基于人工智能的圖書館數據管理內容與體系構建研究
2024-08-19 00:00:00白忠睿陳臣李若冰
圖書館學刊 2024年7期
[摘 要]圖書館具有數據海量、類型繁多、價值密度低、處理速度快的數據環境,基于AI的數據管理策略可以有效提升圖書館數據管理的科學性、智慧性、經濟性和安全性。研究大數據時代圖書館數據管理的內容與目標,構建圖書館基于AI的數據治理體系,提出大數據環境下圖書館基于AI的數據管理策略,為構建智慧圖書館與讀者個性化服務定制提供可靠的數據決策支持。
[關鍵詞]人工智能 圖書館 數據 管理
[分類號] G250.7
隨著大數據、云計算、物聯網、高速移動傳輸網絡技術的飛速發展,圖書館的數據呈現海量(Volume)、高速(Velocity)、多樣(Variety)、高價值(Value)的“4V”數據特征,這些大數據既是圖書館智慧決策與讀者個性化服務的科學依據,也是圖書館智慧服務體系的重要組成部分。
據國際數據公司(IDC)預測,中國是世界上數據總量增速最快的國家,平均每年的增速比全球平均速度快3%。預計到2025年將增至48.6ZB,占全球數據總量的27.8%,且年均復合增長率將達到30.35%[1]。隨著算法應用模型、數據決策理論和數據智慧服務場景的優化與創新,大數據的價值、數據總量增速、結構復雜度及數據來源多樣性和可用性遠高于其他行業的平均水平,因此,如何利用人工智能(AI)技術實現數據資產的科學管理,是智慧圖書館建設的關鍵要素之一
1 圖書館AI數據管理的意義
1.1 提升數據決策智慧程度
大數據時代雖然為圖書館提供了強大的數據采集、傳輸、存儲、分析和決策的信息技術基礎設施系統支持,但傳統的數據管理與應用系統建設缺乏整體規劃,各子系統僅能單一、獨立地處理個性化問題,不能統一、協調地實現大數據分析與決策的部署與傳輸,使圖書館內部形成多個數據孤島和不同的數據標準。此外,數據與讀者個性化需求的匹配度決定了圖書館服務智慧水平,AI數據管理可為圖書館服務決策提供海量、精確和高價值密度的訓練數據,實現讀者個性化智慧服務的精準落地[2]。
1.2 提高圖書館智慧服務質量
數據治理的科學性、高效性、經濟性和智慧化程度,直接關系智慧圖書館決策的科學性和圖書館讀者智慧服務推送的有效性,AI數據管理能有效提高圖書館智慧服務質量。目前,圖書館數據治理涉及數據的采集、傳輸、存儲、處理、分析、AI訓練、推理、決策和應用等步驟,除圖書館IT應用系統的數據處理能力、數據治理工具外,AI人才、AI數據治理環節的流程化、標準化、體系化和業務兼容性程度等,也都是影響圖書館AI大數據治理效率和質量的關鍵因素。
