圖像生成技術的教與學:穩態擴散模型的深入解析與教學應用
2024-10-01 00:00:00林榮輝
中學理科園地 2024年5期
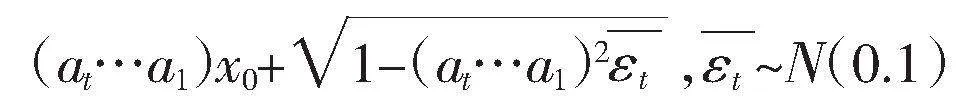

摘 要:在自動圖像字幕技術掀起的AI繪圖浪潮中,以Stable Diffusion為代表的圖像生成新機制既給世間審美派送了杏花疏影,又為智能倫理引進了煩亂紛擾。既然《義務教育信息科技課程標準》與《普通高中信息技術課程標準》皆有“了解人工智能的新進展、新應用”的相關要求,那么此項機器學習領域的最近應用理應成為中學信息技術(科技)教學領域的新入口,而基教階段人工智能的施教者也應該迎接它所攜帶的新挑戰。因此,對人工智能繪圖機制的進化脈絡,對Stable Diffusion數理模型的分析解構,對AI圖像生成的教學適配便成了必要的研究內容。
關鍵詞:穩態擴散模型;AI繪圖;人工智能教學;信息科技;信息技術
計算機視覺是基教階段人工智能教學的關鍵組成,其“觀感”特性天然可與審美傳達產生關聯,因此計算機視覺的教學理應融合與之相配的美學屬性。然而,高教階段計算機教學與美學界域的交集寥寥,同時基教階段實施教育美育融合的門檻較高,導致眾多信息技術(科技)從教者雖理得清算法脈絡,敲得出數理邏輯,辨得明計算思維,卻描不下九州露霜,涂不出故鄉月光,繪不盡紅塵過往。
可喜的是,自2015年掀起的計算機視覺創新浪潮,特別是自動圖像字幕技術加持下的機器學習,實現了對圖像領域內元素對象的文本標記。而當研究人員拓展思維過程,將文本描述翻轉輸出為新圖像時,現實世界難以自然融合的畫境圖景便呈現在世人面前了。穩態擴散(Stable Diffusion,下同)模型便是此次創新浪潮中的典型技術代表。考慮到該技術在互聯網上的開源傳播廣度與技術共享深度,普通的技術學科教師也可借助文本描述詞或短語組合,在智能教學中開展圖像生成與審美融合的探索。
1 圖像生成模型的歷史脈絡
