基于多分類器分級蒸餾的長尾視覺識別方法
2024-11-05 00:00:00鞏炫瑾
現代信息科技 2024年16期
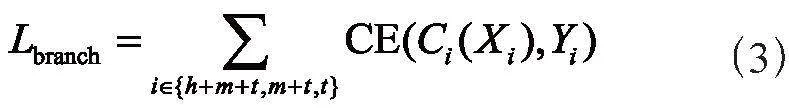
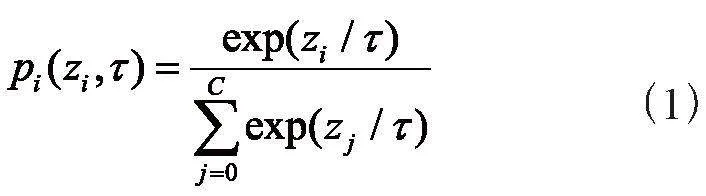
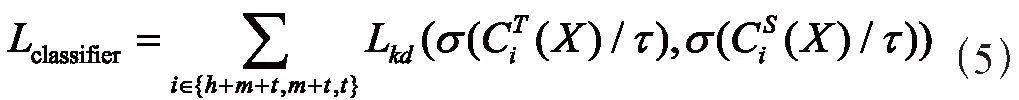

摘 要:為了提高模型在長尾視覺識別領域的性能,文章提出了一種多分類器分級蒸餾框架,該框架包括旋轉自監督預訓練和多分類器蒸餾。旋轉自監督預訓練通過預測圖像旋轉,平等地考慮每一張圖像,減少模型受到長尾標簽的影響。多分類器蒸餾通過三個專門優化的分類器將教師模型的知識一一對應蒸餾到學生模型。在開源的長尾圖像識別數據集上進行了充分實驗,并與現有方法進行了比較。實驗結果表明,所提出的方法在長尾圖像視覺識別方面取得了一定的提升。
關鍵詞:知識蒸餾;長尾分布;圖像識別;深度學習模型
中圖分類號:TP183;TP391.4 文獻標識碼:A 文章編號:2096-4706(2024)16-0049-05
Long-tailed Visual Recognition Method Based on Multi-classifier Graded Distillation
Abstract: In order to enhance model performance in the long-tailed visual recognition domain, this paper proposes a multi-classifier graded distillation framework. The framework comprises rotation self-supervised pre-training and multi-classifier distillation. Rotation self-supervised pre-training treats each image equally by predicting image rotations, and mitigates the impact of long-tailed labels on the model. Multi-classifier systematically distills the knowledge from the teacher model to the student model through three specifically optimized classifiers. Extensive experiment results are conducted on open-source long-tailed image recognition datasets, and comparisons are made with existing methods. The experimental results demonstrate that the proposed method achieves notable improvements in long-tailed image visual recognition.