1.3 提升大數據的價值總量
數據資產是圖書館的核心資產,基于AI技術的數據管理可以完全挖掘大數據價值,提供其價值密度,發現蘊藏其中的知識,實現數據的精細化管理。受當前數據的管理、處理、分析和決策技術限制,雖然非結構化數據占圖書館大數據總量的85%以上,但其使用率僅占圖書館大數據整體使用率的30%,整體處于待發現、挖掘和智慧決策的狀態[3]。采用AI技術對數據進行自動化智慧管理,實現數據的智慧采集、自動編目、應用系統集成、清洗、管理、隱私保護和共享,是圖書館解決海量、復雜、碎片化數據管理與應用的有效方法。
2 圖書館數據資產治理的內容
數據治理是圖書館安全、高效、經濟、可控地管理數據,完全挖掘數據價值,實現智慧圖書館建設和讀者個性化智慧服務的關鍵環節。圖書館數據治理涉及數據采集、傳輸、清洗、存儲、計算、分析和決策應用,這一過程也包含了數據從產生到消亡的全生命周期過程[4]。因此,圖書館數據治理應結合不同類型數據生命周期的結構特點,利用相應的數據治理工具和理論,在圖書館內實現數據的全閉環流程治理,不斷增強數據的智慧決策價值。
2.1 基于AI的圖書館數據類型劃分
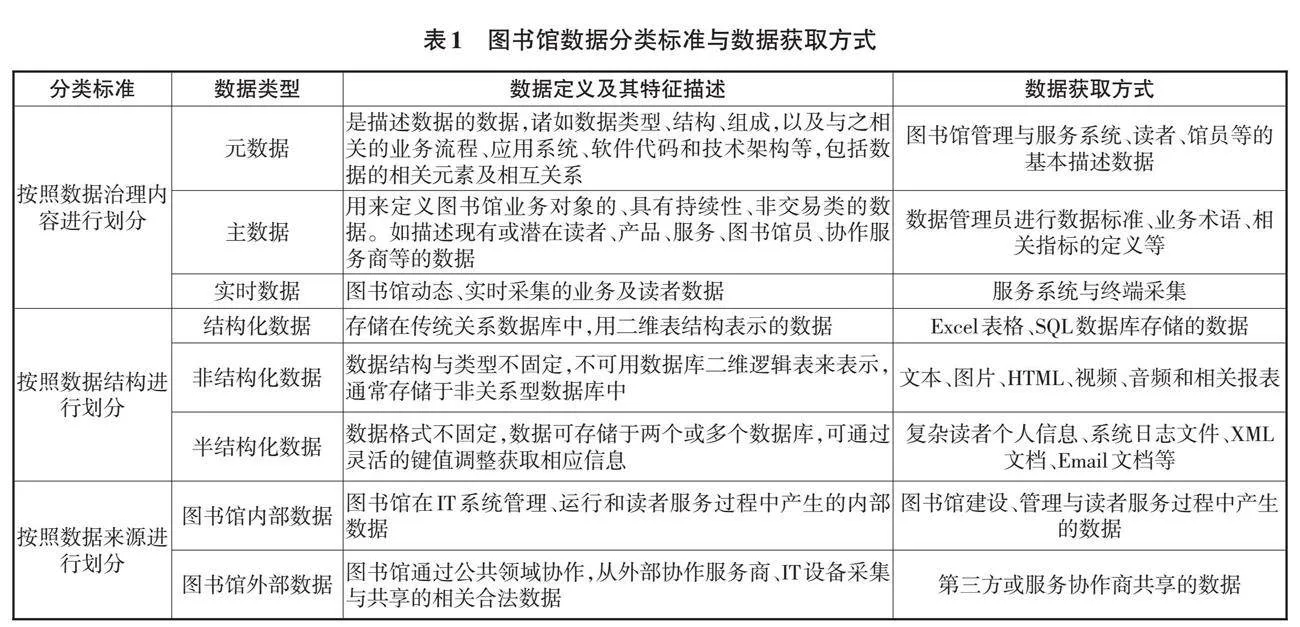
依據圖書館數據生命周期流程特點及數據治理內容、結構與來源劃分圖書館數據類型,如表1所示。
將數據按照治理內容進行劃分,可分為元數據、主數據和實時數據。依據圖書館數據結構和存儲、查詢、調試方式的不同,可將數據劃分為結構化、半結構化和非結構化數據,并根據各數據的特點實現數據安全、高效和經濟的管理與調度。半結構化數據與非結構化數據占據圖書館數據總量的85%以上,其中蘊藏著巨大的數據價值,是圖書館智慧決策與智慧服務所依據的主要內容[5]。此外,伴隨數據采集與傳輸技術的發展,圖書館外部采集和第三方服務商共享的數據,將會成為圖書館個性化智慧服務定制與推送的關鍵數據。圖書館必須依據數據的來源制定相應的安全管理和資源共享策略,才能確保數據安全、合法、實時、可靠地使用。
2.2 AI數據治理的內容與流程
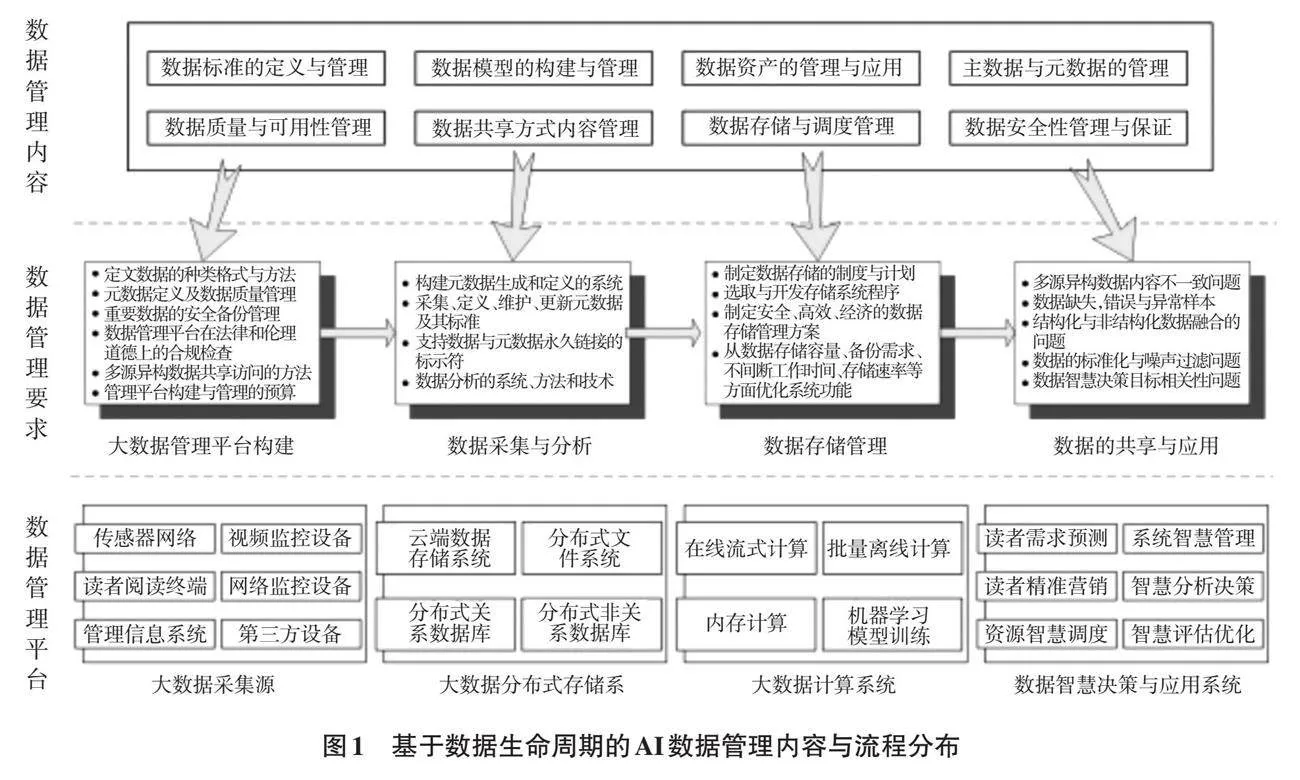
