基于改進AE-CM模型的未知應用層協議識別
2024-03-25 02:05:04馬甜甜
計算機技術與發展 2024年3期
馬甜甜,洪 征,陳 乾
(陸軍工程大學 指揮控制工程學院,江蘇 南京 210014)
0 引 言
未知協議識別是指在網絡通信中識別出無法被預先確定的、類型未知的協議的過程。未知協議識別方法依據協議特征對網絡流量進行分類,有助于發現異常的網絡通信活動[1]。提高未知應用層協議的識別能力,有利于安全高效地提供網絡服務[2]。
基于深度聚類的未知協議識別方法[3]通過神經網絡模型對網絡流量進行特征提取,并進行聚類分配。該方法適用于不同協議的特征和流量分布。
與此同時,基于深度聚類的未知協議識別方法[4]主要存在以下問題:
(1)特征提取和聚類分配是相互獨立的過程,聚類結果不能指導特征提取,導致聚類性能不佳。
(2)未知協議的特征不確定,僅從時間或空間的單一維度提取特征會造成特征不充分。
(3)嵌入式聚類分配模塊對不同特征的影響程度不同[5],但在分配初始權重時采用隨機或相等的權重值,模型需要多次更新,收斂速度較慢。
AE-CM[6]在現有深度聚類模型的基礎上設計了嵌入式聚類分配模塊,克服了聚類分配模塊對特征提取模塊指導性不強的問題。該文以AE-CM為基礎,提出了未知協議識別模型(DAEC-NM)。該文的主要研究工作如下:
(1)提出了一種新的未知協議識別模型,改進了AE-CM,并將改進模型應用于未知協議識別。
(2)在特征提取模塊中插入重新設計的神經網絡模塊,增強了模型對協議時空特征的提取能力。經過特征提取模塊獲取的豐富特征能夠被用于指導聚類簇的產生。
(3)使用Two-branch[7]中提出的鄰居模型提高協議識別的準確性。使用鄰居分支來捕獲鄰居樣本的格式信息和關聯特征,并根據鄰居特征提高主分支中相關協議特征的權重。
(4)在聚類模塊中引入了注意力評分機制。記錄模型特征提取過程中的特征權重,并在樣本聚類分配過程中為相關特征設置合理的初始權重,指導樣本進入相應的聚類簇。
(5)實驗結果表明,與現有的基于深度聚類的未知協議識別方法相比,DAEC-NM在ACC、ARI和NMI等指標上都有明顯提升。
1 協議識別模型的設計
未知協議的識別主要包括協議數據預處理以及協議識別,如圖1所示。數據預處理包括三個步驟。流量清理主要去除與協議識別無關的數據包,提高協議識別準確性。流重組和分割將網絡流量轉換為符合深度自編碼器輸入格式的數據,并將請求與響應組合在一起,便于分析協議內的關聯關系。此后從網絡流的開頭截取固定長度的段,并根據需要執行截斷和填充操作。最后,流量數據歸一化對獲得的固定長度的序列進行歸一化操作,并將序列轉換為固定格式的二維張量。通過數據預處理,可以提高輸入數據的質量,減少數據噪聲,保證模型訓練的有效性和準確性。

圖1 未知協議識別的流程
該文提出的DAEC-NM如圖2所示,主要包含一個深度聚類分支(DAEC-branch)和一個鄰居分支(NM-branch)。其中DAEC分支中包含協議特征的提取模塊(feature extraction module)、聚類分配模塊(clustering module)和協議重構模塊(protocol reconstruction module)。各模塊的具體工作將在后文詳細論述。

