高斯混合模型與文本圖卷積網(wǎng)絡結(jié)合的虛假評論識別算法
2024-03-21 02:25:06劉貴娟陳志豪
計算機應用 2024年2期
王 星,劉貴娟,陳志豪
(1.中國人民大學 應用統(tǒng)計科學研究中心,北京 100872;2.中國人民大學 統(tǒng)計學院,北京 100872)
0 引言
在互聯(lián)網(wǎng)快速發(fā)展的數(shù)字經(jīng)濟背景下,優(yōu)質(zhì)可信的在線消費者評論(Online Consumer Review,OCR)在需求側(cè)消費者的購買決策和供給側(cè)企業(yè)獲得用戶反饋、提高產(chǎn)品質(zhì)量和改善服務等方面發(fā)揮著至關(guān)重要的作用[1]。然而,虛假評論現(xiàn)象廣泛存在于各類在線購物及點評網(wǎng)站中,嚴重阻礙了電子商務的真實性,降低了消費者的信任度[2]。鑒于虛假評論數(shù)量大、信息復雜和隱蔽性強等難點,識別和過濾虛假評論成為學術(shù)界和業(yè)界共同關(guān)注的研究熱點,亟須“去偽存真、去粗取精”[3]。
在虛假評論的識別問題中,常規(guī)的深度學習算法通常將它視為自然語言處理(Natural Language Processing,NLP)領(lǐng)域中的常見任務。Ahmed 等[4]在虛假評論智能檢測的開創(chuàng)性研究中指出,可通過詞向量對評論做矢量化表示的方式獲得虛假評論特征的感知。此后,許多學者沿著詞向量特征的方向,提出諸多從評論文本中提取敏感詞匯識別虛假評論的深度學習算法,為虛假評論的識別作出貢獻。代表性的研究進展主要有兩類:一類通過Word2Vec 和上下文預訓練的BERT(Bidirectional Encoder Representation from Transformers)進行向量詞特征表示[5-6];第二類則將預訓練的詞向量用于深度學習訓練,如卷積神經(jīng)網(wǎng)絡(Convolutional Neural Network,CNN)、循環(huán)神經(jīng)網(wǎng)絡(Recurrent Neural Network,RNN)和殘差網(wǎng)絡(ResNet)等[7]。特征矢量表示方法的局限性多表現(xiàn)為依賴于大量高質(zhì)量的人工標注,成本高、噪聲多、質(zhì)量低[8]。此外,為盡可能納入更多的特征,大量的非官方用語、縮寫詞匯等信息源的出現(xiàn)會干擾特征空間,極易稀釋多標簽組合特征,導致丟失輔助語義理解的完整信息[9]。另外,這些算法主要處理經(jīng)轉(zhuǎn)換為歐氏空間有限維度的結(jié)構(gòu)有序的詞向量表示數(shù)據(jù),難以處理維度可變、搭配無序的關(guān)聯(lián)語義。由于缺少特征間必要的關(guān)聯(lián)組件,這些算法對虛假評論的理解深度不足,導致治理虛假的決策行動陷入響應滯后的困境[10]。
作為凈化網(wǎng)絡評論生態(tài)的基礎(chǔ),首先需要明確虛假評論的關(guān)鍵信息源和敏感的詞匯影響類型,這對制定識別虛假評論算法的語言感知域至關(guān)重要。國內(nèi)外學者對此已有大量研究。虛假評論的源頭一般分為評論作者來源和自然語言來源兩類,兩者不孤立。Zhang 等[11]指出,虛假評論的作者并非真實的消費者,而是由機器人大批量生產(chǎn),存在強偽裝性和數(shù)量激增等諸多隱患。制造虛假評論的動機主要是為了影響消費者的購買決策,通過滲透錯誤印象來刺激消費者;而正常評論則更注重消費后的用戶理性認知。根據(jù)印象感知和理性認知的不同,早期大量的規(guī)則學習和機器學習重點圍繞評論中的情感用詞、聚焦主題和質(zhì)量誤導話術(shù)等做矢量化語義明線索解析,豐富了虛假評論的信源感知理論[12]。然而,虛假評論具有顯著的累積性和后發(fā)性,單純依靠信源明線索難以遏制隱線索的破壞式滲透,智能檢測十分必要。
近幾年,通過圖表示的圖神經(jīng)網(wǎng)絡(Graph Neural Network,GNN)和圖卷積網(wǎng)絡(Graph Convolutional Network,GCN)[13-14]在虛假評論識別中的應用受到越來越多的關(guān)注。在GCN 虛假監(jiān)測的技術(shù)研究中,檢測的問題類型主要集中在虛假新聞、謠言監(jiān)測和垃圾郵件識別等,構(gòu)造GCN 的信源主要為用戶類型[15-16]、網(wǎng)絡結(jié)構(gòu)[17-18]和多層傳播鄰居[19-20]等方面。GCN 的作用主要體現(xiàn)為兩方面:一是學習評論之間的社交關(guān)系;二是結(jié)合GCN 與其他深度學習模型,以提高虛假評論識別的準確性。目前的虛假評論研究多為新聞和謠言類,對電商經(jīng)營中的虛假評論研究卻不多見。與虛假新聞和謠言等識別問題相比,商品評論更需要理解內(nèi)容中潛藏的豐富的用語搭配和長程單詞依賴的句式在語義技術(shù)上的支持,需要增強評論文本中詞的關(guān)聯(lián)信息,捕捉內(nèi)容之間的語義關(guān)系。GNN 和GCN 在NLP 的常規(guī)內(nèi)容分析任務中已展現(xiàn)出強大的語義理解技術(shù)優(yōu)勢,典型的如關(guān)系推理[21-22]、文本分類[23]、復句識別[24]、機器翻譯[25]和序列標簽[26]等。相關(guān)的虛假評論的語義研究表明:融合評論捕捉全局語義信息網(wǎng),將文本特征與用戶行為特征等進行非矢量化語義表達將有助于促進虛假評論檢測理解[12],非矢量化語義特征之間的關(guān)系信息正成為理解虛假評論模式的新熱點。
