技術標準AI智能審校技術的研究與應用初探
2024-10-21 00:00:00徐志軍侯紀勇
標準科學 2024年13期

摘 要:《國家標準化發展綱要》指出“將標準研制融入共性技術平臺建設,縮短新技術、新工藝、新材料、新方法標準研制周期,加快成果轉化應用步伐”。隨著科技與經濟的快速發展,技術標準的更新日益加快,涉及的技術愈發復雜多樣,加之技術標準文檔中公式、圖表、文字等細節繁復,傳統的單純依靠人工審校的方式不僅效率低下,而且容易因人為因素導致審校結果不準確、不一致,已無法滿足技術標準制修訂的需要。引入技術標準AI智能審校技術輔助人工審校已成工作之急需。該技術以其高效精準的優勢,能夠快速完成大量文檔的自動化審校,捕捉并提示文檔中的語法錯誤與不合規項,大幅提高審校效率,顯著降低人力成本,提升審校結果的一致性和規范性。
關鍵詞:技術標準,智能審校
1 開展技術標準AI智能審校技術研究與應用的必要性
2021年10月,中共中央、國務院印發《國家標準化發展綱要》,指出“持續優化標準制定流程和平臺、工具,健全企業、消費者等相關方參與標準制定修訂的機制,加快標準升級迭代,提高標準質量水平”。2024年3月,國家市場監督管理總局等十八部門聯合印發《貫徹實施〈國家標準化發展綱要〉行動計劃(2024—2025年)》(國市監標技發〔2024〕30號),指出“持續優化政府頒布標準制定流程、平臺和工具,強化標準制修訂全生命周期管理,加強標準維護更新、升級迭代”。各地方政府標準化主管部門也陸續出臺政策,支持推動加快標準升級迭代,提高標準質量水平。
在國家電網有限公司,數以百計的技術標準文檔審核是一項十分繁重且重要的工作。這些技術標準文檔涉及專業多,細節繁復,既有復雜詳細的技術要求,又有公式、圖表、文字等多種形式的格式要求,其中還有一些文檔篇幅很長至幾百頁。傳統的人工審核方式不僅效率低下,需要花費大量的時間和精力,而且容易因人為因素導致審校結果不準確、不一致。隨著技術更新速度加快,標準制修訂日益增多,專業更加細化,傳統的人工審核方式難以高效應對龐大的工作量。因此,引入技術標準AI智能審校技術輔助人工審校需求迫切。
技術標準AI智能審校技術憑借其高效、準確的特點,能夠快速完成大量文檔的自動化審核,顯著提高審核效率,降低人力成本。同時,該技術能夠精準識別文檔中的語法錯誤和不合規內容,確保技術標準的準確性和規范性,減少人為主觀性錯誤,提高技術標準的質量。該技術應用有助于提升技術標準制修訂的工作效率和管理水平,保障質量。
2 國內外智能審校技術研究與應用概況
國際上,智能審校技術的研究起步較早,并在近年來取得了顯著的進展。在算法模型、自然語言處理等方面,國外的研究機構和企業進行了深入探索,使得智能審校技術在識別文本錯誤、提高文本質量方面表現出色。這些技術已被廣泛應用于新聞出版、教育等多個領域,極大地提高了文本處理的效率和準確性。
在國內,智能審校技術的研究也呈現出蓬勃發展的態勢。研究人員在算法優化、技術融合等方面取得了重要突破,使得智能審校系統能夠更好地適應中文語境,識別中文文本中的錯誤[1]。同時,國內的研究還注重將智能審校技術與云計算、大數據等先進技術相結合,進一步提升審校系統的性能和效率[2]。
