結(jié)合圖神經(jīng)網(wǎng)絡(luò)的小樣本圖像分類方法
2024-08-23 00:00:00齊露露俞衛(wèi)琴
無(wú)線電工程 2024年7期
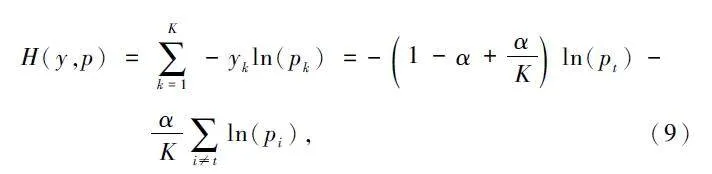

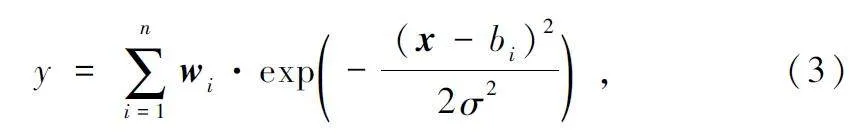
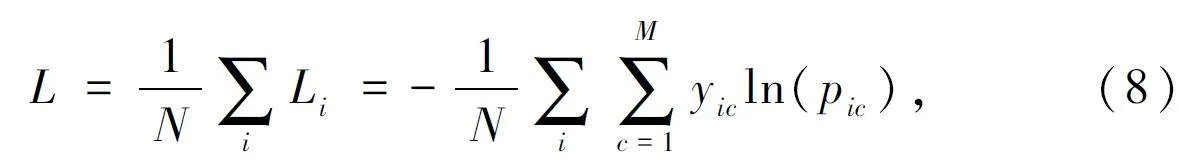

摘 要:針對(duì)目前在小樣本圖像分類任務(wù)上,現(xiàn)有模型存在特征提取不足、提取的特征信息單一等問(wèn)題,提出一種結(jié)合圖神經(jīng)網(wǎng)絡(luò)的雙特征提取的原型網(wǎng)絡(luò)(Graph-Based Dual-Encoding Prototype Network,GB-ProtoNet)。GB-ProtoNet 采用了雙特征提取器結(jié)構(gòu),通過(guò)整合2 種不同的神經(jīng)網(wǎng)絡(luò),有效地捕獲并融合了樣本的全局特征信息和局部特征信息。具體而言,該模型結(jié)合了殘差網(wǎng)絡(luò)(Residual Network,ResNet) 和基于圖譜卷積網(wǎng)絡(luò)(Graph SAmple and aggreGatE,GraphSAGE) 的圖神經(jīng)網(wǎng)絡(luò)。ResNet 能夠在多層網(wǎng)絡(luò)結(jié)構(gòu)中有效地傳遞和保留信息,從而提取樣本的全局特征信息。GraphSAGE 擅長(zhǎng)處理圖結(jié)構(gòu)數(shù)據(jù),通過(guò)采樣和聚合鄰居節(jié)點(diǎn)的信息,提取出樣本的局部特征信息。GB-ProtoNet 在訓(xùn)練階段使用標(biāo)簽平滑交叉熵?fù)p失函數(shù)計(jì)算損失并更新模型參數(shù)。該模型在miniImageNet 和CUB-2002-2011 數(shù)據(jù)集上進(jìn)行對(duì)比實(shí)驗(yàn),與其他經(jīng)典模型相比,GB-ProtoNet 在5-Way 1-Shot 和5-Way 5-Shot 兩種設(shè)置上均取得最佳分類精度。
關(guān)鍵詞:小樣本學(xué)習(xí);圖像分類;圖譜卷積網(wǎng)絡(luò)
中圖分類號(hào):TP391. 41 文獻(xiàn)標(biāo)志碼:A 開放科學(xué)(資源服務(wù))標(biāo)識(shí)碼(OSID):
文章編號(hào):1003-3106(2024)07-1668-08
0 引言
大數(shù)據(jù)時(shí)代下,隨著數(shù)據(jù)獲取和存儲(chǔ)技術(shù)的飛速發(fā)展,數(shù)據(jù)量呈現(xiàn)爆炸式增長(zhǎng)。然而,在一些實(shí)際應(yīng)用場(chǎng)景中,由于數(shù)據(jù)獲取成本高、標(biāo)注難度大和數(shù)據(jù)分布不均勻等因素,往往難以獲得大量標(biāo)注的樣本數(shù)據(jù)。因此,越來(lái)越多的任務(wù)面臨著樣本數(shù)據(jù)不足的問(wèn)題。由此引發(fā)了研究人員對(duì)小樣本學(xué)習(xí)的探索。近年來(lái),研究人員提出了多種小樣本圖像分類方法,主要包括基于數(shù)據(jù)增強(qiáng)、基于遷移學(xué)習(xí)、基于元學(xué)習(xí)和基于度量學(xué)習(xí)的方法。
數(shù)據(jù)增強(qiáng)方法可以為機(jī)器學(xué)習(xí)模型生成數(shù)據(jù),減少對(duì)訓(xùn)練數(shù)據(jù)的依賴性,從而提高機(jī)器學(xué)習(xí)模型的性能[1]。其中,有監(jiān)督的數(shù)據(jù)增強(qiáng)方法有幾何變換和像素級(jí)操作,可增加數(shù)據(jù)量[2]。無(wú)監(jiān)督的數(shù)據(jù)增強(qiáng)方法主要通過(guò)模型,尋找合適的增強(qiáng)方法,如GAN[3]、MFC-GAN[4]、IDA-GAN[5]等方法。遷移學(xué)習(xí)的方法利用先驗(yàn)知識(shí),通過(guò)相似類別的樣本來(lái)提高模型的性能[6]。根據(jù)數(shù)據(jù)和任務(wù)的相似程度來(lái)看,遷移學(xué)習(xí)可分為歸納式遷移學(xué)習(xí)、轉(zhuǎn)導(dǎo)式遷移學(xué)習(xí)和無(wú)監(jiān)督式遷移學(xué)習(xí)[7]。元學(xué)習(xí)也稱學(xué)會(huì)學(xué)習(xí),旨在學(xué)習(xí)如何快速準(zhǔn)確地將模型適應(yīng)新任務(wù)[8],主要分為黑箱元學(xué)習(xí)、層次元學(xué)習(xí)和貝葉斯元學(xué)習(xí)[9]。
