多模型融合投票預標注算法研究
2024-11-05 00:00:00吉星陳喆陳飛揚楊文聽樊楨珍許丹
現代信息科技 2024年16期

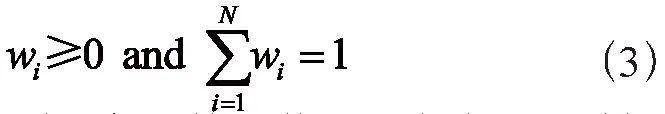
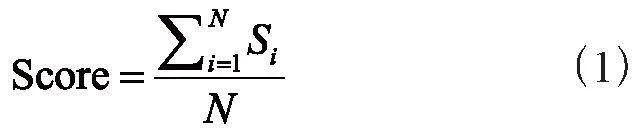
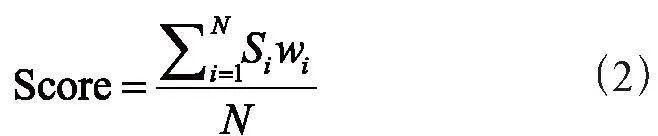

摘 要:針對標注內容煩瑣、耗時等問題,提出一種多模型融合投票預標注方法。在預標注過程中,將Cascade_RCNN、RetinaNet、CondLaneNet三個模型的檢測結果進行融合,然后將各個模型生成的坐標結果進行提取、判斷、匹配、參數平均、排序等處理,得到最終的預標注結果。在公開數據集以及自建數據集上進行多次試驗的結果表明,算法能夠提高預標注精度,減少標注過程中人工標注工作量,具有較好的效果,驗證了該方法的有效性。
關鍵詞:深度學習;目標檢測;車道線檢測;預標注;模型融合
中圖分類號:TP301.6 文獻標識碼:A 文章編號:2096-4706(2024)16-0034-05
Research on Pre-labelling Algorithm for Multi-model Fusion Voting
Abstract: Aiming at the two problems of cumbersome and time-consuming annotation content, a pre-labelling algorithm for multi-model fusion voting is proposed. In the pre-labelling process, the detection results of the three models of Cascade_RCNN, RetinaNet and CondLaneNet are fused, and then the coordinate results generated by each model are processed by extracting, judging, matching, averaging of parameters, sorting and so on, to obtain the final pre-labelling results. The results of multiple tests on the public datasets and the self-constructed datasets show that the algorithm is able to improve the accuracy of pre-labelling and reduce the manual labelling workload in the process of labelling, which has a better effect and verifies the effectiveness of the method.
