基于深度強化學習的移動機器人路徑規劃研究
2024-11-05 00:00:00榮垂霆朱恒偉張賓劉聰
現代信息科技 2024年16期
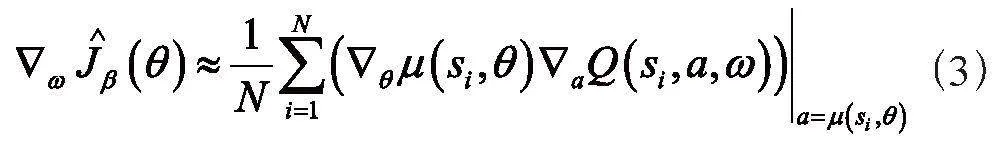




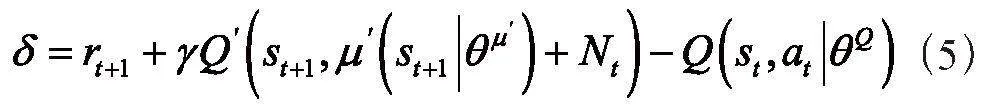
摘 要:鑒于采用深度強化學習算法進行移動機器人路徑規劃時存在收斂速度慢的問題,提出一種改進的算法。對經驗回放機制中樣本的學習潛力得分進行設計,根據學習潛力得分對樣本進行優先級評分,并根據評分進行采樣。將改進算法應用到機器人路徑規劃任務中,并進行獎勵函數、避障參數及路徑規劃實驗環境的設計。通過與對比算法進行實驗比較,驗證了改進算法的收斂速度及其在路徑規劃任務中的有效性。
關鍵詞:深度強化學習;路徑規劃;移動機器人
中圖分類號:TP242;TP18 文獻標識碼:A 文章編號:2096-4706(2024)16-0060-05
Research on Path Planning of Mobile Robots Based on Deep Reinforcement Learning
Abstract: Given the problem of slow convergence speed when using Deep Reinforcement Learning algorithms for mobile robot path planning, an improved algorithm is proposed. It designs the learning potential score of samples in the experience replay mechanism, prioritizes the samples based on the learning potential score, and samples them according to the