度量學(xué)習(xí)的核心思想是學(xué)習(xí)一個(gè)距離度量,使得同一類別的樣本之間的距離盡可能小,不同類別的樣本之間的距離盡可能大[10]。度量學(xué)習(xí)通常使用深度神經(jīng)網(wǎng)絡(luò)提取樣本特征,隨后學(xué)習(xí)一個(gè)距離度量,在新的度量空間中完成相似度比較。例如,關(guān)系網(wǎng)絡(luò)[11]將每個(gè)樣本與每個(gè)類別原型進(jìn)行對(duì)比,學(xué)習(xí)一個(gè)關(guān)系函數(shù)來(lái)表示每個(gè)樣本與每個(gè)類別原型之間的相似性。然后,將關(guān)系函數(shù)的輸出進(jìn)行分類,得到該樣本的預(yù)測(cè)類別。原型網(wǎng)絡(luò)[12]首先為每個(gè)類別學(xué)習(xí)一個(gè)原型,然后將待分類樣本與每個(gè)原型的距離進(jìn)行比較,將距離最小的類別作為該樣本的預(yù)測(cè)類別。匹配網(wǎng)絡(luò)[13]的核心思想是使用余弦相似度度量樣本之間的距離,并使用支持集(SupportSet)和查詢集(Query Set)進(jìn)行訓(xùn)練。MAML[14]的核心思想是學(xué)習(xí)一個(gè)初始模型,該模型能夠快速適應(yīng)新任務(wù)。Zhang 等[15]基于圖像區(qū)域之間最優(yōu)匹配的角度,提出了一種基于度量的小樣本學(xué)習(xí)方法———Deep Earth Mover-s Distance(deepEMD)。該方法使用推土機(jī)距離(Earth Mover-s Distance,EMD)作為度量來(lái)計(jì)算密集圖像表示之間的結(jié)構(gòu)距離,以確定圖像相關(guān)性。任維鑫等[16]使用孿生網(wǎng)絡(luò)作為框架,通過(guò)自監(jiān)督的對(duì)比學(xué)習(xí)和基于構(gòu)造監(jiān)督標(biāo)簽與二值交叉熵的距離損失來(lái)優(yōu)化模型的性能。Yu等[17]通過(guò)改進(jìn)原型網(wǎng)絡(luò)中的度量學(xué)習(xí)方法,將核心度量函數(shù)改為曼哈頓距離并優(yōu)化卷積神經(jīng)網(wǎng)絡(luò)結(jié)構(gòu),減少噪聲的影響且更易于模型優(yōu)化。陸妍等[18]針對(duì)小樣本細(xì)粒度分類中相似性度量單一的問(wèn)題,提出一種基于Transformer 的小樣本細(xì)粒度圖像分類模型,設(shè)計(jì)了具有Transformer 架構(gòu)的多軸注意力模塊,能夠更好挖掘圖像特征。許華杰等[19]提出了一種基于特征圖增強(qiáng)原型和查詢特征聚合的小樣本圖像分類方法,有效緩解了類原型代表性不足和類內(nèi)差異較大問(wèn)題。
圖神經(jīng)網(wǎng)絡(luò)(Graph Neural Network,GNN)[20]是一種用于處理圖結(jié)構(gòu)數(shù)據(jù)的神經(jīng)網(wǎng)絡(luò)。圖結(jié)構(gòu)數(shù)據(jù)是現(xiàn)實(shí)世界中廣泛存在的一種數(shù)據(jù)形式。近年來(lái),有許多研究者將GNN 與小樣本學(xué)習(xí)相結(jié)合,以充分利用圖結(jié)構(gòu)對(duì)節(jié)點(diǎn)和邊的數(shù)據(jù)的提取,提高模型在小樣本上的性能[21]。Zhong 等[22]提出了一個(gè)用于小樣本圖像分類的圖補(bǔ)充潛在表示網(wǎng)絡(luò)(GraphComplemented Latent Representation,GCLR ),引入GNN 充分利用每個(gè)類別內(nèi)樣本之間的關(guān)系,提高關(guān)聯(lián)挖掘能力。Xiong 等[23]提出了一種利用多維邊緣特征的圖神經(jīng)網(wǎng)絡(luò)(Graph Neural Network ExploitingMulti-Dimensional Edge Features,MDE-GNN)。MDE-GNN 引入多維邊緣特征信息構(gòu)建圖中的邊矩陣,使得模型能夠更好地捕捉圖像之間的復(fù)雜關(guān)系。Tong 等[24]提出了一種用于高光譜圖像(HyperspectralImage,HSI)小樣本分類的注意力加權(quán)圖卷積網(wǎng)絡(luò)(Attention-weighted Graph Convolutional Network,AwGCN)模型,通過(guò)構(gòu)建注意力加權(quán)圖和利用圖卷積網(wǎng)絡(luò)傳播標(biāo)簽,解決HSI 少樣本分類所面臨的巨大標(biāo)記數(shù)據(jù)需求問(wèn)題。Chen 等[25]提出了分層圖神經(jīng)網(wǎng)絡(luò)(Hierarchical Graph Neural Network,HGNN),著眼于挖掘類別內(nèi)部和類別之間的區(qū)分特征,從而更好地進(jìn)行小樣本分類。李凡等[26]將ResNet 與GNN 相結(jié)合,設(shè)計(jì)了殘差圖卷積網(wǎng)絡(luò),增強(qiáng)網(wǎng)絡(luò)穩(wěn)定性,并結(jié)合注意力機(jī)制提高信息傳遞效率。
