融合RepVGG的YOLOv5交通標志識別算法
2024-05-10 03:37:36郭華玲劉佳帥鄭賓殷云華趙棣宇
科學技術與工程 2024年9期
郭華玲, 劉佳帥, 鄭賓, 殷云華, 趙棣宇
(1.中北大學電氣與控制工程學院, 太原 030051; 2.瞬態沖擊技術重點實驗室, 北京 102202)
近些年,伴隨著自動駕駛與高級駕駛輔助系統的蓬勃發展,交通場景的目標精確檢測也成為其中的重要一環。其中,交通標志作為交通運輸系統中不可或缺的組件之一,其為駕駛者或行人提供了豐富的道路狀況以及實時的交通條件,提供了利于自動駕駛的指導性或提示信息[1]。目前,交通標志的檢測算法可分為傳統的交通標志檢測算法和基于深度學習的交通標志檢測算法。傳統檢測算法的核心是特征的提取與分類。基于交通標志的色彩與形狀,結合特征提取方法對其進行提取,利用分類器來識別交通標志。孫曉艷等[2]采用自適應伽馬變換的顏色增強方式,采用最大穩定極值區域提取感興趣區域(region of interest,ROI),并基于方向梯度直方圖,利用支持向量機完成交通標志識別,提高了分類精確度,但誤檢率過高。Xiao等[3]融合定向梯度直方圖(histograms of oriented gradients,HOG)與布爾卷積神經網絡(Boolean convolutional neural network,BCNN),針對德國交通標志檢測數據庫(German traffic sign detection benchmark,GTSDB)[4]進行交通標志識別,取得了不錯的效果,但識別速度無法滿足實時需求。韓偉等[5]提出基于極坐標分區的局部二值模式特征提取法,實現交通標志的識別。傳統交通標志的檢測算法雖在不斷的改進中提升了檢測性能,但傳統交通標志檢測算法仍存在計算復雜、泛化性差、操作煩瑣等問題。
隨著圖形處理器(graphics processing unit,GPU)性能與芯片工藝的提升以及大數據的不斷發展,基于深度學習的檢測開始在目標檢測領域嶄露頭角。依照檢測步驟可將深度學習的目標檢測算法分為兩個類別,一類是以Fast-RCNN(fast regions with convolutional neural network features)[6]、Mask-RCNN(mask region-based convolutional neural network)[7]為代表的two-stage法,該類算法通常先產生候選框,隨后進行分類與定位。另一類算法則是以YOLO(you only look once)[8]與SSD(single shot multibox detector)[9]為代表的one-stage法,該類算法無需進行候選框的產生,直接進行物體類別的分類與定位。在交通標志的識別中,郭璠等[10]基于YOLOv3算法并融入通道注意力和空間注意力機制,使得小目標的檢測性能得以提升。但訓練得到的模型較大,不適合用于實際的項目中。袁小平等[11]使用多種卷積構建多尺度特征提取模塊,并設計了輕量混合注意力模塊,檢測精度得以提高,但檢測速度僅49幀/s,實時性較差。林軼等[12]將批量歸一化操作與卷積合并,同時引入空間金字塔池化模塊和CIoU(complete-IoU)損失函數,在CTSDB數據集上取得很高的檢測精度,但對于小目標的檢測效果不佳。
綜上所述,現選用檢測速度更快、檢測精度更高、模型占用內存更小的YOLOv5算法。并對其主干特征提取網絡與Neck層中的CBS模塊進行RepVGG模塊的替換,提高模型的特征提取能力的同時提高檢測精度。而后將通道注意力模塊(channel block attention module,CBAM)融合到Neck層中,提高模型對小目標的魯棒性,最后使用EIoU(efficient-IoU)損失函數來代替GIoU(generalized-IoU)損失函數,提升模型的迭代速度與檢測精度。將模型運用于CCTSDB數據集中,驗證改進算法的可行性與實用性。
1 YOLOv5結構
2015年,YOLO算法的提出將目標檢測問題劃分為了回歸問題,YOLO把圖片細劃為網格,再由網格預測檢測目標。而YOLOv2提出Darknet-19,利用錨框提高算法的召回率。2018年,YOLOv3提出Darknet-53網絡,強化其檢測速度與精度。到了2020年,Bochkovskiy等[13]在YOLOv3的基礎上,融合多通道網絡(cross-stage partial network,CSPNet)與Darknet-53作為主干特征提取網絡,在主干網絡末端添加金字塔空間池化結構(spatial pyramid pooling,SPP)來擴大模型的感受野并結合路徑聚合網絡(path aggregation network,PANet)形成YOLOv4網絡。CSPNet可以實現多樣的梯度組合,而SPP模塊通過4種池化核對特征圖進行處理實現更好的特征提取效果。
圖1為YOLOv5的結構圖。YOLOv5相較于YOLOv4,除了繼續在主干網絡中沿用C3結構,也在Neck層中添加了C3結構,增強了網絡的特征融合能力。

