共享智慧,解讀心愿:公共圖書館用戶檢索意圖庫構建關鍵技術與應用探析
2024-05-24 08:42:31張寧
四川圖書館學報 2024年3期
收稿日期:2023-07-14
摘? 要:
隨著數字化時代的到來,傳統的關鍵詞匹配檢索方式已經無法滿足用戶個性化的信息需求。因此,構建用戶檢索意圖庫成為了解決這一問題的關鍵。通過收集和分析用戶查詢數據和目標數據,分析提取用戶意圖特征,并作為構建用戶檢索意圖庫的基本要素,利用自然語言處理技術理解和識別用戶檢索意圖,同時探析了用戶檢索意圖構建過程中的三大關鍵技術,探討了用戶檢索意圖庫在公共圖書館中的應用。
關鍵詞:
公共圖書館;用戶檢索意圖庫;自然語言處理;特征提取
中圖分類號:G258.2??? 文獻標識碼:A??? 文章編號:1003-7136(2024)03-0054-09
Sharing Wisdom,Unveiling Desires:Analysis of the Key Technology and Application of the Construction of User Retrieval Intention Library in Public Libraries
ZHANG Ning
Abstract:
With the advent of the digital age,the traditional keyword matching retrieval method has been unable to meet the user′s personalized information needs.Therefore,the construction of user retrieval intention library has become the key to solve this problem.By collecting and analyzing the user query data and target data,the user intention features are analyzed and extracted,as the basic elements of constructing the user retrieval intention library,as well as the natural language processing technology is used to understand and identify the user retrieval intention.This paper analyzes the three key technologies in the process of user retrieval intention construction,and discusses the application of users retrieval intention library in public libraries.
Keywords:
public library;user retrieval intention library;natural language processing;feature extraction
0? 引言
在當今信息爆炸的時代,公共圖書館作為知識共享的重要場所,承擔著為用戶提供豐富、準確信息的責任和使命[1]。然而,隨著用戶需求的多樣化,傳統的圖書館檢索系統往往無法準確理解用戶的真實信息需求。因此,如何準確地理解和識別用戶檢索意圖,解決公共圖書館用戶的信息檢索問題已經成為迫切需要解決的問題。
