HRformer:基于多級回歸Transformer網絡的紅外小目標檢測
2024-02-29 14:38:18杜妮妮單凱東王建超
紅外技術 2024年2期
杜妮妮,單凱東,王建超
(1.浙江工商職業技術學院,浙江 寧波 315100;2.浙江摩根集團有限公司,浙江 寧波 315012)
0 引言
相比于可見光圖像容易受到自然界中光照條件、氣象、目標遮擋等因素的影響,難以對目標準確地進行捕獲和觀測,紅外圖像由于其特殊的成像機理,能夠將目標物體與周圍環境之間的熱輻射差異反應為紅外圖像中的灰度差異,具有較強的抗干擾能力、較強的夜間探測能力以及更高的精度,廣泛應用于軍事、安防、航空航天等領域。近些年來,隨著紅外技術的發展,從紅外圖像中對小尺寸目標進行高效檢測引起了學術界廣泛的關注[1]。
相較于普通的自然圖像目標檢測任務,紅外小目標檢測通常面臨著來自多個方面的挑戰:①由于成像距離遠,導致紅外目標占整幅圖像比例較小,通常不到0.15%;②紅外輻射能量隨距離顯著衰減,使物體看起來非常模糊,因此缺乏特定的形狀及紋理,使得單純以目標為中心的表示方法不足以進行可靠的檢測;③原始紅外圖像中通常包含不同類型的干擾,如高亮度背景、混合噪聲等,導致信噪比較低,目標容易被噪聲所淹滅,難以實現檢測。
為了高效、準確地檢測出紅外小目標,早期的研究主要基于背景抑制的方法,通過在圖像上滑動一個特定大小的窗口來增強目標同時抑制背景實現實現小目標檢測,如:高帽濾波[2]、最大平均濾波以及最大中值濾波器[3],然而這類方法只能對特定的均勻噪聲實現一定程度的抑制,在處理紅外圖像中復雜多樣的背景噪聲時效率低下,會產生大量的虛警,難以滿足實際要求。此外有學者還受到人類視覺系統的啟發[4-6],假設目標是一個與背景有顯著灰度差異的局部區域,基于滑動窗口,對比中心像素與相鄰像素之間的差值或比值來實現小目標檢測。然而,由于紅外輻射的遠距離衰減以及目標本身的較弱的輻射強度,紅外圖像中的小目標往往具有較低的灰度值,并不總是滿足此類方法的假設。還有學者將低秩表示以及稀疏分解引入到紅外小目標檢測領域[7-10],其中Zhang 等人[11]提出了一種用于稀疏目標分離和低秩背景的對角塊自適應目標約束表示方法;Guo 等人[12]提出了ReWIPI 檢測算法在保留背景邊緣信息的同時對背景斑片圖像進行限制。