基于雙曲嵌入的露天礦區(qū)暗光環(huán)境下道路多目標(biāo)檢測(cè)模型
2024-03-01 09:53:26顧清華蘇存玲王倩陳露熊乃學(xué)
工礦自動(dòng)化 2024年1期
顧清華, 蘇存玲, 王倩, 陳露, 熊乃學(xué)
(1. 西安建筑科技大學(xué) 資源工程學(xué)院,陜西 西安 710055;2. 西安建筑科技大學(xué) 西安市智慧工業(yè)感知計(jì)算與決策重點(diǎn)實(shí)驗(yàn)室,陜西 西安 710055;3. The Department of Computer,Mathematics and Physical Science Sul Ross State University,Alpine,TX 79830,USA)
0 引言
隨著自動(dòng)駕駛技術(shù)不斷發(fā)展,露天礦區(qū)無(wú)人礦用卡車(chē)(以下稱(chēng)礦卡)逐步投入應(yīng)用。由于礦區(qū)環(huán)境特殊,道路場(chǎng)景復(fù)雜多變,在光照不足時(shí)會(huì)使礦區(qū)道路多目標(biāo)識(shí)別不清、定位不準(zhǔn),進(jìn)而影響檢測(cè)效果,給無(wú)人礦卡的安全行駛帶來(lái)嚴(yán)重安全隱患,因此亟需對(duì)露天礦區(qū)暗光環(huán)境下道路多目標(biāo)精準(zhǔn)檢測(cè)展開(kāi)研究。
道路障礙物檢測(cè)方法主要包括基于機(jī)器視覺(jué)、基于毫米波雷達(dá)、基于毫米波雷達(dá)與其他傳感器融合的檢測(cè)方法3 類(lèi)。基于機(jī)器視覺(jué)的障礙物檢測(cè)方法應(yīng)用較為廣泛,可分為雙階段檢測(cè)和單階段檢測(cè)。經(jīng)典雙階段檢測(cè)算法(如R-CNN[1-3]等)需先生成候選框再進(jìn)行目標(biāo)檢測(cè),檢測(cè)速度慢,不適用于對(duì)實(shí)時(shí)性要求較高的場(chǎng)景。而單階段檢測(cè)算法只需一次特征提取即可實(shí)現(xiàn)目標(biāo)檢測(cè),如單步多框目標(biāo)檢測(cè) (Single Shot MultiBox Detector, SSD)[4-6]、YOLO 系列[7-10]等,雖然檢測(cè)速度快,但檢測(cè)精度比雙階段檢測(cè)算法低,可通過(guò)改進(jìn)模型來(lái)提升檢測(cè)精度,因此單階段檢測(cè)算法在道路障礙物檢測(cè)方面應(yīng)用居多。文獻(xiàn)[11]在模型預(yù)處理階段進(jìn)行數(shù)據(jù)增強(qiáng),以提高YOLO 模型對(duì)小目標(biāo)的檢測(cè)性能。文獻(xiàn)[12]針對(duì)結(jié)構(gòu)復(fù)雜、參數(shù)龐大的SSD 模型進(jìn)行骨干改進(jìn),以降低延時(shí),提升檢測(cè)精度。文獻(xiàn)[13]通過(guò)對(duì)YOLOv3 模型進(jìn)行圖像裁剪,生成適合網(wǎng)絡(luò)輸入的數(shù)據(jù)尺寸,并通過(guò)引入旋轉(zhuǎn)邊界框的方法實(shí)現(xiàn)目標(biāo)的快速識(shí)別與定位。上述研究雖有效提升了單階段檢測(cè)算法的檢測(cè)精度,但均未考慮環(huán)境光照對(duì)檢測(cè)效果的影響。