動態多視圖推理分層相似性的圖文檢索算法
2024-10-31 00:00:00張書銘
現代信息科技 2024年17期






摘 要:跨模態圖像文本檢索通常指的是可見光圖像和正常文本。其中,基于標量的圖文相似度具有局限性,無法全面表示跨模態對齊。同時,局部區域—單詞相關性和全局圖像—文本依賴性之間存在復雜的相互作用,所以用于推理兩種模態特征的模塊存在一定程度的不確定性。針對上述問題,文章提出了一種基于層次相似網絡的圖文匹配動態多視圖推理方法。首先,該方法使用了基于標量和基于向量的全局和局部相似度。其次,設計了四種類型的單元作為探索全局—局部相似性交互的基本單位。最后,引入了可學習的選擇置信度機制,在Flickr30K和MSCOCO數據集上的實驗展現了算法的卓越性能。
關鍵詞:跨模態檢索;圖文匹配;動態交互算法;相似度預測
中圖分類號:TP391;TP399 文獻標識碼:A 文章編號:2096-4706(2024)17-0056-06
0 引 言
鑒于多媒體數據(尤其是圖像—文本對)的迅速增長,研究人員致力于在計算機視覺(CV)和自然語言處理(NLP)之間建立聯系。圖像—文本匹(Image-Text Matching)任務[1]獲得了廣泛的關注,該任務主要通過測量可見光圖像與文本之間的相似性,來獲取文本與可見光圖像之間的對應關系。盡管近年來出現了一些圖像—文本匹配的方法,并取得了良好的性能,但由于圖像—文本對之間精確對齊和準確推斷相似性的復雜要求,它仍然是一項具有挑戰性的任務。該任務的一個突出特點是圖像和文本之間存在很大的語義差異,進而影響跨模態檢索性能。為了減少不同模態之間的語義鴻溝,一些研究人員提出了跨模態語義交互方法,以衡量圖像與文本的相關性。通常情況下,這一過程包括對視覺和語言進行對齊,以彌合它們之間的語義差距,然后根據這些對齊計算不同模態之間的語義相似度。如何尋找到可見光圖像和文本之間最優的對齊方式成為一個亟待解決的問題。
1 相關工作
根據相似度的類別,現有方法大致可分為兩類:基于標量的相似度和基于向量的相似度。最近的研究主要集中于基于標量相似度的方法[2-3]。這類方法通常先將圖像和文本特征映射到一個共享的嵌入空間,然后采用特定的交互模式在這個共享空間內度量兩種模態之間的標量相似度。另一方面,基于向量相似度的方法[4]在獲得所有特征之后,會計算圖像和文本之間的向量相似度。然后,這些方法通過推理向量相似度來推斷跨模態語義相關性。上述兩類方法中,有基于全局對齊的交互,也有基于局部對齊的交互。基于全局對齊的方法[5]直接從全局表征的余弦相似度推斷跨模態語義相似性。與基于全局對齊的方法不同,基于局部對齊的方法[6]從局部突出的區域—單詞對中匯總語義相關性。一般而言,大多數基于局部對齊的方法都采用將圖像區域和文本單詞聚合在一起來衡量圖像與文本的整體相關性[7]。雖然這些方法通過采用不同機制獲得最終的相似度,但它們仍然是靜態的,嚴重依賴經驗知識,這可能限制相似性交互,從而影響檢索性能[8]。此外,這些方法通常傾向于使用平均池化等方法將部分局部對齊的信息聚合為全局對齊的信息,這可能導致丟失許多細節的語義信息[9]。
