基于軸-Transformer的醫學圖像分割模型Axial-TransUNet
2024-11-05 00:00:00劉文科劉琳韓子逸張媛媛
現代信息科技 2024年16期
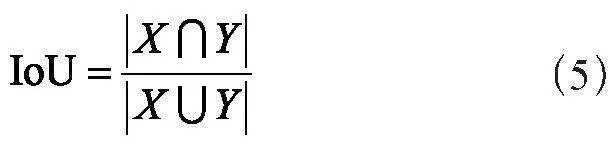
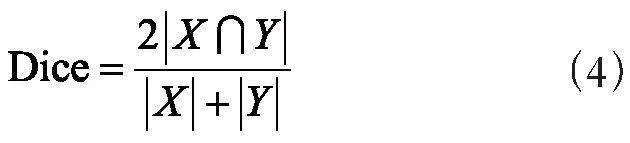
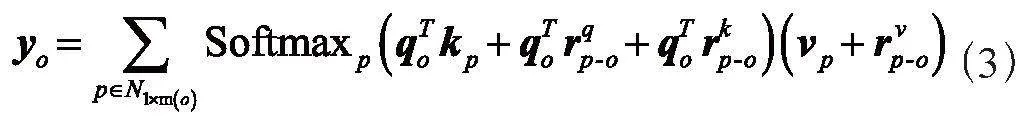
摘 要:針對TransUNet中Transformer自注意力機制計算復雜度高、捕獲位置信息能力不足的問題,提出一種基于軸向注意力機制的醫學圖像分割網絡Axial-TransUNet。該網絡在保留TransUNet網絡編碼器、解碼器以及跳躍連接的基礎上,使用基于軸向注意力機制的殘差軸向注意力塊代替TransUNet的Transformer層。實驗結果表明,在多個醫學數據集上,相較于TransUNet等其他醫學圖像分割網絡,Axial-TransUNet的Dice系數、交并比IoU有更好的表現。與TransUNet相比,Axial-TransUNet網絡的參數量與浮點運算數(FLOPs)分別降低14.9%和30.5%。可見,Axial-TransUNet有效降低了模型復雜度,并增強了模型捕獲位置信息的能力。
關鍵詞:醫學圖像分割;卷積神經網絡;位置信息;計算復雜度;軸向注意力機制
中圖分類號:TP183;TP39 文獻標識碼:A 文章編號:2096-4706(2024)16-0028-06
Axial-TransUNet of Medical Image Segmentation Model Based on Axis-Transformer
Abstract: A medical image segmentation network Axial-TransUNet based on Axial Attention Mechanism is proposed to address the issues of high computational complexity and insufficient ability to capture positional information in the Transformer Self-Attention Mechanism in TransUNet. On the basis of retaining the TransUNet network encoder, decoder, and skip connections, this network uses residual axial attention blocks based on Axial Attention Mechanism to replace the Transformer layer of TransUNet. The experimental results show that compared to other medical image segmentation networks such as