基于EPF-MADDPG算法的多導彈機動策略研究
2024-02-29 04:33:06聶文川樊志強
計算機測量與控制 2024年2期
聶文川,樊志強
(中國電科智能科技研究院,北京 100083)
0 引言
隨著我軍不斷地信息化改革,研究人員探索了眾多的人工智能技術[1-5]。強化學習技術近年來逐漸火熱,強化學習是可以自學習的,它適用于決策,已經應用于許多領域,如流量控制、無人機控制、網絡構建等[6-9]。博弈是指一個理性的人或團隊從選擇行為或策略,到最終獲取相應的利益。強化學習算法通過博弈對抗中產生的回報來優化策略選擇。強化學習的最主流應用仍在游戲領域中,近年來,強化學習征服了象棋、圍棋等完全信息游戲,以及撲克等不完全信息游戲,在電子游戲競賽中的戰爭迷霧和復雜狀態空間以及動作空間的游戲,如Dota、星際爭霸等[10-12],人類玩家也逐漸被強化學習算法超越,而這就是算法有效性最強有力的體現。
本文基于現實海上反艦場景中導彈機動的強化學習進行了研究,將他們遷移到仿真的場景中,尤其是導彈集群反艦任務。針對異構多智能體博弈對抗的情況,本文將MADDPG(multi-agent deep deterministic strategy gradient)算法應用到多智能體彈群反艦任務的場景中,通過分析在巨大狀態空間和動作空間的收斂速度,聚焦真實報酬稀疏的問題。同時,通過設計仿真實驗來驗證算法的有效性。
1 場景分析與數學模型
復雜對抗場景一直是強化學習的熱點和難點之一。隨著深度強化學習的發展,該算法應用到了各種場景。然而目前的主流應用是在圍棋等游戲領域[13-15],一個重要的原因就是游戲場景具有現成的游戲環境和自洽的規則以及獎懲機制,便于強化學習的應用。但在自動駕駛等真實場景中,由于仿真環境的仿真完成度和獎懲機制的不確定性,無法實現強化學習算法。因此在仿真系統中,仍需大量的工作來促進強化學習算法的進步,同時在類似的仿真系統中,強化學習算法本身也有很大的發展潛力。在歷史上,計算機的發展首先運用于軍事領域,用來協助人類計算以及密碼破譯,在現代,人工智能依舊可以運用在軍事領域。基于強化學習的博弈對抗推理是維持軍隊戰斗力的重要手段之一。近年來,軍事象棋推演成為人們普遍關注的熱點,人工智能在推理和分析的過程中起到重要的作用。本文將強化學習應用于多智能體博弈對抗仿真系統中,選取了紅藍兩面異構的博弈對抗場景,即近海反艦作戰場景,紅色攻擊和藍色防御,實現仿真作戰。本文將多智能體強化學習算法應用于異構多智能體系統,增強了智能體之間的協作性,提高了算法的能力。