然而這些方法僅僅在處理一些高信噪比的紅外圖像時有效,對復雜背景下形狀復雜的目標仍然存在較高的誤警率。總的來說,上述這些基于模型驅動的方法不需要大量的標注數據,可以為特定的場景獲得更好的效果。然而,對于復雜多變的真實場景,存在著檢測精度差、特征識別能力不足、對場景變化敏感的超參數等問題。
考慮到深度學習可以將紅外小目標檢測任務視為一個相對較高級的視覺感知問題,為了解決復雜多變的真實場景中的精確檢測問題,近些年來,許多研究人員開始通過構建神經網絡實現紅外小目標檢測[13-14]。與模型驅動的方法不同,基于卷積神經網絡(convolutional neural networks,CNN)的方法具有以數據驅動的方式學習特征的能力。Dai 等人[15]在模型驅動的基礎上提出了一個深度神經網絡模型(attentional local contrast networks,ALCNet),克服了單純模型驅動方法所面臨的檢測性能不足以及魯棒性欠缺的雙重挑戰。然而,該方法在需要手動調整模型參數,導致最終的小目標檢測效果對模塊超參數的設置較為敏感。之后,Wang 等人[16]采用了一種基于生成對抗網絡的MDvsFA(Miss Detection vs.False Alarm),能夠實現漏檢以及虛警之間的權衡。Chen 等人[17]采用UNet 作為骨干網絡來保持空間分辨率和語義信息,利用金字塔池模塊進一步提取特征,提高了目標分割的精度,此外還提出了一種多任務框架降低了模型復雜度同時顯著提升了算法的推理速度。為了在更大的感受野中檢測目標,基于CNN 的方法[18-21]主要利用卷積層的疊加,逐層增加網絡的感受域,但特征圖中的每個值只響應前面特征圖中局部感受域內的值,這種固有的局部性使得學習圖像中的遠距離依賴關系變得困難。同時,此類方法為了對不同尺度的信號進行處理通常采用池化或是下采樣操作,忽略了細節損失問題。