h×w×c表示模塊右側數字為對應特征圖的尺寸參數,h、w、c分別對應特征圖的高度(high)、寬度(weight)和通道數(channel);k(kernel)為卷積核的尺寸;s(stride)為卷積步幅;p(padding)為填充像素行/列數圖1 YOLOv5網絡結構Fig.1 YOLOv5 network architecture
綜上所述,得益于YOLOv5模型小、訓練時間短、推理速度快、更易部署等特點,YOLOv5更加適用于自動駕駛中的交通標志識別。
2 改進YOLOv5算法
2.1 RepVGG模塊
RepVGG[14]在VGG網絡中引入identity殘差分支,利用結構重參數化實現模型在訓練階段與推理階段的解耦。
RepVGG的訓練模塊如圖2(a)所示,由3×3卷積、1×1卷積、殘差結構構成多分支網絡。引入的殘差結構,可以有效針對梯度消失的情況,促使模型更快收斂。

圖2 RepVGG訓練模型和推理模型結構Fig.2 RepVGG training model and inference model structure
推理模塊如圖2(b)所示,由3×3卷積和激活函數ReLU組成的類VGG結構,因結構簡單,能夠極大加速模型的推理。RepVGG采用重參數化將訓練模型轉化為推理模型,融合CONV與BN層,將處理后的卷積層都轉換成為3×3卷積,最后合并分支中的3×3卷積,疊加所有分支的權重W和偏置b,從而得到最終的3×3卷積進行推理。為了滿足交通標志檢測模型精度高、速度快的需求,引入RepVGG模塊,提高主干網絡的特征提取能力,減少特征信息丟失,在提高網絡特征取能力的同時兼顧速度。
2.2 CBAM注意力模塊
注意力機制可以幫助卷積神經網絡將特征的權重從特征圖中提取出來,再將權重進行重分配從而抑制無效特征增強有效特征,使得網絡能夠更好地關注到圖像中的重點區域。
如圖3所示,CBAM包括通道注意力模塊(channel attention module,CAM)與空間注意力模塊(spatial attention module,SAM)兩部分,特征圖經由通道注意力模塊,消除空間維度的影響,使網絡更專注于關鍵特征,再經由空間注意力模塊,使網絡學習到關鍵特征的具體位置。

圖3 CBAM注意力機制Fig.3 CBAM attention mechanism
在CAM中,先對輸入特征圖進行平均池化和最大池化,消除空間維度的影響,得到兩個一維特征。再將兩個一維特征輸入到兩層共享神經網絡中,神經元個數分別為c/r和c。然后,將各元素進行相加合并,并通過Sigmoid激活函數進行非線性處理,生成通道注意力特征Mc(F)∈Rc×1×1。最后通過通道注意力特征Mc(F)和輸入特征圖F進行元素相乘的方式,重新分配通道權重,得到新的通道特征圖F′。通道關注度Mc(F)∈Rc×1×1的計算公式為
Mc(F)=σ{MLP[AvgPool(F)]+
MLP[MaxPool(F)]}