TransUNet, Axial TransUNet performs better in Dice coefficient and intersection union ratio on multiple medical datasets. Compared with TransUNet, the parameter count and FLOPs of the Axial TransUNet network are reduced by 14.9% and 30.5%, respectively. It can be seen that Axial TransUNet effectively reduces model complexity and enhances the model's ability to capture positional information.
Keywords: medical image segmentation; Convolutional Neural Networks; positional information; computational complexity; Axial Attention Mechanism
0 引 言
傳統的人工醫學圖像識別通常依賴于專業醫生的經驗和主觀判斷,且難適應大規模數據集和復雜的疾病模式。因此,深度學習在醫學圖像分析方面的應用具有重要意義。
在醫學圖像分割任務中,卷積神經網絡(ConvolutionalNeuralNetworks, CNNs)特別是全卷積網絡(FullyConvolutionalNetworks, FCNs)[1],憑借其優異的分割性能占據了主導地位。以U-Net [2]為代表的經典U型結構是最為流行和廣泛使用的結構之一。U-Net主要由對稱的編碼器和解碼器組成,結合跳躍連接避免下采樣過程中的信息丟失。U-Net的變體主要有UNet++ [3]、UNet 3+ [4]、Res-UNet [5]、ResUNet++ [6]、3D U-Net [7]、Attention U-Net [8]等,這些模型均在不同的醫學圖像分割任務上展示了優異的性能。
然而,由于卷積運算的內在局部性,它們捕獲長距離依賴的能力不足,無法很好地利用全局信息。為了克服這一局限性,Wang [9]等人提出建立基于CNN特征的自我注意力機制,通過非局部操作捕獲長期依賴,增大模型感受野。此外,為序列建模而設計的Transformer在自然語言處理領域(NLP)取得良好成效。受此啟發,研究人員將其應用到計算機視覺領域。為使Transformer適用于計算機視覺任務,研究人員對其進行了一些修改。例如,Parmar等人[10]在每個查詢像素的局部鄰域中應用自關注;Child等人[11]提出稀疏變換器,采用全局自關注的可擴展近似;Dosovitski等人[12]提出的Vision Transformer將圖像塊的線性嵌入式序列作為Transformer的輸入,使具有全局自關注的注意力機制直接應用于全尺寸圖像,是當時ImageNet分類的最先進技術。