近期,自注意力機制在各種計算機視覺任務中表現出了強大的非局部特征學習的能力并隨后被其他研究人員改進和擴展[22-25]。由于其在對特征局部相似性以及遠程依賴性進行建模的能力遠優于CNN,因此可以用于緩解在紅外小目標檢測任務中單純使用CNN 所產生的局限性。然而,采用基本的Transformer結構通常需要注意到兩個方面的問題:首先,標準全局自注意力模塊的計算復雜度通常與特征的空間維數呈平方關系,此外,另外一種基于局部窗口的自注意力計算模塊雖然能夠降低計算資源的壓力,然而由于特定大小的窗口導致感受域受限。
為解決上述問題,本文在此前研究工作的基礎上,提出了一種多級回歸Transformer網絡的紅外小目標檢測算法(HRformer)。針對紅外場景中尺寸大小變化的弱小目標,HRformer 采用了一種多尺度特征的層次結構,在每一層,輸入通過像素逆重組(PixelUnShuffle)操作所獲取,不會存在信息損失。此外,為實現不同層級之間的信息交互,受到注意力機制的啟發,本文還設計了一種交叉注意力融合(cross attention fusion,CAF)模塊,能夠從不同層級中較高分辨率以及較低分辨率的特征圖中分別提取空間注意力以及通道注意力,并將二者分別與原先的特征圖進行交叉融合,從而實現特征的充分提取以及不同層級信息互補。此外,為了進一步提升檢測網絡的準確率以及抑制虛警率,本文還采用了一種局部-全局Transformer(local-global transformer,LGT)結構,能夠同時捕獲局部及全局遠距離依賴關系。實驗結果表明,本文所提出的HRformer 具有較高的檢測性能。
1 本文方法
1.1 總體框架
本文提出的HRformer 總體框架如圖1所示,采用了一種三級網絡結構用于實現紅外小目標檢測。首先,利用PixelUnShuffle 操作將輸入紅外圖像下采樣到不同層級,由于像素數是固定的,只是空間分辨率降低,而通道數增加,因此不會產生信息損失;相反,本文采用可學習的PixelShuffle 操作對每一層級的輸出特征圖進行上采樣,由于是將特征圖通道維信息轉換到空間維,因此不會像雙線性插值等上采樣過程引入插值操作,也使網絡能夠自適應的學習上采樣操作。
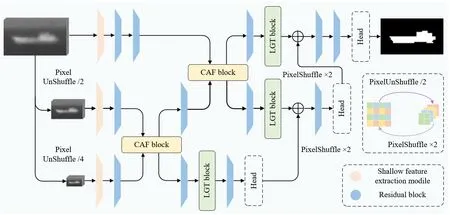
