基于卷積神經網絡和NCC 的兩階段的多尺度高精度定位的模板匹配算法
2024-08-23 00:00:00蒲寶林張衛華蒲亦非
四川大學學報(自然科學版) 2024年4期






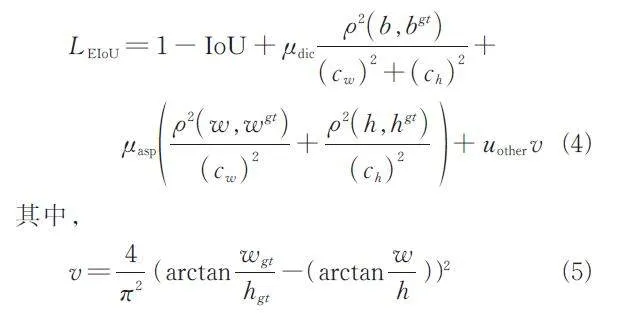
摘要: 當前模板匹配算法中,基于灰度的模板匹配算法具有較好的穩定性和魯棒性. 但是對于大型圖像和復雜模板,它可能需要大量的計算資源和時間. 此外,在應對目標尺度變化較大時,基于灰度的模板匹配算法匹配效果較差. 對于NCC 算法自身速度較慢的問題,本文對NCC 算法進行了改進,減少了平均36% 的匹配時間. 為了應對多尺度的問題,本文結合卷積神經網絡,提出了基于卷積神經網絡和NCC 的兩階段的多尺度高精度定位的模板匹配算法.其中,在一階段目標檢測階段,本文在YOLOX 算法的基礎上改進了主干網絡和損失函數,改善了算法的計算速度以及匹配成功率,并利用一階段目標檢測的結果使二階段NCC 算法動態調整模板大小,極大地減少了NCC 算法大規模制作模板時間,最終使得整體匹配精度遠遠高于傳統基于灰度的模板匹配算法.
關鍵詞: 模板匹配; 多尺度; 卷積神經網絡; 兩階段; YOLOX
中圖分類號: TP391. 41 文獻標志碼: A DOI: 10. 19907/j. 0490-6756. 2024. 043004
1 引言
模板匹配是常用的圖像處理技術,其目的是在圖像中定位與給定模板最相似的局部區域,從而找到與模板最匹配的位置或目標. 其在計算機視覺和圖像處理領域具有廣泛的應用,例如目標檢測[1]、人臉識別[2]、運動跟蹤[3]和遙感圖像分析[4]等. 通過選擇合適的模板和匹配度量指標,可以實現對圖像中感興趣目標的定位和識別.
基于灰度的模板匹配算法,如歸一化互相關NCC(Normalized Cross-Correlation)算法通常表現可靠,但在處理圖像變形、遮擋等問題時受到限制. 為提高準確性和魯棒性[5],需要結合其他技術,然而這會增加執行時間. 基于灰度的算法本身處理速度較慢,因為需要進行復雜的計算,如像素級別的灰度比較和相關性計算. 而且,當目標發生明顯旋轉時,算法需要執行更多的計算和搜索操作[6],進一步延長處理時間. 為了解決處理速度問題,Kai 等[7]改進了基礎NCC 算法,將計算歸一化互相關的模板表示為矩形基函數的和,然后為每個基函數而不是整個模板計算相關性. 該算法在速度上優于歸一化互相關算法的基于傅立葉變換的實現. Chen 等[8]利用旋轉、縮放比較的窗口圖像生成NCC 模型,結合圖像金字塔搜索和SIMD 并行計算,降低算法總耗時. 同時模板匹配算法在處理圖像中目標大小的變化時也存在一定的挑戰[9]. 傳統模板匹配算法使用固定大小的模板,無法應對目標尺度變化. 多尺度模板增加了計算時間,不適合工業應用. 需要尋找更合理的方法應對目標大小變化,實現高效圖像匹配.
近年來,基于深度學習的模型大量涌現[10-13],其中卷積神經網絡(Convolutional Neural Networks,CNN)[14]在特征提取任務中具有顯著的優勢和廣闊的前景. CNN 能夠利用卷積操作對輸入數據進行局部感知. 這種局部連接的方式使得網絡能夠更好地捕捉圖像和其他二維數據中的局部特征,例如邊緣、紋理和形狀等. 通過逐漸堆疊多個卷積層,網絡可以學習到更高層次的抽象特征,從而實現更準確的目標匹配和特征提取. CNN 中的參數共享機制使得網絡能夠高效地處理大規模數據. 通過共享參數,網絡可以在不同的位置上學習到相同的特征. 這種共享能力使得CNN 對平移、縮放和旋轉等圖像變換具有一定的不變性,從而提高了目標匹配和特征提取的魯棒性. 目前主流的算法模型分為以SSD[15]、RetinaNet[16]和YOLO[17-21]系列等為代表的單階段檢測算法模型和以R-CNN[22-24]系列為代表的雙階段檢測算法模型. 單階段的檢測算法既能滿足檢測精度,又在速度上更有優勢.