Yao 等[10]提出了基于文本的圖卷積網(wǎng)絡(Text GCN)用于文本分類,在基準數(shù)據(jù)集中取得良好性能。與傳統(tǒng)的矢量特征方法相比,新興的Text GCN 模型以圖結(jié)構(gòu)的方式解析文本中各語言元素間的豐富關(guān)系,通過GCN 學習詞結(jié)構(gòu)以捕獲深層的語義關(guān)聯(lián)[10],可用于感知虛假評論的結(jié)構(gòu)與文本相結(jié)合的關(guān)聯(lián)信息。然而,在構(gòu)建文本圖的過程中,設(shè)計Text GCN 非常有挑戰(zhàn)。將Text GCN 用于虛假評論的識別目標是找到它與正常評論之間穩(wěn)定的關(guān)聯(lián)結(jié)構(gòu)差異,該過程成功的關(guān)鍵取決于能否控制虛假評論相對于正常評論的信噪比不至于過小,而在輸入信源邊權(quán)信噪比較低的前提下,這有賴于Text GCN 預處理階段的窗口選擇。在Text GCN 的窗口設(shè)計中忽視對虛假評論結(jié)構(gòu)信號強度的感知,易丟失關(guān)鍵結(jié)構(gòu),導致效果虛高而結(jié)構(gòu)泛化識別不足的問題。
在實際算法訓練中,受制于人工打標的保守性,導致虛假評論的訓練樣本相對于正常評論通常呈現(xiàn)數(shù)量明顯偏少的情況,需要有效學習虛假評論豐富的語義特征并提高結(jié)構(gòu)關(guān)聯(lián)識別能力。針對當前Text GCN 對稀疏詞結(jié)構(gòu)選擇能力的不確定性,考慮到用詞量、詞特征、詞與詞以及詞與非文本特征的多模態(tài)組合關(guān)聯(lián)結(jié)構(gòu)的不確定性,在預處理階段引入基于高斯混合分布的虛假結(jié)構(gòu)信號感知檢測模塊,對虛假評論和正常評論實施非破壞性結(jié)構(gòu)檢驗。綜上所述,本文在Text GCN 的基礎(chǔ)上,提出一種用于電商購物平臺虛假評論識別算法F-Text GCN(Fake-review Text GCN)。
1 圖卷積神經(jīng)網(wǎng)絡的虛假評論識別模型
1.1 Text GCN
相較于傳統(tǒng)的基于特征表示和聯(lián)系上下文語義的深度學習方法,基于文本內(nèi)容引入文檔-詞的圖表示學習能更清晰地表示文本結(jié)構(gòu)所包含的深層語義關(guān)系。對于虛假評論識別任務,引入良好的圖結(jié)構(gòu)信息既能克服短評論中信息強度弱的缺點,又能降低模型識別過程中的混雜噪聲。
1.1.1 GCN
本文研究的GCN 模型是Kipf 等[27]在頻譜卷積神經(jīng)網(wǎng)絡(Spectral CNN)和切比雪夫網(wǎng)絡(ChebNet)的基礎(chǔ)上提出的,是將傳統(tǒng)的譜方法中的節(jié)點參數(shù)化方式擴展到對譜域的卷積操作[28]。為獲得更多鄰域和更長程的關(guān)聯(lián)信息,通常需要集成多個GCN 層堆疊。假設(shè)圖結(jié)構(gòu)表示為G=(V,E),|V|=n,當使用多層GCN 獲取鄰域信息時,層間的更新方法為:
其中:j表示層數(shù);L(0)=X∈Rn×m表示初始節(jié)點特征表示矩陣,每個節(jié)點的初始特征維數(shù)為表示第j層節(jié)點特征矩陣表示第j層權(quán)重矩陣,用于調(diào)整每層的特征維數(shù)提取特征表示歸一化的對稱鄰接矩陣,ρ表示激活函數(shù)。根據(jù)式(1)計算可得出第j+1 層節(jié)點特征矩陣L(j+1)。
1.1.2 Text GCN
Text GCN 模型由文本圖構(gòu)建和GCN 訓練兩步構(gòu)成。
1)文本圖構(gòu)建。
根據(jù)詞在文檔中的出現(xiàn)率和詞在整個語料庫中的共現(xiàn)率構(gòu)建詞節(jié)點連邊。模型中,文檔與詞節(jié)點間的邊權(quán)定義為術(shù)語頻率-逆文檔頻率(Term Frequency-Inverse Document Frequency,TF-IDF)值[29],用于評估單詞在文本中的重要程度。對語料庫中所有文檔使用由邊權(quán)閾值控制的窗口,收集共現(xiàn)詞頻統(tǒng)計數(shù)據(jù),用于刻畫全局詞匯共現(xiàn)關(guān)系。衡量詞關(guān)聯(lián)的方法是計算點對點的互信息(Pointwise Mutual Information,PMI)[30],用于表示兩個詞節(jié)點間的權(quán)重。根據(jù)Yao 等[10]提出的帶權(quán)值鄰接矩陣表示如下:
其中:TF-IDF 由詞在文檔中出現(xiàn)的次數(shù)和評論總數(shù)除以包含該詞的評論數(shù)所得的商取對數(shù)兩部分構(gòu)成。詞節(jié)點對(i,j)的PMI 值計算如下:
其中:p(i,j)表示詞節(jié)點i與詞節(jié)點j共現(xiàn)的概率,p(i)是在滑動窗口下詞i出現(xiàn)的概率,#U(i,j)是同時包含詞節(jié)點i和詞節(jié)點j的詞頻數(shù),#U(i)是語料庫中包含詞節(jié)點i的詞頻數(shù),#U是語料庫中詞頻總數(shù)。當語料庫中單節(jié)點對的語義相關(guān)性較高時,PMI 值為正;當語義相關(guān)性很小或沒有時,PMI 值為負。據(jù)此,構(gòu)建詞節(jié)點賦邊時只考慮PMI 值為正的詞節(jié)點對,PMI 值為負的節(jié)點間不連邊。鄰接矩陣A的各部分組成如圖1 所示。