本文提出了一種基于GNN 的雙特征提取原型網(wǎng)絡(luò)(Graph-Based Dual-Encoding Prototype Network,GB-ProtoNet),并對(duì)其在小樣本圖像分類任務(wù)中的表現(xiàn)進(jìn)行了研究。GB-ProtoNet 在原型網(wǎng)絡(luò)的基礎(chǔ)上進(jìn)行了改進(jìn),主要貢獻(xiàn)如下:① 雙編碼特征提取模塊。該模塊融合了ResNet 和基于圖譜卷積網(wǎng)絡(luò)(Graph SAmple and aggreGatE,Graph-SAGE)的GNN分別提取樣本的全局信息和局部信息,提取更全面、更魯棒的圖像特征。② GraphSAGE GNN。采用Graph-SAGE 構(gòu)建GNN,捕捉圖像中的局部依賴關(guān)系,增強(qiáng)模型對(duì)圖像細(xì)節(jié)的表達(dá)能力。③ 標(biāo)簽平滑交叉熵?fù)p失函數(shù)。通過(guò)加入一個(gè)平滑項(xiàng),可以減小梯度的大小,有效緩解模型過(guò)擬合問(wèn)題,提升模型的泛化能力。
實(shí)驗(yàn)表明,GB-ProtoNet 在miniImageNet 和CUB-2002-2011 數(shù)據(jù)集上取得了優(yōu)異的性能,在5-Way 1-Shot 和5-Way 5-Shot 設(shè)置下分別取得了87. 05% 、76. 22% 和96. 76% 、88. 70% 的精度。
1 本文方法
1. 1 小樣本問(wèn)題定義
在小樣本學(xué)習(xí)中,對(duì)于給定任務(wù),其包含3 個(gè)數(shù)據(jù)集為訓(xùn)練集、驗(yàn)證集和測(cè)試集,這3 個(gè)數(shù)據(jù)集類別兩兩正交。為了方便對(duì)比不同方法,通常在N-WayK-Shot 任務(wù)上進(jìn)行測(cè)試,認(rèn)為如果一個(gè)方法可在N-Way K-Shot 任務(wù)上取得較好結(jié)果,則該方法具備小樣本學(xué)習(xí)能力。N-Way K-Shot 任務(wù)也稱為N-WayK-Shot Q-query 任務(wù),一般來(lái)說(shuō),小樣本學(xué)習(xí)的訓(xùn)練集中包含了很多類別,每個(gè)類別有多個(gè)樣本。在訓(xùn)練階段,從訓(xùn)練集中隨機(jī)選取N 個(gè)類別,每個(gè)類別抽取K 個(gè)樣本作為Support Set,Support Set 包括N×K 個(gè)樣本,K 通常設(shè)為1 或5;每個(gè)類再抽取Q 個(gè)樣本作為Query Set,Query Set 可以為1 個(gè)樣本也可以為多個(gè)樣本,根據(jù)其標(biāo)注的類別,計(jì)算分類損失用于模型學(xué)習(xí)。模型在訓(xùn)練過(guò)程中定期在驗(yàn)證集上進(jìn)行評(píng)估,驗(yàn)證集同樣被劃分為Support Set 和QuerySet,并根據(jù)驗(yàn)證集上計(jì)算的損失調(diào)整模型參數(shù),以防止模型過(guò)擬合訓(xùn)練集。在測(cè)試階段,測(cè)試集被分為Support Set 和Query Set,此時(shí)僅計(jì)算模型的分類精度,用于評(píng)估模型在未知數(shù)據(jù)上的泛化能力。
1. 2 模型總體架構(gòu)
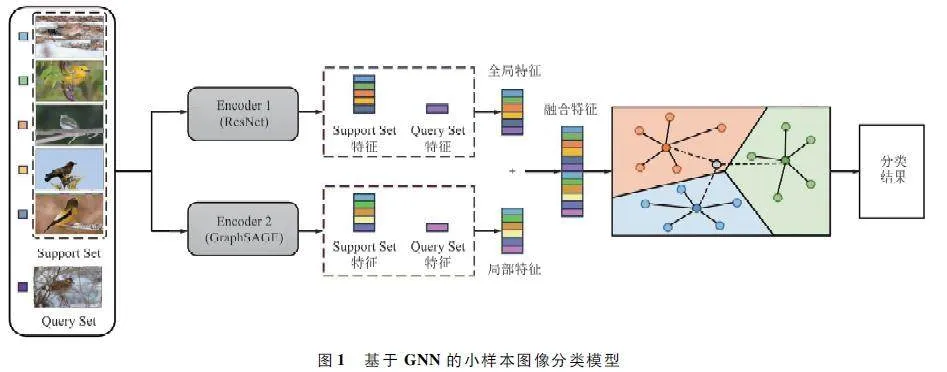
小樣本圖像分類任務(wù)通常由特征提取模塊和特征比較模塊構(gòu)成。本文提出了GB-ProtoNet,在原型網(wǎng)絡(luò)的基礎(chǔ)上,使用雙特征提取模塊,引入殘差特征提取模塊和GNN 特征提取模塊分別進(jìn)行特征提取。ResNet 是一種經(jīng)典的深度卷積網(wǎng)絡(luò),擅長(zhǎng)提取圖像的全局特征;GNN 特征提取模塊中的GraphSAGE,擅長(zhǎng)提取圖像的局部特征。雙特征提取模塊可以充分利用圖像的空間結(jié)構(gòu)信息和局部特征信息,從而提高模型的泛化能力。