為此,許多學(xué)者針對(duì)環(huán)境光照對(duì)檢測(cè)精度的影響進(jìn)行了相關(guān)研究。文獻(xiàn)[14]基于熱特征的負(fù)障礙物檢測(cè),根據(jù)夜間環(huán)境下障礙物散熱情況,對(duì)紅外圖像進(jìn)行局部強(qiáng)度剖析以確認(rèn)障礙物,但障礙物附近的非目標(biāo)物體會(huì)使周?chē)鷾囟壬仙绊憴z測(cè)準(zhǔn)確率,且該方法僅限于在夜間應(yīng)用。毫米波雷達(dá)抗干擾能力強(qiáng),可解決外界天氣對(duì)障礙物識(shí)別的影響[15-16],但易受雜波干擾,分辨率較低,無(wú)法精確識(shí)別反射界面較小的物體。針對(duì)該問(wèn)題文獻(xiàn)[17-18]提出將毫米波雷達(dá)與其他傳感器融合的方法,實(shí)驗(yàn)表明該融合方法能夠解決單傳感器檢測(cè)不準(zhǔn)的問(wèn)題,但對(duì)于特殊場(chǎng)景的礦區(qū),易受到濕度、溫度、大氣壓等因素的影響,不能在暗光環(huán)境下精確檢測(cè)障礙物,且使用成本過(guò)高,不利于礦區(qū)實(shí)際應(yīng)用。文獻(xiàn)[19]受自然視覺(jué)視網(wǎng)膜機(jī)制啟發(fā),開(kāi)發(fā)了夜間圖像增強(qiáng)方法,該方法不受夜間濕度、溫度等因素影響,對(duì)車(chē)輛有較好的檢測(cè)效果,但有效的監(jiān)控?cái)z像機(jī)系統(tǒng)建立的前提條件難以滿足,適用范圍受限。
研究表明,現(xiàn)有檢測(cè)模型均有一定的弊端,不能有效解決礦區(qū)暗光環(huán)境對(duì)模型檢測(cè)效果的影響,同時(shí)對(duì)礦區(qū)小目標(biāo)障礙物的識(shí)別也有較大誤差,不適用于礦區(qū)特殊環(huán)境下障礙物的檢測(cè)與識(shí)別,本文提出一種基于雙曲嵌入的露天礦區(qū)暗光環(huán)境下道路多目標(biāo)檢測(cè)模型。首先,在模型預(yù)處理階段通過(guò)暗光環(huán)境增強(qiáng)算法提高圖像質(zhì)量;然后,在模型加強(qiáng)特征提取部分引入全局注意力機(jī)制(Global Attention Mechanism,GAM),增加網(wǎng)絡(luò)對(duì)礦區(qū)小目標(biāo)的特征偏好,提高目標(biāo)特征表達(dá)能力;最后,在網(wǎng)絡(luò)的Head 層引入雙曲全連接層,解決因目標(biāo)尺寸差距過(guò)大導(dǎo)致檢測(cè)難度大的問(wèn)題,進(jìn)而提升整個(gè)模型檢測(cè)精度與速度。
1 YOLOv5 算法
基于露天礦區(qū)對(duì)目標(biāo)檢測(cè)精度及速度的要求,選用YOLOv5 單階段檢測(cè)算法,其網(wǎng)絡(luò)結(jié)構(gòu)如圖1所示。

圖1 YOLOv5 網(wǎng)絡(luò)結(jié)構(gòu)Fig. 1 YOLOv5 network structure