圖1 基于多級回歸Transformer網絡的紅外小目標檢測框架Fig.1 Infrared small target detection framework based on hierarchical regression transformer network
對于每一層級,首先通過淺層特征提取模塊進行初步特征提取以及提升特征的通道數,其中殘差塊由兩個普通的3×3 卷積,批歸一化操作;接著,通過交叉注意力融合模塊分別計算不同維度注意力,實現信息交互;再通過局部-全局Transformer 結構分別沿著局部以及全局兩個分支提取局部上下文信息同時建模全局依賴關系,集成了普通Transformer 結構以及基于窗口的Transformer 結構的優點,節省計算成本的同時還能獲得更大感受野;最后通過一個由幾個卷積組成的head 模塊對所在層級的分割結果進行初步預測并與前一層級的特征進行整合。此外,頂層使用較多的殘差塊來有效地整合不同層級特征,從而最終產生高置信度的分割結果。
1.2 交叉注意力融合模塊
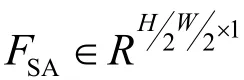
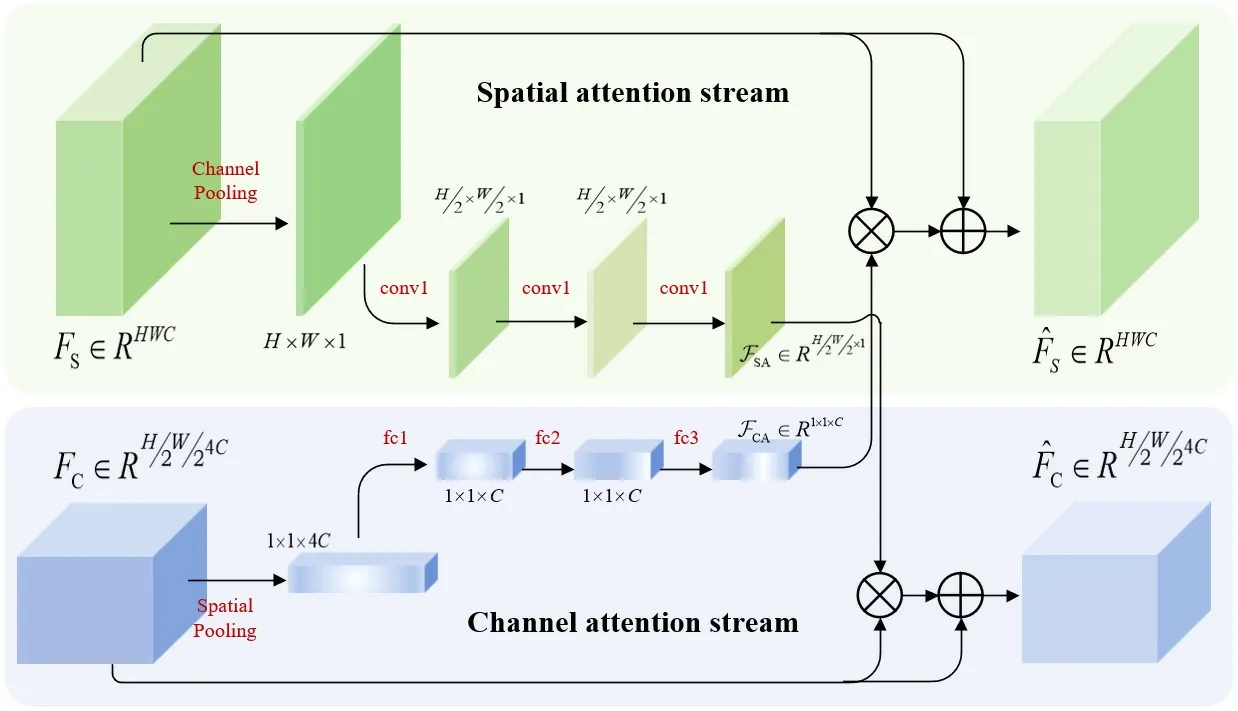
圖2 交叉注意力融合模塊Fig.2 Cross attention fusion module
1.3 局部-全局Transformer
為緩解標準空間維Transformer 所產生計算資源消耗大的問題,基于窗口的Transformer 結構能夠將自注意力[26]的計算限制在一個大小固定的窗口內,從而顯著降低計算復雜度。然而這種結構通常感受野受限,一些具有高度相關內容的圖像塊(Tokens)在計算自注意時不能相互匹配,也就無法對全局相關性進行建模。基于此,本文提出了局部-全局Transformer結構,能夠分別沿著局部以及全局兩個分支提取局部上下文信息同時建模全局依賴關系,節省計算成本的同時還能獲得更大感受野。總體結構如圖3(a)所示,輸入特征首先經過層歸一化操作,通過局部-全局自注意力計算(local-global self-attention,LGSA)塊(如圖3(c)所示)實現基于局部-全局信息的自注意力的計算,接著進行殘差連接以及層歸一化操作,最后通過前饋網絡(如圖3(b)所示)增強模型的擬合能力。