在特征提取階段,殘差特征提取模塊將圖像轉(zhuǎn)換為全局特征向量,GNN 特征提取模塊則將圖像序列化為圖,并使用GNN 進(jìn)行圖像節(jié)點(diǎn)特征的聚合,得到每個(gè)圖像的局部特征向量。隨后,將全局特征向量和局部特征向量進(jìn)行融合,獲得具有更全面圖像信息的特征向量。在分類階段,使用標(biāo)簽平滑交叉熵?fù)p失函數(shù)計(jì)算損失,用歐氏距離度量樣本與各個(gè)類原型間的距離進(jìn)行分類。基于GNN 的小樣本圖像分類模型如圖1 所示。
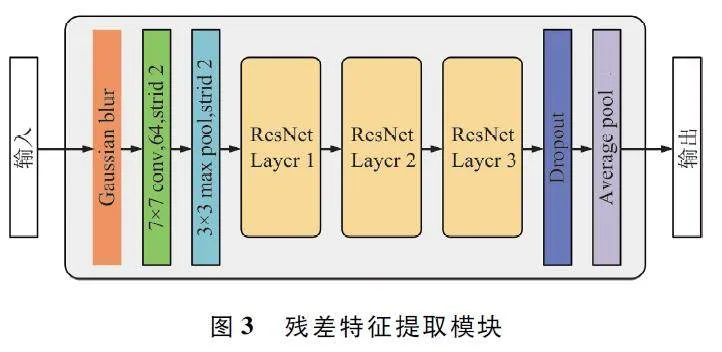
1. 3 殘差特征提取模塊
ResNet 由多個(gè)殘差模塊組成,在防止梯度消失和加強(qiáng)特征提取能力方面效果良好。ResNet 的核心是殘差結(jié)構(gòu)。殘差結(jié)構(gòu)[27]的思想是:將原本要學(xué)習(xí)的函數(shù)H(x)改為學(xué)習(xí)F(x)= H(x)-x,其中x 是輸入。如H(x)的梯度較小或消失,則F(x)的梯度仍有可能較大,從而避免梯度消失問(wèn)題。ResNet 的計(jì)算如下:
y = H(x) = F(x)+ x, (1)
式中:y 為輸出,F(x)為殘差函數(shù),x 為輸入。
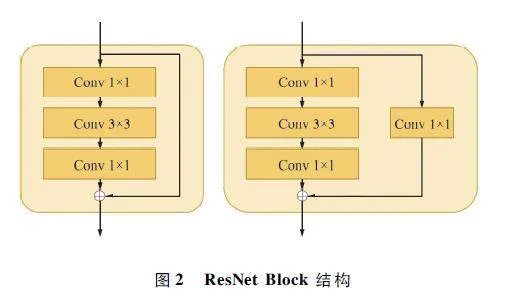
本文提出的殘差特征提取模塊中包含4 個(gè)ResNetlayer,每個(gè)ResNet layer 由多個(gè)ResNet Block 組成。ResNet Block 結(jié)構(gòu)如圖2 所示,其計(jì)算如下:
y = F(x) = F(x;W)。(2)
為了避免殘差特征提取模塊學(xué)習(xí)到過(guò)多圖片噪聲,在其輸入端添加了高斯濾波器。高斯濾波器能夠有效消除圖片噪聲,其輸出在局部區(qū)域是平滑的,并且具有平滑的邊緣,能夠保持圖片的整體結(jié)構(gòu)。高斯濾波器是一種線性濾波器,其輸出如下:
式中:y 為高斯濾波器的輸出,wi 為濾波器的權(quán)重,bi 為濾波器的偏置,x 為輸入,σ 為濾波器的標(biāo)準(zhǔn)差。
在小樣本學(xué)習(xí)中,由于訓(xùn)練數(shù)據(jù)量有限,模型容易過(guò)擬合。為了防止過(guò)擬合,在ResNet layer 后添加了Dropout 模塊,對(duì)特征進(jìn)行稀疏化。Dropout 操作會(huì)隨機(jī)丟棄一部分特征,從而增加模型的隨機(jī)性和魯棒性,提高模型的泛化能力。Dropout 操作的輸出如式下:
y = x⊙d, (4)
式中:x 為輸入特征矩陣,d 為Dropout 矩陣,⊙為按元素相乘運(yùn)算。
Dropout 矩陣的生成方法如下:
d = Bernoulli(p), (5)
式中:Bernoulli(p)表示伯努利分布,p 表示Dropout率,即在訓(xùn)練過(guò)程中丟棄特征的概率。在訓(xùn)練過(guò)程中,生成Dropout 矩陣d。將輸入特征矩陣x 與Dropout 矩陣d 按元素相乘,得到Dropout 操作的輸出y。模型使用輸出y 進(jìn)行訓(xùn)練。
在殘差特征提取模塊中,首先使用高斯濾波器對(duì)圖像進(jìn)行處理,以去除圖像中的噪聲并提高圖像的整體質(zhì)量。然后通過(guò)1 ×1 的卷積和最大池化操作,有效地提取輸入圖像中的特征,并降低特征圖的維度。接著通過(guò)4 個(gè)ResNet layer,每個(gè)ResNet layer由多個(gè)ResNet Block 組成,其中ResNet Block 由2 個(gè)卷積層和一個(gè)殘差連接構(gòu)成。殘差連接可以有效地防止梯度消失,提高模型的深度可訓(xùn)練性。然后通過(guò)Dropout 層,在訓(xùn)練過(guò)程中隨機(jī)丟棄一部分特征,從而增加模型的隨機(jī)性和魯棒性,提高模型的泛化能力,避免過(guò)擬合情況。最后通過(guò)平均池化層,在降低模型的計(jì)算量的同時(shí)保留特征圖中的均值信息,提高模型的魯棒性。殘差特征提取模塊如圖3 所示。
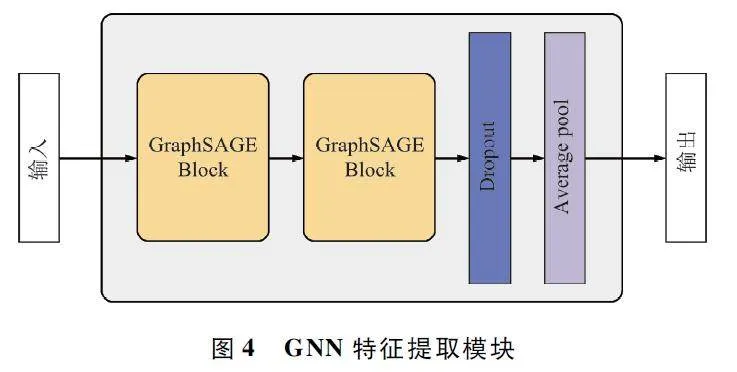
1. 4 GNN 特征提取模塊
為了提取樣本圖像的局部特征,在殘差特征提取模塊的基礎(chǔ)上引入一個(gè)GNN 模塊組合成雙提特征提取器。GNN 可以通過(guò)學(xué)習(xí)圖中的節(jié)點(diǎn)和邊的關(guān)系,從而提取圖中的信息。本文使用GraphSAGE[28]構(gòu)建GNN 特征提取模塊,它基于鄰居聚合(Neighborhood Aggregation),將每個(gè)節(jié)點(diǎn)的特征聚合為一個(gè)新的特征,該特征包含了該節(jié)點(diǎn)和其鄰居的相關(guān)信息。一個(gè)GraphSAGE 模塊的運(yùn)行流程可以分為2 個(gè)步驟:① 鄰居采樣;② 聚合。
