基于靜態博弈和遺傳算法的多智能體博弈策略生成方法
2024-09-19 00:00:00劉東輝鄭贏營暢鑫李艷斌
無線電工程 2024年6期
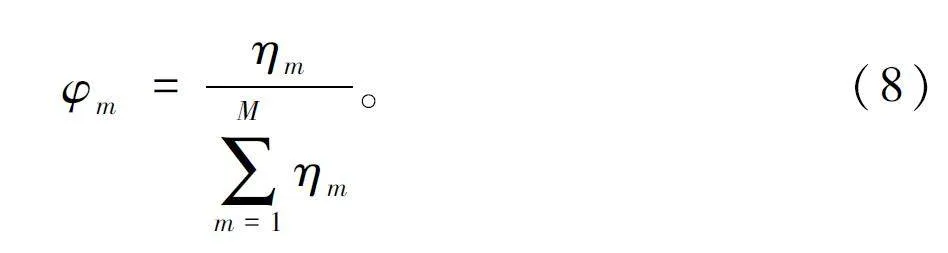
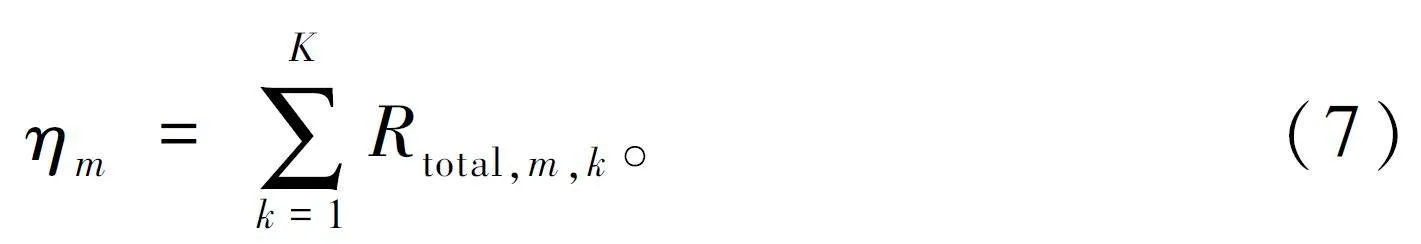

摘 要:在多智能體協同對抗策略生成的過程中,獎勵稀疏和神經網絡參數多易導致策略生成速度慢。針對特定場景如何快速產生對抗策略這一問題,提出了一種基于靜態博弈和遺傳算法的多智能體博弈策略生成方法。基于靜態博弈理念,對馬爾科夫決策過程演化,將策略映射為一串動作組成,簡化策略映射原理;對策略優化問題數學建模。以對抗結果作為目標函數,基于動作集合優化目標函數,通過優化的方法能夠獲得對抗結果最優的策略;給出策略優化框架,并改進遺傳算法實現對于多智能體博弈策略的快速并行尋優。實驗結果表明,相比于經典多智能體強化學習方法,所提方法能夠高效產生多智能體博弈策略。
關鍵詞:靜態博弈;遺傳算法;策略生成
中圖分類號:TN929. 5 文獻標志碼:A 開放科學(資源服務)標識碼(OSID):
文章編號:1003-3106(2024)06-1355-06
0 引言
隨著人工智能技術的發展,近年來在各控制領域不斷取得亮眼表現,如人機博弈[1]、無人駕駛[2]和智慧醫療[3-4]等。特別是對于多智能體協同管控的現實客觀需求,使得智能策略生成和優化技術快速發展,多智能體博弈策略生成方法成為當前的研究熱點。
在實踐過程中,面臨的典型問題為:對手策略或者環境較為固定的情況下,如何快速生成對抗策略。傳統方法采用強化學習方法通過估計當前狀態的狀態轉移過程和動作分布從而估計出得到最大值獎賞值的策略[5-10],如深度Q 網絡(Deep Qnetwork,DQN)、Soft ActorCritic (SAC)。但是,隨著實體個數的增加導致部分可觀測信息和狀態信息的維度增加,神經網絡維度增加,進一步引起神經元參數收斂困難,從而導致神經網絡難訓練引起策略生成和優化失敗。多智能深度強化學習方法被提出用以解決該問題,具有代表性的方法是QMIX[11]和Qtran[12]等。除此之外,強化學習需要動作具有良好的反饋,但是在工程落地過程中,存在中間態指標多維度高難以最終結果作為目標進行擬合,從而引起在強化學習領域中較難處理的“回報稀疏”問題[13-14],但是從對抗結果衡量策略效果較易實現。如在文獻[15]中,任務是否成功可以直接通過判斷無人機是否達到指定位置,但是僅依靠終局結果很難對深度神經網絡進行訓練,所以基于課程學習思路引入了遷移性評估指標對獎賞空間在數學表征上進行稠密化[16]。但是該方法并不通用,原因在于需要對領域知識的深刻理解形成專家知識牽引智能模型進行訓練。故針對特定策略產生對抗策略的關鍵問題在于如何在稀疏獎賞的引導下生成對抗策略。文獻[17]在雷達探測策略假定的情況下,梳理出智能干擾設備可調整的干擾參數。基于任務目標構建目標函數和約束函數,采用元啟發算法對參數進行優化,從而產生最優對抗策略。該方法對博弈過程采用靜態建模,在整個過程中,雷達在特定模式下初始參數和行為模型固定,所以干擾參數數值求解,并形成靜態對抗策略。但是,在動態博弈過程中,需要通過動作組成策略。策略內的動作間會變化,需要針對動態場景進行改進[18]。