1.1 彈群協作的特點
導彈集群協作智能化具有以下4個重要特點:
1)去中心化:任何一枚導彈的消失或者功能喪失,彈群的目標依然可以有序實現[16]。同時每一顆導彈都可以協作其他導彈實現戰術目標。
2)自主性:戰場態勢瞬息萬變,依賴指揮官根據戰場態勢進行決斷勢必會浪費寶貴的作戰時間,甚至可能錯過稍縱即逝的機會。因此為了節省人為決策消耗的時間,飛行期間導彈采取的一切機動操作均可進行自主判斷并及時決策,且彈群內的所有導彈只控制自身飛行,但可以觀察其他導彈位置,不對其他導彈產生影響。
3)高動態:導彈需要根據戰場態勢變化做出快速響應。傳統預先規劃的形式已經無法滿足現在瞬息萬變的戰場環境,而導彈的作戰時間非常短暫,因此要求彈群在收集到戰場態勢信息后迅速做出決策。
4)自治化:所有的導彈形成一個穩定的集群,并且各自承擔相應的功能,當某一導彈喪失功能造成集群結構的缺失后,其他導彈應及時調整并重新構成穩定的集群結構[17-18]。
綜合來看,目前多彈頭集群協同突防技術的研究仍處于初級階段,因為該技術要求各個彈頭具有高度自主性,面臨復雜任務可以快速響應,因此對于彈載計算機的要求較高[19]。
1.2 導彈運動學模型
導彈的運動學方程為 :
(1)
式(1)中,i=p,e;ωi為攔截導彈或突防導彈的角速度大小;vi為攔截導彈或突防導彈的速度,其為一個固定值,即導彈在飛行過程中的速度不改變。
導彈的運動控制變量約束為:
(2)
式(2)中,ωpmax,ωemax分別為攔截導彈和突防導彈的最大角速度,其計算方程為:
(3)
式(3)中,i=p,e;ΔT為方針的時間步長;ri為導彈的機動半徑;rimin為導彈的最小機動半徑;Δψi為ΔT時間內的航向最大轉彎角;nimax為導彈的最大側向過載。因此,由式(4)可得最大角速度的確定公式為:
(4)
攔截捕獲條件為式(5),在攔截半徑范圍內,即我方導彈進入敵方攔截導彈的作用范圍,便會被攔截捕獲。
(5)
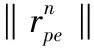
由于本文假定的突防問題是在有限的二維平面內進行的,因此導彈在設定的環境邊界內運動需要滿足式(6):
(6)
式(6)中,n=[1,...,4];xmin、xmax分別為環境邊界,本文的邊界為-250~250;ymin、ymax分別為環境邊界,本文的邊界為-250~250。
在研究中,定義速度比為攔截導彈的最大速度與突防導彈的最大速度之比:
(7)
