基于SSA-LSTM模型的空氣質量預測研究
2024-06-01 11:14:29曹還君李長云
現代信息科技 2024年4期
曹還君 李長云


收稿日期:2023-11-08
DOI:10.19850/j.cnki.2096-4706.2024.04.030
摘? 要:為提高PM2.5濃度的預測精度,提出了一種結合麻雀搜索算法(SSA)和長短期記憶神經網絡(LSTM)的組合預測模型。以2023年5月至8月期間長沙市PM2.5濃度數據為基礎,構建了SSA-LSTM模型并與其他模型進行了對比實驗。實驗結果顯示,SSA-LSTM模型的預測結果在擬合優度(R2)上相較于單一LSTM、PSO-LSTM和WOA-LSTM模型分別提升了45.93%、31.55%、19.12%,同樣在均方根誤差(RMSE)和平均絕對誤差(MAE)的結果上也表現更優,表明該模型在PM2.5濃度預測方面具有高準確性和有效性,可為制定PM2.5相關預防措施提供一定的參考價值。
關鍵詞:麻雀搜索算法;長短期記憶神經網絡;空氣質量;PM2.5濃度預測
中圖分類號:TP18? ? 文獻標識碼:A? 文章編號:2096-4706(2024)04-0142-06
Research on Air Quality Prediction Based on SSA-LSTM Model
CAO Huanjun, LI Changyun
(College of Computer Science, Hunan University of Technology, Zhuzhou? 412007, China)
Abstract: To improve the accuracy of PM2.5 concentration prediction, a combined prediction model integrating Sparrow Search Algorithm (SSA) and Long Short-Term Memory (LSTM) neural networks is proposed. The SSA-LSTM model is developed based on PM2.5 concentration data from Changsha city, spanning from May to August in 2023, and is compared with other models. The results show that the SSA-LSTM model significantly outperformed the standalone LSTM, PSO-LSTM, and WOA-LSTM models in terms of fit quality (R2), registering improvements of 45.93%, 31.55%, and 19.12%, respectively. Similarly, it also shows superior performance in terms of Root Mean Square Error (RMSE) and Mean Absolute Error (MAE). These findings demonstrate the model has high accuracy and effectiveness in PM2.5 concentration prediction, providing a certain reference value for making the PM2.5-related preventive measures.