針對該不足,基于靜態博弈理論[19],提出面向動態場景的多智能體博弈策略生成方法。對馬爾科夫決策過程演化,將策略映射為一串動作組成,簡化策略映射原理。將策略優化問題轉化為數學尋優問題。以對抗結果作為目標函數,基于動作集合優化目標函數,獲得對抗結果最優的策略。除此之外,構建并行優化框架,改進遺傳算法實現對于多智能體博弈策略的快速并行尋優[20]。實驗結果表明,相比于經典多智能體強化學習方法,本方法能夠高效產生多智能體博弈策略。
本文余下內容結構組織如下:第1 節詳細推導并闡述基于靜態博弈理論的策略優化模型,為后續第2 節提出的方法奠定了基礎,并在第3 節通過實驗驗證本方法的有效性,最后總結全文。
1 基于靜態博弈理論的策略優化模型
基于博弈論,策略π 是由一系列動作a 構成的。
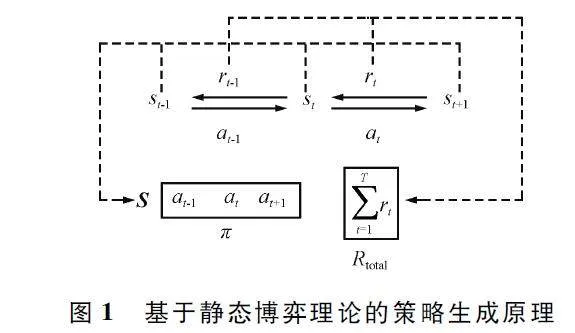
馬爾科夫決策過程的本質也是在數學上尋找到由狀態st 到at 的映射過程,其中st ∈S,S 為狀態空間;at∈A,A 為動作空間。在針對特定策略這一假設前提下,對手策略的狀態動作映射較為固定。對手策略的狀態動作映射可以弱化為策略標簽,用于區分不同對手策略。進一步,可以弱化對于對手狀態st 的特征提取過程,使策略π 直接施加于對手策略上,通過對抗結果進行反饋。上述演進過程如圖1 所示。
從最優化角度分析可知,對手策略和博弈環境可以固定為博弈函數f,策略博弈產生結果的過程可以表述為:
Rtotal = f(π), (1)
式中:Rtotal 為總獎賞。
Rtotal = ΣTt = 1rt。(2)
在典型對抗環境中,中間獎賞較難獲得,需要通過獎賞塑形等大量的專業領域才能構成,所以最直觀為采用最終結果作為獎賞:
Rtotal = rT 。(3)
最優策略即為使得博弈函數最大的策略,即優化目標為:
π* = argmax π f(π), (4)
式中:π 為由一系列動作構成的策略,π 為所有可能的動作組合成的策略集合,π 為最優策略。
該模型的優勢在于能夠有效地解決獎賞稀疏的問題。在智能決策應用場景中,通過結果設計獎賞函數較為容易,如將目標擊毀個數轉化為獎賞分值[15]。但是,在博弈過程中,通過結果設計獎賞會使得大部分時間沒有獎賞值,無法預測獎賞值出現時間,無法準確評估動作的有效性,指引策略的收斂方向。而采用領域知識可以使得獎賞稠密,如將智能體與目標之間的距離或者將抗干擾跳頻時選擇的信道間隔轉化為獎賞值[15,18],有助于策略加速收斂。但是,需要領域專家根據場景需求設計,容易引入主觀因素導致收斂在局部最優策略。所以,針對上述矛盾,依據靜態博弈理論,在獎賞稀疏的假設前提條件下,將馬爾科夫決策過程演化為靜態優化問題,明確目標函數,將策略優化問題完全數學化表征,使得策略可以通過數學優化方法進行求解,規避了馬爾科夫決策過程在獎賞稀疏條件下策略生成困難的弊端。
