融合多點注意力機制的YOLOv7火焰目標檢測算法研究
2024-06-17 14:28:06張冬梅宋子濤范皓鑫
軟件工程 2024年6期
張冬梅 宋子濤 范皓鑫

摘?要:
針對復雜環境中,火焰檢測存在特征提取不足和邊緣模糊目標檢測性能欠缺問題,提出一種融合擠壓激勵(Squeeze\|and\|Excitation,SE)注意力機制的YOLOv7火焰目標檢測算法。該算法以YOLOv7為基礎框架,基于公開火焰數據集,對不同位置點插入SE注意力機制的網絡模型進行研究,進而構建融合多點注意力機制的YOLOv7_Attention網絡模型,以充分提取火焰的有效特征,抑制冗余特征。實驗結果表明,融合SE注意力機制的YOLOv7_Attention網絡模型與原始YOLOv7模型相比,其mAP提升了1.64百分點,邊緣模糊火焰目標檢測效果顯著。
關鍵詞:火焰圖像;目標檢測;注意力機制;YOLOv7
中圖分類號:TP391??文獻標志碼:A
0?引言(Introduction)
火焰探測作為一種火災報警系統的方法,已展現出極大的潛力和發展前景[1]。傳統火焰檢測方法必須依靠溫度、煙霧等傳感設備,容易受環境干擾且系統的穩定性差、誤報率高[2]。近年來,基于深度學習的計算機視覺技術發展迅速,在目標檢測任務中取得了較好的應用效果。目標檢測算法通常分為兩類:一類是以區域卷積神經網絡(Region\|based?Convolutional?Neural?Networks,R\|CNN)[3]為代表的兩階段模型,第一階段產生目標所在區域候選框,第二階段通過神經網絡對候選框進行分類和位置回歸;另一類是以單階多框目標檢測方法(Single?Shot?MultiBox?Detector,SSD)[4]、YOLO(You?Only?Look?Once,YOLO)系列[5\|7]為代表的端到端單階段模型,可以直接確定目標類別和位置且檢測速度較快。
基于深度學習的火焰檢測方法有多種。嚴云洋等[8]基于Faster?R\|CNN網絡識別火焰,大幅提升了火焰檢測精度和魯棒性。HAN等[9]采用了改進的CA\|SSD目標檢測模型,在保證實時準確定位吸煙者位置的基礎上,提高了吸煙檢測的準確性。楊天宇等[10]和徐巖等[11]利用YOLOv3系列算法,融合注意力機制,提高了火焰檢測效果。XU等[12]將YOLOv5與高效可擴展目標檢測器(Scalable?and?Efficient?Object?Detection,EfficientDet)協同工作并行檢測火災,最大化地利用了全局特征和局部特征,提升了小目標檢測精度,提高了召回率。
YOLOv7算法[13]是YOLO系列中高效且重要的目標檢測算法之一,但依然存在特征提取能力不足的問題。本文研究在不同點插入SE注意力機制的網絡模型,進一步構建融合多點注意力機制的YOLOv7_Attention網絡模型,以加強YOLOv7的特征提取能力,提升火焰目標檢測算法的目標檢測效果。
1.1?YOLOv7網絡模型
YOLOv7是基于YOLOv4和YOLOv5的一種單階段目標檢測算法,能較好地均衡算法的速度和精度,為實現復雜環境中的火焰目標檢測奠定了基礎[14]。
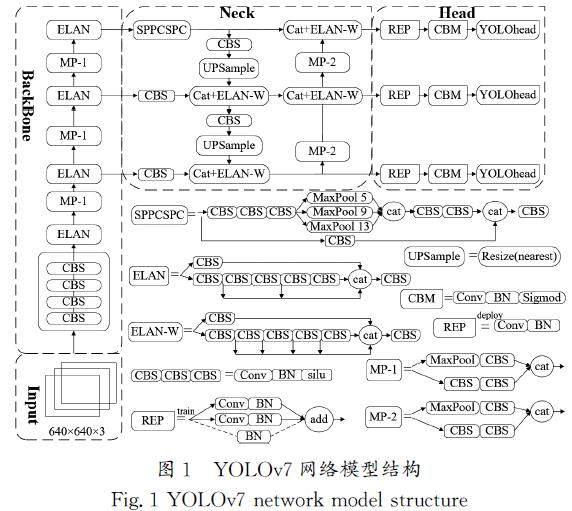
基于YOLOv7網絡模型的目標檢測過程包括4個網絡層次,分別是輸入端、主干網絡、頸部網絡、輸出檢測,YOLOv7網絡模型結構如圖1所示。
