基于MobileNet的輕量化密集行人檢測算法
2024-06-17 14:28:06魏志劉罡張旭
軟件工程 2024年6期
魏志 劉罡 張旭
摘?要:
針對現(xiàn)有的行人檢測算法在復雜場景下檢測速度慢、檢測精度不高的問題,提出一種輕量化密集行人檢測算法MER\|YOLO(Miniature?Enhanced?Recognition\|You?Only?Look?Once)。首先,MER\|YOLO以MobileNetV3(輕量化網(wǎng)絡模型)作為特征提取主干網(wǎng)絡,提升模型對于小目標及模糊圖像的學習能力;其次,通過融合深度可分離卷積和ECA(Efficient?Channel?Attention)注意力機制構建DPE\|C3模塊,解決密集行人檢測過程中的遮擋丟失漏檢的問題;最后,MER\|YOLO使用空間和通道重建卷積處理標準卷積中固有的空間和信道冗余,減少模型計算需求。該算法應用于WiderPerson(混合行人數(shù)據(jù)集)上的檢測精度達到了78.9%,相較于YOLOv5s算法提升了3.0百分點,同時模型計算量比YOLOv5s降低了13.3百分點。因此,MER\|YOLO算法兼顧了檢測準確度和檢測速度的要求。
關鍵詞:行人檢測;輕量化網(wǎng)絡;注意力機制;空間重建卷積
中圖分類號:TP391.4??文獻標志碼:A
0?引言(Introduction)
隨著城市交通建設速度的加快,城市空間布局不斷變化,越加復雜的道路交通環(huán)境造成交通安全事故頻發(fā),行人檢測成為計算機視覺領域重要的研究方向之一,基于深度學習的目標檢測算法發(fā)展迅速,在復雜場景下的目標檢測中具有較高的靈活性。
為了提升行人識別技術的準確性,最大限度地減少漏檢情況,研究人員開展了眾多研究。單志勇等[1]基于Faster?R\|CNN(Faster?Region\|based?Convolutional?Neural?Network)進行了優(yōu)化,在一定程度上減少了重疊區(qū)域的漏檢和誤檢問題。趙九霄等[2]對SSD(Single?Shot?MultiBox?Detector)網(wǎng)絡模型進行了創(chuàng)新,結合聚類算法選取檢測框,提高了算法的學習效率。馮宇平等[3]對目標檢測算法YOLOv3\|Tiny進行了優(yōu)化,降低了復雜背景對檢測精度的影響。石欣等[4]引入了淺層特征金字塔網(wǎng)絡,雖然提升了模型的小目標特征提取能力,但是提升了模型的復雜度。上述算法難以實現(xiàn)檢測精度和模型復雜度的平衡。
基于此,本文將YOLOv5s[5]作為基礎網(wǎng)絡進行改進,使用MobileNetV3、深度可分離卷積、ECA注意力機制、空間和通道重建卷積構建一種輕量化的可面向復雜檢測場景的行人檢測算法模型MER\|YOLO。在降低模型復雜度的同時,提高了其在密集人群場景下對受遮擋行人的檢測能力。
1?算法改進(Algorithm?improvement)
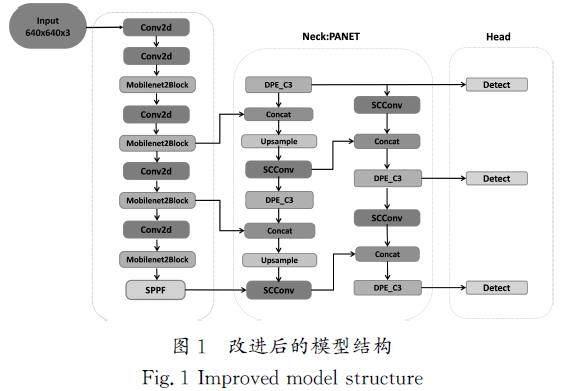
為了能夠快速準確地檢測出行人,本文以?YOLOv5s(You?Only?Look?Once?version?5?small)為基礎模型進行行人檢測算法的改進和驗證,改進后的模型結構如圖1所示。
