國產(chǎn)神威環(huán)境下Athread代碼生成工具的設(shè)計(jì)與開發(fā)
2024-02-22 08:02:20劉加偉張海紅曾云輝
計(jì)算機(jī)工程與設(shè)計(jì) 2024年2期
關(guān)鍵詞:程序
劉加偉,郭 強(qiáng),莊 園,張海紅,王 利,曾云輝+
(1.齊魯工業(yè)大學(xué)(山東省科學(xué)院) 計(jì)算機(jī)科學(xué)與技術(shù)學(xué)部,山東 濟(jì)南 250014;2.齊魯工業(yè)大學(xué)(山東省科學(xué)院) 山東省計(jì)算中心(國家超級計(jì)算濟(jì)南中心),山東 濟(jì)南 250103)
0 引 言
國產(chǎn)神威系列超級計(jì)算機(jī)系統(tǒng)支持多種常見的編程模型和并行標(biāo)準(zhǔn),常用的有消息傳遞接口(message passing interface,MPI)、異構(gòu)系統(tǒng)并行編程模型(open accelerators,OpenACC)、加速線程庫(acceleration thread library)等。當(dāng)前程序員在神威超級計(jì)算機(jī)上進(jìn)行眾核化加速時(shí)會(huì)面臨編程模型選擇的問題。雖然OpenACC執(zhí)行方便,但是并行粒度和并行化效率不高。OpenACC通過導(dǎo)語及子語就可以隱式的實(shí)現(xiàn)并行編程[1,2],即使是針對神威異構(gòu)眾核處理器的結(jié)構(gòu)特點(diǎn)而改進(jìn)的OpenACC*[1]也不能對核組內(nèi)的線程進(jìn)行靈活的控制和調(diào)度,程序優(yōu)化的思想也大多是設(shè)法提高數(shù)據(jù)的傳輸效率,在不追求極致的計(jì)算效率的情況下采用OpenACC*并行實(shí)現(xiàn);而Athread性能更優(yōu),而且編寫靈活,能夠更好地發(fā)揮出核組內(nèi)多從核并行的加速性能[3],但相較于OpenACC*編寫代碼的工作量更大,編程人員在眾核化編程中容易出現(xiàn)書寫失誤,進(jìn)而需要對代碼進(jìn)行人工排查,這將導(dǎo)致眾核化工作效率降低。基于這個(gè)問題,亟需要借助自動(dòng)化的技術(shù)輔助眾核代碼的編寫。
目前國內(nèi)外已有很多研究人員在進(jìn)行關(guān)于自動(dòng)生成并行代碼技術(shù)和方法的研究[4,5]。付昊桓等實(shí)現(xiàn)了OpenACC代碼到基于神威眾核處理器下Athread代碼,主要依靠源代碼到源代碼的翻譯工具來實(shí)現(xiàn)自動(dòng)化和高效的移植[4];朱效民等第一次嘗試在SW26010上進(jìn)行代碼自動(dòng)生成研究,設(shè)計(jì)實(shí)現(xiàn)了二維Fortran代碼轉(zhuǎn)換為Athread代碼的自動(dòng)代碼生成器。該工具使用源到源的轉(zhuǎn)換方法,通過輸入Fortran代碼的數(shù)組維度信息、循環(huán)索引、計(jì)算和循環(huán)結(jié)束關(guān)鍵詞來生成從核代碼。該工具僅僅是對二維Fortran代碼進(jìn)行自動(dòng)轉(zhuǎn)換,缺少對其它維度以及使用C語言編寫的源程序支持[5]。上述研究主要依賴編譯器來實(shí)現(xiàn)程序的源到源的自動(dòng)翻譯,這種編譯器實(shí)現(xiàn)方法后續(xù)修改比較困難,難以完善;而本文設(shè)計(jì)的轉(zhuǎn)換工具基于模板程序進(jìn)行轉(zhuǎn)換,易于修改,而且可以及時(shí)利用新的高效從核優(yōu)化方法,便利性強(qiáng)[6-8]。
本文的主要工作是,提出了一套結(jié)構(gòu)清晰易用的Athread眾核程序模板框架,設(shè)計(jì)提出一種可以使源程序自動(dòng)轉(zhuǎn)換為Athread方式的方法,研發(fā)實(shí)現(xiàn)了一個(gè)面向神威異構(gòu)眾核處理器上Fortran/C語言核心代碼段基于Athread方式的眾核代碼轉(zhuǎn)換系統(tǒng),旨在提高開發(fā)人員的眾核化工作效率。