根據以上分析,為了解決目標尺度變化過大,傳統模板匹配不能有效地匹配到目標的問題,本文提出了基于卷積神經網絡和NCC 的兩階段的多尺度高精度定位的模板匹配算法. 利用一階段卷積神經網絡提取的目標位置和大小特征,動態修改模板匹配中的模板大小,使得二階段NCC 算法只需對少量模板進行匹配. 這一方法減少了傳統基于灰度的模板匹配算法需生成大量模板進行匹配的情況,同時避免了目標尺度變化較大而模板大小覆蓋不到的情況. 另外,利用一階段捕捉的位置信息進一步限制了匹配區域,從而減少了匹配時間. 有效地結合卷積神經網絡在特征提取任務中具有顯著的優勢和NCC 算法的穩定性. 由于其廣泛的兼容性,YOLOv3 仍然是業界最廣泛使用的檢測器之一. 本文選擇了在YOLOv3 基礎上的改進算法YOLOX 作為一階段檢測. 考慮到卷積神經網絡的大參數量可能導致算法執行時間過長,并為方便第二階段NCC 算法的改進,本文對YOLOX 進行了優化,減少了運算時間并提供了更精準的參數. 綜上所述,本文對基礎NCC 算法進行了改進,提升了檢測速度,并解決了基于灰度的模板匹配算法無法對尺度變化較大的目標進行匹配的問題. 主要改進包括:(1) 通過適應性剪枝方式提升了NCC 算法的檢測速度;(2) 改進了YOLOX 算法的網絡結構,減少了參數量,同時保持匹配精度不降低;(3) 改進了YOLOX 算法的損失函數,降低了對定位更精確目標的損失;(4) 提出了基于卷積神經網絡和NCC 的兩階段多尺度高精度定位的模板匹配算法. 該算法第一階段采用改進后的YOLOX 算法,第二階段利用第一階段的結果動態修改模板大小并減少待匹配區域,同時采用改進后的NCC 算法進行匹配.
2 相關工作
2. 1 歸一化互相關(NCC)算法
模板匹配算法主要分為基于灰度的算法和基于邊緣及特征點的算法2 大類. 后者在抗干擾和適應目標尺度變化方面表現較好,但易產生誤識別和定位誤差,不適用于高精度需求場合. 而歸一化互相關(NCC)算法是典型的基于灰度的模板匹配方法,旨在圖像f 中尋找與模板t 最相似的區域.其核心優勢在于通過歸一化處理,降低亮度變化的干擾,提升算法的魯棒性. 相似度通過計算歸一化后的輸入圖像與模板圖像的互相關系數來評估. 實際應用時,通常設定閾值以判斷匹配是否滿足相似度標準. 令f ( x,y )表示大小為Mx × My 的圖像f 在( x,y ),x ∈{0,…,Mx - 1},y ∈{0,…,My -1}處的像素值(所有圖都轉化為灰度圖),模板t 的大小為Nx × Ny,計算f 在x 方向移動了u,在y 方向上移動了v 的歸一化互相關公式R ( x,y ) 表示如下.
2. 2 圖像金字塔搜索算法
使用圖像金字塔[25]搜索算法能提高模板匹配的魯棒性和準確性. 傳統模板匹配方法對目標尺度變化較敏感,而金字塔搜索允許在不同尺度圖像上進行匹配,使得目標以不同尺度出現在圖像中. 通過金字塔的不同層次,可找到與目標尺度相匹配的最佳結果. 在某些情況下,目標可能發生旋轉或仿射變換,傳統方法難以正確匹配. 而使用圖像金字塔搜索算法,在不同層次上進行匹配,增強了對旋轉和仿射變換的魯棒性,提高了準確性. 目標也可能在圖像中不同位置發生局部變化,如姿態、遮擋或形變. 圖像金字塔搜索算法可在不同層次上對目標進行多尺度匹配,更好地適應局部變化.
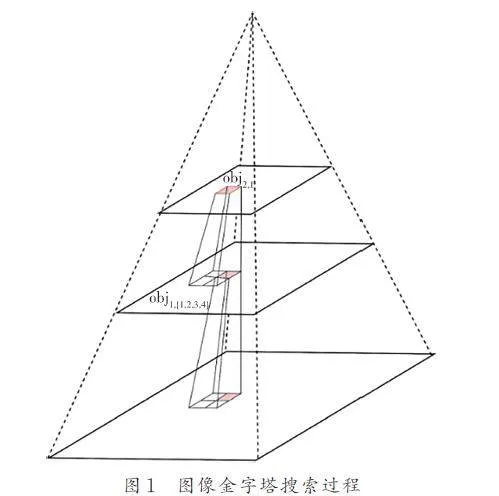
圖像金字塔由一系列縮小比例的原始圖像組成,通過逐層降低分辨率并執行降采樣與平滑處理來構建. 從最高層開始,應用NCC 算法于當前層級圖像以尋找目標物體. 若找到,則記錄其位置、尺寸及其他屬性. 隨后,在更高分辨率的層級繼續搜尋以提升定位精度. 圖1 展示了使用3 個層級圖像金字塔層次進行搜索的過程,搜索過程從最高金字塔級別上的目標開始,通過計算模板與窗口圖像之間的相似性系數,來尋找在最高金字塔級別上位置( x,y )、旋轉為θ 的目標. 選擇最高金字塔級別的圖像作為初始圖像,搜索到圖紅色所示位置時,目標區域對象obj2,1 = { θ2,1,( x2,1,y2,1 ) },在當前金字塔級別的圖像上,將模板與窗口圖像進行相似性計算. 假如該處對象相似性閾值Thmin超過所設閾值,則把對象存到對象列表中,在下一個較低的金字塔級別上進行搜索時. 基于在上一個金字塔級別上找到的對象,如obj2,1. obj1,{ 1,2,3,4 }是由obj2,1 映射而來,同時繼承了obj2,1 的旋轉角度,然后繼續計算此處的相似度,假如相似度超過了相似度閾值Thmin,則繼續映射到下一層,直到最底層. 其中旋轉角度θ 的作用是為了匹配到發生旋轉的目標,相似度閾值Thmin 的作用是為了跳過不必要的運行,使其盡可能匹配到可能的目標.