在這種背景下,借鑒其他行業目前已經比較成熟的方法,構建用戶檢索意圖庫成為一種比較有效的解決方案。在深入分析用戶的檢索行為、理解用戶的搜索意圖和需求的基礎上,公共圖書館可以利用自身優勢提供個性化、精準的信息推薦和導航服務,從而提升用戶的信息獲取率和利用效率。然而,與此相關的問題也隨之而來:如何準確地捕捉和解讀用戶的檢索意圖?如何構建一個有效的檢索意圖庫?如何將檢索意圖庫應用到公共圖書館的信息檢索系統中?這些問題都需要我們進行深入的研究和探索。
本文旨在回答上述問題,提出共享智慧、解讀用戶心愿的解決方案,以構建和應用公共圖書館的檢索意圖庫。利用機器學習、自然語言處理和數據挖掘等相關技術,結合圖書館領域的實際需求,研究如何從用戶的搜索關鍵詞、瀏覽下載的資源中提取有用信息,從而識別用戶的檢索意圖,并以此為基礎,構建一個具有豐富語義信息的公共圖書館檢索意圖庫,從而更準確地理解用戶的真實需求,為用戶提供個性化、精準的信息服務。
1? 研究綜述
1.1? 用戶檢索意圖庫及意義
所謂用戶檢索意圖庫,從數據層面上來說,其實質就是指一個預先構建好的、包含了用戶常見檢索意圖的數據庫;從系統層面上來說,它就是一個集合了常見用戶意圖的庫或分類系統。它包含了用戶在與系統進行交互時可能表達的各種意圖,如獲取信息、執行操作、提出問題等。對于公共圖書館來說,用戶檢索意圖庫主要根據用戶的檢索信息,通過自然語言識別的方式從中抽取用戶的檢索主題和檢索目的,以及檢索需求中所包含的時間范圍、地域范圍和目標人物等。
無論是從公共圖書館角度還是從用戶角度,建立用戶檢索意圖庫都是一件具有重要意義的工作。從公共圖書館的角度來說,建立公共圖書館用戶檢索意圖庫,可以幫助圖書館或其他信息機構更準確地理解用戶的檢索需求,從而提供更精確的檢索結果;從用戶角度來說,用戶的查詢可能涉及不同的主題、領域和意圖,通過建立一個用戶檢索意圖庫,可以收集和整理常見的用戶查詢意圖,并為每個意圖提供相應的處理邏輯和響應策略。此外,用戶檢索意圖庫也具有極為重要的應用意義,具體包括:
①提升用戶體驗。公共圖書館是廣大讀者獲取信息和閱讀資源的重要場所。建立用戶檢索意圖庫可以幫助圖書館系統更準確地理解讀者的查詢意圖,從而能夠更快速、精準地提供符合讀者需求的資源和服務,提升用戶的檢索體驗。
②提高搜索效果。通過建立用戶檢索意圖庫,公共圖書館可以建立豐富的查詢意圖和相關資源的映射關系。當讀者進行查詢時,系統可以根據意圖庫中的信息迅速匹配合適的資源,從而提高搜索結果的質量和相關性。
③個性化服務。通過分析和理解讀者的查詢意圖,公共圖書館可以提供更加個性化的服務。根據讀者的喜好、需求和查詢意圖,圖書館系統可以推薦相關的圖書、文章、活動或其他資源,更好地滿足讀者的閱讀需求。
④指導讀者。用戶檢索意圖庫還可以幫助圖書館系統提供更準確的查詢建議和指導。當讀者輸入查詢時,系統可以根據意圖庫中的信息給出相關的建議或指導,幫助讀者更好地組織查詢、選擇合適的資源或深入探索特定領域。
⑤數據分析與優化。通過對用戶檢索意圖庫的使用情況進行分析,公共圖書館可以獲取有關讀者檢索習慣、偏好和需求的寶貴信息。這些數據可以用于圖書館的服務優化、資源采購決策和用戶行為分析,進一步提升圖書館的運營效率和服務質量。
1.2? 研究進展