2 基于遺傳算法的策略生成方法
得益于在理論層面將動態博弈問題簡化為了優化問題,使得采用遺傳算法能夠快速找出博弈過程中的最優動作排序,并將其映射為策略,從而實現針對特定策略的快速生成。但是,對于遺傳算法而言,其計算量大且耗時的部分在于需要計算種群中每個個體的適應度,故提出并行優化框架對方法進行加速。后續本節分為兩部分,詳細闡述基于遺傳算法的策略生成方法,分別為并行求解框架和優化方法。
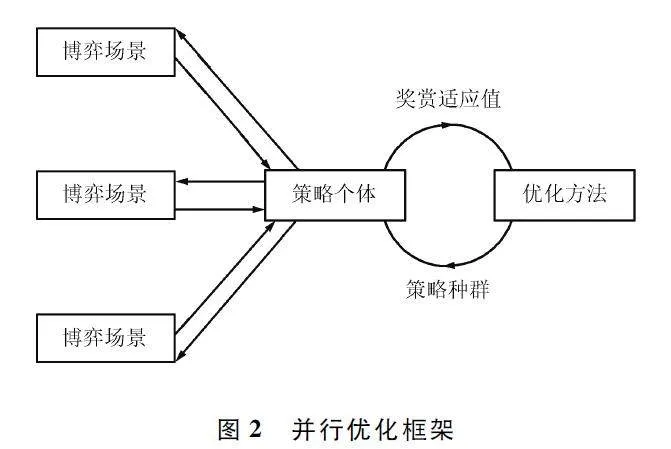
2. 1 并行優化框架
并行優化框架如圖2 所示。整個并行優化過程闡述如下:首先,構建由一系列動作作為基因組成策略個體,再將多個策略個體組成策略種群。在該階段,需要根據對抗時長和受控體的個數相乘得到策略個體中包含的動作基因個數。然后,每一個策略個體在博弈場景中與對手策略對抗,將獎賞作為每個策略個體的適應值返回。在此過程中,利用并行進行多個策略個體的對抗,能夠快速獲得。最后,將策略種群和個體依次對應的獎賞適應值傳入優化方法。優化方法過濾并生成新的策略種群,并進入下一次策略優化環路。由基于靜態博弈理論的策略生成數學優化模型一節的數學分析過程可以看出,作為核心理論,其在實施層面具有良好的并行化能力,從而使得并行化框架的構建成為可能,并將結合硬件算力大幅度提升策略優化的性能。
2. 2 優化方法
在優化過程中,需要完成策略的數學化表達。假設在多智能體對抗環境中,智能體個數為N,在博弈期間需要執行動作次數為T,每次執行離散動作。故策略個體π 由N×T 個動作基因組成,即:
π = [a1 ,a2 ,…,aT ]NT 。(5)
當策略種群由M 個策略個體組成時,策略種群π 可以表示為:
π = [π1 ,π2 ,…,πM ]M ×NT 。(6)
構建多個線程L,線程之間相互獨立。針對不同策略個體的開展K 次博弈對抗,得到與個體相對應的獎賞適應值:
當所有策略個體對應的獎賞適應值計算運行完成后,按照獎賞適應度由高到低,對策略種群π 中的策略個體π 排序。
根據策略種群π 獎賞適應值進行個體獎賞適應值的歸一化,對于第m 個策略個體π,其種群選擇概率為:
根據個體策略的獎賞適應值對種群進行過濾,保留指定數量M′個獎賞適應值排名靠前的策略個體。除此之外,在剩余策略個體中,隨機抽取2 個策略個體進行拼接形成新策略個體并放回種群中,該過程可以通過數學表達為:
π′1 = [π1 [1:t′],π2 [t′ + 1:T]], (9)
π′2 = [π2 [1:t′],π1 [t′ + 1:T]], (10)
式中:π1 和 π2 為隨機抽取出的策略個體,π1′和 π2′為拼接后的策略個體,t′為隨機生成的拼接位置,t′∈NT,隨機概率門限為ε1 。
