基于二次模態分解的LSTM短期電力負荷預測
2024-04-01 07:48:44張淑嫻江文韜陳玉花楊曉東金豐白莉
科學技術與工程 2024年7期
張淑嫻, 江文韜, 陳玉花, 楊曉東*, 金豐, 白莉
(1.國家電網有限公司大數據中心, 北京 100052; 2.合肥工業大學電氣與自動化工程學院, 合肥 230009)
隨著分布式能源的大規模接入,其隨機性、分散性等特點使得配電網從結構和形態上發生了本質變化[1]。配電網的負荷預測與運行控制變得越來越復雜,對開發配電網分布式發電與負荷的精準預測技術提出了很高的要求。精準的短期電力負荷預測可為電網優化調度及控制提供相關參考,對節能減排和分布式能源消納具有重要意義[2-3]。
短期電力負荷預測的方法主要有3種,第一種是傳統的統計分析方法,第二種是機器學習算法,第三種是深度學習算法。傳統的統計分析方法有指數平滑法、卡爾曼濾波法等。文獻[4]采用指數平滑法進行電力負荷預測,同時引入了等維新息數據處理的思想,不斷更新歷史數據,使預測結果包含負荷發展規律的深層信息,提高了預測精度。文獻[5]對節假日負荷特性進行分析,針對不同類型的節假日建立卡爾曼濾波預測模型,并對多種環境影響因素下的負荷變化進行預測,所得結果對節假日負荷預測提供了一定的參考價值。由于時間,地域,用電習慣等存在極大的差異性,再加上日漸普及的分布式發電對于負荷的影響,使得傳統的統計分析方法已難以跟上其日漸增長的分析維度。傳統機器學習方法主要包含隨機森林、支持向量機法、極端梯度提升(extreme gradient boosting, XGboost)等[6]。文獻[7]引入C均值模糊聚類算法,將聚類后的同組分量作為決策樹,同時引入粗糙集理論校正負荷預測結果,可對預測精度有效提升;文獻[8]采用粒子群算法對支持向量機相關參數進行優化,提高了模型預測精度與訓練速度。文獻[9]針對模糊C均值聚類不能自適應選擇聚類數問題,使用均值漂移對聚類數進行尋優,同時結合自適應噪聲的完全集合經驗模態分解(complete ensemble empirical mode decomposition with adaptive noise, CEEMDAN)分解與XGboost的組合模型,降低了負荷不穩定因素對預測精度的影響。上述預測模型的優點是能夠學習樣本數據中的非線性關系,但模型容易出現過擬合現象,且對參數的選擇比較敏感[10-12]。機器學習中的深度學習方法如循環神經網絡(recurrent neural network, RNN)、長短期記憶神經網絡(long short-term memory network, LSTM)等人工神經網絡由于其本身模型的非線性,具有強大的自適應學習能力和一定的抗干擾能力,目前已成為電力負荷預測領域中的主流方法[13]。
由于收集到的負荷數據具有豐富的隱藏信息,往往需要更深層次的挖掘其中的非線性關系。于是在機器學習中引入信號分解技術來發掘負荷數據中的非線性關系。常見的分解方法有經驗模態分解,變分模態分解等[14-16]。經驗模態分解克服了小波變換中基函數無自適應性的問題,但分解后的分量存在模態混疊問題[17-18]。變分模態分解通過構造并求解約束變分問題,自適應地將原始信號的分解為不同中心頻率有限帶寬的平穩信號,具有對復雜數據有著良好的分解能力以及對采樣噪聲有著更強的魯棒性等優點,但是模態分解個數和懲罰因子需要人為選取,對分解結果產生較大影響[19-21]。
CEEMDAN是經驗模態分解的主要方法之一。CEEMDAN分解會產生強非平穩分量,將對后續預測步驟產生不利影響,進而影響最終的預測結果[22]。VMD分解會產生重構誤差,分解分量重構不完全與原序列等同,同時分解個數和懲罰因子對分解結果影響較大[23]。因此現將CEEMDAN和VMD結合,提出一種基于二次模態分解的LSTM電力負荷短期預測方法。首先將原始負荷序列進行CEEMDAN分解,將原始負荷序列分解為多個內涵模態分量(intrinsic mode functions, IMF)和殘差分量,再對CEEMDAN分解后的強平穩分量進行VMD二次分解,將其分解為多個平穩分量。然后將這些分量分別送入LSTM網絡中進行預測,得出每個分量的預測結果。最后將每個分量的預測結果進行線性重構,得到最終的負荷預測結果。將本文所提方法應用于某地的真實負荷數據的預測中,證明所提方法對預測精度具有一定的提升效果。
1 二次模態分解介紹
1.1 CEEMDAN原理
CEEMDAN在集合經驗模態分解(ensemble empirical mode decomposition, EEMD)方法的基礎上改進而來,能夠有效解決模態混疊現象,主要是在進行經驗模態分解(empirical mode decomposition, EMD)后取一階分量,然后進行平均值運算。該方法能夠有效降低篩選次數,也能避免產生幅值很小的低頻分量,且分解分量重構誤差幾乎為零。CEEMDAN的具體步驟如下。
(1)將原始序列x(t)中添加I對符號相反的白噪聲序列,得到I次待分解序列,即
xi(t)=x(t)+εδi(t),i∈{1,2,…,I}
(1)
式(1)中:t代表時刻;xi(t)為第i次加入正負白噪聲后的新序列;ε為白噪聲的幅值系數;δi(t)為第i次添加的標準白噪聲序列。
(2)對添加白噪聲后的序列進行EMD,并且取每次添加白噪聲后的原始序列分解后得到的一階內涵模態分量(intrinsic mode functions, IMF)IMF1(t)以及殘余分量r1(t)。
(2)
r1(t)=x(t)-IMF1(t)
(3)
式中:IMF1(t)為CEEMDAN分解所產生的第一個分量,即一階固有模態分量;r1(t)為殘余分量。
(3)將所得到的一階分量r1(t)再添加白噪聲序列進行EMD分解,取分解得到的第一個分量再取均值得到IMF2(t),再由r1(t)減去IMF2(t)得到r2(t)。即
(4)
式(4)中:E1為一階固有模態分量算子。
(4)重復上述步驟,得到k+1階的分量和殘差。
rk(t)=rk-1(t)-IMFk(t),k=2,3,…,K
(5)
(5)如果滿足EMD的停止條件,即第n次分解的殘差信號單調,則迭代過程終止,同時CEEMDAN算法分解過程完成。
1.2 VMD原理
VMD是一種自適應、完全非遞歸的模態變分和信號處理的方法。該方法通過確定模態分解的個數以構造變分約束問題,并且不斷對每種模態的最佳中心頻率和有限帶寬進行尋優,實現IMF分量的有效分離、信號的頻域劃分,進而得到給定信號的有效分解成分,同時獲得變分問題的最優解。VMD的基本步驟如下。
(1)構造變分約束問題。變分約束表達式為
(6)
式(6)中:{u1,u2,…,uK}為模態分量集合;{ω1,ω2,…,ωK}為中心頻率集合;δ(t)為狄拉克(Dirac)分布。
(2)引入拉格朗日算子和懲罰因子將變分約束問題轉化為無約束問題,即
(7)
式(7)中:λ為拉格朗日乘法算子;α為懲罰因子;〈·〉為求內積;f(t)為待分解序列。
(3)利用交替乘法算子尋優,不斷更新模態分量和中心頻率集合,最終獲取各個不同中心頻率的分量。
運用CEEMDAN對負荷序列分解后將產生平穩分量和強非平穩分量,強非平穩分量中包含了原始負荷信息中的波動成分,因而難以預測。所以提出對強非平穩分量進行VMD二次分解,將平穩后的分量用于后續的預測中。
2 LSTM神經網絡模型
LSTM是一種在循環神經網絡的基礎上改進而來的網絡,解決了RNN在反向傳播時的梯度消失問題,通過引入“門”的作用機制來調節信息流,對傳輸的信息進行保留和刪除[24]。LSTM由三個門來控制細胞狀態,分別是遺忘門、輸出門和輸入門。其基本結構如圖1所示。
LSTM輸入有三個,分別為細胞狀態Ct-1、隱層狀態ht-1、t時刻輸入量xt;輸出有兩個,為細胞狀態Ct和隱層狀態ht。
遺忘門的公式為
ft=σ(Wf[ht-1,xt]+bf)
(8)
式(8)中:ft為遺忘門t時刻的輸出;σ為sigmoid的激活函數;Wf為對應遺忘門的權重矩陣;xt為t時刻輸入量;bf為遺忘門的偏置量。
輸入門的公式為
it=σ(Wi[ht-1,xt]+bi)
(9)
(10)
(11)