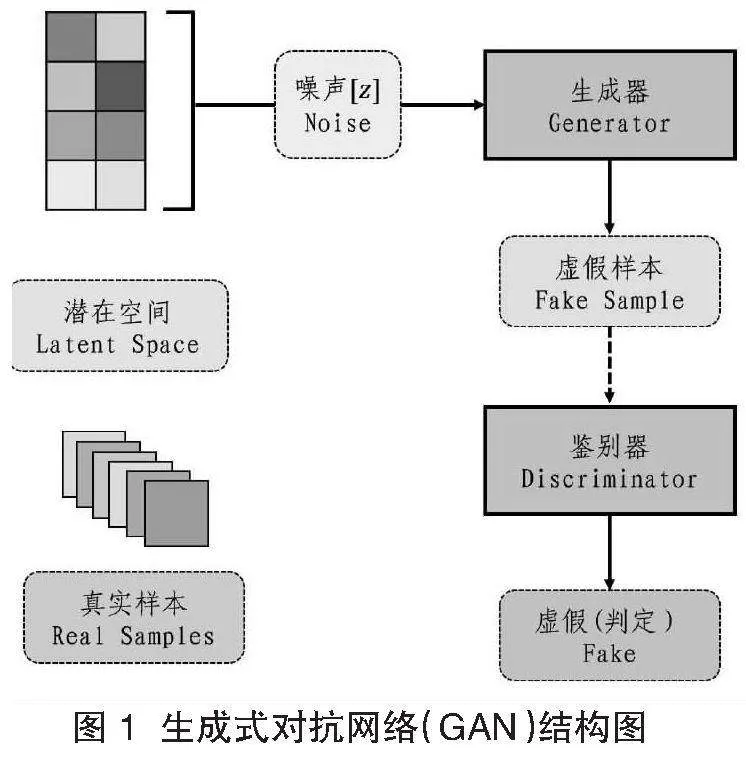
機器學習技術應用于圖像生成的歷史并不短暫,在穩態擴散模型令人驚異地面世之前,2018年,一副由人工智能生成的畫作在嘈雜的爭議中以43.5萬美元在藝術品拍賣會上被售出。該幅《埃德蒙德·貝拉米肖像(Portrait of Edmond Belamy)》的畫作生成,依靠的是名為生成式對抗網絡(Generative Adversarial Network,GAN)的深度學習模型(圖1)。此模型首先經由非監督學習機制訓練符合要求的特定數據集(原件),隨后創建網絡副本,接著依托生成模型(generative model,GM)和鑒別模型(discriminative model,DM)令兩者同步受訓并博弈判斷原件和樣本之間的差異,最后反饋結果。以對抗生成網絡為代表的有條件圖像生成方法具有較強的屬性表達辨別力和泛化力,但需要特定領域的知識信息支撐,從而導致屬性獲取過程較為復雜[ 1 ]。
相對而言,另一類屬性描述手段—通過自然語言賦予空間視覺元素的策略則創建了一條更加普適與輕巧的生成途徑,即依附生活化的文本表達,串聯映射圖像特征數據集,以此生成能與文本描述詞協調共鳴的,甚至具有豐富畫面細節的像素組件并使之拼裝呈現。
2021年1月,一家名為OpenAI的人工智能研究公司首先發布了圖像生成引擎DALL-E,該引擎為用戶構建了可以根據文字描述創建更逼真、更準確圖像的能力[ 2 ],同時支持無縫編輯。同年6月,Midjourney平臺也宣布收費支持文本生成圖像。2022年8月,Stable Diffusion公司將其同名圖像生成模型(即穩態擴散模型)在Github網站公開發布。因其開源屬性,該模型的昭布脫離了盈利模式的約束,任何技術人員通過短期訓練,便可在硬件條件滿足(主要是顯示芯片與顯存大小門檻)后自由搭建“擴散型”圖像生成平臺。至此,“擴散型”圖像生成模型在世界范圍飛速傳播。
2 “擴散型”圖像生成模型機制