Keywords: SSA; LSTM; air quality; PM2.5 concentration prediction
0? 引? 言
進入21世紀以來,隨著人類社會經濟的快速發展,能源消耗量的劇增導致了環境污染問題的加劇,尤其是空氣污染問題變得尤為嚴重。研究顯示,長期暴露于高濃度污染物的環境中,不僅對人類健康構成直接威脅,也會給企業生產帶來直接或間接的影響[1]。空氣污染程度的主要指標是空氣中的污染物濃度,其中PM2.5是影響空氣質量的關鍵指標。由于體積小、重量輕,PM2.5能在空氣中長時間滯留,并在吸入人體后對健康造成嚴重危害[2],因此研究建立一個高效且精確的PM2.5濃度預測模型,有助于人們制定并采取必要的預防措施,具有重要的現實意義。
在PM2.5濃度預測的研究領域,國內外學者們已經探索了多種方法以提升預測的精度和實用性。早期的研究,學者們主要基于傳統的統計學方法建立線性模型對PM2.5濃度進行預測,如多元線性回歸模型(MLP)[3]、差分整合移動平均自回歸模型(ARIMA)[4,5]
等。但由于影響PM2.5濃度的因素過多且相互之間關聯性強,使得PM2.5濃度的變化具有毛刺多、陡升陡降的特點,導致傳統的線性模型在預測這類具有非線性特征的復雜時間序列數據方面,預測誤差較大,存在一定的局限性。近年來,隨著人工智能技術的快速進步,機器學習方法得到了廣泛應用,包括應用在了對PM2.5濃度預測的研究中,有效地克服了傳統統計模型在預測復雜非線性時間序列數據方面的不足,取得了顯著成果。其中隨機森林[6]、支持向量機[7]、神經網絡[8]等機器學習算法能夠捕捉數據中的復雜模式和關系,已被證明在提高預測精度方面具有顯著優勢。特別是,長短期記憶神經網絡[9](Long Short-Term Memory, LSTM)模型作為循環神經網絡(Recurrent Neural Network, RNN)的改進版本,通過其獨特的門控機制解決了長序列數據在訓練過程中的梯度消失和梯度爆炸問題,能夠有效地捕捉和利用長期依賴關系,因而在處理非線性時間序列分析中發揮了重要作用。例如:潘永東等[10]利用LSTM模型對南京市的PM2.5濃度進行預測和趨勢分析,取得了優于SVR、XGBoost和MLR模型的預測結果;肖敏志等[11]的研究也表明,LSTM模型在PM2.5濃度預測上的精度超過了RNN模型。然而LSTM模型的預測準確性高度依賴于其超參數的初始值設置,如迭代次數、學習率以及隱含層神經元數量等,而人工設置這些超參數往往存在諸多挑戰[12],可能導致模型構建困難和預測精度不足等問題,從而影響最終預測結果。
為解決上述問題并進一步提升預測精度,本文提出麻雀搜索算法[13]長短期記憶神經網絡(Sparrow Search Algorithm-Long Short-Term Memory, SSA-LSTM)模型預測PM2.5濃度。研究基于長沙市2023年5月到8月期間的空氣污染物濃度和氣象數據,應用SSA對LSTM模型的超參數進行優化,構建了SSA-LSTM模型,并將其與單一LSTM預測模型、粒子群優化算法(Particle Swarm Optimization, PSO)優化的LSTM模型,以及鯨魚優化算法(Whale Optimization Algorithm, WOA)優化的LSTM模型的預測結果進行對比分析。
1? 基礎理論
1.1? 長短期記憶神經網絡
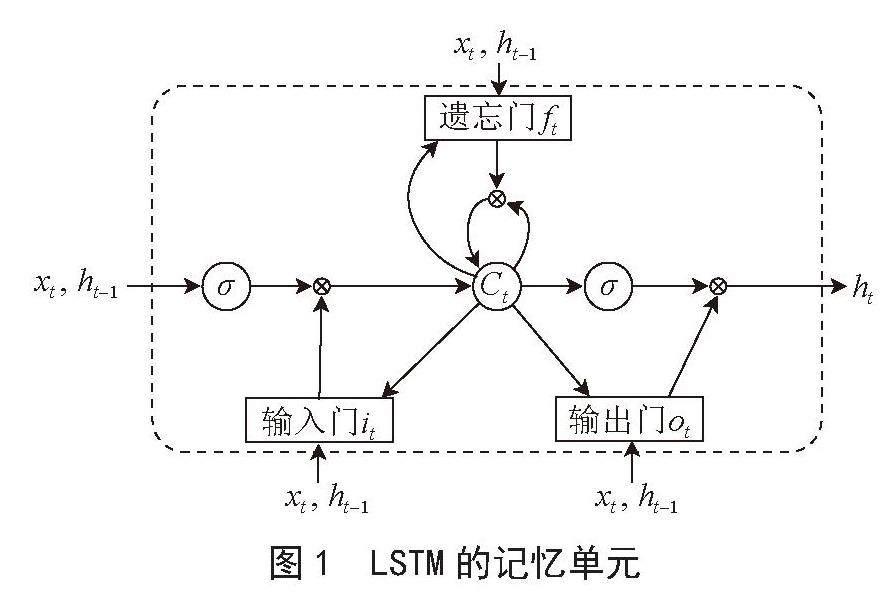
長短期記憶神經網絡[9](LSTM)是深度學習領域中一種重要的遞歸神經網絡(RNN)變體,于1997年由Hochreiter和Schmidhuber首次提出,解決了傳統RNN模型在長序列訓練過程中的梯度消失和梯度爆炸問題,對于長時間序列數據的預測具有非常好的表現能力,LSTM的記憶單元如圖1所示。