Keywords: Deep Learning; target detection; laneline detection; pre-labelling; model fusion
0 引 言
隨著人工智能不斷發展,作為人工智能的上游基礎行業,數據標注也隨之完成了產業升級。用人工智能實現對數據標注的反哺已經成為行業發展的重要驅動力。其中,預標注技術在其中發揮著關鍵作用。
預標注是指利用算法模型進行標注,即標注為算法提供原料,算法反哺數據標注。早期模型是在已標注好的數據集上訓練,當模型達到一定準確度后,便可以讓其開始對原始數據自動標注。但目前在數據集方面大多仍舊采用手動逐個標注的方式,如目標檢測在車輛的應用中盲區監測預警、車道線預警等功能依賴大量數據集,以供模型訓練;但由于路面的場景復雜,目標檢測類別繁多,導致人工標注效率較低,耗時耗人。
預識別技術是一種基于人工智能算法的訓練模式。在預識別技術中,通過對目標檢測模型進行預先訓練,訓練完成的模型即可對原始圖像進行預識別,從而有效減少了標注工作量、提升了標注作業效率。
與普通圖像預識別相比,PC端預識別算法對檢測精度的要求比檢測速度要高,故需要進一步優化精度能力。為進一步提升數據預標注功能的精度,本文開發設計了一種多模型融合投票預標注算法。該算法將原有的圖像預識別功能進一步優化,將訓練得到的融合模型封裝為Docker鏡像,然后利用融合模型對不同樣本進行訓練,再進行測試。測試結果表明:該預識別算法在樣本較少的情況下仍然具有較高的準確率,具有較好的穩定性和可靠性。測試準確率達到了90%以上。
1 相關工作
1.1 單階段目標檢測
近幾年,目標檢測領域中被廣泛使用的算法主要分為兩類:單階段法和兩階段法。兩階段法也叫“兩次迭代”。其步驟包括:第一步,輸入圖像首先經過一個候選框生成網各。在該過程中,我們將候選框與它對應的目標關聯起來,并通過學習對其進行分類。第二步,經過一個分類網絡對候選框的內容進行分類。在單階段算法中,第一步與第二步是并行的,并不會在一次迭代中完成。因此,在第一步和第二步之間,存在著一個中間的“等待”期。在這個等待期內,輸入圖像只經過一個網絡。在這期間,生成的結果同時包含了位置和類別信息。
而單階段法則將這兩個步驟進行了并行處理。與兩階段法相比,單階段法精度更高,但是計算量更大,運算量也更大,因此它的運行速度較慢。