score. It applies improved algorithms to robot path planning tasks and designs reward functions, obstacle avoidance parameters, and path planning experimental environments. Through experimental comparison with comparative algorithms, the convergence speed of the improved algorithm and its effectiveness in path planning tasks are verified.
Keywords: Deep Reinforcement Learning; path planning; mobile robot
0 引 言
移動機器人在醫療、交通、運輸等日常生活中得到了廣泛的運用,路徑規劃技術是其中非常重要的一環。在機器人路徑規劃任務中,精確避障以及快速到達目標點成為路徑規劃中至關重要的兩個任務。常用的路徑規劃方法主要是群智能算法[1-4],但傳統算法已無法滿足實際應用中快速適應未知環境的需求。近年來,隨著人工智能的快速發展,深度強化學習(DRL)逐漸成為解決未知環境下機器人路徑規劃的有效方法之一[5-7]。
本文針對DRL處理路徑規劃任務時存在收斂速度慢的問題,設計一種基于學習潛力的經驗回放機制的強化學習算法。它是基于學習潛力指標對每個經驗樣本的得分進行評定,選取TD誤差和立即獎勵作為評定依據,并為其分配了權重,設計出經驗數據重要性的公式,并依此進行樣本選擇,結合強化學習算法進行改進。將改進算法與路徑規劃任務相結合進行實驗,設計合理的獎勵函數、避障參數及路徑規劃環境模型,驗證改進算法的有效性。
1 深度確定性策略梯度算法
