中文多字體古籍數據集多任務融合識別
2024-11-05 00:00:00薛德軍師慶輝畢琰虹蘆筱菲陳婧王海山吳晨
廣西科技大學學報 2024年4期





摘 要:針對中文古籍數字化處理中大規模高質量數據集匱乏的問題,本文提出了一種新穎的2級古籍數據集建設方法:一是構建了包含119.5萬張圖片、覆蓋6 610個字符類別的多字體古籍單字數據集CACID;二是基于古籍文獻內容合成了包含86 667列古籍文字圖片的古籍篇章數據集CASID,這是目前報道的最大中文古籍合成數據集。本文設計了古籍多任務融合識別模型,并基于所建數據集進行了實驗。結果表明,模型的識別準確率從35.62%顯著提升至85.52%,驗證了涵蓋多字體多朝代的中文合成數據在古籍文字識別中的核心作用和良好泛化能力。
關鍵詞:古籍;訓練數據集;自動構建;深度學習模型;融合建模
中圖分類號:TP391.43 DOI:10.16375/j.cnki.cn45-1395/t.2024.04.014
0 引言
隨著國家對古籍數字化工作的日益重視[1],古籍文獻的數字化不僅成為保護歷史文化遺產的重要手段,更是推動文化傳承與創新的關鍵一環。近年來,隨著古籍研究的不斷深入,人們對于古籍文獻價值的認識愈發深刻,對古籍數字化的需求也日益迫切。同時,隨著人工智能技術的快速發展,越來越多的AI技術被應用到古籍數字化工作中,為古籍的保護與傳承注入了新的活力[2]。
盡管AI技術在古籍數字化中發揮了重要作用,但數字化性能的提升仍然受到高質量古籍數據集缺乏的制約。目前,古籍數字化數據集的建設主要依賴于傳統的人工標注方法,這不僅耗時耗力,而且標注質量難以保證,導致數字化效果不佳。同時,由于古籍文獻的特殊性,如文字表現形式豐富、紙張老化發黃、頁面存在污漬等問題,使得古籍圖像分析與識別成為一項非常具有挑戰性的任務[3-4]。
針對上述問題,本文提出了一種新穎的2級古籍數據集建設方法:一是構建了包含119.5萬張圖片、覆蓋6 610個字符類別的多字體古籍單字數據集CACID,為字符識別提供豐富資源;二是基于古籍文獻內容合成了包含86 667列古籍文字圖片的古籍篇章數據集CASID,進一步擴展數據集的規模和多樣性。此外,在構建好的數據集基礎上,本文設計了古籍多任務融合識別模型,并基于所建數據集進行了實驗。結果表明模型的識別準確率得到大幅度提升,從而驗證了高質量大規模古籍合成數據在古籍文字識別中的核心作用和良好泛化能力。
1 數據集構建
在古籍數字化進程中,數據集的構建至關重要[5]。古籍漢字形態豐富多樣,包括象形圖、書法字、刻板印刷、館閣體及活字印刷等,其多樣性和復雜性增加了識別難度,尤其是書法字,其書寫風格的多樣性和筆畫的流動性更是識別的難點。
由于古籍資源稀缺且標注成本高昂,獲取真實、高質量的標注數據變得異常困難。因此,合成數據成為主流的獲取訓練數據的手段,即通過模擬古籍文字圖像并添加標簽,構建古籍文字數據集。
鑒于此,本文提出2級古籍數據集建設方法。首先,構建古籍單字數據集(CACID),專注于收集古籍中的單個漢字圖像,以支持精確的漢字識別研究。其次,構建古籍篇章數據集(CASID),通過合成方式模擬古籍排版和格式,呈現連續文本段落,以提供接近實際閱讀場景的古籍圖像數據。這2個數據集的結合,全面覆蓋從單個漢字到連續文本段落的古籍內容,為古籍數字化中的文字識別、版面分析等任務提供豐富多樣的數據資源。