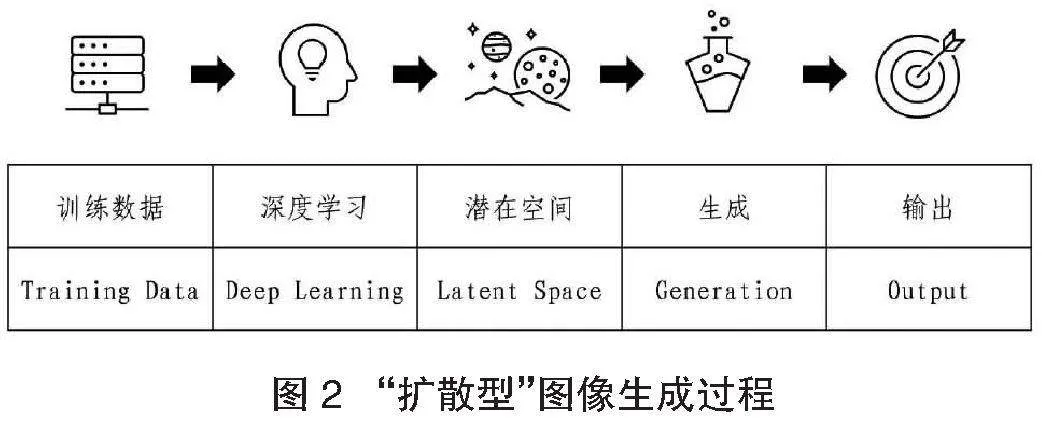
要使圖像生成器能快速響應文本描述,“擴散型”生成模型需要一個龐大且多樣化的訓練數據集。一般來說,為改善圖文的可訪問性和可搜索性,互聯網圖源在發布對象時,大多會為圖像同步搭配與之毗連的替代文本。因此以上訓練數據集通過網絡“抓取”的公眾圖源大概率一并包含圖片與文字描述。但與搜索引擎的機理不同,如圖2所示,用戶提交文本提示時,“擴散型”生成模型的運作并非依照查詢結果,定位訓練數據集中的相關圖像,然后復制像素信息完成組合,而是借助深度學習模型的“潛在空間”(Latent Space)以高維方式標記文本并生成圖像。
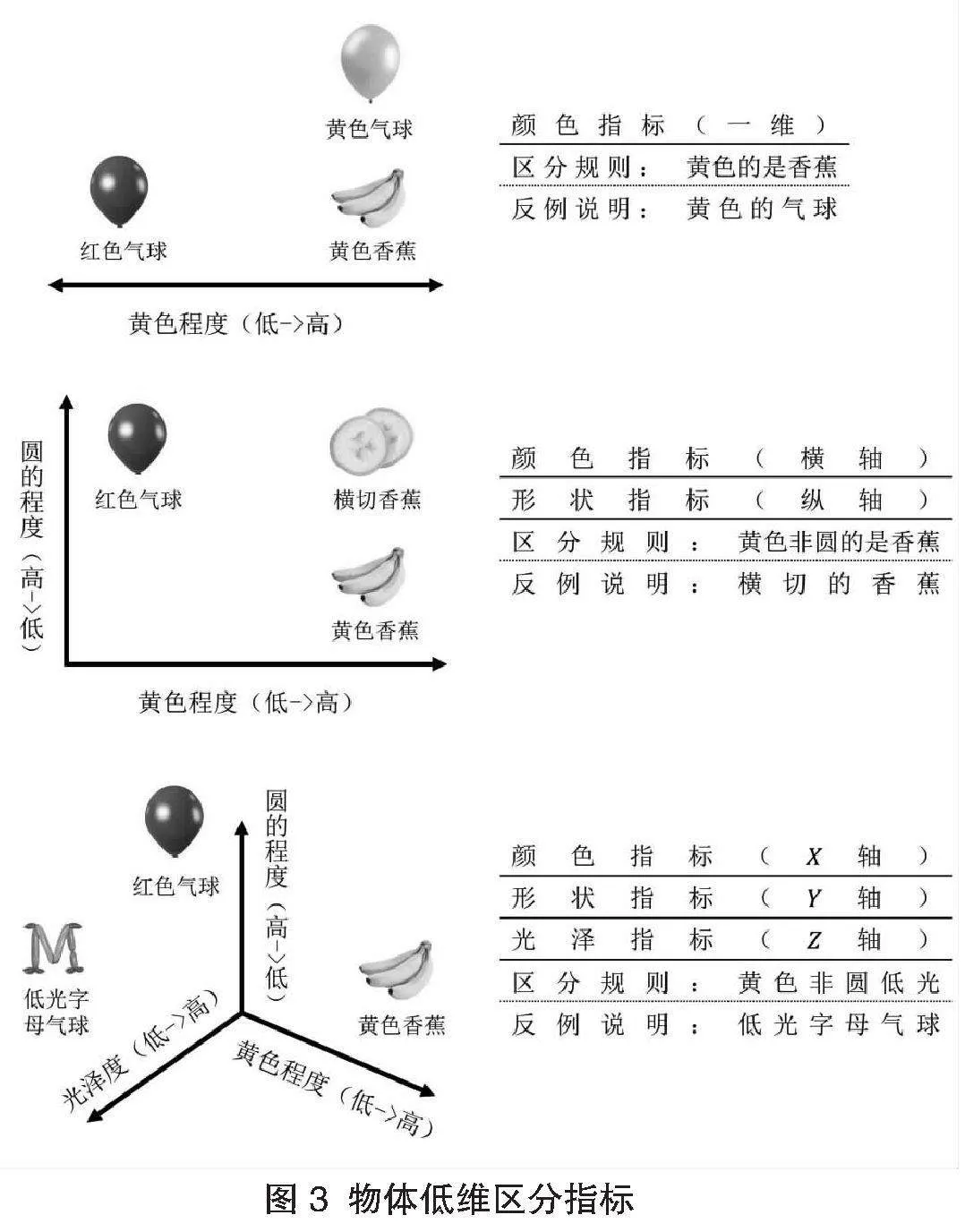
以常見物體香蕉的識別為例,以圖3為例,若以單一色深程度(即黃色程度)作為識別物體的線性指標,模型雖可有效分辨香蕉(黃色)與氣球(紅色)的特征差別,但面對同色氣球(黃色)樣本時,一維指標顯得力不從心。此時,若補充以圓形程度為基準的新指標,“擴散型”模型對物體的識別指標便由一維線性擴展為二維平面樣式。之后,隨著指標排他性性狀的不斷確認,伴隨判定指標體系的延展增維,高維識別模型可大幅強化對指標空間的狀態擴展,進而構建指標眾多、屬性各異的分類標簽。
此即“擴散”模型中深度學習算法在遍歷數據集時的運行機理。在具體實現上,算法在遍歷流程時側重指向提升模型效率的變量,構建了與變量等量且高維的數學空間。雖然在一般情況下,人類無法理解多維空間的高階架構,但穩態擴散模型可提供至多500個維度的潛在空間支持。這所謂的潛在空間代表了現有人類都無法識別或命名的變量集合,其間的任何一點都可視為由文本提示出發,指標體系導航而最終可達的圖像答案。由于導航過程中的一些隨機屬性干預,模型無法為固定文本輸入返回同樣固定的結果,因為數據集、訓練模型的源生差異,會導致潛在空間定位的迥然不同。
3 穩態擴散模型的數理邏輯