Redmon等[1]提出了YOLO單階段目標檢測算法,其直接完成從特征到分類、回歸的預測,分類和回歸使用同一個全連接層實現。Liu等[2]提出了SSD目標檢測網絡,SSD整個網絡是全卷積網絡,即經過VGG16進行特征提取后,提取38×38、19×19、10×10、5×5、3×3、1×1共6層不同尺度特征用于分類和回歸。
RetinaNet是一種用于目標檢測的深度學習網絡,Lin等[3]提出單階段目標檢測相比多階段目標檢測算法性能較差的原因在于正負樣本的篩選不均衡。多階段目標檢測過程中,通過選擇性搜索(Selective Search)、RPN等方式可以過濾掉大量的背景框,然后通過篩選正負樣本(如1:3)的方式進行訓練。但是單階段的目標檢測算法無法過濾這些背景框,導致正負樣本嚴重不均衡。因此提出Focal loss在訓練的時候自適應調整損失權重,使得模型關注難樣本的訓練,同時提出RetinaNet目標檢測框架。
1.2 兩階段目標檢測
在兩階段目標檢測模型中,Girshick等[4]提出了RCNN目標檢測算法,其思想是使用selective search提取2 000個左右的預選框,然后resize到統一的尺度(因為后面接FC分類)進行CNN特征提取,最后用FC進行分類。在2015年,Girshick[5]提出了Fast_RCNN算法,Fast_RCNN的RoI仍然是通過Selective Search的方式進行搜索,其速度較慢。Faster_RCNN在Fast_RCNN的基礎上提出RPN(Region Proposal Network)自動生成RoI,極大地提高了預選框生成的效率。
Cascade_RCNN是由Cai等[6]在2017年提出的基于Faster_RCNN進行改進的版本。Cascade_RCNN提出級聯多個檢測頭來解決這個問題,整體的流程為:級聯多個檢測頭,每個檢測頭的IoU呈現遞增的情況,比如0.5、0.6、0.7,并不是采用相同的閾值(區別于Iterative BBox)。低級檢測頭采用低IoU閾值可以提高召回率,避免目標丟失;后續的高級檢測頭在前一階段的基礎之上提高閾值可以提高檢測精度。
1.3 車道線檢測
在車道線檢測模型中,存在多種檢測方法與模型,例如傳統圖像方法,傳統圖像方法通過邊緣檢測濾波等方式分割出車道線區域,然后結合霍夫變換、RANSAC等算法進行車道線檢測。這類算法需要人工手動去調濾波算子,根據算法所針對的街道場景特點手動調節參數曲線,工作量大且魯棒性較差,當行車環境出現明顯變化時,車道線的檢測效果不佳。