2. 3 YOLOX 網絡結構
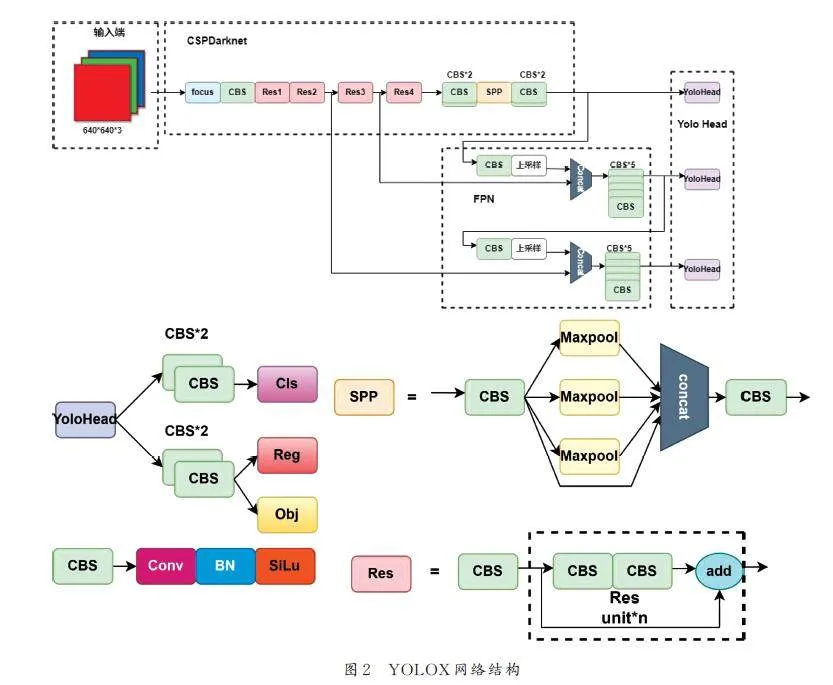
YOLOX 主要可以分為4 個部分:輸入端. 主干網絡(CSPDarknet)、Neck (Feature PyramidNetwork,FPN)和Yolo Head. 具體網絡結構如圖2 所示.
輸入端采用了Mosaic 和Mixup 2 種數據增強方法來強化網絡輸入[26]. Mosaic 數據增強將4 張隨機選取的圖像以一定比例拼接,形成更大且信息豐富的輸入圖像. 而Mixup 則在訓練過程中合成新樣本,通過隨機選取2 個圖像,并按照一定權重進行線性插值,生成新的輸入圖像和相應的標簽.這使得模型能夠在訓練中學習不同樣本之間的關系,提升了泛化能力.
CSPDarknet 是YOLOX 的主干特征提取網絡,采用了殘差網絡、CSPnet 結構、Focus 網絡結構、SiLU 激活函數和SPP 結構. 殘差卷積包括主干部分和殘差邊部分,主干部分由1×1 和3×3 卷積組成,殘差邊部分將主干的輸入與輸出直接相加. CSPnet 將原來的殘差塊堆疊結構拆分為左右2 部分,通過引入大的殘差邊提高了網絡的表達能力. Focus 是YoloV5[25]中引入的網絡結構,通過特征層的像素間隔采樣來提取特征,從而擴展了通道數. SiLU 是改進版本的激活函數,優于ReLU,因此在CSPDarknet 中采用了SiLU. SPP 結構通過不同大小的最大池化核進行特征提取,增加了網絡的感受野,在YOLOX 中被用于主干特征提取網絡中.
構建FPN 是常用的方法,用于增強特征提取并解決目標檢測中多尺度目標的問題. FPN 的主要思想是在主干網絡中引入額外的側邊分支,通過跨層連接和上采樣操作構建多尺度的特征金字塔. 這樣可以獲取不同分辨率的特征圖,更好地捕捉不同尺度目標的特征.
Yolo Head 是YOLOX 中負責分類和回歸的組件,通過加強的特征層判斷特征點是否對應目標. 與以往版本的Yolo 不同,YOLOX 將分類和回歸分開實現并在預測時整合.
3 方法
3. 1 適應性剪枝模板匹配算法
模板匹配是基本的圖像處理方法,需要在整個圖像上移動模板,并計算每個窗口與模板之間的相似度. 計算的時間復雜度與圖像大小和模板大小有關. 本文采用圖像金字塔搜索算法,無需全圖掃描進行歸一化互相關運算,只需將金字塔模型頂層計算結果映射到下層. 然而,頂層模型需要進行1 次全圖掃描,耗時較長,并且復雜的設計可能導致頂層圖像過大增加運算量. 因此,本文提出根據頂層每次歸一化互相關計算結果,對未來多次運算進行提前剪枝,以優化計算效率.