在鄰居采樣階段,為了降低計(jì)算復(fù)雜度,對(duì)每個(gè)頂點(diǎn)采樣a 個(gè)鄰居頂點(diǎn)作為待聚合信息的頂點(diǎn)。如果頂點(diǎn)的鄰居數(shù)少于a,則采用有放回抽樣,直到采樣出a 個(gè)頂點(diǎn);如果頂點(diǎn)的鄰居數(shù)多于a,則采用無(wú)放回抽樣。由于本文中的輸入為圖像,因此構(gòu)建的鄰接矩陣將圖像像素視為圖的節(jié)點(diǎn),并在相鄰像素之間建立邊連接。以此用于鄰居采樣。
在聚合階段,采用mean 聚合函數(shù)聚合鄰居頂點(diǎn)蘊(yùn)含的信息,其運(yùn)算如下所示。
hkv← σ(W·MEAN({hk -1v }∪ {hk -1u ,?u ∈ N(v)})),(6)
式中:hv 為節(jié)點(diǎn)v 的特征向量,hu 為節(jié)點(diǎn)u 的特征向量,σ 為非線性激活函數(shù),W 為鄰接矩陣,N(v)為節(jié)點(diǎn)v 的鄰居節(jié)點(diǎn)集合,k 為聚合深度。
本文提出的GraphSAGE 構(gòu)建的GNN 特征提取模塊如圖4 所示。該模塊首先將輸入圖片的每個(gè)像素視為圖的節(jié)點(diǎn),并構(gòu)建鄰接矩陣。鄰接矩陣表示了圖中節(jié)點(diǎn)之間的連接關(guān)系。然后,該模塊通過(guò)2 個(gè)GraphSAGE 模塊提取圖像的局部特征。GraphSAGE模塊是一種基于鄰居聚合的GNN,通過(guò)聚合每個(gè)節(jié)點(diǎn)的鄰居信息,來(lái)更新節(jié)點(diǎn)的特征。最后,該模塊通過(guò)Flatten 和自適應(yīng)平均池化調(diào)整輸出特征的形狀。Flatten 操作將多維張量展平為一維張量。自適應(yīng)平均池化操作根據(jù)輸入張量的大小,選擇合適的池化窗口大小。
1. 5 雙特征提取結(jié)構(gòu)
如圖4 所示,本文所提出的GBProtoNet 設(shè)計(jì)了2 個(gè)網(wǎng)絡(luò),分別提取圖片的全局特征和局部特征。圖3 所示的殘差特征提取模塊為Encoder 1,表示為f1(x),x 為輸入的圖片,用于提取圖片全局特征。圖4 所示的GNN 特征提取模塊為Encoder 2,表示為f2(x),用于提取圖片局部特征。2 個(gè)特征提取模塊輸出的特征向量尺寸均為1×2 048。
分別提取全局特征和局部特征后,使用下式對(duì)2 個(gè)特征進(jìn)行合并,生成圖片的融合特征。
f(x) = Cat(f1(x),f2(x)), (7)
式中:Cat()操作在最后一個(gè)維度對(duì)特征向量進(jìn)行拼接,融合特征f(x)的特征向量尺寸為1×4 096。
1. 6 損失函數(shù)
交叉熵?fù)p失(Cross Entropy Loss)函數(shù)是一種常用的損失函數(shù),多用于分類任務(wù)。其計(jì)算如下:
式中:M 表示類別數(shù)量,yic 表示符號(hào)函數(shù),pic 表示觀測(cè)樣本i 屬于類別c 的預(yù)測(cè)概率。
交叉熵?fù)p失函數(shù)衡量了2 個(gè)概率分布之間的差異。在分類任務(wù)中,真實(shí)標(biāo)簽表示樣本的真實(shí)類別,預(yù)測(cè)概率表示模型對(duì)樣本的預(yù)測(cè)類別。它的值越小,表示模型對(duì)樣本的預(yù)測(cè)類別與真實(shí)類別越接近,也就是說(shuō)模型的預(yù)測(cè)結(jié)果越準(zhǔn)確。
但交叉熵?fù)p失函數(shù)在訓(xùn)練過(guò)程中可能會(huì)出現(xiàn)震蕩,并對(duì)噪聲敏感,會(huì)影響模型的收斂速度和對(duì)噪聲的魯棒性。因此本文使用標(biāo)簽平滑交叉熵?fù)p失函數(shù)(Smooth Cross Entropy),通過(guò)加入一個(gè)平滑項(xiàng),可以減小梯度的大小,從而提高模型的穩(wěn)定性,計(jì)算如下:
式中:K 為類別數(shù)量,yk 為觀測(cè)樣本的類別,pk 為樣本屬于類別k 的預(yù)測(cè)概率,α 為平滑參數(shù)。
2 實(shí)驗(yàn)
2. 1 數(shù)據(jù)集