1 代碼生成工具設(shè)計(jì)開發(fā)
基于目前人工編寫Athread方式眾核代碼的現(xiàn)狀和技術(shù)方法,我們泛化提出了一套主程序調(diào)用master程序再由master程序調(diào)用slave程序的三層模板程序框架,設(shè)計(jì)研發(fā)了一個(gè)面向C語言和Fortran語言使用的眾核代碼自動(dòng)轉(zhuǎn)換工具。該工具根據(jù)上傳的制導(dǎo)文件和源文件,選擇對應(yīng)的轉(zhuǎn)換模板轉(zhuǎn)換生成Athread方式的眾核代碼,轉(zhuǎn)換成功后可以對生成的文件進(jìn)行編輯保存和下載。
1.1 總體設(shè)計(jì)
眾核代碼自動(dòng)生成工具可以使用可執(zhí)行文件進(jìn)行單機(jī)版的操作,也可使用Web版進(jìn)行使用。Web版采系統(tǒng)用B/S模式,用戶通過瀏覽器可對該工具進(jìn)行操作。服務(wù)器采用Nginx,它具有簡單的負(fù)載均衡和容錯(cuò),后臺(tái)的數(shù)據(jù)服務(wù)采用MySQL數(shù)據(jù)庫,主要包括用戶權(quán)限信息和資源信息,其中資源信息包括上傳的源代碼和轉(zhuǎn)換后生成的一系列Athread代碼,對提交的文件做統(tǒng)一管理[9]。該工具在設(shè)計(jì)上充分發(fā)揮了各種語言的優(yōu)點(diǎn),文件讀寫采用異步的方式實(shí)現(xiàn),體系結(jié)構(gòu)如圖1所示。
將源文件和制導(dǎo)文件上傳到眾核代碼轉(zhuǎn)換平臺(tái)之后,在Web頁面上進(jìn)行操作,選擇對應(yīng)的模板進(jìn)行轉(zhuǎn)換,選擇模板的意義在于選擇handlebars渲染文件路徑。轉(zhuǎn)換之后兩個(gè)文件的字符串直接通過Web頁面調(diào)到Java后臺(tái),在后臺(tái)接收到文件之后,將制導(dǎo)文件內(nèi)容、源文件內(nèi)容和模板路徑交給核心庫,由核心庫統(tǒng)一處理,核心庫通過模板路徑獲取到所需要的模板文件,對文件進(jìn)行語法詞法解析和渲染,輸出的文件保存在硬盤上并把路徑返回給Java后臺(tái),Java后臺(tái)再把路徑發(fā)送到前臺(tái)。
1.2 模板程序架構(gòu)
隨著神威系列超級計(jì)算機(jī)系統(tǒng)的發(fā)展,盡管系統(tǒng)架構(gòu)發(fā)生改變,但是“由主程序調(diào)用master.c程序,再由master.c程序調(diào)用slave.c程序”的編程模式依然是主流思想[1]。本工具以主程序、master.c程序和slave.c程序作為模板,基于制導(dǎo)文件進(jìn)行轉(zhuǎn)換,還添加了一個(gè)全局變量文件定義相關(guān)參數(shù),實(shí)現(xiàn)對不同平臺(tái)的擴(kuò)展。用戶使用本工具時(shí),只需要編寫制導(dǎo)文件即可。
1.2.1 主程序
在主程序中,除過實(shí)現(xiàn)核心段的眾核化之外,一個(gè)常見需求就是計(jì)算結(jié)果比對和運(yùn)行計(jì)時(shí)。通過計(jì)時(shí)函數(shù)來獲取主程序核心段計(jì)算時(shí)間和從核計(jì)算時(shí)間,按制導(dǎo)文件自動(dòng)對原主核核心代碼段和眾核調(diào)用代碼段進(jìn)行計(jì)時(shí)插樁,比較耗時(shí)情況,并對加速效果進(jìn)行輸出。目前采用以基于getlooptime()為基礎(chǔ)的計(jì)時(shí)方法。主程序以逐元素比較原主核計(jì)算變量的結(jié)果與眾核計(jì)算變量的結(jié)果的方式來判斷超出精度范圍的位置和數(shù)值,并進(jìn)行輸出。在主程序模板中還添加了條件編譯語句,用于選擇程序是眾核化運(yùn)行、主核運(yùn)行還是進(jìn)行比對。
1.2.2 master.c