為了進一步提高策略種群的搜索能力,對種群中的個體進行動作基因突變操作。遍歷新生成策略種群中每個動作基因,以概率門限為ε2 為基礎進行隨機變異。當超過變異門限時,從可選動作范圍內隨機選擇一個離散動作進行替換。
經過上述過程的迭代,最終即可獲得最優策略個體和其對應的最優獎賞適應值。
3 實驗驗證
實驗驗證由實驗場景、實驗設計、參數設置和結果分析四部分組成。
3. 1 實驗場景
為了能夠有效驗證本方法的有效性,采用DeepMind 和暴雪公司開發的基于“星際爭霸2”的多智能體對抗環境(StarCraft MultiAgent Challenge,SMAC)進行實驗[21]。SMAC 內置基線對抗策略,用于驗證策略效果。除此之外,由于典型用于多智能體策略對抗的深度強化學習需要對應場景進行超參數調整,該典型場景公認性較高,故均基于此環境進行開發和調試,其對照算法的超參數可以直接獲得。采用SMAC 環境中名稱為“3m”的多智能體同構場景進行驗證。
3. 2 實驗設計
實驗過程共設置步長為106 ,分為訓練階段和評估階段,以5 000 步為周期循環。在訓練階段,設置種群訓練門限為5 000 步。在該階段內,對種群內個體進行適應度并行計算和交叉變異。當每種群運行步數超過5 000 步進行一次性能評估。在性能評估階段,與基線策略對抗24 回合。衡量對抗策略的有效性,最根本在于評估勝率,故在實驗中用勝率作為評估指標。對于勝率而言,計算24 回合內與“3m”場景的基線策略對抗獲勝的次數,再除以總回合數得到勝率。除此之外,在實驗過程中,將QMIX和ValueDecomposition Networks (VDN )方法在“3m”場景中的勝率和平均獎賞作為對照組,驗證本方法的性能。除此之外,VDN 和QMIX 方法分別使用以結果作為獎賞的非獎賞塑形和SMAC 環境提供的獎賞塑形。在判斷勝負的基礎上,SMAC 環境提供的塑形獎賞通過受控體之間的位置關系和生命值等特征構建了獎賞函數。通過設置對照實驗,用于展示獎賞稀疏對于典型算法的影響,突出該問題解決的必要性,并驗證了本方法在解決該問題上的有效性。
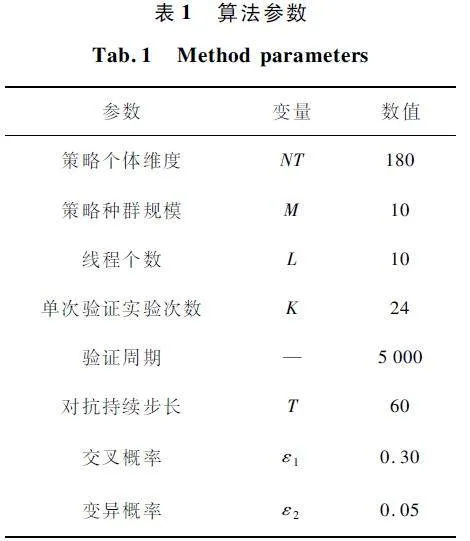
3. 3 參數設置
本文實驗所用到的算法參數如下表1 所示。
3. 4 結果分析
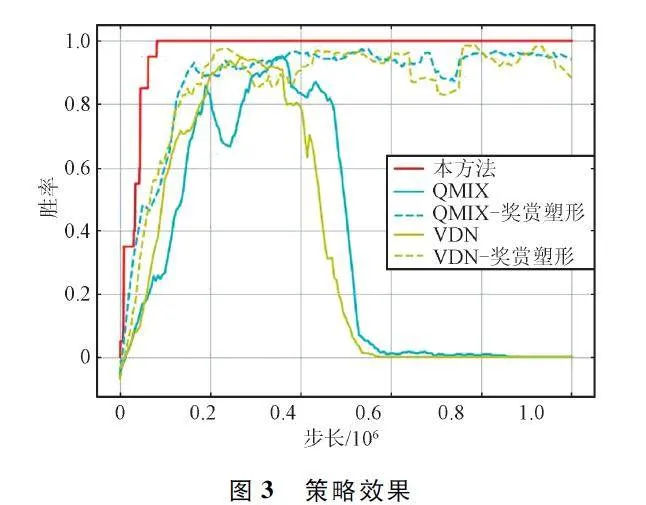
策略效果如圖3 所示,展示了本方法、VDN 和QMIX 隨訓練步長增加的勝率變化趨勢。在圖3中,“VDN-獎賞塑形”和“QMIX-獎賞塑形”表示采用SMAC 提供的獎賞塑形進行訓練得到的博弈策略,而VDN 和QMIX 表示僅通過勝負關系構建獎賞得到的博弈策略。從對比采用獎賞塑形和非獎賞塑形的2 種方法可以看出,采用獎賞塑形的方法勝率提升趨勢較為穩定,而采用非獎賞塑形的由于獎賞反饋稀疏,在實驗初期勝率提升較慢,且在實驗中后期出現明顯的勝率衰退現象。雖然通過保存最大勝率對應的神經網絡參數的方法使其不至于出現嚴重衰退,但是勝率無法與塑形獎賞相比。相比之下,雖然本文方法、“VDN -獎賞塑形”和“QMIX -獎賞塑形”都能夠達到最大勝率,但是本文方法速度快且穩定,且能夠有效避免由于獎賞稀疏導致的性能衰退。