本文在miniImageNet[13]和CUB-2002-2011[29]數(shù)據(jù)集上進(jìn)行了實(shí)驗(yàn)。miniImageNet 數(shù)據(jù)集是ImageNet 數(shù)據(jù)集的一個(gè)子集,共有100 個(gè)類別,每個(gè)類別包含600 張彩色圖片,共60 000 張。CUB-2002-2011 數(shù)據(jù)集是一個(gè)鳥類數(shù)據(jù)集,共有200 個(gè)類別,共11 788 張圖片,該數(shù)據(jù)集由加州理工學(xué)院于2010 年提出。由于2 個(gè)數(shù)據(jù)集的圖片尺寸大小不一,為方便進(jìn)行訓(xùn)練,在預(yù)處理階段,將所有圖片的大小設(shè)置為3×128 pixel×128 pixel。
訓(xùn)練集、驗(yàn)證集和測(cè)試集在數(shù)據(jù)集中的占比分別為64% 、16% 、20% 。在miniImageNet 數(shù)據(jù)集上,訓(xùn)練集包含38 400 張圖片,共64 個(gè)類別;驗(yàn)證集包含9 600 張圖片,共16 個(gè)類別;測(cè)試集包含12 000 張圖片,共20 個(gè)類別。在CUB-2002-2011 數(shù)據(jù)集上,訓(xùn)練集包含7 545 張圖片,共128 個(gè)類別;驗(yàn)證集包含1 886 張圖片,共32 個(gè)類別;測(cè)試集包含2 357 張圖片,共40 個(gè)類別。值得注意的是,CUB-2002-2011數(shù)據(jù)集并非全是彩色圖片,因此本文在預(yù)處理階段將一維圖像擴(kuò)充為三維圖像。數(shù)據(jù)集的示例如圖5所示。
2. 2 實(shí)驗(yàn)設(shè)置
本文的所有實(shí)驗(yàn)均在Ubuntu 20. 04 系統(tǒng)上,NVIDIA RTX A5000 (24 GB),在PyTorch 1. 11. 0、Python 3. 8 和CUDA 11. 3 環(huán)境下進(jìn)行。實(shí)驗(yàn)中使用AdamW 優(yōu)化器進(jìn)行訓(xùn)練,學(xué)習(xí)率初始值為0. 000 1,衰減系數(shù)為0. 5,每10 個(gè)epoch 衰減一次。訓(xùn)練采用余弦退火學(xué)習(xí)率調(diào)整策略,訓(xùn)練輪數(shù)為200。本實(shí)驗(yàn)使用5-Way 1-Shot 和5-Way 5-Shot 實(shí)驗(yàn)策略進(jìn)行訓(xùn)練。
2. 3 評(píng)價(jià)指標(biāo)
為了評(píng)估本文提出的方法在小樣本分類任務(wù)上的有效性,使用分類準(zhǔn)確率作為主要性能指標(biāo)。在miniImageNet 和CUB-2002-2011 數(shù)據(jù)集上,本文的GB-ProtoNet 和其他對(duì)比實(shí)驗(yàn)的精度,均使用1 000 個(gè)epoch 的測(cè)試結(jié)果計(jì)算平均準(zhǔn)確率,并計(jì)算了每個(gè)模型分類準(zhǔn)確率的95% 置信區(qū)間。準(zhǔn)確率計(jì)算如下:
ACC = TP + TN/TP + FN + FP + TN, (10)
式中:真陽(yáng)性(TP)表示正確分類為正類的正樣本,假陰性(FN)表示被誤分類為負(fù)類的正樣本,假陽(yáng)性(FP)表示被誤分類為正類的負(fù)樣本,真陰性(TN)表示正確分類為負(fù)類的負(fù)樣本。
2. 4 對(duì)比實(shí)驗(yàn)結(jié)果
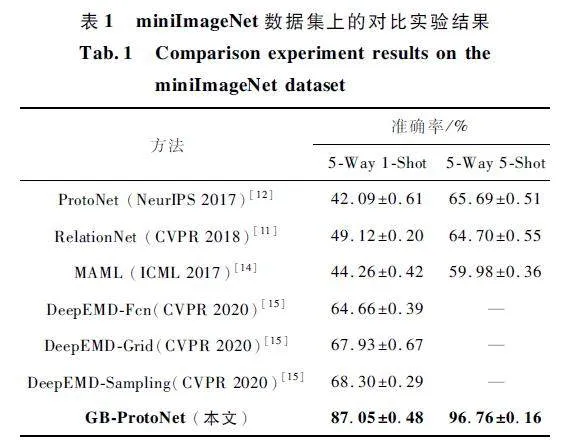
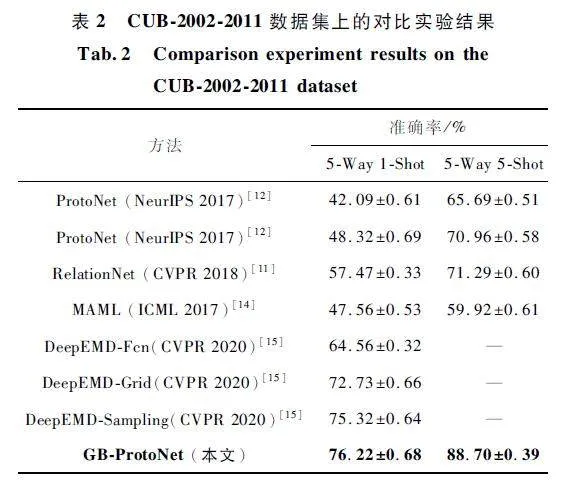
為了驗(yàn)證本文所提GB-ProtoNet 模型的有效性,分別與多種小樣本學(xué)習(xí)方法進(jìn)行對(duì)比實(shí)驗(yàn),如Pro-toNet、RelationNet、MAML、DeepEMD 等模型,并在miniImageNet 和CUB-2002-2011 數(shù)據(jù)集上進(jìn)行對(duì)比實(shí)驗(yàn),結(jié)果如表1 和表2 所示。
從表1 和表2 可以看出,GB-ProtoNet 在2 個(gè)數(shù)據(jù)集上都取得了最優(yōu)的性能。在miniImageNet 數(shù)據(jù)集上,1-Shot 設(shè)置的準(zhǔn)確率為86. 96% ,5-Shot 設(shè)置的準(zhǔn)確率為96. 76% 。在CUB-2002-2011 數(shù)據(jù)集上,1-Shot 設(shè)置的準(zhǔn)確率為76. 13% ,5-Shot 設(shè)置的準(zhǔn)確率為88. 70% 。與其他方法相比,GB-ProtoNet的優(yōu)勢(shì)主要體現(xiàn)在以下方面。