該網(wǎng)絡(luò)由Input、Backbone、Neck、Head 4 個(gè)部分構(gòu)成。輸入的圖像分辨率為640×640。Backbone 包含數(shù)據(jù)預(yù)處理及特征提取2 個(gè)部分。預(yù)處理包括Mosaic(馬賽克)數(shù)據(jù)增強(qiáng)、自適應(yīng)錨框計(jì)算及自適應(yīng)圖像縮放;特征提取由Focus 切片結(jié)構(gòu)[20]、跨階段局部網(wǎng)絡(luò)(Cross Stage Paritial Network,CSP)[21]層結(jié)構(gòu)及空間金字塔池化(Spatial Pyramid Pooling,SPP)[22]3 個(gè)部分組成。Neck 采用特征金字塔(Feature Pyramid Networks, FPN) +路徑聚合網(wǎng)絡(luò)(Path Aggregation Network,PAN)[23-24]結(jié)構(gòu),對(duì)骨干特征提取的3 個(gè)有效特征層分別進(jìn)行上下采樣,融合特征通道,以提升網(wǎng)絡(luò)整體性能。Head 將Neck 層提取的3 個(gè)加強(qiáng)特征層進(jìn)行分類(lèi)與回歸預(yù)測(cè),對(duì)目標(biāo)進(jìn)行準(zhǔn)確識(shí)別與定位。
2 基于改進(jìn)YOLOv5 露天礦區(qū)暗光環(huán)境目標(biāo)檢測(cè)方法
YOLOv5 模型未考慮暗光環(huán)境對(duì)檢測(cè)效果的影響,無(wú)法將此模型直接用于礦區(qū)暗光環(huán)境障礙物檢測(cè)。為解決暗光環(huán)境的影響,在模型的圖像預(yù)處理階段引入Retinex-Net 卷積神經(jīng)網(wǎng)絡(luò)[25-26],對(duì)暗光圖像進(jìn)行增強(qiáng),提高圖像清晰度;針對(duì)數(shù)據(jù)集中特征過(guò)多而無(wú)重點(diǎn)偏好的問(wèn)題,在加強(qiáng)特征提取部分添加GAM[27],聚集3 個(gè)維度上更關(guān)鍵的特征信息,這對(duì)小尺寸目標(biāo)十分重要;為減少模型參數(shù)及處理過(guò)擬合問(wèn)題,在模型預(yù)測(cè)部分嵌入雙曲全連接層,以提升網(wǎng)絡(luò)整體檢測(cè)效果。
2.1 Retinex-Net 暗光環(huán)境圖像增強(qiáng)
露天礦區(qū)存在非結(jié)構(gòu)化道路坡度大、環(huán)境多變等特點(diǎn),極易導(dǎo)致無(wú)人礦卡在暗光環(huán)境下難以準(zhǔn)確檢測(cè)礦區(qū)道路目標(biāo)。為解決礦區(qū)光照不均、遠(yuǎn)距離暗光及低分辨率3 類(lèi)不同場(chǎng)景對(duì)礦區(qū)車(chē)輛和行人檢測(cè)效果的影響,本文在YOLOv5 模型預(yù)處理階段采用Retinex-Net 網(wǎng)絡(luò)增強(qiáng)暗光圖像,提高圖像整體質(zhì)量,以滿足礦區(qū)暗光環(huán)境的檢測(cè)需求。該模型結(jié)構(gòu)如圖2 所示,效果如圖3 所示。該模型主要由分解模塊(Decom-Net)、調(diào)整模塊和重建模塊3 個(gè)部分組成。
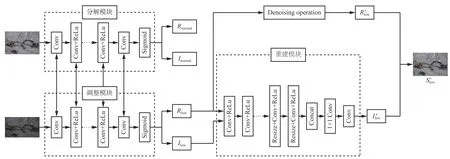
圖2 Retinex-Net 網(wǎng)絡(luò)結(jié)構(gòu)Fig. 2 Retinex-Net network structure

圖3 Retinex-Net 圖像增強(qiáng)前后效果對(duì)比Fig. 3 Image comparison before and after Retinex-Net enhancement