基于深度學習的方法中基于檢測的方法通常采用自頂向下的方法來預測車道線,這類方法利用車道線在駕駛視角自近處向遠處延伸的先驗知識,構建車道線實例。基于Anchor的方法設計線型Anchor,并對采樣點與預定義Anchor的偏移量進行回歸。應用非極大值抑制(NMS)選擇置信度最高的車道線。Li等[7]提出了LineCNN,使用從圖像邊界以特定方向發出的直線射線作為一組Anchor;Tabelini等[8]提出了LaneATT,一種基于線性型Anchor的池化方法結合注意力機制來獲取更多的全局信息。Liu[9]等人提出了一種自上而下的車道線檢測框架CondLaneNet,它首先檢測車道實例,然后動態預測每個實例的線形。
基于關鍵點和參數曲線的方法中,Qu[10]等人提出了對局部模式進行建模,并以自下而上的方式實現對全局結構的預測FOLOLane。Tabelini[11]等人提出了通過多項式曲線回歸,輸出表示圖像中每個車道線的多項式。并維持高效性的PolyLaneNet。
1.4 本文工作
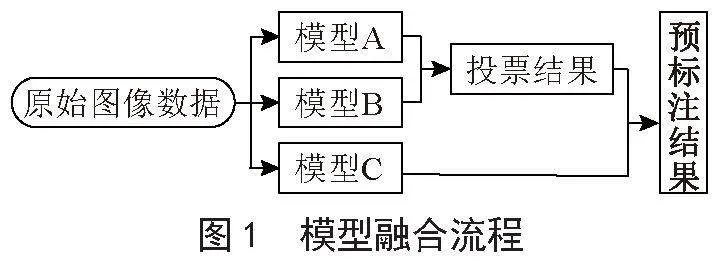
本文擬采用一個單階段目標檢測模型RetinaNet,一個兩階段目標檢測模型Cascade_RCNN,以及一個車道線檢測模型CondLaneNet進行融合,總體步驟為將單階段目標檢測模型與兩階段目標檢測模型(模型A、B)的預測結果進行投票,再加入模型C的車道線檢測模型的結果,并確保融合模型的精度較單個模型預測精度提高,生成最終的預標注結果并進行測試。實現了較高精度的預標注結果,模型融合流程如圖1所示。
2 算法設計實現
2.1 模型網絡框架
2.1.1 單階段目標檢測模型RetinaNet
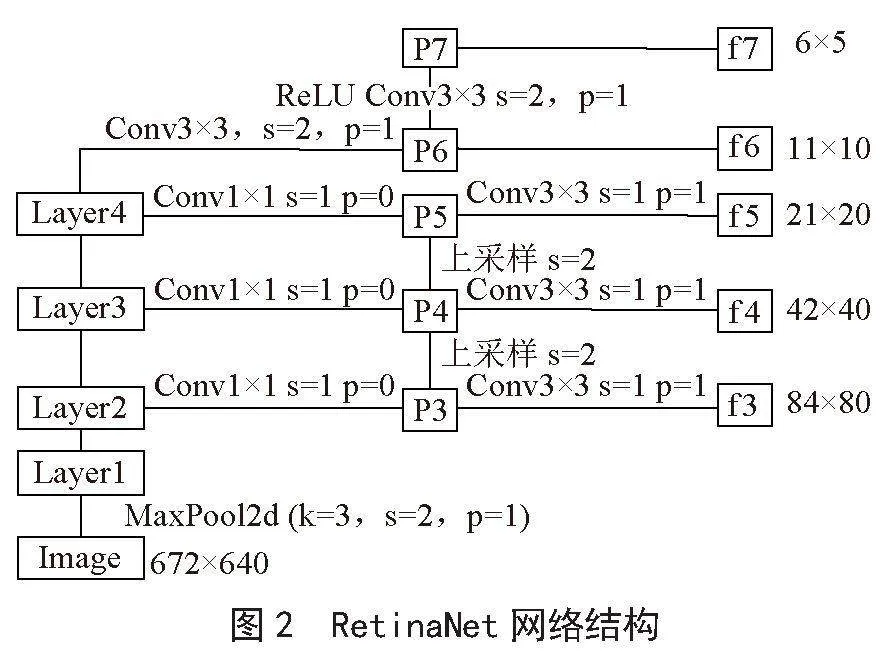
RetinaNet可以看成是一個RPN網絡,經過Backbone進行特征提取之后,接FPN(Feature Pyramid Networks)然后進行分類和回歸的檢測。
在FPN中,采用的特征是P3、P4、P5,然后在P5上面進行一次卷積5得到P6、在P6上進行一次卷積得到P7,最終特征為P3、5GJn5bCXTflM7UdRlh+XnQ==P4、P5、P6、P7,相對于圖像下采樣了8、16、32、64、128倍。其網絡結構如圖2所示。
2.1.2 兩階段目標檢測模型Cascade_RCNN
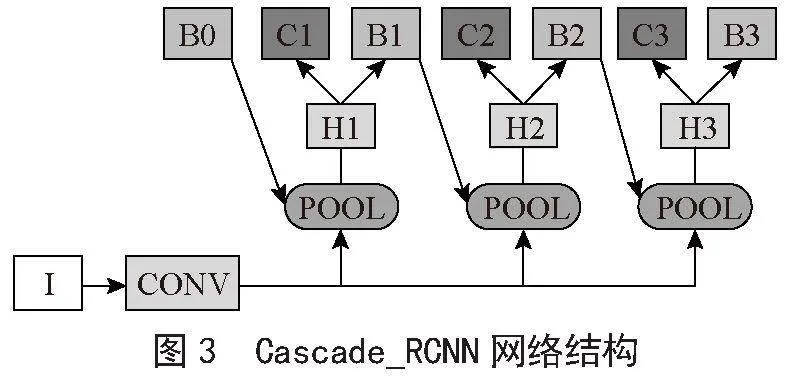
Cascade_RCNN整體流程為級聯多個檢測頭,每個檢測頭的IoU呈現遞增的情況,比如0.5、0.6、0.7,并不是采用相同的閾值。低級檢測頭采用低IoU閾值可以提高召回率,避免目標丟失;后續的高級檢測頭在前一階段的基礎之上提高閾值可以提高檢測精度。其網絡結構如圖3所示。