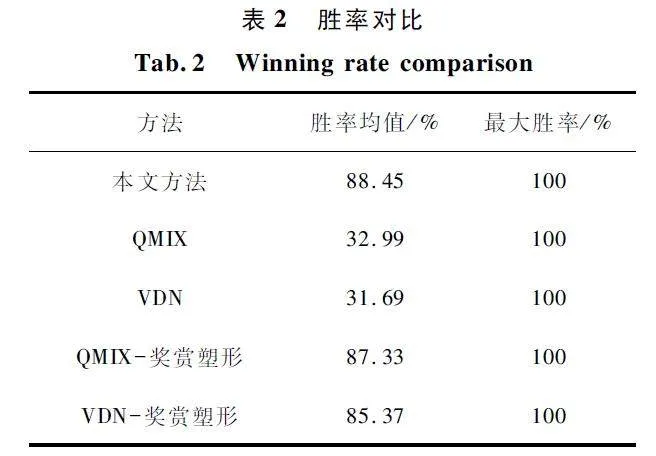
為了進一步量化對比方法性能,對5 種方法的勝率求取均值和最大值,如表2 所示。5 種方法均能夠達到最大勝率,但是通過勝率均值可以發現,本文方法相比于其他方法的勝率均值最大,表明本文方法相對穩定。
綜合圖3 和表2 的勝率趨勢和量化勝率,可見本文方法在針對特定對手策略時,在獎賞稀疏的情況下,能夠快速且穩定地生成對抗策略。
4 結束語
針對特定策略如何快速產生對抗策略這一問題,結合博弈論中的靜態博弈理論和遺傳算法,提出了一種改進的多智能體博弈策略生成方法。在理論層面,基于靜態博弈理念,對馬爾科夫決策過程演化,將策略映射為一串動作組成,簡化策略映射原理。在理論基礎上,對策略優化問題數學建模。以對抗結果作為目標函數,基于動作集合優化目標函數,通過優化的方法能夠獲得對抗結果最優的策略。在實現層面,設計策略優化框架,并改進遺傳算法實現對于多智能體博弈策略的快速并行尋優。在實驗中,將典型多智能體強化學習方法作為基線,通過與基線方法對比,表明了本方法產生策略的高效性,并且展現了本文方法基于并行方法能夠有效提高策略生成與優化速度。
參考文獻
[1] MNIH V,KAVUKCUOGLU K,SILVER D,et al. HumanLevel Control through Deep Reinforcement Learning[J].Nature,2015,518:529-533.
[2] FENG S,SUN H W,YAN X T,et al. Dense ReinforcementLearning for Safety Validation of Autonomous Vehicles[J]. Nature,2023,615:620-627.
[3] ZHU Y,LIANG X F,WANG T T,et al. MultiinformationFusion Fault Diagnosis of Bogie Bearing under Small Samples via Unsupervised Representation Alignment Deep Qlearning [J]. IEEE Transactions on Instrumentation andMeasurement,2022,72:3503315.
[4] ZHU M X,ZHU H G. Learning a Diagnostic Strategy onMedical Data with Deep Reinforcement Learning [J ].IEEE Access,2021,9:84122-84133.