在master.c程序模板中,將常用的數(shù)據(jù)參數(shù)以結(jié)構(gòu)體的形式存儲(chǔ),結(jié)構(gòu)體中成員類型包含了常見集中數(shù)據(jù)類型,每種類型的大小分別受不同的參數(shù)控制。在從核啟動(dòng)的時(shí)候?qū)⒔Y(jié)構(gòu)體加載到每個(gè)從核的LDM(local data memory)中,減少從核直接訪主存的次數(shù),實(shí)現(xiàn)數(shù)據(jù)的重復(fù)調(diào)用,提高程序性能。此外,為了提高二維數(shù)組的可擴(kuò)展性,該模板采用spawn方式[10],以便對多個(gè)并行的二維數(shù)組計(jì)算的核心段進(jìn)行從核分區(qū)并行。
1.2.3 slave.c
為避免從核使用動(dòng)態(tài)分配函數(shù)出現(xiàn)的不穩(wěn)定現(xiàn)象,slave.c從核程序模板采用靜態(tài)存儲(chǔ)變量的方法,即采用LDM靜態(tài)空間分別開設(shè)一個(gè)較大的整型和浮點(diǎn)型的靜態(tài)數(shù)組,對各個(gè)變量按結(jié)構(gòu)體參數(shù)分別對應(yīng)進(jìn)行自動(dòng)映射。此外,為了減少用戶編程的工作量,提高開發(fā)效率,我們使用了新一代神威眾核架構(gòu)下實(shí)現(xiàn)的從核間通信的接口函數(shù)[11]。
1.2.4 制導(dǎo)文件
基于前述模板,轉(zhuǎn)換工具按照用戶提供的制導(dǎo)文件對原始程序代碼(filename.f90/.c)實(shí)現(xiàn)眾核化,自動(dòng)生成filename_struct.h頭文件、filename_sw.f90/.c新的主程序、filename_master.c和filename_slave.c文件。
在使用轉(zhuǎn)換工具前,需要用戶針對原始代碼程序filename.f90/.c中擬轉(zhuǎn)換的核心代碼段編寫一個(gè)制導(dǎo)文件,包括如下內(nèi)容。
(1)明確擬眾核化的代碼段范圍,按照起始行號表述。
(2)按照輸入變量、輸出變量、雙向變量的分類,逐個(gè)對變量的名稱、類型(整型/單精度浮點(diǎn)數(shù)/雙精度浮點(diǎn)數(shù)等)、維數(shù)、每一維需要讀進(jìn)/寫出從核的大小、每一維的起始下標(biāo)等進(jìn)行明確,必要時(shí)可明確每一維的范圍,制導(dǎo)文件中部分變量及數(shù)組見表1。

表1 制導(dǎo)文件中部分變量及數(shù)組示例
(3)增加條件編譯語句(如計(jì)時(shí)統(tǒng)計(jì)和結(jié)果比較等)和調(diào)用master.c中函數(shù)的語句。
(4)部分優(yōu)化方法的選項(xiàng)設(shè)置。
1.3 系統(tǒng)功能模塊設(shè)計(jì)
該工具的后端實(shí)現(xiàn)主要采用Rust語言作為開發(fā)語言,以Handlebars作為語義模板庫,前端展示界面的開發(fā)采用Java語言。之所以選擇Rust語言,是因?yàn)镽ust是非GC的內(nèi)存安全的語言,不像Java需要運(yùn)行時(shí)有GC線程來清理內(nèi)存,也不像C類語言需要手動(dòng)申請、釋放堆內(nèi)存。它有一套自己的語法,按照這套語法編寫自己的代碼,它在編譯時(shí)會(huì)自動(dòng)地在需要的地方添加申請、釋放內(nèi)存的指令[12]。而內(nèi)存安全的機(jī)制可以放心編寫業(yè)務(wù)代碼,不用擔(dān)心空指、野指、堆內(nèi)存不釋放等問題,以提高程序的穩(wěn)定性和安全性。
整個(gè)轉(zhuǎn)換工具的輸入是Fortran/C源程序和對應(yīng)的制導(dǎo)文件。然后,對源碼進(jìn)行詞法分析并用抽象語法樹AST(abstract syntax tree)表示。下一步是根據(jù)轉(zhuǎn)換后的抽象語法樹生成目標(biāo)語句。最后,將生成的目標(biāo)語句轉(zhuǎn)換為Athread源程序。