在文本導航與圖像生成之前,“擴散型”模型還需要將潛在空間中的一個點轉換為實際圖像,該過程即“擴散(diffusion)”機制。“擴散”流程從圖像噪聲輸入開始,經歷一系列的隨機值輔助推導,最終將像素排列為對人類有意義的構圖。
可見,穩態擴散模型以圖像去噪為初始目標,此類機制與早期圖像生成方法,例如以對生成式對抗網絡為代表的直接圖像法或以概率統計分布為代表的變分自編碼(Variational Autoencoders,VAEs)器件近似,生成過程皆起源于輸入的隨機噪聲Z,通過神經網絡層疊加持,由機器學習手段將其轉化為樣本數據X。早期生成式模型受制于從噪聲到清晰圖像的單步轉換,具體為輸入的噪聲僅借助單一模型生成數據樣本,生成的圖像往往質量欠佳。縱然單步生成的模型在現代算力支持下也能改善效果,但需要龐大的模型與海量的時間作為代價。
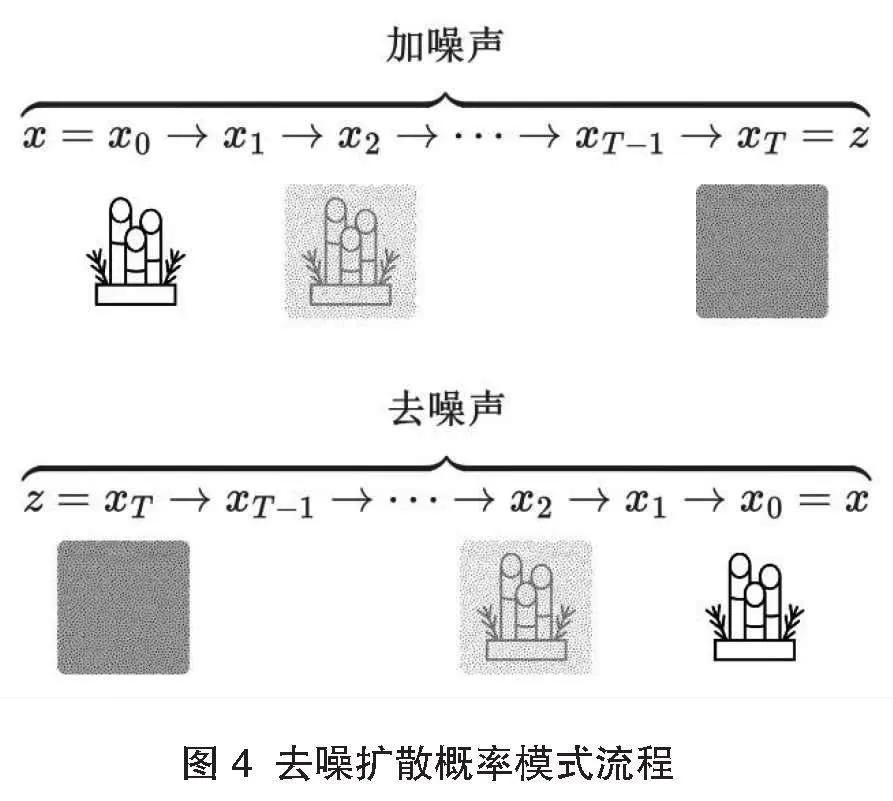
為改善運行效率,穩態擴散模型使用去噪擴散概率模式 (Denoising Diffusion Probabilistic Model,DDPM),利用逐次細分的加噪/去噪聲周期,規避單一模式的低效陷阱。如圖4所示,去噪擴散模式一般由清晰的圖像啟動,而后圖像在細分周期中逐漸融合噪聲。隨著數據與狀態的遞推傳遞,圖像噪聲的比重同步增大。至XT位置時整個圖像完全轉化為噪聲Z。反之同理,逆向處理流程從輸入噪聲開始,圖像按細分步驟逐漸去噪,最終重構回清晰樣態。
3.1 加噪過程分析
由xt到xt-1的遞推公式
xt=atxt-1+βtεt,εt~N(0.1)
可得:
xt表示圖像遞加噪進程第t步的狀態,該狀態首先由上一階段xt-1乘上權重at,加上隨機噪聲εt與權重βt的乘積實現,其中εt滿足0~1之間的正態分布。其次,累加過程中的兩個權重at和βt滿足固定平方和公式:
at2+βt2=1
即權重at和βt滿足一個恒定狀態,此固定關系為后續的狀態推導提供穩定支撐。在正向加噪流程中,權重βt與時間關聯,隨著噪聲比重的提高同步增大。若合并以上遞推過程和關系狀態,可得完整的加噪通項:
3.2 去噪過程分析
通常,去噪過程只需將加噪過程反向推導即可。例如,在加噪過程中,xt的狀態已知,at和βt也由恒定狀態綁定,余下的變量和階段依靠代換順序導入迭代就好。但此想法忽略了一個不可控對象—在加噪過程添加的隨機噪聲εt。此歸屬于正向流程的隨機值換位至去噪過程時,系統無法通過反推得出其原本取值。為解決這個問題,模型需要添加新的神經網絡以供“學習”出εt。此過程滿足公式:
由加噪環節可知,βt隨著時間的增大而不斷增大,因此,由該值構成的損失函數也隨時間增長而同步增大,同理居于分母位置at2的同步減小。εt關聯新創建的神經網絡而t為噪聲強度。整體訓練過程在輸入噪聲后開啟,逐步進行隨機噪聲的機器學習模擬,而后反復迭代直到對象重新變為清晰的圖像。
3.3 穩態擴散模型生成圖像的要點
穩態擴散模型憑借編解碼模型和創新性地文本控制,大大降低了傳統機器學習的時間復雜度,也解放了非專業人群體驗AI繪圖的桎梏。
(1)時間復雜度大幅改善
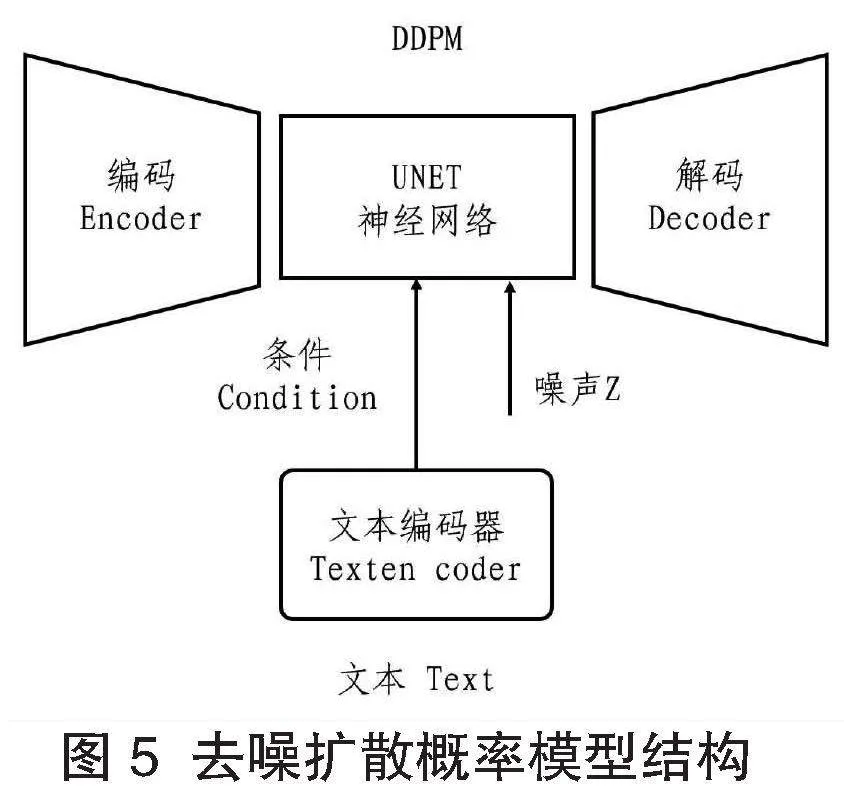
如圖5所示,穩態擴散模型預先訓練了編碼與解碼模型,令其對輸入圖片進行降維編碼,而后于潛空間上處理去噪擴散概率模型。此流程將輸入的圖像規格,由512×512編碼為64×64,而后進行去噪擴散,獲得重構結果后再通過解碼最終還原成512×512的真實圖像。經過這個編碼與解碼的組合過程,圖像生成的整體耗時有了質的飛躍。
(2)橋接文本控制條件
同圖5,穩態擴散模型在獲取輸入噪聲的同期引入文本描述作為新條件,用噪聲和文本各得到一個對應輸出。然后由兩個輸入的加權平均得到真實噪聲,最后以權重調整文本對輸出結果的影響力。
4 圖像生成效果影響要素
生成式繪圖通過“擴散式”模型,從數據中提取圖像的細分要素,于此模型操作者僅需理解文本提示規則,便可復制藝術家或工作室的風格而無需拷貝他們的真實圖像。圖像生成的效果,除受基礎模型成熟程度的影響,還受文本描述詞與圖片尺寸/形態的制約。
