基于集成學(xué)習(xí)算法的5G用戶流失預(yù)警方法研究
2024-02-21 07:53:11路明丁麗
中國市場 2024年4期
路明 丁麗
摘?要:隨著5G技術(shù)的發(fā)展,5G用戶的流失預(yù)警已成為移動運(yùn)營商的重要任務(wù)。然而,傳統(tǒng)的用戶流失預(yù)警方法在5G營銷領(lǐng)域存在準(zhǔn)確性和可靠性不高的問題。為了解決5G用戶流失預(yù)測問題,文章將集成九大機(jī)器學(xué)習(xí)算法,結(jié)合5G降檔以及離網(wǎng)用戶的標(biāo)簽數(shù)據(jù)和消費(fèi)行為,構(gòu)建一個基于集成學(xué)習(xí)算法的用戶流失預(yù)警模型。研究結(jié)果表明,基于集成學(xué)習(xí)算法的5G用戶流失預(yù)警方法具有較高的準(zhǔn)確率、實(shí)時性和可靠性,可以有效地提高5G用戶流失預(yù)警的效率。
關(guān)鍵詞:集成學(xué)習(xí)算法;5G營銷;用戶流失預(yù)警
中圖分類號:F832.4????文獻(xiàn)標(biāo)識碼:A?文章編號:1005-6432(2024)04-0195-04
DOI:10.13939/j.cnki.zgsc.2024.04.049
5G技術(shù)的發(fā)展為用戶提供了更快的網(wǎng)絡(luò)速度、更多的應(yīng)用服務(wù)、更高的網(wǎng)絡(luò)安全性,以及更低的網(wǎng)絡(luò)延遲,然而,由于用戶的使用習(xí)慣和消費(fèi)需求的變化,5G用戶的流失率也不斷增加,這對移動運(yùn)營商的業(yè)務(wù)發(fā)展構(gòu)成了巨大的挑戰(zhàn)。因此,如何通過海量用戶數(shù)據(jù)準(zhǔn)確地預(yù)判5G用戶的流失趨勢并針對性地挽留,已經(jīng)成為當(dāng)前5G市場營銷領(lǐng)域研究的熱點(diǎn)。文章旨在探索基于集成學(xué)習(xí)算法的5G用戶流失預(yù)警方法,首先,收集了5G用戶的使用習(xí)慣和消費(fèi)水平數(shù)據(jù),并對數(shù)據(jù)進(jìn)行預(yù)處理,以便進(jìn)行后續(xù)的分析。其次,文章提出了一種基于集成學(xué)習(xí)算法的5G用戶流失預(yù)警方法。集成學(xué)習(xí)算法是一種有效的機(jī)器學(xué)習(xí)方法,可以將多個機(jī)器學(xué)習(xí)模型結(jié)合起來,提高模型的準(zhǔn)確性。基于安徽移動公司2022年的用戶數(shù)據(jù),文章構(gòu)建了一個基于用戶標(biāo)簽的預(yù)警模型,并采用集成學(xué)習(xí)的方法,將隨機(jī)森林、神經(jīng)網(wǎng)絡(luò)、Xgboost以及Catboost等九大機(jī)器學(xué)習(xí)算法結(jié)合起來,最后對集成學(xué)習(xí)算法進(jìn)行評估,驗(yàn)證了模型的有效性和可靠性。
1?研究現(xiàn)狀