Keywords: knowledge distillation; long-tailed distribution; image recognition; Deep Learning model
0 引 言
不平衡數據在現實世界中是普遍存在的,大規模的數據集往往以一種長尾分布的形式呈現[1]。尤其在安全或健康相關方面的應用,如自動駕駛和醫療診斷[2],數據本質上是嚴重失衡的。盡管現代深度學習和機器學習技術已經在不同的任務集上取得了令人印象深刻的成果,但大多數模型在面對非常罕見或長尾樣本的不均勻數據分布時仍會遇到困難。如何從這種不平衡數據集中獲取到有用信息已然成為當下研究的熱點。
處理不平衡數據的一個經典方法是數據重采樣方法[3-4],這樣做的目的是為了讓類別分布更加平衡,該方法包括對多數類別的降采樣和對少數類別的過采樣,但是重采樣技術在深度學習中會產生一系列的問題,例如過采樣會導致模型的過擬合,而降采樣會限制神經網絡的泛化能力。另一種常用的方法是重加權方法[5-6],該種方法是作用于損失函數上,對不同類別或不同樣本對應的分類損失項賦予不同的權重。然而,這些方法都犧牲了多數類的準確性來補償少數類。
最近的研究表明,將長尾分類解耦為兩個階段:表征學習和分類器學習,是一種良好的處理數據不平衡的方法[7-8]。Kang等人[9]通過自然(實例平衡)采樣學習高質量的表示,并通過類平衡采樣調整分類器實現強大的分類性能。Zhou等人[10]提出了一個雙邊分支網絡,其中一個分支使用實例平衡采樣訓練,另一個分支使用類平衡采樣,得出了類似的結論。解耦學習思想被廣泛采用,Cao等人[11]提出了不同的分類器調整方法,通過調整Logit鼓勵增大少數類與多數類之間的相對差距。通過向輸出層添加額外的可學習層來修改原始Logit。然而上述方法沒有考慮到少數類別的未被充分代表的特征。