圖1中輸入層(Input)負責將輸入的原始三通道圖像尺寸定義成640×640,使用Mosaic數據增強方法,通過隨機縮放、隨機裁剪、隨機排列等操作,將4張圖片拼接在一起,從而增強數據集。主干網絡層(BackBone)主要由擴展高效層聚合網絡(Extended?Efficient?Layer?Aggregation?Network,E\|ELAN)、最大池化(Max?Pooling,MP)模塊構建,通過深度卷積提取不同尺度的特征信息。頸部網絡(Neck)也稱特征融合層,主要由空間金字塔池化(Spatial?Pyramid?Pooling,SPP)和跨階段部分鏈接(Cross?Stage?Partial?Connections,CSPC)結合的模塊SPPCSPC[15]、CBS(Conv\|BN\|Sigmoid)、ELAN的改進版本ELAN\|W、上采樣UPSample等構建,負責深度融合不同尺度的特征圖像信息,形成小、中、大3種不同尺寸的特征。輸出檢測層(Head)對提取的特征進行劃分,將預測出的錨框坐標、類別及置信度進行非極大值抑制后輸出。
1.2?SENet網絡
SENet網絡(Squeeze\|and\|Excitation?Networks,SE)是一種基于注意力機制的深度學習方法[16]。在通道維度上引入注意力機制,通過壓縮操作順著空間維度進行特征壓縮,獲得通道上的全局分布,通過激勵操作構建通道間的自相關性,從而增強有用信息所述特征通道的輸出能力、抑制或弱化非顯著特征,然后對各通道產生的特征圖加權以提升特征提取能力[17]。SE網絡結構如圖2所示。
SE模塊以極小的額外計算成本為現有的深度神經網絡帶來顯著的性能提升,同時由于其簡單的原理與模塊化設計,使得其可以添加在任意一個網絡結構中。
1.3?遷移學習
遷移學習是一種將已有的標注數據作為源域,將需要檢測的數據作為目標域,將源域數據中的已有知識和模型應用于目標域的學習方法[18]。一般用于解決目標域數據量少、標注困難等問題,以提高目標域任務的性能和泛化能力。
由于公開的火焰數據集有限,為了提高模型的泛化能力,本文使用YOLOv7網絡模型在公開數據集COCO(Common?Objects?in?Context)上訓練得到的預訓練權重遷移至火焰任務中。具體過程如下:首先,在YOLOv7網絡模型中加載預訓練權重;其次,在火焰目標集上進行訓練時,先凍結主干部分的權值,確保特征提取網絡保持穩定;最后在解凍訓練階段允許主干參數在訓練過程中發生微調,從而提高模型在火焰檢測任務上的性能表現。網絡初始學習率為1e-2,最小學習率為初始學習率×0.01。采用余弦退火法降低學習率,采用隨機梯度下降(Stochastic?Gradient?Descent,SGD)優化算法。
卷積神經網絡中添加注意力模塊的位置點不同,對神經網絡提取特征的影響也不同。YOLOv7網絡模型主要包括4個部分:輸入網絡、主干網絡、頸部網絡和頭部網絡,輸入網絡用于接收圖像,主干網絡用于提取特征,頸部網路用于融合特征,頭部網路用于預測目標。因此,為了探究注意力機制插入點對YOLOv7網絡模型精度的影響,對YOLOv7網絡模型中的主干網絡和頸部網絡進行單一插入和組合插入。
2.1?單一位置插入注意力機制
單一插入點是指只在網絡中的單個位置一次性插入SE模塊。根據網絡結構確定研究的單一插入點分別為圖3中標注的①②③位置點。
2.2?YOLOv7_Attention網絡模型
在卷積神經網絡中,由于淺層網絡離輸入層較近,因此提取的特征包含更多的細粒度像素點信息,如棱角、顏色、紋理、邊緣等。深層網絡離輸入層較遠,提取的特征包含更抽象的粗粒度信息,如語義信息、目標整體形狀和物體的空間關系等。因此為了提高YOLOv7網絡模型的特征提取能力,使其在充分加強有效特征的同時抑制背景噪聲,在YOLOv7網絡中插入M2和M3,將注意力機制與YOLOv7網絡模型充分融合,構建融合多點注意力機制的YOLOv7網絡模型,稱之為YOLOv7_Attention(圖5)。
