Q學習博弈論的WSNs混合覆蓋漏洞恢復
2024-02-29 09:23:26張鸰
機械設計與制造 2024年2期
張 鸰
(南京交通職業技術學院,江蘇 南京 211188)
1 引言
無線傳感器網絡部署了大量小型智能設備,這些設備形成分布式自組織網絡,用于數據收集和管理,可應用于各種領域,如棲息地監測、機器監控、農業精確定位、室內控制、智能報警和軍事應用等[1]。然而隨機部署、傳感器電池耗盡硬件故障、軟件缺陷和安全攻擊等原因可能會造成覆蓋漏洞,嚴重降低了效率、可靠性和服務質量[2]。
一般通過拓撲控制解決覆蓋漏洞,拓撲控制方案的主要研究領域可分為兩類:基于節點重新定位的方案和基于功率傳輸的方案[3]。重新定位方案可分為虛擬力方案、Voronoi 方案和翻轉方案。文獻[4]提出了一種基于徑向虛擬力的重新定位方法,稱為分布式自蔓延算法(DSSA)。文獻[5]提出了一種基于Voronoi方案和翻轉方案混合的自適應檢測修復策略,有效綜合了Voronoi方案的高精度優點以及翻轉方案的簡易特性,盡管上述方法在傳感器移動和小范圍覆蓋漏洞恢復方面性能良好,但它在大范圍覆蓋漏洞中并不有效,因為它需要大量的迭代計算。另外由于獨立和分布式的運動,節點重新定位可能會產生新的小覆蓋漏洞。在某些情況下,某些節點的運動可能在平均最大化方面無效,并可能耗盡傳感器電池電源,降低其到達和修復覆蓋漏洞的能力。
為了進一步提升回復覆蓋漏洞的效果,考慮將智能算法引入回復策略中。文獻[6]提出了一種基于模糊粒子群優化算法的無線傳感器網絡漏洞修復方法,有效提升了傳感器位置優化,從而強化了修復能力。文獻[7]提出一種基于Delaunay圖的人工蜂群算法控制移動節點的部署策略,通過固定節點形成的Delaunay圖先找出覆蓋漏洞,估算覆蓋漏洞面積并計算出移動節點。文獻[8]提出了一種基于深度神經網絡與模糊熵相結合的集中式傳感器網絡漏洞恢復方法,極大地提升了恢復效果。但是上述方法由于需要進行智能優化,因此系統整體能耗成本較大,對于實際應用存在一定難度。另外上述方法考慮的傳感器系統均為集中式系統,針對分布式傳感器系統中存在的漏洞恢復是否有效還需要驗證。
為此,這里提出了一種基于Q學習算法的博弈論的無線傳感器網絡混合覆蓋漏洞恢復方法。設計了一種能夠以分散、動態和自治的方式縮小覆蓋差距的混合算法,該方法利用基于Q學習算法的博弈論概念,融合了節點重新定位和功率傳輸調整兩種覆蓋控制方案。仿真結果證明了提出方法的有效性。
2 相關理論
2.1 系統模型