隨著5G技術(shù)的發(fā)展,通信行業(yè)面臨著市場競爭激烈、產(chǎn)品同質(zhì)化嚴(yán)重、客戶流失等諸多問題,5G用戶流失問題已經(jīng)成為當(dāng)前研究的熱點(diǎn)。目前,已有一些關(guān)于移動通信客戶流失的研究,對客戶流失預(yù)測方法進(jìn)行了前期研究,以單一機(jī)器學(xué)習(xí)模型和數(shù)據(jù)挖掘?yàn)橹鳌@纾觳莸韧ㄟ^語氣算子的運(yùn)用、信息轉(zhuǎn)換公式等,把模糊語言變成精確概率,并將其應(yīng)用于客戶流失的預(yù)警與分析[1];鄧小龍等引入人工智能遺傳演化思想,對基于心理學(xué)擴(kuò)散模型的SPA預(yù)測流失算法進(jìn)行改進(jìn),提出一種遺傳演化預(yù)測算法,增強(qiáng)了預(yù)測模型泛化能力[2];林濤綜合運(yùn)用了統(tǒng)計方法和機(jī)器學(xué)習(xí)方法,利用正則化邏輯回歸算法,對客戶流失預(yù)測的準(zhǔn)確率基本達(dá)到89%以上[3];李兵等利用決策樹和K-Means++聚類,對傳統(tǒng)的隨機(jī)森林算法進(jìn)行了改進(jìn),獲得了高精度、低相似預(yù)測算法[4];王小超等以電信運(yùn)營商為對象,分別使用支持向量機(jī)、隨機(jī)森林、KNN、BP神經(jīng)網(wǎng)絡(luò)4種算法進(jìn)行研究,對比各種模型的準(zhǔn)確率與召回率,發(fā)現(xiàn)采用BP神經(jīng)網(wǎng)絡(luò)算法構(gòu)建的數(shù)據(jù)模型預(yù)測效果良好[5];喬健等將客戶生命周期價值指標(biāo)引入隨機(jī)森林CART分類樹算法特征選擇過程,有效地提高了客戶流失預(yù)測模型準(zhǔn)確率[6]。
近年來,很多學(xué)者運(yùn)用集成學(xué)習(xí)模型進(jìn)行用戶流失預(yù)測,例如,余路將Logistic回歸、BP神經(jīng)網(wǎng)絡(luò)與決策樹三種模型相結(jié)合,與單一模型預(yù)測結(jié)果相比,組合模型的預(yù)測效果更好[7];Jayaswal等人以電信用戶的數(shù)據(jù)為研究對象,分別構(gòu)造決策樹模型、隨機(jī)森林與GBDT的集成模型,證明隨機(jī)森林與GBDT明顯好于單個決策樹;武小軍等人提出了支持向量機(jī)、CW-SVM、BP神經(jīng)網(wǎng)絡(luò)和改進(jìn)的SMOTE+AdaBoost用于用戶流失預(yù)測,改進(jìn)后的方法能夠有效地確定類別中高價值的客戶群體,并提高流失客戶及非流失預(yù)測準(zhǔn)確性[8];汪明達(dá)等人提出了兩個混合模型來預(yù)測電信用戶的損失,分別為神經(jīng)網(wǎng)絡(luò)與機(jī)器學(xué)習(xí)集成模型、樸素隨機(jī)過采樣與投票結(jié)合的集成模型,研究表明,樸素隨機(jī)過采樣投票集成模型準(zhǔn)確率較高;Ahmed等人對邏輯回歸、樸素貝葉斯、多層感知機(jī)、決策樹、隨機(jī)森林等、GBDT分別進(jìn)行檢驗(yàn),研究表明,隨機(jī)森林模型與GBDT模型預(yù)測效果明顯好于其他單一模型。為進(jìn)一步增強(qiáng)該模型預(yù)測能力,采用Stacking方法實(shí)現(xiàn)了模型集成。
從上述文獻(xiàn)可以看出,用戶流失預(yù)測領(lǐng)域研究已經(jīng)取得了顯著的進(jìn)步,研究人員對用戶流失的預(yù)測方法和思路存在一定差異。隨著5G通信技術(shù)和產(chǎn)品的迭代,現(xiàn)有的用戶流失模型缺乏針對5G套餐用戶的預(yù)測。在5G市場中,降檔和離網(wǎng)是用戶流失的關(guān)鍵預(yù)警行為,對于研究5G用戶流失預(yù)警模型是非常有必要的。因此,本研究通過降檔離網(wǎng)用戶和非降檔離網(wǎng)用戶在近幾個月內(nèi)的相關(guān)數(shù)據(jù),驗(yàn)證最核心的機(jī)器學(xué)習(xí)算法,通過核心標(biāo)簽指標(biāo)和集成學(xué)習(xí)模型,進(jìn)行用戶流失預(yù)測分析,從而準(zhǔn)確定位營銷時機(jī),高效采用營銷策略,全面提升營銷效率。