輸入模板圖像和待匹配圖像后,模板匹配的整體流程如圖3 所示. 首先離線構建模板圖像的金字塔搜索矩陣,對模板圖像進行金字塔縮放,生成多個不同尺度的圖像,計算每個尺度圖像的像素值的均值和標準差,用于后續的NCC 算法. 在線模板匹配處理流程中,根據模板圖像大小和待匹配圖像構建金字塔搜索模型,生成多個不同尺度的圖像,根據待匹配圖像大小和輸入參數θ 構建旋轉尺度,生成多個不同旋轉角度和尺度的圖像.從金字塔的頂層開始遍歷,對當前金字塔層級的圖像,使用NCC 算法計算相關值. 在計算過程中,利用SIMD(單指令多數據)指令集進行并行加速,提高計算效率,同時根據實驗確定最適合的剪枝步長β. 根據計算結果,確定下一次在待匹配圖像中的計算位置,跳過無關區域,減少計算量. 將當前金字塔層級的匹配結果映射到下一層,繼續進行歸一化互相關計算. 整個算法通過金字塔搜索和旋轉尺度的構建,以及NCC 算法的并行加速和跳過無關區域的優化,實現了對模板在待匹配圖像中的精確定位和匹配. 值得注意的是,離線構建模板圖像的金字塔搜索矩陣和NCC 算法中對應區域的均值和標準差的計算不參與NCC 算法的總耗時.。
3. 2 主干網絡改進
在工業應用中,如機器人視覺引導,模板匹配算法需要高定位精度和快匹配速度. 本文通過二階段匹配算法解決了定位精度問題,但結合優化后的模板匹配算法和前置YOLOX 目標匹配提取特征,仍需要較長時間. 因此,我們對YOLOX 算法主干網絡結構進行了優化.
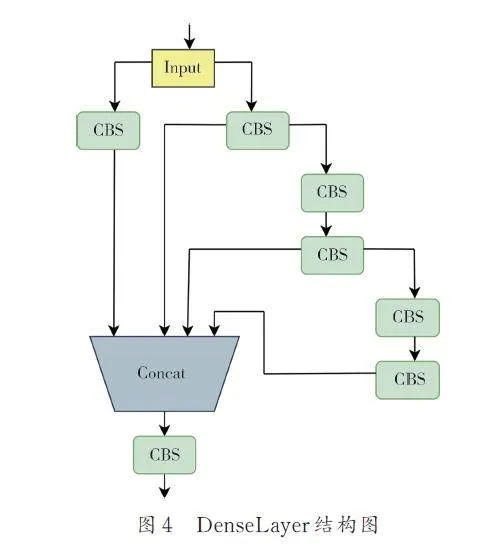
YOLOX 中采用的主干網絡是CSPDarknet,其中的CSPlayer 模塊(即圖2 中的Res 部分)使用了大量的Resunit 來提取更多的特征信息,但也導致了較多的參數使用,增加了計算量. 相比之下,DenseNet(Densely Connected Convolutional Networks)中的每個層都與前面的所有層直接連接,形成了密集連接的結構. 這種密集連接促進了信息的充分流動,有助于特征的重用和信息的傳遞,減輕了梯度消失問題,提高了網絡的穩定性. 由于密集連接,DenseNet 中的參數可以被多個層共享,從而大大減少了參數數量,降低了過擬合的風險,減少了模型的存儲需求,提高了訓練效率. 我們參考了DenseNet 的密集連接結構,將其應用于本文中,使用設計的DenseLayer 代替了CSPlayer 模塊,有效地減少了參數量.
3. 3 損失函數(LOSS)的改進
在YOLOX 算法中,回歸部分的損失函數采用了交并比(IoU),用于衡量“預測邊框”和“真實邊框”的重疊率. 然而,IoU 存在以下問題:(1) 在沒有重疊的情況下,IoU 為0,導致無法優化.(2) IoU無法準確反映重疊度大小,如圖5 所示. 盡管3 種情況的IoU 相等,但可以明顯看出它們的重合度是不同的,圖5a 的回歸效果最佳,圖5c 的效果最差.(3) IoU 無法反映預測框和真實框的大小. 在模板匹配算法中,我們需要目標檢測階段的預測值,以便直接修改模板大小和計算目標位置. 由于IoU的限制,我們采用了改進的EIoU 算法來滿足需求. EIoU 考慮了額外的幾何特征,包括中心點距離和長寬比差異. 它的懲罰項將縱橫比的影響因子拆分成預測框和真實框的寬高差值,從而加速了收斂并提高了回歸精度. 該損失函數包含3 個部分:重疊損失、中心距離損失和寬高損失. 將縱橫比的損失項拆分成預測的寬高分別與最小外接框寬高的差值,加速了收斂,且提高了回歸精度.EIoU 公式如式(3)所示.
其中,c w 和ch 是覆蓋2 個框的最小外接框的寬度和高度;b 代表預測框的中心點;bgt 代表真實框的中心點;ρ 為2 個點的歐式距離. 在模板匹配中,我們需要調整模板大小以適應可能的目標尺寸變化.然而,僅考慮長度或寬度一致可能導致長寬比例差異,進而影響匹配結果. 為解決此問題,我們采用改進的EIoU 算法,綜合考慮IoU、長寬差異、長寬比差異和中心距離差異,以制定損失函數的回歸部分. 公式如下.