總之,現有的方法要么缺乏一種能學習到良好表征的機制,要么過于復雜,缺乏很好的泛化性。針對上述方法存在的問題,本文提出一種基于多分類器的知識蒸餾方法,首先,考慮到直接在不平衡數據集中以監督學習的方式訓練一個網絡會產生較差的性能,其原因是不平衡數據集的標簽信息會帶來“偏見”,這種偏見使模型不能學習到很好的表征,于是我們在進行知識蒸餾之前先對學生網絡進行自監督的預訓練,目的是使學生網絡在不平衡數據集中學習到更好的初始化,一旦網絡經過自我監督預訓練產生了良好的初始化,網絡就可以從訓練前的任務中受益,并最終學習到更好的表示。其次,通過知識蒸餾技術,使用分級蒸餾損失將教師網絡中所包含頭部、中部、尾部類的知識盡可能多地傳遞給學生網絡。我們在幾個長尾基準數據集上進行了大量實驗,證明了所提出的方法是長尾學習場景中有效的學習方法。
1 相關概念
1.1 知識蒸餾
知識蒸餾(Knowledge Distillation, KD)是一種將知識從大的教師模型轉移到小的學生模型的模型壓縮技術,自誕生以來就受到了廣泛關注。Hinton等人[12]提出將知識從教師模型的預測概率分布中提取到學生模型中,稱為基于Logit的知識蒸餾。知識蒸餾引入軟標簽,即帶有參數τ的Softmax函數,以此來軟化概率分布,使概率分布攜帶更多的有用信息,如式(1)所示:
其中,pi為模型第i類的概率分布,zi為模型第i類的輸出結果,C為類別數,τ為溫度參數,用于調節概率分布的平緩程度,τ越大,概率分布就越平均。于是,基于Logit的知識蒸餾通過對齊學生模型與教師模型的概率分布以此來將教師模型的知識傳輸給學生模型,形式如式(2)所示:
其中,ps和pt分別為學生模型和教師模型帶溫度參數τ的經過Softmax函數的概率分布,KL為Kullback-Leible散度損失。
1.2 自監督學習
自監督學習[13]近年來取得了顯著進展,尤其是在圖像視覺方面。自監督方法設計各種代理任務(proxy tasks)來輔助神經網絡學習,這些任務可以是預測圖像上下文或旋轉、圖像著色、解決圖像拼圖游戲、最大化全局和局部特征的互信息以及實例識別。最近的研究工作表明[14],經過自監督預訓練初試化的模型可以產生更好的表示,這一研究啟發了我們,我們將預測圖片旋轉任務作用于學生網絡,使其學習到一種良好的初始化方法,以至于在知識蒸餾階段將教師網絡的知識轉移給學生網絡時學生能更好地吸收和歸納。