圖1? LSTM的記憶單元
長短期記憶網絡(LSTM)的核心在于其獨特的細胞狀態(Cell State),這一狀態構成了網絡的記憶核心,相當于一個內存單元,專門設計用于存儲和傳遞時間序列信息。這一機制賦予了LSTM處理長期時間依賴性的能力,從而在處理序列數據時,能夠維持關鍵信息的長期記憶。LSTM的記憶單元由三個主要的門控組件構成:輸入門(it)、輸出門(ft)和遺忘門(ot)。在時刻t,記憶單元接收輸入向量xt,并更新其隱藏狀態ht。門控結構的作用是調節信息流,其中輸入門負責調控新信息的接入,遺忘門控制信息的保留與丟棄,而輸出門則控制從記憶單元到輸出的信息流。這些門的活動狀態是通過學習得到的,初始狀態分別設定為it、ft和ot,以便網絡能夠在訓練過程中自適應地調整信息流的動態傳遞。
在LSTM中,存儲單元的狀態更新過程如下。
以下等式是輸入門的數學表達式,它決定了哪些信息必須轉移到單元中:
(1)
以下等式是遺忘門的數學表達式,它決定了要忽略哪些信息:
(2)
(3)
根據遺忘門和輸入門的狀態,來更新單元狀態Ct,表達式為:
(4)
輸出門負責更新輸出,由以下等式給出,輸出門還負責更新前一個時間步的隱藏層。輸出門的最終輸出為:
(5)
(6)
式(1)~(6)中,σ表示Sigmoid函數,會根據輸入產生[0,1]之間的向量; 表示的是候選細胞信息;Wf 、Wi、Wo、Wc表示的是LSTM細胞狀態更新過程中的權重系數矩陣;bf 、bi、bo、bc表示狀態更新過程中的偏置矩陣。
1.2? 麻雀搜索算法
麻雀搜索算法[13](Sparrow Search Algorithm, SSA)源自對麻雀群體在自然界中覓食及逃避天敵行為的深入觀察,是一種模擬生物群體智能行為的優化算法。該算法精確地抽象了麻雀在其生態系統中的行為策略和社會結構,明確劃分為發現者、加入者以及警戒者三種角色。在此算法下,發現者承擔著探索資源并指引群體覓食方向的重任,而加入者則依賴發現者的引導以獲得資源,警戒者則在感知到威脅時向同伴發出警報,并引導群體采取避險措施。麻雀搜索算法具有求解精度高、收斂速度快、魯棒性好的特點,在求解復雜優化問題時展現出了顯著優勢,尤其是在收斂速度和增強全局搜索能力方面表現出色,已成為解決各類優化問題的一種高效算法。
在麻雀搜索算法中,N只麻雀所組成的隨機初始化種群表示如下:
(7)
式(7)中,d表示待優化問題變量的維數。麻雀種群的適應度表示如下:
(8)
式(8)中,f表示單只麻雀的適應度值。發現者的位置更新公式:
(9)
式(9)中,t表示當前的迭代索引且 ,其中itermax表示預定的最大迭代次數;j為維度索引, 表示第t次迭代中第i只麻雀的第j維的位置信息;參數α表示一個定義在區間(0,1]上的隨機變量;ST和R2分別表示安全閾值和報警閾值;Q表示一個服從正態分布的隨機變量;L表示一個全由1構成的1×d維矩陣。
當R2<ST時,表示此時具有安全的覓食環境,發現者可進行大范圍的搜索;當R2≥ST,表示當前覓食環境出現危險信息,整個麻雀種群需轉移到安全區域進行搜索。加入者的位置更新公式:
(10)
式(10)中,Xp表示目前發現者所占據的最優位置;Xworst則表示當前全局最差的位置;A表示一個元素隨機為1或-1的1×d維矩陣,并且A+ = AT (AAT)-1。
當i>n / 2時,表明適應度較低的第i個加入者因無法獲取食物而處于饑餓狀態,需前往其他地方進行覓食從而補充能量。預警者的位置更新公式:
(11)
式(11)中,Xbest表示當前迭代中全體個體的最優位置;參數β和α都表示步長控制因子,其中β表示一個服從均值為0的且方差為1的正態分布的隨機變量,而α表示一個值位于[-1,1]的隨機變量;fg和fw分別表示當前迭代中的全局最優適應度值和最差適應度值;fi則表示當前麻雀個體的適應度值;ε表示一個趨近于0的變量,用以確保分母不為0。