(1)
式(1)中:σ為Sigmoid函數。
空間注意力模塊將通道特征圖F′作為輸入,為了加強對待檢測目標的關鍵區域的關注,依次對通道特征圖F′進行基于通道的全局最大池化和全局平均池化,從而得到兩個特征圖。再合并兩個特征圖的通道數,獲得尺寸為2×h×w的空間特征圖。之后利用7×7的卷積核與Sigmoid函數對其進行卷積與非線性處理,得到特征圖的空間關注度Ms(F)∈RH×W,最后將經由通道注意力模塊所得的特征圖F′與空間注意度Ms(F)∈RH×W逐元素相乘得到最終特征圖F″。此時網絡不僅學習到了該特征包含什么關鍵特征,還學習到了關鍵特征所在位置。空間關注度Ms(F)∈RH×W的計算公式為
Ms(F)=σ(f7×7{[AvgPool(F);MaxPool(F)]})

(2)
式(2)中:f7×7為7×7的卷積核。
2.3 損失函數的改進
選擇合適的損失函數有利于獲得針對該數據集表現優異的模型,并且在訓練過程中達到更快收斂[15]。
YOLOv5使用GIoU損失函數,引入預測框與真實框的最小外接矩形。GIoU損失函數為
(3)
式(3)中:A為預測框的面積;B為真實框的面積;C為A,B的最小外接矩形的面積。引入最小外接矩形,即使A,B不相交仍可以實現梯度下降。但其也存在一定的缺陷。如圖4所示,當A,B為包含狀態時,此時GIoU損失函數便無法確定兩個框的位置關系。
圖4 預測框與真實框互為包含Fig.4 The prediction box and the real box are mutually inclusive
為了解決這一問題,CIoU[16]損失函數通過增加多種判別因素,使真實框的擬合更加趨向平穩。為CIoU損失函數表達式為
(4)
式(4)中:ρ2(A,B)為預測框與真實框中心的歐式距離;c為兩框的最小閉包區域的對角線長度;α為平衡比例的參數;v用于判斷預測框與真實框的長寬比統一性;Aw、Ah、Bw、Bh為預測框與真實框的寬高。但CIoU損失函數未考慮長寬邊長真實差,縱橫比描述的是相對值,存在一定的模糊。
故采用EIoU[17]損失函數來替代CIoU損失函數。EIoU損失函數表達式為


(5)
式(5)中:b和bgt為預測框與真實框的中心點;ρ為兩點的歐式距離;d為兩框的最小外接矩形的對角線長;ω、ωgt、h、hgt分別為預測框與真實框的寬度與長度;cω、ch分別為覆蓋兩個框的最小外接矩形的寬度和長度。
EIoU損失函數不僅考慮了預測框與真實框的重疊面積、中心點距離以及長寬邊長真實差,相較于CIoU損失函數還對縱橫比的模糊定義提出了解決方法,能有效幫助模型更好地收斂,從而獲得更加出色的模型。
2.4 改進YOLOv5的結構
改進后的YOLOv5結構如圖5所示,將主干特征提取網絡中的CBS模塊替換為RepVGG模塊,加強主干網絡的特征提取能力。在Neck層將CBS模塊替換為RepVGG模塊,并在圖像特征提取前融合CBAM注意力機制,提升網絡對于特定目標區域的感知能力,從而實現更高的目標檢測精度。最后在網絡訓練過程中使用EIoU損失函數,通過引入目標框長度、寬度,解決了GIoU、CIoU損失函數在水平和垂直方向上誤差較大的問題。