2 相關方法
2.1 預定義
我們有n個圖像X={x1,…,xn}。每個圖像根據Y進行標記Y={y1,…,yn},其中yi∈C為第C類的標簽。在本文中,訓練集遵循長尾分布。盡管訓練集不平衡,但目標是準確識別所有類,因此我們使用平衡的測試集來評估分類結果。
2.2 訓練教師模型
我們觀察到現有的通過知識蒸餾解決長尾分布問題的方法,大多都專注于蒸餾方法的改進,而忽略了對教師模型進行詳細的分析,現有的教師模型僅僅使用普通交叉熵損失訓練網絡,這使得模型的決策邊界嚴重偏向頭部類,影響知識蒸餾的效果,基于這一問題我們提出一種多分類器的教師網絡結構,通過額外的分類器來增強尾部類的分類結果,具體而言,其中一個主分類器Ch+m+t學習識別頭部類+中部類+尾部類的圖片,另外兩個分類器Cm+t和Ct分別識別中部類+尾部類和尾部類的圖片,最終的分類結果為這三個分類器的結果之和,損失函數如下:
其中(X,Y)為一個批次中的圖像和標簽。(Xh+m+t,Yh+m+t)與由所有類圖像組成的(X,Y)相同。(Xm+t,Ym+t)是(X,Y)的子集,僅包含中部和尾部類的圖像。(Xt,Yt)是(X,Y)的子集,僅包含屬于尾部類的圖像。CE為交叉熵損失。通過Lbranch使三個分類器分工明確,分別針對頭+中+尾部,中+尾部,尾部進行專門優化學習。
2.3 知識蒸餾過程
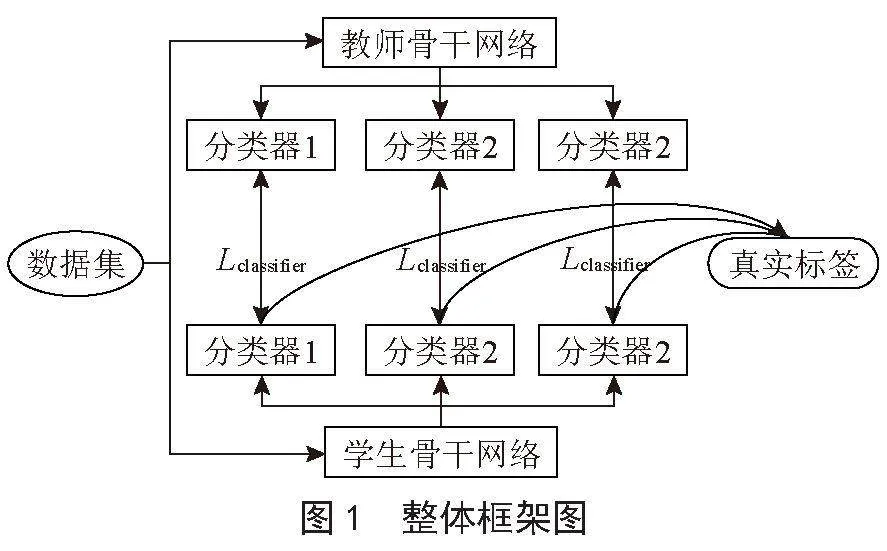
前段已經了解了教師網絡的訓練策略,本段我們將介紹所提知識蒸餾方法的蒸餾過程,整體框架圖如圖1所示,我們將在本節具體介紹其中的內容。
2.3.1 旋轉自監督預訓練
在此階段,我們在原始長尾數據分布下預訓練學生網絡。分類任務為判斷圖像旋轉角度,對比傳統N分類任務,雖然其提供了豐富的語義信息,但它也受到長尾標簽的影響。尾部類的樣本可能會被數據豐富的頭部類所淹沒,從而導致表征不足的問題。因此,我們構建了平衡的自監督分類任務,要求模型預測圖像旋轉,旋轉角度為{0°,90°,180°,270°},將傳統N類分類任務轉換為四分類任務,它們在不受標簽影響的情況下可以平等地考慮每個圖像。