無線傳感器網絡可以看作是一個連通圖G(V,E),其中,V是表示節點的頂點集合,E表示節點間鏈接的邊集合。每個傳感器可以設計為二維矩形區域中的單位圓盤圖,表示為Δ=[xmin;xmax]×[ymin;ymax],具有感應半徑Rs和通信半徑Rc。為了簡單起見,這里假設S中的所有節點都具有相同的Rc。設S1∈S,S2∈S,如果S1在S2的傳輸范圍內,則這對節點(S1,S2)是雙向連接的,令Ei表示傳感器節點i的起始能量。假設每個節點都是通過GPS定位的,由于傳感器節點的可預測或不可預測的無效性,例如電池電量耗盡或長期放置導致的爆炸,可能會出現覆蓋漏洞。覆蓋漏洞i可視為半徑為和圓心為(xHi,yHi)的圓,此圓表示節點故障發生的區域。通過組合不同圓心和半徑的多個覆蓋漏洞,可以輕松估計不同形狀且復雜的覆蓋漏洞。設節點D表示受損節點集,U節點表示未受損節點集,位于空洞區域的每個傳感器節點Si∈S屬于D節點;否則,將其視為未損壞的節點,屬于U節點。
2.2 博弈論
博弈論(Game Theory,GT)是一種用于在不確定環境中做出戰略決策的數學模型,它關注的是情景建模,以描述相互依賴代理的可能行為,從而確定最優策略。在處理GT中的競爭情況時,一個代理選擇行動的結果在很大程度上取決于其他代理的行動。
定義1(博弈論)[9]:策略形式ξ={τ,Λ,υ} 的博弈由三個基本部分組成,定義如下:
(1)參與者集合τ={1,…,n},其中,n是參與者的數量。用-i表示不是i的參與者。
(2)行為空間Λ={ Λ1,Λ2,…,Λn},每個參與者i都有各自的策略Λi,其中Λi是一系列參與者的行為。
(3)效用函數集合υ,其中每個參與者i都有各自的效用函數υi:Λ →R,用來評估參與者的回報。
用Λi表示動作輪廓{a1,a2,…,am},?i∈τ。由除i以外的策略配置文件表示,即除i:{ Λ1,…Λi-1,Λi+1,…,Λn}之外的所有參與者的行動集合。
定義2(納什均衡(Nash Equilibrium,NE))[10]:在這種狀態下,考慮到其他參與者采用的策略,任何參與者都不打算改變自己的策略。如果策略是ξ的NE,對于所有滿足ai∈Λi和,?i∈τ,那么設ξ是一個策略形式的博弈。
定義3(精確勢博弈)[11]。戰略形式博弈Ψ是一種具有勢函數φ:Λ →R的精確勢博弈,如果對于每個i∈τ,滿足a-i∈Λ-i且可以得到:
這里將覆蓋漏洞問題描述為一個潛在的多人重復博弈,在該博弈過程中,傳感器節點代表參與者彼此之間可以通信,從而彌補覆蓋差距。
2.3 Q學習