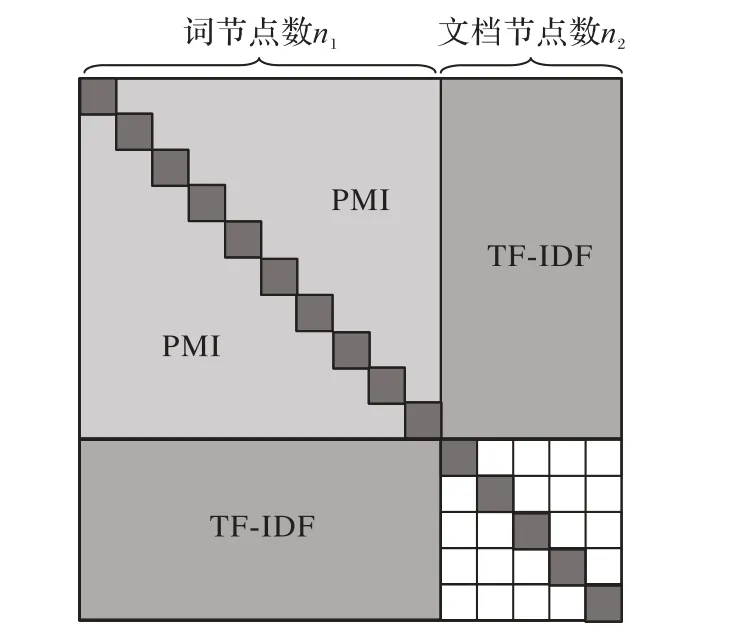
圖1 Text GCN中鄰接矩陣A的示意圖Fig.1 Schematic diagram of adjacency matrix A in Text GCN
在文本圖的構(gòu)建過程中,Text GCN 考慮的重點是詞節(jié)點對之間以及詞節(jié)點-文檔節(jié)點對的關(guān)系,并未對文檔節(jié)點對間的關(guān)系進一步考慮。
2)GCN 訓練學習。
在構(gòu)建文本圖時,使用GCN 提取節(jié)點鄰域信息。通過疊加GCN 的層數(shù),獲取更高階的鄰居節(jié)點信息。Text GCN將構(gòu)建文本圖輸入雙層的GCN 中,以獲取二階鄰居節(jié)點信息。嵌入第一層節(jié)點信息時,使用ReLU(Rectified Linear Unit)作為激活函數(shù)降噪特征。嵌入第二階節(jié)點信息時,需匹配目標維度大小與標簽集維度大小,輸入softmax 分類器:
其中:D是測試數(shù)據(jù);p是輸出的特征維數(shù),也稱為類別數(shù),在虛假評論的例子中是2 維;Ydi表示真實的響應變量特征表示矩陣;Zdi表示式(4)輸出的向量。為便于受到長度限制而缺失了部分詞匯的文檔也能對虛假評論的固定長句式提供證據(jù),GCN 將層數(shù)設(shè)定為雙層,以利于支持間隔兩步之內(nèi)的節(jié)點之間的信息傳遞。短文檔可借助全局語料中與長文檔所包含的固定句式的詞匯節(jié)點形成密切的節(jié)點連接信息。同理,雙層GCN 還允許在兩個文檔對之間交互信息,重要詞節(jié)點信息通過交互節(jié)點對獲得信號增強。由于虛假評論比真實評論更容易呈現(xiàn)詞匯的固定組合,在單條評論信息有限的情況下,Text GCN 的設(shè)計將更容易捕捉到虛假評論的用詞差異,挖掘更全局的語義結(jié)構(gòu)信息。
1.2 F-Text GCN算法
1.2.1 虛假評論詞關(guān)聯(lián)結(jié)構(gòu)的統(tǒng)計特征
將Text GCN 用于虛假評論的識別目標是找到它與正常評論的穩(wěn)定的詞關(guān)聯(lián)結(jié)構(gòu)差異,由邊權(quán)閾值控制的窗口大小的選擇十分關(guān)鍵。窗口邊權(quán)閾值的大小規(guī)定了尋找關(guān)聯(lián)關(guān)系的視野寬度,會直接影響詞節(jié)點i的詞頻和與詞節(jié)點j的共現(xiàn)次數(shù),繼而影響鄰接矩陣A中PMI(i,j)的數(shù)值。過小的窗口閾值將引入太多的低頻連接,導致U(i,j)較小,PMI(i,j)較小,無效的關(guān)聯(lián)噪聲將導致虛假評論中真實的關(guān)聯(lián)信號過于稀疏,破壞了長距離的詞關(guān)聯(lián)結(jié)構(gòu),容易產(chǎn)生較高的假陽率;過大的窗口邊權(quán)閾值雖然能捕捉到較強的詞關(guān)聯(lián)信號,卻容易遺漏與高頻信號連接的中、低頻詞的關(guān)聯(lián)結(jié)構(gòu),破壞了虛假評論語義的完整性,導致較高的虛假評論假陰率。為了確保在使用邊權(quán)閾值控制的窗口提取虛假評論與正常評論中的有效詞關(guān)聯(lián)結(jié)構(gòu)時,能完整、有效地獲取虛假評論的語義結(jié)構(gòu),本文需要對虛假評論的結(jié)構(gòu)進行均衡性設(shè)計。通過這種設(shè)計,窗口邊權(quán)閾值能在提取虛假評論和正常評論的過程中保持穩(wěn)定性,從而提高識別虛假評論的準確性。
圖2 是本文實證研究數(shù)據(jù)集中抽取的一個由3 200 條正常評論和800 條虛假評論的邊權(quán)按4∶1 構(gòu)成的示例數(shù)據(jù)分別擬合的分布密度圖。
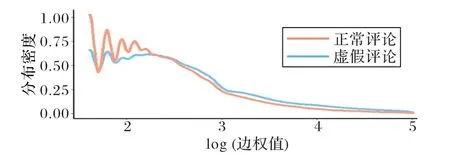
圖2 虛假評論與正常評論邊權(quán)分布密度示例圖Fig.2 Example diagram of edge weight distribution density between fake reviews and normal reviews
由圖2 可見,當邊權(quán)較小時表示弱連接低頻噪聲結(jié)構(gòu),較大的邊權(quán)表示高頻強連接語義結(jié)構(gòu)。虛假評論和正常評論都會出現(xiàn)多個分層弱關(guān)聯(lián)噪聲結(jié)構(gòu),可用分布表示信噪結(jié)構(gòu)。虛假評論厚尾特征明顯強于正常評論,隨著閾值的增加虛假評論的信噪比由小到大的速度先快后慢,而同樣的閾值用于正常評論信噪比具有改變不明顯的特點,運用高斯混合模型(Gaussian Mixture Model,GMM)分解出的均值、方差和比例等分布信息可有助于虛假評論相對于正常評論的信號結(jié)構(gòu)感知。為此,本文使用GMM 作虛假評論的最大噪聲過濾,通過邊權(quán)閾值的邊緣檢測確定最優(yōu)邊權(quán)窗口閾值,以最大可能保留核心關(guān)聯(lián)結(jié)構(gòu)捕獲的完整性,同時剝離干擾虛假評論核心關(guān)聯(lián)結(jié)構(gòu)的噪聲。
