基于流計算和大數據平臺的實時交通流預測
2024-02-22 07:45:08李星輝魏鵬飛
計算機工程與設計 2024年2期
關鍵詞:模型
李星輝,曾 碧,魏鵬飛
(廣東工業大學 計算機學院,廣東 廣州 510006)
0 引 言
如今,城市每天所產生的交通數據量龐大,以深圳某一年的GPS數據為例,深圳市每一輛車的實時定位數據每5 min產生一次,一個月的深圳市滴滴網約車GPS數據就已達到140 GB,而大數據及其可視化技術的發展為交通數據數據挖掘方面提供了便利,不僅為數據提供了足夠的存儲空間,而且在實時數據抓取和預處理方面貢獻巨大。
近期在交通流預測方面,Hsueh等[1]提出用LSTM作為預測交通流速度的模型。交通流預測模型往往參數量多,通常是在GPU上以離線的方式訓練相當長的時間,然后部署到實際的云服務器中用于實時預測。但在實際交通場景中,交通數據不斷更新,交通流預測模型也需要能隨著數據集的更新不斷調整。因此這里提出一種基于流計算和大數據平臺的實時交通流預測方法,在保持一定精度前提下,訓練速度比在GPU上跑的更快,可對實時交通流數據進行捕獲、建模分析和預測,從而滿足實時應用的需求。
綜上所述,主要貢獻如下:
(1)提出一種Flink流計算框架和交通數據預處理方法。
用Kafka消息系統采集交通路段傳感器的數據,經過Flink流式的預處理后,把數據送入到獨立分布式的大數據集群中,實現了對交通流數據的實時抓取—預處理—分流。
(2)提出一種基于Hadoop大數據平臺的深度學習模型并行訓練模式,充分利用大數據資源與技術實現最大程度的數據并行。
(3)采用了某個交通路段的多個道路傳感器產生的數據對模型進行訓練和預測實驗。利用滑動窗口自動地選取最近鄰的歷史數據集對模型進行訓練并用于預測,追求流式自動化和實時處理。在保持一定的精度的情況下,探索了比GPU訓練方式更快的模式,滿足了實時預測的要求。
1 相關工作
1.1 交通流預測相關研究
在交通流預測領域里,基本上都是采取先訓練模型,然后用實時數據集去預測未來的某個道路的車速度和流量。Fitters等[2]利用LSTM模型,先基于車流的密度去劃定一些圓形的區域,提取坐標點之間的時空聯系作為特征輸入到模型,以預測未來某個路口的交通流量。Chen等[3]以Bi-GRU模型作為主干網絡預測未來道路的車流速度,通過增加GRU模型的層數讓模型學習到的特征更多,從而提高訓練精度。Zhang等[4]通過KNN模型與額外的時間-空間-距離權重公式結合去直接預測交通流量,整個過程都將模型運行在Spark中得以加速。以上所提到的方法都是采用離線訓練和處理的方式,模型參數量大,需要較長的訓練時間,很難滿足實時性的要求。所以如何讓模型在保持一定精度的情況下,盡可能縮短訓練時間來實現預測實時性是亟待解決的問題。
1.2 流計算的相關研究