圖2 DAEC-NM結構
1.1 協議識別模型的特征提取
深度聚類模型DAEC的設計如圖3所示,特征提取編碼器根據其功能模塊將輸入的數據流張量轉換為協議特征,聚類分配模塊根據協議特征輸出聚類簇分配結果,并根據協議簇分配結果重新調整協議特征權重,協議重構解碼器根據協議特征重構協議樣本。在設計未知協議識別模型中的特征提取編碼器時,傳統的堆棧自編碼器處理非局部特征信息時不夠靈活。DAEC模型采用了簡單卷積模塊、時序卷積模塊和多層感知機模塊來提取協議樣本的特征。簡單卷積模塊采用高維卷積對協議樣本進行空間特征提取,以增強對不同協議的區分能力。時序卷積模塊是一種時間序列模型,通過殘差鏈接塊和膨脹因果卷積提取協議數據中的時間相關特征,以提高聚類分配的準確性。多層感知機模塊采用全連接層對前兩個模塊提取的特征進行組合和抽象,增強對協議特征的區分能力。為了避免模型計算冗余參數的壓力,該文向MLP中插入衰減層Dropout1,Dropout2,提高模型的泛化能力和穩健性。這些模塊相互結合,可以挖掘協議數據的空間特征和時間特征,增強挖掘特征對不同協議的區分能力。

圖3 DAEC自編碼器模型結構
1.1.1 簡單卷積模塊
簡單卷積模塊由兩個卷積層組成,用于提取協議樣本的空間特征。協議特征在卷積層的輸出值計算方法為:
y=ReLU(Wyx+by)
(1)
其中,y代表卷積操作后的輸出,Wy代表卷積核權重,by表示偏置,ReLU表示激活函數。
1.1.2 時序卷積模塊
TCN由多個殘差模塊(Residual Convolutional Block)構成,其處理函數為TCN(),它的正向傳播計算過程如下:
ht=ReLU(max(Whxt+bh))
(2)
(3)
(4)
ft=Wfxt+bf
(5)
(6)

1.1.3 多層感知機模塊
從TCN模塊輸出的特征輸入MLP模塊,MLP模塊的正向傳播計算公式如下:
z1=W1x+b1
(7)
(8)
x1=z1·d1
(9)
z2=W2x1+b2
(10)
(11)
x2=z2·d2
(12)
z3=W3x2+b3
(13)
其中,W1,W2和W3表示權重,b1,b2和b3表示偏置,p1和p2表示衰退層保留節點的概率。
1.2 鄰居分支與補充特征
高維特征空間表示可能無法捕捉到協議數據的語義和局部聯系。為了解決這些問題,該文采用了Two-branch方法設計鄰居分支,采集鄰居特征獲得更豐富的協議信息,增強模型對協議的學習能力。鄰居分支對鄰居樣本的二維張量進行特征提取,使用平均池化來得到一組鄰居中心特征,從而獲得一組通道特征和局部相關特征。這樣,鄰居分支可以幫助深度聚類模型更好地捕獲協議數據的語義和局部聯系,從而提高協議識別的準確性。
1.2.1 鄰居編碼器模塊設計
模型的編碼器可分為X編碼器和鄰居編碼器,如圖4所示。兩個分支結構的網絡模型相同且同步輸入,X編碼器分支輸入樣本x,鄰居分支通過最近鄰方法[8]將前次聚類結果中x的k個最近鄰樣本作為輸入。假設一個輸入鄰居樣本為z,它的前向傳播過程如下:

圖4 編碼器模型鄰居分支結構
簡單卷積模塊的處理:
yz=ReLU(Wyz+by)
(14)
時序卷積模塊的處理:
rz=TCN(yz)
(15)
多層感知機模塊的處理,簡寫為:
mz=Wmz+bm
(16)
其中,Wm表示權重,bm表示偏置,需要通過多層感知機訓練學習得到。
1.2.2 鄰居編碼器權重加強設計
樣本鄰居的特征可以為協議分析提供更全面的信息,同時可以發現其他樣本的特征模式,進而深入了解數據的總體特征。
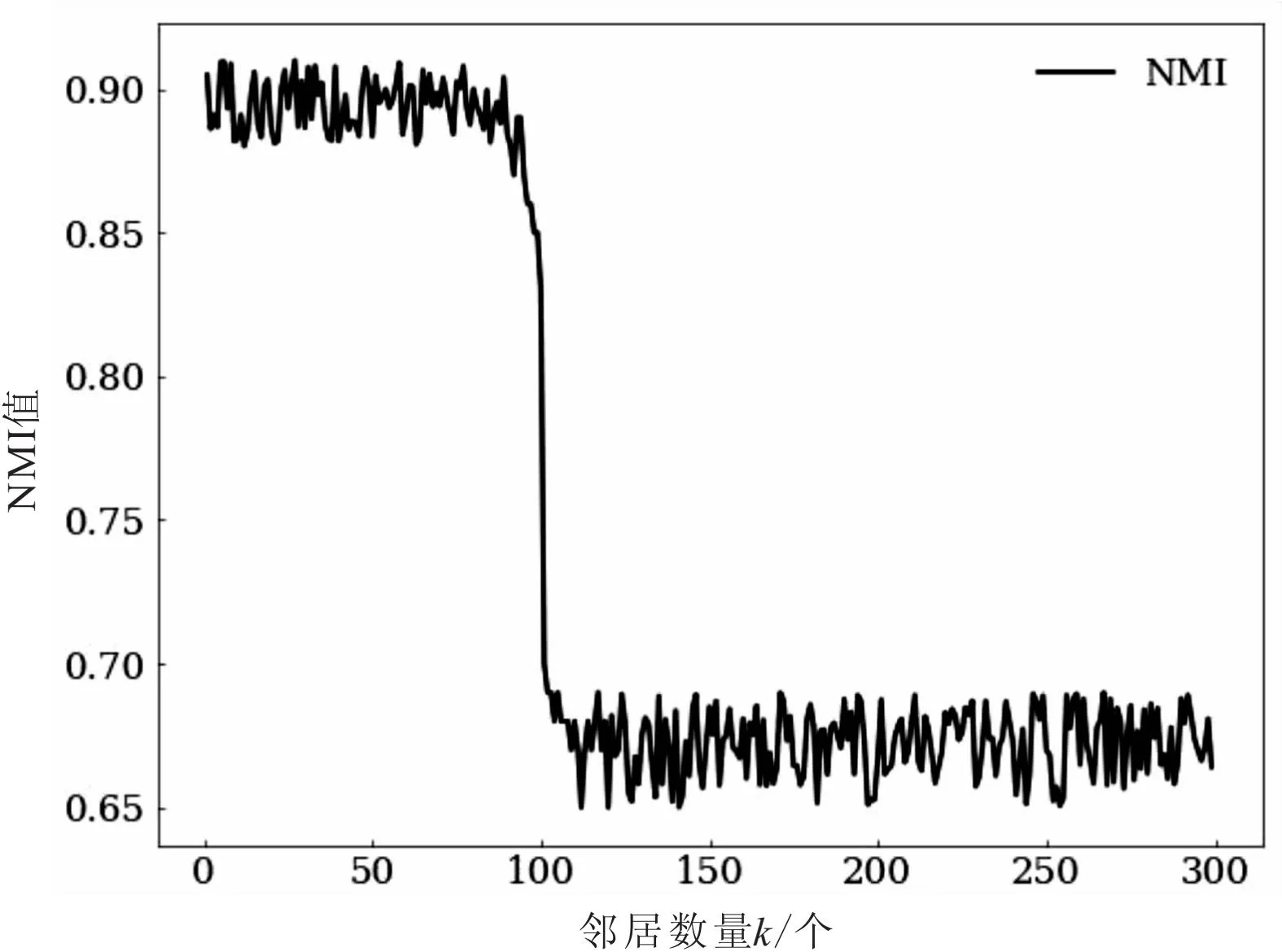
X分支和鄰居分支獲得整體樣本特征表示z=[z1,ze,z3,…,ze]和鄰居特征表示m=[mz1,me,…,mzk,0,0,0,…](k (17) 其中,θ表示增強參數,一般小于0.5,防止鄰居特征中的冗余特征過強,影響原樣本特征。 將加強后的特征輸入聚類層之前的隱藏層,篩選權重較強的特征,其前向傳播計算為: (18) 在AE-CM中使用RMABs[9]映射方法,設計嵌入式聚類模塊,它將原始特征空間映射到低維的嵌入空間,并在嵌入空間中進行聚類。 在RMABs映射方法中,將EM算法迭代過程封裝為一個小型自編碼器表示的聚類模塊,映射過程如下: F-step:Rd→RK,F(x)=〈p(z=k|x)〉{1≤k≤K}= γ~softmax(XWenc+Benc)=Γ (19) (20) AE-CM中聚類模塊的gamma層的初始權重矩陣采用隨機數進行設置,需要多輪訓練來找到合適的特征權重初始值,降低了模型的識別效率,增加了訓練開銷。為解決這一問題,該文使用加性注意力評分機制[10]生成初始權重矩陣。該評分機制捕獲特征關聯性和重要性評分,得到特征權重評分矩陣,并使用該評分矩陣作為初始化的gamma層權重矩陣,從而使gamma層在幾次迭代后快速收斂。這種方法可以降低訓練次數,減少訓練開銷,提高模型的識別效率,同時保持聚類模塊的對稱性。 聚類模塊總體設計如圖5所示,gamma層對于上層網絡提取的每一個協議特征,通過注意力評分函數獲得注意力評分,用來表示該特征的重要性。在此基礎上,對注意力評分進行加權平均f,得到最終的初始注意力評分矩陣Wh,通過gamma層將該樣本特征表示輸入相應簇中。相較于公式19,加入注意力評分機制的gamma層前向傳播計算方法為: 圖5 基于注意力評分機制的聚類模塊 (21) h=Wha+bh (22) (23) 其中,Wv,Wq和Wk表示權重,bh表示偏置,a為注意力評分后加權平均層,h為隱藏層,g為gamma聚類層輸出。 公式20中原mu layer是一個逆線性變化層ΓWdec+Bdec,為了抵消加性注意力機制的影響,聚類模塊中G-step設計為一個多級權重衰減[11]的逆線性變化過程,mu layer前向傳播計算為: mu=Γ?Dropout(Wh)+b (24) 其中,Wh是gamma層提供的注意力權重。 該文提出的未知協議識別模型,通過四個步驟(特征提取、聚類分配、協議重構、模型優化)進行協議識別。