基于絲綢行業電商評論的屬性級情感分析
2024-06-17 16:56:20尤良輝張華熊
軟件工程 2024年6期
關鍵詞:深度學習
尤良輝 張華熊
摘?要:
隨著移動互聯網時代的快速發展,電商平臺迅速崛起成為推動網絡消費增長的一股新興且強大的力量。為了有效利用海量的商品評論數據,文章基于京東商城絲綢商品的評論數據,使用詞頻統計對評論數據進行分析處理,構建屬性\|情感詞詞典,填充了評論中的隱性屬性。利用Label?Studio數據標注平臺對評論數據進行屬性\|觀點\|情感的三元標注,經過標注后的數據集被應用于UIE(Unified?Structure?Generation?for?Universal?Information?Extraction)模型進行屬性級情感抽取,并基于抽取的數據集對ERNIE(Enhanced?Language?Representation?with?Informative?Entities)模型進行微調訓練。實驗結果表明,該方法在屬性級情感分析中的準確率高達90%,填充隱性屬性后,準確率提升至94%,表明該方法所得模型在屬性級情感分析中有著不錯的效果。
關鍵詞:電商評論;深度學習;UIE;屬性級情感分析
中圖分類號:TP391.9??文獻標志碼:A
0?引言(Introduction)
隨著互聯網的快速發展,電子商務已經迅速成為人們進行購物和交易的主導方式。截至2023年6月,我國擁有約10.79億網民,互聯網普及率達到76.4%[1]。這一迅猛發展不僅催生了電子商務的繁榮,還帶來了海量的電子商務數據,其中商品的用戶評論數據相對容易獲取且不涉及敏感信息,因此對這些海量的商品評論數據進行深入分析和挖掘,以提取有價值的消費者見解和市場趨勢,成為當前自然語言處理研究領域的熱點之一[2]。同時,我國紡織服裝企業的生產模式普遍仍以傳統的加工制造為主,智能化、協同化、信息化制造能力不強。隨著近年來信息技術的快速發展,紡織服裝行業也有借助現代信息技術轉變模式、提升競爭力的愿望。
基于以上背景,本文旨在運用深度學習技術對紡織服裝行業的電商評論數據進行屬性級情感分析,希望能夠揭示絲綢紡織行業中消費者的情感、觀點和動態興趣等行為要素,為商家提供決策和管理方面的指導和建議。
屬性級情感分析[3]是一種文本分析技術,旨在從文本中提取出與特定屬性相關的情感信息。相比于傳統的整體情感分析,屬性級情感分析的細粒度更細,可以幫助分析人員更準確地了解消費者對不同屬性的情感傾向。
在絲綢紡織行業中,電商評論常常出現面料、顏色、價格等多個維度的評論,并且每個維度都有對應的情感。例如,“絲巾還是很漂亮的,面料也很舒服,就是價格太貴了”評論中的“面料”維度對應的觀點詞是“舒服”,情感傾向為正向,而“價格”維度對應的觀點詞是“貴”,情感傾向為負向。因此,對于類似的評論,分析人員不能簡單地對整個句子進行情感分析,而是需要找到一種方法更加深入地挖掘信息,這種方法便是屬性級情感分析。
在屬性級情感分析中,需要識別出評論中涉及的不同維度,針對每個維度找到與之相關的觀點詞和情感傾向,通過屬性級情感的提取,分析人員可以了解每個維度上的用戶觀點和情感傾向,從而獲得更豐富的情感分析結果。
2?[JP5]相關深度學習模型(Relevant?deep?learning?models)
2.1?UIE模型