流計算通常是采用基于大數據框架的實時采集、分析和導出數據的工具來實現的,目前應用最多的是SparkStrea-ming和Flink。流計算被廣泛應用到很多領域,這些領域都對實時性要求高和比較依賴于歷史的時間性或空間性,Kanavos等[5]在冬季天氣預測里,SparkStreaming主要負責實時采集天氣傳感器的各類特征數據。在網絡沖突檢測領域,Garcia等[6]以SparkStreaming 作為主要框架進行網絡交通流信息的處理。Tun等[7]提出了采用Kafka集群對輸入流進行采集,經過SparkStreaming批轉換然后進行實時分析。對比SparkStreaming微批處理機制,Flink在時間處理機制方面有著更為靈活的方式,不但能夠基于當前的處理時間,也能夠基于實際的事件時間。Abbas等[8]對交通擁塞進行減緩,在對交通擁塞的檢測之前,利用交叉路口的攝像頭捕捉數據,并對連同道路設施信息一起計算出平均速度、車輛的密度等指標。這種方式可以及時地捕捉到路況的時空變化。Flink對數據集處理延時低,但Abbas等[8]并未涉及交通流預測,本文將Flink實時流計算框架和深度學習模型結合,實現實時采集、處理和訓練的一體化。
1.3 并行計算的研究
Mahmud等[9]和Dafir等[10]對并行計算進行了分類。首先“垂直并行”是運行在同一個服務器上并且添加一定的處理器、內存和快速硬件,如FPGA;而“橫向并行”則是集成多個分布式服務器的系統,把工作量分配給多個服務器去并行。
“垂直并行”中,GPU最大的特點是它擁有超多計算核心。圖1為GPU和CPU的組成原理對比,GPU每個處理器都相當于一個“核",在實際的GPU運算場景中,這些處理器之間相互獨立,其計算能力比起CPU核較弱。GPU相對于CPU是非常昂貴的資源,以時空圖卷積網絡[11]和分層結構的圖神經網絡[12]作為主干網絡的交通流預測模型,GPU在離線的情況下訓練這些深度學習網絡加速效果很明顯,但是GPU顯存不夠用會導致訓練時batch大小被限制,GPU的并行效果突破不了瓶頸,在這種情況下,可能需要再引入顯存更大的GPU以滿足需求,但這樣成本太高。
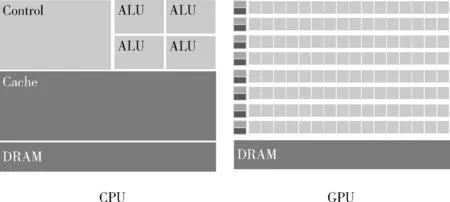
圖1 GPU與CPU內部組成對比
Hadoop大數據集群的Yarn資源管理多“核”和內存,CPU核計算單元對比GPU單個計算單元的處理能力要出色,所以從理論上來說利用大數據平臺的多核資源提高并行度,把工作量分配給多個節點,通過增大每次“喂入”深度學習網絡的batch-size來提升訓練速度,有著潛在的優勢。
1.4 分布式計算框架相關研究
1.4.1 Spark和Ray
Spark繼Mapreduce后,在工作負載方面表現較優越。近幾年頻繁項集挖掘相關算法(FIM)被部署在了Hadoop Mapreduce上,但是由于磁盤IO的問題,Mapreduce在FIM這種高迭代的算法上效率不高,Singh等[13]把FIM的其中一種算法Eclat的思想設計成Spark的RDD框架下的邏輯,使之并行化,并且通過不斷地增加可用核數和數據集的大小優化效率,展現出了可擴展性。Zarindast等[14]在Spark RDD的框架下設計識別高速公路擁堵的模型和邏輯,其模型能夠展現范圍更大的時空擁堵特征,其計算能力之高與覆蓋范圍之廣得益于高效Spark分布式數據處理系統。