分解模塊主要由5 層帶有ReLu 的卷積神經(jīng)網(wǎng)絡(luò)組成,將暗光圖像和正常光照?qǐng)D像作為輸入數(shù)據(jù)對(duì),共享網(wǎng)絡(luò)參數(shù),得到暗光圖像的反射分量Rlow、光照分量Ilow及正常光照?qǐng)D像的反射分量Rnormal、光照分量Inormal。利用Rlow,Ilow,Rnormal,Inormal之間的約束關(guān)系優(yōu)化模型。該模型的損失函數(shù)由重建損失?recon、反射分量一致性損失 ?ir和光照分量平滑損失 ?is3 個(gè)部分組成。
式中: λi j為重構(gòu)系數(shù);Ri為圖像反射分量;Ij為光照分量;Sj為未分解的完整圖像,使模型分解出的反射分量和光照分量能夠重建對(duì)應(yīng)的原圖; ?為梯度算子,包含水平和垂直梯度; λg為平衡結(jié)構(gòu)意識(shí)強(qiáng)度系數(shù)。
式(3)通過(guò)反射分量為光照分量的梯度圖分配相應(yīng)的權(quán)重,使得反射分量與對(duì)應(yīng)的光照分量在確保圖像細(xì)節(jié)上盡可能平滑的同時(shí),仍能夠保持圖像整體的邊界結(jié)構(gòu)完整。
調(diào)整模型主要是對(duì)Rnormal和Inormal進(jìn)行調(diào)整,采用BM3D 算法對(duì)Rnormal進(jìn)行噪聲抑制,采用多尺度encode-decoder 架構(gòu)對(duì)Inormal進(jìn)行調(diào)整,使網(wǎng)絡(luò)能捕獲更大范圍的關(guān)于光照分布的上下文細(xì)節(jié)信息,以提高自適應(yīng)調(diào)整能力。
2.2 基于GAM 的加強(qiáng)特征提取
針對(duì)礦區(qū)小尺度目標(biāo)易被忽略、無(wú)特征偏好及在CSP 層結(jié)構(gòu)中因避免梯度消失而導(dǎo)致顯存過(guò)大并產(chǎn)生特征弱化現(xiàn)象的問(wèn)題,在YOLOv5 網(wǎng)絡(luò)加強(qiáng)特征提取階段引入GAM,以減少信息彌散,增強(qiáng)小尺度目標(biāo)特征的表達(dá)能力,進(jìn)而放大全局維度交互特征的能力。
基于GAM 加強(qiáng)特征提取的檢測(cè)模型如圖4 所示。首先將圖像數(shù)據(jù)分辨率調(diào)整至640×640,引入GAM 模塊;然后將調(diào)整好分辨率的圖像數(shù)據(jù)輸入網(wǎng)絡(luò)進(jìn)行訓(xùn)練,獲取相應(yīng)訓(xùn)練權(quán)重;最后利用權(quán)重進(jìn)行預(yù)測(cè)驗(yàn)證。
GAM 模塊如圖5 所示,其中C,W,H分別為輸入特征圖的通道數(shù)及其寬和高,其運(yùn)算原理為

圖5 GAM 模塊Fig. 5 GAM module
式中:f1為網(wǎng)絡(luò)輸入的有效特征圖;為f1經(jīng)過(guò)通道注意力模塊處理后的有效特征圖;Mc為空間注意力圖; ?為按照特征元素進(jìn)行乘法操作。f_out為經(jīng)過(guò)空間注意力模塊處理后最終的輸出特征圖;Ms為通道注意力圖。