Q學習是一種基于馬爾可夫決策過程(Markov Decision Pro‐cess,MDP)的強化學習算法,主要依賴于代理與環境之間的迭代交互[11]。在Q學習中,代理選擇從當前狀態st在時刻t執行動作,該動作會獲得新狀態st+1并提供獎勵rt。因此,它包括學習根據當前狀態獲得的先前經驗而執行的動作。策略pi(s)是代理選擇每個可能狀態的計劃,由于學習系統和環境之間的相互作用,參與者策略逐漸得到改進。然而,在實踐中,并不直接使用強化學習算法;更傾向于使用迭代求近似值函數Q(s,a)。因此,將Q(s,a)定義為未來估計收益,一旦學習到這些值,最佳策略就是選擇對應于最大Q值的動作。
對于單個參與者系統,狀態的效用計算為該狀態關于所有可能動作的最大Q值。然而,對于多參與者系統,取決于其他參與者的聯合動作,所以最優性準則不能只考慮個體的動作。因此,將Q學習擴展到多參與者框架時,應考慮其他參與者在選擇動作時的行為。
事實上,Q學習算法在離散狀態和動作下的性能良好[12]。然而,在現實應用中,通常是連續的空間,具有無限的狀態和動作組合。Q學習不能直接適用于連續變量,空間通常需要使用近似函數進行離散化,如梯度下降、特征的線性組合和神經網絡。
3 混合恢復算法
3.1 覆蓋問題表達式
基于上述問題,參與者是傳感器節點,可以彼此同時互相通信,以最小的功耗增強自己的覆蓋區域。此外,這里假設所有參與者都是理性的,每個參與者都試圖根據其對網絡的局部期望和自己對其他參與者可能采取的行動的預測來增加其預期效用函數。在每個時間步長t>0時的動作集,節點i∈τ可以選擇其可能作用的集合ai∈Λi。如上文所述,混合拓撲控制使用節點重新定位和功率傳輸調整。因此,每個移動傳感器i∈τ可以選擇改變其位置pi和功率傳輸(傳感器感應范圍r)i的組合動作:ai=(pi,ri),?ai∈Λi。(1)假設pi=(pxi,pyi)是節點i在二維空間中的當前位置:pi→p'i是其位置的變化,其中是節點i的下一個位置。(2)假設分別是節點i的當前和下一次時間感應范圍,ri→r'表示傳感器感應范圍的變化,Rmin和Rmax分別是傳感器節點的最小和最大傳感范圍。效用函數每個節點i都有一個效用函數或收益函數υi:Λ →R,定義為:
式中:P(ai,a-1)、C(ai)—節點i所選擇的策略的利潤和成本;μα、μβ—平衡博弈利潤和成本的權重。
在一個重復的博弈過程中,每個時間t參與者同時選擇他們的行動策略,并接收他們的效用函數,該效用函數取決于應有的回報和付出。當所有參與者正確預測對方參與者的策略并對他們的預測做出最佳反應時,得到的結果就是納什均衡狀態。
每個節點都有一個非重疊傳感區域(Non-Overlapping Sens‐ing Area,NOSA),定義為僅由相關節點覆蓋的區域,如圖3所示。為了使總覆蓋面積最大化,縮小覆蓋間隙,傳感器節點應減少與相鄰節點的重疊區域;因此,將利潤函數最大化等同于NOSA值最大化:
式中:Ni—節點i的鄰域的集合,花銷成本表示恢復覆蓋漏洞時傳感器節點消耗的能量。
該成本主要包括兩種類型:
(1)改變用Epow表示的傳感器工作時功率消耗的能量:
(2)運動時消耗的能量,從而改變由Emot表示的位置。與改變節點i的感應功率相關的能量的表達式如下:
與節點運動相關的能量的表達式為:
式中:Rsi—感應范圍;t—持續時間或跨度。
考慮到傳感器運動和感應功率變化,總消耗能量Etot為消耗能量之和:
引理1:指定的覆蓋博弈ξcov是一個精確勢博弈,如果存在一個函數φ:Λ →R,從而滿足?ai,-i∈Λi,?a-i∈Λ-i,那么有:
φ的定義式如下:
式中:Ptot—網絡總覆蓋率;C—傳感器節點能耗。
證明。對于任何一個策略a:(ai,a-i)∈Λ,?i∈τ,這里從Λ中任意選擇一個策略:=(,a-i)。將覆蓋博弈算法ξconv定義為精確勢博弈。為了證明這一點,將節點i的策略從ai改為,并不改變其他策略。
可以得到:
通常,由于節點i重疊覆蓋區域至少已經被另一個傳感器節點覆蓋,所以其任何變化都不會對整個網絡覆蓋產生任何影響:
因此,可以得到:
因此,當參與者i從策略ai轉換到策略ddotai時,潛在函數的變化等于回報/效用函數的變化。通過參考定義3,可以證明覆蓋率博弈是一個精確勢博弈。
3.2 基于分布式收益的Q學習算法
收益函數不僅取決于傳感器節點動作,還取決于其鄰域的動作。由于分布式學習方法只需要從前面的步驟中獲得回報,因此是最合適的解決方案,參與者調整自己的行為以適應其他參與者行為的變化。這里提出了一種新的基于分布式收益的Q學習算法來執行先前制定的覆蓋博弈,處理的是多個參與者的博弈;因此,采用了多智能體強化學習的概念。這里所提出的算法流程如算法1所示。
算法1:基于分布式收益的Q學習算法
(1)初始化:在t=1時,所有傳感器節點保持其初始隨機位置。隨機初始化Q(s,ai,a-i),NbC(s,a-i)←0和n(s)←0,其中?s∈S;?ai∈Λi;?a-i∈Λ-i。令α∈[ 0,1 ]作為初始學習率,ε為初始探索率。
(2)選擇動作并更新狀態:每次t≥2時,每個傳感器節點根據以下規則更新其狀態:
(3)觀察電流s:n(s)←n(s)+1
(4)選擇探索速率ε
(5)概率ε返回隨機動作
(6)否則,概率為(1 -ε)。通過求解:
(7)學習:觀察對方的行為a-i、獎勵R(s,ai)和下一個狀態:
(8)重復:傳感器i重復執行步驟(2)、步驟(3),直到滿足結束條件。
回報函數在探索和利用過程之間切換,以找到最佳的行動序列。事實上,探索過程有助于節點快速發現未知環境,而開發過程則使節點能夠保持有效場景,指標ε控制系統先前獲得的信息的利用與環境探索之間的權衡。