式(4)中,當μdic 和μasp 取1,uother 取2 時,比μdic、μasp、uother 都取1 時有更好的效果. 本文中所有實驗都是在μdic 和μasp 取1,uother 取2 下驗證的. 今后會進行更多實驗,驗證更佳的參數.
4 實驗與分析
4. 1 數據集
本文采用PASCAL VOC2007 和VOC2012 以及RSOD-Dataset 數據集進行模型訓練和評估.VOC07+12 通用數據集包含4 個大類別和20 個小類別,共9963 張圖像和24 640 個目標(VOC2007),以及23 080 張圖像和54 900 個目標(VOC2012).我們按照9∶1 的比例劃分訓練集、驗證集和測試集,以測試模型的泛化能力,特別針對多任務場景的模板匹配. RSOD-Dataset 數據集由武漢大學于2015 年發布,用于遙感圖像中物體檢測[27],包含飛機、操場、立交橋和油桶4 類目標,共976 張圖像和6950 個目標. 該數據集主要用于模型針對高頻遙感圖像應用場景的訓練[28],并驗證模板匹配算法在此類場景下的性能.
4. 2 實驗參數
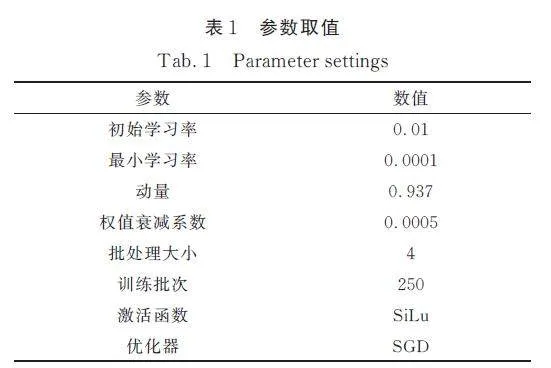
硬件部分:CPU 為Intel Core i7-11800H @2. 30 GHz,8 核16 線程,GPU 為NVIDIA GeForceRTX 3060. 軟件部分:一階段目標檢測部分使用的框架為tensorflow-gpu 2. 4. 0,編程語言為python.設置參數取值如表1 所示.
本文的實驗評估包括3 個方面:(1) 一階段目標檢測階段使用召回率(Recall)、查準率(Precision)、平均準確度均值(mAP)和F2 分數(F2-Score),以及速度來進行評估;(2) 二階段模板匹配使用互相關系數、平均相關度以及速度來評估;(3) 整個算法部分使用總運行時間、最終匹配互相關指數、平均相關度和匹配成功率來評估.
4. 3 實驗結果與分析
4. 3. 1 一階段算法改進實驗及結果
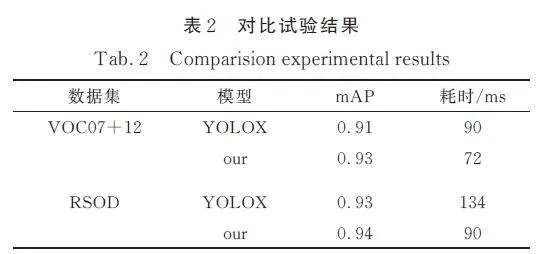
在VOC07+12 和RSOD 數據集下,本文模型和YOLOX 模型在參數驗證最好情況下二者在mAP 和耗時方面的對比,可以看出二者在用測試集評估下mAP 差距不大,但是在耗時方面本文算法有了明顯提升,如表2 所示.
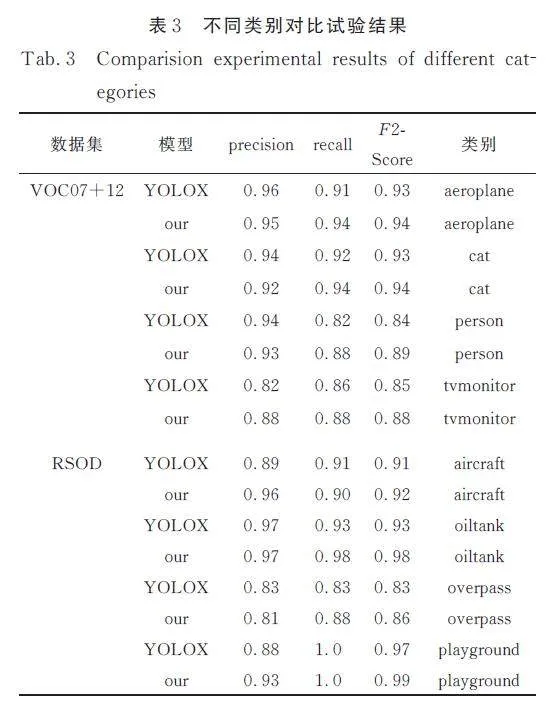
在保持參數一致性的前提下,本文將提出的算法與YOLOX 算法在查準率、召回率和F2-Score等評估指標上進行了對比分析. 我們在PASCALVOC 數據集的4 個主要類別中各選取了1 個子類別進行比較. 對于RSOD,我們則考慮了全部的8個類別,正如表3 所展示的那樣. 通過對比可以觀察到,本文提出的算法在查準率基本保持穩定的同時,召回率(查全率)得到了顯著提升. 這一改進正符合我們對單階段檢測算法的期望,即提高召回率以確保在NCC 算法的后續處理階段能夠識別并定位到更多的目標對象. F2-Score 是結合查準率和召回率的綜合評價指標,其計算時將召回率的重要性定為查準率的2 倍. 因此,在查準率相差不大的情況下,由于召回率的顯著提升,F2-Score也相應地得到了明顯增強. 這表明,本文提出的算法在整體性能上優于YOLOX 算法,尤其是在對不同類別目標的檢測能力方面.