綜上所述,經(jīng)邊權(quán)閾值作用后的虛假評論和正常評論的分布是否有差異,是考察邊權(quán)閾值是否有效的必要條件,那么均衡性對窗口選擇有怎樣的影響呢?為此,本文分別考察虛假評論比例均衡和虛假評論比例不均衡的兩種情形下,經(jīng)GMM 分離噪聲后的兩類邊權(quán)分布的主要統(tǒng)計特征隨邊權(quán)閾值變化的情況。設(shè)計如下兩種情形比較實驗:情形1 是均衡的數(shù)據(jù)設(shè)定,虛假評論數(shù)和正常評論數(shù)各取1 000;情形2 不均衡情況下的虛假評論數(shù)取800,正常評論數(shù)取3 200,不均衡比設(shè)為1∶4,與本文實證研究部分的實驗用例比例一致。
圖3(a)為在不同關(guān)聯(lián)強度閾值過濾下,虛假評論與正常評論在比例均衡情形下的固定詞關(guān)聯(lián)圖的邊權(quán)分布的均值與方差隨閾值的變動情況。經(jīng)GMM 分離后的虛假評論詞關(guān)聯(lián)邊權(quán)分布均值與方差幾乎在所有的邊權(quán)閾值下都高于正常評論,虛假評論的均值和方差都高于正常評論的,顯示出虛假評論的結(jié)構(gòu)聯(lián)系更加緊密的強連通結(jié)構(gòu)特征。隨著邊權(quán)閾值的增長,虛假評論信號增長,詞匯節(jié)點間的關(guān)聯(lián)信號更強,這樣的關(guān)聯(lián)結(jié)構(gòu)與Text GCN 的識別目標相吻合。
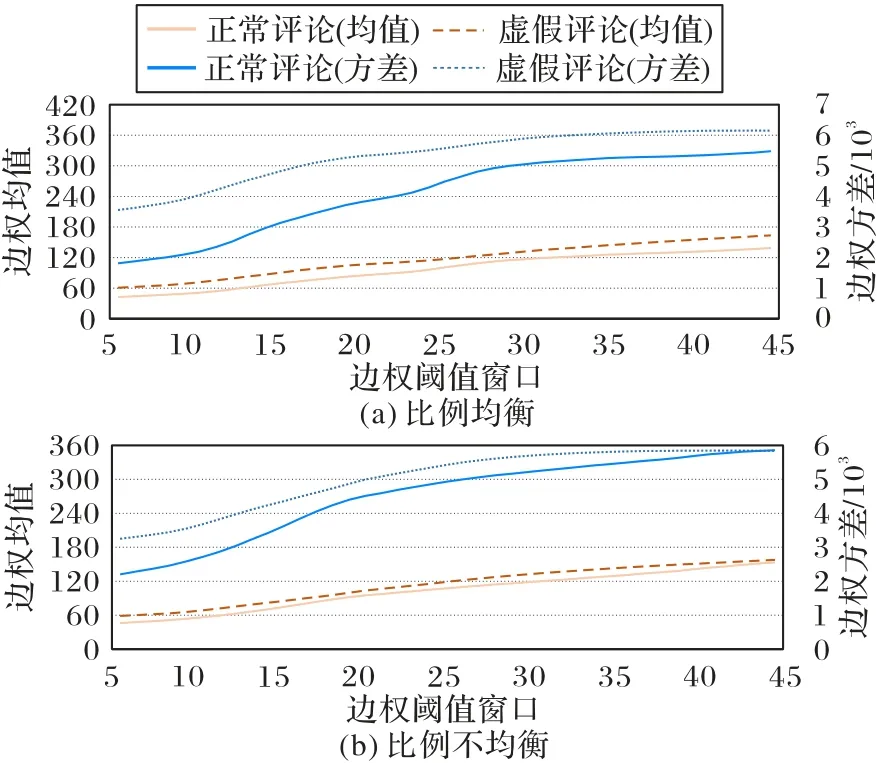
圖3 兩種評論情形下經(jīng)GMM分離噪聲后的邊權(quán)分布均值與方差隨窗口邊權(quán)閾值的變化Fig.3 Changes in mean and variance of edge weight distribution with edge weight threshold window after GMM noise removal for two types of reviews
圖3(b)是虛假評論占比相對于正常評論比例偏少(1∶4)的情形下,經(jīng)GMM 作用后虛假評論與正常評論穩(wěn)定詞關(guān)聯(lián)結(jié)構(gòu)的邊權(quán)分布。虛假評論的邊權(quán)均值與方差仍高于正常評論,均值在虛假評論和正常評論之間的區(qū)分度明顯降低,方差在區(qū)分虛假評論和正常評論的邊權(quán)分布上的作用優(yōu)于均值;但與比例均衡情況相比,虛假評論和正常評論間的分布差異有逐漸縮小的趨勢,這表明邊權(quán)閾值較大時,通過邊權(quán)結(jié)構(gòu)提取虛假評論核心詞關(guān)聯(lián)結(jié)構(gòu)的任務面臨虛假評論相對于正常評論的信噪比優(yōu)勢消失現(xiàn)象,這就需要緊抓閾值這個結(jié)構(gòu)感知的調(diào)節(jié)工具,在邊權(quán)閾值較小的一側(cè)設(shè)計更精細的窗口邊權(quán)閾值。
1.2.2 基于GMM的噪聲感知的窗口預選擇模塊
基于在一個小樣本上的探索性分析,無論在均衡還是非均衡的數(shù)據(jù)條件下,窗口邊權(quán)閾值的設(shè)計都十分必要,將這個過程稱為噪聲感知的窗口預選擇模塊。引入強關(guān)聯(lián)結(jié)構(gòu)與弱關(guān)聯(lián)結(jié)構(gòu)在關(guān)聯(lián)強度上的顯著性差異檢驗過程。先對所選的窗口邊權(quán)閾值實施自助法GMM 統(tǒng)計特征估計,再實施信號分離強度檢驗,將具有強關(guān)聯(lián)信號表現(xiàn)能力的滑動窗口作為Text GCN 的窗口邊權(quán)閾值。
具體方法如下:給定窗口邊權(quán)閾值集L=對于在確認的訓練集中隨機抽取虛假評論與正常評論各n條,重復B次。對于第j次抽取(1 ≤j≤B),統(tǒng)計虛假評論與正常評論在SLi下各詞匯的共現(xiàn)次數(shù),分別得到虛假詞匯共現(xiàn)矩陣,記為CijF,正常詞匯共現(xiàn)矩陣,記為CijN。給定邊權(quán)窗口閾值s,保留CijF和CijN中大于邊權(quán)閾值s的連邊,分別擬合二元GMM 如下:
為感知虛假評論信號的強度,記錄B次重復實驗中拒絕原假設(shè)的次數(shù)nf,對預先指定的閾值γ(0 <γ<1),建議取γ≥0.5。令nf/B=γ1,取I={i:γ1≥γ,1 ≤i≤k}且則記錄將作為Text GCN 的結(jié)構(gòu)感知窗口。
1.3 F-Text GCN
對于虛假評論識別任務,評論者的相關(guān)特征通常是值得引入的重要信息,比如平臺會員更傾向于發(fā)布真實評論而非虛假評論。這些在評論/文檔層面上的特征不僅直接提供信息,還有利于加強評論間的交互關(guān)系,填補Text GCN 在文檔交互層面的空白。
在Text GCN 基礎(chǔ)上,本文引入用戶會員M、評論圖片C和評論視頻T 這3 個與評論者行為相關(guān)的非文本特征標簽,共同參與構(gòu)建多類型異質(zhì)網(wǎng)絡結(jié)構(gòu)感知模塊,這些特征以元路徑方式引入,豐富節(jié)點的關(guān)聯(lián)結(jié)構(gòu)。F-Text GCN 在構(gòu)建鄰接矩陣A*時,增廣原鄰接矩陣A,基于用戶會員M、評論圖片C 和評論視頻T 添加評論與評論者特征節(jié)點間的關(guān)聯(lián)關(guān)系,如圖4 中橙色部分,關(guān)聯(lián)關(guān)系的添加規(guī)則如下:
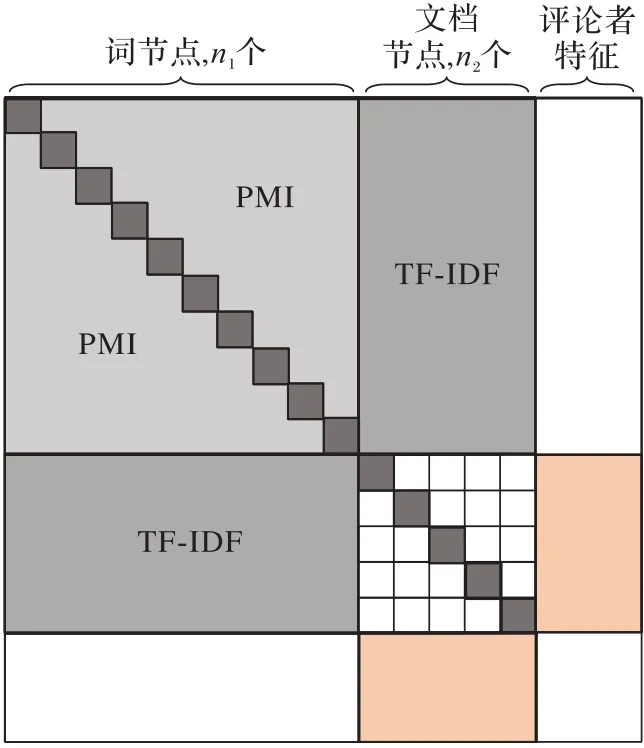
圖4 F-Text GCN中鄰接矩陣A*的示意圖Fig.4 Schematic diagram of adjacency matrix A* in F-Text GCN