1.1 單字數據集構建
中國書法的字體豐富多樣,包括甲骨體、大篆、小篆、隸書、草書、楷書、行書等。在構建古籍單字數據集時,首先對單字圖像進行預處理,去除背景、增強文字部分,并轉換成黑白二值圖像;其次,按命名規則對預處理后的圖像進行標注,將同標簽、同字體的圖像進行整合;最終形成多字體CACID數據集。
該數據集包含119.5萬張圖片,涵蓋6 610個文字類別,每個文字類別包含多種書法字體。CACID數據集的采樣實例圖如圖1所示(示例為“書”的楷書、行書、草書、隸書、篆書字體)。
1.2 篇章數據集構建
篇幅圖像生成是基于古籍文本生成含有單字標注的篇幅級古籍文字圖像。其中,針對每一份古籍文本,可生成多份篇幅級古籍文字圖像與之對應,以楷書體、行書體、草書體、隸書體、篆書體等多種形式呈現。
本文整理了中文重要古籍文本300余篇,包括《晉書》《宋書》《南齊書》《梁書》《陳書》《魏書》《北齊書》《周書》《隋書》《南史》《北史》等,用作生成篇幅級古籍文字圖像的真實文字標簽。構建古籍篇章數據集CASID是一個復雜且精細的過程,涉及多個步驟以確保數據的準確性和多樣性。以下是該構建流程的詳細步驟。
Step 1 字符提取與識別
在構建數據集的開始階段,首先從文字版古籍內容中提取每一個擬使用的字符。隨后,在古籍單字數據集CACID中查找這些字符的對應圖像。為了保證合成數據的豐富性和多樣性,根據字體等標簽隨機選擇字符圖像。如果在CACID數據集中找不到某個字符的圖像,記錄下這個缺失的字符,并繼續尋找下一個字符。
Step 2 字符圖像二值化
經過提取和識別后,對每一個字符圖像進行二值化處理。這一步驟的目的是將字符圖像轉換為只包含黑白像素點的形式,以便于后續的合成和處理。在二值化過程中,設定一個閾值(如200),圖像中灰度高于此值的部分會轉換為白色,低于此值的部分則轉換為黑色。
Step 3 調整字符尺寸
為了確保所有字符在視覺上保持一致和協調,需要對每個字符圖像進行尺寸調整。具體來說,調整字符圖像的寬度或高度,使其不超過設定的像素值(如80像素)。此外,根據字符中黑色文字的像素個數進一步縮放調整,比如根據黑色占比的不同,將字符縮小到適當的比例。
Step 4 背景圖與文字定位
為了模擬真實環境,準備多個與古籍背景相似的圖像作為合成背景。這些背景圖像經過調整,達到統一的像素大小(如1 110×2 110像素)。然后,在這些背景圖像上定位出文字的排列位置。按照古籍的閱讀順序(右上至左下),確定每個文字的中心點位置,并設置適當的間距,以確保文字的整齊排列。
Step 5 文字與背景融合
文字與背景定位完成后,將每個字符圖像的中心點與背景圖像上的文字中心點對齊。通過二值與“bitwise_and”操作將字符圖像融合到背景圖像中。因此,每個字符都會準確地出現在預定的位置上,形成一幅完整的古籍篇章圖像。
Step 6 記錄字符位置
最后,為了便于后續的數據分析和處理,記錄每個字符在最終合成圖像中的位置信息。這通常包括字符的左上角和右下角坐標等數據。這些位置信息有助于快速定位和分析字符在圖像中的分布情況。