然而,純Transformer方法會帶來特征損失等問題,所以建立基于CNN和Transformer相結合的網絡架構受到了廣泛的關注。例如,Yao等人[13]所提出的Transclaw U-Net在編碼器部分將卷積和Transformer結合,分別用于提取淺層特征和全局信息;Xu等人[14]提出的LeViT-UNet結合了LeViT的全局感知能力和UNet的分割能力,生成精確的分割結果。其中,Chen [15]等人提出的TransUNet使用CNN和Transformer的混合編碼器結構,結合CNN對局部細節信息以及Transformer對全局信息的提取優勢來提升分割精度,取得了優異表現。TransUNet [15]編碼器部分的Transformer建立在VisionTransformer(ViT)之上,Vision Transformer基于全局自注意力機制提取注意力,其計算的注意力矩陣大小與輸入序列長度成平方關系,需要消耗大量的內存與計算資源,所以TransUNet在處理較大數據時存在一定的局限性。同時,ViT所采用的自注意力機制會將輸入序列中的所有位置進行交互和整合,而不考慮位置之間的差異,這可能導致一些細節信息在編碼過程中被模糊化或丟失。為解決上述問題,Wang [16]等人提出軸向注意力機制,在保持全局感受野的前提下,將2D注意力按高度軸和寬度軸順序分解為兩個1D注意力,有效降低了參數量,彌補了自注意力機制的不足。同時,軸向注意力機制引入更加精確的位置編碼,使注意模型對位置更加敏感并具有邊際成本。此外,研究人員還將軸向注意力模塊引入殘差結構中形成殘差軸向注意力塊,進一步提升分割精度。
為解決TransUNet參數量大、計算復雜度高以及對位置信息交互能力差的問題,本文提出Axial-TransUNet解決了這些問題帶來的局限性。Axial-TransUNet將基于軸向注意力機制的殘差軸向注意力塊應用于軸-Transformer部分,建立CNN和軸-Transformer混合編碼器架構,在保證較大感受野的前提下實現復雜度的降低,同時增強模型捕獲位置信息的能力。在多個醫學圖像數據集上與有代表性的算法進行評估,Axial-TransUNet表現出了不錯的性能。
1 相關工作
1.1 CNN與Transformer結合
以U-Net為代表的卷積神經網絡存在感受野較小、捕捉長距離依賴不足的問題。受NLP中Transformer的啟發,Dosovitski等人[12]提出的Vision Transformer將圖像拆分為塊,并提供這些塊的線性嵌入序列作為Transformer的輸入,利用其捕獲長距離依賴的優勢克服了這一局限性。然而,純Transformer仍存在特征損失的問題。為解決上述問題,Chen等人[15]提出的TransUNet采用CNN與Transformer相結合的U型結構,將兩者的優勢結合起來并取得優異的性能。其中,編碼器部分的Transformer建立在Vision Transformer之上,將來自CNN特征映射的標記化圖像塊編碼處理成用于提取全局上下文的輸入序列。然而,由于Vision Transformer中自注意力機制是全局的,注意力矩陣大小與輸入序列長度成平方關系,所以TransUNet的計算復雜度較高。同時,自注意力機制在計算注意力權重時,只考慮了特征本身的相似性,而忽略了位置信息。這可能導致在某些任務中,模型無法準確地捕捉到物體的準確位置。