其中:aMR表示用戶會員特征與評論之間的權(quán)重;aCR表示評論圖片特征與評論之間的權(quán)重;aTR表示評論視頻特征與評論之間的權(quán)重。非文本特征取值1 表示非文本特征節(jié)點與其他評論節(jié)點存在連邊關(guān)系。
F-Text GCN 對虛假評論識別的結(jié)構(gòu)流程如圖5 所示,具體內(nèi)容如下:

圖5 F-Text GCN框架流程Fig.5 Framework flow of F-Text GCN
1)對所有評論進行分詞,構(gòu)建詞匯表。對所有評論分詞,構(gòu)建全局詞匯表。給出一組待選擇的滑動窗口大小集,通過GMM 感知分離的窗口大小預選擇模塊,選擇合適的滑動窗口。
2)確定圖節(jié)點并建立連邊。每條評論、詞匯表中的每個詞、用戶會員標簽、評論圖片標簽、評論視頻標簽分別均視為圖節(jié)點。若評論包含詞匯表中的某詞,在該評論與該詞之間建立連邊;根據(jù)預選擇過程中窗口大小設(shè)置滑動窗口。在該窗口內(nèi),對共同出現(xiàn)的詞分別建立連邊;若發(fā)布評論的用戶是會員,則該條評論就與用戶會員節(jié)點建立連邊;若某評論中有圖片,則該條評論與評論圖片節(jié)點之間建立連邊;若某評論中有視頻,則該評論就與評論視頻節(jié)點之間建立連邊。
3)生成文本圖。將評論信息轉(zhuǎn)化為圖中的節(jié)點,生成評論文本圖。
4)GCN 訓練學習。基于上述規(guī)則構(gòu)建文本圖后,將圖輸入雙層GCN 中。GCN 的二階節(jié)點嵌入維度與標簽集維度具有相同大小,并輸入到softmax 分類器中輸出分類結(jié)果。
2 數(shù)據(jù)來源和網(wǎng)絡差異
2.1 數(shù)據(jù)集的構(gòu)建
本文的研究數(shù)據(jù)來自國內(nèi)某大型電商平臺手機相關(guān)產(chǎn)品評論數(shù)據(jù)。對虛假評論認定采用的方法是先排除系統(tǒng)自動生成的默認好評,例如“您沒有填寫內(nèi)容,默認好評”;再通過業(yè)內(nèi)專家構(gòu)建中文虛假評論識別數(shù)據(jù)集。為保證虛假評判標準的一致性,盡量避免主觀判斷的基本原則,安排3 位業(yè)內(nèi)專家參與認定。認定規(guī)則如下:評論數(shù)據(jù)至少經(jīng)過2 次評判,若評判結(jié)果不一致,再由第3 位專家追加認定。根據(jù)大多數(shù)投票表決認定虛假評論,認定的依據(jù)參照國內(nèi)外學者通用的數(shù)據(jù)質(zhì)量標準,主要包括評論對象的真實性,語言邏輯性、附件與文字描述的一致性和預警性字符特征。本文研究構(gòu)造的中文數(shù)據(jù)集共包含126 086 條評論,其中虛假評論數(shù)為26 783 條,其余為正常評論99 303 條,虛假評論占比為21.24%。數(shù)據(jù)分析中虛假評論的標簽值設(shè)為1,正常評論標簽值設(shè)為0。
虛假評論相對于正常評論出現(xiàn)不均衡比例偏低的現(xiàn)象主要有兩方面的原因:1)實證研究所使用的數(shù)據(jù)來源于真實的電商平臺,是經(jīng)平臺系統(tǒng)自動檢測清洗過濾后仍無法消除的虛假評論,數(shù)量相對偏少;但比例相對于正常評論已累計達到1∶4,規(guī)模不容忽視,本文算法將用于推進監(jiān)測力度,改進和完善平臺統(tǒng)計質(zhì)量標準,完善漏檢流程。2)實證使用的虛假評論產(chǎn)品主要針對智能手機類電子產(chǎn)品,智能化對這類產(chǎn)品的可靠性提出巨大挑戰(zhàn),功能繁多、服務類型多造成評論詞匯面廣、語義結(jié)構(gòu)復雜、虛假評論和正常評論共用詞比例較高造成虛假評論人工排查難度較大、實際獲得的虛假評論訓練數(shù)偏低,這表明需要深入挖虛假評論本身的信息,以提升識別虛假評論的算法效力。
2.2 虛假評論與正常評論的差異性分析
2.2.1 文本信息差異
根據(jù)虛假評論相關(guān)研究可知,虛假評論與正常評論的差異主要來自文本信息差異和評論者特征差異。相較于特征構(gòu)建的深度學習網(wǎng)絡,構(gòu)建圖關(guān)聯(lián)信息進行結(jié)構(gòu)探索的Text GCN更有利于分析虛假評論與正常評論間的文本信息差異。
為說明Text GCN 在提取文本信息結(jié)構(gòu)上的有效性,本文以評論中頻數(shù)較高的關(guān)鍵詞“滿意”和“購買”為條件,篩選出50 條虛假評論和50 條正常評論,分別構(gòu)建詞匯共現(xiàn)矩陣表進行評論差異的可視化分析。通過設(shè)置不同的連邊閾值(5~60),當詞匯共現(xiàn)次數(shù)大于等于指定連邊閾值時,構(gòu)建關(guān)聯(lián)關(guān)系,得到各閾值下詞匯共現(xiàn)網(wǎng)絡圖(如圖6、7 所示),網(wǎng)絡密度、連邊數(shù)和節(jié)點數(shù)隨閾值窗口的變化如圖8 所示。

圖6 虛假評論詞匯共現(xiàn)網(wǎng)絡圖示例Fig.6 Example about co-occurrence word network of fake reviews