2?研究設(shè)計
2.1?數(shù)據(jù)提取
本研究數(shù)據(jù)來自安徽移動GBase數(shù)據(jù)庫,隨機(jī)抽取了762191條用戶數(shù)據(jù),其中降檔離網(wǎng)用戶僅有4243人。為了更好地進(jìn)行模型預(yù)測,需要平衡降檔離網(wǎng)人數(shù)和非降檔離網(wǎng)人數(shù),分成兩步提取數(shù)據(jù)。第一步:提取2022年10月“是否降檔離網(wǎng)”標(biāo)記為0,同時2022年11月“是否降檔離網(wǎng)”標(biāo)記為1的用戶500000人,作為正樣本;第二步:提取2022年10月“是否降檔離網(wǎng)”標(biāo)記為0,同時2022年11月“是否降檔離網(wǎng)”也標(biāo)記為0的用戶500000人,作為負(fù)樣本。由于上次提取的762191條數(shù)據(jù)中也含有“11月降檔離網(wǎng)用戶”(3905人)和“10月和11月均未降檔離網(wǎng)用戶”(254022人),將這部分用戶也加入樣本中,最終得到降檔離網(wǎng)用戶503905人(正樣本),未降檔離網(wǎng)用戶754022人(負(fù)樣本)。
2.2?數(shù)據(jù)清洗
在數(shù)據(jù)生產(chǎn)、運(yùn)輸、存儲的過程中可能會產(chǎn)生大量的噪聲點(diǎn),如缺失、重復(fù)、錯誤、異常等情況。數(shù)據(jù)清洗就是要將無效數(shù)據(jù)清洗干凈,從而提高數(shù)據(jù)質(zhì)量,增強(qiáng)預(yù)測結(jié)果的可信度。首先對初始標(biāo)簽進(jìn)行缺失值判斷,查看標(biāo)簽是否完整,發(fā)現(xiàn)部分標(biāo)簽缺失較多數(shù)據(jù),因此選擇直接刪除這部分用戶。除了缺失值,在收集數(shù)據(jù)時也發(fā)現(xiàn)有部分標(biāo)簽的值中含有“不詳”(以“Z”表示)的部分,因此將該標(biāo)簽視作無效標(biāo)簽刪除。剩余標(biāo)簽中,“Z”的存在較少,因此這樣的標(biāo)簽仍然具有預(yù)測能力,只需要把標(biāo)簽未知的這部分用戶刪除即可。
2.3?數(shù)據(jù)標(biāo)準(zhǔn)化
數(shù)據(jù)標(biāo)準(zhǔn)化指的是將樣本的屬性縮放到某個指定的范圍。在采集的數(shù)據(jù)中不同屬性的數(shù)據(jù)具有不同的量級,標(biāo)準(zhǔn)化后可以讓不同維度之間的標(biāo)簽在數(shù)值上有一定比較性,尋優(yōu)過程范圍變小,更容易收斂到最優(yōu)解。文章采用Z-score的方法對數(shù)據(jù)進(jìn)行標(biāo)準(zhǔn)化處理。
2.4?特征工程
特征工程是從用戶基本數(shù)據(jù)、訂購數(shù)據(jù)、行為數(shù)據(jù)中篩選用戶信息,讓其最大限度地表征用戶的所有標(biāo)簽,并盡可能地剔除冗余數(shù)據(jù)的過程。可以從以下幾個方面考慮選擇特征:
方差篩選:在數(shù)理統(tǒng)計中,方差是各變量值與其均值離差平方的平均數(shù),是測算數(shù)值型數(shù)據(jù)離散程度的最重要的方法。方差越大,數(shù)據(jù)的波動就越大,方差越小,數(shù)據(jù)的波動就越小。如果一個特征不發(fā)散,也就是說樣本在這個特征上基本沒有差異,這個特征對于預(yù)測就沒有什么用。因此需要消除方差為0或較小的特征。在本研究中設(shè)置閾值為0.01,然后篩選掉方差小于閾值的特征,剩余46個標(biāo)簽。
相關(guān)性分析:首先與目標(biāo)高相關(guān)的特征應(yīng)該優(yōu)先選擇,與目標(biāo)低相關(guān)的特征應(yīng)該適當(dāng)舍棄。其次特征之間如果存在某種相關(guān)或者高度相關(guān)的關(guān)系,會產(chǎn)生多重共線性的問題,使模型估計失真或難以估計,最后需要進(jìn)行剔除。變量相關(guān)性剔除的方法有很多,本研究主要通過計算兩兩特征的相關(guān)系數(shù),采用皮爾遜相關(guān)系數(shù)計算,皮爾遜相關(guān)系數(shù)定義為兩個變量之間的協(xié)方差和標(biāo)準(zhǔn)差的商。設(shè)置相關(guān)系數(shù)的閾值為0.7,若兩特征的相關(guān)系數(shù)大于0.7則代表他們高度相關(guān),需要刪除其中一個。計算所有特征兩兩之間的相關(guān)系數(shù),將大于閾值的特征進(jìn)行剔除,最終剩余36個標(biāo)簽。
卡方檢驗(yàn):卡方檢驗(yàn)專門針對分類問題的相關(guān)性過濾,可以對離散型特征進(jìn)行篩選,是用來檢驗(yàn)定性自變量對定性因變量的相關(guān)性,構(gòu)建統(tǒng)計量χ2進(jìn)行估計。之后根據(jù)自由度來對照卡方分布的臨界值表進(jìn)行判斷,自由度為K-1。χ2就是自變量對因變量的相關(guān)性,按照計算出的卡方統(tǒng)計量由高到低排列。文章對卡方檢驗(yàn)p值大于0.05的特征進(jìn)行篩除,最終保留31個標(biāo)簽。
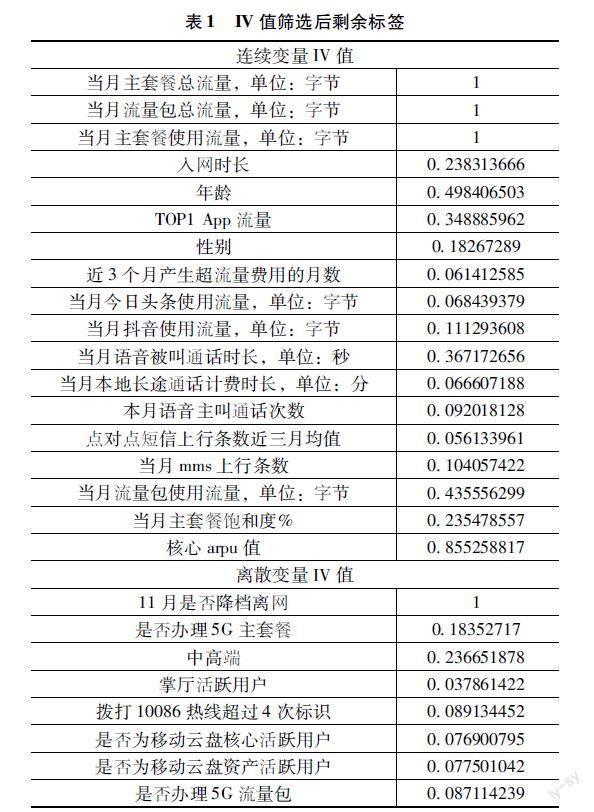
IV值篩選:在進(jìn)行特征工程之前需要對特征進(jìn)行重要性篩選,由于標(biāo)簽較多,所以需要用一種方法幫助衡量什么變量應(yīng)該進(jìn)入模型,什么變量應(yīng)該舍棄,本研究使用了IV值篩選方法,IV值的含義是信息價值或信息量。對于變量來說,IV值越大就表示預(yù)測能力越強(qiáng)。由于連續(xù)變量與非連續(xù)變量計算方式不同,因此首先將連續(xù)變量與非連續(xù)變量分離,最終得到連續(xù)變量18個,非連續(xù)變量13個。然后將連續(xù)變量分箱計算IV值,篩選出IV值大于0.03的標(biāo)簽進(jìn)行保留,最終保留18個標(biāo)簽。對非連續(xù)變量不需要進(jìn)行分箱,直接計算最終保留8個標(biāo)簽,因此通過IV值計算最終保留26個標(biāo)簽。篩選結(jié)果如表1所示。
2.5?模型構(gòu)建
經(jīng)過特征工程后,將提取的標(biāo)簽作為輸入,構(gòu)建一個基于集成學(xué)習(xí)算法的模型,采用決策樹、隨機(jī)森林模型、Xgboost、Catboost、支持向量機(jī)、邏輯回歸模型、最近鄰(KNN)算法、樸素貝葉斯算法、BP神經(jīng)網(wǎng)絡(luò)算法,用于5G用戶流失預(yù)警推薦。
決策樹:作為機(jī)器學(xué)習(xí)算法中一種基本的分類和回歸算法,決策樹學(xué)習(xí)是以實(shí)例為基礎(chǔ)的歸納學(xué)習(xí)。模型呈樹形結(jié)構(gòu),主要由節(jié)點(diǎn)和有向邊組成,代表的是對象屬性與標(biāo)簽值之間的一種映射關(guān)系。