2.3.2 多分類器蒸餾
知識蒸餾首先被引入用于通過軟標簽將知識從高性能網絡(教師模型)轉移到小型網絡(學生模型)。我們的方法受到知識蒸餾的啟發,但與之有本質區別。在我們的方法中,學生模型與教師模型大小是相同的。此外,針對長尾識別,軟標簽中的暗知識可以通過將知識從頭部類轉移到尾部類從而幫助尾部類更好地進行識別。由于類樣本分布不均勻,我們設計了一種基于多分類器的分級蒸餾方法,將教師網絡的三個分類器中包含頭部+中部+尾部,中部+尾部,尾部的知識一一對應蒸餾到學生網絡中,分級蒸餾損失函數Lclassifier如下所示:
最終學生模型的損失函數為:
其中α為超參數用于平衡兩個損失項。
3 實驗分析
我們在兩個開源數據集進行了一系列實驗來證明所提方法的有效性。我們首先介紹了數據集和實驗設置,然后討論和驗證所提方法和現有方法的實驗結果,最后對所提方法進行消融實驗。
3.1 數據集和實驗設置
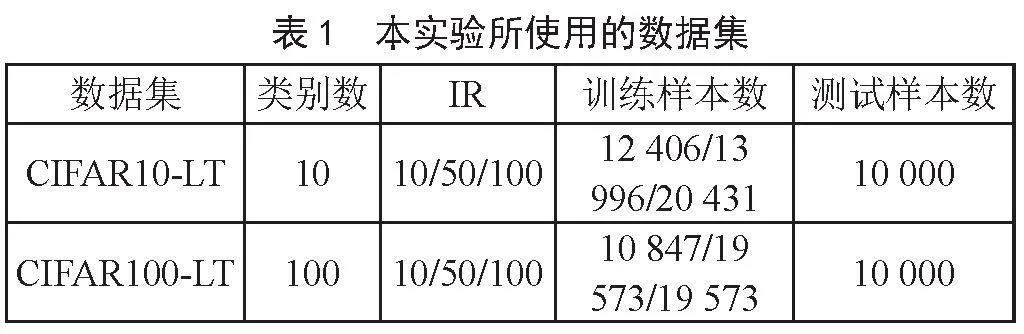
實驗所用硬件環境為11th Gen Intel Core i5 2.40 GHz,16 GB內存,使用Python編程語言實現,操作系統平臺為Windows 10。在實驗中,將使用兩個基準數據集,即CIFAR10-LT和 CIFAR100-LT,來驗證本文所提方法的有效性,數據集的詳細信息如表1所示。
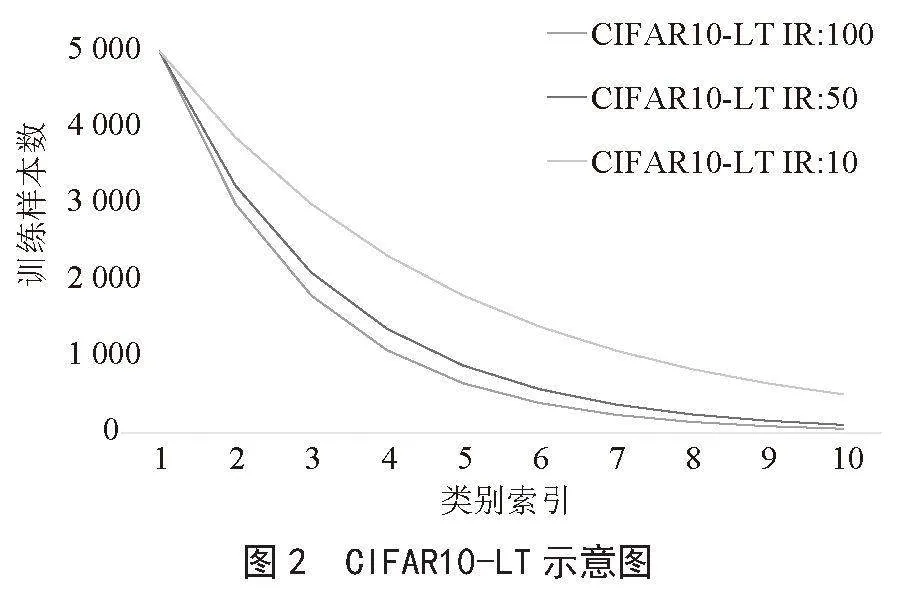
原始CIFAR10和CIFAR100都包含6萬張大小為32×32彩色圖片,其中5萬張用于訓練,其余用于驗證。前者有10個類,每個類別有5 000張訓練樣本和1 000張測試樣本,后者有100個類,每個類別有500張訓練樣本和100張測試樣本。CIFAR10-LT和CIFAR100-LT分別為其對應長尾版本。本文和文獻[8]的構造方法一致,訓練集中每個類別的數量按照Nc=Nmax×(IR)-c/C進行配置,其中,C為數據集中類別總數,Nc為第c個類別所包含的樣本數,Nmax為原始數據集中樣本數量最多的類別所包含的樣本數,在CIFAR10數據集中Nmax為5 000,在CIFAR100數據集中Nmax為500,IR為不平衡比率。