當個體適應度fi大于全局適應度fg時,這表明該麻雀處于潛在的危險區域,易受到捕食者的攻擊;當fi = fg時,位于種群中間的麻雀感知到危險的跡象,它們會傾向于靠近其他個體,以減少自身被捕食的可能性。
1.3? SSA-LSTM模型
LSTM模型的性能和預測準確性在很大程度上受到其超參數配置的影響,這些超參數包括但不限于迭代次數、隱含層神經元數量以及學習率等。傳統的超參數調整方法往往依賴于經驗和試錯,這種方法不僅耗時而且缺乏系統性,很難保證達到模型性能的最優化。因此本文采用了智能優化算法——麻雀搜索算法(SSA),對LSTM模型的超參數進行系統地優化。通過SSA算法的全局搜索能力,可以確保LSTM模型在多維超參數空間中有效地探索,并快速穩定地收斂到全局最優解,從而顯著提升模型的性能和預測精度。
此模型的優化過程包含以下幾個步驟:
1)首先對缺失數據采用拉格朗日插值法對數據進行填補。之后執行歸一化處理,根據式(12),將所有數據縮放到[0,1]區間中以消除量綱影響。
(12)
式(12)中,X表示原始數據;Xmin和Xmax分別表示原始數據中的最小值和最大值;Xnew表示歸一化處理之后的數據。完成這些步驟后,再將數據集劃分為訓練集和測試集。
2)利用參數如最大迭代次數、麻雀種群規模、尋優維度以及生產者比例來初始化麻雀種群。采用訓練集上的均方誤差作為適應度函數,對LSTM網絡的關鍵超參數——迭代次數、隱含層神經元數量和學習率進行自動優化。
3)計算種群中每個麻雀個體的適應度,并按適應度值進行排序,以識別當前具有最優和最差適應度的個體。
4)根據式(9)~(11)更新發現者、跟隨者和預警者的位置。在每次迭代中,保留適應度最高的個體,并更新全局最優適應度值。
5)判斷是否滿足算法的終止條件,如果滿足,則保存算法所尋到的最優參數;如果不滿足,則返回步驟3)繼續迭代優化過程。
6)使用優化后的超參數重構LSTM模型,并輸入測試集數據以獲得預測值。最后,對預測結果進行反歸一化處理,以得到最終的預測結果。
構建的系統模型整體結構如圖2所示。
圖2? SSA-LSTM流程圖
2? 實驗與結果分析
2.1? 實驗平臺
本實驗基于Python語言,使用JupyterLab進行代碼編寫和結果展示。具體實驗環境及相關版本號如表1所示。
表1? 實驗環境配置
項目 版本
操作系統 Ubuntu 22(x86)
CPU Intel(R)Xeon(R)CPU E3-1231 v3
GPU NVIDIA Quadra K1200
內存 32 GB
Python 3.8.17
TensorFlow-GPU 2.3.0
Numpy 1.24.3
Matplotlib 3.7.1
2.2? 數據來源
本文采用的數據來自中國環境監測總站(www.cnemc.cn),選取了2023 年5月1日0點到2023年8月25日23點的長沙市空氣質量小時數據,包括PM2.5、PM10、SO2、NO2、O3等空氣污染物濃度和風速、溫度、濕度等氣象數據共3 000條記錄,其中前80% 數據作為訓練集,后20%數據作為測試集。空氣污染物濃度單位為μg/m3、溫度單位為℃、風速單位為m/s、濕度單位為%RH。受篇幅限制,部分數據如表2所示。
2.3? 評價指標
為了全面評估預測模型的性能,本實驗選用了均方根誤差(Root Mean Square Error, RMSE)、平均絕對誤差(Mean Absolute Error, MAE)和擬合優度R2(Goodness of Fit)作為評價指標,計算公式如下:
(13)
(14)