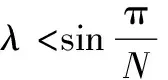
(8)
2 約束與算法設計實現
2.1 導彈突防場景下的約束
在彈群攻防對抗的場景中,除了雙方彈群之間的對抗,彈群內部的導彈也需要協同完成任務,使得場景要素更加復雜,且對抗雙方的對抗性更強。針對在作戰空域內的多導彈協同攻防對抗場景,本文將對抗場景的預設為:作戰空域內同時存在多顆攔截導彈和突防導彈,雙方具有相反的戰術目標。攔截導彈的目標是追擊并攔截突防導彈,而突防導彈的目標是盡可能地突破攔截導彈的封鎖,或者盡可能地保護其他導彈進行突防。彈群突防的對抗場景如圖1所示。
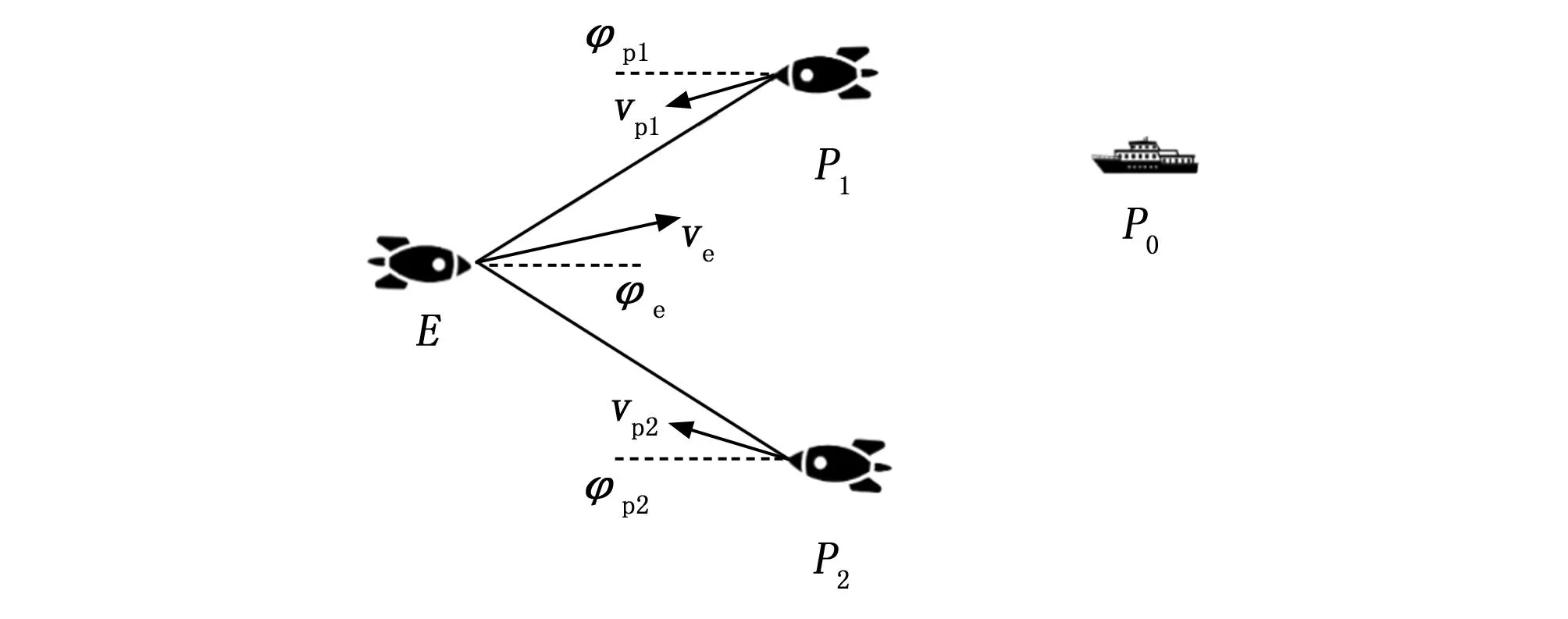
圖1 導彈追捕場景
圖1中,E為進攻方導彈,P1P2為攔截方導彈,P0為進攻方目標(攔截方保護目標;ve為進攻方導彈的速度大小及方向,vp1vp2為攔截方導彈的速度大小及方向;φe為進攻方的導彈的速度航向角,φp1φp2為攔截防導彈的速度航向角。針對以上導彈集群攻防問題描述構造彈群攻防博弈數學模型[25],建立了有控制約束的多無人機追捕對抗零和微分博弈模型。
考慮到我們簡化的二維平面區域的追逃博弈,可以使用直角坐標系來表示對抗雙方導彈的實時運動狀態。圖2展示了數學幾何模型。
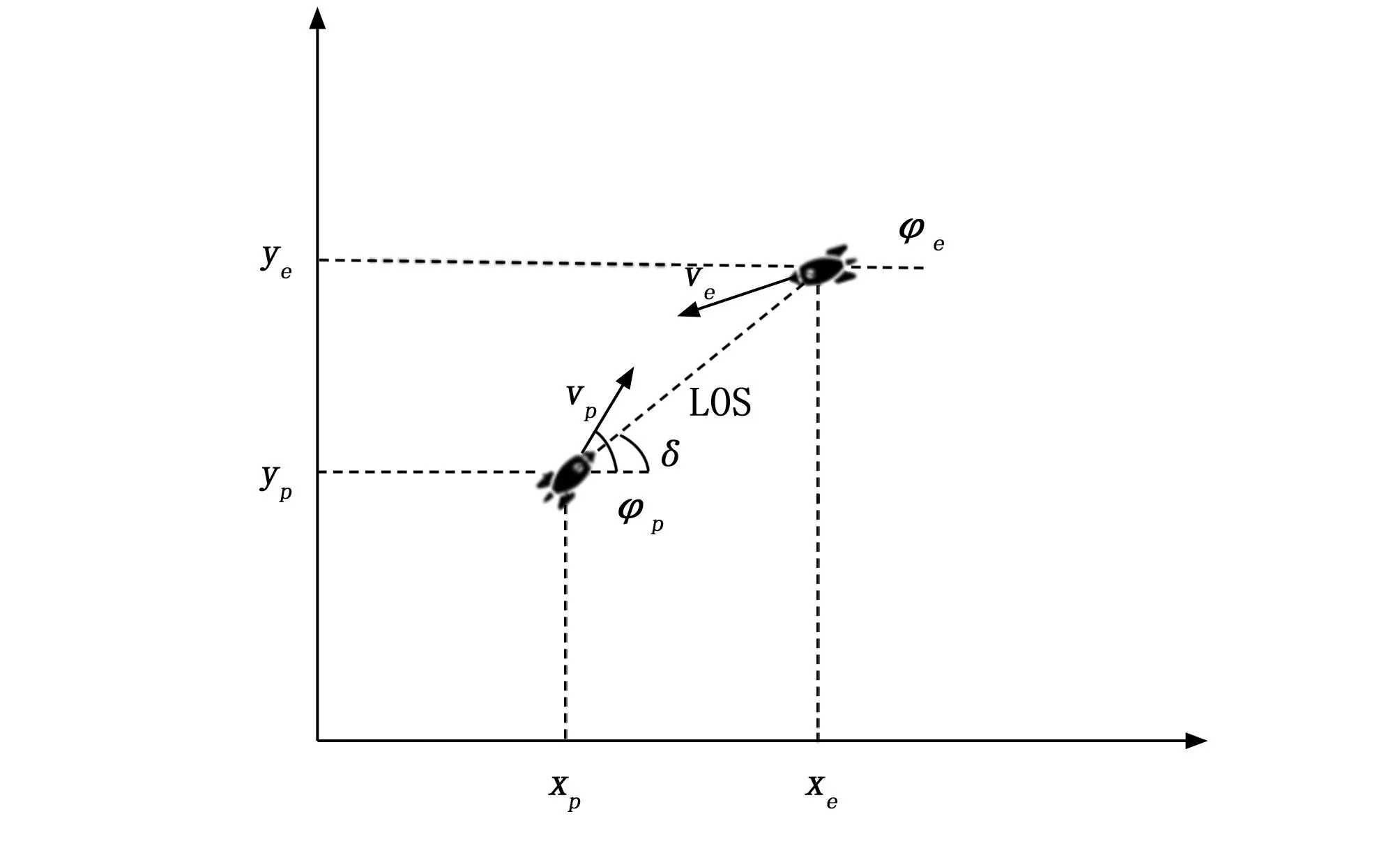
圖2 導彈運動模型
圖2中,δ為目標視線(LOS,line of sight)的夾角-視線角,目標視線指攻防導彈Ε的射線,(xpn,ypn)(n=1,2,…,N)、(xe,ye)分別為攻擊方導彈和攔截方導彈的位置坐標。
攔截方導彈的目標是通過最短時間內攔截目標。而突防導彈的目標是躲避攔截導彈,以避免在作戰時間段內被導彈攔截捕獲。或者盡可能延遲其他突防導彈被攔截的時間。攻防雙方博弈標準微分博弈數學描述為:
Tc=f[vp1,ψp1,L1,…,vpn,ψpn,Ln,…,
vpN,ψpN,LN,ve,ψe]
(9)
式(9)中,Ln(n=1,2,…,N)為攔截導彈n到突防導彈的距離;Tc為攔截導彈P攔截突防導彈E的時刻。其中導彈攔截的最優時刻是Tcmin,導彈突防的最優時刻是Tcmax。
2.2 獎勵設計