為了解決上述問題,我們的方法通過從多個視圖動態推導向量相似度,并利用標量相似度來調整選擇置信度,以指導最合適的相似度交互選擇。在相似度推理模塊中,我們受到何振華[10]和郁萬蓉[11]的啟發,設計了四c9bcad8fcba1f4125cf4024206c3d746種單元來完成不同相似度交互操作,包含了整體和局部的不同視角下的交互。然后將這四個單元堆疊起來,構建了一個完整的相似度動態交互選擇空間,從而可以考慮各種交互模式。為了確保動態選擇交互模式的合理性和有效性,我們為每個單元配置了可學習的選擇置信度,并且引入了標量相似性作為正則化,以驅動網絡學習更全面、更詳細的矢量相似性。在Flickr30K和MSCOCO數據集上的實驗結果表明,我們的模型可以獲得良好的檢索性能。
2 本文方法
2.1 圖文和相似度表征學習
給定一張可見光圖像I,利用基于He等人[12]提出的ResNet-101的Faster R-CNN[13]實現了自下而上的注意力機制,根據最高的類別置信度得分提取K個突出的區域表征。然后,我們使用一個線性投影ri,將其轉換為D維視覺區域特征。為了獲得每個區域的空間相關性,采用位置編碼方法,充分利用每個區域的邊界框信息Pi,其式為:
其中,FCp(·)表示全連接層。最后,進行區域嵌入和位置嵌入的融合:
對于包含N個單詞的給定句子T,首先使用Devlin等人[14]提出的Bert作為文本編碼器來提取單詞級別的文本語義特征。緊接著,采用不同大小的并行二維卷積核來捕捉更精細的短語特征。然后,將這些核的文本特征級聯起來,再將其傳入全連接層,得到D維的單詞特征,記為:T=[t1;t2;…;tM]∈RM×D。此外,整個圖像I的全局表示vglo和整個句子T的全局表示tglo由注意力機制編碼得到。
受Diao等人[15]提出的SGRAF這一工作的啟發,我們利用局部和全局跨模態之間的向量語義相似度來捕捉特征表示之間更詳細的關聯。將圖像特征vglo和文本特征tglo之間基于向量的全局語義相似度sglo表示為:
(1)
其中,Wg∈Rd×D表示一個可學習的參數矩陣,用于獲得d維向量相似性。∣·∣2和∣·∣∣2分別表示逐元素平方和?2歸一化。我們還使用余弦相似度來衡量圖像和文本之間的親和性,即基于標量的圖像—文本相似度Aglo。
為了得到區域和單詞特征之間的局部相似性表征,我們應用注意力機制的方法來關注每個單詞與每個區域的關系。每個單詞的注意力權重由帶有溫度參數τ的SoftMax函數計算:
(2)
其中,旨在將余弦相似度cij標準化,cij表示區域vi與詞tj之間的余弦相似度,標準化過程如下:
(3)
然后,通過來聚合與位置加強的區域特征匹配的文本上下文。圖像區域特征與其語義匹配的上下文詞語特征之間的局部語義相似度表示為:
(4)
其中,Wl∈Rd×D表示可學習的參數矩陣。將全局和局部的向量語義相似度串聯起來,作為動態選擇空間的初始輸入:。
2.2 動態選擇空間
2.2.1 殘差修正單元(RRC)
直接采用校正線性單位(ReLU)激活函數來設計一個簡單的全視角交互單元,這個全視角交互單元會充當殘差連接中的直接映射部分。我們總結RRC為:。
2.2.2 自我推理單元 (SRC)
為了通過捕捉更全面的互動來增強相似性預測,我們利用自注意力機制來促進相似度之間的傳播。這也是一種全視角的交互方式,其計算式可以表示為:
(5)
其中,Q和K由全連接層得到,表示Q的通道數的平方根。我們總結SRC為:。
2.2.3 全局門控單元(GGC)
局部語義相似度已經包含了豐富的細粒度的局部信息。另一方面,全局語義相似度涉及圖像—文本對的對齊,這是一種粗粒度對齊,包含了上下文語義信息。因此,從不同的角度考慮局部視角和全局視角之間的相互作用是至關重要的。在這個單元中,我們考慮的是全局視角,利用全局相似度來生成指導局部相似度的門閾值。這種方法確保了局部和全局信息的整合,充分利用了它們的互補性,其表述為:
(6)
其中,FCsg/sl(·)表示線性層。我們總結GGC為: 。
2.2.4 局部細化單元(LRC)
為了進一步豐富相似度表示,我們設計了這個從局部視角進行相似度交互的單元。首先同時采用了最大池化和平均池化的方法來降低局部相似度的維度,如。這樣可以有效地聚合局部相似度信息,捕捉細粒度相似度的不同方面,促進對圖像與文本關系的更全面理解。之后,按照Qu等人[2]提出的方法,增強全局表示的語義如下:
(7)
其中,FCω/r(·)表示線性層,用于將映射到縮放權重向量ωr和移動偏置向量中βr。我們可以總結LRC為:。
現在,綜合上文介紹的四個單元,這些單元的輸出可形式化地概括為,其中Fi(·)和分別表示第l層的第i個單元的功能和輸入。
2.2.5 選擇置信度
如圖1所示,為了創建一個動態選擇空間,我們以密集連接的方式在相鄰層之間建立上述四個單元之間的交互關系。這四個單元在每一層內并行配置,同級水平上發揮作用,最大限度地提高了各層的利用率。為了使得動態交互模式成為可能,我們進一步引入了選擇置信度的概念,使得交互模式具有了適應性,每個輸入可根據自身的語義信息執行最合適的交互。這種適應性考慮了各種因素,如復雜性、對象數量和其他相關屬性。因此,每個單元都承擔著不同的角色,并與其余單元保持密切聯系。值得注意的是,我們的交互模式是動態的、可學習的,這與之前的許多靜態方法不同。它既包括現有的交互模式,也包括尚未探索的交互模式,具有更大的靈活性和提高性能的潛力。