4 仿真結果分析
4.1 仿真參數設置
在模擬過程中考慮了一個正方形區域δ,其邊長為100m,將其劃分為預定義數量的小正方形。每個小正方形的面積為1m2,其中心是要覆蓋的點,用Matlab進行了仿真試驗。節點通過均勻分布隨機部署在感興趣的領域(AoI)δ中。傳輸范圍固定為30m,傳感范圍在7m和15m之間隨機選擇,如表1所示。如果通信半徑大于傳感半徑的兩倍,則假定網絡連接已滿。

表1 模擬參數值設置Tab.1 Analog Parameter Value Setting
如上所述,Q學習不適用于連續空間,需要一個近似函數來離散該空間,這里使用了一種簡單的離散化形式。事實上,代理執行兩個操作,即更改位置和功率傳輸。對于每個算法迭代,節點通過沿左、右、上或下的方向移動一步來更改其位置。傳感器感應半徑在該集合中取一個值:7、9、11、13或15。文獻[13]提出的分布式混合覆蓋漏洞恢復方法縮寫為DHCHRA。
算法中使用ε來平衡探索和勘探過程。使用表中給出的取值范圍有助于Q學習算法收斂到最優解。
在這里,考慮了傳感器移動所消耗的能量及其傳感范圍的變化,因此傳感器應該提高其傳感范圍,以避免不必要的移動,尤其是在頻繁出現覆蓋漏洞的情況下。針對每個場景生成了四個不同大小的破壞事件。在每個新出現的覆蓋漏洞之后,算法保持活動狀態,直到達到95%的總覆蓋率。如果未滿足此閾值,則當迭代次數達到500次時,算法將停止運行。最大迭代次數設為500次,以防止傳感器節點因電池中剩余能量耗盡而集體失效。
4.2 仿真結果
4.2.1 無障礙情景下的AoI
將這里的算法結果與DSSA和DHCHRA的結果進行了比較,使用四種不同的場景在相同的初始節點分布上測試了所有算法的實例。
在該場景中,呈現了一個無物理障礙的檢測區域,并生成了四個破壞事件。破壞事件時間序列為1s、14s、57s和161s。一個時間樣本結果,如圖1所示。證明了所提出的基于博弈論的Q學習算法恢復覆蓋漏洞的能力,圖中的顏色是指可以覆蓋區域的傳感器數量。準確地說,隨著顏色變為藍色,區域中的傳感器數量減少;而當顏色變為紅色時,傳感器數量增加。

圖1 時間樣本結果Fig.1 Time Sample Results
然而,一種色表示區域未被任何傳感器節點覆蓋。從圖1(b)、圖1(d)、圖1(f)和圖1(h)可以發現,由于連續破壞性事件而出現的新覆蓋漏洞,圖1(c)、圖1(e)、圖1(g)和圖1(j)說明了處理四個覆蓋漏洞的勢博弈行為。這些結果圖清楚地顯示了這里拓撲控制方案在連續覆蓋漏洞后,修復網絡并保持最高覆蓋閾值的效率。傳感器節點調整傳感范圍和位置,以便快速準確地彌補覆蓋范圍的差距。