Ray[17]分布式計算框架吸收了Spark在數據邏輯上的好處并且具備了像Yarn一樣的資源管理功能。在Ray的遠程調用函數中可以自由定義多個遠程節點并按需分配計算資源。Ray的分布式應用能直接無縫地集成到Spark數據處理的流水線中,在Spark平臺中Ray給予其更為靈活的資源分配與調度方式。
1.4.2 分布式集群下的深度學習
深度學習與大數據平臺的結合在電商領域,Mishra等[15]基于Analytics Zoo,把商品推薦算法關聯規則分析和協同過濾算法部署在分布式計算平臺上取得了一定的成效,展現了Spark集群的可擴展性,比起單機模式在訓練精度和速度上大大提升。Haggag[16]基于SparkDL,通過不同的節點數和并行度,對比在不同的配置下網絡沖突檢測算法的訓練速度。
以上方法基于分布式集群加快模型訓練速度的,但是對于節點的每個任務的資源分配無法細化,而Ray可以進一步操控資源的分配,使資源利用率和擴展性更高和更強。
2 系統架構與問題建模
2.1 系統架構
整個系統架構如圖2所示,主要包括兩大部分:一個是基于Flink流計算的環境部署;另一個是分布式深度學習的環境部署。

圖2 實時交通預測系統架構
2.1.1 數據抓取、預處理和采集
首先實時的交通數據都分別存于Mysql,總共有307個傳感器的數據,Flink對這些數據進行校驗,對異常數據,如塞車或者速度檢測異常的數據實時過濾。這些數據源源不斷地流入到Kafka并在某個Topic中進行存放,然后Flink再把這些數據從Kafka“沉積”到HDFS文件系統。
2.1.2 滑動窗口選取數據集
數據進入HDFS文件系統后,本文采用滑動窗口形式選取數據,每過一段時間從HDFS中選取最近的歷史序列數據作為大數據并行框架下預測模型的輸入來訓練模型。
每當有新的數據進入,即新增一小時的數據進入HDFS,負責采集最新數據集的窗口就會以若干小時為單位去移動(具體多少個小時由實際的交通場景去確定)并進行實時預測,如圖2所示。
2.1.3 大數據平臺下的數據并行環境
大數據并行的環境主要包括SparkonYarn和RayonSpark兩個方面。
第一,SparkonYarn作為Spark的其中一種運行模式,將Spark應用部署在Yarn上,SparkonYarn流程如圖3所示。

圖3 SparkonYarn整體流程
第二,RayonSpark把Ray部署在了Spark大數據集群之上,首先,使用conda-pack打包Python環境,在運行時分發到各個節點上。其次,Spark會在Driver節點上啟動一個Spark上下文的實例,SparkContext會在整個集群啟動多個Spark executor執行Spark的任務。除了Spark上下文之外,RayonSpark設計中還會在Spark Driver中創建一個Ray上下文的實例,利用現有的Spark上下文將Ray在集群里啟動起來,Ray的進程會伴隨著在Spark executor,包括一個Ray 主節點進程和其它的Ray從節點進程,圖4為RayonSpark整體架構建立流程。

圖4 RayonSpark整體架構建立流程
結合相關工作所述,把大數據平臺的Yarn和Spark、Ray兩個分布式框架進行整合,使得從數據邏輯方面到資源調度方面可控性高,可擴展性強。
2.2 問題建模