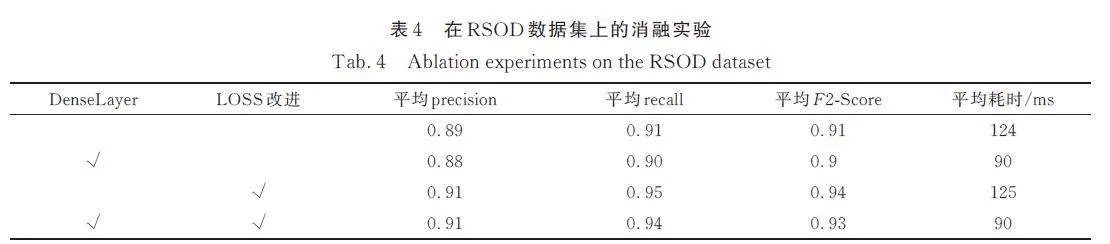
本文對主干網絡的Res 模塊及網絡的損失函數進行了優化. 通過設計的消融實驗,我們分析了每項改進對性能的具體貢獻,結果如表4 所示. 在RSOD 數據集上的實驗表明,將Res 模塊改進為DenseLayer 后,盡管精度等指標未見顯著變動,但平均處理時間顯著縮短. 僅優化損失函數時,雖然處理時間保持不變,但關鍵指標召回率和F2-Score得到顯著提升. 綜合改進Res 模塊和損失函數,則在提高處理速度和F2-Score 方面均取得了顯著成效.
4. 3. 2 NCC 算法及總體改進后實驗和結果
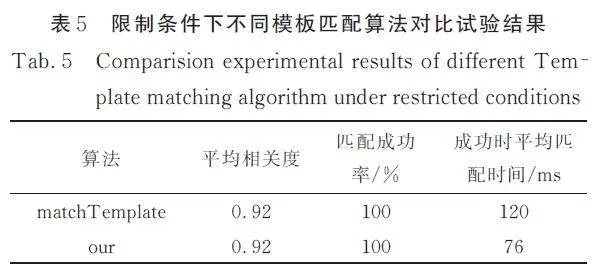
本文在未借助一階段檢測成果的條件下,針對目標尺寸限定在模板大小0. 9~1. 1 倍范圍內,對OpenCV 中的matchTemplate 方法和本文提出的算法進行了對比研究. 為確保比較公平,我們對OpenCV 的matchTemplate 以外的部分實施了同等優化,包括圖像金字塔搜索等. 實驗確定了最佳旋轉角度和參數設置,0°~180°的旋轉范圍、0. 5 的閾值和遮擋率、β 值為2. 在這些條件下,表5 顯示了不同模板匹配方法的對比結果. 結果顯示,在不涉及尺度變換的場景中,本文算法與優化后的OpenCV matchTemplate 方法在成功率上持平,但在平均匹配時間上有顯著差異,本文算法比match?Template 快36%. 這一改進是在采用步長為2 的剪枝策略后,僅對NCC 算法進行剪枝處理時實現的.
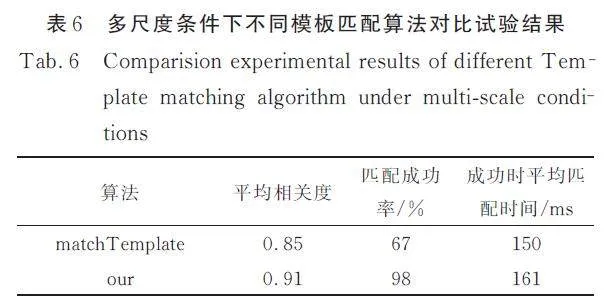
在多尺度情境下,單一模板難以匹配不同大小的目標. 本文采用整合策略,結合一階段目標檢測和二階段改進的NCC 算法,提出了基于卷積神經網絡和NCC 的兩階段多尺度高精度定位模板匹配算法. 與優化后的matchTemplate 方法對比(如表6 所示),在RSOD 數據集及部分工業圖像中抽取的100 張圖片上進行重復檢測,結果表明本文算法的匹配成功率遠高于優化后的matchTemplate方法. 這是因為當模板與目標尺度差異顯著時,matchTemplate 難以實現識別;而本文算法通過一階段獲取尺度和位置信息,并傳遞給優化后的NCC 算法,利用插值算法調整模板尺度以匹配目標,同時利用一階段的位置信息進行快速預定位,從而縮短了匹配時間. 總體用時包括了一階段和二階段的時間總和.