總的來說,國內外都在努力推動智能審校技術的發展和應用,在該技術的研究上各有優勢。技術標準的內容審核涉及多個方面,目前暫無十分成熟的通用的技術研究與應用。
3 AI智能審校技術的理論和實踐依據
3.1 理論依據
3.1.1 自然語言處理(NLP)技術
NLP技術是實現文本自動化處理的關鍵,它涵蓋了從詞匯分析、句法分析到語義理解的全方位處理流程[3]。NLP技術為智能審校系統提供了強大的文本處理能力,使系統能夠準確識別并糾正文檔中的語法、拼寫和標點錯誤。在技術標準文檔的內容審校中,NLP技術主要用于構建語法檢查模型、拼寫校正模型和標點規范模型,以提高文檔內容的準確性和規范性。
3.1.2 機器學習算法理論
機器學習算法通過大量數據的訓練,使系統能夠自動學習并改進模型性能[4]。在智能審校中,監督學習、非監督學習和深度學習等算法都能發揮重要作用。對于技術標準文檔中引用其他技術標準的糾錯,機器學習算法可以通過訓練技術標準數據,使系統自動識別并比對技術標準文檔中引用的其他技術標準是否準確。同時,這些算法也可以用于構建文檔格式和排版檢查模型,確保文檔的排版和結構符合特定要求。
3.1.3 基于規則/模板的生成方法
如果規則文件具有一定的結構或模式,可以使用基于規則或模板的生成方法來構建模型。這種方法需要語言學專家手工構造規則模板,并選用特征如:統計信息、標點符號、關鍵字等來進行匹配和生成。雖然這種方法相對簡單且易于理解,但可能需要大量的人工參與,并且對于復雜的規則文件可能不夠靈活。
3.1.4 基于統計的算法
統計方法可以根據規則文件中的數據建立統計模型,如:關聯規則算法(Apriori算法)等[5]。這些算法通過分析數據中的頻率、概率等統計信息來發現規則或模式,并生成相應的模型。統計方法在處理大規模數據集時可能更加有效,但可能需要更多的計算資源和時間。
3.1.5 上下文無關文法(CFG)
在一些情況下可以使用CFG來定義規則文件的語法結構,并將其解析為樹結構或其他易于處理的數據結構。CFG有助于將規則文件中的語法規則轉化為計算機可處理的格式,并支持進一步的邏輯推理和計算。
3.1.6 文檔格式和排版理論
文檔格式和排版理論為文檔的視覺呈現和可讀性提供了指導。在智能審校中,這些理論將用于確保文檔的排版和結構符合技術標準文檔的格式要求。通過應用文檔格式和排版理論,智能審校系統可以構建符合特定要求的格式檢查模塊,如:體例檢查、字體字號檢查、段落格式檢查等。此外,這些理論還可以用于指導上下文中對應關系查驗、表格圖例等相關內容格式糾錯的工作。
3.2 實踐依據
3.2.1 技術可行性
NLP和機器學習技術的發展已經為智能審校系統提供了強大的技術支撐。這些技術已經成功應用于多個領域,包括文檔自動化處理、信息抽取等。因此,從技術上講,技術標準AI智能審校系統的開發和應用是可行的。
3.2.2 現實需求