4.1 文本描述詞
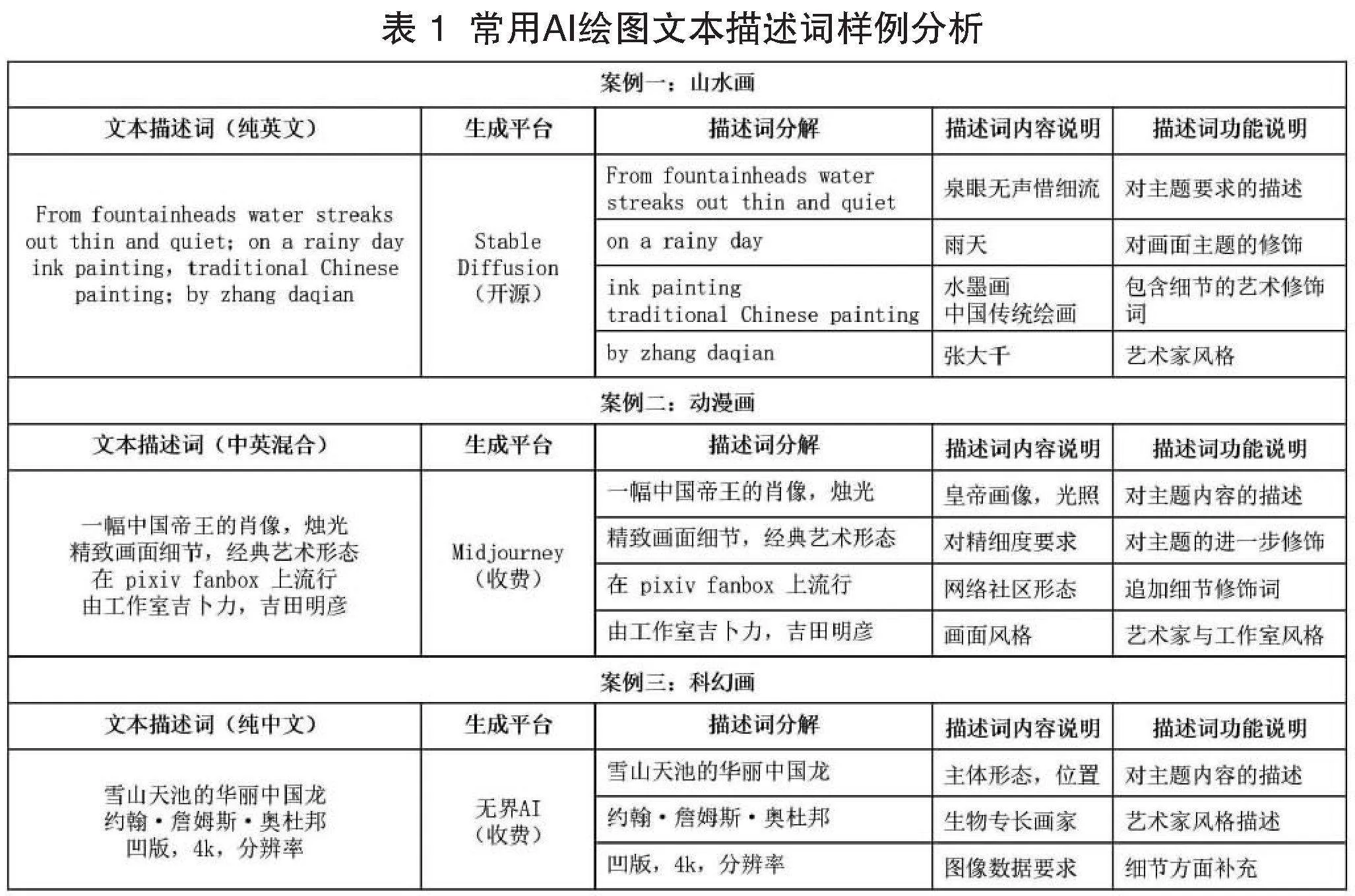
初嘗智能繪圖的用戶,其挫敗感多源自文本描述內容難以駕馭或畫面美感與預期設想的不匹配。這里文本描述詞的使用門檻主要是用戶對關鍵詞輸入結構和修飾詞語的不熟悉造成的。
如表1,案例一為純英文描述詞指向“張大千”風格的山水畫,案例二為中英混合導向“吉卜力”風格的動漫畫,案例三則趨向純中文描述的中式虛幻畫。不同語種的案例組合分別對應中外主流智能繪圖平臺。從描述詞結構可見,各平臺文本描述雖有差異,但總體都包含對主題內容的期望、對畫面主題的進一步修飾、對專業藝術家或工作室風格的參考以及其他細節方面的修飾四個部分。
4.2 圖片尺寸與形態
除文本描述詞,尺寸與形態也對繪圖的呈現效果產生重要的影響,例如畫面的橫縱比例,場景的橫豎形態等,都對畫面效果有作用:
(1)人像類畫作類型的構筑建議選擇1:1方圖,如若選取了豎圖或者橫圖,可能會出現兩個或者多個人臉疊加現象的,即常被社群用戶戲稱為的“買一送一”。
(2)構建風景、想象、山水等崇尚空間結構的畫作類型時,優先推薦豎圖或者橫圖。特別是計劃輸出山水畫、風景畫與大場景的情況。
以上標準并非絕對,一名優秀的智能藝術創作者可以通過多種手段駕馭尺寸的邊界,而且生成模型普遍具有意識隨機性,創作中時常需要經多次迭代才能輸出令人滿意的作品。
5 人工智能圖像生成與教學適配
基礎教育階段人工智能課程體系并沒有具體的國家標準,教材選用也沒有規范指標,因此教學內容的選擇和目標的確定往往取決于實施教師,所需資源也更偏向于教師自身從互聯網上搜索到的可用數字化材料[ 3 ]。生成式智能繪圖技術的高度話題性和充足的趣味性,為基教階段的人工智能教學帶了新情境和新入口,伴隨其發展歷程的版權爭議性與藝術性討論也為初高人工智能教學提供了遼闊的思辨空間。
5.1 智能繪圖引入教學的屬性增益