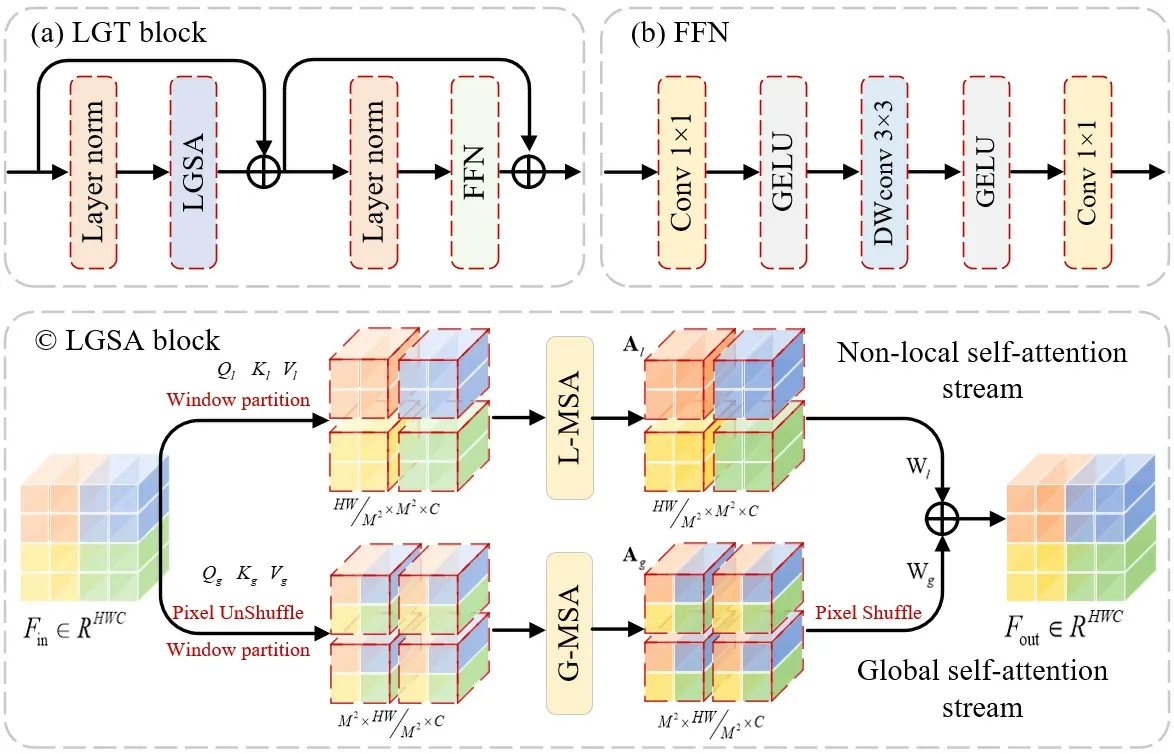
圖3 局部-全局transformer 模塊Fig.3 Local-global transformer module
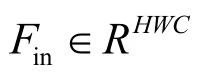
1)局部自注意力計算分支
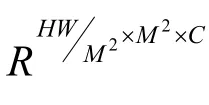
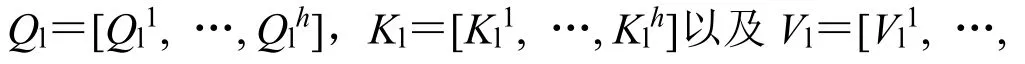
2)全局自注意力計算分支
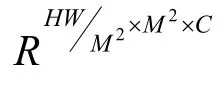
同樣的,Qg、Kg、Vg會沿著通道維劃分為h個head:Qg=[Qg1,…,Qgh],Kg=[Kg1,…,Kgh]以及Vg=[Vg1,…,Vgh]。對于每一個head 內的全局自注意Agi的計算過程可以表示為:
最終通過線性映射將局部分支以及全局分支的注意力計算結果進行聚合:
2 實驗結果與分析
2.1 數據集介紹
本文在NUDT-SIRST 數據集[28]上進行實驗,其中包含了427 張具有代表性的紅外圖像以及480 個小目標實例,同時為了方便和大部分方法進行比較,本文將大約50%的數據用于訓練、20%以及30%的數據分別用于驗證及測試。
2.2 訓練環境及實驗設置
本文基于PyTorch 平臺對所提出算法進行實驗驗證,GPU 為RTX3090Ti,操作系統為Ubuntu20.04。同時本文采用AdaGrad 作為網絡迭代優化器,初始學習率設為0.04,網絡一共需要訓練500 個epoch,衰減率為10-4,batch 大小為8。本文同一些目前較為先進的紅外小目標檢測算法進行對比,包括:ALCNet[15],IAANet[29],AGPCNet[30],ACMNet[28],MDvsFA[16],WSLCM[31],TLLCM[32],IPI[33],NRAM[34],PSTNN[35]以及MSLSTIPT[36]。
2.3 評價指標