隨著技術標準制修訂速度的不斷加快和數量的不斷增加,僅僅依靠人工審校已經難以滿足需求。《國家電網有限公司技術標準體系表(2024年版)》,收錄國家電網有限公司企業標準2483項,團體標準361項、行業標準4413項、國家標準4651項和國際標準655項,每年修訂的標準數量多、編審工作量大。在調研中發現,國家電網有限公司存在這種現象和需求,電力行業甚至整個工程建設領域都面臨同樣的情況和需求。因此,通過運用技術手段,輔助相關部門或組織快速高效、高質量地完成技術標準審校的需求變得格外迫切,技術標準AI智能審校技術的研究與應用能夠很好地解決這一問題。
3.2.3 數據支撐
在技術標準AI智能審校技術的研究與應用中,數據支撐至關重要。我們將通過3個途徑獲取數據:(1)國家電網有限公司現有的大量技術標準(企標2483項)數據和文檔數據;(2)爬取互聯網上已公開的海量技術標準數據;(3)聯合相關技術標準出版單位共同開展數據訓練和模型優化,或者購買相關技術標準數據。這些數據將涵蓋多個行業和領域,確保系統能夠廣泛適用于各種技術標準的內容審校。
3.2.4 相似案例
在技術標準AI智能審校技術的研究與應用中,已經有個別的類似項目取得了階段性成果,例如:中國計劃出版社自行開發的工程建設標準智能審校系統,該系統可以提高工程建設行業團體標準的編寫效率和準確性。這些項目通過應用NLP和機器學習技術,實現了文檔內容的自動審核和糾錯。這些已經取得階段性成果的實踐案例為本項目提供了寶貴的經驗。
4 技術標準AI智能審校研究的基本內容
4.1 通用文本糾錯
研究并優化適用于技術標準文檔的語言模型,以提高語法、拼寫和標點錯誤的識別與糾正能力。
研究如何增強系統的上下文理解能力,以便更準確地糾正因上下文缺失或誤解而導致的錯誤。
4.2 標準引用糾錯
首先,對行業標準數據進行收集與整理,構建并維護一個全面的標準數據庫。
其次,研究如何高效存儲、檢索和實時更新標準數據庫,以確保數據的準確性和時效性。
最后,開發高效的算法,確保系統能夠處理各種復雜的引用格式,以識別文檔中對其他技術標準的引用,并將引用的技術標準與標準數據庫中的數據進行比對,確保引用的準確性和一致性。
4.3 格式糾錯
分析并解析技術標準文檔的格式規則,將其轉化為程序可理解的指令或模板。開發一系列算法來檢查文檔的排版和結構是否符合規定的格式要求,包括標題、段落、專業術語、目錄、中英文固定表達方式、引用說明等。
4.4 上下文中對應關系查驗
研究并提取文檔中的上下文信息,并分析其中的邏輯關系和對應關系,開發算法來識別文檔中的對應關系,如:定義與引用、前提與結論等,并檢查其準確性,對于識別出的對應關系錯誤,提供準確的錯誤提示。
4.5 表格、圖例等相關內容格式糾錯
準確識別文檔中的表格和圖例,并提取其相關信息,分析并定義表格和圖例的格式規則,包括尺寸、字體、邊框、顏色、說明等,與規定的格式做比對,對不符合要求的內容給出錯誤提示。識別表格和圖例中的文字,對其正確性和準確性給出參考建議。
4.6 公式符號糾錯
準確識別文檔中的數學公式,并解析其結構和符號,開發算法來檢查公式中的符號是否正確,包括符號類型、大小、位置、說明等,對于識別出的錯誤符號,提供準確的替換建議。
4.7 引用標準糾錯
準確識別文檔中的引用標準,與構建的標準庫進行匹配和對比,開發算法來檢查引用技術標準的標準號和名稱是否準確,是否為現行的最新標準,對于識別出0c8a9dbaea7cda1f95780341d320fc01af00ea24caa144ba51c9cfe77b8e36b0的有疑問的技術標準,提供準確的替換建議。