隨機(jī)森林:隨機(jī)森林是由多個決策樹組成。在處理分類問題時,隨機(jī)森林本質(zhì)上是對許多決策樹進(jìn)行打包處理(bagging),最后以所有決策樹的投票來確定最終分類結(jié)果。文章中通過python的sklearn庫調(diào)取模型進(jìn)行應(yīng)用,隨機(jī)森林決策樹數(shù)量為1000,最大深度為40。
Xgboost:Xgboost算法屬于GBDT梯度提升決策樹的一種,通過對決策樹進(jìn)行提升(boosting)處理來實(shí)現(xiàn)集成。隨機(jī)森林對決策樹進(jìn)行打包時最終輸出的結(jié)果由所有決策樹投票產(chǎn)生,而Xgboost每一次迭代都會在上一次迭代的基礎(chǔ)上進(jìn)行。文章中Xgboost樹的數(shù)量為1000,最大深度為40。
Catboost:Catboost是嵌入了自動將類別型特征處理為數(shù)值型特征的創(chuàng)新算法。首先對分類特征做一些統(tǒng)計,計算某個類別特征出現(xiàn)的頻率,之后加上超參數(shù),生成新的數(shù)值型特征,且使用了組合類別特征,可以利用特征之間的聯(lián)系,豐富了特征維度。
支持向量機(jī):通過一條支持向量來實(shí)現(xiàn)對數(shù)據(jù)的劃分,并且力求使向量到兩類數(shù)據(jù)最近的樣本距離最大。它是機(jī)器學(xué)習(xí)中最流行的模型之一,特別適用于復(fù)雜的中小型數(shù)據(jù)集分類。
邏輯回歸模型:邏輯回歸也被稱為廣義線性回歸模型,是一種簡單的二分類模型,與線性回歸模型的形式基本上相同。邏輯回歸在線性回歸的基礎(chǔ)上,套用了一個邏輯函數(shù)。
最近鄰:最近鄰算法從現(xiàn)有特征出發(fā),如果i與某一類別的群體比較相似,則i就屬于這一類。因此,在最近鄰算法中最重要的是K值的選取和點(diǎn)距離的計算,本研究通過交叉驗(yàn)證的方式最終確定K值選取為5時預(yù)測效果最好。
樸素貝葉斯:樸素貝葉斯算法對于給出的待分類項(xiàng)目,求解在此項(xiàng)目出現(xiàn)的條件下各個類別出現(xiàn)的概率,哪個最大就認(rèn)為此待分類項(xiàng)屬于哪個類別。只需要求出在特定特征下某個新值是某個類別的概率即可。
神經(jīng)網(wǎng)絡(luò)模型:神經(jīng)網(wǎng)絡(luò)大體可以分為輸入層、隱藏層以及輸出層。為了充分地利用數(shù)據(jù)中的信息,可以通過在輸入層與輸出層之間加入隱藏層的方式來將數(shù)據(jù)投影到高維空間中,并在高維空間對數(shù)據(jù)進(jìn)行劃分來更好地對數(shù)據(jù)進(jìn)行線性劃分。文章中神經(jīng)網(wǎng)絡(luò)設(shè)置兩層隱藏層,每層具有50個隱藏神經(jīng)元,正則化懲罰系數(shù)為10-5,求解方式為隨機(jī)梯度下降。
3?實(shí)驗(yàn)結(jié)果
3.1?模型評估
在模型評估方面,從precision、recall、accuracy、f1score四個角度來使用10折交叉驗(yàn)證對模型進(jìn)行評估。
查準(zhǔn)率(precision):指被分類器判定正例中的正樣本的比重。
查全率(recall):指的是被預(yù)測為正例的占總的正例的比重。
準(zhǔn)確率(accuracy):代表分類器對整個樣本判斷正確的比重。