獎勵設計是指導增強學習算法性能改進的重要組成部分。攻防雙方之間的對抗最終結果只有一個真正的獎賞。在引導智能體產生足夠智能的策略中,人工設計的內在回報是關鍵。 本文設計了攻擊方導彈、攔截方導彈的獎勵,以指導其各自的策略。 突防導彈根據爆炸時距離目標位置扣10分到加10分不等,給予隨距離變化的負獎勵,系數為 0.001,并引導突防方導彈盡快獲得正獎勵;當攔截導彈處于攔截任務時,攔截成功的目標越多,得到的獎勵越多,以引導攔截導彈盡可能同時攔截多個突防導彈。同時,為了防止進攻方導彈耗盡燃料,將給予隨著時間變化的負獎勵。 攻擊上,殲敵航母加50分,引爆多個攔截導彈加5到20分,自身損壞扣5分。這種設置是鼓勵進攻方導彈重視協作的重要性,引導導彈進行掩護任務。同時,為鼓勵導彈進攻敵方航母,將距敵航母的距離設為正獎勵,系數為 0.000 000 1。 防御方面,攔截方將敵導彈和航空母艦的距離作為負獎勵,系數為 0.000 000 1,可防止導彈太近。
2.3 EPF-MADDPG算法結構及優化
2.3.1 MADDPG算法
MADDPG算法是一種針對多智能體協同決策的強化學習算法,在導彈協同領域具有以下優勢:1)基于策略梯度的方法,能夠有效地處理非線性、高維、連續的動作空間,更適合于導彈協同問題;2)可以學習合作策略,MADDPG算法可以學習到智能體之間的合作策略,從而在導彈協同中實現協同作戰和任務分配,提高協同效率和任務完成率[21-23]。而其他單智能體算法往往只能處理獨立策略的問題;3)具有策略共享機制,MADDPG算法具有策略共享機制,能夠讓智能體之間共享策略信息,提高學習效率并減少訓練時間;4)具有經驗回放機制:MADDPG算法還具有經驗回放機制,能夠利用過去的經驗進行學習,減小樣本相關性,提高算法的穩定性和收斂性。 綜上所述,MADDPG算法在導彈協同相比其他方法具有更好的學習效果、更高的協同效率和任務完成率。
“集中訓練,分散執行”是一種方法,它在訓練階段集中資源進行模型學習和優化,然后在執行階段將訓練好的模型分散到不同計算節點或設備上進行并行計算和推理。這樣做可以通過訓練學習得到最優的訓練策略,使算法得到高效靈活地執行。在運行該算法時,利用智能體的觀測信息可以求出最優解,從而得出想要的最優策略。
在“集中訓練”階段,為了計算出更精確的Q值反饋給“表演者”網絡,可以根據DDPG算法平臺添加額外數據,包括其他智能體的運動狀態、觀察值或動作。智能體還可以根據其他智能體的動作價值以及自身的觀察值和動作來判斷當前輸出動作的價值。