輸出門的公式為
ot=σ(Wo[ht-1,xt]+bo)
(12)
ht=ottanh(Ct)
(13)
式中:ot為t時刻輸出門的輸出信號;ht為當前時刻的隱藏單元狀態;Wo為輸出門的權重矩陣;bo為輸出門的偏置量。
LSTM通過忘記階段、記憶階段、輸出階段,不斷更新細胞狀態,保留之前有用的信息,舍棄掉無用信息,其基本步驟如下。
(1)由t時刻的輸入變量xt和t-1時刻的特征變量ht-1,通過計算得出三個門的各特征變量、輸出變量Ct。
(2)通過遺忘門和輸入門來更新細胞狀態。
(3)通過輸出門將隱藏層信息傳遞給外部狀態ht。
3 負荷預測模型
3.1 負荷預測模型總體框架
本文提出的基于二次模態分解的LSTM電力負荷預測整體框架如圖2所示。將預處理后的原始電負荷數據使用CEEMDAN進行分解,得到子序列,再對子序列中的強非平穩分量進行二次VMD分解,分解為平穩的子序列,再單獨把每個分量都送入LSTM網絡中進行預測,得出每個分量的預測結果,最后把由CEEMDAN和VMD分解后的每個分量的預測結果進行線性疊加即可獲得最終的負荷預測結果。