1.1?輕量化網(wǎng)絡模塊
本研究的核心目標是設計一種新的特征提取網(wǎng)絡架構,減少信息融合過程中的梯度冗余,增強網(wǎng)絡的學習效率并加速訓練過程。為此,本研究選擇使用MobileNet網(wǎng)絡,這是一種輕量級的特征提取模塊,用以替代YOLOv5網(wǎng)絡中的特征提取模塊,減少模型的體積和參數(shù)量。
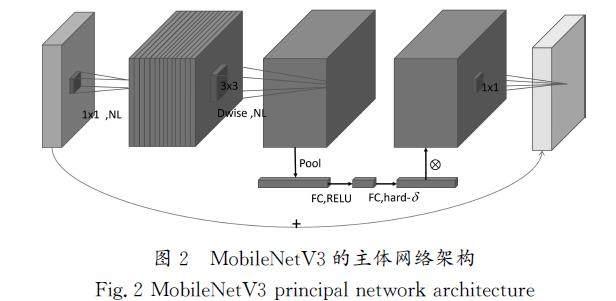
MobileNetV3[6]是通過網(wǎng)絡架構檢索(Network?Architecture?Search,?NAS)構建的深度神經(jīng)網(wǎng)絡架構,它繼承了MobileNetV1的深度可分離卷積和MobileNetV2的線性殘差結構。MobileNetV3的最大改進是在瓶頸結構上增加了壓縮和激勵(SE)[7]結構,以及用h\|swish函數(shù)代替swish函數(shù),由于“s”形曲線的計算時間較長,特別是在移動設備上,因此采用h\|swish近似“s”形曲線,消除量化過程中潛在的精度損失,swish和h\|swish的公式分別如下:
swishx=x·δ(x)[JZ)][JY](1)
h\|swish=x·[ReLU6(x+3)/6][JZ)][JY](2)
公式(1)表示swish激活函數(shù),該函數(shù)將輸入x與δ(x)進行逐元素乘法運算,在計算中引入非線性量。公式(2)表示h\|swish激活函數(shù),這是一種計算效率更高的swish版本,它將輸入x與ReLU6[8]函數(shù)進行逐元素乘法運算,使其能有效地提取重要特征。利用MobileNetV3的特征提取層,可以有效地從輸入數(shù)據(jù)中捕獲相關特征和判別特征,MobileNetV3的主體網(wǎng)絡架構如圖2所示。
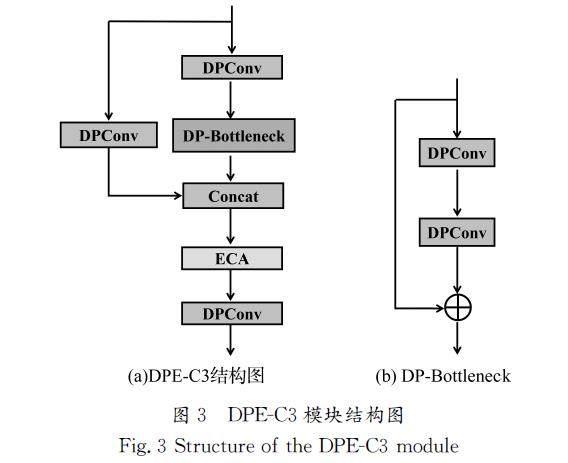
1.2?DPE\|C3模塊
在目前的道路行人檢測中,檢測目標往往很小,增大了檢測網(wǎng)絡的識別難度,為了充分提取輸入特征的上下文信息,增強對行人小目標、圖像模糊情形下的檢測能力,對原有的YOLOv5算法的C3模塊進行改進,通過融合深度可分離卷積和ECA注意力機制構建DPE\|C3模塊(圖3)。在增強模型檢測能力的同時,使得整體模塊更加輕量化,也可以更好地解決梯度消失等導致模型不穩(wěn)定的問題。本文使用深度可分離卷積DPConv替換原C3模塊中的普通卷積,在C3模塊的Concat操作之后加入ECA注意力機制,增強了模型對上下文特征信息的提取能力,進一步提升了模型對小目標行人的檢測能力。
高效通道注意力機制ECA[9](Efficient?Channel?Attention)的結構如圖4所示,它的主要作用是突出特征圖中有效信息的特征通道,ECA模塊考慮到了跨通道的交互問題,能更好地捕捉通道間的聯(lián)系,獲得較高的性能增益。
注意力通道權值表達式如下:
w=σ([WTHX]W[WTBX]y)[JZ)][JY](3)
其中:σ代表ReLU6激活函數(shù),[WTHX]W[WTBX]代表一個c×c的參數(shù)矩陣,w表示通道的權值。
1.3?SCConv卷積模塊