利用GNN 捕捉圖像的局部特征。GNN 能夠有效地學(xué)習(xí)圖像中的節(jié)點(diǎn)信息,這對(duì)于小樣本圖像分類任務(wù)非常重要。GB-ProtoNet 使用GraphSAGE 來(lái)生成圖像特征,通過(guò)鄰接聚合學(xué)習(xí)圖的節(jié)點(diǎn)特征,從而能夠更好地捕捉圖像的局部信息。
使用雙特征提取模塊進(jìn)行分類。雙特征提取模塊能夠從全局和局部?jī)煞矫鎭?lái)學(xué)習(xí)特征,可以提高分類性能。GB-ProtoNet 使用2 個(gè)特征提取模塊,其中殘差特征提取模塊用于生成圖像全局特征,GNN特征提取模塊用于生成局部特征。
2. 5 消融實(shí)驗(yàn)
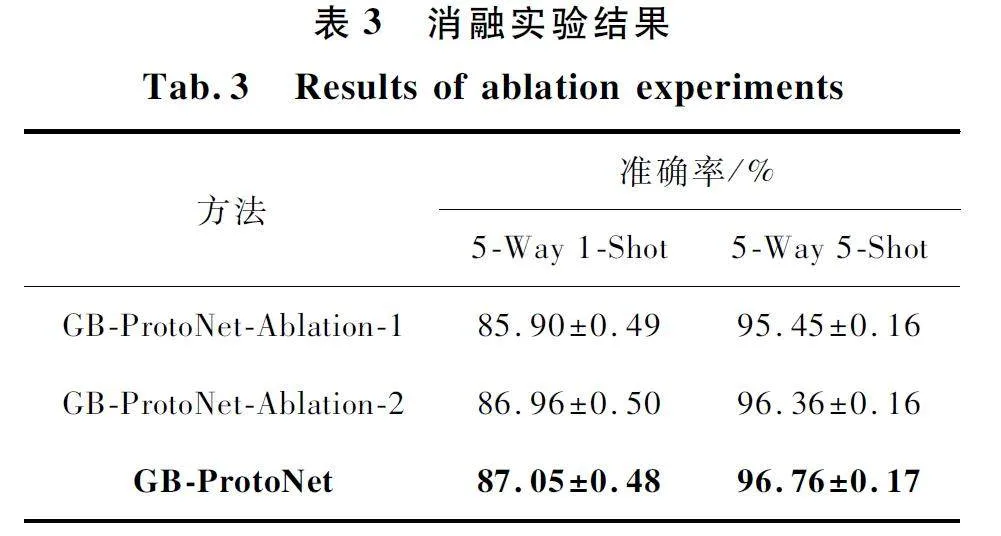
消融實(shí)驗(yàn)是評(píng)估模型性能的重要手段之一。通過(guò)消融實(shí)驗(yàn),可以分析模型的不同組成部分對(duì)性能的影響,從而更好地理解模型的工作機(jī)制。在數(shù)據(jù)集miniImageNet 上對(duì)GB-ProtoNet 進(jìn)行消融實(shí)驗(yàn),以分析GNN 特征提取模塊和標(biāo)簽平滑的交叉熵?fù)p失函數(shù)對(duì)模型性能的影響。實(shí)驗(yàn)結(jié)果如表3 所示。
在消融實(shí)驗(yàn)中,GB-ProtoNet-Ablation-1 為保留殘差特征提取模塊、使用交叉熵?fù)p失函數(shù)的模型,GB-ProtoNet-Ablation-2 為保留雙特征提取模塊、使用交叉熵?fù)p失函數(shù)的模型,GB-ProtoNet 為使用雙特征提取模塊、使用標(biāo)簽平滑交叉熵?fù)p失函數(shù)的模型。實(shí)驗(yàn)結(jié)果表明,當(dāng)添加GNN 特征提取模塊時(shí),分類效果有所提升,說(shuō)明GNN 能有效提取模型的局部信息,增強(qiáng)模型的特征提取能力。模型GB-ProtoNet 在miniImageNet 數(shù)據(jù)集上的5-Way 1-Shot 和5-Way 5-Shot 兩種設(shè)置的分類性能最佳,準(zhǔn)確率分別達(dá)到87. 05% 和96. 76% 。
3 結(jié)束語(yǔ)。
現(xiàn)有的小樣本圖像分類模型存在特征提取不足、信息單一等問(wèn)題。針對(duì)這些問(wèn)題,提出了一種結(jié)合GNN 的雙特征提取的原型網(wǎng)絡(luò)———GB-ProtoNet。GB-ProtoNet 采用雙特征提取器,分別使用ResNet和基于GraphSAGE 的GNN 提取樣本的全局特征和局部特征。全局特征反映了樣本的整體信息,而局部特征反映了樣本的局部細(xì)節(jié)。在訓(xùn)練階段,GB-ProtoNet 使用標(biāo)簽平滑交叉熵?fù)p失函數(shù),該損失函數(shù)可以有效緩解模型在訓(xùn)練過(guò)程中的極端值問(wèn)題,提高模型的穩(wěn)定性。通過(guò)對(duì)比實(shí)驗(yàn),本文提出的GB-rotoNet 模型在miniImageNet 數(shù)據(jù)集上,1-Shot設(shè)置下的準(zhǔn)確率為86. 96% ,5-Shot 設(shè)置下的準(zhǔn)確率為96. 76% ;在CUB-2002-2011 數(shù)據(jù)集上,1-Shot 設(shè)置下的準(zhǔn)確率為76. 13% ,5-Shot 設(shè)置下的準(zhǔn)確率為88. 70% 。相較于ProtoNet、RelationNet、MAML、DeepEMD 等同類模型,GB-ProtoNet 在2 個(gè)數(shù)據(jù)集上均取得了最優(yōu)性能,充分驗(yàn)證了其先進(jìn)性和有效性。
參考文獻(xiàn)
[1] XU M L,YOON S,FUENTES A,et al. A ComprehensiveSurvey of Image Augmentation Techniques for DeepLearning[J]. Pattern Recognition,2022,137:109347.
[2] KHALIFA N E,LOEY M,MIRJALILI S. A ComprehensiveSurvey of Recent Trends in Deep Learning for Digital Images Augmentation [J ]. Artificial Intelligence Review,2021,55(3):2351-2377.
[3] GOODFELLOW I,POUGETABADIE J,MIRZA M,et al.Generative Adversarial Networks[J]. Communications ofthe ACM,2020,63(11):139-144.