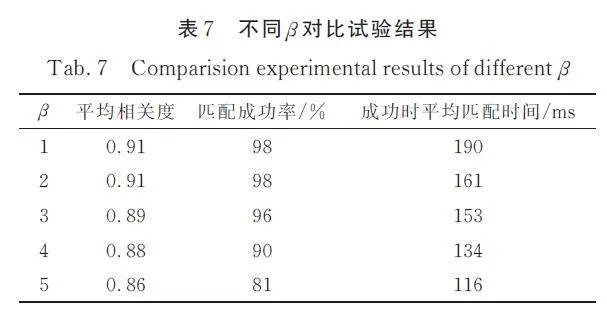
在NCC 算法中,我們實施了自適應剪枝技術以排除不必要的計算區域. 通過設定不同的β 值作為剪枝步長,本文對這一策略的有效性進行了評估. 如表7 所示,使用與前述實驗相同的數據集,在0°~180°的旋轉范圍內,閾值和遮擋率均設為0. 5 的條件下,我們從平均相關度、匹配成功率以及成功匹配時的平均處理時間3 個指標進行了對比分析. 結果表明,當β 值為2 時,綜合性能最優.
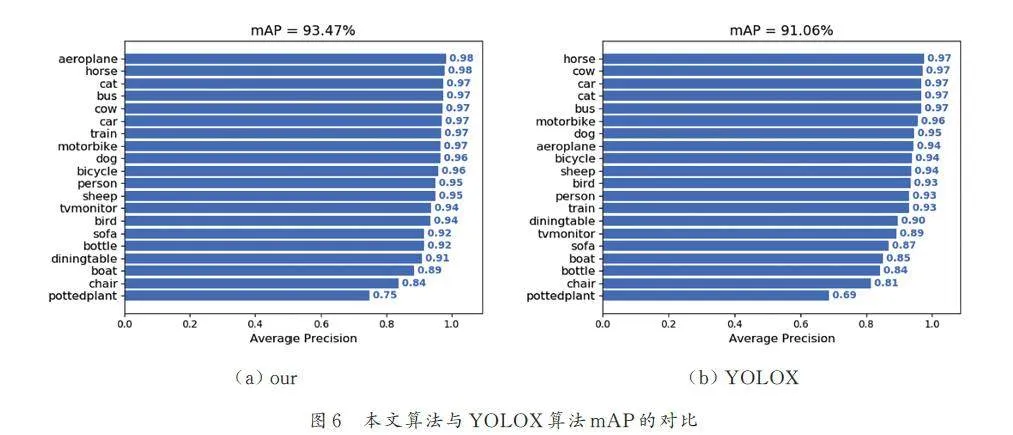
我們將通過一系列實驗效果圖來闡述本文算法的優勢. 圖6 展示了本文算法與YOLOX 算法在mAP(平均精度均值)上的對比情況. 從表6 可以看出,在保持較快速度的同時,本文算法的檢測精度與YOLOX 算法相當.
圖7 展示了本文提出的基于卷積網絡和NCC的兩階段多尺度高精度定位模板匹配方法的結果,其中紅色框表示匹配算法自動繪制的匹配結果,準確標出了待匹配模板. 目標尺度變化不大的情況下,本文算法和OpenCV 的matchTemplate 方法都能很好地匹配到目標,如圖7a(本文算法)和圖8b(OpenCV 的matchTemplate). 在目標尺度變化較大的情況下,與OpenCV 中的matchTemplate方法相比,本文算法表現出明顯的優勢,如圖7b 和圖7c 所示( 它們是同一次匹配的不同展示). 而matchTemplate 方法在許多情況下未能成功匹配,如圖8 b 所示.
5 結論
本文在NCC 算法的基礎上使用適用性剪枝算法減少了模板匹配的匹配時間,以及通過結合卷積神經網絡和NCC 算法使得本文算法解決了傳統模板匹配算法對于多尺度目標無法匹配的問題.通過改進YOLOX 算法的網絡結構,借鑒DenseNet類似的網絡結構減少了網絡參數量,同時密集結合了不同尺度的信息,在不損失精度的情況下減少了檢測時間;通過改進YOLOX 算法損失函數設計,使得檢測召回率有所提升,滿足我們對于后續模板匹配的需求. 下一階段,我們嘗試研究輕量級網絡進一步嘗試減少整體算法耗時.
參考文獻:
[1] Hou B, Ren Z L, Zhao W, et al. Object detection inhigh-resolution panchromatic images using deep modelsand spatial template matching [J]. IEEE Transactionson Geoscience and Remote Sensing, 2020,956: 970.
[2] Vyanza V E, Setianingsih C, Irawan B. Design ofsmart door system for live face recognition based onimage processing using principal component analysisand template matching correlation methods [C]//Proceedings of the 2017 IEEE Asia Pacific Conferenceon Wireless and Mobile (APWiMob). Bandung,Indonesia: IEEE, 2017: 23.
[3] Daga A P, Garibaldi L. GA-adaptive template matchingfor offline shape motion tracking based on edgedetection: IAS estimation from the SURVISHNO2019 challenge video for machine diagnostics purposes[ J]. Algorithms, 2020, 13: 33.
[4] Liu W, Anguelov D, Erhan D,et al. SSD: Singleshot multibox detector [C]//Computer Vision andPattern Recognition(cs. CV). [S. l.]: ECCV,2016.
[5] Chen L F, Liu Y, Xu W B. Improved grayscale imagetemplate matching method based on normalizedcross-correlation approach [J]. Computer Engineeringand Applications, 2011, 47: 181.[陳麗芳,劉淵,須文波. 改進的歸一互相關法的灰度圖像模板匹配方法[J]. 計算機工程與應用, 2011, 47: 181.]