用戶檢索意圖是信息檢索領域的重要研究方向,指用戶在檢索信息時,所表達的需求和目的[2],即通過對用戶檢索意圖的識別和理解,幫助用戶縮小檢索范圍,明確檢索目的。早期的用戶檢索意圖研究主要基于關鍵詞檢索,通過對用戶檢索關鍵詞的分析,研究用戶的檢索意圖,包括基于關鍵詞集合進行共現分析[3],利用聚類算法對檢索詞進行聚類分析等[4]。隨著信息檢索技術的不斷發展,研究者開始采用自然語言處理技術和機器學習技術,從文本中提取和分析用戶的檢索意圖。如今,隨著大數據技術和人工智能技術的應用,用戶檢索意圖的研究進入了一個新的階段。目前,用戶檢索意圖的研究和應用主要集中在以下幾個方向。
(1)檢索意圖分類。研究者致力于開發算法和模型,將用戶的查詢意圖進行分類和歸納。常見的方法包括基于標簽分類[5-6]、機器學習和深度學習的分類算法[7],通過訓練模型從用戶查詢中識別出不同的檢索意圖,如信息獲取、問題解答、產品比較等。
(2)檢索意圖理解。研究者關注如何更好地理解用戶的檢索意圖。這涉及自然語言處理、語義理解[8]、語義表示、知識圖譜[9]和情感分析[10]等技術。通過構建語義模型和語義表示方法,系統可以更好地理解用戶的查詢意圖,進而提供更加準確和相關的搜索結果。
(3)個性化檢索意圖。研究者探索如何根據用戶的個性化需求和偏好定制檢索意圖模型。這包括用戶模型的構建[11]、個性化推薦和查詢擴展等技術。通過分析用戶的興趣[12]、上下文和歷史行為[13],系統可以更好地適應用戶的個性化需求,提供個性化的檢索意圖服務。
(4)多模態檢索意圖。隨著多模態數據的廣泛應用,研究者開始關注多模態檢索意圖的研究。這包括文本、圖像、語音和視頻等多種模態信息的融合和理解[14-15]。通過融合不同模態的信息,系統可以更全面地理解用戶的檢索意圖,提供更豐富和準確的搜索結果。
總體而言,用戶檢索意圖研究在算法、模型和應用方面都取得了一定的進展。通過深入研究用戶檢索意圖,能夠更好地理解用戶需求,提供個性化、精準和高效的信息檢索服務,從而提升用戶的搜索體驗滿意度。隨著技術的不斷進步和應用場景的拓展,用戶檢索意圖研究仍然是一個具有挑戰和潛力的領域。
2? 需求場景與技術路線
構建公共圖書館用戶檢索意圖庫,其目的在于完整地捕捉用戶自然語言中所蘊含的檢索意圖,使圖書館現有的檢索系統能夠更加智能化地理解用戶的檢索意圖和需求。從整體上來說,包括檢索需求分析及構建場景、設計技術路線兩個部分。
2.1? 檢索需求場景分析
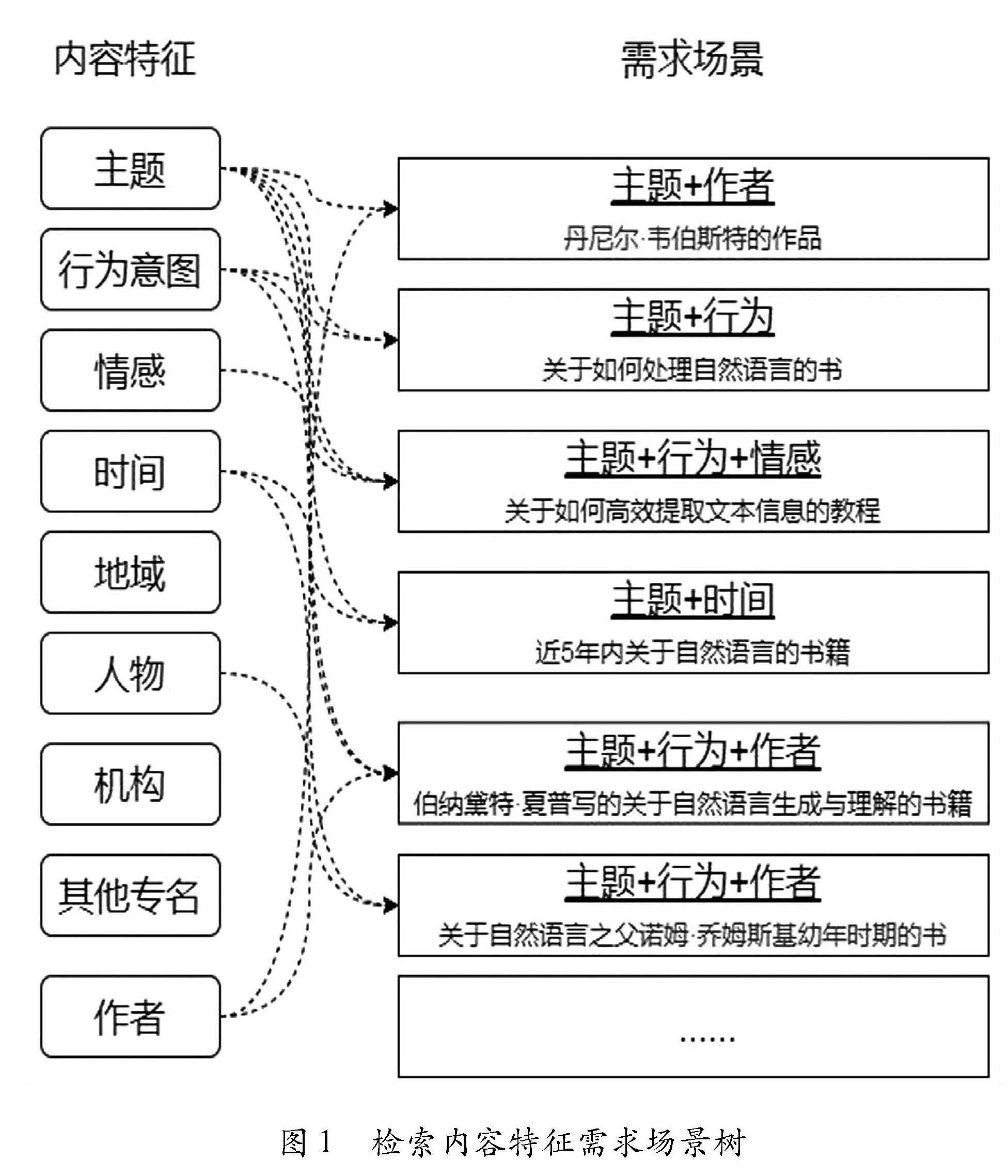
本文從用戶視角出發,設計了以用戶檢索內容為特征的場景樹,如圖1所示。以查詢語句“我想看一本近5年以來美國哈佛大學推薦的如何高效地提取文本信息的關于自然語言處理的書”為例,其檢索語句中包含了主題、行為意圖、時間、地域、機構等多種信息要素,并通過“關于”“推薦”等顯式謂詞或隱含關系指示實體與數據屬性之間的從屬、并列等關系。在智慧圖書館條件下,公共圖書館的搜索引擎需要支持此類自然語言的響應,能夠分析和識別出用戶期望的需求和給定的各種限定條件,并返回正確的檢索結果。
公共圖書館用戶檢索意圖庫設計要充分結合用戶的實際檢索需求和落地的可行性,需要遵循以下幾個基本原則。
(1)全面性。意圖庫應該覆蓋用戶可能的多樣化檢索意圖。收集和整理不同類型、不同領域的檢索意圖樣本,包括常見的查詢目的、問題類型、需求表達方式等。
(2)智能性。利用機器學習和自動化技術對用戶檢索意圖進行建模和識別。通過訓練算法和模型,讓系統能夠自動學習和識別用戶的意圖,減少人工標注的工作量,提高效率和準確性。