UIE(Unified?Structure?Generation?for?Universal?Information?Extraction)[4]模型是一個面向信息抽取的統一文本到結構生成框架,它可以統一建模不同的信息抽取任務,如實體、關系、事件和情感等,并自適應地生成目標結構。該模型設計了一種結構提取語言(Structure?Extraction?Language,SEL),該語言可以有效地將不同的信息抽取(Information?Extraction,IE)結構編碼為統一的表示,從而可以在相同的文本到結構生成框架中對各種IE任務進行通用建模。為了自適應地為不同的IE任務生成目標結構,百度在線網絡技術(北京)有限公司提出了結構模式指導器(Structural?Schema?Instructor,SSI),這是一種基于模式的提示機制,用于控制UIE中要發現的內容、要關聯的內容及要生成的內容。
2.2?ERNIE模型
ERNIE[5](Enhanced?Language?Representation?with?Informative?Entities)模型采用Transformer?Encoder的方式作為基本的編碼器,模型大小是12?encoder?layer、178?hidden?units、12?attention?heads。ERNIE模型與BERT[6](Bidirectional?Encoder?Representations?from?Transformers)模型十分相似,但ERNIE改進了兩種masking策略,一種是基于短語的masking策略,另一種是基于名詞(如人名、位置、組織、產品)的masking策略。在ERNIE中,將由多個字組成的短語或者名詞當成一個統一單元,相比于BERT基于字的mask,這個單元當中的所有字在訓練的時候,統一被mask。對比直接將知識類的query映射成向量后直接相加,ERNIE通過統一mask的方式,可以潛在地學習到知識的依賴及更長的語義依賴,進而讓模型更具泛化性。
3.1?在線評論數據采集
(1)采集來源
網絡化時代的到來產生了大量的消費者生成內容,消費者不僅可以在消費前在互聯網中獲得產品的基本信息,也可以獲知其他已購買該產品的消費者對產品的使用體驗。這些信息在互聯網不同的平臺上不停地更新,例如京東、淘寶等第三方購物平臺,以及官方的論壇、社區、社交平臺賬號等。由于絲綢紡織行業的用戶評論內容豐富,用戶的需求多樣,這就要求采集的用戶評論數量足夠多、內容真實且篇幅不能過短。官方的論壇、社區、社交平臺賬號的評論數量較少,不滿足采集需求,并且有可能是商家花錢買推廣的評論。相比于官方的論壇、社區、社交平臺賬號,第三方在線平臺具有評論真實、屬性全面、質量更高的優勢。首先,隨著互聯網購物方式的普及和物流行業的快速發展,越來越多的消費者選擇線上購買產品,因此第三方購物網站的每款熱銷絲綢商品的評論都達到數萬條,這些評論可以真實地反映大多數消費者的心聲。其次,用戶在評論商品時,可以選擇不同的屬性標簽,這為細粒度的需求分析提供了相對完善的評論信息。最后,得益于平臺的評論監測過濾機制,大大減少了其中摻雜的垃圾評論,提高了評論的質量。因此,本文選擇各個電商平臺的評論作為在線評論數據來源。
(2)采集過程
基于用戶評價的數據挖掘需要大量的用戶評論語料,顯然依靠人力收集在線用戶評論的工作量相當大,因此必須借助現有的爬蟲技術從電商平臺快速獲取用戶評論。網絡爬蟲[7]其實就是一個程序或者腳本,它向目標鏈接發起Http請求并按照開發者設定的規則對返回數據進行過濾解析,實現自動從互聯網上抓取所需的信息。為我們熟知的搜索引擎如谷歌和百度都是大型的爬蟲系統,基于用戶輸入的關鍵字在全網進行爬蟲搜索,并將相關的網頁呈現給用戶。