本文基于大數據平臺,采用LSTM作為交通流預測模型,LSTM部署在遠程大數據平臺,結合基于Flink的實時流計算模式,以及部署在大數據平臺多節點的資源分配算法,本文提出了一種基于流計算和大數據平臺下LSTM的實時交通流預測方法RT-LSTM(real-time LSTM)。在后面對比實驗中,與之對比的是離線模式下GPU的訓練方式G-LSTM(GPU-LSTM)和基于CPU和內存的方式(CM-LSTM)。
2.2.1 LSTM模型
(1)LSTM模型包含輸入門Zi、遺忘門Zf和輸出門Zo,其計算公式見式(1)~式(4),其中xt,ht分別為t時刻的輸入和隱藏層輸出
Z=tanh(W(xt-1,ht))+b
(1)
Zi=σ(Wi(xt-1,ht))+b1
(2)
Zf=σ(Wf(xt-1,ht))+b2
(3)
Zo=σ(Wo(xt-1,ht))+b3
(4)
(2)長期記憶Ct、短期記憶ht和最后的輸出Yt的計算見式(5)~式(7)
Ct=Zf·Ct-1+Zi·Z
(5)
ht=Zo·tanh(Ct)
(6)
Yt=σ(W′·ht)
(7)
其中,t指輸入序列的長度,W開頭的參數與輸入和隱藏層維度的拼接的維度一致,需訓練參數有W、Wi、Wf、Wo和W′這5個參數矩陣。
2.2.2 多個遠程節點的資源分配算法
在Ray_on_Spar和Spark_on_Yarn的環境部署完畢后,在大數據平臺開啟多個訓練節點,并把所準備的資源分配到這些節點上,最后得到多個遠程工作節點。具體實現過程如下。
首先獲取Ray的上下文,從Ray上下文獲取到每個executor所分配的core數和executor數,而在Ray層,可以再次劃分子節點數,見算法1的過程(1)至(4)所示。
接著Ray分布式框架開啟多個遠程節點(Remote Runner),并根據每個executor的所分配的core數、executor數和子節點worker數(worker_per_node)分配資源,Ray 把參數Params分配給對象 obj,并且形成遠程工作節點Remote Runner的公式可表示成如算法1的過程(4)。其中RemoteRunner的類型即為obj的類型,而此處的對象類型是基于Pytorch的分布式訓練器,本文2.2.3給出其定義。
預定義好Ray遠程節點的相應參數和對象類型后,接著分配計算資源,包括子工作節點和cpu核,最后將所有工作節點集合起來啟動torch分布式模式setup_torch _distributed,setup_torch_distributed的分布式的原理會在2.2.3詳細介紹。
算法1:啟動多個遠程節點
輸入:Raycontext:Ray環境上下文
PC:在Spark on Yarn后獲取每個executor的所分配的core數。
N:在Spark on Yarn后獲取executor數。
W:預設的每個節點的子工作節點數。
TR:TorchRunner(Pytorch模型封裝運行器)。
Params:LSTM模型參數(包括模型結構model、優化器optimizer、損失函數loss、評判指標merics等)。
預定義函數:R(params)(obj)。
輸出:多個遠程工作節點RW