(3)可擴展性。意圖庫的設計應具備可擴展性,以便隨著用戶需求的變化和增長不斷更新和擴展。新的檢索意圖樣本可以根據用戶反饋、數據分析結果和領域知識變化進行持續補充和更新。
(4)組織性。意圖庫應該有良好的組織結構,便于快速準確地匹配用戶的檢索意圖。可以根據意圖的主題、目的、領域等屬性對樣本進行分類和標注,方便后續的意圖匹配和處理。
(5)實時性。意圖庫需要保持實時更新,及時反映用戶的新興檢索需求和趨勢。隨著時間的推移,一些檢索意圖可能會變得不再流行或過時,因此需要定期審查和更新意圖庫中的樣本。
2.2? 總體技術方案設計
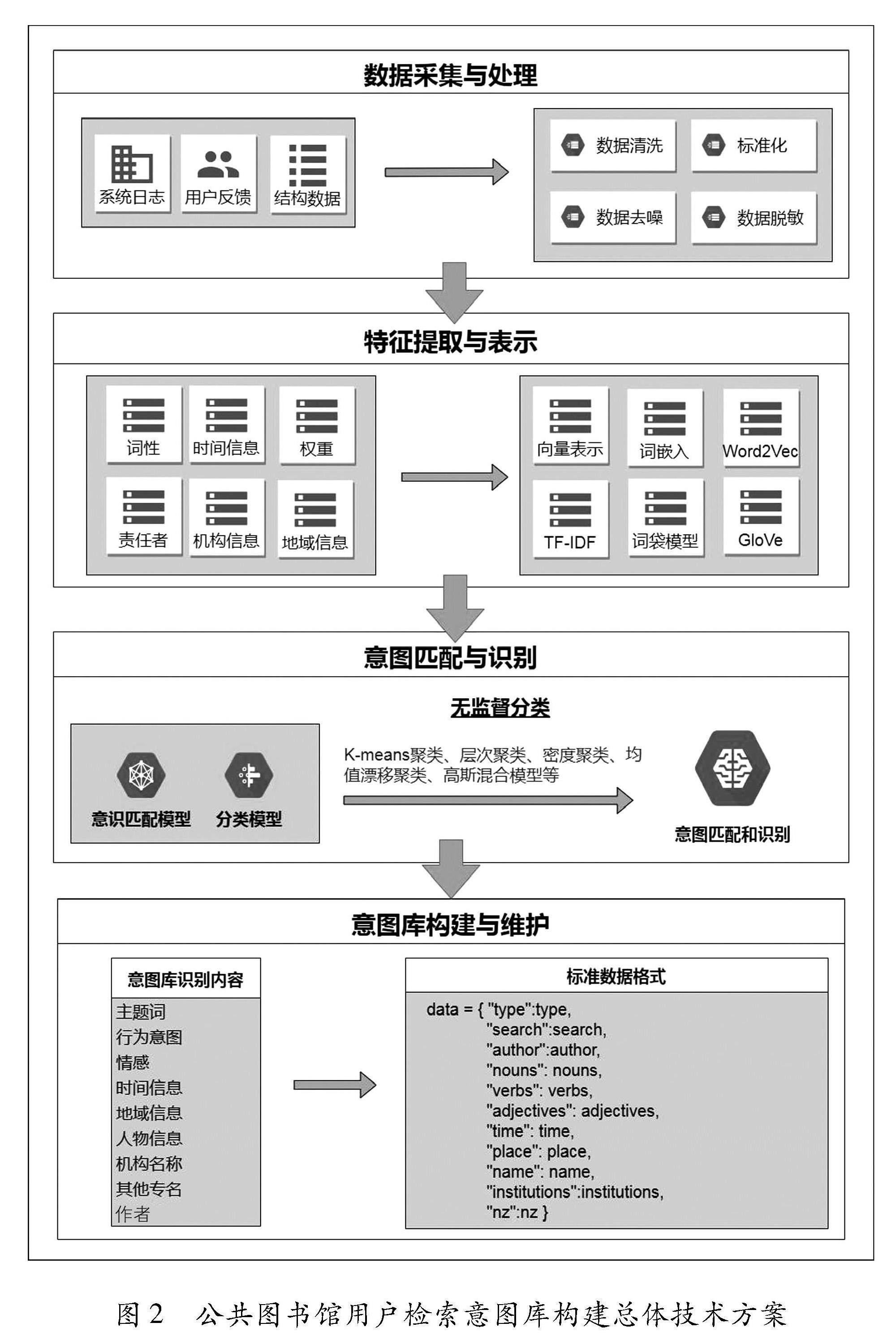
在明確需求場景和設計原則后,本文提出相應的技術方案,從總體上來說,總共分為四大步驟,具體如圖2所示。
(1)數據采集與處理。收集用戶的查詢數據和相關上下文信息,如搜索日志、用戶反饋等。對收集到的數據進行預處理,將清洗、去噪之后的數據制作成標準格式統一組合和存儲,以提高后續處理的質量和準確性。
(2)特征提取與表示。特征提取是機器學習和數據分析中的關鍵概念,指從原始數據中選擇和提取最相關、最具有代表性的特征,以捕捉數據的重要信息[16],其目標是減少數據的維度,同時保留盡可能多的有用信息,以便于后續的模型訓練和分析。在表示方式上,特征表示是將提取到的特征以一種可操作的方式呈現出來,便于機器學習算法的處理和分析,即需要將自然語言轉化為計算機可以理解的文本表示方法[17]。從用戶的角度考慮,提取最能表達用戶意愿的信息作為本文特征能夠更加準確地理解和識別檢索意圖,縮小檢索范圍,如主題信息、行為信息、時間信息等。
(3)意圖匹配與識別。利用機器學習或深度學習的方法,建立意圖匹配模型或分類模型,對用戶查詢進行意圖匹配和識別。可以使用傳統的機器學習算法如支持向量機、決策樹等,或者使用深度學習算法如循環神經網絡、卷積神經網絡等。訓練模型時,可以使用已標注的數據集進行監督學習,也可以利用無監督學習或半監督學習的方法。由于用戶檢索意圖是大量無標記的數據,比較適用于采用無監督的分類方案對數據進行聚類,因此本文將采用無監督分類的方法對數據進行聚類。(4)意圖庫構建與維護。根據用戶查詢數據和已有的標注數據,在特征提取的基礎上,構建用戶檢索意圖庫,提取的特征包括主題詞、行為意圖、情感、時間信息、地域信息、人物信息、機構名稱、其他專名、作者等信息,并將這些信息以標準數據的形式進行表達和存儲,作為檢索意圖的統一描述,能夠滿足檢索引擎在開發時所面對的功能需求,形成可復用的框架產出[18]。此外,定期維護意圖庫,更新和擴充其中的意圖樣本,從而保持其準確性和覆蓋范圍。
3? 流程構建與關鍵技術
在明確了公共圖書館用戶檢索意圖庫的總體設計與實現思路后,本節重點關注用戶檢索意圖庫實現流程及所需的關鍵技術,就其目標與任務等進行闡述,并探討原型系統的設計與構建。
按照總體技術方案設計,本文將公共圖書館用戶檢索意圖庫的構建工作流程分為三個主要部分。
3.1? 文本處理與特征提取
文本處理和特征提取是自然語言處理中的重要技術,主要是指在對文本數據進行清洗、分詞、詞性標注、句法分析、實體識別和文本分類等操作[19]的基礎上,按照實際的需求提取能夠反映文本主要內容特征的詞項,并附有權重,包括文本特征選擇和特征權重計算兩個主要環節[20]。在特征提取內容上,特征提取分為句法分析特征、文本語義特征、文本結構特征和文本分類特征等。在公共圖書館日常的用戶信息檢索中,常常會使用查詢語句來表達自己的信息需求[21],因此在實際對用戶檢索意圖進行識別和理解之前,需要對其進行檢索信息處理和文本特征提取,并且從檢索信息中提取有用的信息。