現有的網絡爬蟲工具有“八爪魚”、HTTrack、Scraper、OutWit?Hub等。“八爪魚”是一款免費且功能強大的網站爬蟲,用于從網站上幫助使用者提取需要的幾乎所有類型的數據。用戶可以使用其內置的正則表達式工具從復雜的網站布局中提取許多棘手網站的數據,并使用XPath配置工具精確定位Web元素。
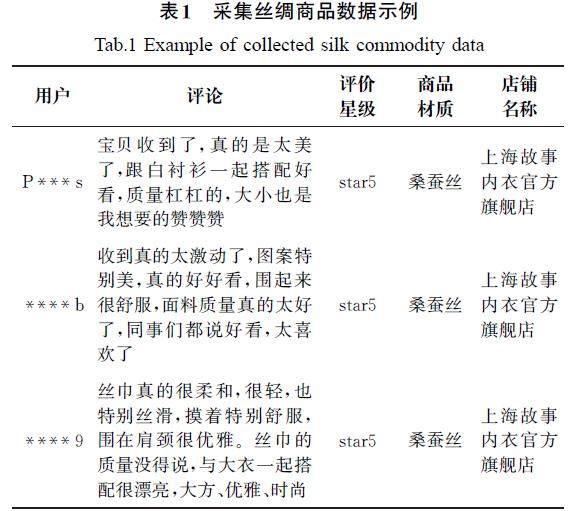
利用網絡爬蟲工具“八爪魚”對京東商城的絲綢類商品評論進行爬取,主要爬取評論、用戶名、評價星級、店鋪名稱、貨號、商品材質等內容(表1)。
3.2?數據預處理
雖然在線商城的用戶評論數量龐大,但是由于用戶表達隨意,其中摻雜了許多無效評論,若在后續分析階段不對其進行處理,則這些無效評論將帶來較大的干擾。因此,需要對評論進行預處理,去除無效評論。需要刪除的評論可分為3種情況。
一是重復的評論。爬取的評論難免會出現重復內容,原因可能是用戶進行了復制粘貼,或是在分批爬取時,網頁更新了評論動態等。為此,需要刪除重復的評論。
二是過短的評論。一些評論可能只包含一兩個字,這類過短的評論所包含的信息非常有限,因此真正有效的評論至少需要包含3個字以上,例如“速度快”,因此需要刪除少于3個字的評論。
三是無意義的評論。某些消費者為了積分而隨意評論,他們會隨意打字湊字數,這種評論毫無挖掘價值,同樣需要刪除。
經過上述篩選步驟,共得到了16?900條有效的評論數據。
[BT5+*5]3.3?詞頻統計與分析
詞頻統計分析是文本分析中一種重要的方法。它通過計算詞語在文本中的頻率揭示文本的特征和模式。詞頻統計可用于識別文本的主題和關鍵詞,把握評論中的核心內容和重點詞匯,同時它能揭示詞語之間的關聯關系,幫助分析人員理解文本的內在結構和語義信息。此外,詞頻統計可用于情感分析,評估文本的情感傾向。在特定領域的文本分析中,詞頻統計也具有重要作用,它能幫助分析人員理解和解釋領域內的文本內容。
3.3.1?Jieba分詞
Jieba分詞[8]是一種基于Python語言的中文分詞工具,它采用了基于前綴詞典實現的分詞算法,能夠將一段中文文本切割成一個一個的詞語,并對每個詞語進行詞性標注。停用詞是指在文本分析過程中需要過濾掉的一些常見詞語,這些詞語通常是出現頻率較高,但對文本分析任務并沒有實質性貢獻的詞語,比如“的”“是”“在”等。本文在使用Jieba分詞工具對數據進行分詞處理時,使用了公開的中文常用停用詞表——哈工大的中文停用詞表(哈爾濱工業大學自然語言處理實驗室發布的一個停用詞表)過濾掉停用詞。
3.3.2?統計詞頻與分析詞性
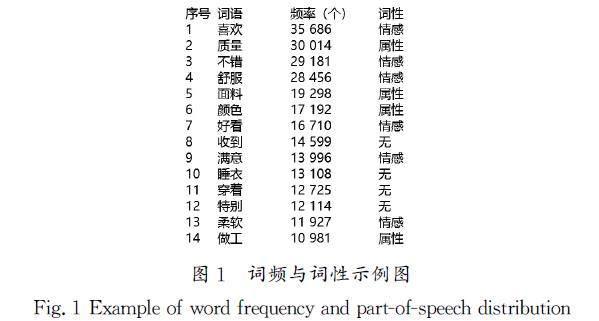
對每條評論的詞語進行頻率統計,提取所有出現頻率超過1%的詞語共104個,并對它們進行詞性分析,詞頻與詞性示例圖如圖1所示。
3.3.3?構建屬性聚類表和屬性\|情感詞詞典
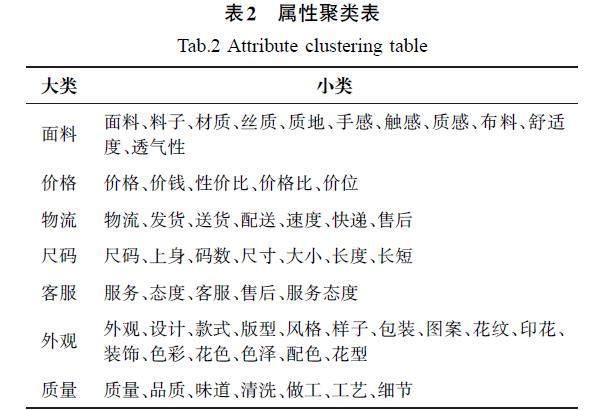
統計得出與絲綢有關的屬性,并根據相似性將其分為7個大類,創建屬性聚類表(表2)。
3.4?屬性級情感數據標注
數據標注平臺:Label?Studio是一個開源的數據標注平臺,支持各種類型的數據標注任務,包括文本、圖像、音頻、視頻等。它可以幫助數據科學家和研究人員快速地創建高質量的標注數據集,將其用于機器學習、深度學習等任務中。
根據屬性聚類表(表2)和屬性\|情感詞詞典(表3)進行標注,具體標注規則如下:將屬性標注為評價維度(正向或負向),將其對應的情感詞標注為觀點詞,二者之間以“觀點詞”相關聯,屬性級情感數據標注示例圖如圖2所示。
3.5?屬性級情感數據提取
3.5.1?設計結構提取語言