3.1?實驗環境及模型訓練
由于本地計算機環境無法滿足實驗需求,因此租用智星云AI?Galaxy平臺中的GPU云服務器。
硬件環境如下:GeForce?RTX?3080(10?GB顯存)、GPU數量為1個、GPU大小為16?GB、CPU核數為12核、內存為27?GB、系統盤大小為100?GB、數據盤大小為120?GB、鏡像為Win10。軟件環境如下:Tensorflow?2.4、Python?3.8.3、PyCharm。
基于YOLOv7神經網絡構建火焰目標檢測模型并進行模型訓練。批次選取太小會引起訓練震蕩,因此選取批次大小為4。訓練輪數為100輪,前50輪為凍結訓練,后50輪為解凍訓練,訓練100輪左右時,損失值趨于穩定,訓練效果達到最優。
3.2?數據集
采用公開火焰數據集(http:∥www.yongxu.org/databases.html),數據集中共有2?688張圖片,對目標位置的標注格式為TXT文件,實驗過程中將TXT文件轉換成XML文件。輸入圖片大小為640×640。
為了使錨框的大小更符合數據集的目標尺寸,通過K\|means聚類分析法重新尋找合適火焰目標的聚類中心,生成適合本數據集的9個錨框,位置分別為(26,41)、(29,126)、(68,72)、(73,140)、(129,126)、(96,228)、(182,205)、(192,375)、(400,393),錨框的分布如圖6所示,橫、縱坐標為所有圖片的尺寸范圍,圖6中的符號“×”表示目標的聚類錨框中心。錨框尺寸整體符合數據集中火焰目標框的尺寸分布,以提升算法訓練性能。
3.3?評價指標
本實驗采用目標檢測中常用的5個性能評價指標對模型的檢測性能進行驗證,分別為精度(Precision,?P)、召回率(Recall,?R)、F1分數(F1?Score,?F1),平均精度(Average?Precision,?AP)、平均精度均值(mean?Average?Precision,?mAP),其計算公式如下:
P=TPTP+FP[JZ)][JY](1)
R=TPTP+FN[JZ)][JY](2)
F1=2PRP+R[JZ)][JY](3)
AP=∫10PdR[JZ)][JY](4)
mAP=∑Ni=1APiN[JZ)][JY](5)
其中:TP為將正樣本預測為正的個數,FP為將負樣本預測為正的個數,FN為將正樣本預測為負的個數。對所有類別的AP取平均值得到mAP,用于對整個目標檢測網絡模型的檢測性能進行評價;N為類別的個數。由于只有火焰一類目標,因此實驗中采用的評價指標為mAP,該值越高,表示模型檢測性能越好。
3.4?結果對比與分析
在火焰數據集上,構建了3個單一位置插入注意力機制的網絡模型,分別為YOLOv7_M1_Attention、YOLOv7_M2_Attention及YOLOv7_M3_Attention網絡模型。3種模型與YOLOv7網絡模型性能對比如表1所示,單一位置插入注意力機制的網絡模型的性能指標整體優于YOLOv7網絡模型的性能指標,這也證明了SE注意力機制對提高YOLOv7網絡模型的綜合性能是有效的。
從表1中的數據可以看出,①位置點插入的YOLOv7_M1_Attention的mAP比YOLOv7的mAP提高了0.12百分點,②位置點插入的YOLOv7_M2_Attention的mAP比YOLOv7的mAP提高了1.25百分點,③位置點插入的YOLOv7_M3_Attention的mAP比YOLOv7的mAP提高了1.35百分點。分析該結果可能是因為M1位置位于網絡的淺層部分,卷積深度不高,網絡提取的目標特征較少,使得注意力機制并未能充分發揮其加強有效特征、抑制無關噪聲的作用。在M2和M3位置上,隨著網絡層數不斷加深,網絡提取的目標越多,對提升網絡模型檢測性能的作用越大。