該模型將f1輸入通道注意力模塊,使用三維排列來(lái)保留3 個(gè)維度上的信息和兩層的多層感知機(jī)(Multilayer Perceptron,MLP),來(lái)放大跨維度通道-空間依賴性;將在空間注意力模塊中使用2 個(gè)卷積層進(jìn)行空間信息的融合,并從通道注意力模塊中使用與瓶頸注意力模塊(Bottleneck attention Module,BAM)相同的縮減比a,通過(guò)2 次7×7 的卷積保持通道數(shù)一致。本文在模型加強(qiáng)特征提取部分的4 個(gè)CSP 模塊后分別引入GAM,以解決卷積注意力模塊(Convolutional Block Attention Module,CBAM)中最大池化操作會(huì)減少特征信息的問(wèn)題,使整個(gè)網(wǎng)絡(luò)更關(guān)注感興趣區(qū)域及全局特征。進(jìn)行雙曲嵌入,二維Poincare 球模型如圖6 所示,嵌入模型如圖7 所示。

圖6 Poincare 球模型Fig. 6 Poincare ball model

圖7 Hyperbolic-YOLOv5 head 模型Fig. 7 Hyperbolic-YOLOv5 head model
2.3 基于雙曲嵌入的YOLOv5-Head 模型優(yōu)化
通常復(fù)雜數(shù)據(jù)常表現(xiàn)出較高非歐氏的潛在聯(lián)系,無(wú)法給出較可靠的幾何表示,導(dǎo)致模型不能準(zhǔn)確提取有效特征而影響檢測(cè)效果。具有負(fù)曲率的雙曲空間[28-30]有較強(qiáng)的數(shù)據(jù)建模能力,對(duì)于有層次結(jié)構(gòu)的數(shù)據(jù),該空間能夠使檢測(cè)模型更加緊湊,具有更強(qiáng)的物理可解釋性,且對(duì)網(wǎng)絡(luò)復(fù)雜性和訓(xùn)練數(shù)據(jù)要求低,可解決參數(shù)冗余問(wèn)題。雙曲空間常見(jiàn)推廣模型即Poincare 球,其是一個(gè)m維雙曲幾何模型,也稱(chēng)為共形圓盤(pán)模型。該模型幾何中的點(diǎn)均在Poincare球的內(nèi)部,幾何中心的測(cè)地線對(duì)應(yīng)任意垂直于圓盤(pán)邊界的圓弧或圓盤(pán)的直徑。根據(jù)Poincare 球的幾何性質(zhì),可對(duì)實(shí)體進(jìn)行層次性建模,這是探索嵌入結(jié)構(gòu)層次性信息的關(guān)鍵性質(zhì)。本文選擇Poincare 球模型針對(duì)模型因提取特征不全面而影響檢測(cè)效果的問(wèn)題,本文將模型Neck 層輸出的3 個(gè)有效特征層嵌入雙曲空間進(jìn)行全連接層分類(lèi)。全連接變換即線性變換,將歐氏空間Y=Ax+b映射至雙曲空間,并進(jìn)行雙曲空間中全連接運(yùn)算,利用矩陣向量乘法構(gòu)造。
式中:Y為模型對(duì)輸入數(shù)據(jù)處理后最終的輸出結(jié)果;A為所選參數(shù);x為輸入網(wǎng)絡(luò)模型中的變量;b為線性變化的偏置參數(shù);log0x為莫比烏斯標(biāo)量乘法通過(guò)在切空間中以0 為點(diǎn)投影至x。
將歐氏空間全連接映射至雙曲空間進(jìn)行處理后,再反映射回歐氏空間,此過(guò)程稱(chēng)為雙向映射。指數(shù)映射定義了從歐氏空間到Poincare 球模型的映射,即
式中: ⊕c為雙曲空間中的加法運(yùn)算;c為曲率值;為保形因子。
偏置可通過(guò)莫比烏斯平移表示,首先將偏置映射至Poincare 球模型原點(diǎn)切線空間,然后將其平移至含偏置的新切線空間,最后將結(jié)果反映射回原模型。映射關(guān)系為