“分散執行”是指在訓練完成后,每個Actor根據自身的觀測值選擇適當的動作,無需其他智能體的動作信息。在MADDPG算法中,“表演者”網絡和“評論家”網絡協同工作。每個智能體都有自己的“表演者”網絡,用于輸出確定的動作。然而,“評論家”網絡不僅考慮自身的觀測狀態和動作,同時也要考慮其他智能體的動作信息。每個智能體都有一個中心化的“評論家”網絡,該網絡同時接收所有智能體的“表演者”網絡生成的數據。[24]。
2.3.2 基于經驗池篩選機制的算法策略改進
采取原始MADDPG算法時,每一個評論家都需要觀察到所有agent的狀態,而對于本文中涉及的大量不確定agent的場景,不是特別適用,而且當按agent數量特別多時,狀態空間太過于巨大,導致難以收斂。同時每一個agent都對應了一個評論家和表演者網絡,數量多時,存在大量的模型,增加算法的計算時間。
針對上述問題,設計基于經驗池篩選的EPF-MADDPG算法。從兩個方面對算法進行改進:1)引入長短期記憶(LSTM)網絡保存過往訓練信息;2)加入閾值篩選機制對算法經驗回放策略做出調整。
MADDPG算法的經驗回放策略沒有考慮到動作前后的相關性,在遇到從未見過的情況時,往往需要大量的嘗試才能學習到最優動作。LSTM網絡主要用于處理環境狀態信息的輸入,基于“門”來控制信息的丟棄或增加,從而實現遺忘或者記憶的功能,達到緩解梯度消失的作用。
LSTM網絡中的遺忘門、記憶門以及輸出門是LSTM神經網絡中的3種門控機制,用于控制輸入、輸出和忘記之前的信息。其中,遺忘門用于決定之前輸入的信息被遺忘的程度;輸入門用于控制新輸入信息的加入程度;輸出門用于控制當前狀態的輸出程度。網絡的整體結構如圖3所示。
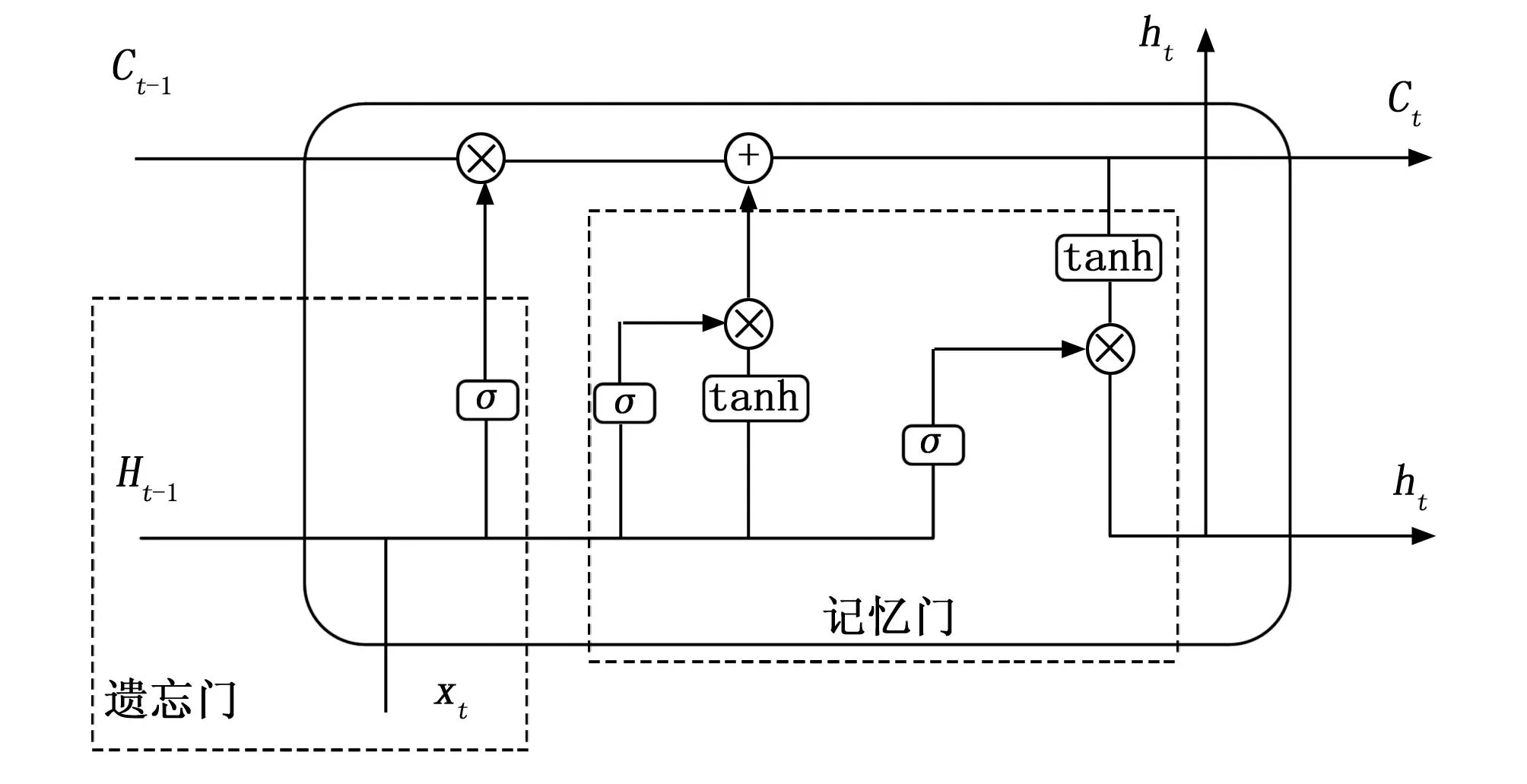
圖3 LSTM網絡結構
遺忘門:控制歷史狀態流經當前狀態后允許多少進入當前狀態的門控設備。
記憶門:控制從當前狀態向長期記憶中存儲哪些信息的門控設備。
輸出門:控制從長期記憶中向當前狀態輸出哪些信息的門控設備。
經驗池閾值的設置由預訓練決定,將預訓練的樣本數據按照從大到小依次排列為一序列,序列樣本總數為n,設定參數α代表正式訓練時使用序列樣本的比例,選取α×n位置的樣本所對應的值作為預值。為設立合理的閾值進行預訓練,按優先級從高到低的順序對數據列表進行排序,然后從高斯隨機數值生成器中獲取一個0~1之間的隨機數α,其中α在0~1之間取值的概率呈正態分布,這樣就可以盡可能取到中間的數值,避免出現接近0或接近1的極端情況。
對于正式訓練的樣本數據,只有大于預設閾值的樣本才會放入經驗池中。在基于經驗池篩選的MADDPG算法中,采用純粹貪婪優先方法對樣本進行排序,確保被采樣的頻率在繼承優先級上是單調的。同時在排序好的樣本隊列中加入均勻隨機采樣,避免了高優先級產生的過擬合問題。