通過以上6個步驟,本文構建出一個古籍文字圖片與文本標簽對應的古籍篇章數據集CASID,共86 667列古籍文字圖片數據和對應的列文本標簽,涵蓋字符類別6 610個,總計包含104.1萬字,這是目前公開報道的最大規模的中文合成古籍篇章數據集。生成的篇幅古籍圖像實例如圖2所示(示例為三皇本紀 小司馬氏撰并注的篇幅圖像)。
2 文字識別模型
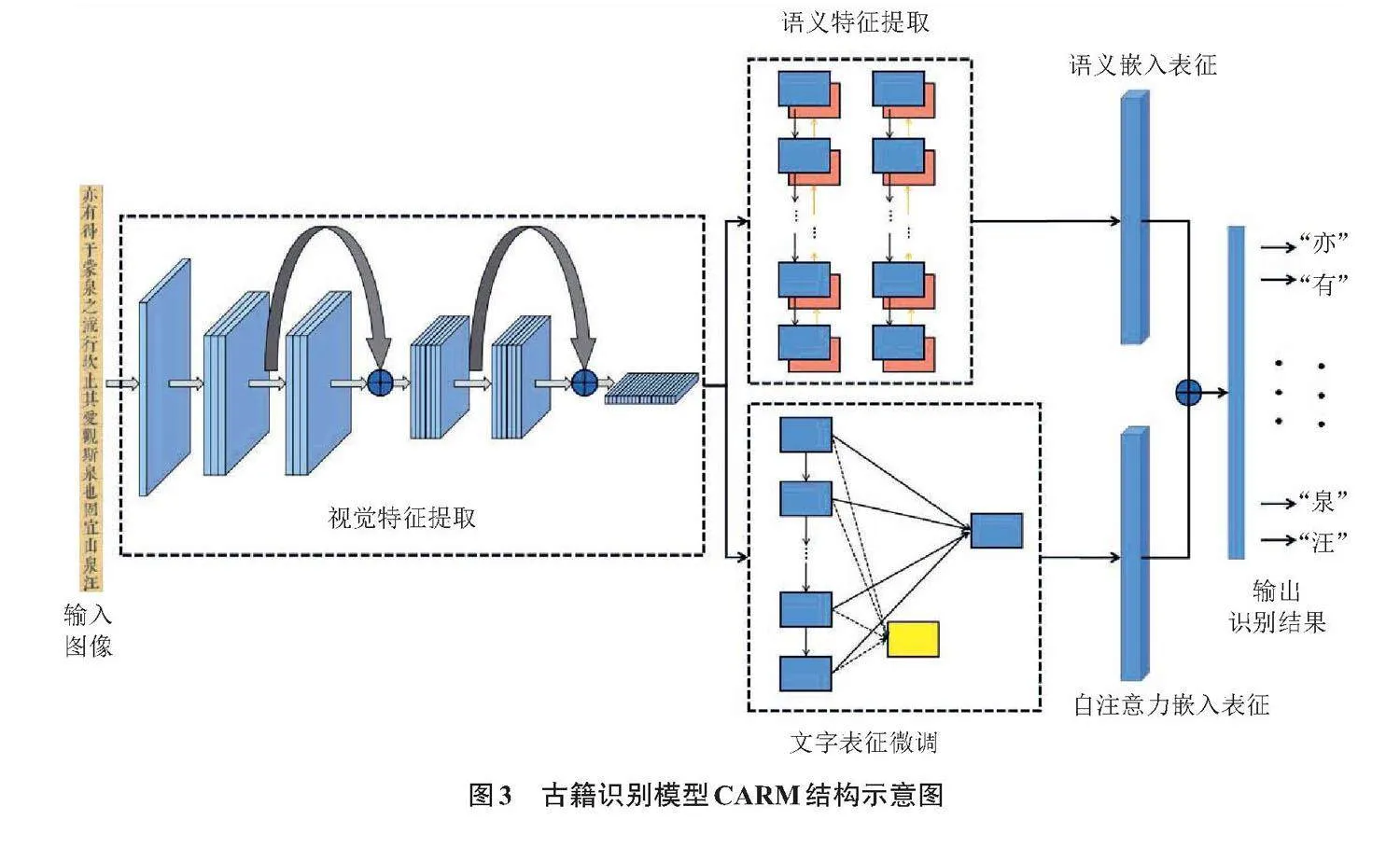
本文設計了古籍多任務融合識別模型CARM,模型結構示意圖如圖3所示。
2.1 視覺特征提取
在經典殘差模型[6]的基礎上,本文引入了通道混淆、分組卷積以及深度可分離卷積技術,旨在保障模型深度的同時拓展其寬度,進而增強通道間的信息交互與依賴關系學習。網絡結構采用模塊化設計,通過5種不同模塊與卷積的組合堆疊,構建了一個18層的模型。此外,在模塊單元間實現了多尺度特征融合[7],將模型的計算復雜度控制在2.3 G FLOPs(floating point operations per second)以內,以確保在不顯著增加計算負擔的前提下,實現模型性能的優化。
2.2 語義特征提取
在傳統序列識別結構[8]的基礎上融入語義信息,結合雙向多門循環網絡[9]與雙向自注意力模型[10-11],通過聯合調節網絡內所有神經層的前后神經元,對卷積網絡提取的圖像特征進行深度雙向表達學習。如此,不僅實現了對圖像特征的降維語義編碼,并在不同層級上進行了多輪迭代學習,從而使模型深入挖掘圖像特征中的語義表征信息與關聯信息。
2.3 多階段多任務訓練策略
為提升模型在形近字、繁體字、異體字識別上的精度及復雜背景的應對能力,本文設計了多階段、多任務訓練策略。
初始階段,混合使用合成與真實數據訓練模型,以糾正合成樣本帶來的特征偏差。隨后,利用模型識別文字類別的核心表征,并用真實數據進行文字表征微調,確保學習到的文字表征與對應類別的核心表征盡可能接近,而與其他類別的核心表征保持較遠距離[12],以此確保文字表征的準確性和區分度。最后,根據專業人員的反饋優化系統,并據此擴充和篩選數據再次訓練,以進一步提升模型性能。
3 實驗結果
3.1 實驗設置與數據集
本實驗中的訓練數據由兩部分組成:真實古籍數據集CARD和合成古籍篇章數據集CASID。CARD數據集來源于傳統的古籍文獻資源,共399萬字符,包括來自《四庫全書》約10萬列文字圖像,約189萬字符,以及來自刻版印刷書籍(包括《晉書》《宋書》等多部史書)約10萬列文字圖像,約210萬字符。兩類數據共4 285個字符類別,樣本實例圖如圖4所示。基于這些數據構建相應的訓練集和驗證集,訓練得到CARM-Base模型。
本文基于不同的數據集訓練了2個識別模型:一是基于CARD數據集構建相應的訓練集和驗證集,訓練得到CARM-Base模型;二是在CARD數據集中加入CASID數據集共同作為訓練數據,構建相應的訓練集和驗證集,訓練得到CARM-Large模型。
在測試階段,選用100張真實的古籍圖像作為模型測試集,共計1 345列。其中,隨機抽取520列進行標注,包含8 865字。測試集數據未參與上述訓練集的構建,因此可以客觀評估模型的泛化性能。測試集數據實例圖如圖5所示。
3.2 評估指標
本文采用的評估指標為[Wc](字正確率)和[Wa](字準確率)。[Wc]的計算如式(1)所示,
[Wc=Nc/Nr+Nd+Nc×100%], (1)