Cascade_RCN5N損失函數采用多個檢測頭的分類損失+回歸損失,與Faster_RCNN檢測頭的損失一樣。分類用Cross Entropy,回歸用Smooth L1 Loss。
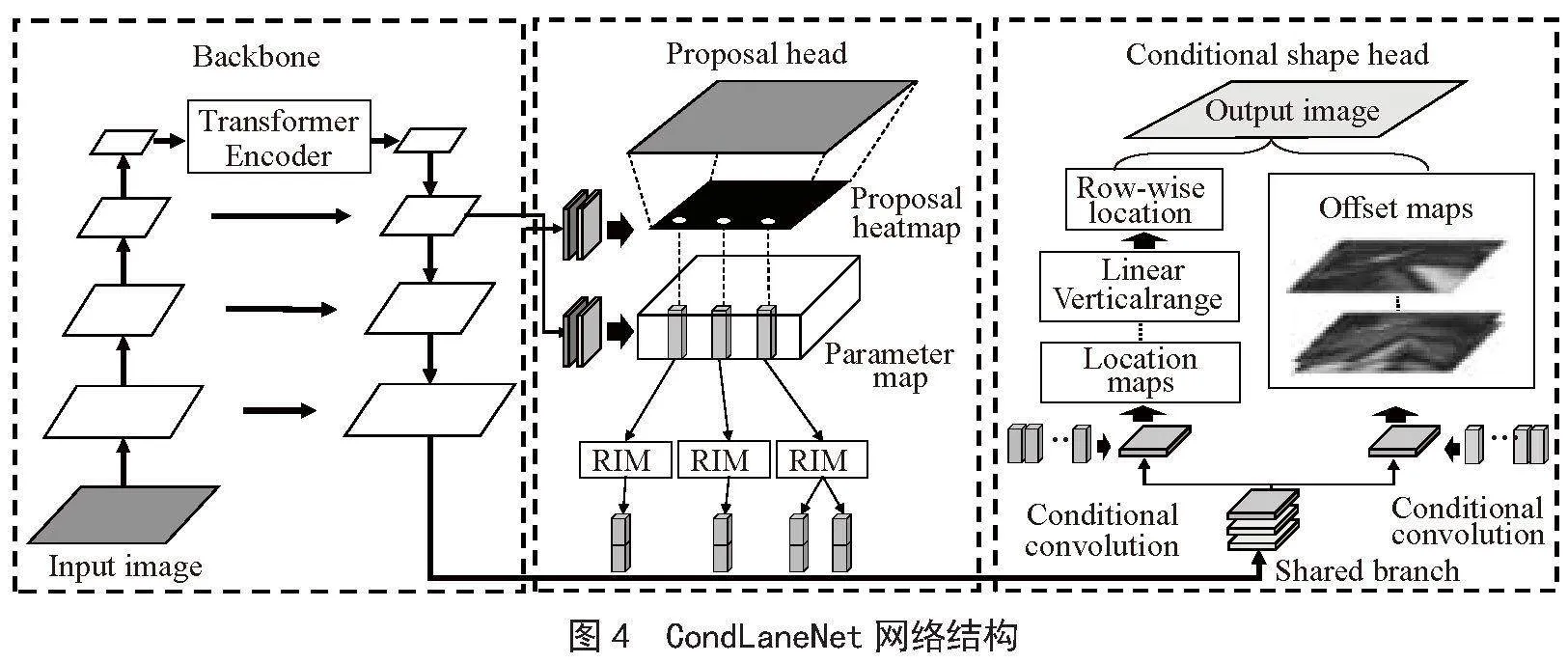
2.1.3 車道線檢測模型CondLaneNet
CondLaneNet是一種自上而下的車道線檢測框架,它首先檢測車道實例,然后動態預測每個實例的線形。自頂向下的設計能夠更好地利用車道線的先驗知識,提高檢測實時性,同時在處理嚴重遮擋等情況下能夠獲得連續的車道線檢測實例。但預設Anchor形狀會影響檢測的靈活性。CondLaneNet網絡結構如圖4所示。
2.2 數據集構建
為滿足預標注準確度及模型訓練泛化性要求,本文選取數據集包含園區、高速、城市和港口等場景,共包含311 538幀數據。其中,高速和城市場景數據為公開數據集,包括BDD100K目標檢測數據、Culane車道線數據以及自建園區和港口場景數據。
對所有數據集圖像中包含的道路物體、車道線、可行駛區域進行標注。數據集中,用于目標檢測的標簽有小汽車、卡車、工程車輛、交通燈、交通標志、行人、自行車、電動車、路障等數十萬個標簽數據;且有超過十萬個車道線檢測標注數據。
根據不同場景將數據集按8:1:1的比例分為訓練集、測試集以及驗證集三部分。
2.3 目標檢測模型融合
多模型融合通常有以下3種方法[12]。
2.3.1 直接平均法
直接平均不同模型產生的類別置信度得到最終預測結果,如式(1):
2.3.2 加權平均法
在直接平均法的基礎上加入權重來調節不同模型輸出間的重要程度,如式(2):
其中,wi對應第i個模型的權重,且必須滿足:
實際使用中,權重wi的取值可以根據不同模型在驗證集上各自單獨的準確率而定。簡單說:準確率高點的權重高點,準確率低點權重就小點。
2.3.3 投票法
少數服從多數,投票數最多的類別作為最終預測結果。投票法前,先將模型各自預測的置信度基于閾值轉換為相應的類別,那么對于某次預測,就有兩種情況:某個類別獲得一半以上模型投票,則將樣本標記為該類別;沒有任何類別獲得一半以上投票,則拒絕預測。模型拒絕預測時一般采用相對多數投票法,即投票數最多的類別即作為最終預測結果。
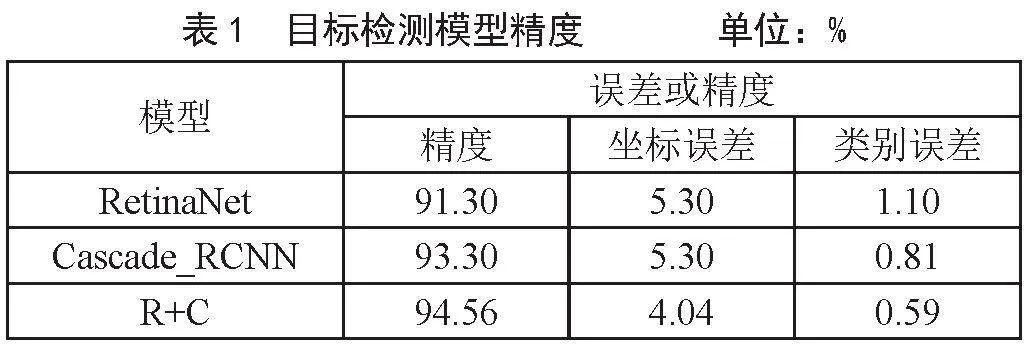
本文在對兩個目標檢測模型進行融合時,使用直接平均法作為融合方法,其邏輯為將兩個模型生成的預測結果(json文件)進行提取、判斷、匹配、參數平均、排序等處理,將兩個預測結果融合為一個總的預測結果。且最后的融合結果比單個目標檢測結果都要高,在模型融合后,對其精度進行測試,與單個模型測試結果作對比,單一的RetinaNet模型精度與誤差、Cascade_RCNN模型精度與誤差以及融合后的模型精度與誤差如表1所示。