我們根據(jù)轉(zhuǎn)換工具功能實(shí)現(xiàn)的流程邏輯,將項(xiàng)目劃分為核心數(shù)據(jù)轉(zhuǎn)換模塊、模板模塊、展示模塊,這3個(gè)模塊依次完成。
(1)核心數(shù)據(jù)轉(zhuǎn)換模塊
利用抽象語法樹(AST)規(guī)則通過解析、轉(zhuǎn)換、生成3個(gè)步驟[13]將Fortran/C文件和制導(dǎo)文件轉(zhuǎn)換為內(nèi)置數(shù)據(jù)模型。該工具在實(shí)現(xiàn)上將解析、轉(zhuǎn)換和生成進(jìn)行業(yè)務(wù)切割,其中,解析業(yè)務(wù)以數(shù)據(jù)序列化的方式實(shí)現(xiàn),轉(zhuǎn)換業(yè)務(wù)則是根據(jù)轉(zhuǎn)換庫預(yù)留接口實(shí)現(xiàn),達(dá)到業(yè)務(wù)上的解耦,提高該工具的可擴(kuò)展性。
1)解析,將原始語句解析為抽象語法樹。
使用AST對原始語句解析時(shí),需要先進(jìn)行詞法分析。詞法分析會(huì)根據(jù)既定的語法單元表,將原始語句分割成一維數(shù)組語法單元列表(token表)。詞法分析時(shí)會(huì)將連續(xù)的空格當(dāng)做分割符,自動(dòng)切分語法單元。獲得token表之后,再使用語法分析,將一維無結(jié)構(gòu)的token表轉(zhuǎn)化為樹形結(jié)構(gòu)。在語法分析時(shí),也會(huì)驗(yàn)證語法的正確性。
2)轉(zhuǎn)換,操作抽象語法樹節(jié)點(diǎn)完成轉(zhuǎn)換。
AST轉(zhuǎn)換沒有固定的標(biāo)準(zhǔn),本項(xiàng)目存在兩種情況:對匹配節(jié)點(diǎn)簡單的替換和對匹配子樹結(jié)構(gòu)的調(diào)整或者替換。這個(gè)過程包含遍歷和轉(zhuǎn)換兩步。抽象語法樹可以使用一般樹的遍歷方法,如先序遍歷和后序遍歷。
3)生成,根據(jù)轉(zhuǎn)換后的抽象語法樹生成目標(biāo)語句。
在生成的遍歷過程中,需要對所有不同類型語法單元的節(jié)點(diǎn)的所有情況定義不同的處理邏輯,而不同類型語法節(jié)點(diǎn)下子樹的遍歷順序也有可能會(huì)不同。所以,需要為所有情況進(jìn)行枚舉。AST遍歷示例如圖2所示。
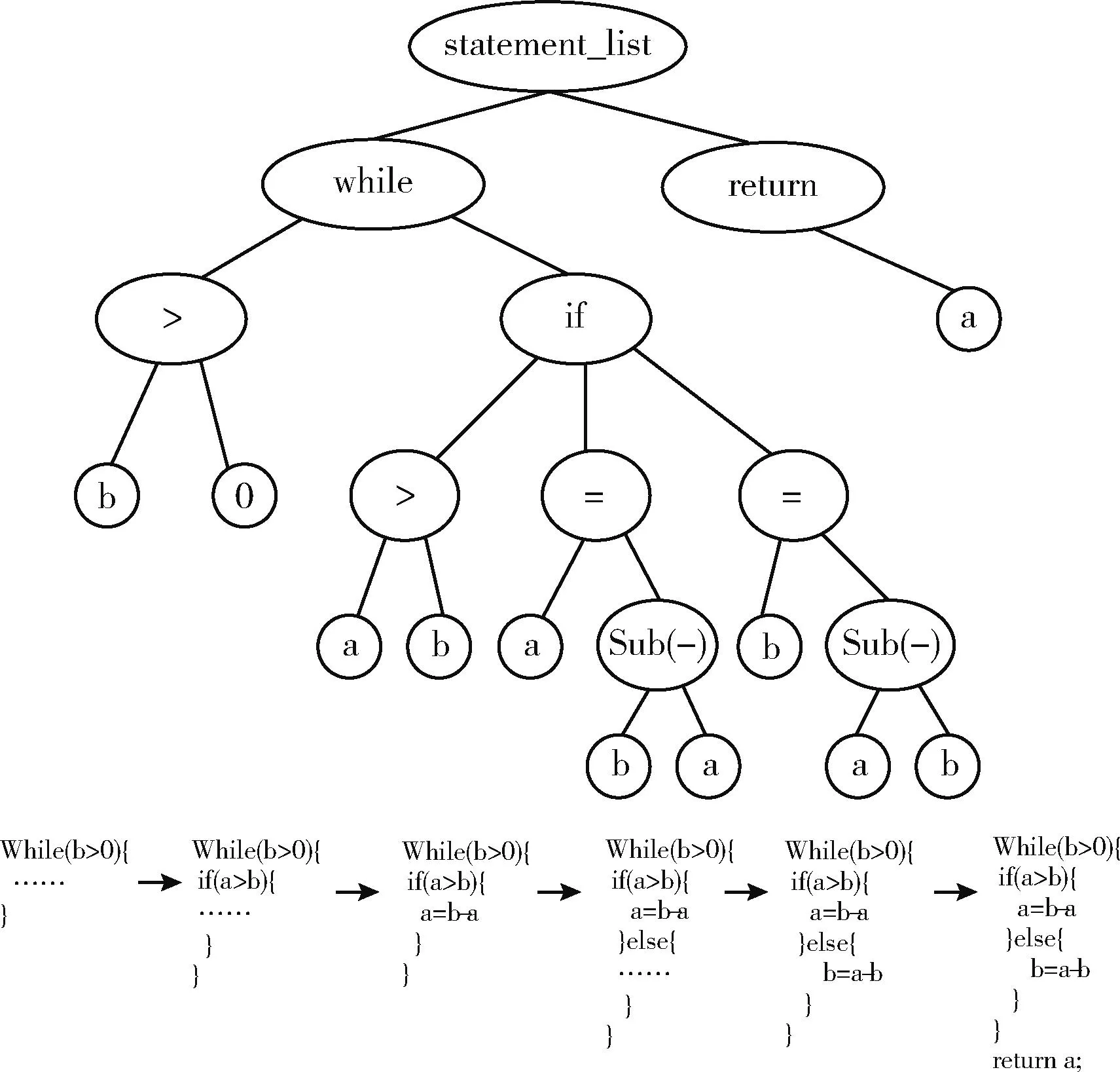
圖2 AST遍歷示例
其中,statement_list語法單元用來表示子節(jié)點(diǎn)都是并列依次執(zhí)行的語句。while子樹中包含了while循環(huán)的條件判斷和if的語句塊,if語句塊包含了if的條件判斷和兩個(gè)賦值語句。在編譯器構(gòu)造同樣類型語法樹時(shí),一般會(huì)使用與具體語言無關(guān)的語法單元的命名,這樣在后續(xù)的轉(zhuǎn)換只是對節(jié)點(diǎn)采用不同的翻譯模式而已,做到了和具體語言的解耦。
(2)模板模塊
在此模塊中自定義模板組件,將數(shù)據(jù)轉(zhuǎn)換模塊中的內(nèi)置數(shù)據(jù)格式轉(zhuǎn)換為C語言文本。表2中列舉了部分主要的模板組件。

表2 主要模板組件
(3)展示模塊
單機(jī)版采用exe可執(zhí)行文件直接生成導(dǎo)出文件到響應(yīng)目錄。Web版采用Web頁面展示轉(zhuǎn)換結(jié)果。在使用轉(zhuǎn)換工具之前先把相應(yīng)的f90/c源文件和制導(dǎo)文件上傳,之后選定源文件和制導(dǎo)文件分別放到源文件代碼編輯區(qū)和制導(dǎo)文件代碼編輯區(qū),然后保存,選擇相關(guān)的模板開始轉(zhuǎn)換,最后可以把生成的所有文件的壓縮包下載,也可以在線預(yù)覽生成的文件內(nèi)容。Web原型設(shè)計(jì)如圖3所示。

圖3 Web版前端界面原型框架
Web版本中的兩個(gè)編輯區(qū)可以實(shí)現(xiàn)在線的實(shí)時(shí)修改,同時(shí)我們添加了對“do”、“for”、“if”、“else”等關(guān)鍵詞的高亮顯示,更方便使用人員操作。