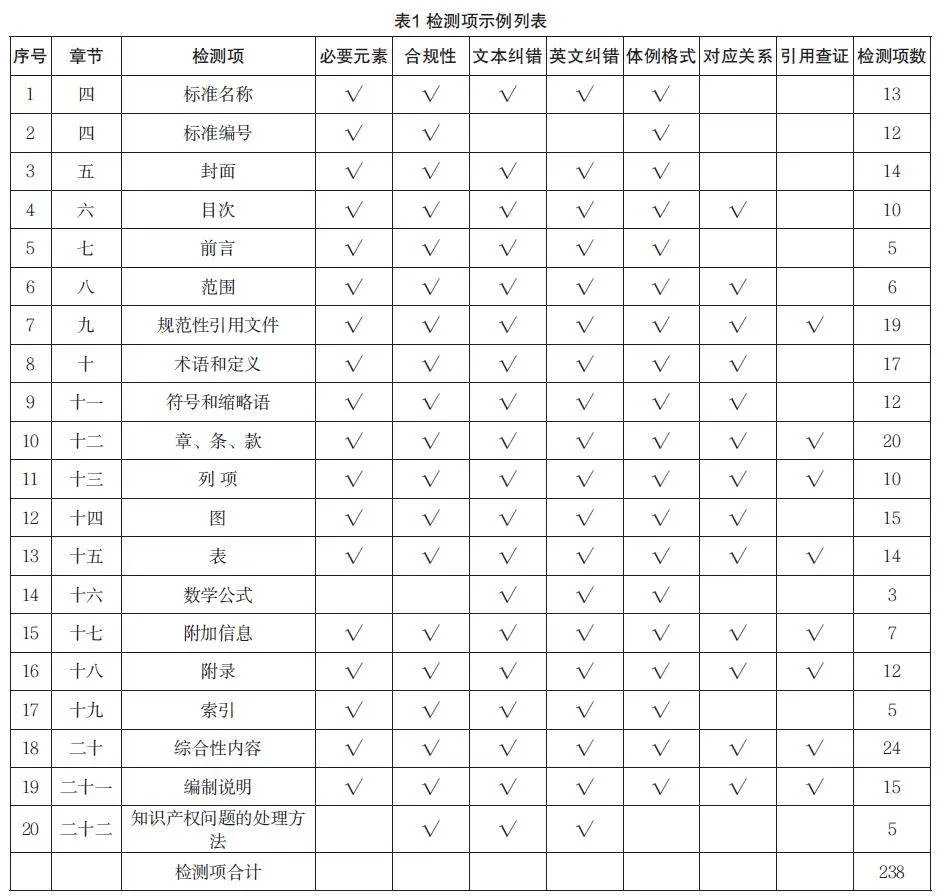
4.8 檢測項
依據《國家電網有限公司 技術標準制修訂手冊(第二版)》[6],具體檢測項示例列表見表1。
5 預期目標和成果形式
5.1 預期目標
技術標準AI智能審校技術與應用基于強大的自然語言處理能力以及各種審校算法,糾正文檔中的語法、拼寫和標點錯誤;精確識別并比對大量標準數據,確保文檔引用的準確性;按照特定格式要求自動檢查文檔的排版和結構;處理包括上下文對應關系查驗、表格與圖例格式糾錯和公式符號糾錯等在內的復雜審校任務。
技術標準A I智能審校技術的應用,將顯著提高技術標準規范文檔的內容審核效率和準確性,極大推動技術標準制修訂工作的規范化與標準化進程。
5.2 成果形式
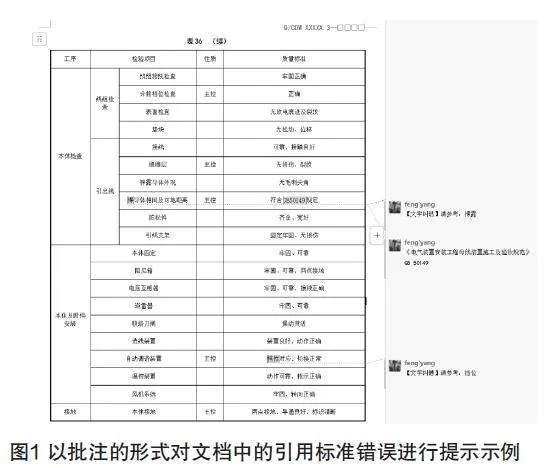
對于技術標準中使用AI智能審校技術識別出來的不符合規范的內容以及文本錯誤,系統可以不改變文檔的原內容,而以批注的形式插入到文檔中,這樣能夠保持文檔的完整性和原始性,便于審查者迅速定位問題,并清晰記錄修改建議和討論內容,有助于團隊協作和后續修改,同時提升文檔的可讀性和管理效率。
以批注形式進行錯誤提示的展示示例見圖1和圖2。
以上兩個圖例為批注形式示例,系統對有異議和錯誤問題進行批注展示,并不對原文內容進行更改,由審核人進行人工確認。
6 展 望
智能審校技術,包括基于人工智能的圖像識別、文本審校等功能,近年來得到了快速發展,能夠顯著提升審校效率,大幅降低人工成本。通過自動化處理和高效審核,提高標準內容發布的速度與質量,減少了錯誤風險,有著顯著的社會效益和經濟效益[7]。
隨著版本的不斷迭代升級,未來的技術標準AI智能審校系統將在保持體例邏輯檢查、格式檢查等優勢的基礎上持續改良,不斷精進,具備更強的自主學習和決策能力。通過不斷的學習和優化算法模型,系統將能夠自動識別和分析文本中的錯誤和不合規項,提高審校的智能化程度,加快技術標準編制迭代,提高技術標準質量水平,推動我國標準化工作和相關行業規范快速發展。
參考文獻
[1]劉長明,高國連,楊勇,等.智能審校的應用和探索——以“ 方正智能輔助審校系統”為例[ J ] . 出版與印刷,2020(03):12-16.
[2]羅學科,黃瑩.出版人工智能賦能:內容生態重塑與產消圖景互構[J].中國編輯,2022(02):27-31.
[3]喬寶榆.基于NLP的輔助審稿系統設計與開發實踐[J].中國科技期刊研究,2024,35(06):798-804.
[4]李金亮.基于深度學習的中文標點符號審校算法研究[D].成都:西南交通大學, 2018.
[5]馬曉平,曹少中,李旸.基于優化Apriori算法的印刷檢測數據關聯分析[J].北京印刷學院學報,2024,32(06):22-26.
[6]國家電網有限公司科技創新部.國家電網有限公司技術標準制修訂手冊:第二版[ M ] .北京:中國電力出版社,2021.
[7]龍啟銘.人工智能時代下智能審校的應用探析[J].傳播與版權,2022(06):39-41+45.