給定算法中出現每個覆蓋漏洞NS=250個節點后所需迭代次數的平均值,如圖2所示。對于這三種算法,迭代次數隨著連續事件的出現而增加。DSSA和DHCHRA分別在事件2和事件3后達到停止標準,迭代次數等于500。與其他方法相比,該方法收斂速度更快。它成功地恢復了四個覆蓋漏洞,并在達到停止標準之前達到上述覆蓋閾值,即總覆蓋面積的95%。
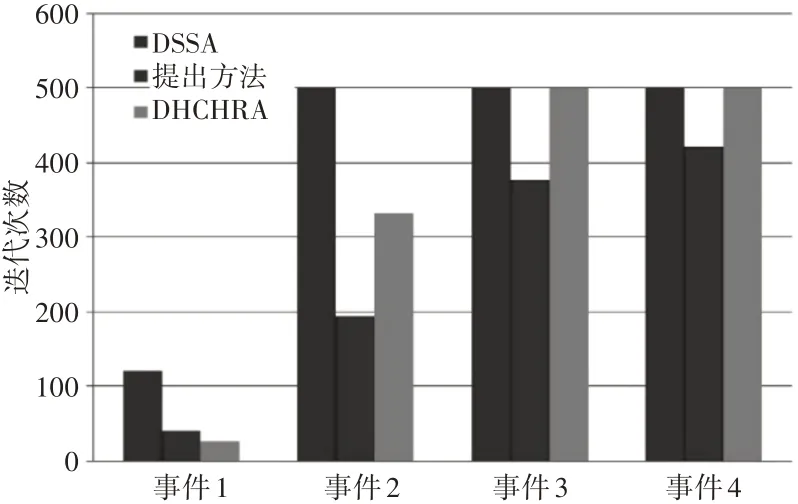
圖2 迭代次數的平均值Fig.2 Average Number of Iterations
DHCHRA、DSSA的總覆蓋率的百分比,以及考慮到AoI中部署的傳感器節點(50到250個節點)的數量,總覆蓋率性能對比,如圖3所示。在連續四個覆蓋漏洞出現期間,對總覆蓋率進行評估。從圖3中可以看出,所提出的算法在整體網絡覆蓋方面優于上述算法,并模擬了DSSA、DHCHRA 和提出的方法在能耗方面的效率。
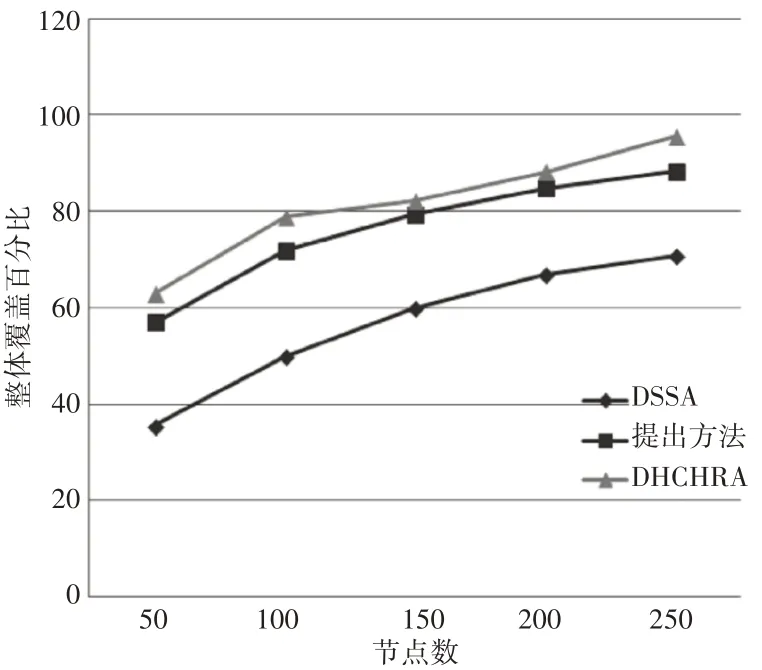
圖3 總覆蓋率性能對比Fig.3 Comparison of Total Coverage Performance
與感測功率的變化相關的消耗能量、與節點運動相關的消耗能量以及總消耗能量,如圖4(a)~圖4(c)所示。結果表明,這里的方法在能耗方面優于其他兩種方法。如圖2 所示,與DSSA 和DHCHRA 相比,所提出的方法對連續覆蓋漏洞具有快速響應。這些結果意味著傳感器節點在覆蓋范圍方面移動占據其最佳位置的可能性較小,這使網絡能夠消耗較少的能量,如圖4 所示。從而能夠擴展網絡的生存能力。
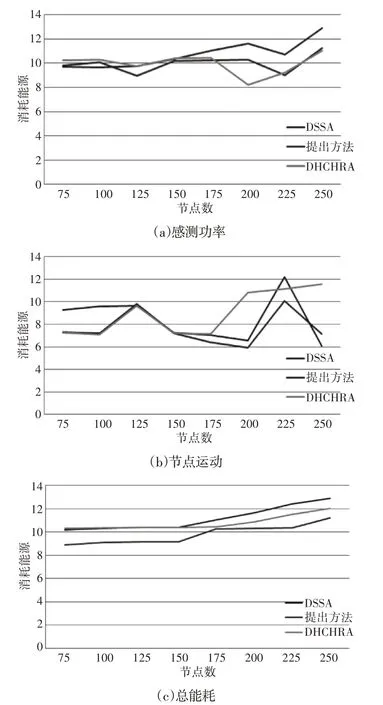
圖4 三種情況下的能量消耗Fig.4 Energy Consumption in Three Cases
4.2.2 有障礙情景下的AoI
為了使這里模擬更接近實際情況,我們在模擬場景中考慮了兩種障礙物形狀:矩形和T形,將障礙物放在AoI的中心,傳感器節點可以放置在障礙物的邊界上。這兩種情況的結果如下,一個時間段的示例,證明了所提出的基于博弈論的Q學習算法能夠分別恢復包含矩形和T形障礙物的檢測區域中的覆蓋漏洞,如圖5、圖6所示。
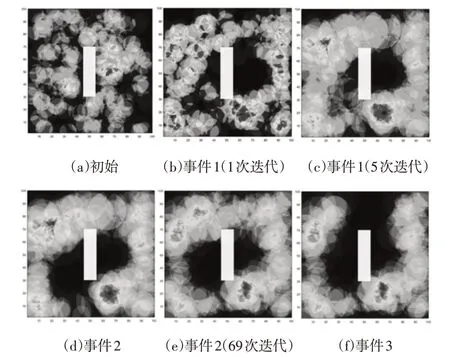
圖5 矩形時間樣本事例Fig.5 Time Sample Examples of Rectangle
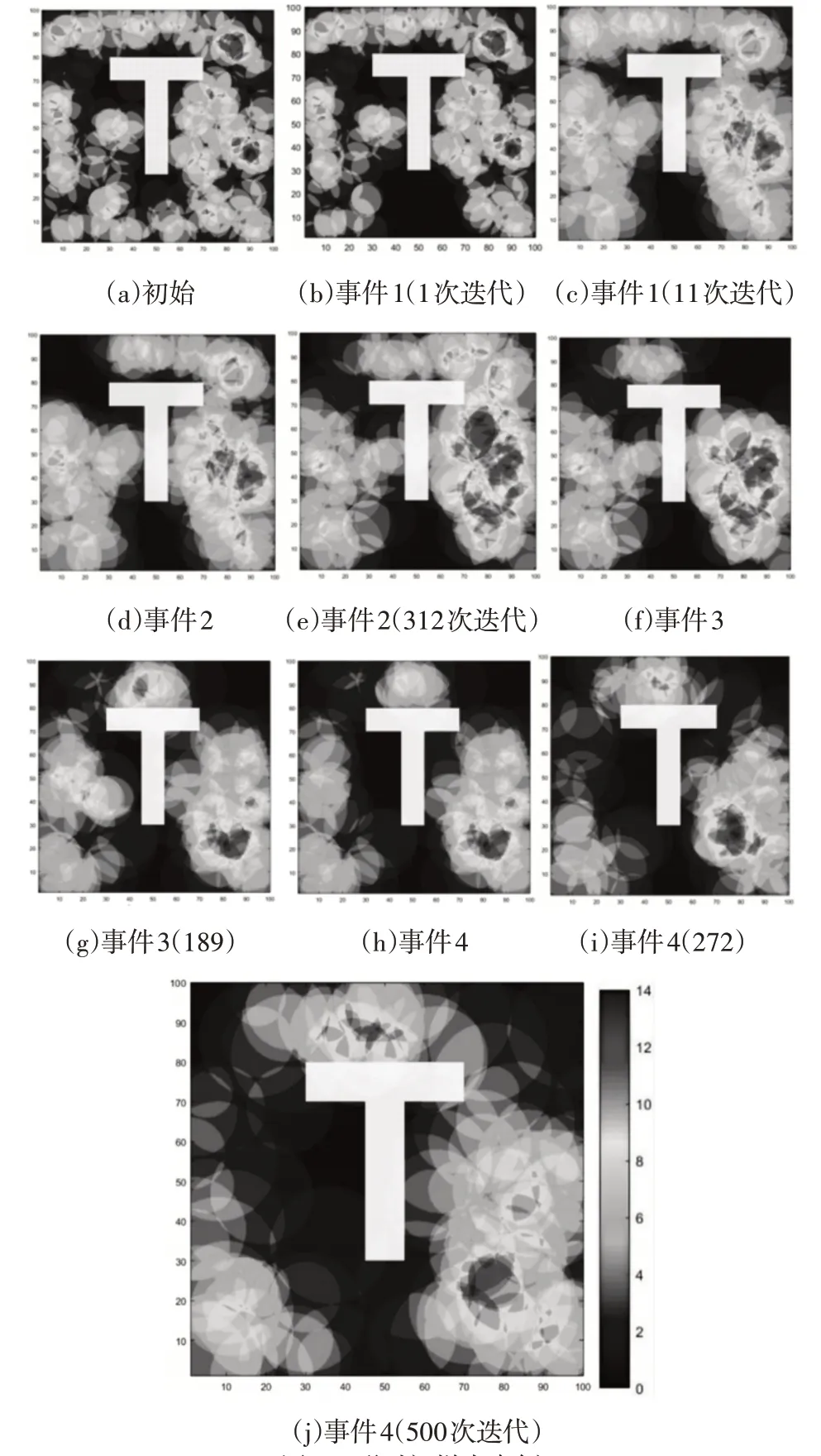
圖6 T形時間樣本事例Fig.6 Time Sample Examples of T