[5] MNIH V,KAVUKCUOGLU K,SILVER D,et al. PlayingAtari with Deep ReinforcementLearning [EB / OL ].(2013-12-19)[2024-03-06]. https:∥arxiv. org / abs /1312. 5602.
[6] HASSELT H V,GUEZ A,SILVER D. Deep ReinforcementLearning with Double Qlearning [C]∥ Proceding of theThirtieth AAAI Conference on Artifical Intelligence. Phoenix:AAAI Press,2016:2094-2100.
[7] SCHAUL T,QUAN J,ANTONOGLOU I,et al. PrioritizedExperience Replay[EB / OL]. (2015 - 11 - 18 )[2024 -03-06]. https:∥arxiv. org / abs / 1511. 05952.
[8] HAARNOJA T,ZHOU A,ABBEEl P,et al. Soft Actorcritic:Offpolicy Maximum Entropy Deep ReinforcementLearning with a Stochastic Actor[EB / OL]. (2018 - 01 -04)[2024-03-06]. https:∥arXiv:1801. 01290v2.
[9] HAARNOJA T,ZHOU A,HARTIKAINEN K,et al. SoftActorcritic Algorithms and Applications[EB/ OL]. (2018-12-13)[2023-09-06]. https:∥ arXiv:1707. 06347v2.
[10] WANG Z Y,SCHAUL T,HESSEL M,et al. Dueling NetworkArchitectures for Deep Reinforcement Learning [C]∥Proceeding of the 33rd International Conference on MachineLearning. New York:JMLR. org,2016:1995-2003.
[11]RASHID T,SAMVELYAN M,WITT C S D,et al. MonotonicValue Function Factorisation for Deep Multiagent Reinforcement Learning [J]. Journal of Machine Learning Research,2020,21(1):7234-7284.
[12]SON K,KIM D,KANG W J,et al. QTRAN:Learning to Factorize with Transformation for Cooperative Multiagent Reinforcement Learning [EB/ OL]. (2019 -05 -14)[2024 -03 -06]. http:∥arXiv. org/ abs/ 1905. 05408.
[13]WANG X,CHEN Y D,ZHU W W. A Survey on CurriculumLearning [J]. IEEE Transactions on Pattern Analysis andMachine Intelligence,2022,44(9):4555-4576.
[14] OKUDO T,YAMADA S. Learning Potential in Subgoalbased Reward Shaping [J ]. IEEE Access,2023,11:17116-17137.
[15] 暢鑫,李艷斌,趙研,等. 基于MA2IDDPG 算法的異構多無人機協同突防方法[J]. 河北工業科技,2022,39(4):328-334.
[16] YIN H,GUO S X,LI A,et al. A Deep ReinforcementLearningbased Decentralized Hierarchical Motion ControlStrategy for Multiple Amphibious Spherical Robot Systemswith Tilting Thrusters [J]. IEEE Sensors Journal,2024,24(1):769-779.
[17] CHANG X,LI Y B,ZHAO Y,et al. A MultiplejammerDeceptive Jamming Method Based on Particle Swarm Optimization against Threechannel SAR GMTI [J]. IEEEAccess,2021,9:138385-138393.
[18] LIU S Y,XU Y F,CHEN X Q,et al. Patternaware Intelligent Antijamming Communication:A Sequential DeepReinforcement Learning Approach [J ]. IEEE Access,2019,7:169204-169216.
[19] 阿維亞德·海菲茲. 博弈論[M]. 劉勇,譯. 上海:上海人民出版社,2015.
[20] ENGELBRECHTA P. Computational Intelligence:An Introduction[M]. New Jersey:Wiley,2007.
[21] SAMVELYAN M,RASHID T,WITT C S D,et al. TheStarCraft Multiagent Challenge[C]∥ Proceedings of the18th International Conference on Autonomous Agents andMulti Agent Systems. Montreal:International Foundutionfor Autonomous Agents and Multiagent Systems,2019:2186-2188.
作者簡介
劉東輝 女,(1990—),博士,講師。主要研究方向:復雜系統管理、策略優化等。
鄭贏營 女,(1998—),碩士研究生。主要研究方向:復雜系統管理。
暢 鑫 男,(1990—),博士,高級工程師。
基金項目:國家自然科學基金(71991485,71991481,71991480);中國博士后科學基金(2021M693002)
