基于低維二階馬爾可夫矩陣的加密流量分類方法
2024-06-29 22:43:18郭昊陳周國劉智冷濤郭先超張巖峰
四川大學學報(自然科學版) 2024年3期
關鍵詞:機器學習
郭昊 陳周國 劉智 冷濤 郭先超 張巖峰


摘要: 網絡流量加密在增強了通信安全與隱私保護的同時,也為惡意流量檢測帶來了新的挑戰. 近年來隨著機器學習在各領域成功應用,其也被應用于加密流量分類中,但傳統特征提取方法可能會導致流量中重要信息丟失或無效信息冗余,阻礙了分類精度與效率的進一步提升. 本文提出一種基于低維二階馬爾可夫矩陣的加密流量分類方法LDSM,用以篩選表征能力強的流量特征,從而優化模型分類效果. 首先,提取加密流量中有效負載,根據其十六進制字符空間分布構建二階馬爾可夫矩陣;其次,通過計算狀態轉移概率矩陣中各特征的基尼增益,迭代刪除對模型訓練貢獻最低的特征,取模型分類準確率最高的特征集合作為低維二階馬爾可夫矩陣特征;最后,通過實驗驗證低維二階馬爾可夫矩陣特征的模型訓練能力. 實驗中構建了Scikit-learn 的實驗環境,采用兩個公開數據集CTU-13 和CIC-IDS2017,實現對加密流量的分類任務,特征降維實驗結果表明,LDSM 方法將二階馬爾可夫矩陣特征降維至256 個特征時分類效果最佳,特征降維后僅為原特征數量的6. 25%,保證模型分類精度的同時提升了模型訓練效率;與其他方法對比實驗結果表明,LDSM 方法流量分類的平均準確率達到98. 51%,與其他方法相比,分類準確率提高3% 以上,所以LDSM 方法對于加密流量分類是可行且有效的.
關鍵詞: 加密流量; 機器學習; 馬爾可夫; 基尼增益; 特征降維
中圖分類號: TP393. 08 文獻標志碼: A DOI: 10. 19907/j. 0490-6756. 2024. 030003
1 引言
網絡流量分類是網絡空間安全和網絡管理領域的一項重要任務. 如今,隨著加密技術在保護用戶隱私方面的廣泛應用,網絡通信中加密流量的占比日益增多[1]. 不同類型加密流量之間的區別很小,傳統基于端口或基于簽名的流量分類方法不適用于加密流量識別,因此對不同類型加密流量的區分是一項具有挑戰性的任務. 近年來,機器學習在圖像分類[2]和文本識別[3]等領域取得了很好的效果,因此其也被廣泛應用于惡意流量檢測中[3-5].
相較于傳統方法,基于機器學習的分類方法可以在使得分類過程更加自動化的同時提高分類精度. 機器學習模型可以針對性的構建學習模型以適應惡意網絡流量的獨特特征,也可以擴展以處理大量數據,對網絡行為和流量環境的變化具有魯棒性. 將機器學習模型應用于加密流量分類領域需要采取合適的數據轉化方式將網絡數據包轉化為機器學習模型的輸入格式[6]. 圖像分類領域中樣本往往為固定尺寸的圖像,文本識別領域中模型通常用于分類明文語句,由于數據流量包不規則且所含信息為密文,故上述領域中的特征工程方法難以直接運用到加密流量領域中.
在早期研究中,一部分研究側重于提取流量的統計特征,如Meta 特征[7]統計包長度、傳輸時間間隔等特征,BD(Byte Distribution)特征[8]利用16×16 的矩陣統計不同字符的出現頻率,Man 等人[8]直接利用加密流量的196 項統計特征形成灰度圖像,這類方法雖然可以將所有原始流量轉化為具有相同格式的統計特征,但是卻忽略了流量中的數據空間信息,降低了模型的學習效果;一部分研究直接將原始流量中的有效字段轉換為向量或矩陣特征,如Tathri 等人[9]將原始流量轉化為灰度特征圖像,通過切片(當長度大于固定長度時)或填充(當長度小于固定長度時)數據包中的字節流有效負載,以獲得固定大小的矩陣,這類方法雖然可以有效地保留流量中的數據空間信息,但是卻只能通過截取或填充的方法統一特征格式,可能造成數據信息丟失或冗余. 除此之外Bai 等人[10]借用文本處理的方式作為數據轉換的方法,將網絡流量字段轉換成文本,但隨著更多加密協議的使用,有效負載被隨機加密,不再具有特定的語義.