1.2 軸向注意力機制
Wang等人[16]提出的軸向注意力機制是一種具有全局感受野的獨立自注意力機制,其核心思想是將2D注意力分解為兩個1D注意力模塊,第一個模塊在特征圖高度軸上進行自我關注,第二個模塊在寬度軸上進行操作,有效地模擬了原始的自注意機制,具有更好的計算效率。同時,軸向注意力機制通過在計算軸向注意力權重時考慮位置信息,可以更好地保留物體的空間結構和位置關系,提高模型在位置感知任務中的性能。
2 方法介紹
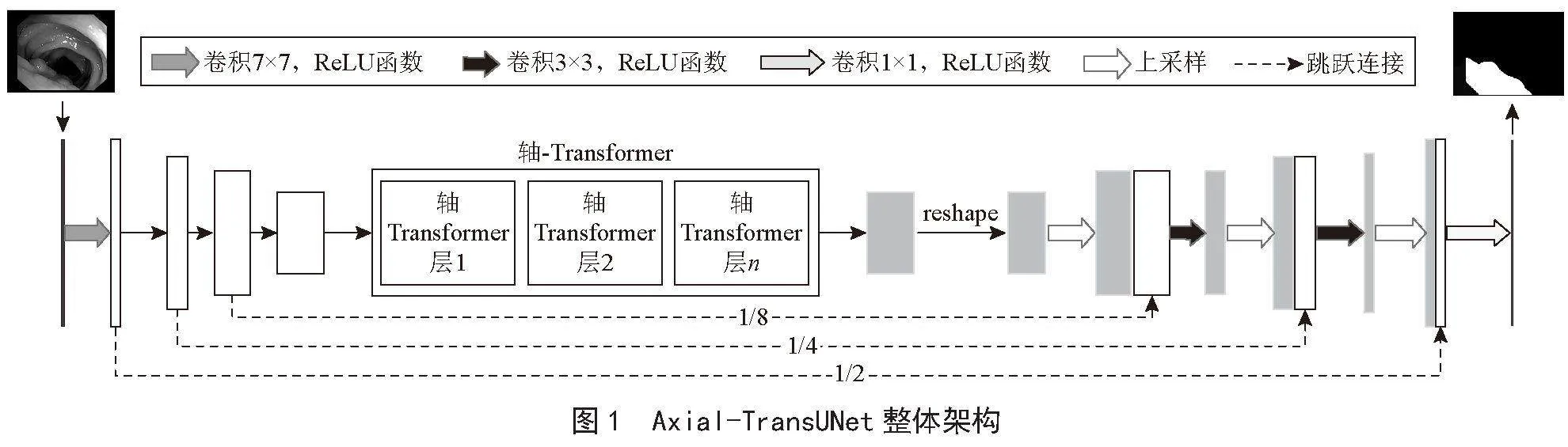
Axial-TransUNet的整體結構如圖1所示。輸入圖像首先被送入混合編碼器模塊,由CNN進行逐級特征提取,然后送入軸-Transformer層進行全局上下文信息提取。解碼器模塊將編碼特征進行上采樣并將其與高分辨率CNN特征圖相結合,實現特征聚合。其中,軸-Transformer部分通過采用基于軸向注意力機制的殘差軸向注意力塊。從分割結果及參數量對比結果可以看出,Axial-TransUNet實現了更好的分割精度,且參數量相較TransUNet [15]有明顯降低。
2.1 融合軸向注意力機制的編碼器模塊
在Axial-TransUNet中,編碼器模塊包括殘差特征提取部分和軸-Transformer部分。
2.1.1 殘差特征提取器
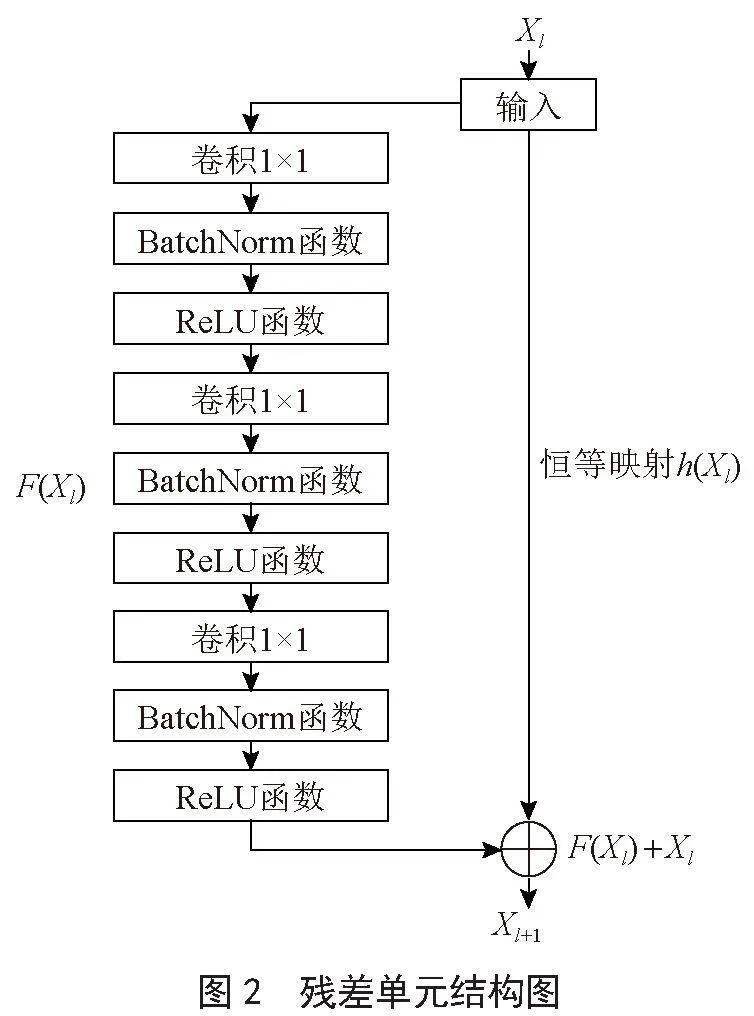
殘差特征提取器負責對輸入圖像進行逐級特征提取,并將不同層次的高分辨率特征圖輸出至跳躍連接路徑中。首先將輸入圖像Ho×Wo×Co通過卷積變換到指定大小H×W×C,其中H、W、C分別表示圖像的高度、寬度和通道數,然后通過四級殘差特征提取塊進行特征提取。每一級殘差特征提取塊將圖像通道數變為原來的2倍,將圖像的分辨率降低為原來的1/2。其中,每個殘差特征提取塊基于3個堆疊的殘差單元進行特征提取。每個殘差單元包含3個卷積層,每個卷積層結構如圖2所示。
每個殘差單元可以用下面的通用形式表示:
其中,Xl和Xl+1為第l個單元的輸入和輸出,Wl為可學習的權重矩陣,F為殘差函數,f為激活函數,h為恒等映射函數,通常取h(Xl) = Xl。
2.1.2 軸-Transformer
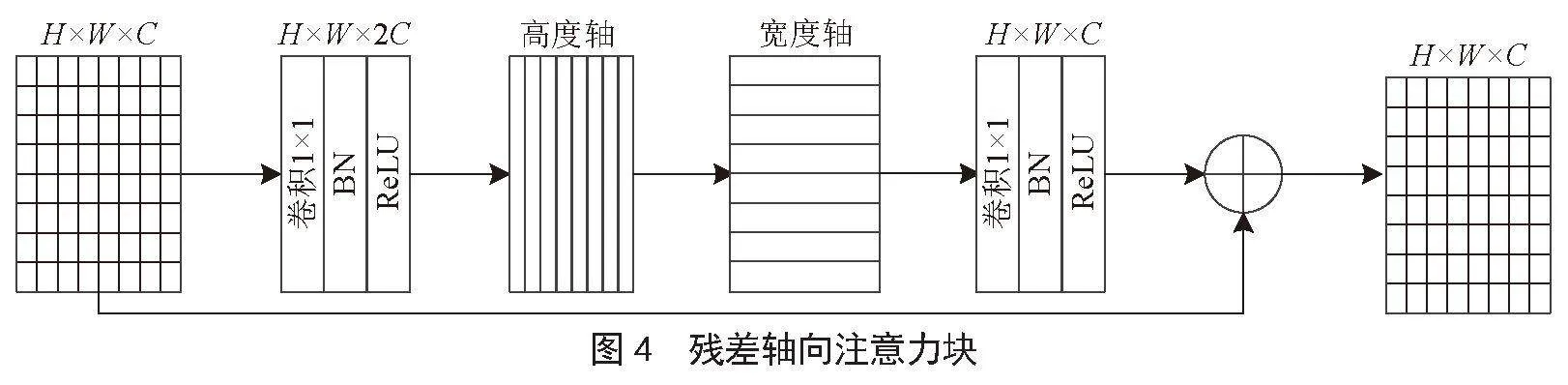
軸-Transformer由若干殘差軸向注意力塊堆疊而成,殘差軸向注意力塊基于軸向注意力機制分別在高度軸及寬度軸上計算注意力,并采用殘差結構提取特征。
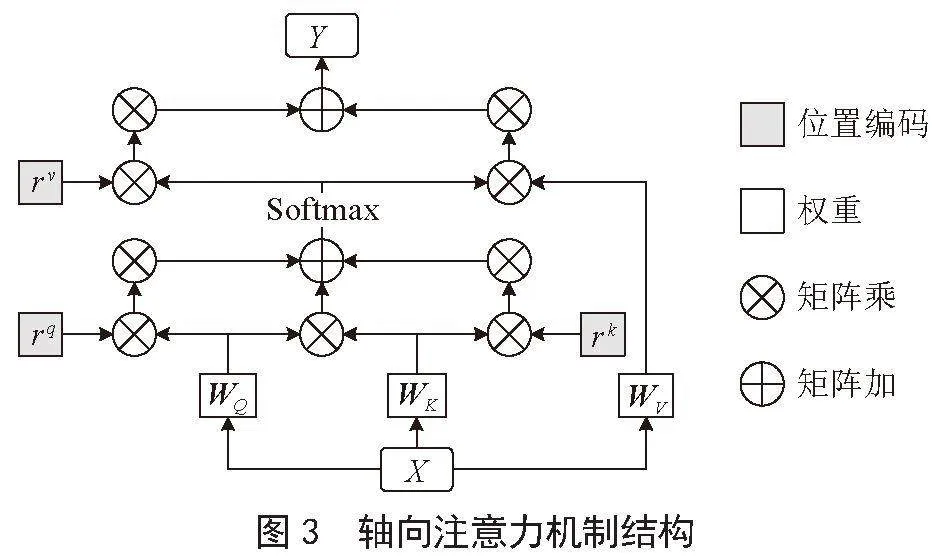