深度確定性策略梯度(Deep Deterministic Policy Gradient, DDPG)[8]是一種結合了演員-評論家(Actor-Critic)框架和經驗回放機制(Experience Replay, ER)[9]的強化學習算法,適于處理連續動作空間任務的問題。
DDPG采用ER來打破樣本間的時間相關性,同時重復利用過去的經驗。經驗回放機制工作時首先是進行數據存儲,在與環境交互的過程中將每一步的數據(st,at,rt,st+1)保存在經驗回放緩沖區中。接下來再進行隨機采樣,從緩沖區中隨機抽取小批量的樣本來更新網絡參數。
在DDPG算法中,需要對Critic網絡中的目標Q值進行更新,更新參數計算式如式(1)和式(2)所示:
根據最大化目標函數來更新策略網絡參數θ,如式(3)所示:
最后利用軟更新目標網絡,如式(4)所示:
2 改進的深度確定性策略梯度算法
DDPG算法的經驗回放機制使用隨機采樣方式采樣,這種采樣方式并未考慮樣本之間重要性的不同,會造成算法收斂速度低的問題。針對這一問題,本節在對ER中樣本的重要性進行處理時設計一種基于學習潛力的經驗回放機制(Learning Potential Experience Replay, LPER)。LPER是基于學習潛力指標對每個經驗樣本的得分進行評定,并結合DDPG算法進行改進,進而提高收斂速度。
2.1 基于學習潛力的經驗回放機制
學習潛力指標是一種用來衡量每個經驗樣本對當前策略學習的潛在貢獻程度的指標。學習潛力可以通過衡量經驗數據能在多大程度上改變當前策略或價值函數來評估。由于經驗數據的TD誤差和獎勵值對樣本重要性具有非常重要的意義,本小節選取TD誤差和獎勵值作為經驗樣本數據對當前策略學習貢獻的潛在影響因素:
1)TD誤差。TD誤差是強化學習中的一個重要概念,用來衡量當前估計的狀態值或動作值與實際獲得的獎勵之間的差異[10]。TD誤差表示當前狀態的值函數或動作值函數的估計值與下一個狀態的值函數或動作值函數的估計值之間的差異,加上實際獲得的獎勵。計算式如式(5)所示:
其中,rt+1表示智能體從環境中實際獲得的獎勵;γ表示折扣因子,用于衡量未來獎勵的重要性;Q表示當前狀態s的值函數或狀態-動作對(s,a)的動作值函數的估計值;st+1表示下一個狀態。
2)獎勵值。獎勵值表示智能體與環境交互時獲得的反饋,用來表明智能體在某個狀態下執行某個動作的好壞程度或者是對智能體行為的評價。獎勵值是強化學習算法中一個重要輸入,它直接影響智能體的學習和決策過程。
針對上述每個潛在的貢獻因素,本小節設計一個函數來量化其對學習潛力的貢獻值。由于TD誤差因素的重要性比獎勵值要高一些,在對線性函數的權重進行設計時,將TD誤差的權重設為0.7,將獎勵值的權重設為0.3。樣本優先級計算式如式(6)所示:
其中,p表示樣本的學習潛力得分;δ表示樣本的TD誤差;r表示樣本的獎勵值;b表示偏置項,它是一個很小的正數,偏置項的作用是使TD誤差和獎勵值均為零時,模型的學習潛力不為零,使得該樣本可以被采樣。
2.2 基于LPER的DDPG算法
本小節將2.1中改進的經驗回放機制與DDPG相結合,設計出基于學習潛力的經驗回放機制的深度確定性策略梯度算法(DDPG Algorithm Based on LPER, LPER-DDPG)。改進算法偽代碼如算法1所示:
算法1 基于學習潛力的經驗回放機制的深度確定性策略梯度算法
3 基于改進算法的移動機器人路徑規劃實驗
為了驗證改進算法的有效性,本文將改進算法與機器人路徑規劃任務相結合,通過改進算法與對比算法在機器人路徑規劃任務中的性能表現比較來驗證改進算法的優勢。在本節中,首先對獎勵函數和避障參數進行設計;其次對路徑規劃環境進行設計;最后對強化學習與機器人路徑規劃任務的實現進行設計。
3.1 獎勵函數設計
獎勵函數會直接影響路徑規劃策略的性能和效果。設計一個合適的獎勵函數需要考慮多個因素,包括路徑長度、避障效果、到達目標點的速度等。在本論文中,我們提出一種綜合考慮這些因素的獎勵函數設計方案,包括到達目標點獎勵、避障獎勵、路徑長度懲罰、速度獎勵四種因素:
1)到達目標點獎勵。當機器人成功到達目標點時,應該給予較大的正phgjwCVuNobFrjSd8C+DGQ==獎勵,以鼓勵機器人快速、高效地完成了路徑規劃任務。因此,當機器人處于目標點附近時,獎勵函數應該輸出一個較大的正值。
2)避障獎勵。為了使機器人能夠避開環境中的障礙物,我們引入了避障獎勵機制。當機器人與障礙物距離較遠或成功規避了障礙物時,應該給予一定的正獎勵;相反,當機器人與障礙物距離較近或發生碰撞時,應該給予較大的負獎勵,以懲罰機器人的不良行為。
3)路徑長度懲罰。考慮到路徑長度對于機器人移動的影響,我們引入了路徑長度懲罰項。即使機器人成功到達目標點,如果其路徑過長,應該給予一定的負獎勵,以鞭策機器人尋找更短的路徑。
4)速度獎勵。為了鼓勵機器人以較快的速度到達目標點,我們可以引入速度獎勵項。當機器人在規劃路徑上以較快的速度前進時,應該給予一定的正獎勵,以鼓勵機器人的快速移動。
綜合以上因素,本文設計如式(7)所示的獎勵函數:
其中,Rgoal(s′)表示到達目標點的獎勵函數,Robstacle(s,s′)表示避障獎勵函數,Rlength(s,s′)表示路徑長度懲罰函數,Rvelocity(s,a)表示速度獎勵函數。
3.2 避障參數設計
在基于深度強化學習的機器人路徑規劃中,避障參數的設計至關重要,它直接影響著機器人的避障效果。我們針對機器人與障礙物之間的實時距離L、最大距離Lmax和最小距離Lmin進行參數設計,其中Lmax設為0.5 m,Lmin設為0.1 m,以確保機器人能夠安全、高效地避開障礙物。
具體參數設計如下:
1)當機器人探測到的障礙物與機器人之間的距離L大于最大距離Lmax時,機器人可繼續沿原定路徑前進,因為障礙物遠離機器人,不會對其造成影響。
2)當機器人探測到的障礙物與機器人之間的距離L小于最小距離Lmin時,機器人應立即采取避障措施,停止前進或選擇繞過障礙物的路徑,以避免發生碰撞。
3)當機器人探測到的障礙物與機器人之間的距離L處于最大距離Lmax和最小距離Lmin之間時,機器人需要根據具體情況采取相應的避障策略。可考慮調整機器人的速度或方向,以安全繞過動態障礙物。