根據模型進精度分析,單階段目標檢測模型(RetinaNet)精度為91.30%,坐標誤差與類別誤差分別為5.30%、1.10%,兩階段目標檢測模型(Cascade_RCNN)精度為93.30%,坐標誤差與類別誤差分別為5.30%、0.81%,而對兩個模型融合后,融合模型的精度達到94.56%,坐標誤差與類別誤差降低到了4.04%、0.59%,相較于單個模型,融合模型的精度有較好的提升,另外,兩個模型融合后且坐標誤差與類別誤差降低明顯。
2.4 多模型融合
完成兩個目標檢測模型融合后,需要將融合模型與車道線檢測模型進行最后整合,得到最終的圖像預標注模型,其流程是將兩階段目標檢測推理、單階段目標檢測推理、車道線檢測模型推理過程封裝在一個鏡像中,通過一個主程序完成整合,具體整合流程如圖5所示。
3 實驗分析
3.1 模型訓練設置
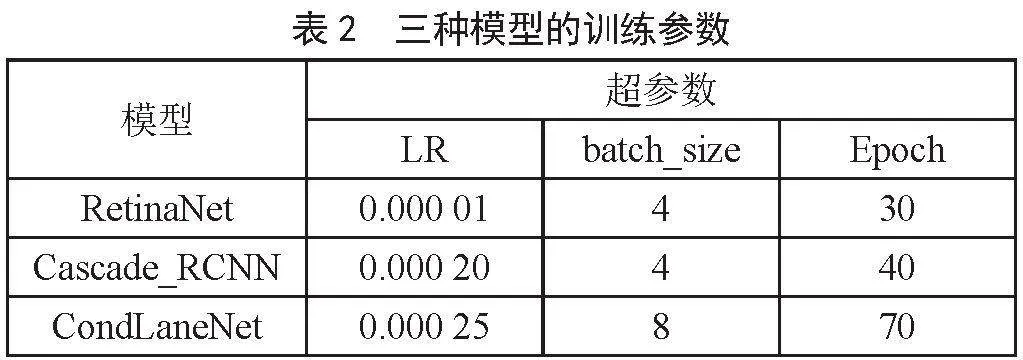
為了提高目標檢測的準確率,本方法通過加載模型預訓練權重進行遷移學習,調整學習率(Learning Rate, LR),訓練輪次(Epoch)和一次訓練所取樣本數(batch_size)尋找相對較優參數。根據消融實驗測試結果,較小的batch_size與較大的Epoch能夠提升部分精度,但過小的batch_size會導致訓練過程中損失函數值震蕩,不利于模型收斂。在進行多次訓練過程中,通過不斷改變3個超參數,進行參數調優處理,最后調整的3種模型訓練的最優參數如表2所示。
表中3種模型的學習率、訓練樣本數、訓練輪次均為多次測試后取最好效果的最優參數,以確保最優的融合結果。
3.2 模型評價指標
在2.3節模型融合中,已對單階段目標檢測模型以及兩階段檢測模型分別評估,以及兩個模型的融合精度(Accuracy)評估,對每一個模型的檢測效果進行評價,對單階段、兩階段目標檢測模型生成的預測結果與其原標注結果進行比對。
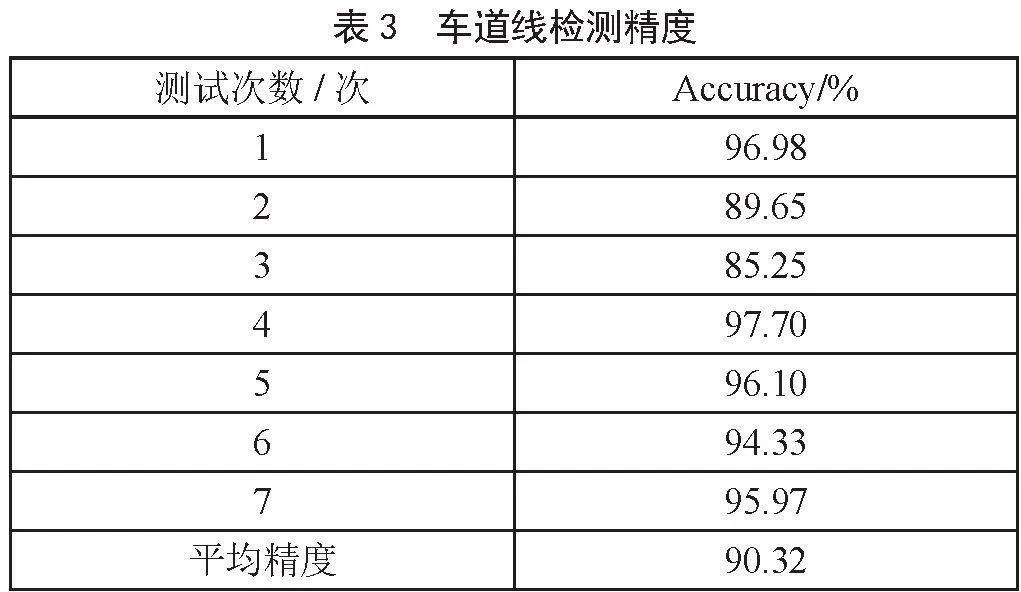
將車道線檢測模型放入模型精度評估代碼進行判定,得到多次測試結果,對測試結果進行記錄并計算其平均精度,如表3所示。
多次測試中,由于數據集的泛化性,即其中個別數據可能存在無目標物、目標物模糊不清、車道線復雜不清晰等原因,從而導致結果精度低于90%,故而后續需要進一步改進優化算法。
在模型整合完成后,對整體功能預標注功能進行測試,在可視化平臺對測試圖像進行標注預識別可視化測試,測試結果如圖6所示。
經過觀察模型整合完成后的預標注測試結果,發現目標檢測和車道線檢測方面的預標注效果非常好。目標框與待標注的目標物以及車道線的貼合度良好,同時類別分類準確度也得到了顯著提升,相較于單一模型的預測結果明顯有所改善。