通過對國家圖書館用戶檢索數據
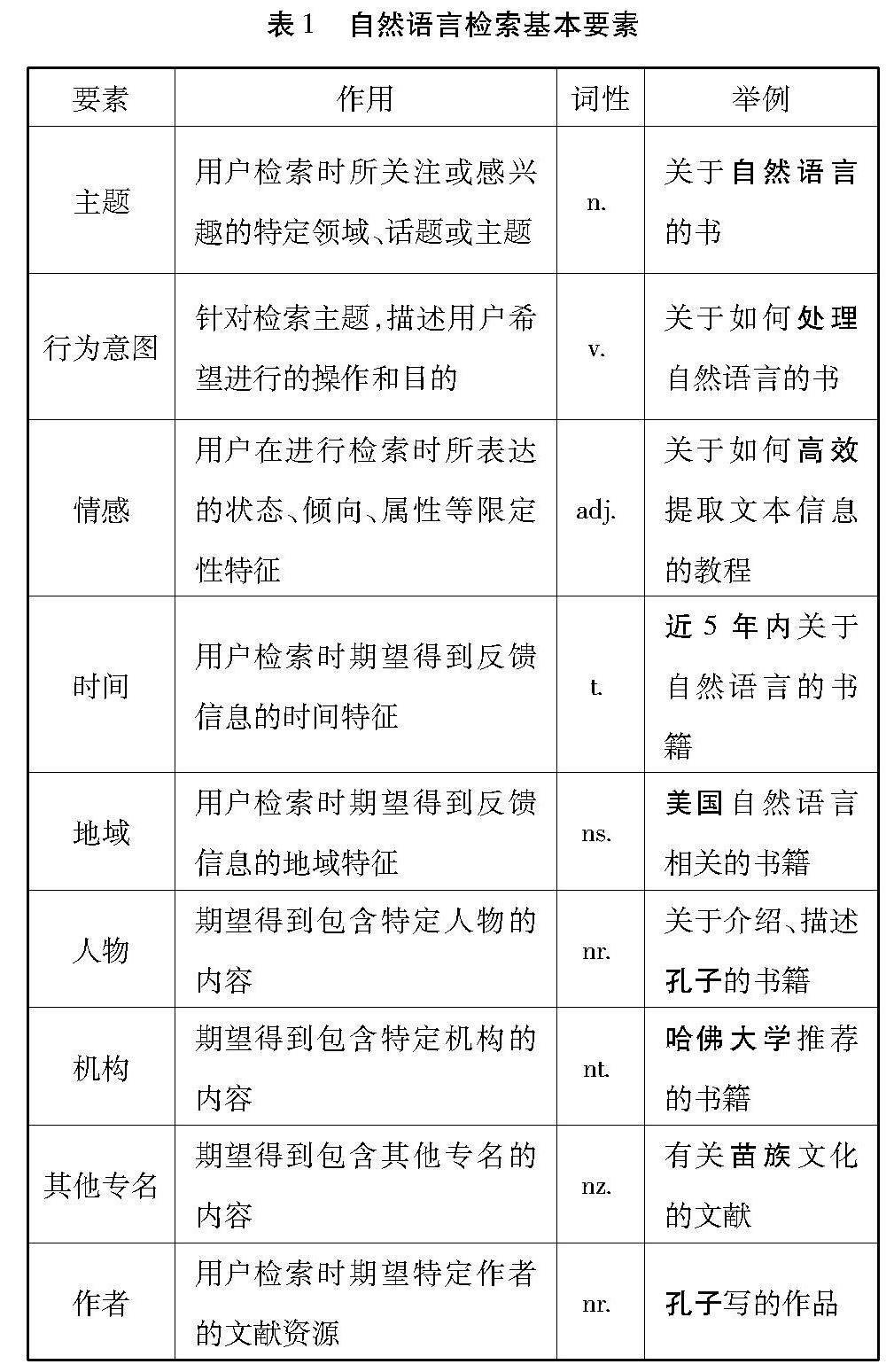
檢索數據來源于國家圖書館文津搜索系統。進行分析,發現用戶常用的檢索語句中一般會包括檢索主題、檢索行為意圖、情感、時間范圍、地域范圍、人物、機構和其他專名等要素,其中大約有70%的檢索信息為檢索主題和行為意圖[22],詞性多為名詞和動詞,其余要素多數以定狀補的形式出現,詞性以形容詞為主,少數為時間詞、地點詞或專有名詞,具體如表1所示。因此,在建立公共圖書館用戶檢索意圖庫時,需要將這些關鍵信息作為文本語義特征進行提取,作為用戶檢索意圖庫的基本信息要素。當然,隨著對建立用戶檢索意圖庫需求和文本處理能力的不斷提高,基本信息要素也會隨之不斷地修改和完善,這里僅以表1列出的文本特征作為本文用戶檢索意圖庫建設的基本信息要素。
3.2? 檢索意圖理解與識別
檢索意圖理解與識別是自然語言處理和信息檢索領域的關鍵任務和熱點之一[23],指對用戶輸入的搜索查詢或問題進行分析和理解,以確定用戶的搜索意圖或需求,同時按照一定的標準或規則進行分類和組織,以方便用戶進行有效的信息檢索和瀏覽[24],本文所考慮的檢索意圖理解與識別主要包括實體識別、分詞權重和依存關系分析三個方面。
實體識別是自然語言處理中的一項任務,旨在從文本中識別和提取具有特定意義的命名實體,在本文中,實體識別主要的識別內容為用戶檢索的基本特征要素,即檢索主題、檢索行為意圖、情感、時間范圍、地域范圍、人物、機構和其他專名等,利用分詞工具進行分詞、詞性標注、關鍵詞提取等處理,根據處理和識別結果抽取主要信息。
分詞權重是指對文本中的每個詞語進行權重計算或賦值的過程,在智能檢索系統中,語義分詞的權重會對語義檢索產生影響[25],通過計算關鍵詞的權重,可以確定文本中哪些詞語是重要的關鍵詞,有助于用戶快速理解文本的主題和內容,同時,分詞權重可以用來計算文檔與用戶查詢之間的相關性,從而對檢索結果進行排序。因此,用戶檢索意圖庫的建設除了需要對實體進行識別外,還需要利用分詞權重技術計算實體的權重值。
依存關系分析是自然語言處理中的一項重要任務,旨在識別句子中單詞之間的語法依存關系,并以此表示句子中單詞之間的關聯性和句子的結構。依存關系分析可以深入理解句子的語法結構,從而幫助解析句子的含義、進行文本理解和其他自然語言處理任務。在具體操作上,通過分析用戶檢索語言的各個成分之間的依存關系來揭示相互之間的語義修飾關系[26],即分析出一個句子的主、謂、賓、定、狀、補結構,從而幫助判斷特征要素。本文采用DDParser
DDParser是一個基于深度學習的依存句法分析器,在句法分析任務中具有較高的準確性和魯棒性。它使用神經網絡模型來自動分析句子中詞語之間的依存關系,并預測每個詞語在句子結構中的角色和語法功能。來分析語句之間的依存關系,并根據需要生成相應依存關系圖,如查詢語句 “我想了解一下美國學者德里克·賈里尼克寫的關于自然語言處理方面的書”,其依存關系如圖3所示。
此外,在檢索意圖表達形式方面,戚越、陳博立等分別在各自的研究中提出了較為一致的想法,即采用標準的結構化形式進行表達[18,27]。為了便于下游任務的使用和調取,本文采用了基于json格式的方式表示和存儲用戶檢索意圖理解和識別,以及各關鍵詞的權重結果,示例如圖4所示。
3.3? 自定義詞庫構建