隨著連邊閾值的增加,虛假評論和正常評論網(wǎng)絡圖的規(guī)模逐步減小。在閾值提升的初期,正常評論網(wǎng)絡規(guī)模的下降速度明顯高于虛假評論,主要原因是,相較于正常評論,虛假評論的詞節(jié)點間存在更強的關(guān)聯(lián)關(guān)系;并且兩類評論中大量的弱關(guān)聯(lián)關(guān)系被剔除,造成網(wǎng)絡密度急劇下降。而由于虛假評論的詞節(jié)點間更容易存在強關(guān)聯(lián)關(guān)系,詞節(jié)點的剔除速度遠小于正常評論,如圖6(b)虛假評論的網(wǎng)絡密度下降更為明顯。當連邊閾值繼續(xù)提升時,兩類評論的非核心關(guān)聯(lián)節(jié)點逐漸被淘汰,核心結(jié)構(gòu)逐漸披露,網(wǎng)絡密度出現(xiàn)回升,甚至超過初始密度。
由于評論者發(fā)布虛假評論時,常出現(xiàn)調(diào)用模板和固定句式等加工套件,虛假評論間的結(jié)構(gòu)相似度高,導致詞節(jié)點間關(guān)聯(lián)關(guān)系強;而正常評論中,評論者個體語言風格差異較大,詞節(jié)點間關(guān)聯(lián)聯(lián)系較弱。因此,在相同的高連邊閾值篩選下,虛假評論的節(jié)點規(guī)模仍能呈現(xiàn)完整的句式結(jié)構(gòu),而正常評論的詞匯僅存留部分短語關(guān)聯(lián)結(jié)構(gòu),詳情參見圖7(d)、圖8(d)。

圖7 正常評論詞匯共現(xiàn)網(wǎng)絡圖示例Fig.7 Example about co-occurrence word network of normal reviews
2.2.2 虛假評論的二階網(wǎng)絡圖統(tǒng)計分析
為進一步說明虛假評論與正常評論之間的區(qū)別,本文以“滿意”關(guān)鍵詞為中心,加工出與“滿意”關(guān)鍵詞建立一階連邊鄰居節(jié)點詞子網(wǎng)絡,又延展出一階鄰居節(jié)點的鄰居加工出詞共現(xiàn)網(wǎng)絡圖的二階鄰居子網(wǎng)絡,再按會員和非會員作對比分析,詳見圖9。
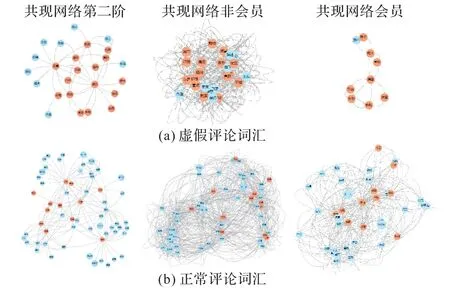
圖9 評論詞匯共現(xiàn)網(wǎng)絡二階圖示例Fig.9 Example of second-order diagram of co-occurrence word network for reviews
從節(jié)點的用詞來看,虛假評論中與“滿意”關(guān)鍵詞建立連邊的一階鄰居節(jié)點詞有“特別”“便宜”“購物”“價格”“東西”“收到”“喜歡”“寶貝”“值得”“購買”“質(zhì)量”“不錯”“真的”“打開”“商品”,而正常評論中與“滿意”關(guān)鍵詞建立連邊的節(jié)點詞有“拍照”“流暢”“超級”“效果”“做工”“收到”“系統(tǒng)”“不錯”“手感”“手機”“充電”,只有“不錯”和“收到”兩個詞是虛假評論和正常評論共有,虛假評論的語義表現(xiàn)為多態(tài)復雜性,既有主觀對話往來用語(如購物),也有表態(tài)用語(如喜歡、值得),更有客觀產(chǎn)品功能(如拍照、充電、流暢)。除主觀表態(tài)外,還混雜了多種關(guān)于產(chǎn)品功能等相互關(guān)聯(lián)的表態(tài)語義,通過簡單的特征提取是不易分辨的。
從圖9 可觀察到,正常評論的網(wǎng)絡節(jié)點數(shù)遠多于虛假評論。正常評論中,由于評論者個體異質(zhì)性,遣詞造句時涉及的詞匯較廣。從節(jié)點詞來看,正常評論中與“滿意”連邊數(shù)較多的節(jié)點詞有“手機”“超級”“滿意”“充電”“流暢”“拍照”等,與購買的產(chǎn)品、產(chǎn)品功能和使用體驗等反饋意見密切相關(guān),而虛假評論中連邊數(shù)據(jù)較多的節(jié)點詞聚焦于“滿意”和“質(zhì)量”,與“滿意”相連的多與購物過程和價格等有關(guān)。二階關(guān)系進一步擴大了虛假評論和正常評論的節(jié)點詞間的差異。
為說明圖結(jié)構(gòu)對虛假評論識別的有效性,本文基于上述評論集,整理出虛假評論典型句式如表1。類型Ⅰ出現(xiàn)了系統(tǒng)默認昵稱“寶貝”,盲目夸贊的無邏輯短語堆疊現(xiàn)象比較明顯;類型Ⅱ中,夸大服務感受和誘惑導購型搭配語句成串出現(xiàn)。
在Text GCN 模型下,固定搭配信息通過圖二階鄰居節(jié)點作關(guān)聯(lián)結(jié)構(gòu)的信息傳遞。通過圖結(jié)構(gòu)的關(guān)聯(lián)關(guān)系,即使句子不完整,仍可通過隱性的典型特征結(jié)構(gòu)識別虛假評論。典型的虛假評論圖結(jié)構(gòu)如圖10 所示。
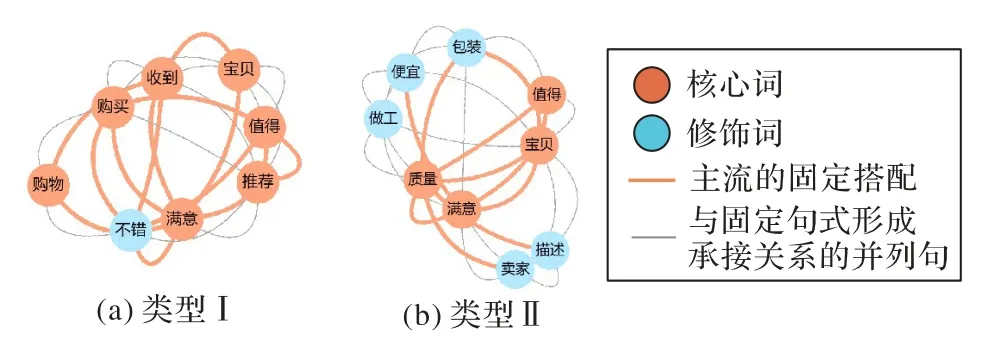
圖10 虛假評論典型句式圖結(jié)構(gòu)Fig.10 Typical sentence pattern structures of fake reviews
2.2.3 評論者特征差異
除文本信息差異外,虛假評論和正常評論的差異還體現(xiàn)在評論者特征上。從本文采集的126 086 條評論的評論者特征(非文本特征)中,發(fā)現(xiàn)用戶會員M、評論圖片P、評論視頻V 這3 個評論者相關(guān)特征與虛假評論占比存在顯著關(guān)系。對于評論者為會員用戶、評論時包含圖片或視頻的評論,其虛假評論的占比較低。為引入與虛假評論產(chǎn)生相關(guān)的評論者特征及其關(guān)聯(lián)信息,本文對非文本特征節(jié)點與評論節(jié)點的關(guān)聯(lián)關(guān)系作如下設(shè)計:在雙層GCN 的作用下,產(chǎn)生“評論-非文本特征-評論”關(guān)聯(lián)關(guān)系的評論節(jié)點更容易屬于同類節(jié)點并交互信息。