特征提取模塊采用兩個分支的設計,嵌入式聚類分配模塊使用gamma層進行聚類分配,使用mu層調整未知協議特征的影響權重,最后使用重構誤差和聚類損失來聯合優化模型。模型不需要標記標簽就能夠自動識別未知協議的分布情況。 基于Tensoflow2.0構建了未知協議識別原型系統。為評價模型的性能,主要考慮了以下標準: (1)評價鄰居數量以及鄰居分支對協議識別性能的影響。 (2)評價改進聚類模塊對協議識別性能的影響。 (3)與其他協議識別模型進行比較,并對協議識別模型的整體性能進行了評價。 選擇數據集IDS2017[12]進行實驗。數據集包含的是網絡流量數據,以pcap的格式提供。提取了四種應用層協議(HTTP,FTP,DNS和SMB)進行測試。根據預處理方法對協議數據進行預處理后,得到了45 514條有序的網絡流。在實驗中,協議的標簽被刪除,從而使所有的協議都可以被視為未知的協議。為了評估所提出的協議識別模型的有效性,選擇了精確度(ACC)、歸一化互信息(NMI)和調整蘭德指數(ARI)作為評估指標。 2.2.1 鄰居的影響 該文通過鄰居分支提取樣本鄰居的特征作為補充特征。在鄰居分支的設計過程中,通過近似算法選取k個樣本鄰居。需要設置實驗分析鄰居數量對協議識別效果是否有影響。此外,需要設置實驗探究鄰居分支對協議識別模型識別精度的提升效果。 (1)鄰居數量的影響。 探究鄰居數量對協議識別模型效果影響,設計k鄰居數量范圍為1~300,實驗通過NMI值隨k值變化,探究鄰居數量的影響。 從圖6分析可得,鄰居數量小于90時,NMI曲線波動小,鄰居數量超過110時,NMI曲線恢復平穩波動;而鄰居數量在100左右時,NMI曲線急劇下降。NMI值在鄰居數量小于100時較高(約0.9),在鄰居數量超過100時較低(約0.66)。 圖6 NMI值隨k的變化 從實驗結果可以看出,較遠處的鄰居與原樣本相差較大,從而導致原樣本的特征被鄰居樣本的補充特征干擾。因此,該文選擇較小數量的k值,能夠呈現較好的協議識別效果。 (2)鄰居分支的影響。 為探究鄰居分支對協議識別模型的效果影響,通過實驗比較帶鄰居分支的模型和不帶分支的模型的識別效果。實驗中分別獲得協議識別模型(DAEC)帶鄰居分支(NM)和不帶鄰居分支(NA)情況下,模型的精確度(ACC)、調整蘭德指數(ARI)和歸一化互信息(NMI)。 從表1中得出以下結論:帶鄰居分支的深度聚類模型協議識別表現優于不帶鄰居的模型。 表1 有無鄰居狀態下協議識別模型表現 % 表2 有無注意力評分機制的聚類模塊對協議識別模型表現的影響 % 2.2.2 注意力評分機制在聚類模塊中的影響 探究注意力評分機制在聚類模塊中對協議識別模型的效果影響,通過實驗比較聚類模塊(CM)包含和不包含注意力評分機制對協議識別模型的效果。實驗結果顯示,相較于不包含注意力評分機制的聚類模塊,包含注意力評分機制的聚類模塊的協議識別模型表現更優。精確度提升了4.23百分點,ARI指數提升了11.63百分點,NMI指數提升了10.78百分點。