選擇置信度得分表示的是從第l-1層的第i個單元到第l層的第j個單元的概率。每個單元的選擇置信度得分由每個單元的輸入計算得出。除第一層外,下一層中某一單元的輸入是通過對當前層中四個單元的輸出進行加權匯總得到的。其中權重就是每個單元的置信度得分。這種加權聚合過程結合了來自不同單元的信息,從而在后續層中更全面地呈現輸入數據。聚合操作如下:
(8)
其中Z表示總層數。在這項工作中,,是計算選擇置信度的函數,具體操作如下:
(9)
這個公式中,FFN(·)表示由多層感知器實現的前饋網絡。ReLU和Tanh都是激活函數,用于將置信度得分映射到[0,1]區間。
在動態相似性選擇的最后階段,我們級聯最后4個單元的輸出,計算出圖像和文本的最終相似度R(I,T),其式如下:
(10)
其中和分別表示最后一層中第i個單元的選擇置信度得分和得到的相似度。WR∈R1×4d表示將級聯后的相似度向量映射到標量相關得分的可學參數。
為了學習選擇置信度,我們收集并級聯來自所有層的所有單元的作為,并將其映射到與向量相似度相同的嵌入空間中:
(11)
其中表示選擇置信度向量,FCc(·)表示全連接層。
2.3 目標函數
我們采用雙向三元組排序損失進行端到端訓練,將匹配的圖像—文本對進行嵌入拉近,同時將非匹配的圖像—文本對嵌入推開。具體過程如下:
(12)
其中λ表示一個邊界參數,R(I,T)表示由上述公式定義的圖像I和文本T的全局表征之間的語義相關性。在一個小批量數據中,最難區分的負樣本文本為,最難區分的負樣本圖像為。在推理階段,利用動態交互模式預測的相關性R(I,T)進行檢索評估。
相似的交互模式應適用于相似的語義相似度。這意味著選擇置信度的分布應與相似度的分布一致。為了使動態交互模式和選擇置信度的訓練過程更加穩定,我們引入了標量相似性Aglo表示正則化項。為了捕捉選擇置信度向量的內部語義依賴性,我們計算其自身的內在相似性,其式如下:
(13)
表1展示了我們提出的DMRSN與不同方法在Flickr30K和MS-COCO數據集上的性能比較。符號“*”是指集合模型。
為了實現相似性和選擇一致性,將正則化項表達為:
(14)
其中,MB是小批量圖文對的數量。和則表示的是第i個樣本對。將上述三重損失L(I,T)與選擇正則化Lsc相結合,得到如下總體目標函數:L=(I,T)+μLsc,其中μ表示一個手動設置的超參數,其目的是平衡兩種類型的損失。
3 實驗分析
3.1 數據集與實驗設置
在實驗中使用了兩個基準數據集來驗證我們方法的性能:1)Flickr30K:Flickr30K數據集包含31 783張圖片,每張圖片有5個相應的標題。2)MS-COCO:MSCOCO數據集包含123 287幅圖像,每幅圖像都有5個注釋標題。我們報告了直接在全部5K測試圖像上計算的評估結果(MS-COCO 5K),以及對1K測試圖像的5次平均的匹配性能(MS-COCO 1K)。