SCConv[10]卷積模塊(圖5)代表空間和信道重構卷積,設計了一種新的CNN(Convolutional?Neural?Network)壓縮方法,用以減少卷積層中存在的空間和信道冗余,它通過兩個獨特的模塊,即空間重構單元SRU(Selective?Receptive?Unit)和通道重構單元CRU(Channel?Recalibration?Unit),實現(xiàn)了較大的性能提升,同時顯著降低了計算量,這兩個模塊最大限度地減少了特征映射中的冗余。
SRU主要關注特征圖的空間維度,它的目標是減少空間冗余。為了實現(xiàn)這一目標,SRU將輸入特征映射分解為多個空間塊的機制,并對每個空間塊應用不同的卷積核,這種方法不僅可以更精確地捕獲每個空間塊內(nèi)的特征信息,而且可以顯著降低整體空間冗余。
本研究在MER\|YOLO檢測網(wǎng)絡的設計中,采用SCConv替代原始模型Neck中的普通卷積,減少了標準卷積中普遍存在的空間冗余和信道冗余,從而提高了卷積網(wǎng)絡模型的性能,同時減少了計算需求。
2?實驗與分析(Experiment?and?analysis)
2.1?實驗環(huán)境
模型實驗基于Pytorch框架,實驗所使用GPU為GeForce?RTX3060(16.0?GB),CUDA版本12.0,Pytorch版本1.11,Python版本3.9,CPU為i7\|11800H,操作系統(tǒng)為Windows11?64位。
2.2?數(shù)據(jù)集
本實驗使用的WiderPerson數(shù)據(jù)集,是一個多樣化密集行人檢測數(shù)據(jù)集,具有豐富的前景圖像和背景圖像以及行人高度模糊的豐富人群場景。WiderPerson數(shù)據(jù)集中主要涉及的行人有3類,第一類是行人,即完全行人;第二類是騎行者,他們騎電動車或自行車;第三類是部分可見的行人,所有行人都受到不同程度的遮擋。在實驗中對原始數(shù)據(jù)集按照8∶2的比例劃分訓練集和測試集。
2.3?實驗結果與分析
為了有效地評估模型的檢測效果,采用平均精度均值mAP(mean?Average?Precision)衡量模型的性能,用浮點運算次數(shù)FLOPs表示模型的復雜度。
2.3.1?消融實驗
為了評估各改進部分對整體算法性能的優(yōu)化程度,本文設計了消融實驗,實驗結果如表1所示。
從表1中可以看出,改進1實驗引入MobileNetV3模塊后,網(wǎng)絡模型的FLOPs降低了48%,而mAP0.5和mAP0.5:0.95分別降低了1.4百分點和1.6百分點,表明MobileNetV3模塊在犧牲一定精度的情況下成功地降低了算法的復雜度。改進2實驗引入DPE\|C3模塊后,雖然FLOPs增加了35.4%,但是網(wǎng)絡模型的mAP0.5提高了0.7百分點,表明DPE\|C3模塊可以增強網(wǎng)絡提取特征和關注大量語義信息的能力,從而提高針對小目標行人的檢測準確率。改進3實驗引入SCConv模塊后,在不提升網(wǎng)絡復雜度的情況下,將網(wǎng)絡模型的mAP0.5和mAP0.5:0.95均提高了1.7百分點,表明SCConv模塊可以降低卷積網(wǎng)絡的冗余,提高回歸精度,對增強網(wǎng)絡對遮擋行人的識別能力有較大的幫助。