3.3 路徑規劃環境設計
本文所使用的路徑規劃仿真環境是使用ROS和Gazebo構建的。在仿真環境中建立機器人模型,并在構建好的路徑規劃環境中添加靜態障礙物。圖1為機器人路徑規劃仿真環境。
圖1為本實驗所使用的機器人路徑規劃仿真環境,目標位置為左下角方形區域;右上角的圓形物體為構建的機器人模型,同時也表示路徑規劃任務的起始點;周圍的墻壁和中間的六個木板代表路徑規劃環境中的障礙物。機器人從起始點出發,利用深度強化學習算法在環境中進行學習探索,對環境中的障礙物進行避障,通過不斷的試錯學習,最終規劃出一條從起始點到目標點的最優路徑。
3.4 仿真實現及結果分析
3.4.1 實驗參數設置
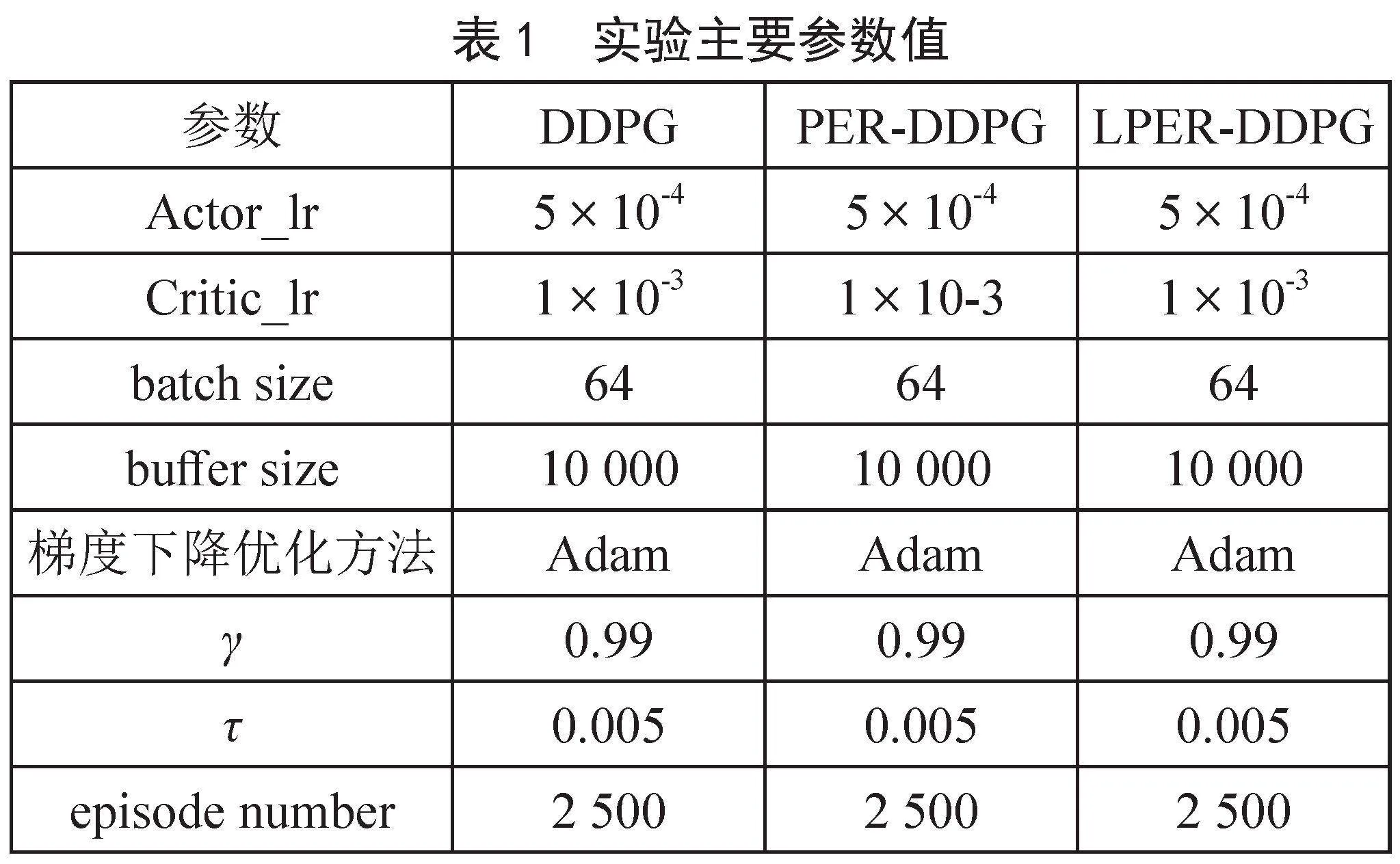
在進行機器人路徑規劃仿真實驗時,為了保證實驗的公平性,實驗用的對比算法和改進算法均采用相同的獎勵函數、避障參數等。表1為實驗時的主要參數。
3.4.2 實驗結果及分析
本實驗選取DDPG和PER-DDPG兩種算法作為比較算法。平均獎勵、回合數和最短路徑也是判定改進算法性能好壞的三種指標。以下是三種評價指標的評價原則:
1)達到穩定狀態時,系統平均獎勵值越高,表明該算法的性能更優。
2)達到穩定狀態時,所經歷的回合(episodes)數表示收斂時間,episodes越小表明該算法的收斂速度越快。
3)達到穩定狀態后,穩定的路線長度越短,表明其性能越好。
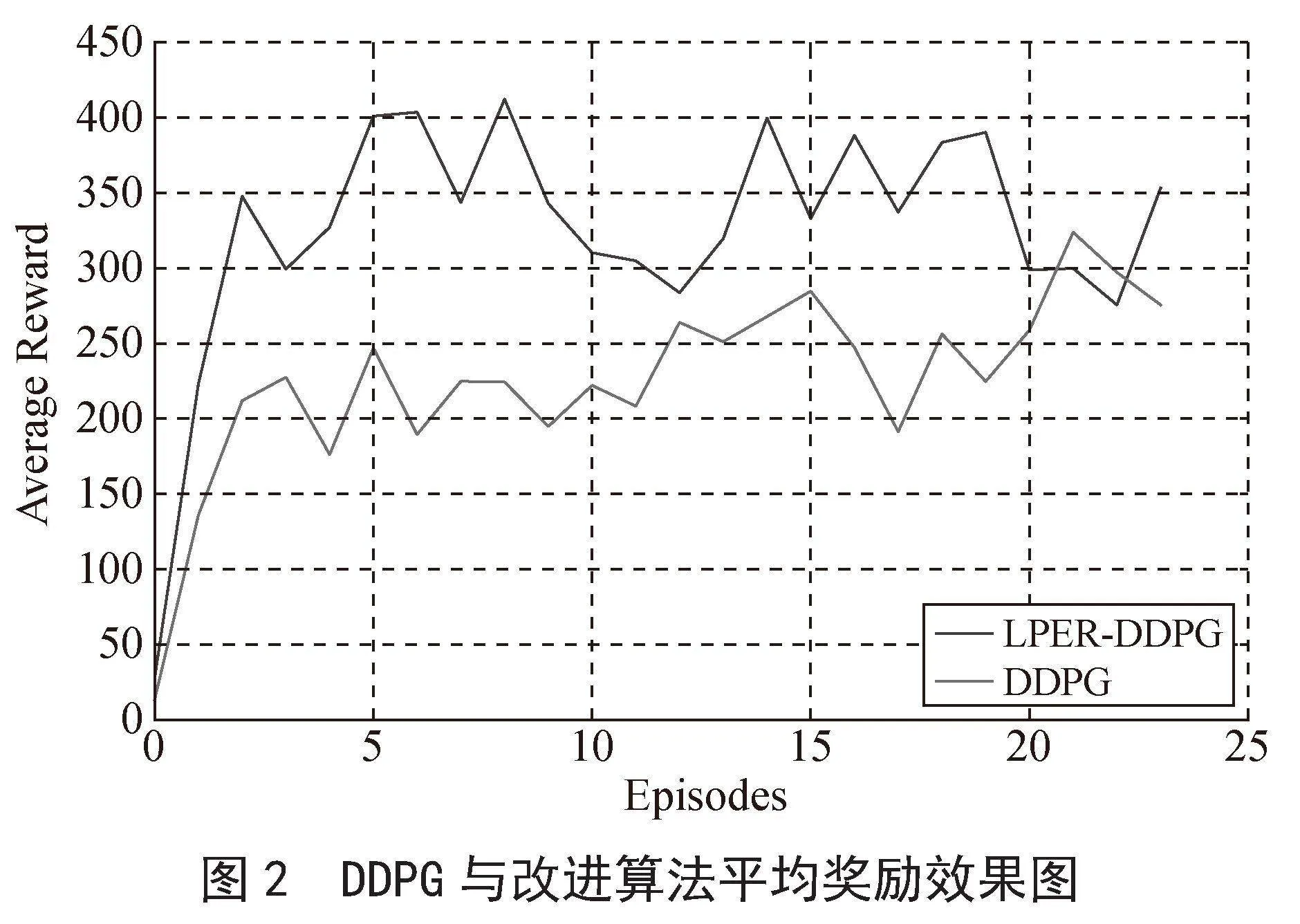
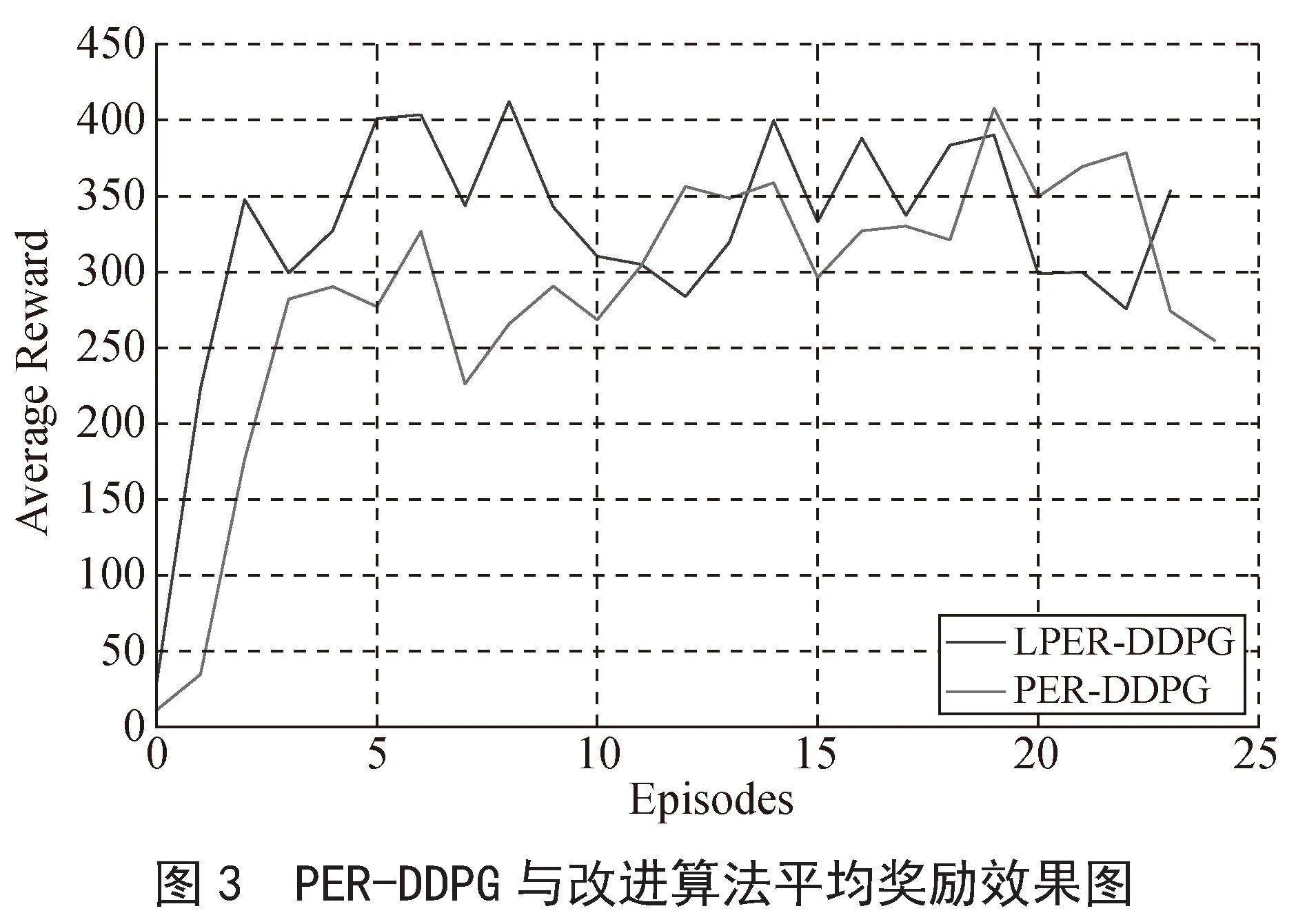
圖2和圖3為改進算法與機器人路徑規劃任務結合訓練的平均獎勵效果圖,本實驗設定的episodes數為2 500,為使本實驗的效果圖平滑,采用每100回合求其平均獎勵值,繪制在效果圖上面,并得出最終效果圖。