圖書館數據環境具有數據海量、結構復雜、多數據來源、低價值密度和處理高速的特點,因此,數據治理流程要以數據智慧決策需求為依據,包含從數據采集到智慧決策的全數據生命周期流程,避免全數據的治理陷阱,構建符合圖書館當前數據應用現狀及未來發展的安全管理框架,有效保證數據全生命周期流程管理的合法、合規性。此外,還應通過AI技術實現對多數據來源、非結構化數據的全流程管理,以數據的高價值密度保證、字段多樣性、分布科學性和決策實時性等方面為重點。基于數據生命周期的AI數據管理內容與流程,主要由數據管理的對象與內容、數據管理要求和數據管理平臺系統三部分組成,涉及數據管理全平臺、全生命周期流程、全數據科學決策需求和全智慧決策對象,如圖1所示[6]。
3 圖書館基于AI的數據治理體系構建
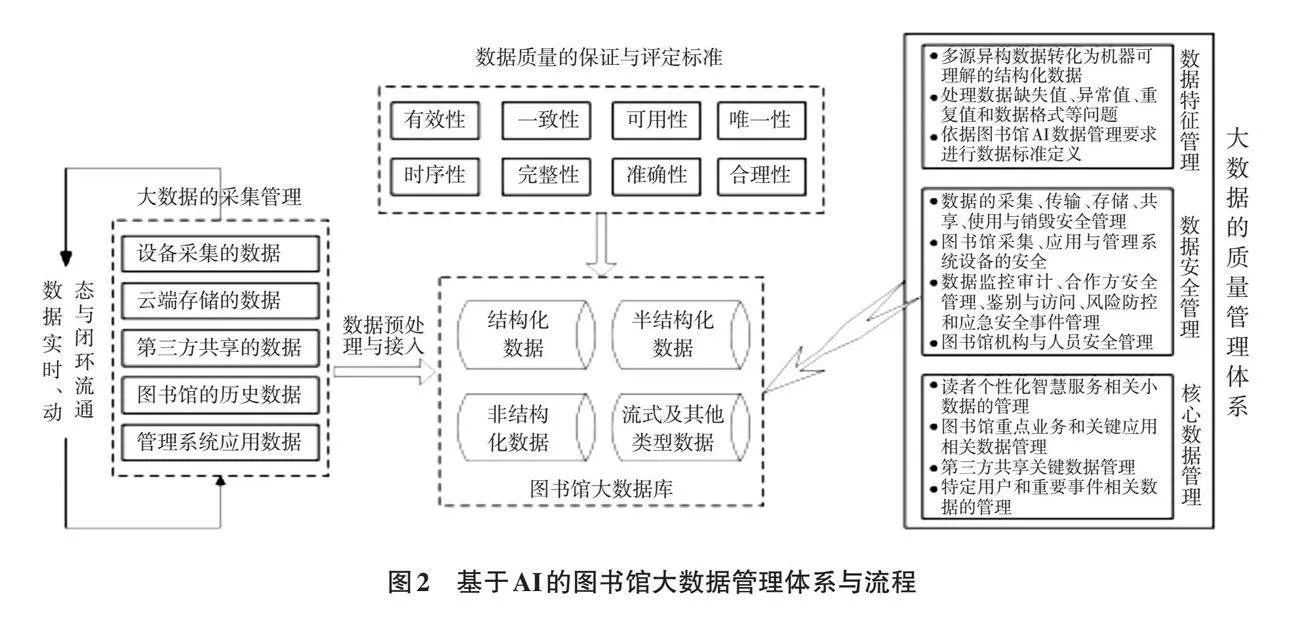
圖書館數據治理內容包括數據的采集、傳輸、清理、存儲、標注、處理、訓練、部署、決策和銷毀等操作,涉及大數據的全生命周期流程。基于AI的數據處理、算法開發、模型訓練、模型管理和應用部署等環節的科學性、可操作性,關系到圖書館數據治理的效率、科學性、可用性、經濟性和安全性,圖書館基于AI的大數據管理體系及流程如圖2所示。它是以圖書館大數據存儲庫為核心,涉及大數據的采集管理、數據質量的保證與評定標準、大數據的質量管理體系等環節的閉合應用數據管理體系流程[7]。
3.1 基于AI的圖書館數據采集管理
圖書館大數據的價值密度、準確性、時效性和決策科學性,直接關系到基于AI的數據管理系統模型在AI離線訓練和上線推理過程中的精確性[8]。因此,圖書館應加強對初始數據采集的質量管理,通過對數據在AI數據管理閉環流通模型中,進行噪聲過濾、價值量提升、應用相關性增強和智能標注等操作,結合圖書館數據管理AI模型中的離線訓練和上線推理過程,使圖書館采集數據更加科學、準確、實時和可用。此外,可通過圖書館AI優化數據的閉環流通,打造數據采集和回饋分析的閉環式自主學習體系,實現AI模型上線后的持續迭代優化,滿足不同復雜場景AI應用的需求。
3.2 數據質量的評定與有效性保證
圖書館數據質量的保證與評定標準,是與圖書館大數據AI治理與智慧決策的必要需求。圖書館數據具有異構多源、結構多樣、強實時性和多噪聲的特點,因此,其數據質量的評定標準主要由有效性、一致性、可用性、唯一性、時序性、完整性、合理性和準確性8個維度組成,在對圖書館數據的質量評估和訓練中,應對數據的可用性、唯一性、完整性和準確性4個維度給予較高的評估影響因子[9]。
