92-95.
[3] 王陽,杜霞.高校審計線索分析方法探究[J].審計與理財,2022(3):14-16.