矩形障礙場景和T形障礙場景中由于連續破壞性事件而出現的新覆蓋漏洞,如圖5(b)、圖5(d)、圖5(f)、圖5(h)和圖6(b)、圖6(d)、圖6(f)、圖6(h)。矩形障礙情景和T形障礙情景的破壞事件時間序列分別為1s、5s、70s和273s,以及1s、11s、169s和312s。其他子圖說明了處理矩形障礙物形狀檢測區域中四個覆蓋漏洞的方法的行為。圖中結果證明了這里的方法即使存在障礙物的情況下仍舊具備消除覆蓋漏洞的能力。
針對所提出的障礙場景恢復每個覆蓋漏洞所需的迭代次數的平均值,如圖7所示。對于矩形障礙物場景,DSSA和DHCHRA在事件2后達到停止標準。這里的方法恢復了四個覆蓋漏洞,在達到停止標準之前成功地達到了覆蓋閾值。對于T形障礙場景,DSSA 和DHCHRA 分別在事件1 和事件2 后達到停止標準。然而,這里的方法在達到總覆蓋面積的92%之前恢復了四個覆蓋漏洞。
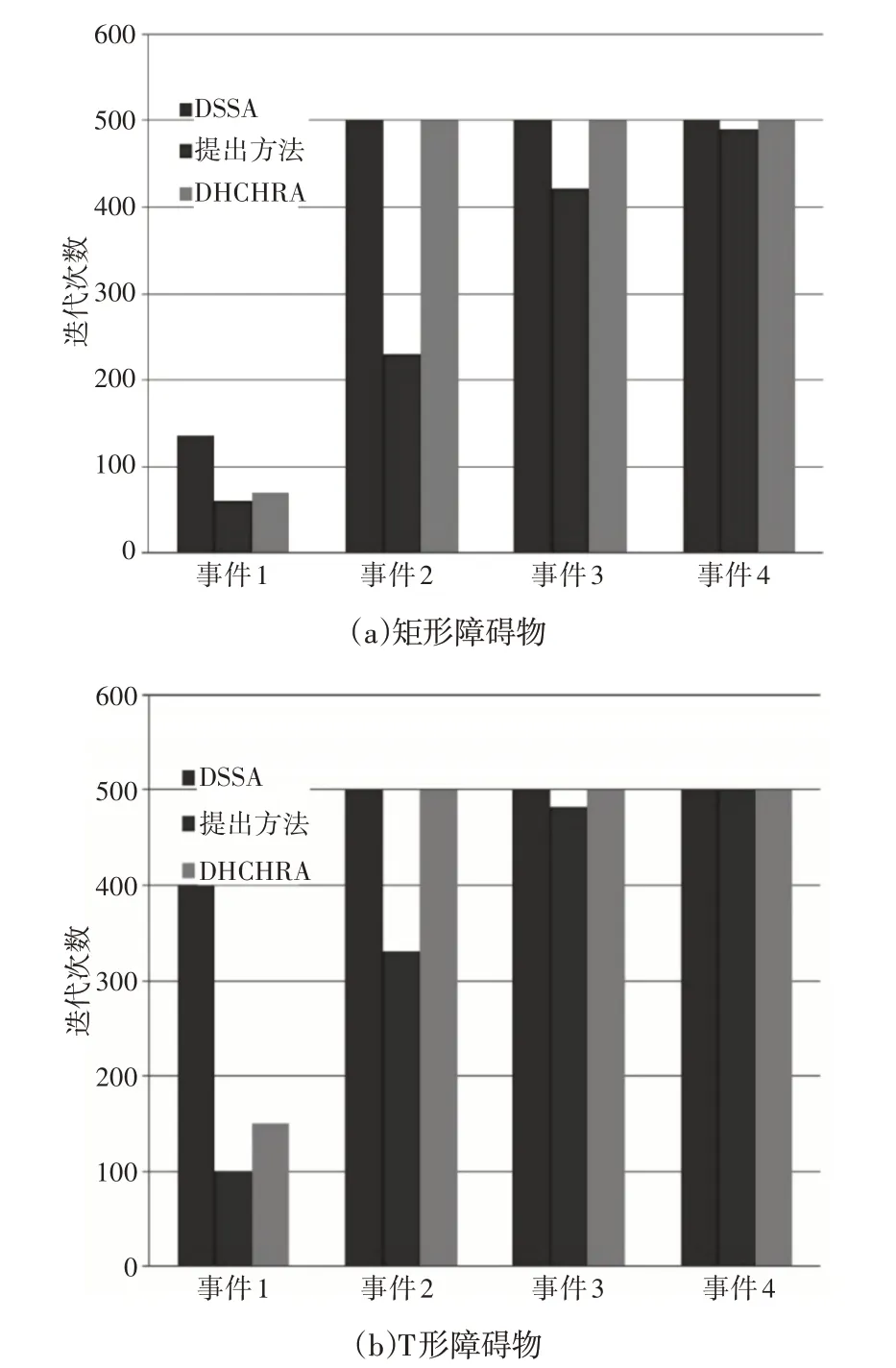
圖7 迭代次數的平均值Fig.7 Average Number of Iterations
DHCHRA、DSSA 的總覆蓋率的百分比,以及這里的算法改變部署在具有障礙物的檢測區域中的傳感器節點的數量如圖8所示。在連續四個覆蓋漏洞出現期間,對總覆蓋率進行評估。從圖中可以發現,即使在存在障礙的情況下,提出的算法在總體網絡覆蓋率方面也優于其他算法。
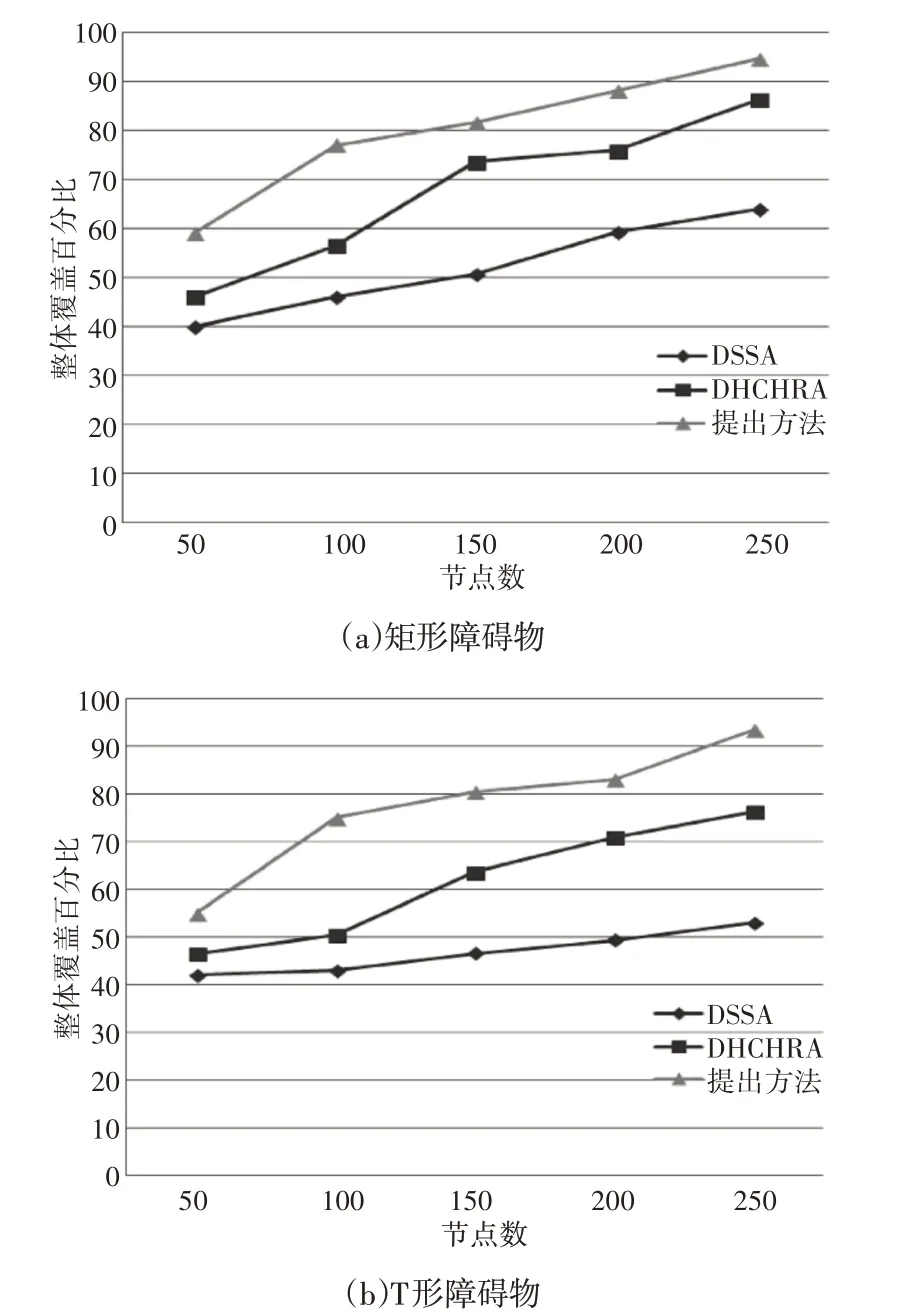
圖8 覆蓋率情況Fig.8 Overall Coverage
DSSA、DHCHRA 的效率,以及這里的算法在有障礙物的探測區域消耗的能量,如圖9、圖10所示。與感測功率變化相關的消耗能量、與節點運動相關的消耗能量和總消耗能量,如圖9(a)、圖9(b)、圖9(c)、圖10(a)、圖10(b)、圖10(c)所示。結果表明,這里的方法在能耗方面優于兩種方法。
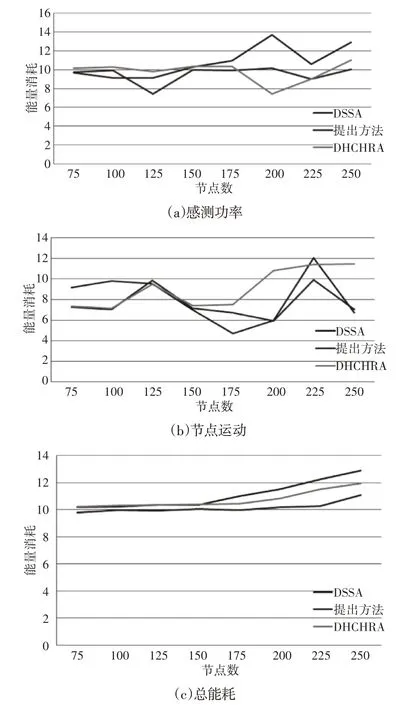
圖9 矩形障礙下的能量消耗Fig.9 Energy Consumption Under Rectangular Obstacles
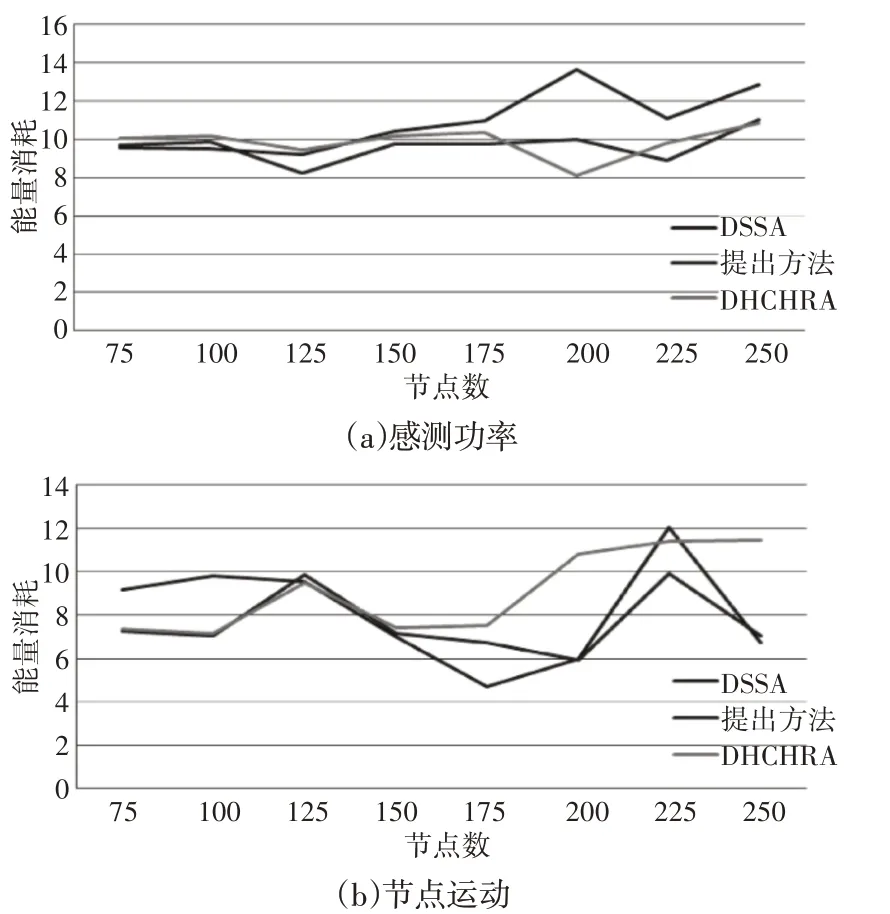
圖10 T形障礙下的能量消耗Fig.10 Energy Consumption Under T Obstacles
4.2.3 無需功率調整的拓撲控制方案