過程:
(1)Ray_ctx←RayContext.get()
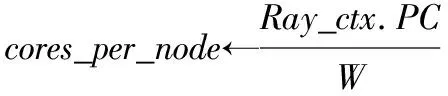
num_nodes←Ray_ctx.N*W
(3)RemoteRunner←R(PC)(TR)
foralli∈{1,2…num_nodes}do
(4)RWi←R(params)(RemoteRunner)
(5) (RWi指的是第i個RemoteWorker)
endfor forallj∈{1,2…num_nodes}do
RWj←set_up(cores_per_node)
(6)endfor
(7)HW←RW0
(8)addr←HW.set_up_address()
(9)forallk∈{1,2…num_nodes}do
RWk.setup_torch_distributed(addr,k,num_nodes)
endfor
2.2.3 Pytorch分布式訓練流程
環境部署后,需要把RT-LSTM模型參數打包給訓練器,這里所用到的是基于Pytorch的訓練器(Torch-Runner),訓練器主要負責把模型參數封裝好,并且定義并行度以及已有資源分配方面的參數,比如子節點數,表示每個訓練器分配多少個worker去訓練。
Pytorch分布式訓練通信的后端使用的是gloo或者NCCL,其中NCCL對應于GPU分布式訓練,gloo對應于CPU分布式訓練(即本文采用的模式)。Pytorch中的數據并行訓練,涉及nn.Data Parallel(DP)和nn.parallel.Distributed DataParallel(DDP)兩個模塊。效率較高的是DDP模式,圖5為DDP模式下各設備(Rank0~Rank4)的參數傳輸機制。

圖5 DDP模式參數傳輸機制
Pytorch分布式訓練流程如圖6所示,第一次循環后,每個設備會把收到的數據和自己的數據相加,然后進行下一個循環,經過K-1次循環后,每個設備都有其中一部分參數的完整數據,比如設備0有完整的b,設備1有完整的c。經過上述的Scatter-reduce后。后續再進行All_gather過程。這樣經過K-1次后,所有的設備都將具有所有參數的完整數據,如圖6所示,下一步將把這些參數匯總到第一個設備RW0上,也如算法2過程的式(5)所示。
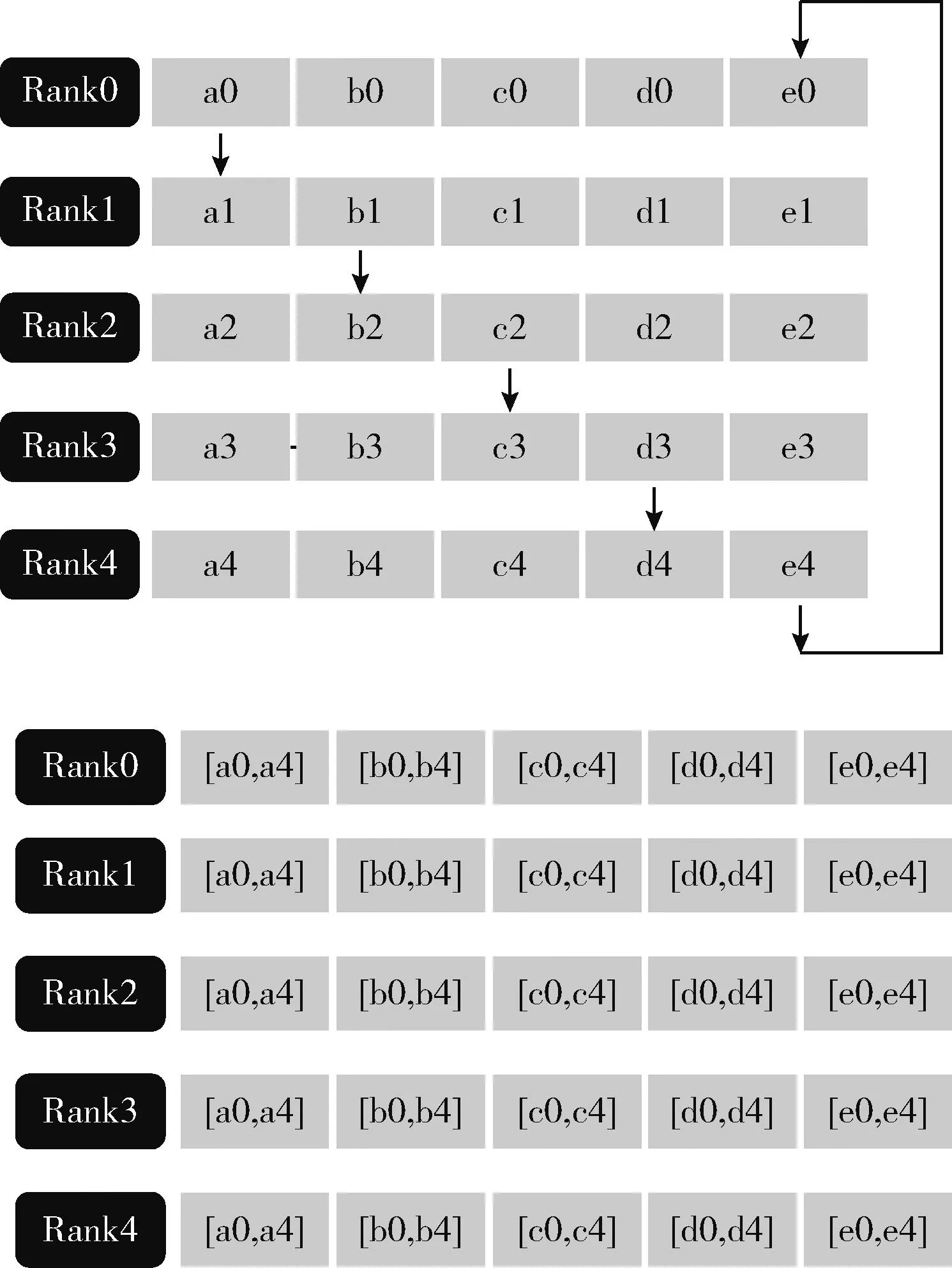
圖6 DDP Scatter-reduce和All_gather
算法2的步驟如下:首先根據device、訓練集與測試集比例,輸入與輸出的序列制作數據集,根據RemoteWorker的數量分發數據集到每個工作節點,然后依據batch_size構建批數據集,即增加一個關于batch的維度,接著多個工作點開始同時訓練,不斷地以Pytorch分布式DistributedData-Parallel的機制去更新模型參數,最后匯總到rank為0的device上,并預測未來的速度值。
算法2:RT-LSTM分布式訓練的算法流程
輸入:epoch:訓練迭代次數
Size:RemoteWorker的數量
RW:RemoteWorker
W:預設的每個結點的子工作節點數