2 系統(tǒng)實(shí)現(xiàn)
2.1 詞法語法分析器的具體實(shí)現(xiàn)流程
詞法語法分析器主要是用于將一個(gè)編程語言轉(zhuǎn)換成另外一種編程語言,相當(dāng)于一個(gè)簡單編譯器的實(shí)現(xiàn)。按照需求該編譯器包含詞法分析、語法轉(zhuǎn)換以及簡單的錯(cuò)誤分析,分析流程如圖4所示。
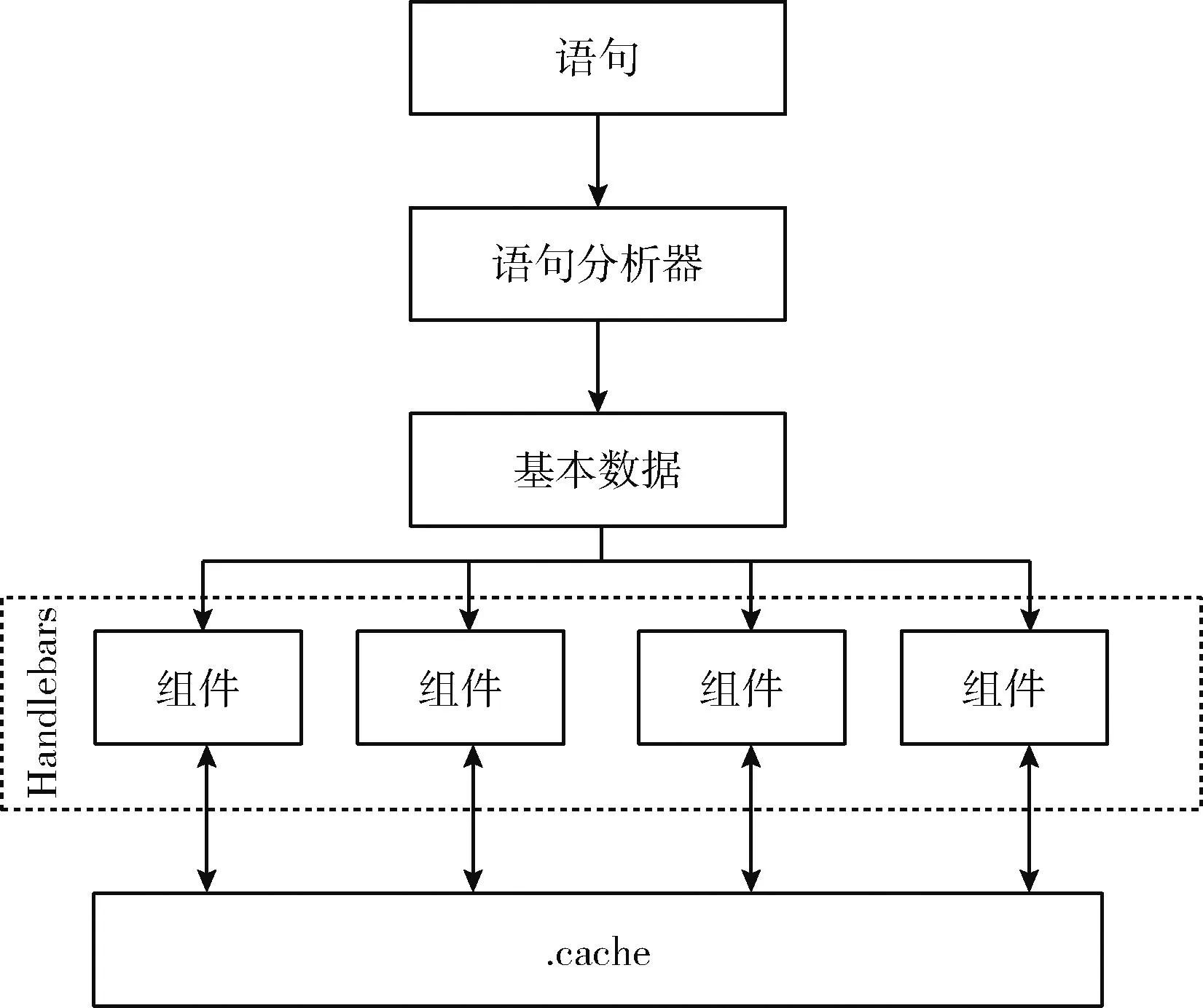
圖4 分析流程
2.1.1 詞法語法分析
(1)語句分析器
分析器采用流式解析的方法,將整個(gè)代碼的字符串按行讀取,分析器按照規(guī)則匹配token表,在備選的語法結(jié)構(gòu)中排除,直到匹配到語句結(jié)束并且備選的語法結(jié)構(gòu)中只剩下一個(gè)備選。使用這種流式的語法解析方法可以減少掃描過多而帶來的內(nèi)存占用和時(shí)間問題。針對于一個(gè)語句多行編寫的情況,會(huì)將語句之前的解析內(nèi)容緩存,等到完整的語句解析完成之后再寫入到數(shù)據(jù)結(jié)構(gòu)中。按照制導(dǎo)文件和f90文件的結(jié)構(gòu)可分為輸入變量、輸出變量、輸入輸出變量等,具體匹配流程如圖5所示。
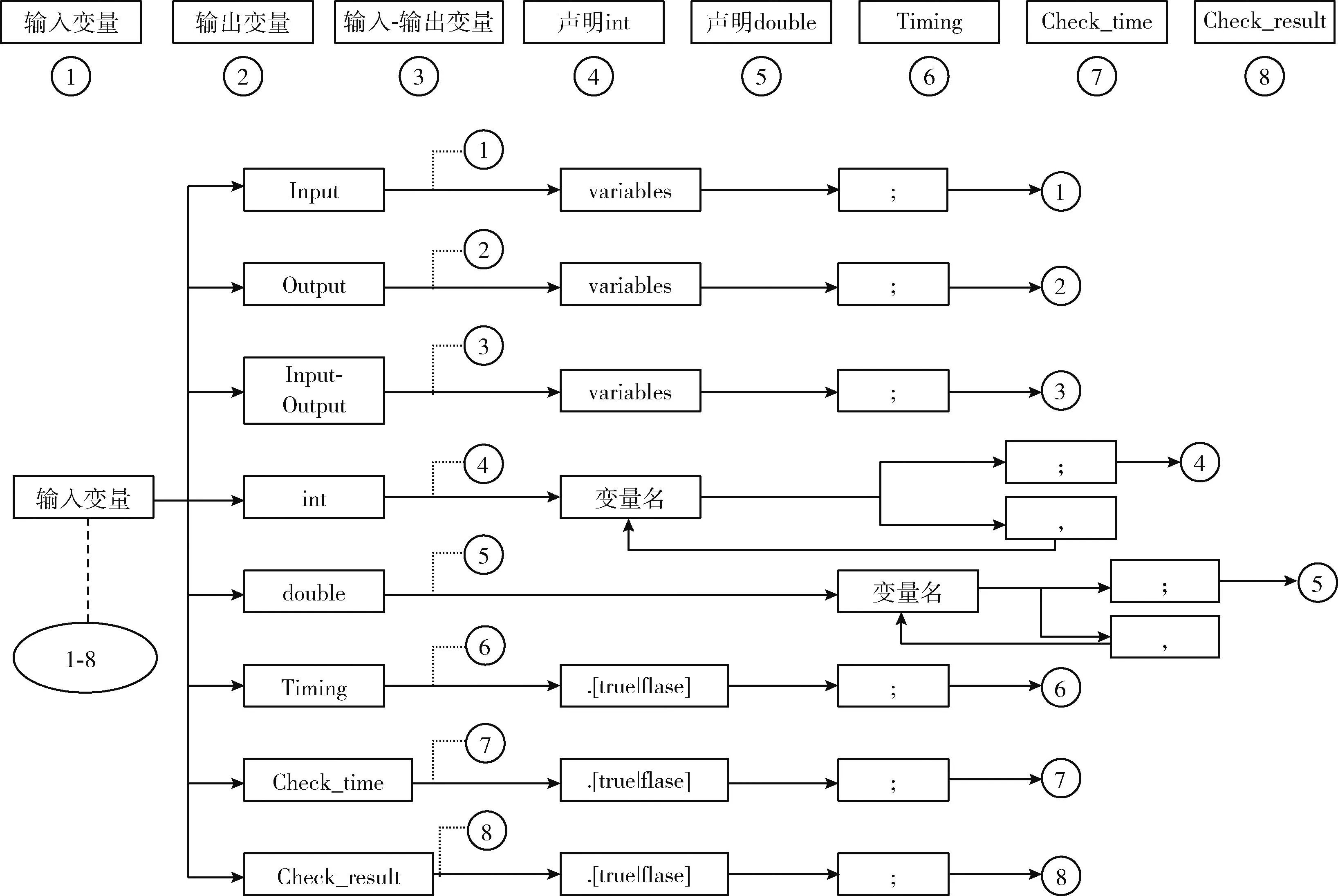
圖5 語義匹配有限狀態(tài)自動(dòng)機(jī)
圖5中虛線代表推測的是哪種語義。該流程圖中的任意語句必須完全匹配才能確定是否為該語義,如果匹配出來的不在推測的集合中,則會(huì)返回錯(cuò)誤信息。
對于不同的語言,該工具在解析規(guī)則上有較小的差別,只需更改相應(yīng)的解析規(guī)則和模板就可以很好實(shí)現(xiàn)語言上的擴(kuò)展。以C程序中的for循環(huán)為例,當(dāng)輸入一串字符串為 “for(i=0;i<10;i++)” 時(shí),它會(huì)逐字進(jìn)行判斷,匹配過程如圖6所示。
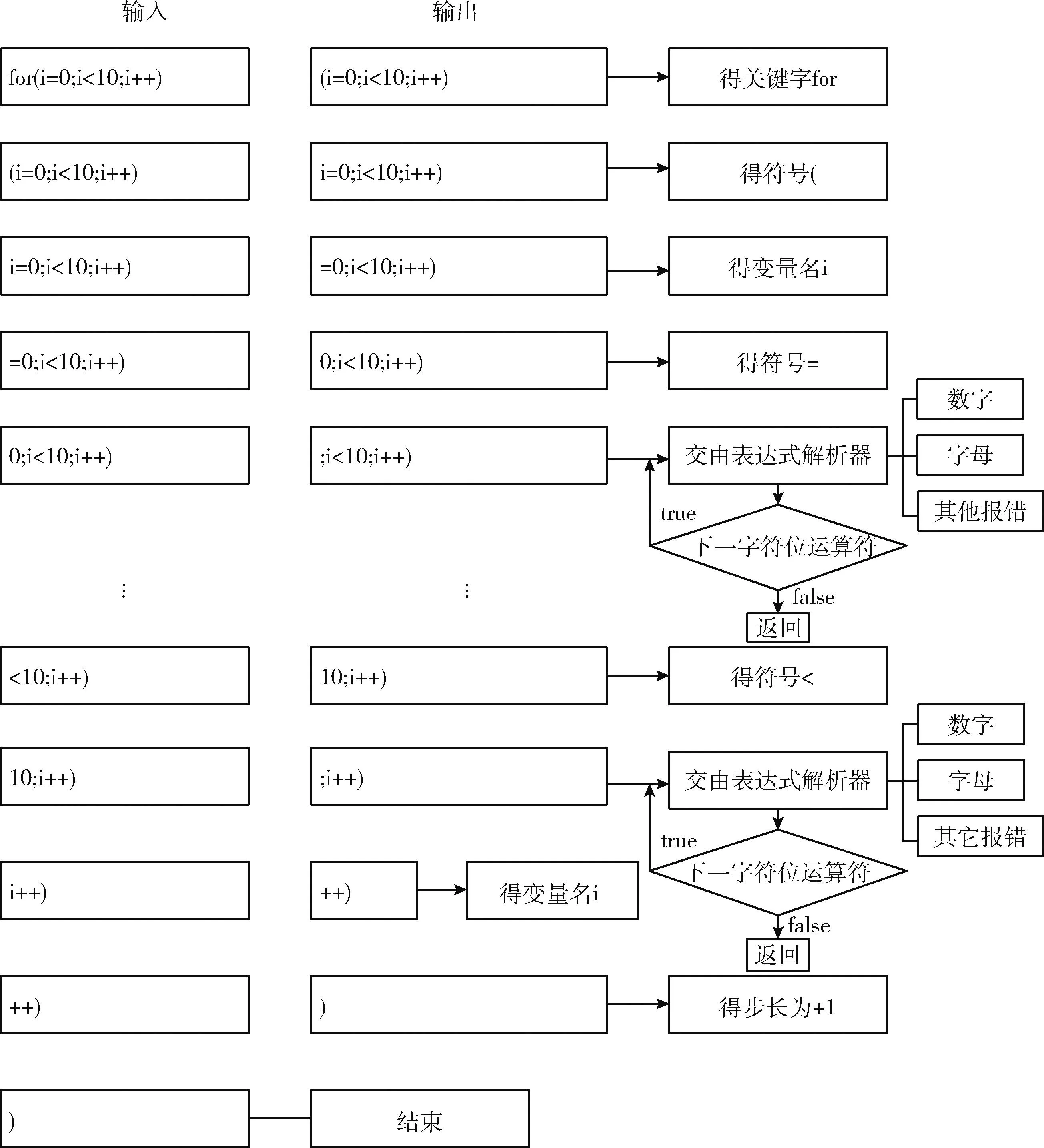
圖6 for循環(huán)解析過程
(2)源文件語句分析
以f90源文件為例,系統(tǒng)需要提交的f90源文件主要用于解析變量、計(jì)算語句源語句、子程序識(shí)別。f90變量的解析主要用于提供變量的初始值。
根據(jù)f90源文件的結(jié)構(gòu),可以定義4個(gè)解析位置,分別為:開始子程序、解析變量、核心計(jì)算語句、結(jié)束子程序,并且可以循環(huán)。在f90中,語句的結(jié)束標(biāo)識(shí)符為換行符,如果多行為一個(gè)語句,則行結(jié)束后為“&”標(biāo)識(shí)符。
解析位置間的切換規(guī)則為:
1)文件初始時(shí)為解析位置為None。
2)當(dāng)解析位置為None或結(jié)束子程序時(shí),遇到 “subroutine”關(guān)鍵字則解析位置切換為開始子程序。
3)開始子程序行結(jié)束后無 “&”字符,則解析位置切換為解析變量。
4)當(dāng)解析位置為解析變量時(shí),遇到“……”行,則切換為計(jì)算源語句。
5)當(dāng)解析位置為計(jì)算源語句時(shí),遇到“end subroutine”時(shí),切換為結(jié)束子程序。
(3)計(jì)算語句分析
計(jì)算語句主要進(jìn)行格式的判斷、轉(zhuǎn)換,不牽扯到計(jì)算相關(guān)的運(yùn)算符優(yōu)先級相關(guān)的運(yùn)算,所以此次解析只按照順序?qū)⒔馕龅降南嚓P(guān)的數(shù)據(jù)存入到屬性結(jié)構(gòu)中即可。模板渲染時(shí)按照屬性結(jié)構(gòu)從上到下、從左到右的挨個(gè)轉(zhuǎn)換渲染出來即可。