R2 = 1 -? ? ? ? ? ? ? ? (15)
式中,Yi表示第i個時間點實際觀測到的PM2.5濃度值, 表示模型預測的PM2.5濃度值,N表示觀測序列的總長度。理想情況下,RMSE和MAE的值越低,表明預測誤差越小;R2的值越接近1,則說明模型的預測能力越強,擬合度越高。
2.4? 結果分析
SSA會對LSTM網絡的超參數尋優,包括迭代次數、學習率、第1和第2隱含層的神經元數量,并以訓練集的均方差(RMSE)為適應度函數,適應度函數值越大,表明模型訓練結果越準確。設置麻雀種群中個體數目為10,尋優維度為4,最大迭代次數為10,發現者和警戒者在麻雀種群中所占比例分別為20%和10%,安全閾值ST為0.8。設置學習率的范圍為[0.001,0.01],迭代次數尋優范圍為[10,100],第1和第2隱含層的神經元數量范圍為[1,100]。
為了充分證實所提出的SSA-LSTM模型在預測精度和有效性方面的優勢,本文設計了以下對比實驗,涵蓋了單一LSTM模型、PSO-LSTM模型和WOA-LSTM模型。通過這些對比實驗,旨在展示SSA-LSTM模型在處理PM2.5濃度預測問題時的性能表現。預測結果的對比展示在圖3中,其直觀反映了不同模型間的預測能力差異。
如圖3所示的實驗結果顯示,SSA-LSTM模型在預測精度方面相對于單一LSTM模型具有顯著提升,并且與PSO-LSTM模型和WOA-LSTM模型相比,展現出更優的擬合能力。這一結果凸顯了SSA-LSTM模型在整體預測性能上的優越性。為了進一步量化各模型的預測效果,本文采用了式(13)~(15)定義的評價指標RMSE、MAE和R2進行計算,并將結果匯總至表3。
表3? 實驗結果
預測模型 評價指標
RMSE MAE R2
LSTM 2.407 6 1.938 4 0.874 8
WOA-LSTM 2.139 2 1.634 4 0.901 1
PSO-LSTM 1.968 2 1.488 1 0.916 3
SSA-LSTM 1.745 2 1.293 9 0.932 3
由表3可知,SSA-LSTM的預測結果擬合效果表現最佳,相較于單一LSTM模型、WOA-LSTM模型以及PSO-LSTM模型,SSA-LSTM的均方根誤差(RMSE)分別降低了27.51%、18.42%、11.33%,平均絕對誤差(MAE)分別降低了33.25%、20.83%、13.05%,擬合優度(R2)分別提高了45.93%、31.55%、19.12%。這些結果進一步證明了SSA-LSTM模型在提高PM2.5濃度預測準確性方面具有顯著優勢。
3? 結? 論
本研究提出了一種結合麻雀搜索算法和長短期記憶神經網絡的PM2.5濃度預測模型(SSA-LSTM),針對空氣質量評估的關鍵問題進行了探究。通過構建的SSA-LSTM模型,本文有效地解決了LSTM模型超參數的初始化設置難題,實現了對PM2.5濃度的精確預測,為相關領域研究提供了新的思路。基于長沙市2023年5月至8月的空氣污染物濃度和氣象數據,建立對比實驗,實驗結果表明,SSA-LSTM模型的預測結果相比于單一LSTM模型以及其他先進的組合模型(如PSO-LSTM和WOA-LSTM),表現出了更優秀的預測精度。
未來的工作將聚焦于進一步提升預測模型的實時性和動態適應性,探索實時數據流環境下的模型快速更新機制,并結合更多種類的環境數據源,以及考慮更加復雜的外部影響因素,例如區域工業活動、交通流量和天氣變化等。同時,也應關注模型的可解釋性,以便更好地理解模型預測結果背后的驅動因素,為政策制定者提供更可靠的決策支持。
參考文獻:
[1] 李衛兵,張凱霞.空氣污染對企業生產率的影響——來自中國工業企業的證據 [J].管理世界,2019,35(10):95-112+119.