教育部《普通高中信息技術課程標準(2017年版2020年修訂)》對人工智能的學業要求中指出:“(學生能)了解人工智能的新進展、新應用,并能適當運用在學習和生活中”[ 4 ];《義務教育階段信息科技課程標準(2022年版)》在第四學段(7-9年級)人工智能與智慧社會部分的教學提示中也提到:“通過對人工智能應用的分類和分析,引導學生發現其中存在的不同實現方式,認識各種實現方式的計算過程,了解其適用的場景”[ 5 ]。依表2,基礎教育階段初高信息技術(科技)課程標準皆鼓勵在人工智能教學中引入新應用與新接口。同時,作為最具活力的信息科技前沿領域,人工智能技術的快速迭代本就具有即時性與顛覆性的特征。響應時下尖端技術,符合教學對象對新生事物的渴求;智能繪圖新接口的教學導入,即以文本描述詞對教學情境的改善或師生實踐手段的改進,也與生成圖像的隨機規則一道,為算法比重頗高的人工智能技術原理教學增添了趣味性,還為受矩陣排布和卷積計算困擾的基教師生彌補了因審美傳遞受高校專業領域限制而難以實施的缺憾。
5.2 智能繪圖技術的爭議性與教學實施的挑戰
生成式智能繪畫技術,本源上是依仗海量人類藝術家的公開著作,連同基于現代互聯網“抓取”的開源畫作,萃取佳作集群的構圖、色彩、風格等物料進行的“再創造”。該過程的知識產權歸屬,依所屬平臺規則的差異大相徑庭。不僅如此,“擴散型”圖像生成過程中潛在空間形成的“黑盒”機制、于互聯網“抓取”元素對象的道德/法律規避案例,連同各閉源/開源平臺非公開數據集的“暗部”內容等等,都令未成年學習者可能面對的繪畫作品充滿了不確定性。再者,以網絡技術為核心的網絡空間成為意識形態領域最難以預測的變量[ 6 ],結合互聯網偏向英語信息、偏向西方概念的特性,繪畫學習來源是否代表人群均衡權重,是否代表宏觀人類文化形態也始終存疑。以上內容極大地擴充了基教階段人工智能教學中的倫理討論區間,也對人工智能施教者自身“技術式敘事”與“中國化敘事”的能力提出了更高也更靈活的要求。
