基于優(yōu)先度函數的概率不確定語言術語集雙邊匹配方法
2024-04-11 12:54:08白曉莉陳巖鄧珍美
商丘師范學院學報 2024年3期
白曉莉,陳巖,2,鄧珍美
(1.沈陽工業(yè)大學 理學院,遼寧 沈陽 110870;2.沈陽工業(yè)大學 管理學院,遼寧 沈陽 110870)
雙邊匹配研究可以追溯于Gale和Shapley[1]在關于婚姻匹配問題中的研究,研究中論證了雙邊穩(wěn)定匹配的存在性以及最優(yōu)性,并提出了著名的Gale-Shapley算法.自此之后,雙邊匹配問題的研究不斷涌現于各個領域.例如,崗位與求職者匹配問題[2]、風險投資企業(yè)匹配問題[3]、醫(yī)生與患者匹配問題[4]、物流服務供應方與需求方匹配問題[5]等.隨著社會的發(fā)展,匹配問題背景愈加復雜,由于評價主體受專業(yè)知識限制,評價信息通常具有不確定性.不確定信息下的雙邊匹配問題是目前研究的熱點,在不確定形式下,主體無法使用比較精確的數值進行評價,為了這一問題得到解決,學者們將直覺模糊、猶豫模糊[6]、區(qū)間猶豫模糊[8]、區(qū)間直覺模糊[9]、三角模糊[10]等方法引入雙邊匹配問題中,并應用于各個領域.但在模糊環(huán)境下進行評價,就意味著主體所提供的語言術語集的重要程度是一致的.實際并非如此,主體給出的語言術語集中的語言術語不一定是等概率的.在2016年,Pang[11]等學者們對猶豫模糊語言術語集中的每一個語言項都賦予了概率,定義了概率語言術語集(PLTS).因此,學者們開始對概率語言環(huán)境下雙邊匹配問題進行研究.Li等提出了一種在概率語言環(huán)境下,基于前景理論的屬性權重未知的雙邊匹配方法.Li等[13]提出了基于概率語言偏好關系的雙邊匹配方法,其中給出了時間滿意度的定義,并構建模型來處理概率語言偏好關系.Li等[14]學者提出了一種在概率語言術語集下,考慮最低可接受值的基于后悔理論雙邊匹配決策方法.汪新凡等針對概率猶豫模糊信息下準則具有期望水平的雙邊匹配問題,提出了一種考慮匹配主體心理行為的雙邊匹配方法.之后就有一些學者提出匹配主體可能更傾向用類似于[好,非常好]這種語言評價區(qū)間的形式來表達偏好信息,基于Xu[11]在2004年提出了不確定語言變量(ULV)的概念后,在2017年,由Lin等[17]提出了概率不確定語言術語集(PULTS)的概念.概率不確定語言術語集體現不確定語言術語集的概率特征,是概率語言術語集與不確定語言術語的擴展形式.但從目前來看,將概率不確定語言術語集應用于雙邊匹配問題中的研究鮮有涉足,并且已有研究大多以設立參照點獲得主體相對優(yōu)勢,這會導致匹配主體評價信息的偏差,從而影響匹配結果.其次,為獲得符合匹配主體偏好的匹配方案,匹配主體在匹配過程中的心理行為也應當充分考慮.
因此,本文對于概率不確定語言環(huán)境下的雙邊匹配問題進行了研究,并且考慮了主體的心理行為.首先,給出了概率不確定語言術語集區(qū)間型得分的定義,進而根據可能度公式計算概率不確定語言術語集間的可能度,比較概率不確定語言術語集的優(yōu)劣程度;其次構造出優(yōu)先度函數來反映匹配主體心理行為;然后,利用新的滿意度公式構建滿意度矩陣,建立雙邊匹配滿意度最大化模型,通過求解模型,獲得最優(yōu)匹配方案;最后,進行算例分析,并與現有雙邊匹配方法進行比較,證明了所提出方法的優(yōu)點.
1 基礎知識
1.1 不確定語言變量
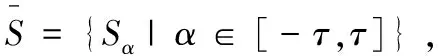
1.2 概率不確定語言術語集(PULTS)相關概念
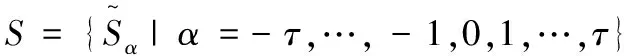
其中〈[Lk,Uk],pk〉表示不確定語言術語,且[Lk,Uk]的概率為pk,Lk和Uk是語言術語,滿足Lk≤Uk,#S(p)是S(p)的基數.
Lin[17]等學者給出了概率不確定語言術語集標準化的方法:
(1)S(p)為任一概率不確定語言術語集,則已標準化的概率不確定語言術語集Sn(p)為
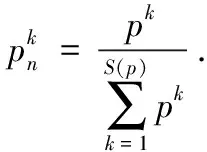
(2)如果#S1(p)<#S2(p),則給S1(p)增加具有概率為0的最小不確定語言變量#S2(p)-#S1(p)個,這樣使得兩個概率不確定語言術語集的基數相等.
定義3 設兩個標準化概率不確定語言術語集為
那么它們的運算法則為
(3)λS(p)=∪〈[Lk,Uk],pk〉∈S(p){λpk[Lk,Uk]};
(4)(S(p))λ=∪〈[Lk,Uk],pk〉∈S(p){[Lk,Uk]λpk}.
其中λ≥0.
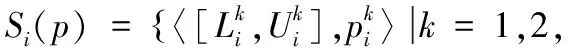
=
為概率不確定語言術語集平均算子(PULA).
1.3 雙邊匹配
設雙邊匹配主體集合分別為A={A1,A2,…,Am},B={B1,B2,…,Bn},其中,Ai表示A中的第i個主體,i∈M,M={1,2,…,m}.Bj表示B中的第j個主體j∈N,N={1,2,…,n}.一般地,m≥n.
定義5 設一一映射μ:A∪B→A∪B,若?Ai∈A,?Bj∈B,滿足:
(1)μ(Ai)∈B;
(2)μ(Bj)∈A∪{Bj};
(3)μ(Ai)=Bj當且僅當μ(Bj)=Ai.
則稱μ為雙邊匹配.其中μ(Ai)=Bj或μ(Bj)=Ai,表示Ai與Bj在μ中匹配,記為(Ai,Bj);μ(Bj)=Bj表示Bj在μ中未匹配,記為(Bj,Bj).
2 優(yōu)先度函數
2.1 可能度