1)軸向注意力機制。一個軸向注意力層沿著一個特定的軸傳播信息。如圖3所示,輸入圖像X分別與可學習的權重矩陣WQ、Wk、WV相乘得到查詢q、鍵k、值v,查詢q與鍵v相乘得到注意力矩陣,同時,為q、k添加可學習的位置矩陣,二者的輸出與注意力矩陣拼接并進行Softmax操作后得到最終的注意力矩陣。注意力矩陣與添加位置編碼信息的值v進行矩陣乘法操作得到最終的輸出Y。對于一張H×W×C的輸入圖像,軸向注意力機制將圖像寬度軸上的軸向注意力層定義為簡單的1D位置敏感的自我注意力,并對高度軸使用類似定義。沿寬度軸的軸向注意層定義如下:
其中,m為區域大小,查詢q = WQ X,鍵k = Wk X,值v = WV X,WQ、Wk、WV均為可學習的權重矩陣,rq、rk、rv分別為q、k、v的可學習的位置編碼。
2)殘差軸向注意力塊。如圖4所示,將ResNet中殘差瓶頸塊的3×3卷積替換為兩個軸向層,其中一個用于高度軸,另一個用于寬度軸,形成殘差軸向注意力塊。
2.2 解碼器模塊
解碼器部分主要通過多層解碼模塊對圖像信息進行恢復。首先通過上采樣操作將低分辨率圖像轉換成高分辨圖像。然后將上采樣后的特征圖與對應的編碼器層的特征圖進行跳躍連接,通過逐層特征融合和特征提取,逐漸將特征圖恢復到與原始輸入圖像相同的分辨率。最后,解碼器模塊使用一個卷積層將恢復到原始分辨率的特征圖映射到與輸出圖像大小相同的特征空間中,并使用激活函數將其映射到0~1之間的數值范圍內,得到預測結果[17]。
2.3 評價指標
對于醫學圖像分割任務,采用交并比IoU(Intersection
over Union)和相似系數Dice(Dice Similarity Coefficient)來評估模型的分割性能[18]。
2.3.1 Dice系數
Dice系數是一種集合相似度度量函數,通常用于計算兩個樣本的相似度,取值范圍在[0,1],值越大,分割效果越好。其計算式如下:
其中,X和Y分別表示真實標簽和預測結果。
2.3.2 交并比IoU
IoU是預測結果和真實標簽之間的重疊區域除以兩者之間的聯合區域,取值范圍為[0,1],值越大,分割效果越好。其計算式如下:
其中,X和Y分別為真實標簽和預測結果。
3 實驗分析
3.1 數據集
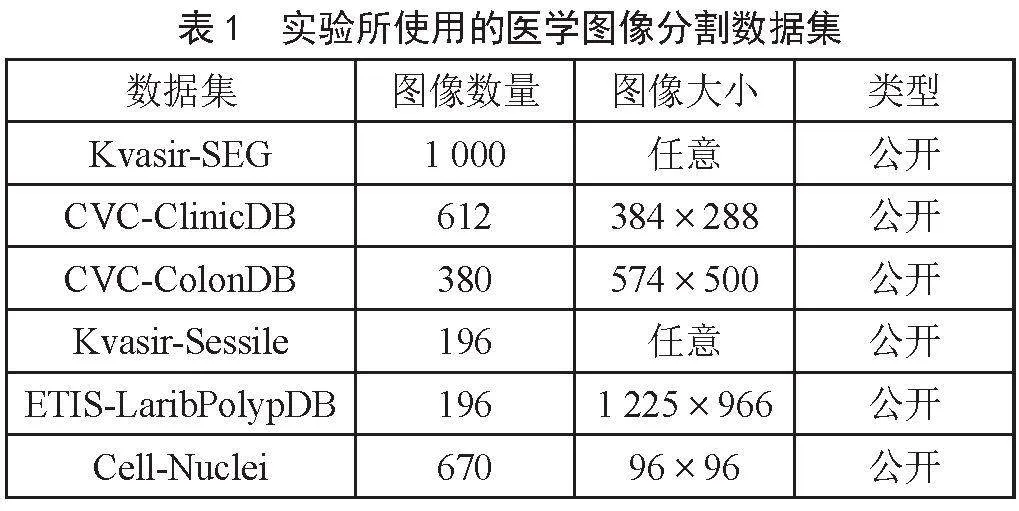
實驗采用6個公開的醫學圖像分割數據集,如表1所示,包括5個息肉數據集Kvasir-SEG、Kvasir-Sessile、CVC-ClinicDB、CVC-ColonDB和ETIS-LaribPolypDB以及1個細胞核數據集Cell-Nuclei。每個數據集均以8:2的比例劃分為訓練集和測試集。
3.2 實驗細節及環境
實驗是在單個11 GB的RTX 2080 GPU上運行的,實驗環境為Python 3.8和PyTorch 1.11.0。數據的預處理主要包括歸一化、隨機旋轉、隨機翻轉、色調飽和度、亮度及對比度調節等。對于5個息肉數據集Kvasir-SEG、Kvasir-Sessile、CVC-ClinicDB、CVC-ColonDB和ETIS-LaribPolypDB,其輸入圖像大小為256×256,細胞核數據集Cell-Nuclei的輸入圖像大小為96×96。殘差軸向注意力塊默認堆疊1層,batch_size為8,使用BCEDiceLoss作為損失函數,學習率為0.01,動量為0.9,權重衰減為1×10-3的SGD作為優化器,迭代次數為100。對于模型,使用二分類交叉熵損失(BCELoss)和Dice損失(DiceLoss)的組合來訓練Axial-TransUNet,如下式所示:
3.3 實驗結果及分析
實驗在6個醫學圖像分割數據集上對Axial-TransUNet進行訓練,并與模型U-Net [2]、UNet++ [3]、
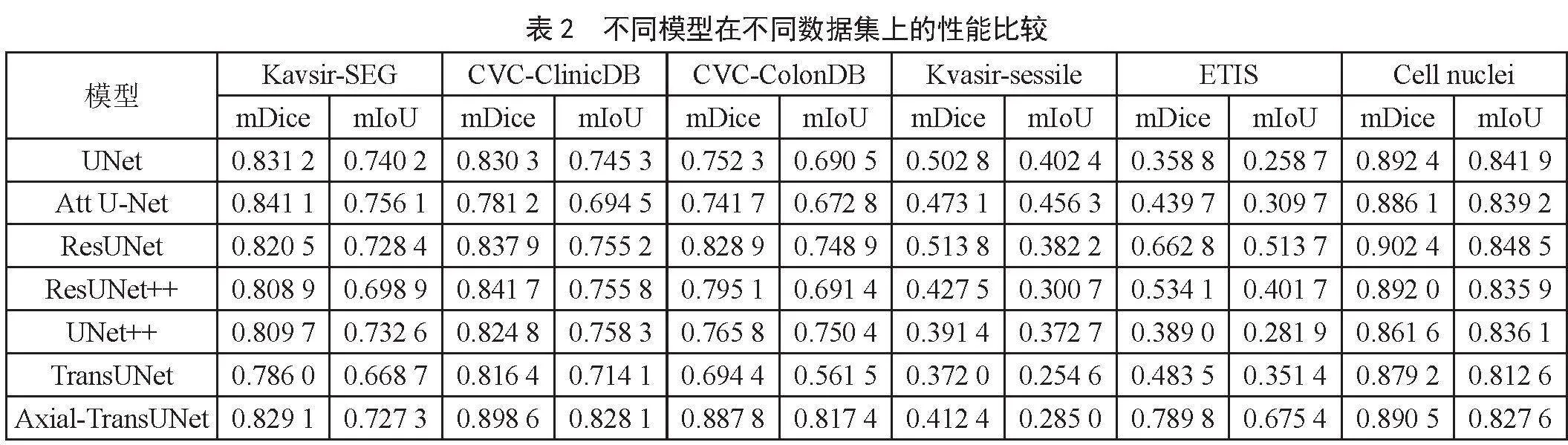
Attention U-Net [8]、Res-UNet [5]、ResUNNet++ [6]、TransUNet [15]進行分割精度以及參數量的對比。由實驗結果可知,Axial-TransUNet的分割精度優于TransUNet [15],并在CVC-ClinicDB、CVC-ColonDB、ETIS-LaribPolypDB三個數據集上達到最佳分割性能。除此之外,Axial-TransUNet的參數量相對TransUNet [15]也有顯著降低。
3.3.1 模型定量分析
Axial-TransUNet與U-Net [2]、UNet++ [3]、Res-UNet [5]、ResUNet++ [6]、Attention UNet [8]、TransUNet [15]
在6個公開醫學圖像分割數據集上的定量分析結果如表2所示。由表2可知,Axial-TransUNet的分割精度相較TransUNet [15]均有不同程度的提升。在CVC-ClinicDB、CVC-ColonDB、ETIS-LaribPolypDB上,Axial-TransUNet獲得了最好的分割效果。其中,在Kavsir-SEG數據集上,Axial-TransUNet相對TransUNet在Dice上提升了約5.5%,在IoU上提升了約8.8%。在CVC-ClinicDB數據集上,Axial-TransUNet相對TransUNet在Dice上提升了約10.1%,在IoU上提升了約16.0%。在CVC-ColonDB數據集上,Axial-TransUNet相對TransUNet在Dice上提升了約27.9%,在IoU上提升了約45.6%。在Kvasir-sessile數據集上,Axial-TransUNet相對TransUNet在Dice上提升了約10.9%,在IoU上提升了約11.9%。在ETIS-LaribPolypDB數據集上,Axial-TransUNet相對TransUNet在Dice上提升了約63.4%,在IoU上提升了約92.2%。在Cellnuclei數據集上,Axial-TransUNet相對TransUNet在Dice上提升了約1.3%,在IoU上提升了約1.8%。
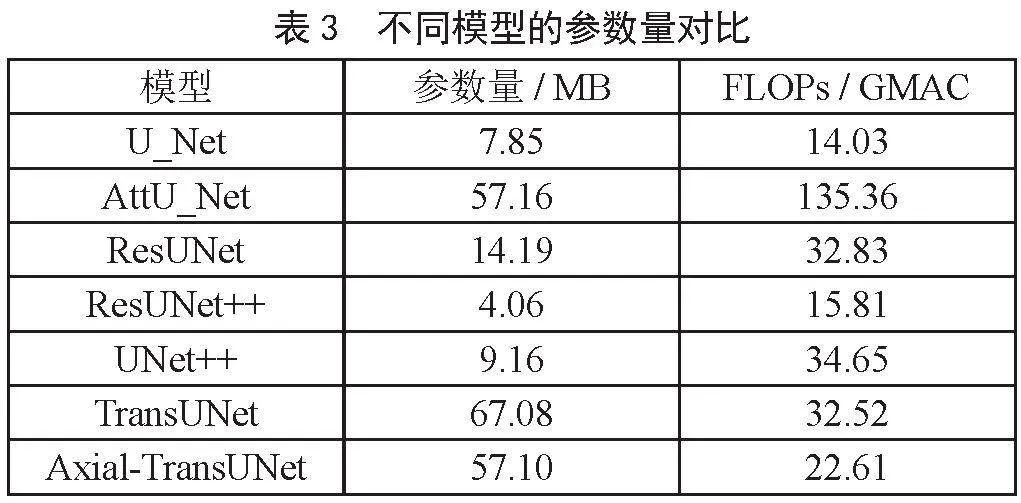
3.3.2 模型參數量對比
如表3所示,與其他兩種引入注意力機制的網絡Attention UNet [8]、TransUNet [15]相比,Axial-TransUNet參數量更少,計算復雜度更低。其中,相比于TransUNet,Axial-TransUNet參數量降低了約14.9%,計算復雜度降低約30.5%。