與原始YOLOv5s檢測網(wǎng)絡相比,MER\|YOLO的mAP0.5提高了3.0百分點,mAP0.5:0.95提高了1.2百分點,模型的復雜度降低了13.3%。以上結構說明,同時采用3種改進模塊,在提升了模型平均精度的基礎上,也降低了模型的復雜度,兼顧了模型的檢測精度與計算量。
2.3.2?不同算法的對比實驗
為了進一步驗證本文提出的MER\|YOLO算法的檢測效果,與現(xiàn)有目標檢測算法YOLOv3、YOLOv4和YOLOX\|Tiny在混合行人數(shù)據(jù)集上的應用效果進行對比,得到最符合本文要求的算法模型,MER\|YOLO與現(xiàn)有目標檢測算法的對比結果如表2所示。
YOLOv3使用兩種主要的輕量化策略,去除骨干網(wǎng)絡中的殘差結構,只保留兩個檢測頭,犧牲了一定的檢測精度,YOLOv3網(wǎng)絡的mAP0.5和mAP0.5:0.95分別比MER\|YOLO降低了12.2百分點和10.7百分點,表明MER\|YOLO更好地兼顧了計算量和檢測精度要求,盡可能地保留了原有YOLOv5s的基本架構,將YOLOv5s網(wǎng)絡中的Conv模塊替換為SCConv模塊,最大限度地減少了特征網(wǎng)絡映射中的冗余。此外,MER\|YOLO網(wǎng)絡采用ECA注意力機制,緩解了輕量化帶來的精度下降問題。
YOLOv4通過對原始網(wǎng)絡進行特定優(yōu)化,將骨干網(wǎng)絡激活函數(shù)改為LeakyReLu函數(shù),保留了3個殘差結構及特征融合金字塔,由于網(wǎng)絡使用了同樣的輕量化策略,因此網(wǎng)絡也面臨同樣的精度下降問題。YOLOv4網(wǎng)絡的mAP0.5和mAP0.5:0.95分別比MER\|YOLO網(wǎng)絡降低了12.5百分點和16.8百分點,F(xiàn)LOPs比MER\|YOLO網(wǎng)絡多2.4?GB。由此可見,YOLOv4采用的輕量化策略并不適合行人檢測。
YOLOX\|Tiny中使用的輕量化方案保留了原有的YOLOX的框架結構,減少了網(wǎng)絡中的通道數(shù),使網(wǎng)絡更輕量化。YOLOX\|Tiny的mAP0.5和mAP0.5:0.95分別比MER\|YOLO降低了3.8百分點和4.5百分點,F(xiàn)LOPs比MER\|YOLO網(wǎng)絡多1.4?GB,實驗數(shù)據(jù)表明,MER\|YOLO更適合應用于行人檢測算法。
2.3.3?可視化實驗對比
為了更直觀地體現(xiàn)改進后算法與原有算法的區(qū)別,本研究使用WiderPerson數(shù)據(jù)集對比了MER\|YOLO和YOLOv5s的檢測效果。分別在不同檢測場景下對模型進行檢驗,如圖6所示,對于漏檢目標圖中用箭頭標簽指示出。對比圖6(a)和圖6(b),MER\|YOLO能夠檢測出圖片邊緣部分出現(xiàn)的行人,而原有算法出現(xiàn)了漏檢。在行人互遮擋的檢測中,圖6(c)中原有算法對貼近的兩個行人只給出了一個檢測框,圖6(d)中改進后算法給兩個行人分別分配了檢測框。圖6(e)和圖6(f)為暗光密集行人場景下的檢測效果對比,MER\|YOLO算法具有較好的檢測效果,檢測框也更加貼近被檢測行人。綜合對比各種場景下的檢測效果來看,本文改進算法對于密集行人檢測有更好的檢測效果和魯棒性。