定義6 對于任意的概率不確定語言術語集S(p)={〈[Lk,Uk],pk〉|pk≥0,k=1,2,…,#S(p)},稱
為概率不確定語言術語集的區(qū)間型得分.
定義7 概率不確定語言術語集間的可能度定義為:
(1)
①若0.5<ρ(S1(p1)≥S2(p2))≤1時,則S1(p1)優(yōu)于S2(p2),記為S1(p1)?S2(p2);②若ρ(S1(p1)≥S2(p2))=0.5時,則S1(p1)和S2(p2)無差異,記為S1(p1)~S2(p2);③若0≤ρ(S1(p1)≥S2(p2))<0.5時,則S1(p1)劣于S2(p2),記為S1(p1)S2(p2).
顯然,通過此公式,不僅能夠反映出概率不確定語言術語集間“期望”的差異,還可以反映它們之間“方差”的差異;其次,此公式無需借助像 Lin等學者提出的雙層比較的方式,就可以進行概率不確定語言術語集間的優(yōu)劣比較,并能度量出兩個概率不確定語言術語集間的優(yōu)劣程度.
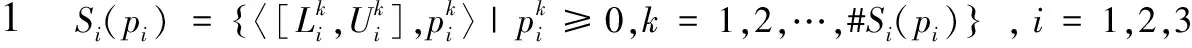
(1)有界性:0≤ρ(S1(p1)≥S2(p2))≤1;
(2)互補性:ρ(S1(p1)≥S2(p2))+ρ(S2(p2)≥S1(p1))=1;
(3)自反性:當S1(p1)=S2(p2)時,ρ(S1(p1)≥S2(p2))=0.5;
(4)傳遞性:ρ(S1(p1)≥S2(p2))≥0.5,ρ(S2(p2)≥S3(p3))≥0.5,則ρ(S1(p1)≥S3(p3))≥0.5.
證明
(1)由定義7可知,可能度滿足0≤ρ(S1(p1)≥S2(p2))≤1.
(2)分兩種情況討論,第一種情況,當SL1≥SU2時,ρ(S1(p1)≥S2(p2))=1,而ρ(S2(p2)≥S1(p1))=0,滿足ρ(S1(p1)≥S2(p2))+ρ(S2(p2)≥S1(p1))=1;
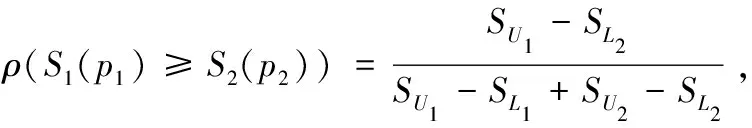
(3)根據公式(1),當S1(p1)=S2(p2)時,SL1=SL2,SU1=SU2,因此,ρ(S1(p1)≥S2(p2))=0.5.
(4)ρ(S1(p1)≥S2(p2))≥0.5,ρ(S2(p2)≥S3(p3))≥0.5時,
可以推導出SU1-SL2≥SU2-SL1,SU2-SL3≥SU3-SL2,接著推導出,SU1-SL3≥SU3-SL1,再由公式
因此,ρ(S1(p1)≥S3(p3))≥0.5.
2.2 優(yōu)先度
定義8 設任意兩個已標準化的概率不確定語言術語集為