IR可用于描述數據集的不平衡程度,定義為訓練集中樣本數最多的類所包含的樣本數量與樣本數最少的類所包含樣本數量之間的比值。在本文中對不同方法基于三種不平衡比率(IR)進行驗證,IR的取值分別為100、50和10,測試集數量不變。不同IR下的數據訓練集樣本分布如圖2和圖3所示。
對于CIFAR10-LT和CIFAR100-LT數據集,我們對圖像進行預處理操作,具體操作是從原始圖像或在水平翻轉中隨機裁剪一個32×32面片,每側填充4個像素,并將像素歸一化值為[0,1]。我們采用ResNet-32作為所有實驗的骨干網絡。采用動量為0.9的SGD優化器。迭代次數為200Epoch。初始學習率設為0.1,前五個Epoch通過線性預熱進行訓練。學習率在160和180個Epoch分別衰減0.1。批次大小為128用于所有實驗,動量衰減率為0.000 5。采用廣泛使用的Top-1分類準確率作為評估指標,所報告的準確率為模型在相同設置情形下運行三次取平均的結果。
3.2 實驗結果
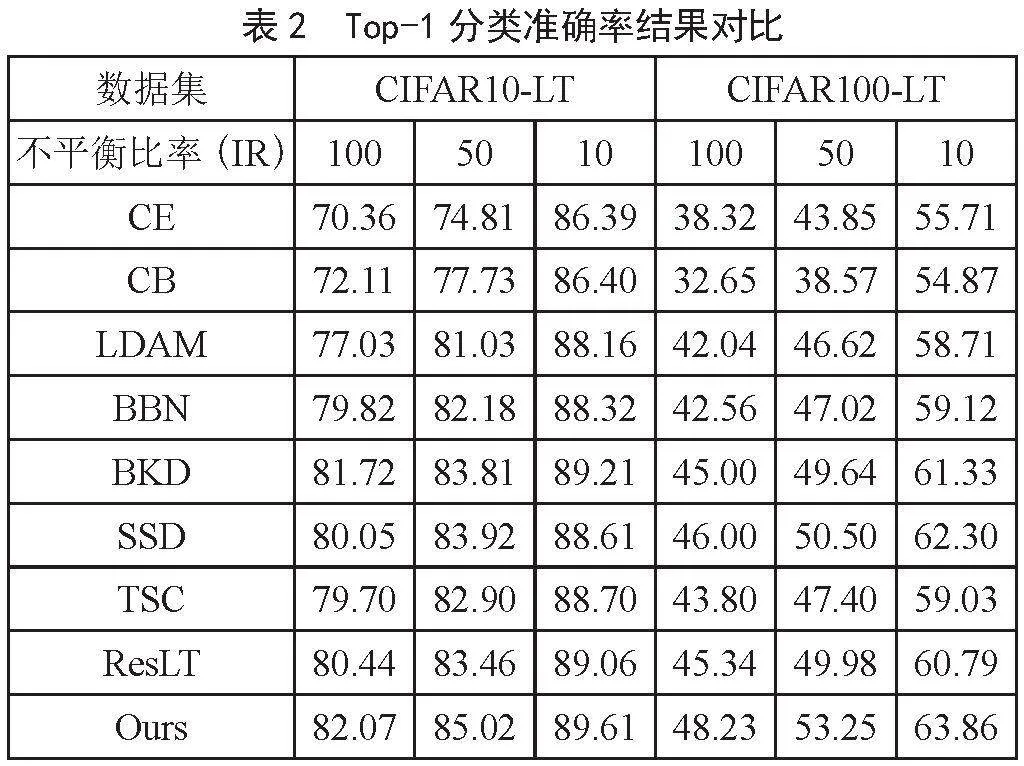
為了驗證本文所提方法的有效性,本文與長尾視覺識別相關的7種主流方法進行對比:CE、CB、LDAM、BBN、BKD、SSD、ResLT。結果如表2所示。
表2中,CE是使用普通交叉熵損失訓練長尾分布數據集,我們將其作為基線,本文所提方法相對CE在數據集CIFAR10-LT和CIFAR100-LT上的分類準確率分別提升了11.71%、10.21%、3.22%、9.98%,9.4%,8.15%。其中BKD、DiVE、SSD與我們一樣使用了知識蒸餾技術訓練模型,可以看出本文所提方法相對他們在數據集CIFAR10-LT、CIFAR100-LT上的分類準確率有較大的提升。
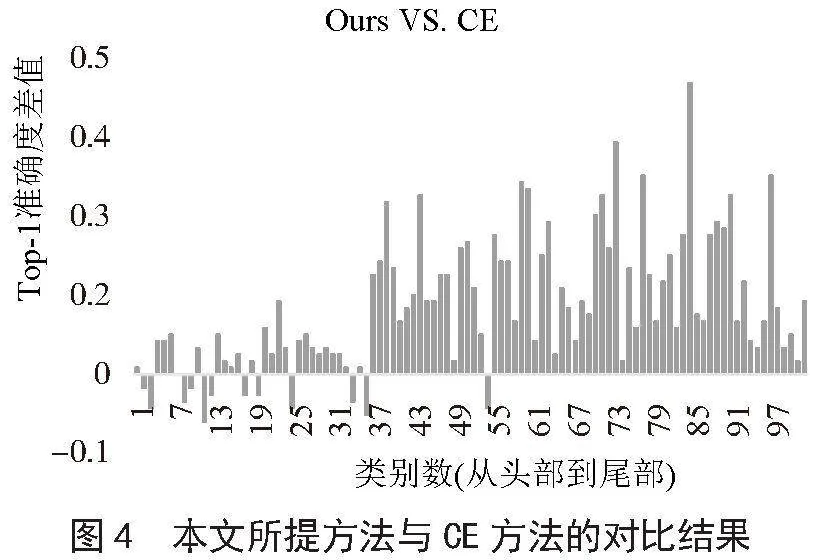