[6] Qi X W, Miao L G. A template matching method formulti-scale and rotated images using ring projectionvector conversion [C]//Proceedings of the 2018IEEE 3rd International Conference ON Image, Visionand Computing (ICIVC). Chongqing, China:IEEE, 2018.
[7] Kai B, Hanebeck U D. Template matching using fastnormalized cross correlation[ J]. Optical Pattern RecognitionXII, 2001, 4387: 277.
[8] Chen C S, Huang C L, Yeh C W, et al. An acceleratingCPU based correlation-based image alignmentfor real-time automatic optical inspection [J]. Computersand Electrical Engineering, 2016, 47: 207 .
[9] Zhu X C, Hu X, Li D Y, et al. A dual evaluationmulti-scale template matching algorithm based onwavelet transform [J]. Electronics Letters, 2022,58: 145.
[10] Shi X, Chen Z, Wang H, et al. ConvolutionalLSTM network: A machine learning approach forprecipitation nowcasting [J]. Advances in Neural InformationProcessing Systems, 2015, 28: 1.
[11] Goodfellow I, Pouget-Abadie J, Mirza M, et al.Generative adversarial networks [J]. Communicationsof the ACM, 2020, 63: 139.
[12] He K, Zhang X, Ren S, et al. Deep residual learningfor image recognition [C]//Proceedings of the IEEEConference on Computer Vision and Pattern Recognition.Las Vegas, USA: IEEE, 2016: 770.
[13] Hu J, Shen L, Sun G. Squeeze-and-excitation networks[C]//Proceedings of the IEEE Conference onComputer Vision and Pattern Recognition. USA:IEEE, 2018: 7132.
[14] Zhang Y P, An R, Liu S h, et al. Predicting and understandingstudent learning performance using multisourcesparse attention convolutional neural networks[J]. IEEE Transactions on Big Data, 2023,9: 118.
[15] Zhao H, Li Z W, Zhang T Q. Attention based singleshot multibox detector [J]. Journal of Electronics amp;Information Technology, 2021, 43: 2096.
[16] Lin T Y, Goyal P, Girshick R, et al. Focal loss fordense object detection [J]. IEEE Transactions onPattern Analysis and Machine Intelligence, 2020,42: 318.
[17] Deng L X, Li H Q, Liu H Y. A lightweight YOLOv3algorithm used for safety helmet detection [J].Scientific Reports, 2022, 12: 2045.
[18] Parico A I B, Ahamed T. Real time pear fruit detectionand counting using YOLOv4 models and deepSORT[ J]. Sensors, 2021, 21: 1424.
[19] Qiao S, Chen L C, Yuille A. Detectors: Detectingobjects with recursive feature pyramid and switchable atrous convolution [C]//Proceedings of the IEEE/CVF Conference on Computer Vision and PatternRecognition. Virtual: IEEE, 2021: 10213.
[20] Gao F, Cai C, Jia R, et al. Improved YOLOX forpedestrian detection in crowded scenes [J]. Journalof Real-Time Image Processing, 2023, 20: 24.
[21] Wang C Y, Bochkovskiy A, Liao H Y M. YOLOv7:Trainable bag-of-freebies sets new state-ofthe-art for real-time object detectors [C]//Proceedingsof the IEEE/CVF Conference on Computer Visionand Pattern Recognition. Seattle WA, USA:IEEE, 2023: 7464.
[22] Girshick R, Donahue J, Darrell T, et al. Rich featurehierarchies for accurate object detection and semanticsegmentation [C]//Proceedings of the IEEEconference on computer vision and pattern recognition.Columbus, Ohio: IEEE, 2014: 580.
[23] Girshick R. Fast r-cnn [C]//Proceedings of theIEEE international Conference on Computer Vision.Santiago, Chile: IEEE, 2015: 1440.
[24] Ren S, He K, Girshick R, et al. Faster r-cnn: Towardsreal-time object detection with region proposalnetworks [J]. Advances in Neural Information ProcessingSystems, 2017, 39: 1137.
[25] He Z L, Jin Y Y. Image enhancement method basedon image pyramid [J]. Electronic Technology amp;Software Engineering, 2014(16): 134.[何志良,晉妍妍. 基于圖像金字塔的圖像增強方法[J]. 電子技術與軟件工程, 2014(16): 134.]
[26] Zhang C J, Hu X B, Niu H C. Vehicle object detectionbased on improved YOLOv5 method [J]. JournalSichuan University(Natural Science Edition),2022, 59: 053001.[章程軍,胡曉兵,牛洪超. 基于改進YOLOv5 的車輛目標檢測研究[J]. 四川川大學報(自然科學版), 2022, 59: 053001.]
[27] Long Y, Xiao Z, Liu Q, et al. Accurate object localizationin remote sensing images based on convolutionalneural networks [J]. IEEE Transactions onGeoscience and Remote Sensing, 2017, 55: 2486.
[28] Xiao Z, Liu Q, Tang G, et al. Elliptic fouriertransformation-based histograms of oriented gradientsfor rotationally invariant object detection in remotesensingimages [J]. International Journal of RemoteSensing, 2015, 36: 618.]
(責任編輯: 伍少梅)
基金項目: 國家自然科學基金面上項目(62171303)