2014 年,Korczynski 等人[11]首次提出了一種基于馬爾可夫鏈的加密流量分類方法,使用馬爾可夫模型進行流量分類和識別,他們利用給定應用程序的SSL/TLS 標頭中的一系列消息類型,以構建一階齊次馬爾可夫鏈作為該應用程序的統計指紋. 2017 年,Shen 等人[12]改進了Korczynski 等人的方法并提出了基于二階馬爾可夫鏈可感知屬性的加密流量分類方法. 2022 年,Tang 等人[13]基于流量文件中每個字節對應的ASCII 碼(0-255),構建一階馬爾科夫鏈特征用于流量分類;Cao 等人[14]提取流量文件中的二進制比特流,將長度為4 個比特的比特串作為一個基本單位,構建一階馬爾科夫特征圖像. 通過研究分析,發現上述文獻仍存在不足之處:
(1) 部分文獻側重于提取流量的統計特征,如包長度、傳輸時間間隔等,這種方法雖然可以將所有原始流量轉化為具有相同格式的統計特征,但是卻忽略了流量中的數據空間信息,降低了模型的學習效果.
(2) 一階馬爾可夫鏈特征的當前狀態僅由先前狀態決定,忽略了當前狀態與更早狀態的依賴關系,特征表征能力弱,導致模型學習不足.
(3) 二階馬爾可夫鏈特征數過多,概率轉移矩陣為稀疏矩陣,包含大量低區分度特征,模型訓練效率差,且有過擬合的風險.
針對以上問題,本文提出一種基于低維二階馬爾可夫矩陣(Low Dimensional Second-orderMarkov Matrix, LDSM)的加密流量分類方法,拼接原始流量中的有效負載,構建具有數據空間信息的二階馬爾可夫矩陣,提升了特征表征能力,根據基尼增益降低特征維度,刪除低區分度特征,優化了模型訓練開銷,降低了過擬合的風險.
2 方案設計
2. 1 整體流程
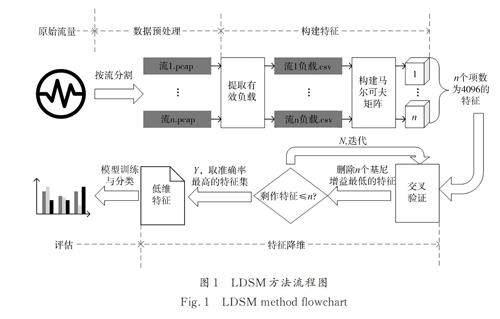
為了高效地識別網絡中的加密流量,本文提出了LDSM 方法,方法流程如圖1 所示. LDSM 方法由4 部分組成,第1 步為數據預處理,過濾無用數據包,并根據五元組(源IP 地址、源端口、目的IP地址、目的端口和傳輸層協議)將流量文件分割為網絡流;第2 步為構建特征,按十六進制讀取網絡流文件中的有效負載(0-F),以相鄰字符分布構建二階馬爾可夫矩陣;第3 步為特征降維,利用特征進行交叉驗證,迭代刪除基尼增益最低的n 項特征,直至剩余特征小于或等于n 項. 取迭代過程中準確率最高的特征集合作為低維二階馬爾可夫特征. 第4 步為評估,是將低維二階馬爾可夫特征隨機分為訓練集與測試集,由訓練集對模型進行訓練,將測試集輸入到已訓練完畢的模型中進行分類效果評估.
2. 2 數據預處理
為了評估LDSM 方法的加密流量分類效果,需要充足的加密流量集作為實驗數據集. 實驗使用CTU-13 數據集[15]和CICIDS-2017 數據集[16]作為惡意流量樣本. CTU-13 是2013 年由捷克理工大學捕獲的僵尸網絡流量數據集,其中共包含13個不同場景的僵尸網絡攻擊;CICIDS-2017 于2017 年由加拿大網絡安全所構建,其中共包含8 種不同的網絡攻擊. 正常流量樣本使用Wireshark 訪問Alexa 排名前列網站進行收集. 由于原始數據集含有較多雜流量,所以對數據集進行數據清洗,過濾雜流量,最后篩選出用于實驗的惡意流量共計4. 25 GB,正常流量共計4. 53 GB.
使用SplitCap. exe 工具,根據五元組信息(源IP 地址、源端口、目的IP 地址、目的端口和傳輸層協議)分割原始流量文件,生成的每個文件為一個單獨的網絡流,最終統計惡意流量TLS 流數共153 662 條,正常流量TLS 流數共162 362 條. 數據集分布如表1 所示.
猜你喜歡
電子技術與軟件工程(2016年22期)2016-12-26 21:36:42
時代金融(2016年27期)2016-11-25 17:51:36
科教導刊(2016年26期)2016-11-15 20:19:33
活力(2016年8期)2016-11-12 17:30:08
科學與財富(2016年28期)2016-10-14 21:19:17
電腦知識與技術(2016年20期)2016-08-19 18:49:49
電腦知識與技術(2016年12期)2016-06-14 00:45:31
科教導刊·電子版(2016年10期)2016-06-02 19:17:03
科教導刊·電子版(2016年10期)2016-06-02 18:04:11
電腦知識與技術(2016年3期)2016-04-07 16:12:55