(2)
其中0≤ρ≤1.
進一步說明,當ρ∈[0,0.5)時,S1(p1)S2(p2),此時ρ*<0;當ρ=0.5時,S1(p1)和S2(p2)無差異,ρ*=0;
當ρ∈(0.5,1]時,S1(p1)?S2(p2),此時ρ*>0.
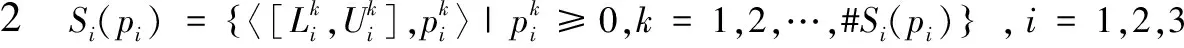
(1)-0.5<ρ*(S1(p1)≥S2(p2))<0.5;
(2)互補性:ρ*(S1(p1)≥S2(p2))+ρ*(S2(p2)≥S1(p1))=0;
(3)自反性:當S1(p1)=S2(p2)時,ρ*(S1(p1)≥S2(p2))=0;
(4)傳遞性:ρ*(S1(p1)≥S2(p2))≥0,ρ*(S2(p2)≥S3(p3))≥0,則ρ*(S1(p1)≥S3(p3))≥0.
由定理1及證明和公式(2),可證明優(yōu)先度函數具有以上性質.
2.3 距離測度
為了避免匹配主體評價信息中偏倚數據的影響,根據區(qū)間型得分,定義了兩個概率不確定語言術語集間的距離測度.
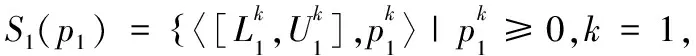
(3)
定理3 給定概率不確定語言術語集S1(p1),S2(p2),S3(p3),則式(3)滿足:
(1)d(S1(p1),S2(p2))≥0;
(2)d(S1(p1),S2(p2))=d(S2(p2),S1(p1));
(3)d(S1(p1),S2(p2))+d(S2(p2),S3(p3))≥d(S1(p1),S3(p3)).
注:d(S1(p1),S2(p2))=0當且僅當S1(p1)與S2(p2)相等.
3 基于優(yōu)先度函數的雙邊匹配模型與方法
3.1 雙邊匹配問題描述
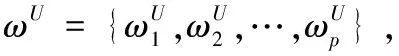
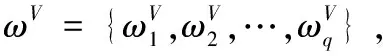
3.2 滿意度計算
雙邊匹配的目標是使得雙邊匹配主體滿意度最大,由式(2)、式(3)概率不確定語言術語集的優(yōu)先度函數以及距離測度,在此定義雙邊匹配主體的滿意度.
定義10 設SdAi→Bj是在屬性Up下,匹配主體Ai對匹配主體Bj的滿意度,其計算公式為
(4)
定義11 設SdBj→Ai是在屬性Vq下,匹配主體Bj對匹配主體Ai的滿意度,其計算公式為
(5)
那么,匹配主體Ai對于Bj的綜合滿意度以及匹配主體Bj對于Ai的綜合滿意度分別為
(6)
(7)
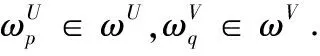
3.3 雙邊匹配模型
基于以上匹配雙方滿意度矩陣的計算,建立了匹配雙方滿意度最大化目標雙邊匹配模型P1如下:
(8)
(9)
(10)
(11)
其中,xij為0-1變量,xij等于1時,說明Ai與Bj匹配,xij等于0時,說明Ai與Bj不匹配.式(8)是表示匹配主體A的最大化滿意度,式(9)是表示匹配主體B的最大化滿意度,式(10)表示任一匹配主體A只能與一主體B匹配或不匹配,式(11)表示任一匹配主體B與一匹配主體A匹配.
由于匹配雙方的目標函數是等級的,因此,通過線性加權法可將多目標模型P1轉化為單目標模型P2,分別加權α和β(0≤α,β≤1,α+β=1).則P2為:
3.4 雙邊匹配方法步驟
基于概率不確定語言術語集下考慮心理行為的雙邊匹配問題,提出了優(yōu)先度函數和距離測度,用于構造滿意度矩陣,進而建立雙邊匹配模型,具體步驟如下:
Step 2 對評價信息進行標準化處理,并集結屬性準則下的評價信息.
Step 3 將已標準化的評價信息,根據定義6和式(1)-(5)求得SdAi→Bj和SdBj→Ai.
Step 4 利用式(6)、(7)得到滿意度aij和bij,進而構造滿意度矩陣A=[aij]m×n和B=[bij]m×n.
Step 5 構建多目標模型P1,并將其轉化為單目標模型P2.
Step 6 用Kuhn-Munkras算法求解模型P2,得到最優(yōu)匹配方案.
4 算例分析
4.1 問題描述
某工業(yè)園有3家新進企業(yè)需要實施倉儲管理系統(tǒng)(WMS),通過服務中介機構投放廣告等相關信息,有4家軟件供應商有合作意向,記為Ai(i=1,2,3,4),這3家軟件需求企業(yè)記為Bj(j=1,2,3),軟件供應商Ai對軟件需求企業(yè)Bj評價的參考屬性為U1(系統(tǒng)實現的收益)、U2(企業(yè)規(guī)模)、U3(發(fā)展前景),加權向量為
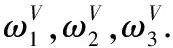
S={s-3:非常差,s-2:較差,s-1:差,s0:中等,s1:好,s2:很好,s3:非常好}.
4.2 求解過程
Step 1獲得評價信息.