本文根據(jù)語句的特點(diǎn),可以將語句分為循環(huán)語句、條件語句和普通語句,這3個(gè)語句分別都有自己重要的組成部分。在這3種語句中,其中循環(huán)語句和條件語句是樹形結(jié)構(gòu),含有子集;普通語句為鏈表結(jié)構(gòu)。目前采用對關(guān)鍵字的解析,通過解析規(guī)則對語句類型進(jìn)行匹配。語法解析時(shí)按照 “do”、“if”、“else”、“end do”、“endif”等關(guān)鍵字判斷語法類型,將不在關(guān)鍵字內(nèi)但是符合變量命名規(guī)則的按照普通語句規(guī)則進(jìn)行匹配并存入鏈表中;讀取到“do”、“if”、“else”關(guān)鍵字時(shí),后續(xù)的語句存入到相關(guān)結(jié)構(gòu)體的children節(jié)點(diǎn)上,直到“end”結(jié)束,后續(xù)的解析存入到next節(jié)點(diǎn)上。
2.1.2 語義轉(zhuǎn)換
語義轉(zhuǎn)換部分采用模板渲染的方式。通過對比多個(gè)模板語言后采用handlebars作為該工具的模板語言,該模板語言具有高可擴(kuò)展性以及具有簡單的條件判斷和循環(huán)判斷能力,非常適合該工具的語義轉(zhuǎn)換部分。
針對于handlebars開發(fā)多個(gè)定制化組件的過程中遇到的數(shù)據(jù)共享問題,我們采用寫入、讀取的方式實(shí)現(xiàn)數(shù)組間的數(shù)據(jù)共享,并且在文件的寫入、讀取時(shí)采用異步的方式進(jìn)行,防止IO期間對于CPU占用導(dǎo)致的性能問題,提高程序性能。基本實(shí)現(xiàn)為每次語句轉(zhuǎn)換生成的文件寫入到的目錄都是隨機(jī)生成的,并且不會(huì)重復(fù),所以我們在這個(gè)寫入的文件夾中創(chuàng)建一個(gè)名為.cache 的隱藏文件中。當(dāng)一個(gè)組件生成其它組件需要的數(shù)據(jù)時(shí),則將該部分?jǐn)?shù)據(jù)進(jìn)行序列化并寫入到.cache文件中;當(dāng)其它組件需要讀取時(shí)直接從.cache文件中讀取數(shù)據(jù)進(jìn)行反序列化操作即可。
2.1.3 錯(cuò)誤分析
轉(zhuǎn)換工具目前可以進(jìn)行簡單的語法錯(cuò)誤分析,利用有限狀態(tài)自動(dòng)機(jī)來進(jìn)行語法的錯(cuò)誤分析,通過前面的輸入會(huì)判定后面會(huì)有的可能性,如果待驗(yàn)證的語句都不屬于任意可能性則會(huì)被判定為錯(cuò)誤語法。
2.2 基準(zhǔn)模板文件生成
在按照神威系列超級計(jì)算機(jī)系統(tǒng)所提供的Athread庫格式[1]編寫典型的模板程序后,該工具將進(jìn)行識(shí)別后形成包含變量的基準(zhǔn)模板文件。
在這個(gè)過程中,我們首先進(jìn)行AST解析,采用流式的思想將程序中的變量、語句相關(guān)的內(nèi)容轉(zhuǎn)換為內(nèi)置的數(shù)據(jù)結(jié)構(gòu)。然后我們對每個(gè)維度類型的神威眾核代碼的特性進(jìn)行歸納總結(jié),將程序中的整個(gè)代碼看作一個(gè)字符串,每個(gè)字符串分為固定字符串和可替換字符串。固定字符包括數(shù)據(jù)類型和常用的函數(shù)名等,而可替換字符包括變量名、數(shù)組名和循環(huán)判斷等。其中固定的字符串直接顯示在模板上,可替換的字符串根據(jù)原數(shù)據(jù)類型或者變量使用循環(huán)組件、判斷組件、變量組件等組件進(jìn)行替換顯示最終生成的基準(zhǔn)模板文件,如圖7(a)所示。

圖7 從核模板代碼(a)與生成代碼(b)對比
2.3 眾核代碼生成
模板代碼根據(jù)需要生成的可替換數(shù)據(jù),在對應(yīng)位置以識(shí)別組件方式來進(jìn)行代碼的替換。具體體現(xiàn)在該工具通過對上述源文件和制導(dǎo)文件的詞法語法解析,把解析數(shù)據(jù)轉(zhuǎn)換成內(nèi)部對象,通過把對象序列化成json串[14],交給handlebars渲染庫,由handlebars統(tǒng)一調(diào)度。以從核代碼slave.c為例,在生成slave.c文件的時(shí)候根據(jù)slave.c模板的組件調(diào)用相應(yīng)的handlebars庫,讀取數(shù)據(jù)進(jìn)行替換,轉(zhuǎn)換效果如圖7所示。