從圖4中可以看出,所提方法是對頭部類、中部類和尾部類進行全面的改進,對比與CE方法,所提方法可以在不損失頭部類準確度的情況下大幅度提升中部類和尾部類的準確度。
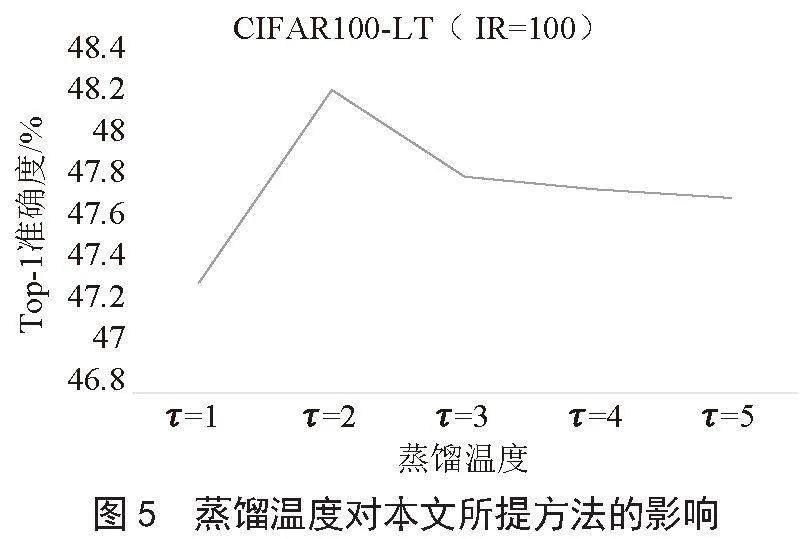
圖5研究了不同的溫度參數τ對于學生網絡性能的影響,可以看出當溫度很高時(τ =5)會導致學生性能的下降,原因是因為高溫會增加非正確類的Logit從而影響學生網絡預測的正確性。
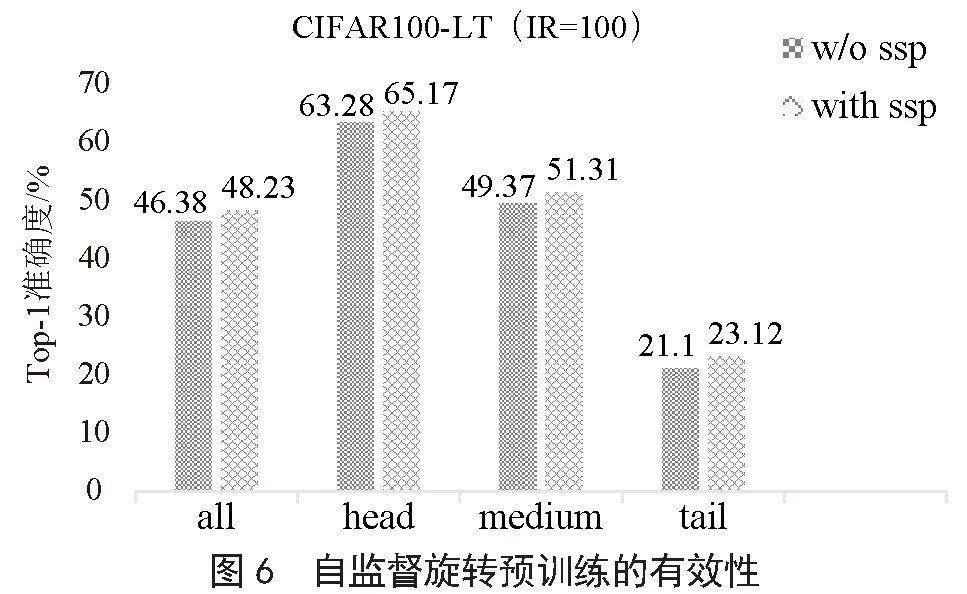
我們還研究了自監督預訓練學生模型的有效性。在不平衡比率IR為100的CIFAR100-LT數據集上評估結果,具體而言,根據訓練樣本數將測試集劃分為3個部分:head(訓練樣本數≥100)、medium(20<訓練樣本數<100)和tail(訓練樣本數≤20)用于研究自監督預訓練方法對不同部分的改進效果。結果如圖6所示。
從圖6中可以看出使用自監督旋轉預訓練(ssp)可以使學生模型整體性能提升1.85%,并且對于不同部分均有明顯的提升,如對于head部分有1.89%的改進,medium部分有1.94%的改進,tail部分有2.02%的改進,說明自監督預訓練能幫助學生網絡更好的識別不同類的語義信息,并且有助于學生模型更好地吸收教師傳遞過來的知識2m2ApfMsPV/2ot1T+zRTuQ==。
4 結 論
本文針對長尾視覺識別中尾部類不能被很好識別的問題,提出了一種基于分類器分級蒸餾的長尾視覺識別方法。首先提出一種基于多分類器的教師模型訓練方法,可以有效增強教師的教學能力,然后采用了自監督技術對網絡進行預訓練,最后通過分級知識蒸餾將教師模型中有用的信息傳遞給學生模型,實驗結果表明,本文所提方法可以有效地提高長尾視覺識別任務的準確性。
參考文獻:
[1] HE H B,GARCIA E A. Learning from Imbalanced Data [J].IEEE Transactions on Knowledge & Data Engineering,2009,21(9):1263-1284.