表1 在屬性U1下的評價信息矩陣

表2 在屬性U2下的評價信息矩陣

表3 在屬性U3下的評價信息矩陣

表4 在屬性V1下的評價信息矩陣

表5 在屬性V2下的評價信息矩陣

表6 在屬性V3下的評價信息矩陣
Step 2根據式(1)-(5)分別求得滿意度SdAi→Bj和SdBj→Ai,如下表7、8所示:

表7 Ai對Bj滿意度矩陣

表8 Bj對Ai滿意度矩陣
Step 3 利用式(6)、(7)獲得滿意度aij和bij,進而構造滿意度矩陣A=[aij]4×3和B=[bij]4×3.
Step 4 構建多目標模型P1,令α=β=0.5,將多目標模型P1轉化為模型P2.
Step 5 將綜合滿意度作為二分圖匹配中的權值,用Kuhn-Munkras算法求解模型P2,獲得雙邊匹配矩陣為
所以最優(yōu)匹配方案為{(B1,A2),(B2,A3),(B3,A4)}.
4.3 比較分析
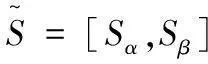

表9 不同匹配方法的對比
表9顯示,這4種不同的匹配方法所對應的匹配方案存在差異,進一步分析存在差異的原因:
文獻[12]、文獻[19]中均應用前景理論來考慮匹配主體心理行為,但前景理論需要考慮雙邊匹配主體的損失規(guī)避系數、風險厭惡系數和風險偏好系數,參數較多,計算較冗雜,本文的優(yōu)先度不需要考慮參數的設置,計算較簡潔;文獻[14]中通過概率語言術語集期望值與匹配主體評價值的方式來獲得滿意度會導致綜合滿意度偏高或偏低,從而影響匹配結果.
文獻[14]的雙邊匹配方案與本文的方案不完全一致,造成這種差異的主要原因:一方面在于文獻[14]構建基于期望值的滿意度函數,建立了基于后悔理論的雙邊匹配模型,這樣應用期望值會導致評價信息的失真,后悔理論也僅反映了匹配主體的后悔心理;另一方面在于文獻[14]考慮了最低可接受度,但最低可接受度是假設的虛擬值,選取不同可能會對匹配結果有影響.本文應用優(yōu)先度與距離測量來獲得滿意度,可以避免信息的失真,從而確保匹配結果更合理,更準確.并且參照點設置為評價信息的綜合平均值而不是虛擬值,這樣不但可以集中于原始評價信息,而且使計算更簡化,本文中提出的優(yōu)先度函數不同于后悔理論,它能更靈活的反映匹配主體的趨優(yōu)性、規(guī)避劣性的心理行為.
5 結 論
針對概率不確定語言環(huán)境下的雙邊匹配問題,考慮雙邊主體趨優(yōu)性的心理行為特征,提出了一種基于優(yōu)先度函數的雙邊匹配方法.(1)定義概率不確定語言術語集區(qū)間型得分,給出可能度公式,以此把定性信息轉化為定量分析,使得匹配結果更符合匹配雙方主體的預期.(2)定義的優(yōu)先度函數和距離測度為處理概率不確定語言環(huán)境下的雙邊匹配問題提供了一種有力工具,有效避免了目前研究中直接應用期望值或評分值的方式來獲得滿意度所導致的信息失真.(3)定義的優(yōu)先度函數可以反映主體趨優(yōu)性和規(guī)避劣性的心理行為且不需要考慮參數的設置,計算較簡潔.
猜你喜歡
工會博覽(2023年3期)2023-04-06 15:52:34
南大法學(2021年3期)2021-08-13 09:22:32
小康(2021年7期)2021-03-15 05:29:03
活力(2019年19期)2020-01-06 07:34:38
雜文月刊(2019年15期)2019-09-26 00:53:54
自然與文化遺產研究(2016年2期)2016-05-17 05:53:59
山東青年(2016年1期)2016-02-28 14:25:25
山西大同大學學報(社會科學版)(2015年6期)2015-01-22 07:22:22
當代修辭學(2014年3期)2014-01-21 02:30:44
公務員文萃(2013年5期)2013-03-11 16:08:37