4 結 論
本文提出了一種多模型融合投票預標注方法,該方法能夠通過將模型訓練后生成的json結果進行提取、判斷、匹配、參數平均、排序等處理,將Cascade_RCNN、RetinaNet、CondLaneNet三個模型的預測結果進行融合,在公開數據集以及自建數據集上進行多次實驗,結果表明,本方法在對三個模型進行融合后,預標注精度得到顯著提升,預標注最高精度達到94%,平均精度達到90%,該方法有效地減少了標注過程中人工標注工作量,在標注工作中起到優秀的輔助作用。
在分析測試結果后,發現數據集并不是每一張都有效,無目標物或目標物、車道線不清晰的冗余數據集降低了預標注精度,后續需改進算法使其能夠自動拋棄冗余數據集或將冗余數據集進行標記,以便人工審核時及時處理。
參考文獻:
[1] REDMON J,DIVVALA S,GIRSHICK R,et al. You Only Look Once: Unified, Real-Time Object Detection [C]//2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Las Vegas:IEEE,2016:779-788.
[2] LIU W,ANGUELOV D,ERHAN D,et al. SSD: Single Shot MultiBox Detector [C]//Computer Vision - ECCV 2016.Amsterdam:Springer,2016:21-37.
[3] LIN T-Y,GOYAL P,GIRSHICK R,et al. Focal Loss for Dense Object Detection [C]//2017 IEEE International Conference on Computer Vision (ICCV).Venice:IEEE,2017:2999-3007.
[4] GIRSHICK R,DONAHUE J,DARRELL T,et al. Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation [C]//2014 IEEE Conference on Computer Vision and Pattern Recognition.Columbus:IEEE,2014:580-587.
[5] GIRSHICK R. FAST R-CNN [C]//2015 IEEE International Conference on Computer Vision (ICCV).Santiago:IEEE,2015:1440-1448.