式中: PT為Paallel Transport 并行傳輸; λ0, λx為并行傳輸對(duì)應(yīng)的結(jié)果。
Poincare 球模型中的2 個(gè)變量x、Y求和定義為
莫比烏斯標(biāo)量乘法等同歐氏空間乘法,當(dāng)c=0 時(shí)退化為歐氏空間,即
式中:e為標(biāo)量因子; ?c為雙曲空間下的乘法運(yùn)算。
雙曲模型內(nèi)部是指數(shù)型運(yùn)算,該運(yùn)算有利于模型獲取數(shù)據(jù)的底層信息,對(duì)目標(biāo)精確分類(lèi)。因此,將歐氏空間內(nèi)的運(yùn)算推廣至雙曲空間可提升模型整體的檢測(cè)效果。
3 實(shí)驗(yàn)與分析
實(shí)驗(yàn)平臺(tái)軟硬件配置見(jiàn)表1。在模型訓(xùn)練參數(shù)的設(shè)置中,將輸入檢測(cè)模型的圖像尺寸調(diào)整至640×640×3,動(dòng)量因子為0.937,模型訓(xùn)練優(yōu)化器為SGD,學(xué)習(xí)率下降方式選用cos,初始學(xué)習(xí)率為0.001,批次大小為8,置信度閾值為0.5,根據(jù)損失收斂確定模型迭代2 500 次。對(duì)比模型訓(xùn)練參數(shù)與之保持一致。

表1 實(shí)驗(yàn)平臺(tái)軟硬件配置Table 1 Hardware and software configuration of experimental platform
3.1 數(shù)據(jù)集構(gòu)建
實(shí)驗(yàn)數(shù)據(jù)集源于某露天礦,通過(guò)海康威視紅外雙目攝像頭實(shí)地采集,共獲取788 張圖像。利用labelimg 對(duì)數(shù)據(jù)集進(jìn)行標(biāo)注,并按照(訓(xùn)練集+驗(yàn)證集)∶測(cè)試集=(8+1)∶1 的比例對(duì)礦區(qū)數(shù)據(jù)集進(jìn)行劃分。由于礦區(qū)環(huán)境特殊,導(dǎo)致收集數(shù)據(jù)量過(guò)少,所以采用Mixup 數(shù)據(jù)增強(qiáng)方法將數(shù)據(jù)擴(kuò)增至原數(shù)量的6 倍,再將圖像調(diào)至640×640 后輸入檢測(cè)模型。對(duì)于礦區(qū)場(chǎng)景的特殊性,將礦區(qū)非結(jié)構(gòu)化道路上的檢測(cè)目標(biāo)——小型廂車(chē)、礦卡、礦卡2、礦卡3、灑水車(chē)、挖機(jī)、電鉆挖機(jī)、行人、鏟土機(jī)、電車(chē)分為3 大類(lèi),即挖機(jī)、非同類(lèi)型礦卡及行人。
3.2 模型評(píng)價(jià)指標(biāo)
檢測(cè)模型可用混淆矩陣作為評(píng)價(jià)指標(biāo),通常用n行n列矩陣表示,見(jiàn)表2。
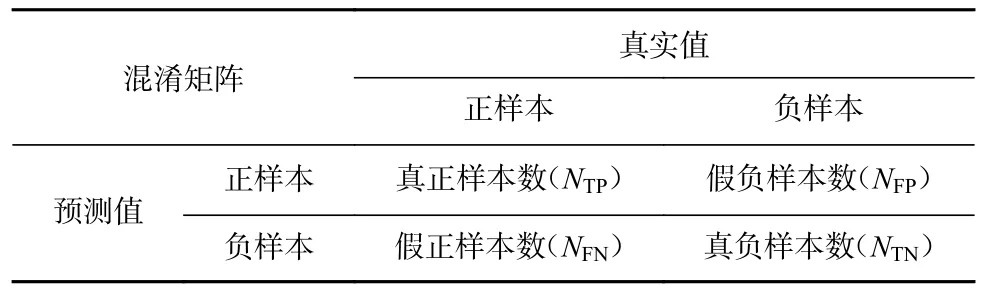
表2 混淆矩陣評(píng)價(jià)Table 2 Confusion matrix evolution
基于混淆矩陣的評(píng)價(jià)指標(biāo)有精確率、召回率、平均精度、準(zhǔn)確率、F1度量,其計(jì)算方法見(jiàn)表3。其中B為檢測(cè)的目標(biāo)數(shù)量,檢測(cè)模型綜合評(píng)價(jià)指標(biāo)越高,表示模型性能越好。