和大多數紅外小目標檢測方法一樣,本文采用了IoU、nIoU、Pd以及Fa這幾個常用的指標將所提出的HRformer 與其他方法進行比較:
交并比IoU 定義為:
IoU=Ai/ Au(6)
式中:Ai和Au分別表示相交區域和并集區域的大小;nIoU 是IoU 的標準化,即:
式中:N表示樣本總數;TP[?]表示被模型正確預測的正樣本的像素數目;T[?]和P[?]分別表示圖像中真實值和預測為正樣本的像素數目。
檢測率Pd表示正確檢測出的目標Npred與所有目標Nall的比值:
虛警率Fa表示錯誤預測的目標像素數Nfalse與圖像中所有像素Nall的比值:
2.4 消融實驗
本文通過設置消融實驗對所提出的不同模塊對網絡性能的影響進行分析,具體包含3 個部分:
①是否采用UnShuffle 對輸入數據做下采樣以及采用Shuffle 操作對每一層級的輸出進行上采樣操作。本文通過普通的下采樣操作以及插值上采樣操作對UnShuffle 以及Shuffle 進行替換從而實現對該部分有效性的驗證。實驗結果如表1所示,實驗8 為原始HRformer 的結果,通過與實驗1 的結果進行對比,可以發現IoU 指標增加了1.07,證明該處理方式的有效性;同時,本文還對實驗4、實驗7 這一組的結果進行對比,能夠發現采用UnShuffle 以及Shuffle 操作進行的下采樣以及上采樣能夠較好地維持原始圖像的信息,使得各項指標均有所提升。
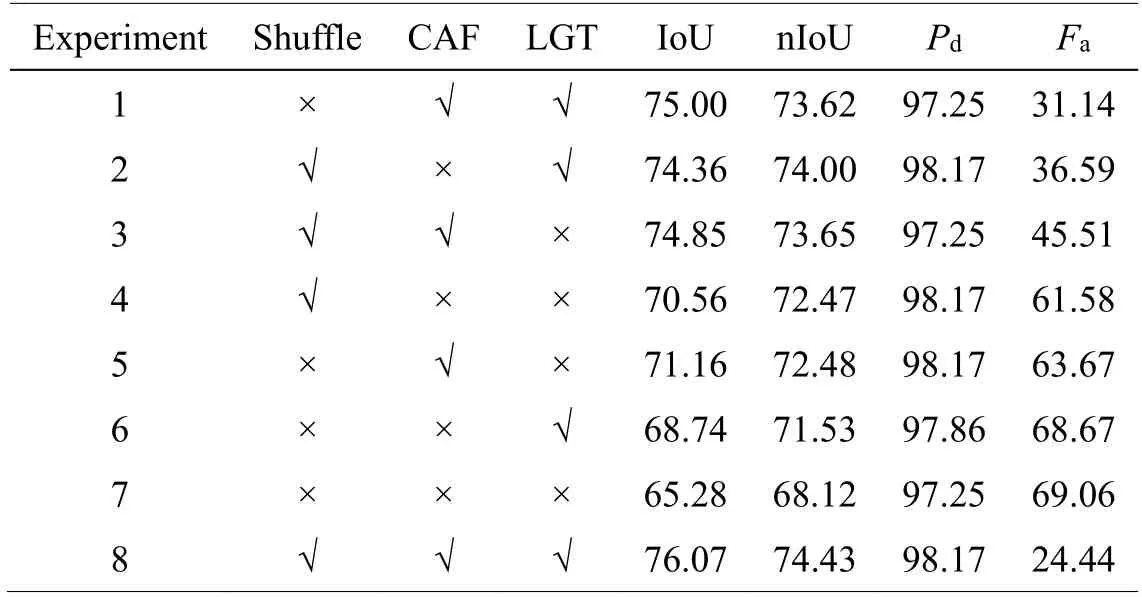
表1 消融實驗結果Table 1 Ablation experimental result s
②是否采用本文所設計的交叉注意力(CAF)模塊對不同層級的特征信息進行交互。通過對表1 中的實驗2、實驗8 以及實驗5、實驗7 這兩組實驗的結果分別進行對比,不難發現,采用CAF 模塊能夠顯著提升檢測的各項指標,證明該模塊對于不同層級信息進行融合對于紅外小目標檢測任務的有效性。