Para:LSTM模型參數
X:最近一小時的各個傳感器的記錄的車流速度
Device:設備(CPU或者GPU)
v_path:數據文件路徑
train_pct:訓練集比例
n_time:歷史時間序列
out_time:以未來的某個時間標簽值
Info:訓練參數
數據集轉換函數:TFD(d,v,train,test,n,o)
數據集分發函數:DistributedSampler(d,s,r)
輸出(output):模型預測的未來的15 min個傳感器的速度值
過程:
(1)Ds←TFD(device,v_path,train_pct,test_pct,n_time,out_time)
(2)foralli∈{1,2…size}do
Di←DistributedSampler(Ds,size,rank)
(其中D={D1,D2…Dsize})
endfor
(4)forallj∈{1,2…size}do
Dataloaderj←Datacreator(Dj,batch_size)
endfor
(5)forallk∈{1,2…epochs}doRWj.train_epochk(Dataloader,Info)
(表示第j個RW的第k個epoch,此處多個RW同時進行訓練。)

endfor
(6)Output=RW0.model(x)
3 實驗及分析
3.1 數據集
本文的交通數據從PEMS 數據集中選取,這些數據已被廣泛用于測試大規模交通流預測模型,它們都來自于美國加州某主要路段300多個loop傳感器采集的數據。傳感器每30 s采集一次,并以5 min為一個周期聚合。本文采用了2018年兩個月的數據,并選用了其中的速度值作為特征進行實驗。超參數優化之后,以12作為窗口大小(1 h,12個5 min)選取數據集進行預測。
3.2 對比方法
對比方法根據并行的理論進行分類,首先是基于CPU與內存的離線訓練模式—CM-LSTM,其次是GPU模式G-LSTM,利用GPU本身的并行機制,通過調整batch-size的大小,使之一次性盡可能地處理更多的數據。最后是Ray-Spark大數據框架并行模式—RT-LSTM,調整不同并行度(D3、D6、D12)作比較。為了能夠對比不同模式上的實時性,這里通過調整batch-size,使得所用的內存和GPU并行模式所用的顯存基本一樣,都約為8 G。
后面的實驗從兩個方面展開,一方面是在運行內存基本一樣的情況下,從訓練的時間和誤差(RMSE)去對比幾個模式的并行的效果;另一方面通過調整不同executor數量、worker_per_node(子工作節點數)、core數量,以研究RT-LSTM訓練的最優化效果。
3.3 實驗設置
3.3.1 顯卡配置
GPU Memory:11 019 MB
CUDA 版本:11.4
3.3.2 Hadoop集群配置
集群節點數:3
可用RAM:40 960 MB
存儲空間:28.4 TB
3.4 對比結果和分析
首先本文在相同的顯存和內存的情況下進行了實驗一,比較了CM-LSTM、G-LSTM和RT-LSTM大數據框架并行兩種模式下模型訓練的效果,主要比較它們的訓練誤差、訓練速度和擬合的效果,表1為整體對比效果。