如圖2所示,改進算法在500回合處達到穩定獎勵值340,DDPG算法在1 200回合處達到穩定獎勵值240,兩者相比,改進算法收斂速度提高了58.3%,reward增加了100,提高了41.7%,表明改進算法的收斂速度較快。如圖3所示,PER-DDPG算法在1 100回合處達到穩定獎勵值300,改進算法的收斂時間及獎勵值和圖2一樣,兩者相比,改進算法的收斂速度提高了54.5%,獎勵值增加了40,提高了13.3%,收斂速度和獎勵值均有所提升。綜上分析可得,改進算法與兩種對比算法相比,其收斂速度均有所提升。
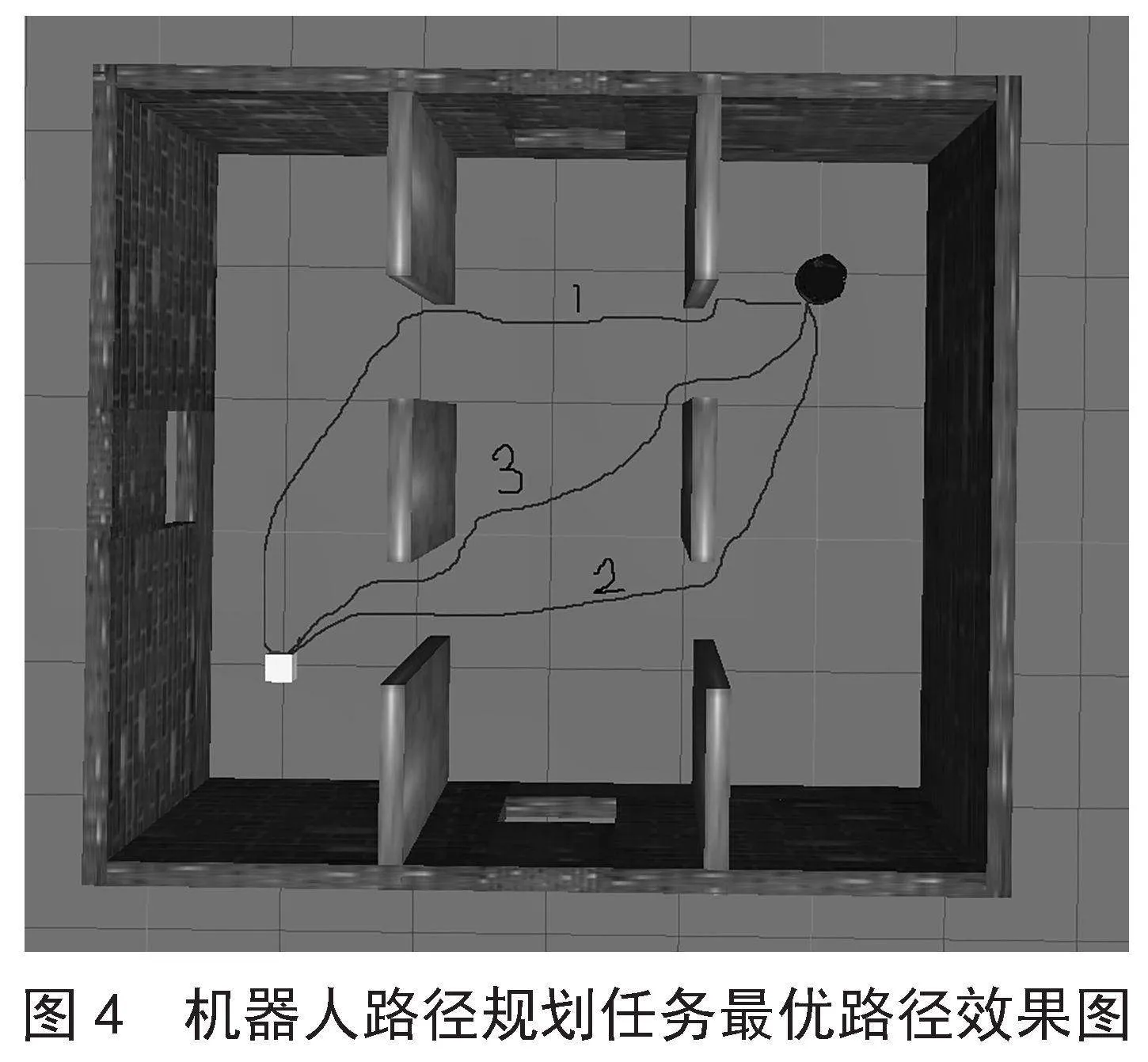
經實驗得到三種算法的最優路徑效果,如圖4所示。
在圖4中,1、2、3分別代表DDPG、PER-DDPG、LPER-DDPG經過機器人不斷學習探索后得出的最優路徑效果路線圖。由圖4可得出改進算法的路徑是最優的,性能優于其他兩種比較算法,由此可斷定算法的改進方式是行之有效的。
4 結 論
本文提出一種基于學習潛力的經驗回放機制的DDPG算法——LPER-DDPG。為了提高DDPG的收斂速度,首先提出一種全新的經驗回放機制采樣思想,利用TD誤差和獎勵值作為每個經驗數據的學習潛力指標的評分標準;其次,綜合考量兩個因素的重要性,分別為它們賦予權重,得出評分依據;再次,將所設計的基于學習潛力的經驗回放機制思想應用在DDPG中,形成改進算法LPER-DDPG;最后,為實現機器人路徑規劃任務而進行獎勵函數和避障參數設計,構建機器人路徑規劃ROS環境等,將改進算法與機器人路徑規劃任務相結合,驗證改進算法的有效性。實驗結果表明,改進算法的收斂速度有了明顯的提升。
參考文獻:
[1] 張國勝,李彩虹,張耀玉,等.基于改進人工勢場法的機器人局部路徑規劃 [J/OL].計算機工程,1-9[2024-02-15].https://doi.org/10.19678/j.issn.1000-3428.0068738.