綜上所述,虛假評論和正常評論在詞關(guān)聯(lián)強度、詞關(guān)聯(lián)結(jié)構(gòu)和評論者特征上存在明顯差異。通過詞匯網(wǎng)絡圖可提取正常評論和虛假評論之間在結(jié)構(gòu)上和用詞上的差異,并且二階鄰接矩陣相較于一階鄰接矩陣能提供更多的差異性信息。F-Text GCN引入圖結(jié)構(gòu)信息和評論者特征,可提取評論中的文本內(nèi)容差異,提升模型的識別能力。虛假評論的語義表現(xiàn)為多態(tài)復雜性,既有主觀對話往來用語,也有表態(tài)用語,更有誘導夸大客觀產(chǎn)品功能的現(xiàn)象,傳統(tǒng)的特征提取則不易于分辨。
3 實證研究
實驗主要在Windows11 環(huán)境下完成,基于Pytorch 框架,CPU 為Intel Core i7-4790K CPU @ 4.00 GHz 4.00 GHz,編程語言為Python3.8。基于GMM 的滑動窗口與選擇模塊的編程語言為R4.0.2,其中GMM 的使用參考Mclust 包。F-Text GCN 模型包含雙層GCN,將第1 個卷積層的嵌入大小設(shè)置為200,窗口大小設(shè)置為20,學習率設(shè)置為0.02,dropout設(shè)置為0.5,L2 損失權(quán)重設(shè)置為0。隨機選擇10%的訓練集作為驗證集。使用Adam 訓練Text GCN 最多200 次迭代,若驗證損失連續(xù)10 次迭代都沒有減小,則停止訓練。本文使用準確率(P)、召回率(R)和F1 值(F1)作為評價指標,計算公式如下:
其中:TP表示將虛假評論類判斷成虛假評論類的數(shù),F(xiàn)P表示將正常評論類判斷為虛假評論類的數(shù),F(xiàn)N表示將虛假評論類判斷成正常評論類的數(shù)。
3.1 有效性實驗
為驗證F-Text GCN 在識別虛假評論上的有效性,本文將在信息源是否引入非文本特征標簽上將它與Text CNN 比較,只含純文本的圖卷積結(jié)果記為Text GCN,不含圖卷積的卷積記為Text CNN;將引入非文本特征并經(jīng)GMM 作用的新圖卷積算法記為F-Text GCN,不含圖卷積的普通卷積記為F-Text CNN,以BERT 作為基線模型。將數(shù)據(jù)集中的126 086條評論,按8∶2 的比例對虛假評論和正常評論獨立劃分,將劃分得到的80%的虛假評論和80%的正常評論組合為訓練集,并將剩余的虛假評論和正常評論組合為測試集,實驗結(jié)果如表2 所示。
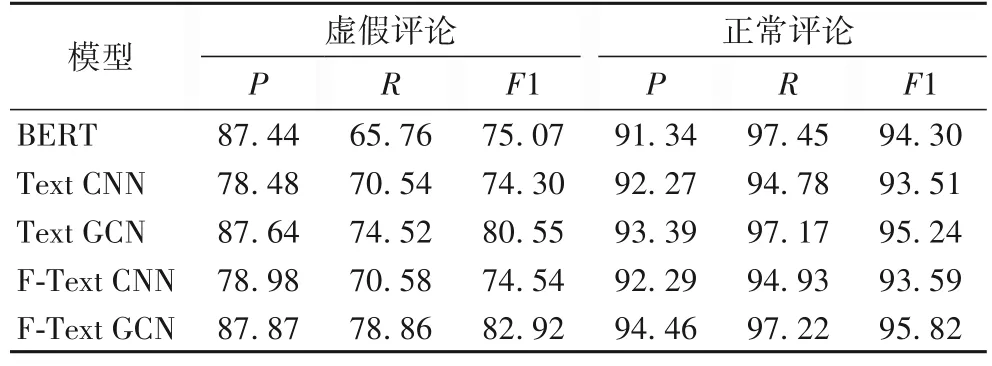
表2 幾種模型評論識別性能比較 單位:%Tab.2 Comparison of review detection performance among different models unit:%
由表2 可知,與Text CNN、F-Text CNN 和BERT 相比,Text GNN 和F-Text GCN 模型準確率、召回率和F1 值均較高。F-Text GCN 識別虛假評論的F1 值達到82.92%,比BERT 提高了10.46%,比Text CNN 提高了11.60%,比F-Text CNN 提高了11.24%,比Text GCN 提高了2.94%。由表2 還可知,F(xiàn)-Text GCN 的虛假評論召回率比Text GCN 提高了5.82%,表明評論者特征的引入改善了模型對虛假評論的識別效果。除引入了非文本特征信息外,還更新了文本網(wǎng)絡圖結(jié)構(gòu),在一定程度緩解了數(shù)據(jù)的稀疏性,增強了虛假評論特征的信號強度,有助于虛假評論的識別。
3.2 基于不同的窗口邊權(quán)閾值的敏感性實驗
引入圖信息的虛假評論識別模型,對虛假評論圖信號強度的把控至關(guān)重要。為驗證Text GCN 和F-Text GCN 對窗口邊權(quán)閾值的敏感性,本文設(shè)置了一組窗口邊權(quán)閾值,觀察新提出的F-Text GCN 的效果隨窗口邊權(quán)閾值變化的情況。實驗結(jié)果如圖11 所示。
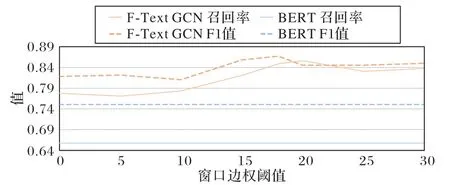
圖11 不同的窗口邊權(quán)閾值測試時召回率和F1值Fig.11 Recall and F1 values of testing with different window edge weight thresholds
由圖11 觀察到,F(xiàn)-Text GCN 測試召回率和F1 值隨著窗口邊權(quán)閾值的增大而增加,當窗口邊權(quán)閾值大于20 時,召回率和F1 值上升緩慢。這一結(jié)果驗證了本文提出的通過GMM 預訓練模塊選擇窗口邊權(quán)閾值的有效性,實驗窗口大小在15~20 比較合適。
3.3 難分辨評論的穩(wěn)定性對比實驗
為進一步確認圖卷積類算法對虛假評論識別方面的性能穩(wěn)定性,并探究識別能力效果提升的原因,將Text GCN 和F-Text GCN 兩種深度學習算法與主流的虛假評論識別淺層模型進行比較。實驗中,為獲得難區(qū)分相似樣本的學習情況,將SVM 訓練時易錯的13 065 條評論按訓練數(shù)據(jù)與測試數(shù)據(jù)8∶2 的比例拆分,其中訓練數(shù)據(jù)10 452 條和測試數(shù)據(jù)2 613條,兩組的虛假評論和正常評論比例保持在1∶4,對Text GCN 和F-Text GCN 訓練和測試,重復20 次訓練得到測試結(jié)果如表3 所示。