在實際的用戶檢索意圖庫建設過程中,為了提高自然語言處理系統在特定領域或任務中的準確性和增強效果,同時為了解決在檢索語句中存在的歧義問題,需要根據實際需要構建自定義詞庫。如當用戶檢索“鋼鐵是怎樣煉成的”時,其本意大概率并不是想了解鋼鐵的煉制過程,而是希望檢索蘇聯作家尼古拉·奧斯特洛夫斯基所著的一部長篇小說《鋼鐵是怎樣煉成的》。因此,本文除了常用的停用詞庫之外,還構建了自定義詞庫,具體包含別稱庫、特殊名稱庫和敏感詞庫三部分,具體見表2。其中:①別稱庫是為了解決中文中經常出現的別稱、簡稱問題而建立的詞庫,目的是建立同一種實體的全稱與別稱或簡稱之間的關聯關系,這種關聯關系包括同義詞、習慣用語、多義詞等。當用戶輸入一個別稱時,系統可以將其映射到對應的實體或概念,從而擴展搜索范圍,提高搜索結果的準確性。②特殊名稱庫用于存儲特定領域中的專有名詞、實體或術語。這些包括人名、地名、組織機構名、產品名等。特殊名稱庫可以幫助系統正確識別和標注文本中的命名實體,提高命名實體識別的準確性。③敏感詞庫用于存儲敏感或不良的詞匯,如不雅詞匯、侮辱性詞匯、歧視性詞匯等。這樣的詞匯通常需要在應用中進行過濾或審查,以遵守相關規定或維護良好的用戶體驗。
3.4? 原型驗證和分析
本文以國家圖書館2022年文津搜索系統用戶檢索數據為原型,按照用戶檢索意圖庫構建思路和方法構建相應的處理流程,并以此驗證技術的可行性和流程的實用性。
數據預處理和清洗方面,本文共計采集了文津搜索系統2022年用戶檢索記錄共計1,132,340條。由于這些數據均以日志形式保存,因此在進行數據清洗時,采用了基于awk技術的處理方式對原始數據進行處理,包括去重、刪除無效或低質量數據,提取基本要素信息等,從而實現高效便捷的數據處理過程[28]。
在檢索意圖理解和識別方面,除檢索語句外,由于用戶的查詢目標即是用戶查詢意圖[29],因此本文以圖書檢索為例,從已采集的數據中分離了668,633條有效的圖書檢索記錄,并提取記錄中的關鍵信息,包括時間、用戶IP、檢索詞、檢索目標圖書的摘要信息等,作為本文驗證原型的原始數據使用。在具體操作中,由于中文切詞是中文自然語言處理工作的基礎,對于文本理解、信息提取、機器翻譯等任務具有重要作用[30],因此我們首先選取jieba工具
jieba是一個基于Python的中文分詞工具,它具有簡單易用、高效準確的特點。jieba使用了基于字典的分詞算法,可以將中文文本切分成一個個獨立的詞語。對用戶檢索信息和圖書的摘要信息進行切詞,按照詞語的劃分規則將連續的漢字序列切分成有意義的詞語單元,同時為了保證結果的簡潔性,本文只保留長度大于1的詞語單元;其次在詞性標注方面,由于中文詞語含義的復雜性,本文選取了thulac工具
thulac是由清華大學自然語言處理與社會人文計算實驗室開發的一款中文詞法分析工具,支持用戶自定義詞典,能夠高效、準確地對中文文本進行分詞、詞性標注和命名實體識別等處理。對詞性進行標注,從而實現對于中文的快速且較高速度的詞性標注[31];最后在上述工作的基礎上,根據前文制定的檢索意圖庫基本要素提取相應的關鍵詞,并計算權重,形成基于json格式表達的具有422,809條數據的用戶檢索意圖庫。其中有420,274條記錄含有主題詞,404,447條記錄含有行為意圖信息,252,188條記錄用戶情感數據,59,505條記錄含有時間數據,121,297條記錄含有地域信息,36,703條記錄含有專有名稱。
4? 應用前景
用戶檢索意圖庫的應用范圍主要集中在自然語言處理和對話系統領域,主要包括信息檢索、智能客服、問答系統、信息推薦等多個應用場景,本文以檢索意圖細化分析和意圖預測為例,探討了用戶檢索意圖庫在公共圖書館的應用。