3?結論(Conclusion)
本文提出的MER\|YOLO算法是一種輕量化行人檢測網(wǎng)絡,在MER\|YOLO檢測網(wǎng)絡中,通過MobileNetV3輕量化特征提取主干網(wǎng)絡,降低主干模型復雜度的同時,獲取了更多的行人目標特征,通過融合深度可分離卷積和ECA注意力機制構建DPE\|C3模塊,提升了模型對于小目標及模糊圖像的學習能力。
在WiderPerson數(shù)據(jù)集上的消融實驗表明,與YOLOv5s相比,MER\|YOLO可以提高行人識別精度,同時最小化網(wǎng)絡復雜度。不同算法的對比實驗結果表明,與其他算法相比,MER\|YOLO在準確性和復雜性之間取得了更好的平衡。未來,研究人員將通過優(yōu)化模型去除更多冗余的特征信息,進一步降低網(wǎng)絡的復雜度,確保MER\|YOLO能夠大幅降低對計算能力的需求,并容易部署在算力有限的嵌入式設備上。
參考文獻(References)
[1]?單志勇,張鐘月.?基于改進Faster?R\|CNN算法的行人檢測[J].?現(xiàn)代計算機,2021,27(23):124\|128.
[2]?趙九霄,劉毅,李國燕.?基于改進SSD的視頻行人目標檢測[J].?傳感器與微系統(tǒng),2022,41(1):146\|149,156.
[3]?馮宇平,管玉宇,楊旭睿,等.?融合注意力機制的實時行人檢測算法[J].?電子測量技術,2021,44(17):123\|130.
[4]?石欣,盧灝,秦鵬杰,等.?一種遠距離行人小目標檢測方法[J].?儀器儀表學報,2022,43(5):136\|146.
[5]?陳冬冬,任曉明,李登攀,等.?基于改進的YOLOv5s的雙目視覺車輛檢測與測距方法研究[J].?光電子·激光,2024,35(3):311\|319.
[6]?楊登杰,葉愛芬,袁舸凡,等.?基于MobileNetV3\|YOLOv4超市取貨機器人目標檢測策略優(yōu)化設計[J].?電腦知識與技術,2022,18(30):18\|22.
[7]?賀海玉.?基于多注意力機制的多粒度讀者畫像分析[J].?微型電腦應用,2023,39(12):143\|146.
[8]?張煥,張慶,于紀言.?卷積神經(jīng)網(wǎng)絡中激活函數(shù)的性質(zhì)分析與改進[J].?計算機仿真,2022,39(4):328\|334.
[9]?袁培森,歐陽柳江,翟肇裕,等.?基于MobileNetV3Small\|ECA的水稻病害輕量級識別研究[J].?農(nóng)業(yè)機械學報,2024,55(1):253\|262.
[10]?[ZK(]ZHANG?Z?Y,TAN?L?Y,TIONG?R?L?K.?Ship\|fire?net:an?improved?YOLOv8?algorithm?for?ship?fire?detection[J].?Sensors,2024,24(3):727.
作者簡介:
魏?志(1996\|),男,碩士生。研究領域:計算機視覺,行人檢測。
劉?罡(1981\|),男,碩士,副教授。研究領域:深度學習,計算機視覺。
張?旭(1998\|),男,碩士生。研究領域:機器視覺,人工智能。