2.3.3 算法框架實現
本文采用的MADDPG算法框架如圖4所示。在訓練過程中,首先初始化整體的狀態和策略網絡。智能體根據當前時刻的狀態輸入Actor網絡,生成對應的動作。環境返回智能體執行當前動作時所獲得的獎勵和轉移到的下一狀態。智能體將生成的四元組數據存儲到經驗回放緩存中,以備后續的“表演者”網絡和“評論家”網絡更新時使用。然后智能體從緩存池中采樣多個批次的機動軌跡,每一條機動軌跡是智能體與環境進一步交互得的。輸入 Actor 網絡進行訓練的數據是智能體當前時刻的狀態。智能體利用已更新的模型與環境進行下一步的交互,然后利用生成的數據更新經驗回放緩存池。當然,每個智能體都有自己的 “表演者”網絡和 “評論家”網絡,還有一個所有智能體共有的 “評論家”網絡,每個智能體自身的 “評論家”網絡學習單個智能體每輪訓練的期望收益,所有智能體共有的 “評論家”網絡學習團隊的期望收益。
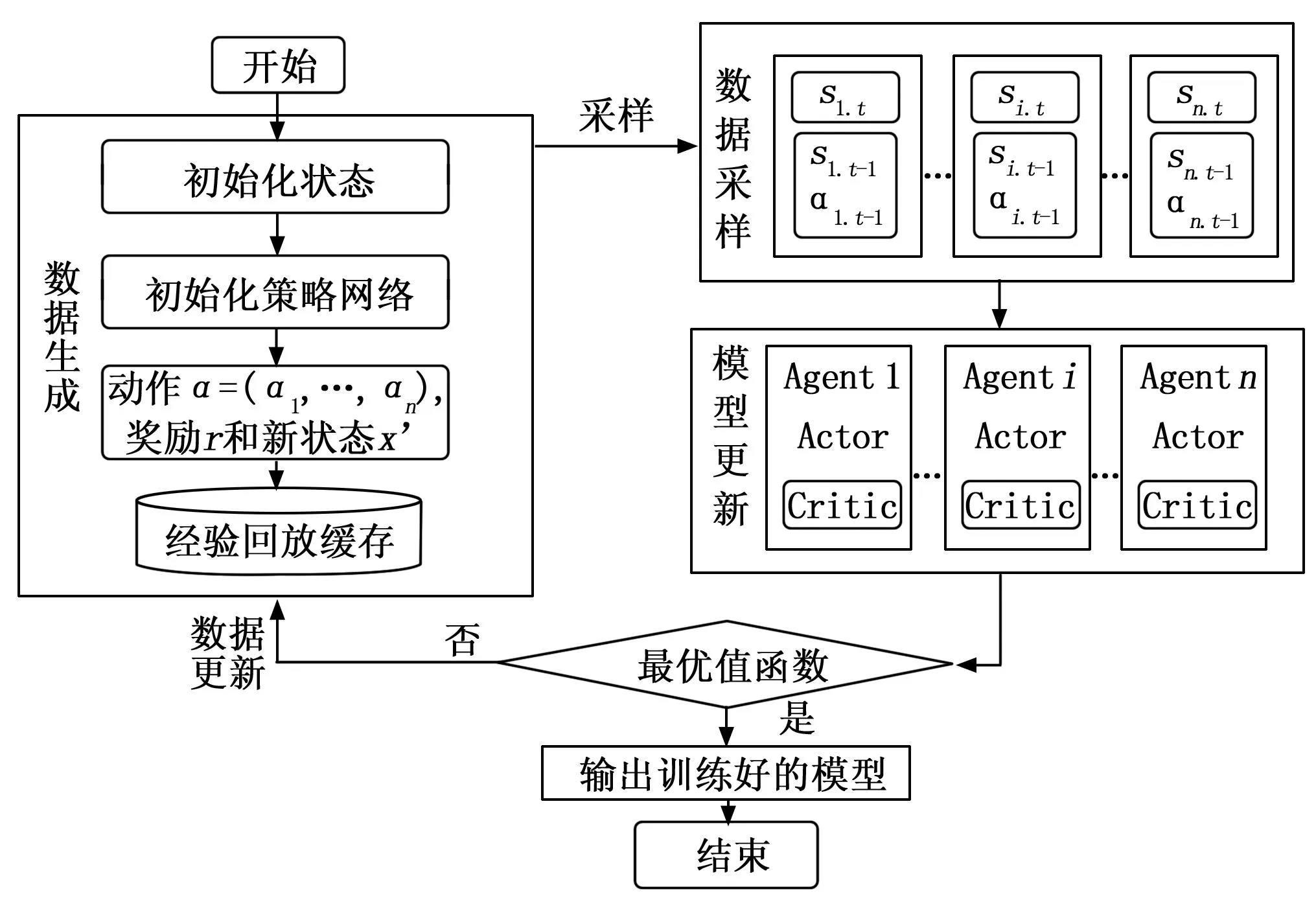
圖4 MADDPG算法框架
下面是本文的整體算法設計。
Forepisode = 1 to MaxEpisode do
在設定的范圍內隨機初始化突防導彈、 攔截導彈的初始狀態
Fort = 1 to MaxStep do
獲得仿真環境初始狀態st
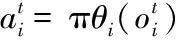
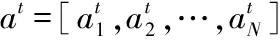
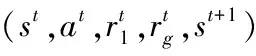
/*全局Critic網絡更新*/
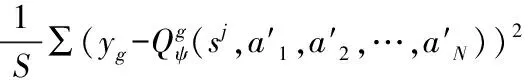
/*Actor網絡和局部Critic網絡更新*/
For Agenti=1 toNdo
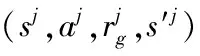
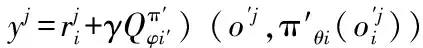
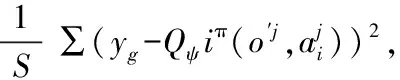
End For
End For
End For
3 實驗結果
為了驗證所提方法的優越性,本實驗的硬件配置為,CPU:Intel○RCoreTMi7-13700KF CPU @4.20 GHz;內存:32 G;顯卡:Geforce RTX4070Ti(12 G內存)上,基于Windows10平臺,顯存位寬為64位DDRM。