在相同的實驗環境中,對比引入注意力機制融合的YOLOv7_Attention和YOLOv7,性能對比結果如表2所示,改進后的方法相比于原方法,mAP提升了1.64百分點,并且均優于表1中單一位置點插入的網絡模型。結果表明,基于融合多點注意力機制的網絡模型對火焰特征提取充分,證明了本算法的有效性。
為進一步驗證本文研究的改進算法的有效性,從訓練輪數與mAP和損失函數的變化情況進行評價。圖7為YOLOv7和YOLOv7_Attention在訓練過程中的mAP曲線對比圖,實驗結果表明,隨著訓練輪數的不斷增加,兩種網絡模型的mAP曲線整體呈上升趨勢,最終在100輪左右趨于穩定。YOLOv7的mAP為81.39%,YOLOv7_Attention的mAP達到83.03%,整體提升了1.64百分點。
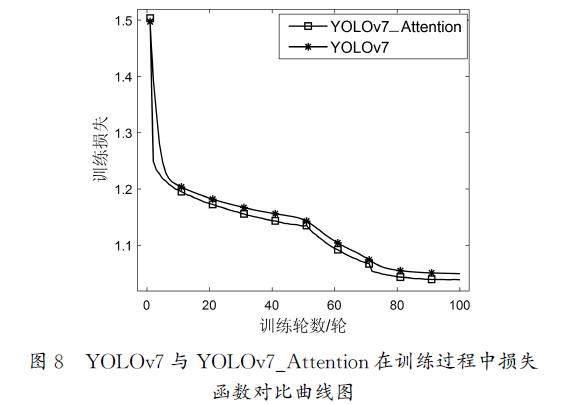
圖8為YOLOv7與YOLOv7_Attention在訓練過程中損失函數對比曲線圖。經對比發現,改進前、后的算法的損失曲線整體都呈現下降趨勢。隨著訓練輪數的不斷增加,YOLOv7的損失值穩定在1.049左右,YOLOv7_Attention的損失值穩定在1.038左右。相比于原方法,經改進的算法的損失值的下降趨勢更早地趨于穩定。
為對比算法改進前、后的檢測效果,將其應用于部分火焰圖片中進行測試。圖9中左邊一列圖片為YOLOv7的檢測結果,右邊一列圖片為YOLOv7_Attention的檢測結果。圖9(a)為森林火災圖片,特點是小火焰目標多、邊緣模糊,右邊的圖片檢測出更多目標。圖9(b)為室內火災圖片,由于室內墻壁反光,使左、右兩邊的圖片檢測均受到影響,但右邊圖片相比于左邊圖片,檢測結果更準確。圖9(c)為城市火災圖片,特點是火焰覆蓋面大,右邊圖片中的檢測范圍相比于左邊圖片精準度更高。實驗結果表明,融合注意力機制后,網絡模型能提取到更深層、更有效的特征,對原算法漏檢的邊緣模糊的小火焰目標達到了較好的檢測效果。
4?結論(Conclusion)
本研究選取SE注意力機制,研究其不同插入點對YOLOv7網絡結構的影響,提出一種融合多點注意力機制的YOLOv7_Attention的火焰檢測算法。在公開的火焰數據集上進行相關實驗的結果表明,注意力模塊插入點所在網絡深度越深,提取的火焰網絡特征就越充分。融合不同位置的注意力機制的YOLOv7_Attention方法相比于YOLOv7算法,mAP提高了1.64百分點,檢測效果顯著提升。
后續,將研究多層注意力機制對網絡模型的影響。此外,目前使用的公開火焰數據集不夠充分,下一步將進一步擴充有效的火焰數據集。
參考文獻(References)
[1]?ZHAO?Y?J,ZHANG?H?B,ZHANG?X?L,et?al.?Fire?smoke?detection?based?on?target\|awareness?and?depthwise?convolutions[J].?Multimedia?tools?and?applications,2021,80(18):27407\|27421.
[2]?JIN?Z?Y,ZAI?W?J,HUANG?J?Y,et?al.?Monitoring?of?smoking?behavior?in?construction?sites?of?the?power?system[C]∥IEEE.?Proceedings?of?the?IEEE:2023?Panda?Forum?on?Power?and?Energy.?Piscataway:IEEE,2023:1471\|1475.