[2] KONG S,RAMANAN D. OpenGAN: Open-Set Recognition via Open Data Generation [C]//2021 IEEE/CVF International Conference on Computer Vision.Montreal:IEEE,2021:793-802.
[3] HAN H,WANG W Y,MAO B H. Borderline-SMOTE: A New Over-Sampling Method in Imbalanced Data Sets Learning [C]//International Conference on Intelligent Computing,ICIC 2005.Hefei:Springer,2005:878-887.
[4] DRUMNOND C,HOLTE R C. Class Imbalance and Cost Sensitivity: Why Under-sampling beats OverSampling [EB/OL].[2024-01-08].https://www.docin.com/p-871518697.html.
[5] CHU P,BIAN X,LIU S P,et al. Feature Space Augmentation for Long-Tailed Data [C]//16th European Conference on Computer Vision.Glasgow:Springer,2020:694-710.
[6] SHEN L,LIN Z C,HUANG Q M. Relay backpropagation for effective learning of deep convolutional neural networks [C]//14th European conference on computer vision.Amsterdam:Springer,2016:467-482.
[7] KHAN S H,HAYAT M,BENNAMOUN M,et al. Cost-Sensitive Learning of Deep Feature Representations From Imbalanced Data [J].IEEE Transactions on Neural Networks and Learning Systems,2018,29(8):3573-3587.
[8] WANG Y X,RAMANAN D,HEBERT M. Learning to Model the Tail [C]//NIPS'17:Proceedings of the 31st International Conference on Neural Information Processing Systems,2017:7032-7042.
[9] KANG B Y,XIE S N,ROHRBACH M,et al. Decoupling Representation and Classifier for Long-Tailed Recognition [J/OL].arXiv:1910.09217[cs.CV].[2024-01-08].https://arxiv.org/abs/1910.09217?context=cs.CV.
[10] ZHOU B Y,CUI Q,WEI X S,et al. Bbn: Bilateral-Branch Network with Cumulative Learning for Long-tailed Visual Recognition [C]//2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition.Seattle:IEEE,2020:9716-9725.
[11] CAO K D,WEI C,GAIDON A,et al. Learning Imbalanced Datasets with Label-Distribution-Aware Margin Loss [J/OL].arXiv:1906.07413 [cs.LG].[2024-01-09].https://arxiv.org/abs/1906.07413.
[12] HINTON G,VINYALS O,DEAN J. Distilling the Knowledge in a Neural Network [J/OL].arXiv:1503.02531[stat.ML].[2024-01-09].https://arxiv.org/abs/1503.02531.
[13] GIDARIS S,SINGH P,KOMODAKIS N. Unsupervised Representation Learning by Predicting Image Rotations [J/OL].arXiv:1803.07728 [cs.CV].[2024-01-09].https://arxiv.org/abs/1803.07728v1.
[14] YANG Y Z,XU Z. Rethinking the Value of Labels for Improving Class-Imbalanced Learning [J/OL].arXiv:2006.07529[cs.LG].[2024-01-09].https://arxiv.org/abs/2006.07529?amp=1.