圖2 模型總體框架Fig.2 Overall framework of the model
3.2 評價指標
選取3種評價指標,分別為平均絕對百分比誤差(mean absolute percentage error, MAPE)、均方根誤差(root mean square error, RMSE),對預測結果精度進行評價,用確定系數(R-square_score,R2)對模型好壞進行評價。表達式分別為
(14)
(15)
(16)
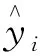
4 算例分析
本文數據選用美國國家可再生能源實驗室官網上提供的亞利桑那州立大學鳳凰城校區的相關數據,數據維度為8維。7維數據是輸入數據,分別為溫度、濕度、風速、露點、太陽垂直輻射、太陽水平輻射、大氣壓共七維數據;1維為輸出數據,即電力負荷數據。
本文選擇下載2021年1月1日—2021年12月31日按照1 h為間隔的小時級數據,按照8∶2劃分訓練集和測試集,預測步長也為一小時。
軟件選用python語言,深度學習框架選取tensorflow。LSTM的神經網絡層數設置為1層,神經元的個數為50個,優化算法為Adam,添加Dropout層防止過擬合。
4.1 電力負荷的二次模態分解
對收集到的原始數據進行整理,繪制出原始電負荷數據圖像如圖3所示,再對原始數據直接進行CEEMDAN分解,將原始序列自適應地分解為10個IMF分量和殘差分量(residual,RES),分別記為CIMF和RES,分解效果如圖4所示。