此外,圖書館數據治理應根據數據的類型、結構、用途和作用對象等,動態調整評定標準的評估維度和內容。比如,讀者閱讀數據和圖書館用戶服務數據的AI訓練應結合讀者智慧閱讀滿意度和圖書館服務收益率。而占數據總量比較高的讀者個性化閱讀服務數據的評估中,應針對性地提高與數據時序性相關的實時性和時間間隔的影響因子,以增強數據管理模型AI訓練的科學性,不斷提升AI數據管理系統自動化管理的準確度、系統效率和智能化水平[10]。
3.3 圖書館AI大數據質量管理體系的構建
3.3.1 數據的采集管理與定義
圖書館采取的是實時、動態、全對象和360度的全數據采集模式,因此,圖書館AI數據管理模型只有通過統一的數據語言和標準,才能實現多來源、多決策對象和多應用系統數據的融合、共享與復用[11]。圖書館在數據類型結構與特征定義中,應結合國家、行業和地方相關數據標準,以及自身的數據特征環境和智慧應用業務實際,構建基礎數據標準、指標數據標準、缺失與異常數據標準和數據應用模型標準,以實現圖書館外部與內部多源數據的融合互通。
3.3.2 基于AI的數據安全管理
在基于AI的數據質量管理體系中,數據的安全性是關系智慧圖書館安全可靠度和讀者智慧閱讀服務滿意度的關鍵因素,安全性管理應涉及數據全生命周期應用流程。具體可通過數據安全的監控審計、協作第三方的安全管理、用戶身份與權限的鑒別、安全風險事件防控和應急安全事件管理、數據加密與防火墻安全系統構建等實現。在安全管理中,圖書館應通過AI訓練來持續提升IT系統的數據安全事件智能化預測、識別、分析、判斷和智慧決策能力,保證圖書館數據安全管理的智能、高效、自動、實時和自我優化[12]。
3.3.3 基于AI的核心數據管理
出于對投資收益的考慮,圖書館應將主要系統資源和AI管理策略應用于核心數據上[13]。核心數據主要由圖書館重點業務、IT關鍵應用數據、核心讀者群個體小數據、第三方協作服務商關鍵數據、數據中心IT系統重要事件生成數據、數據中心IT系統配置參數、用戶保密和隱私數據等組成,是關系圖書館服務安全性、讀者滿意度、系統管理智慧性和服務收益率的重要數據。在基于AI的核心數據管理中,圖書館應避免核心數據采集、存儲、分析和決策流程大而全的思路,依據核心數據對圖書館的IT管理業務、服務收益率、讀者滿意度、決策智慧性和決策科學性的影響因子數值大小,調整數據采集與應用的投入,確保最優服務收益率[14]。