(1)用戶檢索意圖的細化分析。在以往的研究成果中,公共圖書館領域的用戶檢索意圖往往僅集中在主題分類上,并沒有針對某個主題進行深入分析并反饋用戶可能會搜索的方面和角度。因此,本文在構建用戶檢索意圖庫的基礎上,對已有的用戶檢索記錄進行統計分類,分析同類檢索主題下不同的檢索角度和各種方面,實現對用戶檢索意圖的細化分析。以檢索詞“自然語言”為例,雖然檢索主題詞都屬于自然語言大類,但用戶意圖和搜索的角度卻有所不同。在利用用戶檢索意圖庫進行細化分析過程中,采用dbscan算法對自然語言主題的檢索數據以主題詞和行為意圖進行無監督分類,統計分析用戶檢索意圖和興趣點。
(2)用戶檢索意圖預測。在對用戶檢索意圖細化分類和分析的基礎上,利用檢索意圖庫可以展示與關鍵詞相關的常見問題、關聯詞匯、預測性搜索以及各種相關主題,幫助用戶發現與特定關鍵詞相關的問題、主題和內容,提供相應的檢索建議,形成一個類似于AnswerThePublic
AnswerThePublic 是一個與關鍵詞相關問題和內容的探索工具,它提供了廣泛的問題和關鍵詞聯想,以幫助用戶了解與特定主題相關的問題、疑慮、需求等。的檢索意圖探索工具。如當用戶輸入“自然語言”時,約有67%的用戶選擇如分詞、詞性標注文本提取等與自然語言基本處理相關的內容,19%的用戶選擇如文法分析、邏輯時態、句子依存關系等與自然語言高級處理的內容。
5? 結論與展望
隨著信息處理技術的不斷發展和公共文化服務水平的不斷提高,公共圖書館構建檢索意圖庫在信息服務和用戶體驗方面將發揮更重要的作用,未來可能會有以下發展方向。
(1)深化語義理解。當前的檢索意圖庫主要基于關鍵詞匹配和規則匹配的方式,對用戶的意圖進行簡單的識別。未來的發展方向是進一步深化語義理解,將自然語言處理和人工智能技術應用于檢索意圖庫的構建,實現對用戶意圖更準確、細致地理解和分析。
(2)跨領域知識整合。隨著知識的日益增長和學科的不斷拓展,公共圖書館需要構建一個跨領域的檢索意圖庫,以滿足用戶跨學科、綜合性的信息需求。這需要整合各個學科領域的知識資源,并建立相應的檢索意圖庫,為用戶提供全面、多樣化的信息服務。
(3)強化個性化推薦。個性化推薦是公共圖書館構建檢索意圖庫的重要應用之一。未來的發展方向是通過用戶行為分析、機器學習和推薦算法等技術手段,進一步提升個性化推薦的精度和效果,實現更精準、個性化的信息推薦服務。
(4)引入用戶反饋機制。用戶反饋是改進和優化檢索意圖庫的重要依據。未來的發展方向是引入用戶反饋機制,通過用戶評價、評論和推薦等方式,收集用戶對檢索結果和服務質量的反饋信息,不斷優化和改進檢索意圖庫的性能和準確度。
(5)融合社交媒體數據。社交媒體已成為用戶獲取信息和交流的重要渠道。未來的發展方向是融合社交媒體數據,將社交媒體平臺的數據納入檢索意圖庫的構建和分析中,以更好地理解用戶的興趣和需求,提供與社交媒體相關的信息服務。
(6)優化用戶界面和體驗。用戶界面和體驗對于公共圖書館的信息檢索服務至關重要。未來的發展方向是不斷優化用戶界面設計,提供更直觀、簡潔和易用的檢索界面,同時考慮多樣化的用戶需求和特點,提供個性化的用戶體驗。
(7)加強安全與隱私保護。隨著信息技術的快速發展,安全與隱私保護越來越受到關注。未來的發展方向是加強公共圖書館的安全防護機制,保護用戶的個人信息和隱私,建立健全的信息安全管理體系,確保用戶的信息安全和權益。
參考文獻:
[1]王錚,張珺敏,黃靜.公共型知識服務的時代使命、價值定位與完善路徑[J].文獻與數據學報,2023,5(1):16-26.