3 工具應(yīng)用
3.1 工具使用
該轉(zhuǎn)換工具目前實(shí)現(xiàn)了Fortran語言和C語言的二維模板、三維模板以及混合維度數(shù)組模板的轉(zhuǎn)換。單機(jī)版采用exe可執(zhí)行文件直接生成導(dǎo)出文件到相應(yīng)目錄。Web版采用Web頁面進(jìn)行操作和展示轉(zhuǎn)換結(jié)果,轉(zhuǎn)換效果如圖8所示。
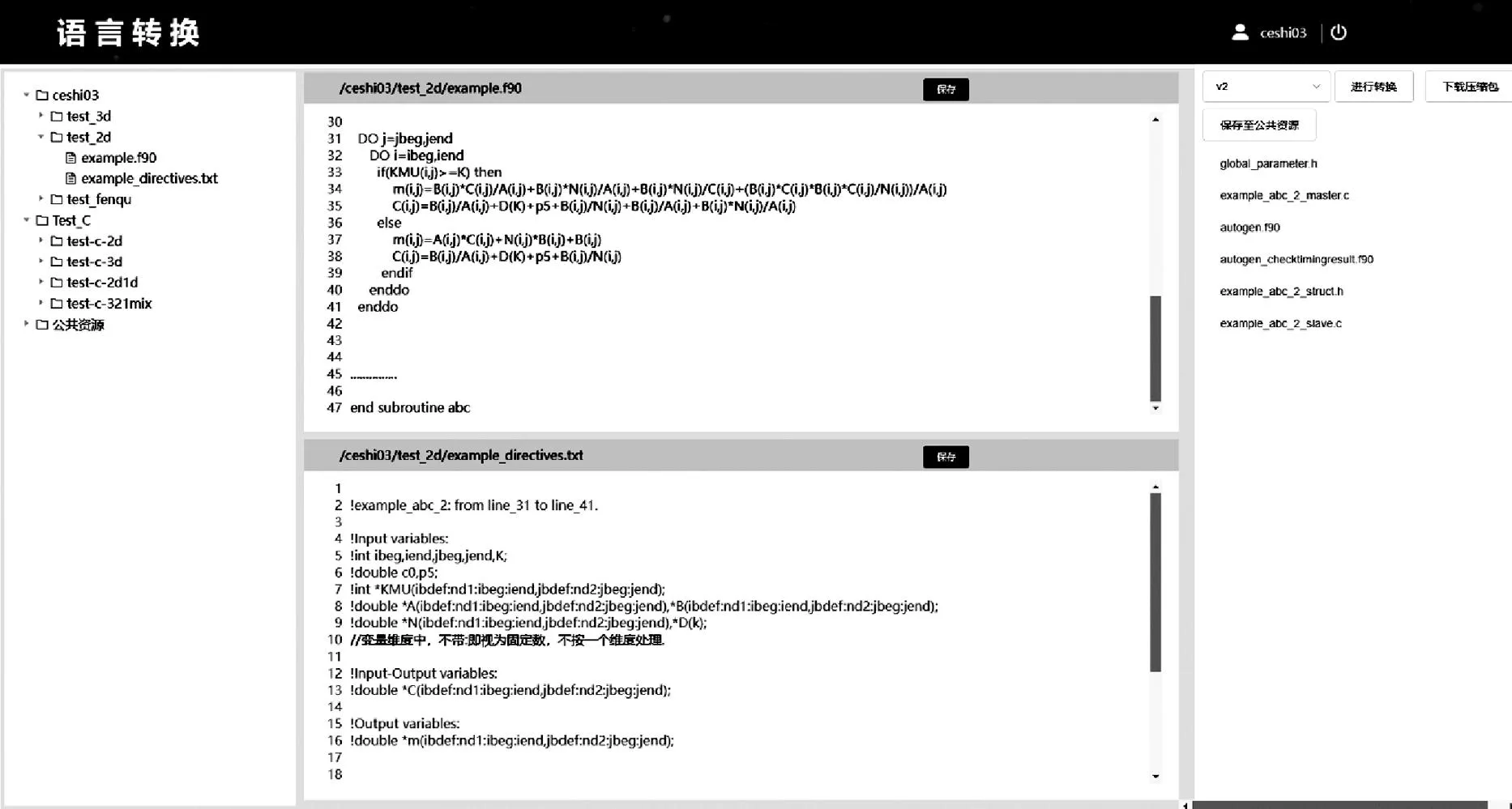
圖8 Web界面二維模板轉(zhuǎn)換效果
用戶通過輸入賬號密碼登錄該平臺(tái),圖8顯示該平臺(tái)的Web頁面包含左側(cè)一欄的文件管理區(qū)域,用戶可以創(chuàng)建目錄和子目錄,將待轉(zhuǎn)換的源文件和制導(dǎo)文件上傳到用戶創(chuàng)建的子目錄中;中間一欄為代碼文件編輯區(qū),用戶將子目錄中的源文件添加到上側(cè)的源文件代碼編輯區(qū),制導(dǎo)文件添加到下側(cè)的制導(dǎo)文件文件編輯區(qū),用戶可以在這兩個(gè)區(qū)域進(jìn)行修改,修改完畢之后可以點(diǎn)擊保存按鈕保存到后臺(tái)服務(wù)器的數(shù)據(jù)庫中;右側(cè)一欄為轉(zhuǎn)換區(qū),用戶可以通過選擇對應(yīng)的數(shù)組維度信息對文件編輯區(qū)顯示的源代碼和制導(dǎo)文件進(jìn)行相應(yīng)的轉(zhuǎn)換,轉(zhuǎn)換成功后會(huì)出現(xiàn)如圖8所示的一些Athread代碼相關(guān)的源代碼,并可以通過點(diǎn)擊“下載壓縮包”下載到本地。
該工具有很好的便利性,即通過上傳源文件和編寫好的制導(dǎo)文件到web界面即可進(jìn)行代碼轉(zhuǎn)換,自動(dòng)生成新的主程序、頭文件、master.c和slave.c程序,用戶不需要考慮神威環(huán)境下從核分配和LDM空間地址偏移等問題。
3.2 正確性檢驗(yàn)
為了保證轉(zhuǎn)換后的眾核代碼的準(zhǔn)確性提供了部分檢查功能,包括代碼一致性檢查、結(jié)果正確性檢查。代碼一致性檢查指修改或合并之后的主核代碼和從核代碼內(nèi)部及相互之間的一致性,包括下標(biāo)、大小、數(shù)值等。目前通過主程序的結(jié)果正確性函數(shù)來驗(yàn)證轉(zhuǎn)換后結(jié)果。
本文基于上述幾個(gè)模板,將海洋數(shù)值模式中advu和advt的二維矩陣計(jì)算核心段由轉(zhuǎn)換工具生成Athread格式的源代碼及包含正確性檢驗(yàn)的主程序在神威太湖之光平臺(tái)上提交運(yùn)行。運(yùn)行結(jié)果部分效果如圖9所示。

圖9 二維模板正確性檢驗(yàn)部分效果
圖9顯示的第一列數(shù)字表示原串行程序的執(zhí)行結(jié)果和利用工具轉(zhuǎn)換生成的眾核程序執(zhí)行結(jié)果的差值,實(shí)驗(yàn)結(jié)果顯示,兩個(gè)二維矩陣運(yùn)算利用轉(zhuǎn)換工具得到的眾核代碼在從核加速后的計(jì)算結(jié)果均與主程序串行執(zhí)行的計(jì)算結(jié)果相同,驗(yàn)證了本文轉(zhuǎn)換工具的正確性。
3.3 性能分析
實(shí)驗(yàn)驗(yàn)證平臺(tái)選擇神威太湖之光超級計(jì)算機(jī),操作系統(tǒng)為RaiseOS 2.0.5,其眾核處理器的主核和從核工作頻率均為1.5 GHz,訪存帶寬為136.51 GB/s[15]。
實(shí)驗(yàn)采用的二維代碼為海洋數(shù)值模式中advu和advt的典型計(jì)算核心段。其中,二維數(shù)組規(guī)模為最小設(shè)為32×32,最大設(shè)為512×512,對應(yīng)的數(shù)據(jù)量大小由64 kB增加到16 MB。