根據屬性級情感數據標注構建結構模式指導器(SSL),用于控制UIE中要發現的內容、要關聯的內容及要生成的內容。在本研究中需要構建的結構模式指導器有4個,分別是“屬性”“屬性對應的觀點詞”“觀點詞”“情感傾向”。
通過UIE模型設計結果提取語言(SEL),完成屬性級情感的信息抽取任務。在形式上,UIE將給定的結構模式指導器(S)和文本序列(X)作為輸入,并生成線性化SEL(Y),其中包含基于模式S從X中提取的信息:
3.5.2?隱性屬性提取
在中文語境中,常常會出現省略的情況,因此為了增加句子的表達能力和描述能力,本文采用屬性\|情感詞詞典補全省略的屬性。使用UIE模型構建結構提取語言(SEL)時,當句子中存在某個觀點詞沒有相互對應的屬性詞時,會在屬性\|情感詞詞典中進行檢索,查看是否將屬性詞省略,若存在省略情況,則將省略的屬性詞添加到SEL中,實現隱性屬性的提取。以評論“太貴了”為例,該句子中明顯省略的屬性詞為“價格”。隱性屬性SEL構建表如表5所示。
3.5.3?UIE模型提取結果
屬性級標注數據共1?000余條,經過UIE模型構建后,可得到訓練集13?000余條,驗證集1?600余條,測試集1?600余條。
3.6?ERNIE模型訓練
3.6.1?實驗環境配置
本文模型基于Paddlepaddle框架,使用GPU進行訓練,實驗使用的GPU為NVIDIA?GTX3060,Paddlepaddle\|gpu版本2.4.2,Paddlenlp版本2.5.2,Python版本3.9,CPU為R9\|6900HX,操作系統為Windows10家庭中文版。模型支持處理的最大序列長度為256,訓練批次為8次,訓練最大學習率設置為0.000?01。
3.6.2?評價指標
評價模型的指標[9]主要有精確率(Precision),召回率(Recall)和F1值,計算方法如公式(2)至公式(4)所示:
其中:TP為預測正確的正樣本數量,FP為預測錯誤的正樣本數量,FN為預測錯誤的負樣本數量。
3.6.3?實驗結果與分析
第一組實驗是直接將ERNIE預訓練模型對測試集進行多次驗證后的平均評價指標;第二組實驗是通過UIE屬性提取后,對ERNIE模型進行小樣本訓練后的平均評價指標;第三組實驗是采用隱性屬性提取后,對ERNIE模型進行小樣本訓練后的平均評價指標。實驗結果如表6所示。
從表6中的數據可以看出,通過屬性聚類表和屬性\|情感詞詞典設計的UIE提取規則對于預訓練模型效果提升十分有效,特別是召回率有了大幅的提升,這是模型能夠學習到更多絲綢紡織行業屬性的表現;而隱性屬性提取的方法使模型能夠注意到評論中隱含的屬性,使模型的評價指標F1值相較于未經過隱性屬性提取的方法的相應指標值提升了4百分點。
4?結論(Conclusion)
在如何有效利用商品評論數據的問題上,本文針對絲綢紡織行業的商品評論數據,通過詞頻統計分析構建了屬性聚類表和屬性\|情感詞詞典,同時基于評論中隱性屬性的提取并結合UIE模型和ERNIE模型,實現了對絲綢紡織行業電商評論的屬性級情感提取。實驗結果證明了本文所提方法的有效性,該方法能夠幫助商家有效了解消費者的需求和市場發展趨勢,從而有針對性地對產品進行改進。此外,該方法對于其他行業的評論數據挖掘也具有一定的參考價值。
參考文獻(References)
[1]?CNNIC.?第52次中國互聯網絡發展狀況統計報告[EB/OL].?(2023\|08\|28)[2024\|02\|01].?https:∥www.cnnic.net.cn/n4/2023/0828/c88\|10829.html.
[2]?李鐵.?面向大規模電商評論的情感分析與興趣挖掘研究[D].?成都:電子科技大學,2018.