3.4 圖書館大數據庫的AI訓練原則
圖書館通過AI對存儲系統的訓練與管理,可以有效提升圖書館數據存儲的智慧化、自動化和動態管控能力。第一,海量、高價值和強相關性數據是機器學習模型與算法科學性驗證、優化、提升的關鍵,圖書館必須依據AI機器訓練需求,為其提供總量為TB甚至PB級別的科學訓練數據。第二,圖書館為機器學習模型訓練數據的輸入/輸出速度、單位時間吞吐量及機器學習模型和AI算法并行處理訓練數據的能力,也是決定機器學習能力與時效性的關鍵因素。第三,依據數據的類型、安全存儲需求、用戶訪問頻率和數據量大小,將數據分別存儲于基于本地超高速網絡的存儲集群系統和云存儲系統,是圖書館目前采取的主要數據存儲方式。圖書館必須根據數據存儲網絡系統的負荷和數據流變化趨勢,根據AI訓練結果,精確掌握存儲系統傳輸網絡和數據庫系統的存儲瓶頸與動態負荷,才能有效進行存儲系統資源調度和負荷的動態均衡分配[15]。
4 結語
當前,自然語言處理、知識獲取與表現、機器學習、智能搜索、動態感知、模式識別和資源智慧組合調度等技術已成為智慧圖書館構建和讀者個性化閱讀服務的關鍵支撐,而圖書館海量、高價值和高相關性的數據恰是這些關鍵技術在智慧圖書館構建中落地的基礎與依據。伴隨著圖書館采集數據、系統生成數據、服務數據和讀者個人數據總量的指數級遞增,數據呈現海量、結構類型繁雜、低價值密度和高時效的特點,數據存儲也呈現出系統管理與服務終端、本地大數據庫、云存儲空間等多種存儲模式共存現象,圖書館的海量小文件數據、熱點目錄和讀多寫少的數據讀取模式,對大數據的存儲管理模式與應用決策方法提出了挑戰。因此,圖書館在基于AI技術的大數據智慧、自動化動態管理中,必須將降低冗余數據存儲總量、提升數據存儲效率、保證訓練數據高相關性和智慧服務有效性等作為數據管理的主要目標,在數據的采集、標注、處理、匹配、訓練和部署流程中,堅持應用海量、安全、精準和強相關性的原則,通過機器學習讓數據管理系統自動形成最優算法,實現AI數據管理系統的自我選擇、優化與更新[16]。
參考文獻:
[1] 安小米,等.國際標準中的數據治理:概念、視角及其標標準化協同路徑[J].中國圖書館學報,2021(5):59-79.