圖5為在不同范圍的仿真場景下的所有智能體的算法回報,圖中隨著場景的一步步擴大,算法收斂得到的回報也逐漸提高,說明在更大的作戰范圍中突防導彈可以更好地達到任務目標,攔截方導彈在更小的作戰范圍內,攔截的成功率就越高。同時在1 000*1 000(km)以后,場景得到的回報提升就不再顯著。
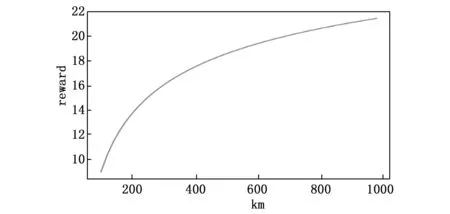
圖5 范圍-回報變化
本文實驗針對海域上的導彈集群攻防博弈情形進行了設計。假設在某海域中,我方發射兩枚導彈對敵方航母發起打擊,在相對坐標1 000*1 000(km)的區域內敵方發射三枚攔截導彈,實施突防策略。為了使實驗具有可操作性,設定突防導彈的機動能力比攔截導彈的機動能力大,同時規定為距離的安全約束,當其中有一個攔截導彈靠近了突防導彈該距離約束值內,追捕成功,博弈結束。為加速收斂,忽略z軸的動力學模型,得到一個平面內二維的博弈場景[26-27]。實驗設計的訓練參數如表1所示。
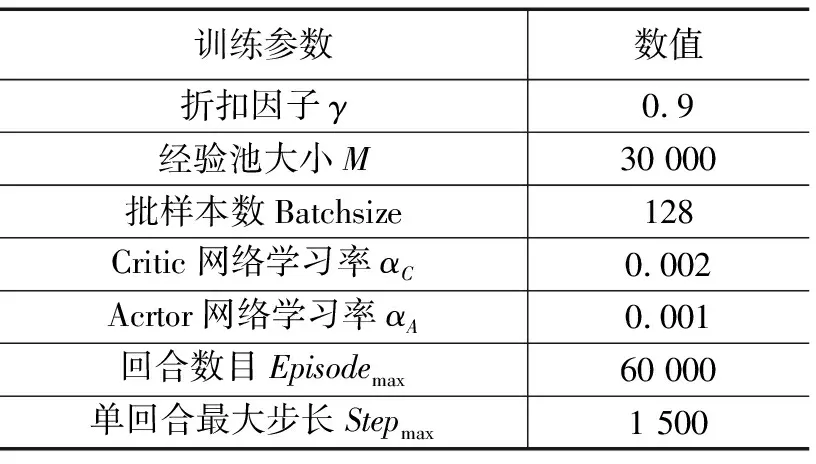
表1 算法訓練超參
首先,實驗分析了該場景下MADDPG算法的收斂性。圖6為MADDPG與DQN算法的回報獎勵,其中DQN的學習率設置為0.001,采用批量梯度下降的方式進行學習,經驗池大小與批樣本數與EPF-MADDPG算法保持一致。經過 14 000 輪的訓練后,網絡的loss值逐漸降低,且趨于穩定,說明網絡收斂,各個智能體都能產生更合適的動作。 從圖5、6中可以看出,MADDPG算法相較于DQN算法具有更快的收斂速度,以及更優秀的回報獎勵。同時,各單元參與者網絡的下降趨勢相似,關鍵網絡的下降趨勢也相似。
同時,根據圖6所示,基于經驗池篩選策略的MADDPG算法耗時明顯低于傳統的MADDPG算法,其最大時延為320 ms,而DQN算法需要400 ms。EPF-MADDPG相較于DQN算法提升了8%左右,滿足實際場景中的實時性需求。
隨著不斷地訓練,敵方智能體也會學習到一些策略,這就會導致回報的下降,但這也會促進我方智能體的學習,最后收斂到一個穩定的回報。
隨著不斷地學習,智能體會逐漸學習到一些策略,用來欺騙敵方。圖7中是智能體的行動軌跡,我們可以看到智能體會做出“假動作”誘使敵方智能體做出錯誤的判斷,并加速通過速度優勢越過攔截導彈的攔截。