表1 各種模式實驗效果對比
其次,在大數據框架并行模式下進行了實驗二至實驗四,對比了不同參數時的訓練誤差RMSE、訓練速度和實現擬合收斂所需的epoch數,從表1和表2可看出相應的對比效果。而從表3得出計算資源分配數量與訓練速度的關系。
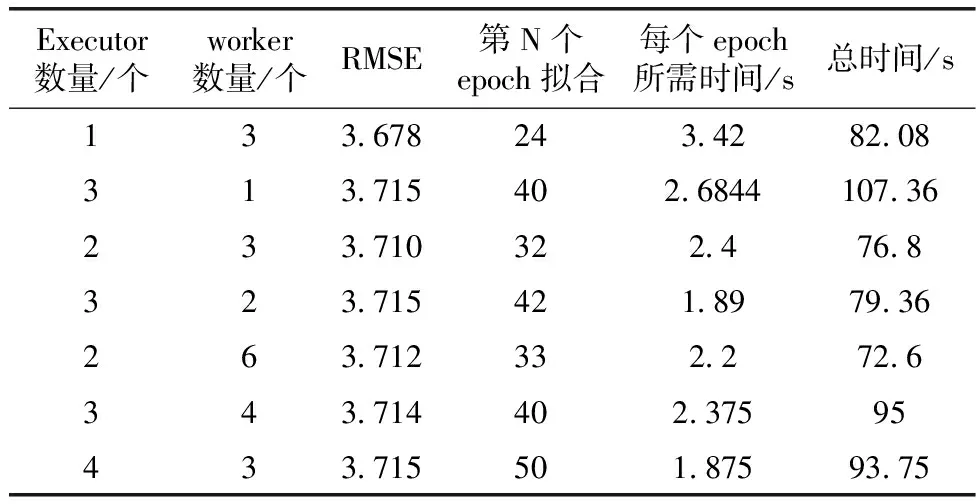
表2 RT-LSTM模式下不同節點數和worker數的對比

表3 RT-LSTM模式下(工作節點數相同)的不同節點分配的core數結果對比
3.4.1 實驗一
首先對比的是CM-LSTM、G-LSTM模式和框架并行RT-LSTM的測試誤差RMSE,RMSE為均方根誤差,從框架下的并行(RT-LSTM)里可以看出,由于數據集被分發了3份、6份和12份分別進行訓練,訓練誤差方面雖然不如G-LSTM模式和CM-LSTM,但是相差不是很大,只相差了大約0.33 km/h,這個誤差在實際的場景中是可以接受的,比如預測速度值是50.33 km/h,而實際的速度值是50 km/h。在訓練速度方面,對比的是總訓練時間,總訓練時間等于擬合所需要的epoch數乘以平均每個epoch的所需要的時間,可以看到,在所需內存相同的情況下,大數據框架并行模式所需總訓練時間最多為93.8 s,比GPU模式總訓練時間要小很多,可見在訓練速度方面均優于GPU并行,而從表1可以看出,CM-LSTM已經完全不具備實時性。圖7和圖8分別為不同模式在總訓練時間和訓練誤差的對比。
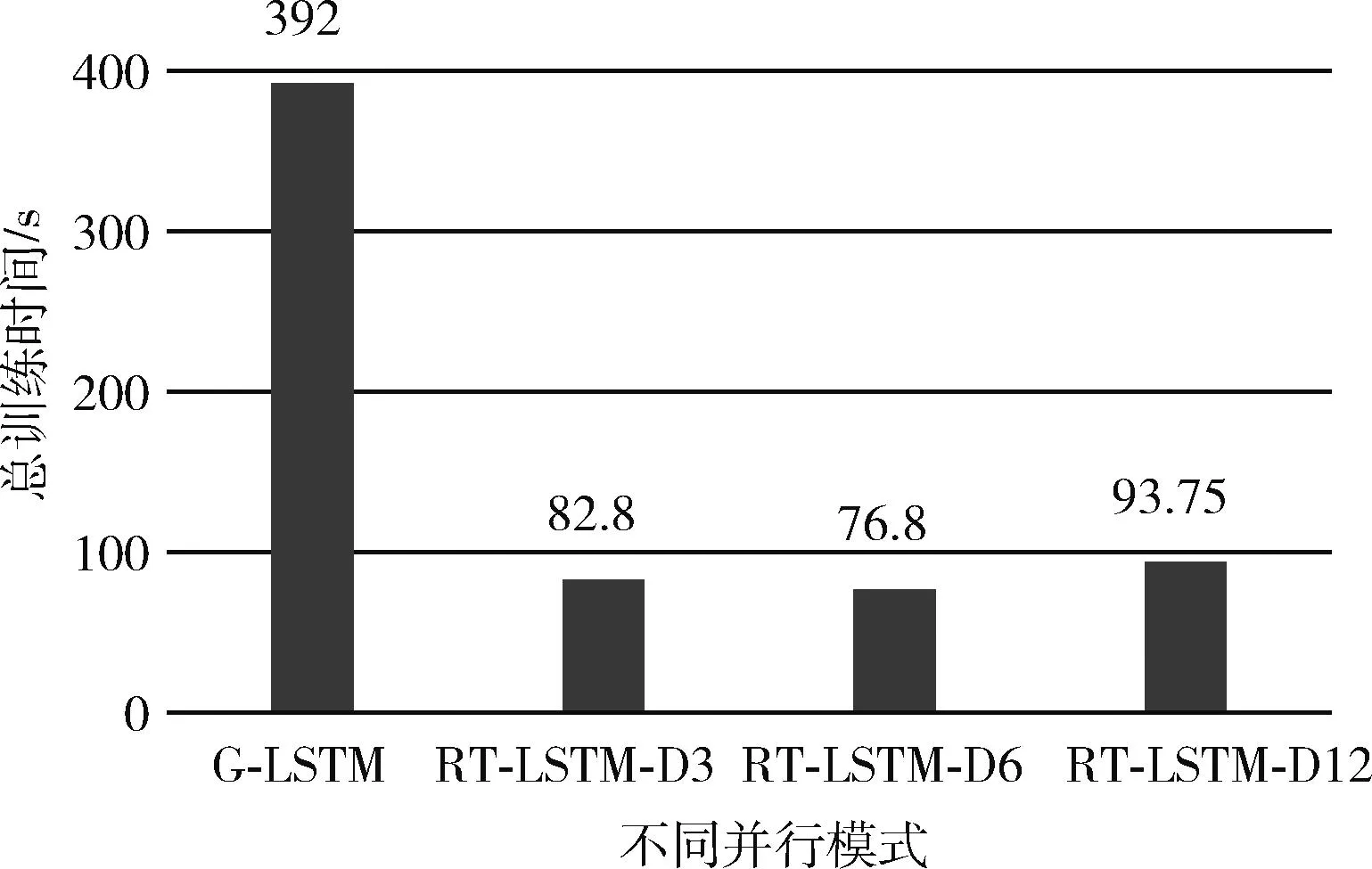
圖7 不同模式總訓練時間對比

圖8 不同并行模式訓練誤差對比
3.4.2 實驗二
在大數據框架并行模式中,不同的TorchRunner數量對訓練誤差影響不大,但是速度上會有顯著的區別,TorchRunner即為總工作節點數,其數量等于數據并行度(并行度=num_node*worker_per_node),誤差效果方面最好的是并行度為3的情況,誤差為3.678。然而在總訓練時間方面,雖然并行度提高了對于本來可以一次讓模型的效果達到擬合收斂的數據集,被劃分成了3份,需要一份接著一份地去讓模型進行學習,相當于要把訓練的“步伐”減緩。圖9和圖10分別為不同工作節點數的訓練誤差和訓練時間對比,其中n1w3表示executor數為1,子工作節點為3,其工作節點數為n*w=3,其它以此類推,圖11為每個epoch所需的時間的結果對比。
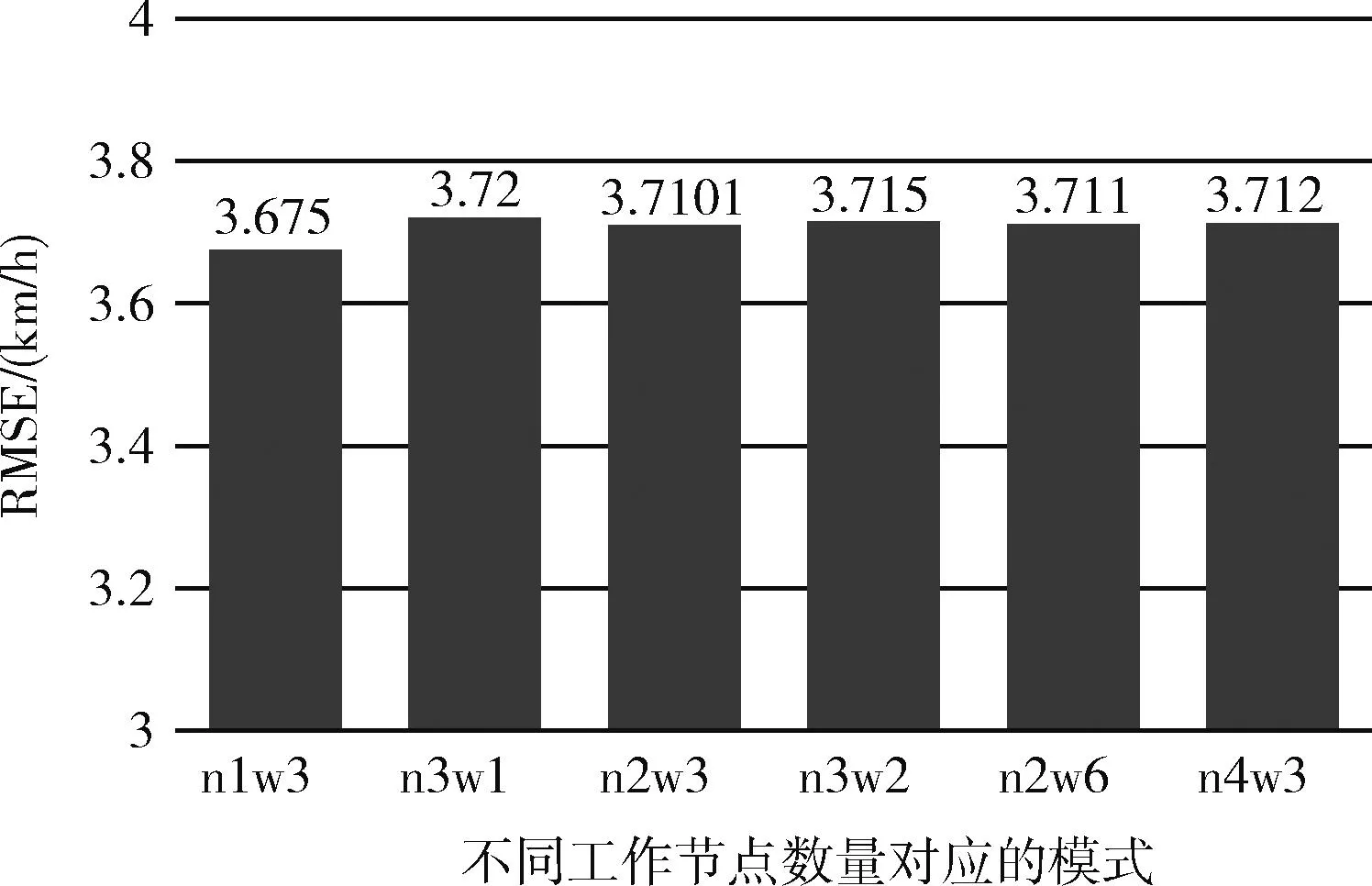
圖9 RT-LSTM下不同工作節點數之誤差對比

圖10 RT-LSTM下不同工作節點數之總訓練時間對比
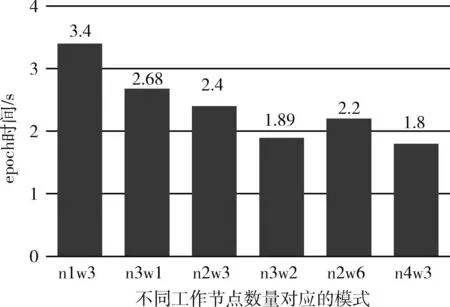
圖11 RT-LSTM下不同工作節點數之epoch時間對比
3.4.3 實驗三