在訓練和推理過程中,Bert和Faster R-CNN只作為特征提取器,其參數被凍結,不加入訓練過程。圖像文本對聯合嵌入的維度D設置為512,語義相似性向量d的維度為256。將溫度參數τ設為9。此外,動態交互模式單元數、選擇層數Z、損失參數λ和權衡參數μ分別設為4、3、0.2和0.5。我們的模型DMRSN在一塊GeForce RTX 2080 Ti GPU上采用Adam優化器來優化模型,最小訓練批量為64,訓練周期為30。學習率設定為0.000 2,每15個階段衰減10%。驗證集上性能最好的參數將被用于測試。
3.2 對比實驗結果及分析
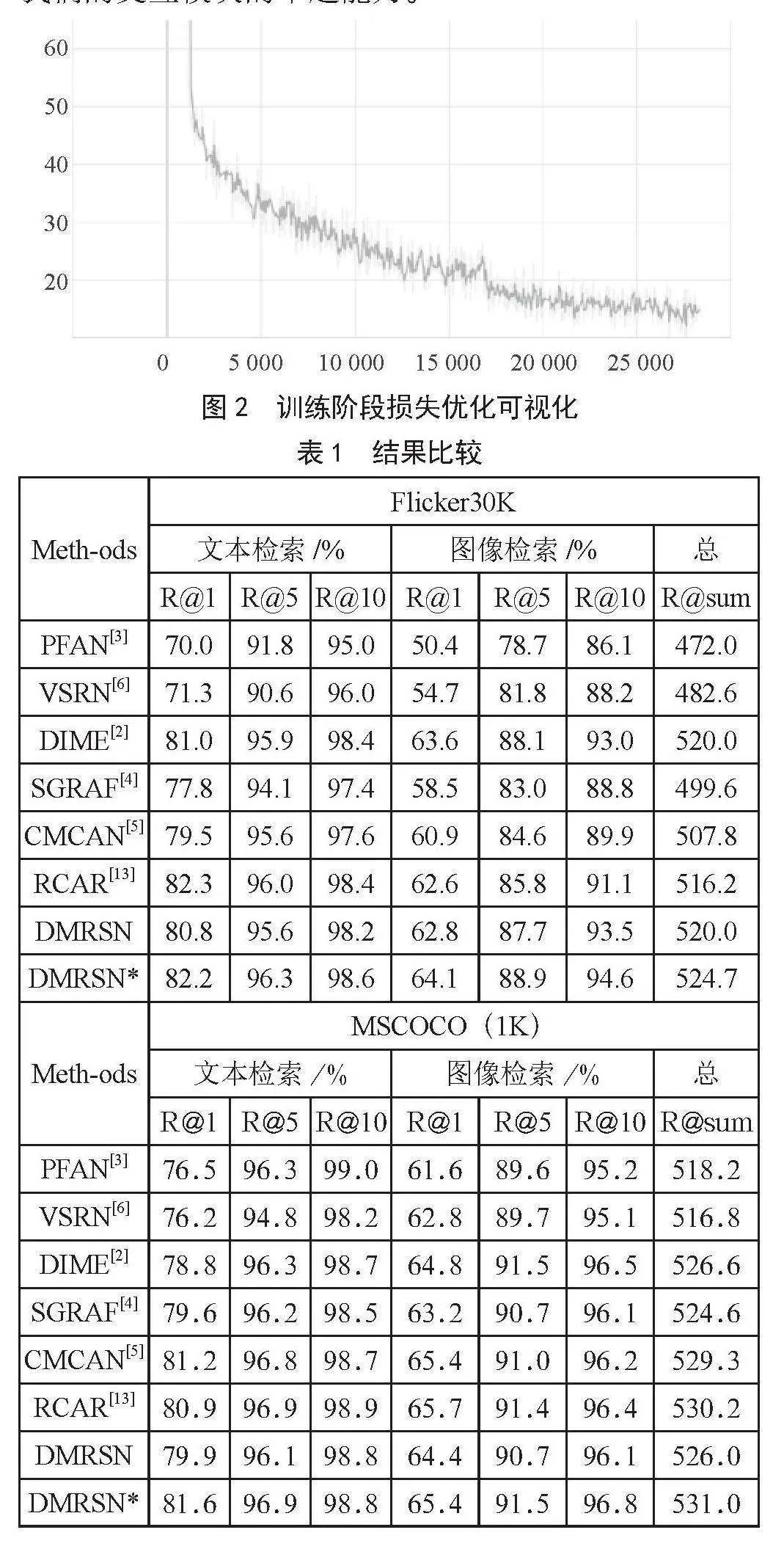
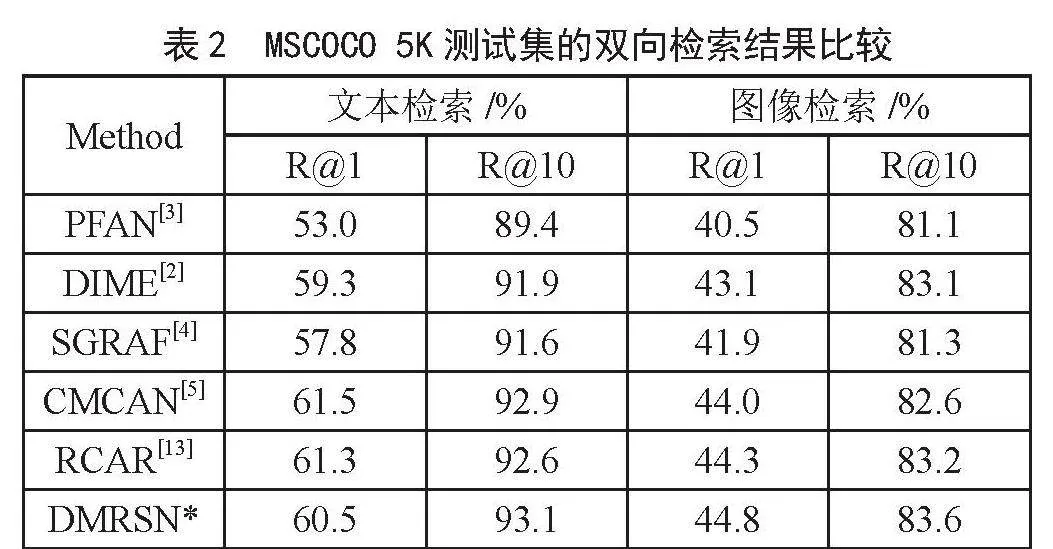
圖2是模型在訓練階段的優化過程。表1左半部分展現了與之前模型在Flickr30K數據集上雙向檢索結果的比較。可以看到,我們提出的DMRSN模型優于所有比較的高性能方法,僅在文本檢索的R@1得分上比RCAR低0.1%。除此之外,在圖像和文本檢索兩個子任務上,我們的模型在所有指標上都比以前的方法取得了更好的結果。與基線模型SGRAF相比,我們的文本檢索R@1提高了4.4%,圖像檢索上R@1提高了5.6%,R@sum提高了25.1%。SGRAF僅從整體角度進行學習相似度之間的語義關系。這些改進說明了動態探索相似性交互模式的可行性和重要性。值得注意的是,我們的單個模型也能實現有競爭力的檢索性能,這是因為全局和局部相似度會經過幾層的動態交互,從而挖掘出最適合的交互模式,這進一步證明了我們模型的有效性和穩定性。表1右半部分和表2分別給出了MS-COCO數據集上1K和5K測試的實驗結果。除了文本檢索的R@10分數和圖像索的R@1比最好的低0.2%和0.3%,我們的模型在其他所有指標上都取得了最好的性能。雖然其在R@10和R@1上的表現可能略低于PFAN和RCAR,但在其他評價指標上的得分卻明顯優于它們。事實上,我們的R@sum分數極大超過PFAN,高出了12.8%。我們的單一模型與一些最先進的方法相比,尤其是和以往集合模型相比,仍然具有很強的競爭力。這進一步證明了我們提出的模型的魯棒性,并顯示了我們的交互模塊的卓越能力。
3.3 消融實驗結果及分析
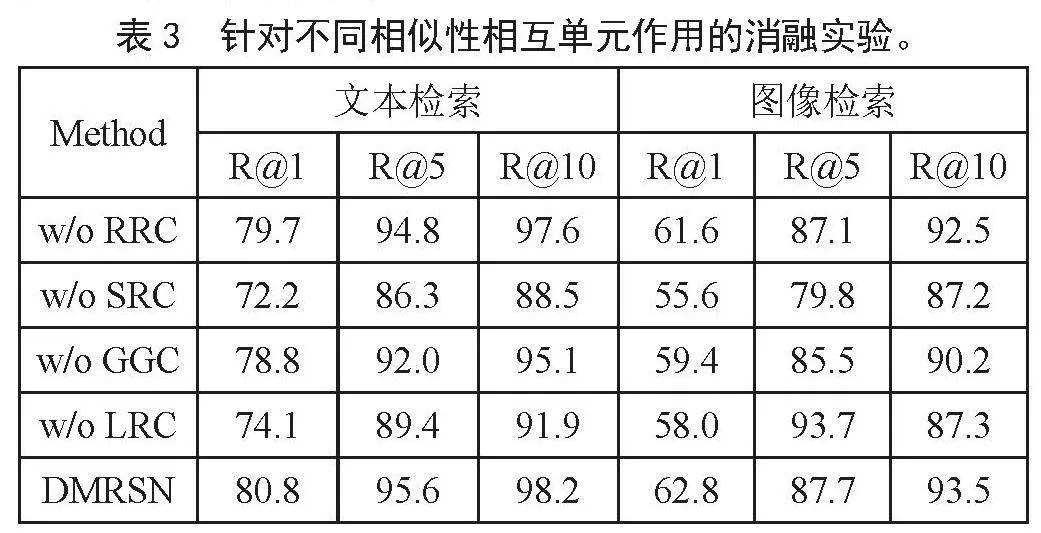
將獨立模型與去除某個單元的變體進行比較。如表3所示,去除SRC(w/o SRC)的性能下降最為明顯,這表明傳播局部和全局相似性之間的整體信息非常重要。我們的模型能取得比去除局部相似性推理單元(w/o LRC)和去除全局相似性推理單元(w/o GGC)更好的性能,這說明從多個視角進行相似性推理也是有效的。此外,w/o GGC的結果優于w/o LRC,這表明局部相似性中的細粒度的語義信息可以更好地用來完善全局相似性。總體而言,我們的模型在所有指標上都優于消融模型,這進一步證明了我們的模型相似性交互單元的有效性。