表3 混淆矩陣性能指標(biāo)計(jì)算公式Table 3 Calculation formula of performance indexs of confusion matrix
3.3 實(shí)驗(yàn)結(jié)果與分析
基于雙曲嵌入的露天礦區(qū)暗光環(huán)境下道路多目標(biāo)檢測(cè)模型的檢測(cè)結(jié)果由遠(yuǎn)端和車(chē)載顯示器展示,結(jié)果如圖8 所示。

圖8 基于雙曲嵌入的露天礦區(qū)暗光環(huán)境下道路多目標(biāo)檢測(cè)模型檢測(cè)效果Fig. 8 Detection effect of road multi-object detection model based on hyperbolic embedding in dark environment in open pit mine
實(shí)驗(yàn)結(jié)果表明:該模型不僅對(duì)露天礦區(qū)暗光環(huán)境下的大尺度目標(biāo)分類(lèi)與定位精度較高,對(duì)礦卡及較遠(yuǎn)距離的小尺度目標(biāo),即行人也可準(zhǔn)確檢測(cè)和定位,能夠滿足無(wú)人礦卡在礦區(qū)特殊環(huán)境下駕駛的安全需求。由圖8(a)、圖8(d)可看出,模型利用Retinex-Net 將暗光處的像素動(dòng)態(tài)擴(kuò)展,可提高整體可視化,降低光照對(duì)目標(biāo)的干擾,提升檢測(cè)效果;由圖8(b)、圖8(e)可看出,對(duì)于礦卡、挖機(jī)及行人這類(lèi)尺度差距較大的目標(biāo),模型利用GAM 后,對(duì)不同尺度特征用不同加權(quán)方式,弱化非檢測(cè)對(duì)象的特征表達(dá),提高檢測(cè)準(zhǔn)確性;由圖8(c)、圖8(f)可看出,對(duì)于常見(jiàn)低分辨率圖像,先處理光照,再在模型輸出階段通過(guò)雙曲模型獲得更底層的特征信息,可進(jìn)一步提高圖像整體檢測(cè)效果。
為驗(yàn)證礦區(qū)暗光環(huán)境道路多尺度目標(biāo)提出的圖像增強(qiáng)、GAM 及雙曲全連接層的有效性,開(kāi)展消融實(shí)驗(yàn)進(jìn)行性能驗(yàn)證。以YOLOv5 網(wǎng)絡(luò)模型為基礎(chǔ)模型,分別驗(yàn)證加入Retinex-Net、GAM、雙曲全連接層后的效果,并將3 種改進(jìn)策略同時(shí)加入基礎(chǔ)模型,進(jìn)行驗(yàn)證,結(jié)果見(jiàn)表4。可看出在YOLOv5 網(wǎng)絡(luò)模型中分別使用Retinex-Net、GAM、雙曲全連接層后,模型的檢測(cè)準(zhǔn)確率分別提升了4%,8.23%和14.51%,檢測(cè)速度分別提高了-0.87,0.25,1.42 幀/s;使用Retinex-Net、GAM 及雙曲全連接層后,模型檢測(cè)準(zhǔn)確率達(dá)98.6%,檢測(cè)速度為51.52 幀/s,檢測(cè)性能明顯提升。
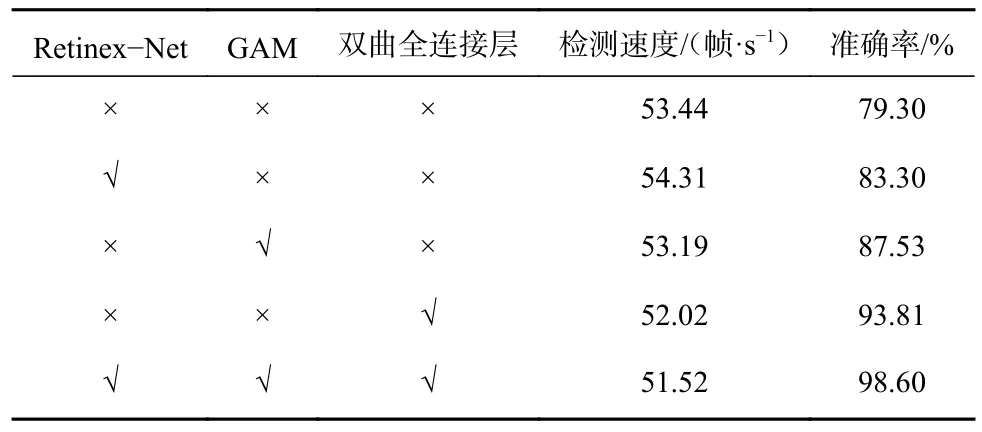
表4 消融實(shí)驗(yàn)結(jié)果Table 4 Ablation test results