表3 難區(qū)分數(shù)據(jù)上的Text GCN和F-Text GCN實驗結(jié)果Tab.3 Comparison of experiment results between Text GCN and F-Text GCN with confusing data
從表3 結(jié)果可以看出,文本圖卷積算法在使用淺層模型難分辨的評論作為訓練集時,能取得較好的識別效果;Text GCN 和F-Text GCN 的標準差均小于0.05,表明模型穩(wěn)定性也較好。
綜上所述,對于SVM 性能不佳的難識別評論,F(xiàn)-Text GCN 和Text GCN 的識別效果均有顯著提升,且F-Text GCN 對虛假評論識別準確率略高于Text GCN,這與F-Text GCN 引入的非文本特征標簽有關(guān),引入的非文本特征標簽豐富了模型的文本圖節(jié)點和關(guān)系信息。
3.4 消融實驗
為探究非文本特征引入模型的影響,本文設(shè)計消融實驗,將三類非文本特征對應的連邊關(guān)系及其組合引入圖結(jié)構(gòu),實驗設(shè)計如表4。
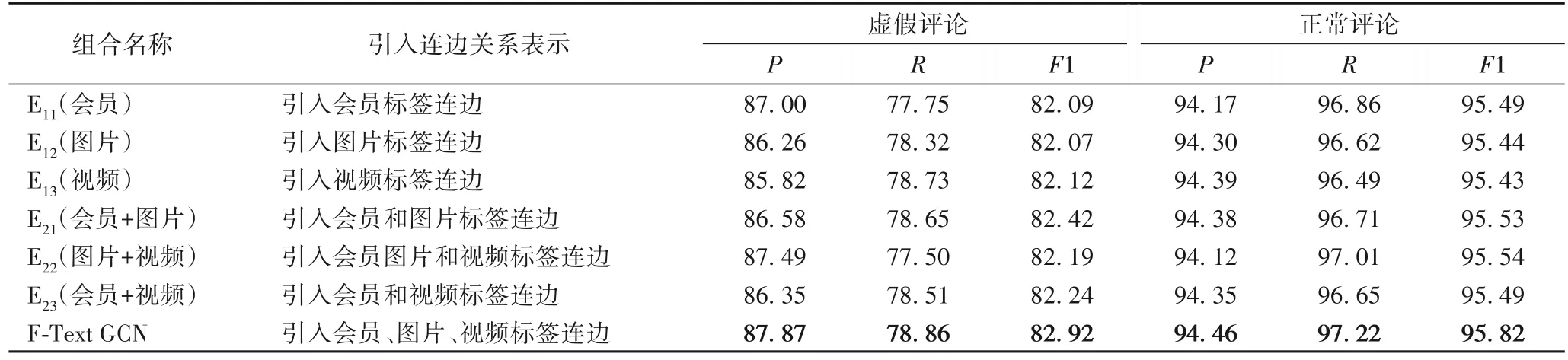
表4 消融實驗設(shè)計和結(jié)果 單位:%Tab.4 Design and results of ablation experiments unit:%
從表4 可知:整體上,三種非文本特征關(guān)聯(lián)關(guān)系的引入后在準確率上與Text-GCN 基本持平,都在85%以上。本文所提的F-Text GCN 對于虛假評論的識別效果在準確率和召回率上都是最佳的。對虛假評論的召回率,相對于其他模型有3%~5%的提升,表明引入GMM 預訓練模塊和非文本特征可有效降低虛假評論的漏檢率。值得注意的是,會員+圖片、會員+視頻比單獨使用會員標簽時都出現(xiàn)了準確率略微下降的現(xiàn)象,準確率下降造成的假陽率略微升高是由于虛假評論在人工標注的執(zhí)行規(guī)則較為嚴格所致,假陽率略微升高檢測出的虛假評論經(jīng)專家判斷應為高度疑似虛假,可作為推進虛假評論監(jiān)測治理力度的有力證據(jù)。
4 結(jié)語
本文提出用GMM 與Text GCN 合成的F-Text GCN 識別虛假評論,引入窗口預選擇模塊,將組合評論文本中的詞匯和非文本特征進行多標簽節(jié)點構(gòu)圖,對節(jié)點的文本標簽信息和節(jié)點之間的一階和二階鄰域信息進行延伸表示,通過詞匯網(wǎng)絡圖,提取正常評論和虛假評論之間在結(jié)構(gòu)上和用詞上的差異。研究表明:
1)F-Text GCN 模型將文本以圖的形式表示,顯著提升了虛假評論的識別效果。
2)基于混合高斯分布估計和自助檢驗方法設(shè)計的窗口邊權(quán)閾值的選擇方法,增強了模型對虛假評論詞關(guān)聯(lián)結(jié)構(gòu)的分離感知能力。
3)虛假評論與正常評論的差異表現(xiàn)為:虛假評論在詞匯豐富程度上低于正常評論;虛假評論詞庫與正常評論詞庫存在一定重疊,但在一階及二階的詞匯用詞與結(jié)構(gòu)上存在明顯差異。實驗結(jié)果表明,詞庫上的差異體現(xiàn)在F-Text GCN 可有效提取二階固定句式特征,有助于通過固定搭配預報虛假評論的決策管理。
4)F-Text GCN 模型引入了評論者特征(非文本特征)信息,添加了評論節(jié)點間的關(guān)聯(lián)結(jié)構(gòu),能通過發(fā)現(xiàn)非會員屬性提升虛假評論的識別效果。在SVM 預測錯誤的難區(qū)分評論識別中,F(xiàn)-Text GCN 和Text GCN 性能明顯更優(yōu),穩(wěn)定性更好。
F-Text GCN 模型在虛假評論識別任務中取得了較好效果。本文僅探討二元高斯分布的噪聲分離能力,在算法方面可繼續(xù)關(guān)注影響圖卷積漏檢特征的參數(shù)調(diào)節(jié)問題,進一步可以研究由多分支構(gòu)成的混合高斯分布在檢測虛假評論中的詞語結(jié)構(gòu)的作用;在引入非文本特征關(guān)聯(lián)時,關(guān)于關(guān)聯(lián)關(guān)系中防止過平滑性風險的參數(shù)設(shè)定也是值得考慮的問題;在信息提取方面可進一步研究包括虛假評論固定搭配的層次提取和隨時間的動態(tài)演化規(guī)律等。本文采用虛假評論相較于正常評論比例偏低的數(shù)據(jù)實證研究,暴露了虛假評論僅依靠人工打標的局限性,能為現(xiàn)有虛假評論自動檢測提供廣泛的技術(shù)實踐支持。
猜你喜歡
當代陜西(2021年17期)2021-11-06 03:21:36
開放教育研究(2020年2期)2020-03-31 01:54:14
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
學苑創(chuàng)造·A版(2018年11期)2018-02-01 06:29:20
數(shù)學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
讀者(2017年5期)2017-02-15 18:04:18
現(xiàn)代語文(2016年21期)2016-05-25 13:13:44
大連民族大學學報(2015年2期)2015-02-27 08:28:11
河南科技(2014年23期)2014-02-27 14:19:15