[4] ALIGOMBE A,ELYAN E. MFCGAN:ClassimbalancedDataset Classification Using Multiple Fake Class GenerativeAdversarial Network [J ]. Neurocomputing,2019,361:212-221.
[5] YANG H,ZHOU Y. IDAGAN:A Novel Imbalanced CataAugmentation GAN[C]∥2020 25th International Conference on Pattern Recognition (ICPR). Milan:IEEE,2021:8299-8305.
[6] ZHUANG F Z,QI Z Y,DUAN K Y,et al. A ComprehensiveSurvey on Transfer Learning [J ]. Proceedings of theIEEE,2020,109(1):43-76.
[7] AGARWAL N,SONDHI A,CHOPRA K,et al. TransferLearning:Survey and Classification[J]. Smart Innovationsin Communication and Computational Sciences,2021,1168:145-155.
[8] LI X X,SUN Z,XUE J H,et al. A Concise Review of Recent Fewshot MetaLearning Methods[J]. Neurocomputing,2021,456:463-468.
[9] PENG H. A Comprehensive Overview and Survey of RecentAdvances in Metalearning [EB / OL]. (2020 - 04 - 17 )[2024-02-01]. https:∥arxiv. org / abs/ 2004. 11149.
[10] LI X X,YANG X C,MA Z Y,et al. Deep Metric Learningfor Fewshot Image Classification:A Review of Recent Developments[J]. Pattern Recognition,2023,138:109381.
[11] SUNG F,YANG Y X,ZHANG L,et al. Learning to Compare:Relation Network for Fewshot Learning[C]∥2018IEEE / CVF Conference on Computer Vision and PatternRecognition (CVPR). Salt Lake City:IEEE Computer Society,2018:1199-1208.
[12] SNELL J,SWERSKY K,ZEMEL R. Prototypical Networksfor Fewshot Learning[C]∥Proceedings of the 31st International Conference on Neural Information Processing Systems. New York:ACM,2017:4080-4090.
[13] VINYALS O,BLUNDELL C,LILLICRAP T,et al. MatchingNetworks for One Shot Learning [C]∥ Proceedings of the30th International Conference on Neural Information Processing Systems. [S. l. ]:ACM,2016:3637-3645.
[14] FINN C,ABBEEL P,LEVINE S. Modelagnostic Metalearning for Fast Adaptation of Deep Networks[C]∥ International Conference on Machine Learning. Sydney:ACM,2017:1126-1135.
[15] ZHANG C,CAI Y J,LIN G S,et al. DeepEMD:Differentiable Earth Movers Distance for Fewshot Learning [J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2022,45(5):5632-5648.
[16] 任維鑫,曹新亮,白宗文. 一種單樣本農(nóng)作物病害識(shí)別方法[J]. 無(wú)線電工程,2023,53(2):484-489.
[17] YU Z C,WANG K,XIE S X,et al. Prototypical NetworkBased on Manhattan Distance[J]. Computer Modeling inEngineering & Sciences,2022,131(2):655-675.
[18] 陸妍,王陽(yáng)萍,王文潤(rùn). 基于Transformer 的小樣本細(xì)粒度圖像分類方法[J]. 計(jì)算機(jī)工程與應(yīng)用,2023,59(23):219-227.
[19] 許華杰,梁書偉. 采用特征圖增強(qiáng)原型的小樣本圖像分類方法[J]. 計(jì)算機(jī)科學(xué)與探索,2024,18 (4 ):990-1000.
[20] ZHOU J,CUI G Q,HU S D,et al. Graph Neural Networks:A Review of Methods and Applications [J]. AI Open,2020,1:57-81.
[21] 楊潔,董一鴻,錢江波. 基于圖神經(jīng)網(wǎng)絡(luò)的小樣本學(xué)習(xí)方法研究進(jìn)展[J]. 計(jì)算機(jī)研究與發(fā)展,2024,61(4):856-876.
[22] ZHONG X,GU C,YE M,et al. Graph ComplementedLatent Representation for Fewshot Image Classification[J ]. IEEE Transactions on Multimedia,2023,25:1979-1990.
[23] XIONG C,LI W,LIU Y,et al. Multidimensional EdgeFeatures Graph Neural Network on Fewshot Image Classification[J]. IEEE Signal Processing Letters,2021,28:573-577.
[24] TONG X Y,YIN J H,HAN B N,et al. Fewshot Learningwith Attentionweighted Graph Convolutional Networks forHyperspectral Image Classification[C]∥IEEE InternationalConference on Image Processing (ICIP ). Abu Dhabi:IEEE,2020:1686-1690.
[25] CHEN C,LI K L,WEI W,et al. Hierarchical GraphNeural Networks for Fewshot Learning[J]. IEEE Transactions on Circuits and Systems for Video Technology,2022,32(1):240-252.
[26] 李凡,賈東立,姚昱,等. 結(jié)合殘差與自注意力機(jī)制的圖卷積小樣本圖像分類網(wǎng)絡(luò)[J]. 計(jì)算機(jī)科學(xué),2023,50(增刊1):376-380.
[27] HE K M,ZHANG X Y,REN S Q,et al. Deep ResidualLearning for Image Recognition[C]∥Proceedings of theIEEE Conference on Computer Vision and Pattern Recognition. Las Vegas:IEEE,2016:770-778.
[28] HAMILTON W L,YING Z,LESKOVEC J. Inductive Representation Learning on Large Graphs[C]∥ Proceedingsof the 31st International Conference on Neural InformationProcessing Systems. New York:ACM,2017:1025-1035.
[29] WAH C,BRANSON S,WELINDER P,et al. The CaltechUCSD Birds2002011 Dataset[DB]. [2024-01-10]. http:∥www. vision. caltech. edu / datasets / cub_200_2011 / .
作者簡(jiǎn)介
齊露露 女,(1998—),碩士研究生。主要研究方向:小樣本圖像分類。
(*通信作者)俞衛(wèi)琴 女,(1982—),博士,副教授,碩士生導(dǎo)師。主要研究方向:非線性動(dòng)力學(xué)理論與應(yīng)用。