③是否采用本文所構建的局部-全局Transformer(LGT)結構用于實現基于局部-全局信息的自注意力的計算。對表1 中實驗3、實驗8 以及實驗6、實驗7這兩組實驗的結果進行對比,可以看到不包含LGT 模塊的IoU 指標和nIoU 指標分別降低了1.22(3.46)和0.78(3.41)。能夠證明該結構的有效性。得益于對輸入圖像局部-全局相關性的建模,網絡能夠提升對特征圖中的小目標的判別能力,因而檢測性能顯著提升。
2.5 實驗結果
為了對本文所提出HRformer 紅外小目標檢測算法的先進性,在SIRST 數據集[28]上與現有的一些經典算法進行比較,如表2所示(最優指標已被加粗)。不難看出,傳統算法由于大都基于一些手工先驗,在處理具有挑戰性的樣例時往往受限,導致檢測性能與其一些基于深度學習的方法差距較大。同時,在單純基于CNN 的算法中,由于自身表達能力不夠以及對全局信息建模能力不夠,導致難以對掩碼進行準確地預測,因此各項指標都較低;此外,這類算法在噪聲背景下的學習判別能力比較弱,因此容易造成對目標的漏檢以及錯檢。與這些方法相比,本文所提出的HRformer 網絡,在所有的評價指標方面都表現出了最好的性能,并且相較于ALCNet,IoU 指標和nIoU 指標分別提升2.64%以及2.99%,且參數量不及ALCNet的一半;同時本文所提算法在參數量、單張圖像推理時間都遠少于IAANet 的情況下,還取得了更加優異的檢測性能,證明了HRformer的先進性以及高效性。
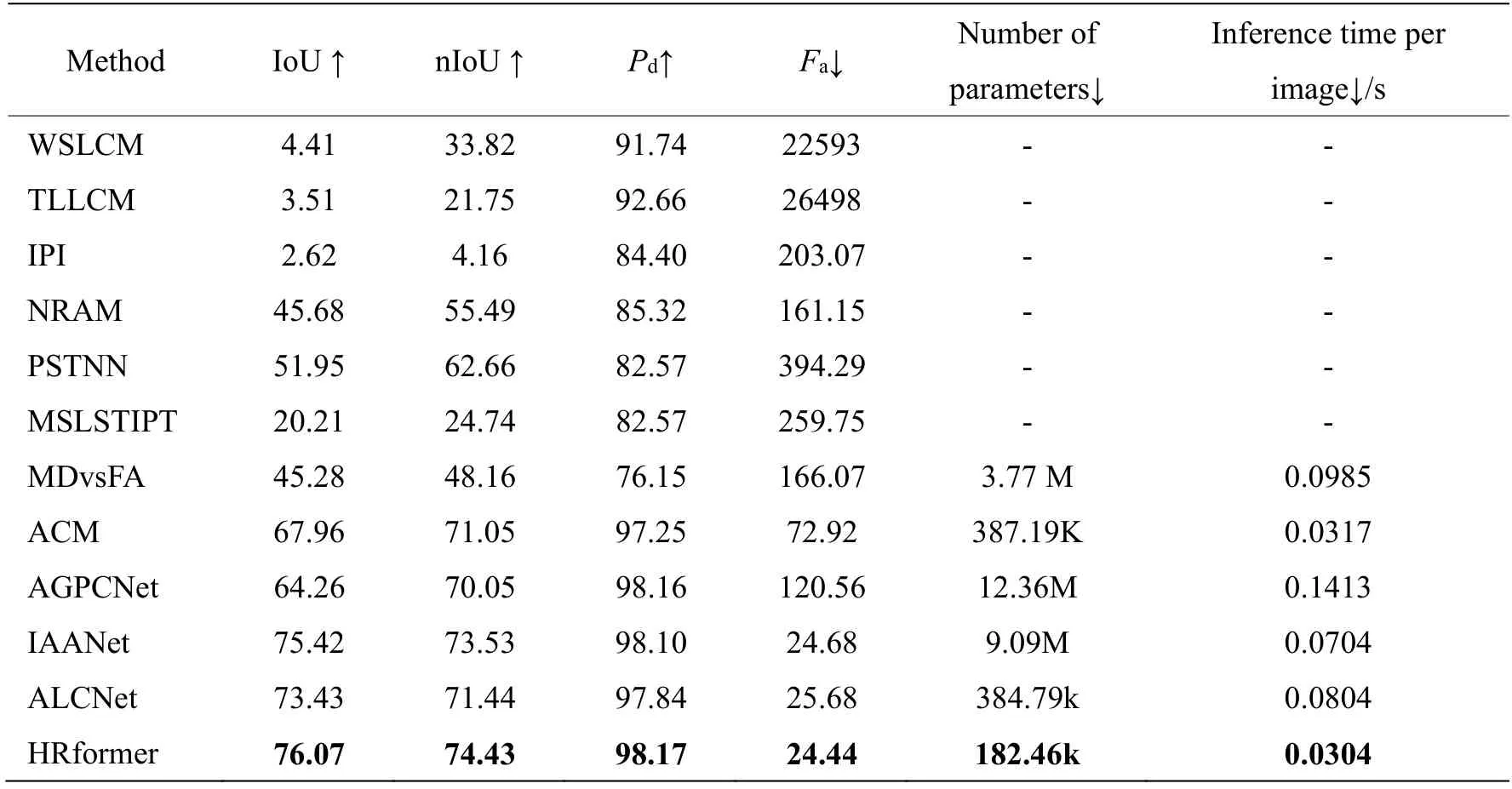
表2 對比實驗結果Table 2 Experimental results comparison of different algorithms
如圖4所示,本文對這些檢測算法的可視化結果進行了對比,不難看出,即使是在一些具有較低信噪比以及低對比度的紅外圖像作為輸入的情況下,本文所提出的HRformer 同樣能夠對目標進行準確的定位,同時所檢測出的目標形狀大致完整且準確。這些得益于本文所采用的UnShuffle 操作對輸入圖像進行的下采樣操作,能夠避免有效信息的損失;同時LGT 模塊分別對于局部以及全局進行的建模也提升了網絡的表達能力以及鑒別學習能力,和其他算法的檢測結果相比,較少出現漏檢以及錯檢情況。最后,如圖5所示,本文還繪制了一些算法的ROC 曲線,可以看到,本文所采用的HRformer網絡的性能明顯優于其他算法。