[2] 楊新興,馮麗華,尉鵬.大氣顆粒物PM2.5及其危害 [J].前沿科學,2012,6(1):22-31.
[3] DIMITRIOU K,KASSOMENOS P. A study on the reconstitution of daily PM10 and PM2.5 levels in Paris with a multivariate linear regression model [J].Atmospheric Environment,2014,98:648-654.
[4] 黃婷婷,朱家明,劉丹丹.蕪湖市PM(2.5)的影響因素分析與預測 [J].山西師范大學學報:自然科學版,2017,31(2):88-93.
[5] JIAN L,ZHAO Y,ZHU Y P,et al. An application of ARIMA model to predict submicron particle concentrations from meteorological factors at a busy roadside in Hangzhou,China [J].Science of the Total Environment,2012,426:336-345.
[6] HU X,BELLE J H,MENG X,et al. Estimating PM2.5 Concentrations in the Conterminous United States Using the Random Forest Approach [J].Environmental Science & Technology,2017:6936-6944.
[7] LAI X,LI H,PAN Y. A combined model based on feature selection and support vector machine for PM2.5 prediction [J].Journal of Intelligent & Fuzzy Systems,2021:10099-10113.
[8] CHEN Y. Prediction algorithm of PM2.5 mass concentration based on adaptive BP neural network [J].Computing,2018:825-838.
[9] HOCHREITER S,SCHMIDHUBER J. Long short-term memory [J].Neural computation,1997,9(8):1735-1780.
[10] 潘永東,曹騮,劉明.基于LSTM網絡的PM2.5濃度預測 [J].金陵科技學院學報,2021,37(4):7-13.
[11] 肖敏志,王淑君,宋巍巍.基于LSTM的PM(2.5)預測模型綜述 [C]//2019中國環境科學學會科學技術年會論文集(第一卷).西安:[出版者不詳],2019:949-952.
[12] GILIK A,OGRENCI A S,OZMEN A. Air quality prediction using CNN+LSTM-based hybrid deep learning architecture [J].Environmental Science and Pollution Research,2022:11920-11938.
[13] 薛建凱.一種新型的群智能優化技術的研究與應用 [D].上海:東華大學,2020.
作者簡介:曹還君(2000—),男,漢族,湖南常德人,碩士在讀,研究方向:工業大數據、智能信息處理;李長云(1971—),男,漢族,湖南衡陽人,教授,博士,研究方向:軟件理論、物聯網工程、人工智能。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
房地產導刊(2022年5期)2022-06-01 06:20:14
建材發展導向(2021年12期)2021-07-22 08:06:48
建材發展導向(2021年7期)2021-07-16 07:07:52
中學生數理化(高中版.高二數學)(2021年12期)2021-04-26 07:43:48
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
作文周刊·小學一年級版(2016年27期)2017-06-03 23:21:17
光學精密工程(2016年6期)2016-11-07 09:07:19
新湘評論·下半月(2016年4期)2016-05-05 22:12:41