由于本文設(shè)計(jì)的轉(zhuǎn)換工具的目的是解決前述提到的編寫Athread代碼所存在的問題,以達(dá)到或超過OpenACC*的性能。因此,本節(jié)比較了使用轉(zhuǎn)換工具的Athread版本和使用OpenACC*人工編寫獲得的代碼之間的性能比較,性能比較如圖10和圖11所示。
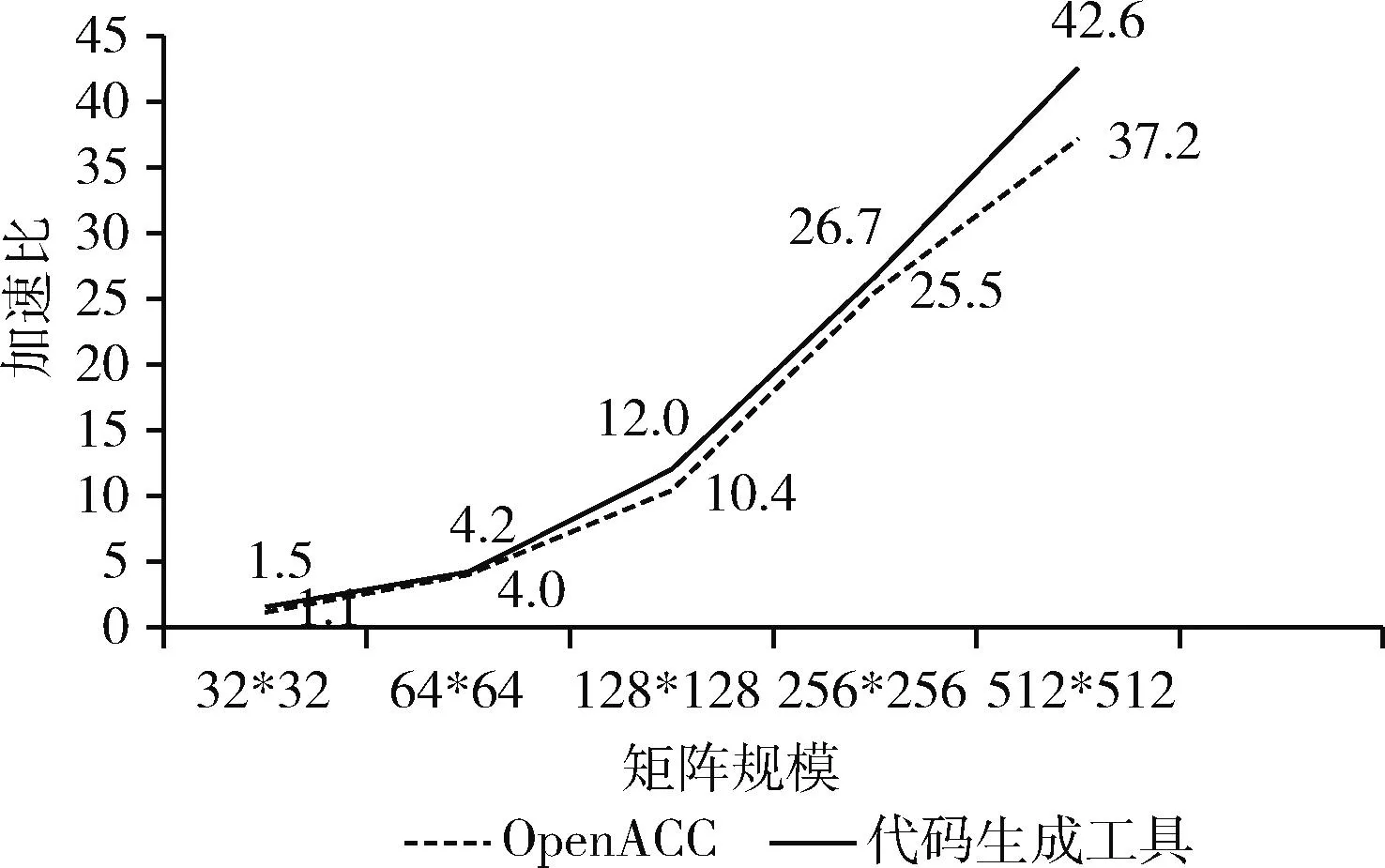
圖10 兩種編程模型的加速效果比較(單個(gè)核心段)
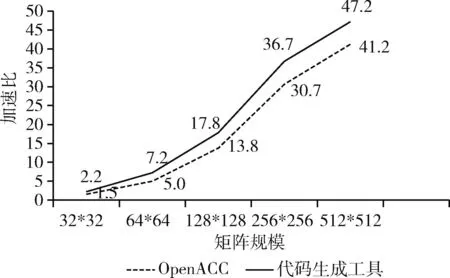
圖11 兩種編程模型的加速效果比較 (兩個(gè)核心段)
根據(jù)圖10和圖11所示結(jié)果,自動(dòng)生成的Athread代碼比OpenACC*代碼有更好的加速效果。雖然在2D模板中對一個(gè)核心段進(jìn)行加速時(shí),兩種編程方法的加速性能差異不是很明顯,這主要是由于核心段計(jì)算量小;但是如圖11所示,當(dāng)對2個(gè)核心段進(jìn)行加速時(shí),兩種編程方法的加速比具有明顯不同,這是由于OpenACC*對于多個(gè)核心段的并行粒度不高,只能分別進(jìn)行加速;而轉(zhuǎn)換工具采用一次spawn加載方式,并行粒度增大,從而產(chǎn)生差別明顯的加速效果。通過上述實(shí)驗(yàn)可以驗(yàn)證這個(gè)轉(zhuǎn)換工具是具有應(yīng)用價(jià)值的。
自動(dòng)轉(zhuǎn)換的主從核代碼與人工編寫的代碼相比具有很多優(yōu)勢,轉(zhuǎn)換工具可以有效避免變量名稱和大小寫的低級書寫錯(cuò)誤;避免了結(jié)構(gòu)體傳參時(shí)變量順序的錯(cuò)誤;模板是自動(dòng)計(jì)算地址偏移大小,可以有效防止人工編寫代碼計(jì)算從核地址偏移量時(shí)所發(fā)生的錯(cuò)誤;此外,該工具還可直接調(diào)用已有的從核間通訊接口函數(shù),方便用戶使用,提高了代碼的重用性。總體來說,該轉(zhuǎn)換工具與人工編寫相比,可以準(zhǔn)確地生成Athread代碼,提高開發(fā)人員的工作效率。
4 結(jié)束語
本文在國產(chǎn)神威系列超級計(jì)算機(jī)系統(tǒng)的架構(gòu)下,泛化提出基于主程序調(diào)用master程序再由master程序調(diào)用slave程序的三層模板程序架構(gòu),集成了常用的眾核優(yōu)化方法,采用Rust語言進(jìn)行詞法和語法分析,設(shè)計(jì)開發(fā)了一個(gè)圖形化使用界面的Athread代碼自動(dòng)轉(zhuǎn)換工具。與現(xiàn)有的轉(zhuǎn)換工具相比,該工具實(shí)現(xiàn)了在異構(gòu)眾核處理器上不同維度下Fortran/C程序核心段代碼的基于Athread方式的自動(dòng)眾核代碼轉(zhuǎn)換。當(dāng)前該工具采用基于制導(dǎo)文件的方法,下一步將采用成熟的編譯器前端分析結(jié)果自動(dòng)生成。同時(shí),將繼續(xù)集成一些新的優(yōu)化方法、添加性能分析工具和支持一些新的語法格式。
猜你喜歡
電腦愛好者(2020年6期)2020-05-26 09:27:33
人大建設(shè)(2019年12期)2019-05-21 02:55:44
中山大學(xué)法律評論(2018年1期)2018-03-30 01:21:00
瞭望東方周刊(2017年42期)2017-12-05 18:49:38
環(huán)球時(shí)報(bào)(2017-03-30)2017-03-30 06:44:45
信息安全與通信保密(2016年3期)2016-08-23 01:23:56
山西省政法管理干部學(xué)院學(xué)報(bào)(2016年2期)2016-07-31 18:19:34
山西省政法管理干部學(xué)院學(xué)報(bào)(2016年2期)2016-07-31 18:19:25
中國衛(wèi)生(2015年3期)2015-11-19 02:53:32
政治與法律(2014年11期)2014-03-01 02:20:40