其原因在于,注意力評分機制側重于提高協議識別模型對于重要特征的關注度,有利于提高聚類效果。具體來說,注意力評分機制可以通過動態給不同的特征分配不同的權重,使得那些更具有代表性和區分度的特征能夠更好地被聚類模塊所利用。 2.2.3 與其他模型的橫向比較 為了驗證所提出的未知協議識別模型的性能,將該模型與DEC[13],CAE[14],AE+K-Means[15],K-Means和GMM進行橫向比較。 其中,K-Means和GMM是傳統的聚類算法,常用于協議識別模型中。根據本研究實驗結果設置它們的參數,K-Means聚類簇數為4,GMM的成份數為4。深度聚類的方法包含DEC,CAE,AE+K-Means,AECM以及DAEC-NM(ours),其中除該文設計的網絡外,其他方法的自編碼器均為對稱的堆棧多層感知機。 不同協議識別模型的協議識別結果如表3所示。在表3所示的協議識別模型中,K-Means和GMM表示基于機器學習的協議識別模型,其余為基于深度聚類的未知協議識別模型。實驗結果表明,提出的深度聚類協議識別模型優于傳統聚類模型,在此基礎上,基于高斯混和聚類的模型優于基于K-Means聚類的模型。同時,嵌入式模型優于異步訓練的模型,因為嵌入式模型能夠更好地將聚類表現融入到編碼器的訓練中。此外,增加卷積模塊的自編碼器模型也優于原堆棧編碼器模型,能夠增強模型的時間、空間特征的提取能力,從而提高識別精度。總體而言,提出的協議識別模型比DEC模型在ACC,ARI和NMI評判標準上分別提高了12.03百分點,25.52百分點和17.78百分點。 表3 各種方法下協議識別模型表現 % 該文提出了一種未知應用層協議識別模型(DAEC-NM)。該模型的特征提取模塊包含兩個分支,主分支采用時空卷積網絡來提取協議數據的時空特征,鄰居分支捕獲鄰居樣本間的局部關聯特征作為補充。模型的聚類模塊通過增加注意力評分機制的方法進一步優化識別模型,并實現聚類簇分配。實驗結果表明,該模型在識別性能上優于其他協議識別模型。在未來的工作中,考慮把該模型應用于協議逆向分析、入侵檢測等領域,為網絡安全提供有效的保障。1.3 基于注意力評分機制的聚類模塊的設計

1.4 協議識別過程
2 實驗分析
2.1 數據集與評價標準
2.2 實驗結果分析



3 結束語
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
數學小靈通·3-4年級(2024年2期)2024-05-15 02:02:28
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
世界科學技術-中醫藥現代化(2020年2期)2020-07-25 02:05:36
數學物理學報(2020年2期)2020-06-02 11:29:24
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
光學精密工程(2016年6期)2016-11-07 09:07:19
核科學與工程(2015年4期)2015-09-26 11:59:03