[3]?GIRSHICK?R,DONAHUE?J,DARRELL?T,et?al.?Rich?feature?hierarchies?for?accurate?object?detection?and?semantic?segmentation[C]∥ACM.?Proceedings?of?the?2014?IEEE?Conference?on?Computer?Vision?and?Pattern?Recognition.?New?York:ACM,2014:580\|587.
[4]?LIU?W,ANGUELOV?D,ERHAN?D,et?al.?SSD:single?shot?multiBox?detector[C]∥Springer:European?Conference?on?Computer?Vision.?Cham:Springer,2016:21\|37.
[5]?REDMON?J,DIVVALA?S,GIRSHICK?R,et?al.?You?only?look?once:unified,real\|time?object?detection[C]∥IEEE.?Proceedings?of?the?IEEE:2016?IEEE?Conference?on?Computer?Vision?and?Pattern?Recognition.?Piscataway:IEEE,2016:779\|788.
[6]?REDMON?J,FARHADI?A.?YOLO9000:better,faster,stronger[C]∥IEEE.?Proceedings?of?the?IEEE:2017?IEEE?Conference?on?Computer?Vision?and?Pattern?Recognition.?Piscataway:IEEE,2017:6517\|6525.
[7]?張富凱,楊峰,李策.?基于改進YOLOv3的快速車輛檢測方法[J].?計算機工程與應用,2019,55(2):12\|20.
[8]?嚴云洋,朱曉妤,劉以安,等.?基于Faster?R\|CNN模型的火焰檢測[J].?南京師大學報(自然科學版),2018,41(3):1\|5.
[9]?HAN?L?S,RONG?L?L,LI?Y?Q,et?al.?CA\|SSD\|based?real\|time?smoking?target?detection?algorithm[C]∥ACM.?Proceedings?of?the?2021?5th?International?Conference?on?Digital?Signal?Processing.?New?York:ACM,2021:283\|288.
[10]?楊天宇,王海瑞.?基于改進YOLOv3融合特征的火焰目標檢測方法[J].?農業裝備與車輛工程,2022,60(11):68\|72.
[11]?徐巖,李永泉,郭曉燕,等.?基于YOLOv3\|tiny的火焰目標檢測算法[J].?山東科技大學學報(自然科學版),2022,41(6):95\|103.
[12]?XU?R?J,LIN?H?F,LU?K?J,et?al.?A?forest?fire?detection?system?based?on?ensemble?learning[J].?Forests,2021,12(2):217.
[13]?WANG?C?Y,BOCHKOVSKIY?A,LIAO?H?Y?M.?YOLOv7:trainable?bag\|of\|freebies?sets?new?state\|of\|the\|art?for?real\|time?object?detectors[C]∥IEEE.?Proceedings?of?the?IEEE:2023?IEEE/CVF?Conference?on?Computer?Vision?and?Pattern?Recognition.?Piscataway:IEEE,2023:7464\|7475.
[14]?祝志慧,何昱廷,李沃霖,等.?基于改進YOLOv7模型的復雜環境下鴨蛋識別定位[J].?農業工程學報,2023,39(11):274\|285.
[15]?趙偉,沈樂,徐凱宏.?改進YOLOv7算法在火災現場行人檢測中的應用[J].?傳感器與微系統,2023,42(7):165\|168.
[16]?HU?J,SHEN?L,SUN?G.?Squeeze\|and\|excitation?networks[C]∥IEEE.?Proceedings?of?the?IEEE:2018?IEEE/CVF?Conference?on?Computer?Vision?and?Pattern?Recognition.?Piscataway:IEEE,2018:7132\|7141.
[17]?肖鵬程,徐文廣,張妍,等.?基于SE注意力機制的廢鋼分類評級方法[J].?工程科學學報,2023,45(8):1342\|1352.
[18]?IMAN?M,ARABNIA?H?R,RASHEED?K.?A?review?of?deep?transfer?learning?and?recent?advancements[J].?Technologies,2023,11(2):40.
作者簡介:
張冬梅(1995\|),女,碩士,助教。研究領域:計算機視覺。
宋子濤(1994\|),男,碩士,助教。研究領域:機器學習。
范皓鑫(2003\|),男,本科生。研究領域:計算機視覺。