RT-LSTM模式中,在同樣的工作節點數量下,也就是數據并行度一樣的情況下,子工作節點數對模型的訓練也有所影響,每個節點的worker數主要影響的是節點的每次訓練的batch-size。雖然在環境準備時,所分配給每個節點的core資源是一樣的,worker_per_node數量越高,單個工作節點每次訓練的batch-size會越小,batch的數量會提高,但是由于RT-LSTM的多核的環境下并行度隨著子工作節點數量的提高而變高,所以如圖12所示,每個epoch需要的時間減少,即訓練速度加快。此外,由于batch-size減小使每次epoch對參數的更新次數增加了,訓練“步伐”加快,因此收斂所需要的迭代次數降低,從而縮短了總訓練時長,如圖13所示。

圖12 不同worker_per_node數目之單個epoch時間對比

圖13 不同worker_per_node數目之總訓練時間對比
3.4.4 實驗四
對于每個訓練節點,給予其不同數量的core資源,訓練速度也會有提高。若分配給工作節點的core數量越高,即可運行的資源會更多,訓練速度越快,但是達到一定數量情況下,由于不是所有的core會參與到訓練中,所以訓練速度會到達一個瓶頸就不再上升。圖14為相同訓練節點數的情況下分配資源不同的實驗對比,其中C6表示6個core。

圖14 不同core分配數量的單個epoch時間對比
3.5 交通路況可視化
為了可視化交通流的速度預測效果,從307個傳感器中選取位于PaloAlto至Giltroy路段的26個作為研究對象,傳感器在主干道路的分布如圖15所示,若以一小時窗口大小的數據作為模型預測的輸入,把窗口末尾5 min作為當前的時間,其部分傳感器車速值分布如圖15上所示,而未來15 min內傳感器的速度預測值分布如圖15下所示。
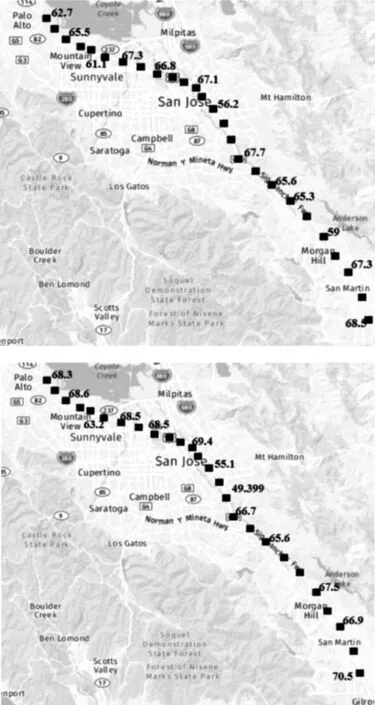
圖15 當前速度值和未來15 min內的速度預測值分布
4 結束語
本文設計一種基于Flink流計算框架和大數據平臺結合的實時交通流預測方法,并采用該方法對實際交通路段中的多個傳感器產生的海量數據進行實時捕捉、存儲和建模分析,實現了對該路段交通流的實時預測。探討和比較了CM-LSTM、G-LSTM和大數據框架下RT-LSTM并行模式下模型訓練效果。實驗結果表明,在大數據框架下的多節點同時訓練的橫向并行模式,比起縱向并行模式(G-LSTM),橫向并行模式訓練速度大大提升,并且又能保持一定的預測精度。但并行的訓練方式在數據集分布不均勻時,還是存在收斂速度慢和效果相差較大的風險,如何去把控數據集的分布問題、訓練的并行度以及模型收斂問題是未來需要進一步探索的。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
網絡安全與數據管理(2022年1期)2022-08-29 03:15:20
導航定位學報(2022年4期)2022-08-15 08:27:00
中學生數理化·中考版(2022年8期)2022-06-14 06:55:24
新世紀智能(數學備考)(2021年9期)2021-11-24 01:14:36
成都醫學院學報(2021年2期)2021-07-19 08:35:14
新世紀智能(數學備考)(2020年9期)2021-01-04 00:25:14
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