軟件如此,硬件亦然。以穩態擴散模型的開源搭建為例,其顯示芯片的高標準與最低8G的顯存需求讓現有基于“因材施教”與“依財適配”的校園信息化建設決策者變得局促不安。從教師與學校的視角來看,目前學校開展人工智能教學的基礎應用和基礎支撐,都依賴于高等教育階段形成的成熟的計算機科學研究體系。而這一體系的認知本源考察手段,對基礎教育階段的人工智能教學提出了過高的要求,直接將其應用于基礎教育階段,不僅加劇了現有信息技術與信息科技教師學科專業知識和培養體系的不完善之間的矛盾,也導致了高等教育階段培養的智能人才與基礎教育階段需要的智能人才之間的錯位越來越嚴重。
總之,一味逃避上游人工智能的前沿成果,無視當下媒體對前沿科技的恐慌解讀,回避智能教學的新情境與新領域并非長遠之計。以一燈傳諸燈,終至萬燈皆明。智能繪圖技術的公平妙趣,使得教師在個人發展與智能教學之間有了細化的選擇,也令眾人皆能以文本統御機器,化解意愿與圖像之間的障礙,消弭視畫和虛擬之間的隔閡,最終引導人類文化合作方式的革新。
參考文獻:
[1] 王宇昊,何彧,王鑄.基于深度學習的文本到圖像生成方法綜述[J].計算機工程與應用,2022,58(10):50-67.
[2] 云熙.風口上的AI繪畫:藝術,還是生意?[EB/OL].https://www.ithome.com/0/650/662.htm.2022-11-02.
[3] 林昉.學習科學視域下的中小學人工智能教學資源應用策略[J].中國信息技術教育,2022(12):35-37.
[4] 中華人民共和國教育部.普通高中信息技術課程標準(2017年版2020年修訂)[S].北京.2020:人民教育出版社.2020:28-29.
[5] 中華人民共和國教育部.義務教育課程方案和課程標準(2022年版)[S].北京.北京師范大學出版社,2022:41-42.
[6] 方旭.論新時代意識形態領域重大風險的防范與化解[J].理論視野,2021(9):53-59.