[2] 李國良,周煊赫.面向AI的數據管理技術綜述[J].軟件學報,2021(1):21-40.
[3] 梁俊榮.基于大數據決策的圖書館信息系統安全分析與管理研究[J].圖書館理論與實踐,2017(3):93-98.
[4] 葉蘭.高校圖書館科學數據管理服務能力成熟度模型構建與應用研究[J].圖書情報工作,2022(6):3-14.
[5] IBM data governance maturity model[EB/OL]. [2022-07-11].https://www.lightsondata.com/?s=IBM+data+governance+maturity+modelamp;tcb_sf_post_type%5B%5D=postamp;tcb_sf_post_type%5B%5D=page.
[6] 徐緒堪,薛夢瑤.面向大數據管理與應用專業的數據素養能力評價指標體系構建[J].情報理論與實踐,2021(9):50-56.
[7] 李冰,賓軍志.數據管理能力成熟度模型[J].大數據,2017(4):29-36.
[8] A guide to creating an effective big data management framework[EB/OL].[2024-01-05].https://journalofbigdata.springeropen.com/articles/10.1186/s40537-023-00801-9.
[9] 陳媛媛.高校科研數據管理服務能力研究[J].情報雜志,2020(6):203-207.
[10] 葉蘭.數據管理能力成熟度模型比較研究與啟示[J].圖書情報工作,2020(13):51-57.
[11] 崔建偉,趙哲,杜小勇.支撐機器學習的數據管理技術綜述[J].軟件學報,2021(3):604-621.
[12] 秦小燕,初景利.科學數據素養能力評價指標體系構建研究[J].圖書與情報,2020(4):56-66.
[13] ICPSR.Data Management amp; Curation[EB/OL].[2022-07-11]. https://www. icp sr. umich.edu/web/pages/data management/index.html.
[14] 孫路明,等.人工智能賦能的數據管理技術研究[J].軟件學報,2020(3):600-619.
[15] 柴茗珂,范舉,杜小勇.學習式數據庫系統:挑戰與機遇[J].軟件學報,2020(3):806-830.
[16] Sadri Z,Gruenwald L, Leal E. Online index selection using deep reinforcement learning for a cluster database[J].ICDEW,2020:158-161.
白忠睿 女,1991年生。碩士,館員。研究方向:閱讀推廣、信息資源管理。
陳 臣 男,1974年生。碩士,教授。研究方向:大數據、數字圖書館建設。
李若冰 女,1999年生。本科生在讀。研究方向:人工智能。
(收稿日期:2024-01-09;責編:劉清揚。)
猜你喜歡
今日農業(2022年15期)2022-09-20 06:56:20
商界(2019年12期)2019-01-03 06:59:05
IT經理世界(2018年20期)2018-10-24 02:38:24
小太陽畫報(2018年1期)2018-05-14 17:19:25
小康(2017年16期)2017-06-07 09:00:59
少年博覽·小學低年級(2016年10期)2016-11-24 06:48:23
南風窗(2016年19期)2016-09-21 16:51:29
雜文月刊(2016年1期)2016-02-11 10:35:51
漫畫月刊·炫版(2015年4期)2015-05-27 07:52:10
現代企業(2015年8期)2015-02-28 18:54:47