式中:[Nc]為模型正確識別并保留的字符數;[Nr]為模型錯誤將一個字符替換為另一個字符的數量;[Nd]為模型錯誤刪除的字符數量。
[Wa]的計算如式(2)所示,
[Wa=Nc-Ni/Ni+Nd+Nc×100%], (2)
式中:[Ni]為模型錯誤插入到文本中的字符數量。
[Wc]只關注模型保留正確字符的能力,不看其是否插入額外字符;[Wa]既考慮保留正確字符,又考慮是否插入不必要字符。因此,模型若插入過多額外字符,即使正確識別許多字符,其準確率也會受影響。
3.3 結果分析
在測試集上,本文對CARM-Base和CARM-Large這2個模型進行了評估。測試集的識別結果實例圖見圖6,模型的性能評估結果見表1。
從實驗結果可以看出,CARM-Large在測試集上的表現顯著優于CARM-Base。CARM-Large的字正確率達到了88.59%,比CARM-Base的55.53%提升了59.53%;CARM-Large的字準確率為85.52%,比CARM-Base的35.62%提升了140.09%。2個指標的大幅度提升意味著CARM-Large在識別古籍文字時能夠更好地處理各種復雜的字符特征,更準確地還原古籍文本的內容。
CARM-Large性能顯著提升主要歸功于在訓練過程中充分利用了多書法字體古籍數據集CASID。CASID的引入不僅豐富了訓練樣本的多樣性,還使得模型能夠更好地適應不同字體和風格的古籍文字。實驗結果充分驗證了使用合成數據可以大幅提升古籍識別模型的識別能力和泛化性能,可以解決古籍文字識別中訓練數據缺乏的問題。
此外,本文分析了構建古籍單字數據集CACID后,數據集中單字分布的變化情況。原數據集包含4 285個單字類別,樣本數量分布不均,存在明顯的長尾現象。經過擴充,字符類別的總數增長至6 610個,增長了近55%,顯著豐富了數據集字符的多樣性。
具體到字符來看,一些原來樣本較少的字符在擴充后得到了顯著增加。例如,“商”字的樣本數量從1 102個增加至3 191個,增長了近2倍;“簡”字從695個增加至4 075個;“趺”字從2個增加至48個等。這些字符樣本數量的提升有助于模型在訓練過程中學習到其字體特征,從而提高識別性能。
但是,一些罕見字符的樣本數量增長并不明顯。例如,“旈”字從1個增為2個,這說明對于這些罕見字符,現有的擴充策略還不夠有效。這些發現為后續改進和優化古籍文字識別模型提供了重要的指導方向。
4 結論
本文針對中文古籍數字化處理中大規模高質量數據集匱乏的瓶頸問題,提出了一種新穎的2級古籍數據集建設方法,并成功構建了CACID和CASID 2個數據集。古籍單字數據集CACID的構建豐富了古籍字符的種類和樣本數量,為模型訓練提供全面和多樣的數據支持;古籍篇章數據集CASID的合成則基于實際古籍文獻中的文字布局和排列方式,有助于模型在實際應用中適應復雜多變的古籍識別場景。
本文設計的古籍多任務融合識別模型在構建數據集上的實驗結果表明,模型的識別準確率從35.62%顯著提升至85.52%,驗證了涵蓋多字體多朝代的文字合成數據在實際應用中具有優異的識別能力和泛化能力。
本文通過對數據集中單字分布變化的分析,發現模型在識別罕見字符和復雜布局時的性能仍有待提升,這是本文后續需要重點改進的方向。
參考文獻
[1] 全國古籍整理出版規劃領導小組. 2021—2035年國家古籍工作規劃[R]. 2022.