[6] CAI Z W,VASCONCELOS N. Cascade R-CNN: High Quality Object Detection and Instance Segmentation [J/OL].arXiv:1906.09756 [cs.CV].[2023-09-23].https://arxiv.org/abs/1906.09756.
[7] LI X,LI J,HU X L,et al. Line-CNN: End-to-End Traffic Line Detection With Line Proposal Unit [J].IEEE Transactions on Intelligent Transportation Systems,2020,21(1):248-258.
[8] TABELINI L,RODRIGO B,THIAGO M,et al. Keep your Eyes on the Lane: Real-time Attention-guided Lane Detection [J/OL].arXiv:2010.12035 [cs.CV].[2023-09-23].https://arxiv.org/abs/2010.12035.
[9] LIU L Z,CHEN X H,ZHU S Y,et al. CondLaneNet: a Top-to-down Lane Detection Framework Based on Conditional Convolution [J/OL]. arXiv:2105.05003 [cs.CV].[2023-09-26].https://arxiv.org/abs/2105.05003.
[10] QU Z,JIN H,ZHOU Y,et al. Focus on Local: Detecting Lane Marker from Bottom Up via Key Point [J/OL].arXiv:2105.13680 [cs.CV].[2023-09-26].https://arxiv.org/abs/2105.13680.
[11] TABELINI L,RODRIGO B,THIAGO M,et al. PolyLaneNet: Lane Estimation via Deep Polynomial Regression [J/OL].arXiv:2004.10924 [cs.CV].[2023-09-29].https://arxiv.org/abs/2004.10924.
[12] 魏秀參.解析深度學習:卷積神經網絡原理與視覺實踐 [M].北京:電子工業出版社,2018:143-149.