[3]?ZHANG?L,WANG?S,LIU?B.?Deep?learning?for?sentiment?analysis:a?survey[J].?WIREs?data?mining?and?knowledge?discovery,2018,8(4):e1253.
[4]?LU?Y?J,LIU?Q,DAI?D,et?al.?Unified?structure?generation?for?universal?information?extraction[C]∥Proceedings?of?the?60th?Annual?Meeting?of?the?Association?for?Computational?Linguistics?(Volume?1:Long?Papers).?Stroudsburg,PA,USA:Association?for?Computational?Linguistics,2022:5755\|5772.?[HJ2.5mm]
[5]?ZHANG?Z?Y,HAN?X,LIU?Z?Y,et?al.?ERNIE:enhanced?language?representation?with?informative?entities[C]∥Proceedings?of?the?57th?Annual?Meeting?of?the?Association?for?Computational?Linguistics.?Stroudsburg,PA,USA:Association?for?Computational?Linguistics,2019:1441\|1451.
[6]?李可悅,陳軼,牛少彰.?基于BERT的社交電商文本分類算法[J].?計算機科學,2021,48(2):87\|92.
[7]?陳國良,郭修豪.?基于商品評論信息的特征挖掘[J].?福建電腦,2015,31(5):106\|107.
[8]?韋人予.?中文分詞技術研究[J].?信息與電腦(理論版),2020,32(10):26\|29.
[9]?POWERS?D?M?W.?Evaluation:from?precision,recall?and?F\|measure?to?ROC,informedness,markedness?and?correlation[DB/OL].?(2020\|10\|11)[2024\|02\|01].?https:∥arxiv.org/abs/2010.16061.
作者簡介:
尤良輝(2000\|),男,碩士生。研究領域:深度學習。
張華熊(1971\|),男,博士,教授。研究領域:智能信息處理。本文通信作者。
猜你喜歡
中國教育技術裝備(2016年19期)2016-12-27 19:23:52
中國遠程教育(2016年11期)2016-12-27 18:07:31
現代商貿工業(2016年25期)2016-12-26 09:58:02
江蘇教育·中學教學版(2016年11期)2016-12-21 11:45:08
江蘇教育·中學教學版(2016年11期)2016-12-21 11:36:29
現代情報(2016年10期)2016-12-15 11:50:53
考試周刊(2016年94期)2016-12-12 12:15:04
新教育時代·教師版(2016年23期)2016-12-06 06:02:38
法制與社會(2016年32期)2016-12-01 15:25:53
軟件導刊(2016年9期)2016-11-07 22:20:49