許多無線傳感器網絡應用不支持功率傳輸調整,因此,在本節中,提出了一種在無障礙AoI中測試的無功率控制拓撲控制策略,節點的動作僅限于位置調整。針對不同建議場景,即無障礙AoI、矩形障礙AoI、T形障礙AoI以及無障礙AoI無功率調整的控制拓撲方案,這里的方法的總覆蓋面積的百分比,如圖11所示。通過改變傳感器節點的數量(從50到250個節點),評估總覆蓋率的百分比。從圖11可以發現,對于每個提出的場景,即50、100、150和200個節點,這里的方法均獲得了令人滿意的覆蓋率。此外,有250個節點達到了覆蓋閾值(總覆蓋面積的95%),但T形障礙場景僅達到總覆蓋面積的93%。這里的方法在所有場景中的能耗結果,如圖12所示。對于無障礙場景、矩形障礙場景和T形障礙場景,能耗值均是收斂的。然而,在不進行功率調整的情況下,該方法的能耗明顯增加。
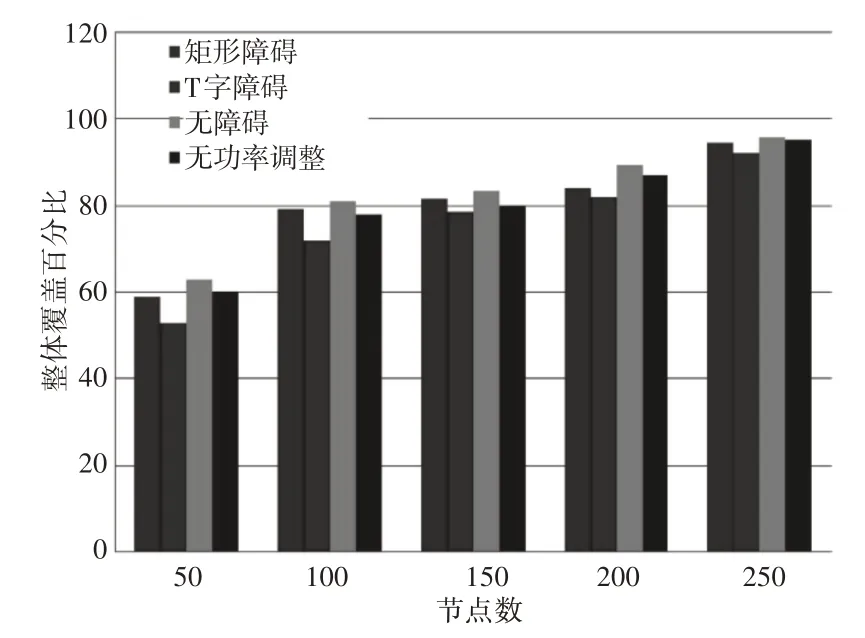
圖11 這里方法的總覆蓋百分比Fig.11 Total Coverage Percentage of Proposed Method
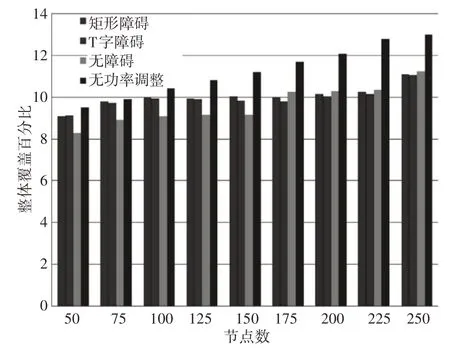
圖12 能耗結果Fig.12 Energy Consumption Results
5 結論
針對惡劣環境下分布式無線傳感器網絡,為了降低成本與恢復能力,提出了一種Q學習博弈論的無線傳感器網絡混合覆蓋漏洞恢復方法。最后仿真結果可以證明如下結論:
(1)提出的方法有助于傳感器有效預測應采取的最佳策略,并執行最準確、最成功的決策,從而能夠在實現惡劣環境下分布式無線傳感器網絡的覆蓋漏洞恢復,并且能夠降低能耗成本。
(2)與其他算法相比,在無功率調整的情況下,該算法的覆蓋率是收斂的,然而,能耗有所上升。
(3)在無障礙AoI場景和有障礙AoI場景中,這里的方法所產生的拓撲控制方案在能耗和覆蓋率方面優于其他方法。但是,在有障礙物的情況下,在遵守預定義的覆蓋閾值的同時恢復覆蓋漏洞的方法的降低了恢復速度。
猜你喜歡
教學考試(高考化學)(2021年2期)2021-05-30 06:15:52
中學生數理化·高一版(2020年3期)2020-04-21 08:03:20
中學生數理化(高中版.高考理化)(2020年2期)2020-04-21 05:32:50
小學生作文(低年級適用)(2019年9期)2019-10-08 08:37:10
兒童故事畫報(2019年5期)2019-05-26 14:26:14
數學大世界(2018年1期)2018-04-12 05:39:14
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年7期)2015-08-11 15:03:12
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