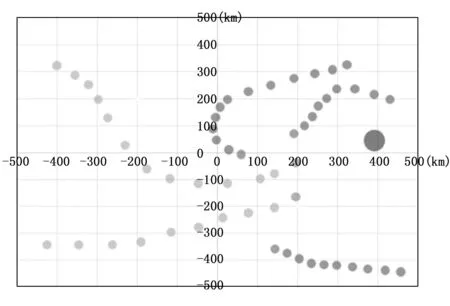
圖7 智能體機動行為
并且經過訓練的智能體也表現出協作的特征,圖8中顏色較深的智能體作為誘餌,吸引了敵方3枚導彈的圍追堵截,通過消滅攔截方的3枚導彈,為己方的突防導彈創造了條件,另一枚導彈最后順利完成任務目標。
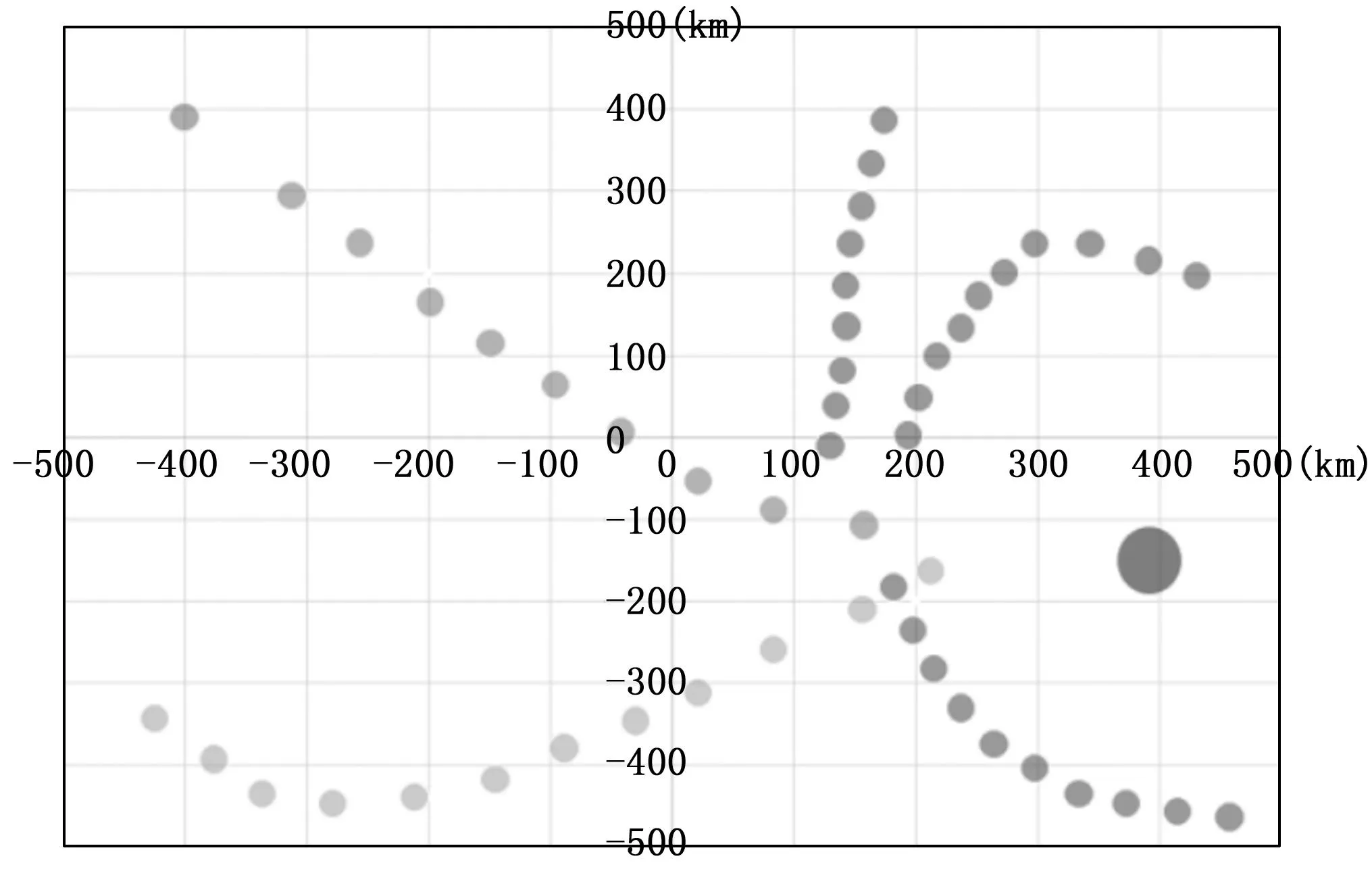
圖8 智能體協同行為
實驗經過100次仿真模擬,如表2所示,經過EPF-MADDPG算法訓練的突防方導彈勝率可以達到73%,實驗結果表明,訓練出來的協同突防策略具有明顯合作以及欺騙對手的行為,突防導彈不僅簡單的依靠速度進行突防,同時表現出一些高級的協同行為,極大提高了突防策略的訓練效率。
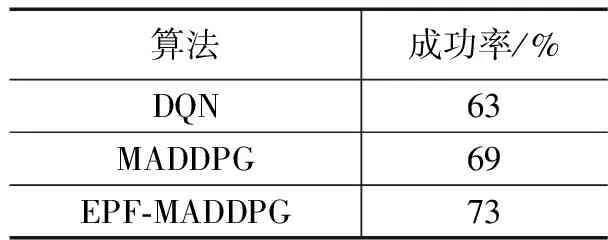
表2 各個算法突防成功率
4 結束語
為了在仿真環境中實現多智能體對抗的智能決策,提出了一種基于 MADDPG 的異構多智能體對抗決策算法,輔助決策者進行導彈集群突防方案的制訂,并且在方案執行的過程中具有一定的自主決策能力。為了進一步地驗證MADDPG算法對于導彈突防場景的可行性,本文還從仿真的角度進行驗證,經過基于經驗池篩選策略的MADDPG算法計算的突防策略成功率達到73%。
本文還存在待改進的方面:首先,對于導彈突防任務來講,不僅有同波次導彈間的協同配合,同時還應有多波次導彈的協同配合,對于任務分解規劃,以及戰場態勢的偵察獲取,還需要進行深入的研究改進,得到一個簡單易行的方法;其次,本算法的仿真業務場景具有特殊性,仍需進行改進學習,在不同環境不同維度進行推演驗證。
猜你喜歡
教學考試(高考化學)(2021年2期)2021-05-30 06:15:52
中學生數理化·高一版(2020年3期)2020-04-21 08:03:20
中學生數理化(高中版.高考理化)(2020年2期)2020-04-21 05:32:50
小學生作文(低年級適用)(2019年9期)2019-10-08 08:37:10
表面工程與再制造(2019年6期)2019-08-24 06:40:04
文苑(2018年23期)2018-12-14 01:06:06
文苑(2018年19期)2018-11-09 01:30:14
文苑(2018年17期)2018-11-09 01:29:26
文苑(2018年21期)2018-11-09 01:22:32
商周刊(2018年18期)2018-09-21 09:14:46