圖5 改進YOLOv5網絡結構Fig.5 Improving YOLOv5 network structure
3 實驗及結果分析
3.1 數據集準備
數據集采用由長沙理工大學制作的CCTSDB[18]交通標志數據集,其為當前中國交通標志公認的數據集之一。從中選取10 000張圖片,該數據集標注的數據共分為指示、禁止、警告3種類型。將標注信息通過程序轉換為TXT格式,按照9∶1的比例將數據劃分為訓練集與測試集。訓練時,采用Mosaic數據增強,將4張圖片拼接為一張圖像,加強圖像的多樣性,降低GPU資源的消耗。
3.2 訓練環境與評測標準
實驗在Windows 10系統下進行,實驗設備為Intel i7CPU,顯卡為GTX3090,24 G顯存。使用Pytorch1.12,CUDA版本為11.3,使用Python語言進行代碼編寫。
目標檢測的重要性能評價指標為準確率(precision,P)、平均準確率(mean average precision,mAP)、召回率(recall,R),公式如下。
(6)
(7)
(8)
式中:TP為真正例,即樣本自身的真實標簽為A,而預測的標簽也為A;FP為假正例,即樣本自身的真實標簽為B,但預測的標簽卻為A;FN為假負例,即樣本本身的真實標簽為A,但預測的標簽為B;AP為所有類別的平均準確率均值;N為類別數。
3.3 實驗結果與分析
選擇部分從校園以及街道所采集到的圖像對改進算法與YOLOv5算法進行對比測試。圖6所示為改進算法與原算法的檢測結果對比。
由圖6可知,原始YOLOv5在照片相對比較模糊且交通標志比較小的情況下會出現檢測缺失,第二張圖無法檢測出禁止標志的現象。而改進算法針對第一張圖像的交通標志檢測置信度更高,且成功識別第二張模糊圖像中的小目標。
圖7所示為改進算法與YOLOv5、YOLOv4的評測標準對比,可以看出,在訓練初期改進算法與YOLOv5算法相較于YOLOv4來講收斂更快,而在迭代10次以后,可以明顯看到改進算法在各項指標都超越了另外兩種算法,在迭代39次時基本各項數據達到最優,后續的迭代評價指標也基本維持在最優值僅有小幅度波動。

圖7 評測標準對比Fig.7 Comparison of evaluation standards
各算法的最優性能指標如表1所示。可以看到,改進的算法相比較于原始YOLOv5在準確率上提高了4.99%,達到91.55%,召回率提高了3.62%達到85.04%。mAP提高了1.73%,達到了91.71%。
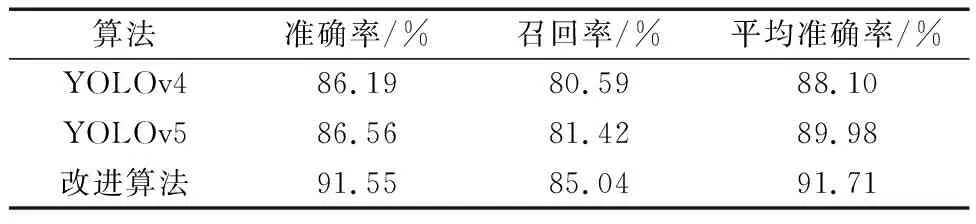
表1 改進算法與其他算法的性能對比Table 1 Comparison of performance between improved algorithms and other algorithms
4 結論
針對傳統交通標志檢測算法所存在的精度較低的問題,提出一種融合RepVGG的改進YOLOv5算法。通過更替主干特征提取網絡中CBS模塊為RepVGG模塊,在Neck層融合CBAM注意力機制、RepVGG模塊。改進后的YOLOv5得益于重參數化后的RepVGG模塊,算法在CCTSDB數據集的檢測精度、檢測速度得以優化,適宜應用在實踐中。所以改進算法在自動駕駛交通標志識別方面有著較高的應用價值。但CCTSDB的交通標志類型過少,面對復雜多樣的交通路況與標志并不能精確檢測其具體含義,接下來會使用分類更為多樣與精確的TT100K數據集來對算法進行驗證,實現更加有指導意義的交通標志檢測。
猜你喜歡
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
電子制作(2019年15期)2019-08-27 01:12:00
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
中國生物醫學工程學報(2017年6期)2017-02-10 05:11:45
海峽科技與產業(2016年3期)2016-05-17 04:32:12
噪聲與振動控制(2015年4期)2015-01-01 07:08:21