圖4 不同算法紅外圖像檢測結果Fig.4 Experimental results of different algorithms
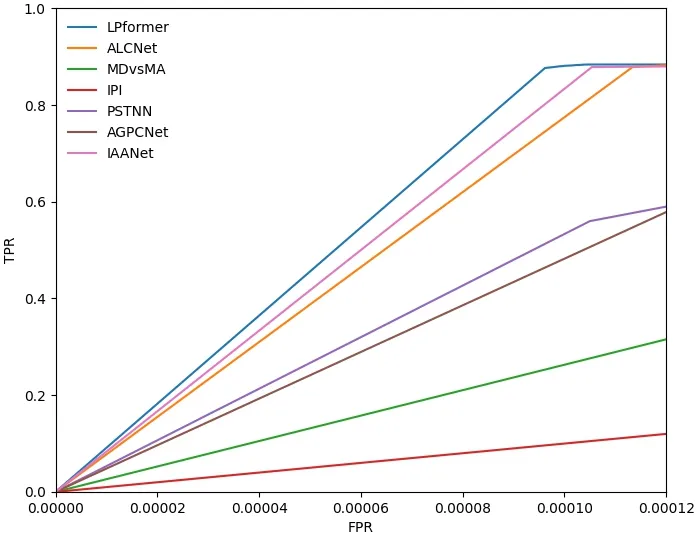
圖5 不同算法ROC 曲線Fig.5 Curves of ROC by different methods
3 結論
本文提出了一個新穎的基于多級回歸Transformer(HRformer)網絡來解決低信噪比、低對比度以及復雜背景條件下的紅外小目標檢測任務。首先,為了在獲得多尺度信息的同時盡可能避免原始圖像信息的損失,本文采用了Pixel UnShuffle 操作來獲取不同層級網絡的輸入,同時采用了可學習的PixelShuffle 操作對每一層級的輸出特征圖進行上采樣,用于提升網絡的靈活性;接著,為實現網絡中不同層級之間信息交互,本文還設計了一種包含空間注意力計算分支以及通道注意力計算分支在內的交叉注意力融合(CAF)模塊實現特征融合以及信息互補;最后為進一步提升網絡的檢測性能,考慮到普通Transformer 結構具有較大感受野而計算復雜度高、基于窗口的Transformer 結構具有較少計算復雜度而感受野受限的情況,提出了一種局部全局Transformer(LGT)結構,能夠在提取局部上下文信息的同時建模全局依賴關系,計算成本也得到節省。通過在SIRST數據集上與其他先進算法進行的大量對比實驗,證明了本文所提出的算法的優越性。
猜你喜歡
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
中學生數理化·中考版(2022年11期)2022-02-16 07:01:20
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
小哥白尼(趣味科學)(2019年6期)2019-10-10 01:01:50
發明與創新(2016年38期)2016-08-22 03:02:52
太空探索(2016年5期)2016-07-12 15:17:55