3.4 可視化結果與分析
將動態選擇空間可視化,如圖3所示,圖中顯示了每張圖像的選擇置信度得分的注意力圖。為簡潔起見,這一置信度可以揭示每張圖片自身的交互模式。由圖3可知,圖像—文本對的相似性越復雜,交互選擇就越復雜,即選擇過程會動態地適應輸入的復雜性,并相應地調整交互模式,以捕捉模式之間錯綜復雜的關系。例如,圖3(b)的簡單實例只激活了相對簡單的交互模式,而圖3(a)的復雜實例則激活了幾乎所有交互模式。這是因為細節更多的圖像—文本對在其矢量語義相似性中包含了更多的語義信息。所以有必要考慮多視角相似性的交互作用。對比兩個例子可以驗證這一觀點。此外,還可以觀察到即使圖像—文本對所包含的信息差別很大,在選擇淺層交互單元時也會存在一些共同點。這些觀察結果表明,我們的模型具備針對不同的樣本動態學習不同交互模式的能力。
4 結 論
在本文中,我們提出了一種新穎的針對圖文匹配的動態多視角推理相似性網絡,這是一個采用多視角來研究相似度動態交互的工作。首先綜合考慮了標量和矢量相似度;其次將推理相似度的視角分為局部到全局視角、全局到局部視角、整體到整體視角;再次將四個交互單元密集連接起來,構建了一個動態的相似性選擇空間,以適應多視角的相似度交互;最后,所有被選中的相似性交互模式都會根據我們提出的選擇置信度進行加權。在兩個基準數據集上進行的廣泛實驗證明了我們模型的有效性和優越性。未來,我們計劃進一步研究相似度的交互模式,更好地將細粒度局部相似度和粗粒度全局相似度聯系起來。并且思考將紅外模態引入檢索任務的可能性。
參考文獻:
[1] ANDERSON P,HE X D,BUEHLER C,et al. Bottom-Up and Top-Down Attention for Image Captioning and Visual Question Answering [C]//2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition.Salt Lake City:IEEE,2018:6077-6086.
[2] QU L G,LIU M,WU J L,et al. Dynamic Modality Interaction Modeling for Image-Text Retrieval [C]//Proceedings of the 44th International ACM SIGIR Conference on Research and Development in Information Retrieval.Virtual:Association for Computing Machinery,2021:1104-1113.