圖3 原始負荷Fig.3 Original electric load

圖4 CEEMDAN模態分解結果Fig.4 CEEMDAN modal decomposition results of electric load
從圖4可以看出,CEEMDAN分解的分量中CIMF1為強非平穩分量,而其余分量為平穩分量。強非平穩分量樣本時間序列的均值、方差、協方差不為常數,與時間相關,當前時間序列的特征不會延伸到下一時刻,關聯性不強,所以很難取得好的預測效果;而平穩分量中時間序列的均值和方差為與時間無關的常數,樣本時間序列在未來的一段時間內仍有順著當前的時序特征延續下去的趨勢,所以需要將強非平穩序列CIMF1進行平穩化,以提升預測效果。對CEEMDAN產生的CIMF1分量進行VMD二次分解,經VMD分解的分量都為平穩序列,此外,VMD分解個數越多重構與原始序列越接近,所以存在最佳分解個數,通過中心頻率法改變模態分解數,觀察中心頻率看有無模態混疊現象,得到最佳分解個數為12個。VMD分解結果如圖5所示,分量即為VIMF。從圖5可以看出,VMD分解后的各分量均為平穩分量,預測效果較好,且通過中心頻率法確定分解個數為12時不會產生模態混疊現象,從而有效避免了VMD分解后的分量之間的相互影響,有效避免了錯誤的預測結果。

圖5 VMD模態分解結果Fig.5 VMD modal decomposition results of electric load
4.2 負荷預測結果對比分析
為驗證本文所提的基于二次模態分解的負荷預測方法的有效性,選取2021年12月的最后一個星期預測結果作對比實驗,分別對比了不做模態分解直接預測,做一次模態分解后預測、做兩次模態分解后預測的效果。3種情況下的MAPE、RMSE、R23種指標,負荷預測結果如圖6所示。

圖6 模態分解前后電負荷預測結果Fig.6 Prediction results of electric load before and after modal decomposition
由圖6可得,進行CEEMDAN和VMD分解后的負荷預測結果精度最高,其次是只進行一次CEMMDAN分解的預測結果,預測精度最差的是不進行模態分解的情況。
不做模態分解、做一次模態分解和做兩次模態分解的指標對比如表1所示。

表1 3種情況指標對比Table 1 Prediction accuracy results before and after modal decomposition
由表1可知,不做模態分解、做一次模態分解和做兩次模態分解的MAPE/RMSE/R2的值為2.4%/28.155/0.905、2%/22.436/0.945、1.7%/18.675/0.962。可見二次模態分解的MAPE、RMSE、R2的值優于只進行一次模態分解的值,MAPE、RMSE、R2分別提升了0.4%、5.719、0.04;而只進行一次模態分解又比不做模態分解的效果好,MAPE、RMSE、R2分別提升了0.3%、3.761、0.017。說明本文方法對于負荷預測精度和模型性能有明顯提升。
5 結論
本文針對具有較強波動性和隨機性的電力負荷變化趨勢預測問題,提出了一種基于二次模態分解的LSTM預測模型。該模型運用CEEMDAN分解和VMD分解將原始電負荷序列分解為多個平穩的子序列,然后運用LSTM網絡對分解的子序列進行訓練,能夠更好地學習到原始序列中的非線性關系,得到更精準的預測結果。同時分解的子序列重構能夠得到較好的預測結果。
通過仿真得到以下結論。
(1)通過引入模態分解,能夠使短期電力負荷預測精度有著較大提升。經過二次模態分解,使得原始負荷序列的時間特征更加突出,便于神經網絡進行信息的捕捉,分解后分量的預測精度能夠大大提升。
(2)將原始負荷序列進行模態分解的各個分量,可以明顯看到進行模態分解后進行預測的各個預測分量進行疊加能夠保持很大程度上保證對原有信息的保留。
猜你喜歡
兒童故事畫報(2019年5期)2019-05-26 14:26:14
廣西科技大學學報(2016年1期)2016-06-22 13:10:37
Coco薇(2016年2期)2016-03-22 02:42:52
湖北經濟學院學報·人文社科版(2015年8期)2015-12-29 05:53:07
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年7期)2015-08-11 15:03:12
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
航空學報(2015年4期)2015-05-07 06:43:35
上海電機學院學報(2015年4期)2015-02-28 14:30:00
計算物理(2014年2期)2014-03-11 17:01:39