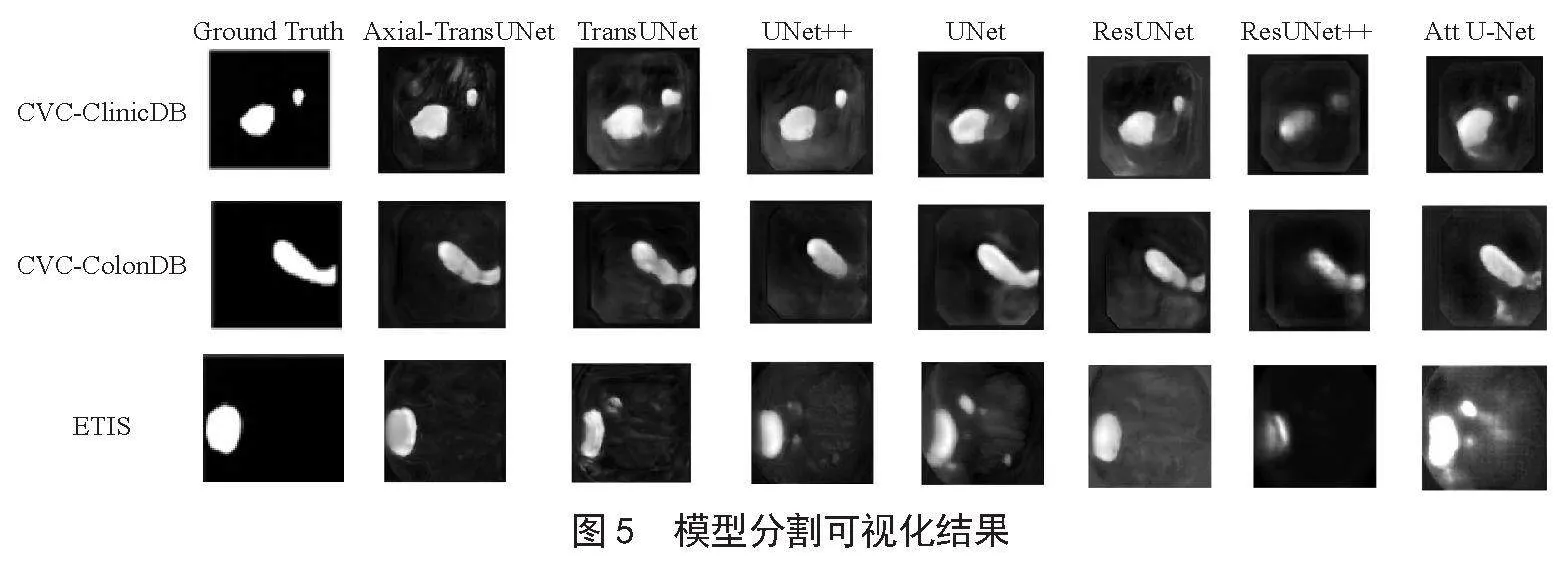
3.3.3 模型可視化結果
不同模型在不同數據集上的分割結果如圖5所示。從圖中可以看出,相較于純CNN的方法,Axial-TransUNet對邊界信息分割更為精準。例如,第一行中,UNet [2]、UNet++ [3]等對圖像的邊界信息不夠敏感,出現了特征丟失的問題,而Axial-TranUNet保留了很好的邊界信息。
相較于TransUNet [15],Axial-TransUNet能夠較好地避免特征損失、過度分割的問題。例如,第三行中,TransUNet對白色區域左半部分進行分割時出現了特征損失的問題,而Axial-TransUNet則較好地保留了圖像的特征。同樣,Axial-TransUNet也實現了更好的邊緣預測。
4 結 論
TransUNet模型的Transformer基于自注意力機制進行注意力計算。由于自注意力機制在計算注意力權重時需要考慮所有位置之間的關系,注意力矩陣大小與輸入序列長度成平方關系,所以Transformer的計算復雜度較高。同時,由于自注意力機制僅對查詢向量采用位置編碼,所以Transformer在捕獲位置信息方面能力較低。針對上述問題,本文提出Axial-TransUNet網絡。Axial-TransUNet將軸向注意力機制融入Transformer中,軸向注意力機制僅考慮處于同一軸向位置之間的關系,因此可以通過降低注意力權重計算的復雜度來減少模型參數量,并且可以更好地捕捉輸入數據中不同方向上的特征和關系。這種方向性信息的建模有助于提升模型的表示能力和泛化性能。此外,軸向注意力機制引入的更豐富的可學習的位置矩陣,使模型可以根據不同位置的需要自適應地調整注意力權重,從而更好地利用位置信息進行建模和預測。基于軸向注意力機制的Axial-TransUNet有效降低了TransUNet的計算復雜度,同時有效彌補了TransUNet捕捉位置信息能力的不足,提高了分割精度。如表2所示,Axial-TransUNet網絡在6個醫學圖像數據集上表現出比TransUNet更優的分割性能,在CVC-ClinicDB、CVC-ColonDB、ETIS-LaribPolypDB這3個數據集其分割性能上達到最佳。如表3所示,與其他兩種引入注意力機制的網絡AttentionUNet、TransUNet相比,Axial-TransUNet參數量與計算復雜度均較低。這也表明,軸Transformer在未來仍有很高的研究價值。
然而,軸向注意力機制并不是對自注意力機制的全面替代,而是在特定任務或場景下的一種改進選擇。在某些情況下,自注意力機制可能仍然是更合適的選擇,特別是當全局信息之間的關系對任務至關重要時。
參考文獻:
[1] LONG J,SHELHAMER E,DARRELL T. Fully Convolutional Networks for Semantic Segmentation[C]//2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR).Boston:IEEE,2015:3431-3440.