[2]田蒂.基于用戶檢索意圖的元搜索引擎研究[D].長春:吉林大學,2016.
[3]亢麗蕓,王效岳,白如江.國內語義檢索研究計量分析[J].現代情報,2012,32(5):104-109.
[4]楊宇.搜索詞的意圖分析與應用[D].北京:北京郵電大學,2010.
[5]沈思,吳璽煜.基于多標簽分類的學術文獻潛在時間意圖識別研究[J].湖南大學學報(自然科學版),2017,44(10):158-164.
[6]張曉娟.查詢意圖自動分類與分析[D].武漢:武漢大學,2014.
[7]鐘世敏.基于信息抽取的英文問句意圖分類[D].成都:西華大學,2018.
[8]孫佳寶.基于用戶意圖理解的空間關鍵字查詢研究[D].蘇州:蘇州大學,2020.
[9]楊峰宇.基于知識圖譜的用戶意圖理解研究[D].長沙:國防科學技術大學,2016.
[10]李沁桐.基于情感增強的用戶意圖理解的文本生成研究[D].濟南:山東大學,2021.
[11]許舸.基于語言模型的個性化檢索方法研究[D].武漢:華中師范大學,2018.
[12]王曉春,李生,楊沐昀,等.一種長短期興趣結合的個性化檢索模型[J].中文信息學報,2016,30(3):172-177.
[13]王威.基于上下文的個性化信息檢索技術研究[D].廈門:廈門大學,2009.
[14]溫皓琨.基于多模態查詢的圖像檢索研究:以時尚領域為例[D].濟南:山東大學,2022.
[15]張龍濤.基于社交感知的跨模態檢索研究[D].北京:北京郵電大學,2018.
[16]徐冠華,趙景秀,楊紅亞,等.文本特征提取方法研究綜述[J].軟件導刊,2018,17(5):13-18.
[17]韓旭.基于神經網絡的文本特征表示關鍵技術研究[D].北京:北京郵電大學,2019.
[18]戚越.面向自動問答的學術搜索通用查詢語言設計與實現[D].武漢:武漢大學,2020.
[19]趙京勝,宋夢雪,高祥,等.自然語言處理中的文本表示研究[J].軟件學報,2022,33(1):102-128.
[20]商憲麗,王學東.微博話題識別中基于動態共詞網絡的文本特征提取方法[J].圖書情報知識,2016(3):80-88.
[21]徐博.面向查詢理解的擴展詞排序模型研究與應用[D].大連:大連理工大學,2018.
[22]丁俊,戴岳,周佳威,等.基于實體行為間語義關聯的用戶行為意圖挖掘方法[J].計算機應用與軟件,2021,38(9):343-349.
[23]杜思佳.基于深度神經網絡的法律咨詢用戶意圖理解研究與實現[D].哈爾濱:哈爾濱工業大學,2019.
[24]孫悅民.信息分類檢索的技術演進及模式[J].情報資料工作,2009(6):49-52.
[25]顏小平,嚴長春,馬順,等.智能檢索系統中生成語義分詞的原理及調整策略[J].中國發明與專利,2022,19(9):42-51.
[26]甘麗新,萬常選,劉德喜,等.基于句法語義特征的中文實體關系抽取[J].計算機研究與發展,2016,53(2):284-302.
[27]陳博立,鮮國建,趙瑞雪,等.科技文獻問答式智能檢索總體設計與關鍵技術探析[J].中國圖書館學報,2023,49(3):92-106.
[28]姜莉.基于網絡背景流量的監控信息的模擬與分析[D].長春:吉林大學,2008.
[29]陸偉,周紅霞,張曉娟.查詢意圖研究綜述[J].中國圖書館學報,2013,39(1):100-111.
[30]黎佳.淺談中文切詞算法[J].軟件,2013,34(7):75-76,120.
[31]陶德彬.基于領域文本大數據的快速分詞系統的設計與實現[D].南京:南京大學,2019.
作者簡介:
張寧(1982— ),男,碩士,副研究館員,任職于國家圖書館。研究方向:數字圖書館、大數據分析、數據科學。
猜你喜歡
制造技術與機床(2019年10期)2019-10-26 02:48:08
電子制作(2018年18期)2018-11-14 01:48:06
小太陽畫報(2018年1期)2018-05-14 17:19:25
商用汽車(2016年11期)2016-12-19 01:20:16
少年博覽·小學低年級(2016年10期)2016-11-24 06:48:23
商用汽車(2016年6期)2016-06-29 09:18:54
商用汽車(2016年4期)2016-05-09 01:23:12
小學教學參考(2015年20期)2016-01-15 08:44:38
漫畫月刊·炫版(2015年4期)2015-05-27 07:52:10
創業家(2015年5期)2015-02-27 07:53:25