為了驗(yàn)證本文模型的有效性,將其與YOLO 系列和SSD 目標(biāo)檢測(cè)網(wǎng)絡(luò)進(jìn)行對(duì)比,結(jié)果見(jiàn)表5。可看出,本文所提模型的準(zhǔn)確率較SSD、YOLOv4、YOLOv5、YOLOx、YOLOv7 分別提高了20.31%,18.51%,10.53%,8.39%,13.24%,達(dá)到98.67%,對(duì)于礦區(qū)道路上的行人、礦卡及挖機(jī)的檢測(cè)準(zhǔn)確性達(dá)97%以上。
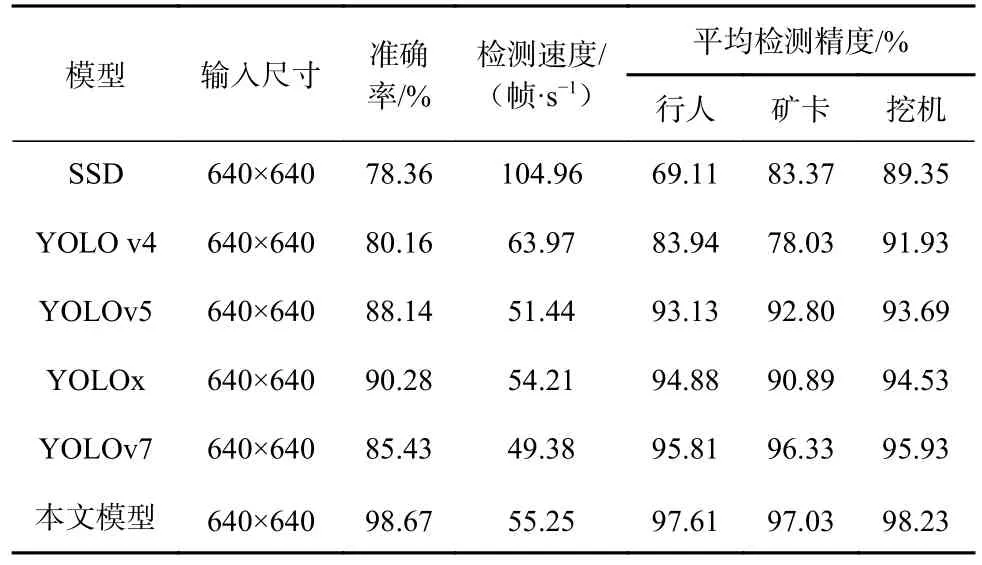
表5 不同網(wǎng)絡(luò)性能對(duì)比Table 5 Performance comparison of different networks
4 結(jié)論
1) 基于雙曲嵌入的露天礦區(qū)暗光環(huán)境下道路多目標(biāo)檢測(cè)模型不僅對(duì)露天礦區(qū)暗光環(huán)境下的大尺度目標(biāo)具有較高的分類(lèi)與定位精度,對(duì)礦卡及較遠(yuǎn)距離的小尺度目標(biāo)也可準(zhǔn)確檢測(cè)及定位,滿足無(wú)人礦卡在礦區(qū)特殊環(huán)境下駕駛的安全需求。
2) 為了減少露天礦區(qū)多種暗光圖像對(duì)檢測(cè)效果的影響,采用Retinex-Net 算法進(jìn)行圖像預(yù)處理,檢測(cè)準(zhǔn)確率提高了4%。
3) 使用Retinex-Net 進(jìn)行圖像處理、添加GAM模塊及雙曲全連接層的完整改進(jìn)模型檢測(cè)準(zhǔn)確率達(dá)98.6%,檢測(cè)速度保持在51.52 幀/s,可為礦區(qū)安全提供保障。
4) 基于雙曲嵌入的露天礦區(qū)暗光環(huán)境下道路多目標(biāo)檢測(cè)模型準(zhǔn)確率達(dá)98.67%,對(duì)于礦區(qū)道路上的行人、礦卡及挖機(jī)的檢測(cè)精度達(dá)97%以上。
5) 由于實(shí)驗(yàn)所需數(shù)據(jù)收集難度大、危險(xiǎn)系數(shù)高,使數(shù)據(jù)集數(shù)量有限,該模型檢測(cè)目標(biāo)的置信度還未達(dá)到0.9。下一步應(yīng)考慮如何增加數(shù)據(jù)量,并提高檢測(cè)物體的置信度。
猜你喜歡
童話王國(guó)·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2021年6期)2021-11-22 07:50:58
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2021年6期)2021-11-22 07:50:58
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2021年6期)2021-11-22 07:50:58
中老年保健(2021年12期)2021-08-24 03:30:40
中國(guó)傳媒大學(xué)學(xué)報(bào)(自然科學(xué)版)(2021年1期)2021-06-09 08:43:00
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2020年10期)2020-11-26 08:24:50
數(shù)學(xué)物理學(xué)報(bào)(2020年2期)2020-06-02 11:29:24
中國(guó)生殖健康(2020年6期)2020-02-01 06:28:50
中國(guó)生殖健康(2019年11期)2019-01-07 01:28:02