[2] RONNEBERGER O,FISCHER P,BROX T. U-Net: Convolutional Networks for Biomedical Image Segmentation [C]//Proceedings of the Lecture Notes in Computer Science.Munich:Springer,2015:234-241.
[3] ZHOU Z W,SIDDIQUEE M M R,TAJBAKHSH N,et al. UNet++: A Nested U-Net Architecture for Medical Image Segmentation [C]//Medical Image Computing and Computer-Assisted Intervention - MICCAI 2015.Granada:Springer,2018:3-11.
[4] HUANG H M,LIN L F,TONG R F,et al. UNet 3+: A Full-Scale Connected UNet for Medical Image Segmentation [C]//ICASSP 2020 - 2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP).Barcelona:IEEE,2020:1055-1059.
[5] XIAO X,LIAN S,LUO Z M,et al. Weighted Res-UNet for High-Quality Retina Vessel Segmentation [C]//2018 9th International Conference on Information Technology in Medicine and Education (ITME).Hangzhou:IEEE,2018:327-331.
[6] JHA D,SMEDSRUD P H,RIEGLER M A,et al. ResUNet++: An Advanced Architecture for Medical Image Segmentation [C]//2019 IEEE International Symposium on Multimedia (ISM).San Diego:IEEE,2019:225-230.
[7] ?I?EK ?,ABDULKADIR A,LIENKAMP S S,et al. 3D U-Net: Learning Dense Volumetric Segmentation from Sparse Annotation [C]//Medical Image Computing and Computer-Assisted Intervention - MICCAI 2016.Athens:Springer, 2016:424-432.
[8] OKTAY O,SCHLEMPER J,FOLGOC L L,et al. Attention U-Net: Learning Where to Look for the Pancreas [J/OL].arXiv:1804.03999 [cs.CV].[2023-11-15].https://arxiv.org/abs/1804.03999.
[9] WANG X L,GIRSHICK R,GUPTA A,et al. Non-local Neural Networks [C]//2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition.Salt Lake City:IEEE,2018:7794-7803.
[10] PARMAR N,VASWANI A,USZKOREIT J,et al. Image Transformer [J/OL].arXiv:1802.05751 [cs.CV].[2023-10-22].https://arxiv.org/abs/1802.05751v3.
[11] CHILD R,GRAY S,RADFORD A,et al. Generating Long Sequences with Sparse Transformers [J/OL].arXiv:1904.10509 [cs.LG].[2023-10-20].https://arxiv.org/abs/1904.10509.
[12] DOSOVITSKIY A,BEYER L,KOLESNIKOV A,et al. An Image is Worth 16×16 Words: Transformers for Image Recognition at Scale [J/OL].arXiv:2010.11929 [cs.CV].[2023-10-20].https://arxiv.org/abs/2010.11929.
[13] YAO C,HU M H,LI Q L,et al. Transclaw U-Net: Claw U-Net With Transformers for Medical Image Segmentation [C]//2022 5th International Conference on Information Communication and Signal Processing (ICICSP).Shenzhen:IEEE,2022:280-284.
[14] XU G P,ZHANG X,FANG Y,et al. LeViT-UNet: Make Faster Encoders with Transformer for Medical Image Segmentation [J/OL].arXiv:2107.08623 [cs.CV].[2023-09-19].https://arxiv.org/abs/2107.08623.
[15] CHEN J N,LU Y Q,YU Q H,et al. TransUNet: Transformers Make Strong Encoders for Medical Image Segmentation [J/OL].arXiv:2102.04306 [cs.CV].[2023-09-19].https://arxiv.org/abs/2102.04306.
[16] WANG H Y,ZHU Y K,GREEN B,et al. Axial-DeepLab: Stand-Alone Axial-Attention for Panoptic Segmentation [C]//Computer Vision - ECCV 2020.Glasgow:Springer,2020:108-126.
[17] HE K M,ZHANG X Y,REN S Q,et al. Deep Residual Learning for Image Recognition [C]//2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR).Las Vegas:IEEE,2016:770-778.
[18] 丘文峰.基于Python的醫學圖像處理框架及其應用 [D].廣州:華南師范大學,2010.