[2] 王秋云.我國古籍數字化的研究現狀及發展趨勢分析[J].圖書館學研究,2021(24):9-14.
[3] 李國新.中國古籍資源數字化的進展與任務[J].大學圖書館學報,2002(1):21-26.
[4] 周迪,宋登漢.中文古籍數字化開發研究綜述[J].圖書情報知識,2010(6):40-49.
[5] 李春桃,張騫,徐昊,等.基于人工智能技術的古文字研究[J].吉林大學社會科學學報,2023,63(2):164-173.
[6] HE K M,ZHANG X Y,REN S Q,et al.Deep residual learning for image recognition[C]//2016 IEEE Conference on Computer Vision and Pattern Recognition,2016:770-778. DOI:10.1109/CVPR.2016.90.
[7] MA N N,ZHANG X Y,ZHENG H T,et al.ShuffleNet V2:practical guidelines for efficient CNN architecture design[C]//15th European Conference on Computer Vision(ECCV),Munich,Germany,September 8-14,2018. Proceedings,Part XIV,2018,11218:122-138.
[8] SHI B G,BAI X,YAO C.An end-to-end trainable neural network for image-based sequence recognition and its application to scene text recognition[J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2017,39(11):2298-2304.
[9] SCHUSTER M,PALIWAL K K.Bidirectional recurrent neural network[J].IEEE Transactions on Signal Processing,1997,45(11):2673-2681.
[10] MINJOON S,ANIRUDDHA K,ALI F,et al.Bidirectional attention flow for machine comprehension[C]//International Conference on Learning Representations,2016.
[11] CUI Y M,CHEN Z P,WEI S,et al.Attention-over-attention neural networks for reading comprehension[C]//55th Annual Meeting of the Association-for-Computational-Linguistics(ACL),2017. DOI:10.18653/v1/P17-1055.
[12] SCHROFF F,KALENICHENKO D,PHILBIN J.FaceNet:a unified embedding for face recognition and clustering[C]//IEEE Conference on Computer Vision and Pattern Recognition(CVPR),2015,Boston,MA,USA. DOI:10.1109/cvpr.2015.7298682.
Multi-task fusion recognition of Chinese multi-font ancient literature dataset
XUE Dejun, SHI Qinghui, BI Yanhong, LU Xiaofei, CHEN Jing, WANG Haishan, WU Chen
(Tongfang Knowledge Network Digital Publishing Technology Co., Ltd., Beijing 100192, China)
Abstract: To address the scarcity of large-scale, high-quality datasets for digitizing Chinese ancient literature, this paper introduces a novel two-tiered approach for dataset construction. Firstly, we establish a multi-font Chinese ancient character image dataset(CACID), containing 1.195 million images across 6 610 character categories. Secondly, we synthesize the Chinese ancient synthetic image dataset(CASID)which consists of 86 667 columns of ancient text images, based on authentic ancient literature content. This is currently the largest synthetic dataset for Chinese ancient literature reported. Then, we design a multi-task recognition model tailored for ancient literature and experimentally verify its effectiveness using our constructed datasets. The experimental results show a remarkable enhancement in recognition accuracy, with the model,s recognition rate soaring from 35.62% to 85.52%. This significant improvement verifies the excellent generalization capability of the synthetic data, encompassing diverse fonts and dynasties, in practical applications.
Keywords: ancient literature; training dataset; automatic construction; deep learning model; fusion modeling
(責任編輯:黎 婭)
收稿日期:2024-04-10;修回日期:2024-04-24
基金項目:國家重點研發計劃(2020YFC0833003);國家卓越行動計劃(WKZB1911BJM501173/02)資助
第一作者:薛德軍,博士,高級工程師,研究方向:自然語言處理、深度學習、大模型,E-mail:xuedejun@cnki.net