[2] 劉建娟,劉忠璞,張會娟,等.基于模糊控制蟻群算法的移動機器人路徑規劃 [J].組合機床與自動化加工技術,2023(1):20-24.
[3] 馮舒,劉明.基于遺傳算法改進的AGV路徑規劃研究 [J].現代電子技術,2024,47(4):123-127.
[4] 郭錦春,秦可,王超,等.基于優化Hopfield神經網絡的海事飛機巡航路徑規劃 [J].航海,2023(5):28-31.
[5] 康振興.基于路徑規劃和深度強化學習的機器人避障導航研究 [J].計算機應用與軟件,2024,41(1):297-303.
[6] 李明,葉汪忠,燕潔華,等.基于深度強化學習的沙漠機器人路徑規劃 [J/OL].系統仿真學報,1-9[2024-02-15].https://doi.org/10.16182/j.issn1004731x.joss.23-1422.
[7] 張森,代強強.改進型深度確定性策略梯度的無人機路徑規劃 [J/OL].系統仿真學報,1-8[2024-02-15].https://doi.org/10.16182/j.issn1004731x.joss.23-1524.
[8] LILLICRAP T P,HUNT J J,PRITZEL A,et al. Continuous Control with Deep Reinforcement Learning [J/OL].arXiv:1509.02971v6 [cs.LG].[2024-02-19].https://arxiv.org/abs/1509.02971.
[9] MNIH V,KAVUKCUOGLU K,SILVER D,et al. Human-level Control Through Deep Reinforcement Learning [J].Nature,2015,518(7540):529-533.
[10] 張龍飛,馮旸赫,梁星星,等.基于時間差分誤差的離線強化學習采樣策略 [J].工程科學學報,2023,45(12):2118-2128.