[3] WANG Y X,YANG H,QIAN X M,et al. Position Focused Attention Network for Image-Text Matching [J/OL].arXiv:1907.09748 [cs.CL].[2024-02-16].https://arxiv.org/abs/1907.09748.
[4] DIAO H,ZHANG Y,MA L,et al. Similarity Reasoning and Filtration for Image-Text Matching [J/OL].arXiv:2101.01368 [cs.CV].[2024-02-18].https://arxiv.org/abs/2101.01368.
[5] ZHANG H T,MAO Z D,ZHANG K,et al. Show Your Faith: Cross-Modal Confidence-Aware Network for Image-Text Matching [C]//Proceedings of the AAAI Conference on Artificial Intelligence,36(3),3262-3270.
[6] LI K P,ZHANG Y L,LI K,et al. Visual Semantic Reasoning for Image-Text Matching [C]//2019 IEEE/CVF International Conference on Computer Vision (ICCV).Seoul:IEEE,2019: 4653-4661.
[7] CHEN T L,LUO J B. Expressing Objects Just Like Words: Recurrent Visual Embedding for Image-Text Matching [C]//Proceedings of the AAAI Conference on Artificial Intelligence,34(7),10583-10590.
[8] ZHANG Q,LEI Z,ZHANG Z X,et al. Context-Aware Attention Network for Image-Text Retrieval [C]//2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Seattle:IEEE,2020:3533-3542.
[9] LIU C,MAO Z,LIU A A,et al. Focus Your Attention: A Bidirectional Focal Attention Network for Image-Text Matching [C]//Proceedings of the 27th ACM International Conference on Multimedia.Nice:Association for Computing Machinery,2019:3-11.
[10] 何振華,胡恒博,金鑫等.基于注意力機制的多任務漢語關鍵詞識別 [J].現代信息科技,2022,6(6):82-85+89.
[11] DEVLIN J,CHANG M W,LEE K T,et al. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding [J/OL].arXiv:1810.04805 [cs.CL].[2024-02-18].https://arxiv.org/abs/1810.04805.
[12] REN S Q,HE K M,GIRSHICK R,et al. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks [J/OL].arXiv:1506.01497 [cs.CV].[2024-02-15].https://doi.org/10.48550/arXiv.1506.01497.
[13] HE K M,ZHANG X Y,REN S Q,et al. Deep Residual Learning for Image Recognition [C]//2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR).Las Vegas:IEEE,2016:770-778.
[14] 郁萬蓉.基于多級結構的深度子空間聚類方法 [J].現代信息科技,2022,6(6):100-103.
[15] DIAO H,ZHANG Y,LIU W,et al. Plug-and-Play Regulators for Image-Text Matching [J].IEEE Transactions on Image Processing,2023.32:2322-2334.
DOI:10.19850/j.cnki.2096-4706.2024.17.011
收稿日期:2023-03-20
基金項目:國家自然科學基金(62020106012,U1836218,61672265);中國教育部111項目(B12018)
作者簡介:張書銘(1999.07—),男,漢族,CCF會員,碩士研究生,主要研究方向:圖文檢索、深度學習。
Image-text Retrieval Algorithm of Dynamic Multi-view Reasoning
Hierarchical Similarity
ZHANG Shuming
(School of Artificial Intelligence and Computer Science, Jiangnan University, Wuxi 214122, China)
Abstract: Cross-modal image-text retrieval usually refers to visible light images and normal text. Among them, image-text similarity based on scalar has limitations and cannot fully represent cross-modal alignment. At the same time, there is a complex interaction between local region—word correlation and global image—text dependence, so the modules used to infer the two modal features have a certain degree of uncertainty. In view of the above problems, this paper proposes a dynamic multi-view reasoning method of image-text matching based on hierarchical similarity network. Firstly, the method uses global and local similarity based on scalar and vector. Secondly, four types of units are designed as the basic units to explore the global—local similarity interaction. Finally, a learnable selection confidence mechanism is introduced, and experiments on Flickr30K and MSCOCO data set show the excellent performance of the algorithm.
Keywords: cross-modal retrieval; image-text matching; dynamic inter-action algorithm; similarity prediction