f1score:查準(zhǔn)率和查全率的綜合。
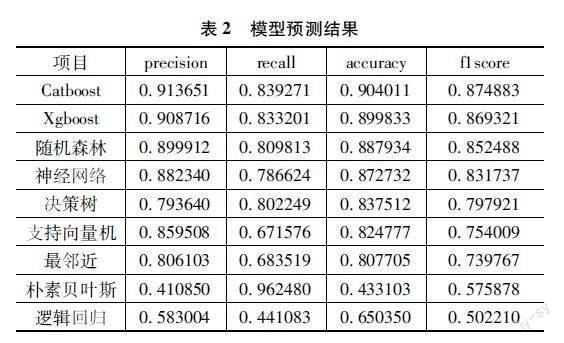
交叉驗(yàn)證:指在給定的建模樣本中,拿出其中的大部分樣本進(jìn)行模型訓(xùn)練,留小部分樣本用剛建立的模型進(jìn)行預(yù)測,并求這小部分樣本的預(yù)測誤差,記錄它們的平方加和。這個過程一直進(jìn)行,直到所有的樣本都被預(yù)測了一次而且僅被預(yù)測一次,比較每組的預(yù)測誤差,選取誤差最小的那一組作為訓(xùn)練模型。表2展示了交叉驗(yàn)證結(jié)果:
由表2可知,按模型效果大體可以將模型分為三個層次:邏輯回歸和樸素貝葉斯位于第三梯隊;最鄰近、支持向量機(jī)、決策樹有效性位于第二梯隊;隨機(jī)森林、神經(jīng)網(wǎng)絡(luò)、XGBoost以及CatBoost有效性處于第一梯隊。
3.2?模型進(jìn)一步處理
為了提高模型穩(wěn)健性,現(xiàn)選擇隨機(jī)森林、神經(jīng)網(wǎng)絡(luò)、CatBoost以及XGBoost模型以打包(bagging)的形式進(jìn)行集成,集成后的學(xué)習(xí)模型采取以下規(guī)則對客戶是否為潛在降檔離網(wǎng)客戶進(jìn)行判斷:對客戶k來說,分別用隨機(jī)森林、神經(jīng)網(wǎng)絡(luò)、XGBoost以及CatBoost對當(dāng)前客戶進(jìn)行預(yù)測,如果有三個或三個以上模型預(yù)測客戶k為潛在流失客戶,則認(rèn)為客戶k為潛在流失客戶,否則認(rèn)為客戶k不是潛在流失客戶。
經(jīng)測試,得到多模型的準(zhǔn)確率為0.93220,遠(yuǎn)高于上述所有單個模型,但由于高準(zhǔn)確率是由嚴(yán)格的條件而來的,因此查全率的表現(xiàn)平平,查全率為0.80593,f1score值為0.86447,總體上略低于CatBoost和XGBoost,因此是否運(yùn)用多模型,需要考慮準(zhǔn)確與查全的平衡,若要求高準(zhǔn)確率,則可使用多模型預(yù)測,若既要求準(zhǔn)確也要求查全,則使用單模型CatBoost或XGBoost是較好的選擇。
4?結(jié)論
隨著5G技術(shù)的發(fā)展,5G用戶流失預(yù)警方法的研究受到了越來越多的關(guān)注。文章研究了基于集成學(xué)習(xí)算法的5G用戶流失預(yù)警方法,具體來說,提出了一種基于集成學(xué)習(xí)算法的5G用戶流失預(yù)警方法,該方法利用多種機(jī)器學(xué)習(xí)算法,從查準(zhǔn)率、查全率、準(zhǔn)確率、F1值多指標(biāo)維度對模型進(jìn)行評估,發(fā)現(xiàn)隨機(jī)森林、神經(jīng)網(wǎng)絡(luò)、XGBoost以及CatBoost效果最好,效果在所測試模型中處于第一梯隊。另外,為了提高預(yù)測的穩(wěn)健性,文章對測試效果較好的模型進(jìn)行打包集成處理,并將集成后的模型作為最終預(yù)測模型。
本研究主要貢獻(xiàn)有以下幾點(diǎn):首先,構(gòu)建了5G市場用戶標(biāo)簽庫,通過不斷優(yōu)化標(biāo)簽,最終形成一個精準(zhǔn)的標(biāo)簽庫,從而使模型產(chǎn)生更好的預(yù)測效果;其次,構(gòu)建了5G用戶流失預(yù)測模型,對約100萬用戶數(shù)據(jù)進(jìn)行了訓(xùn)練,幫助運(yùn)營商找到合適的客戶進(jìn)行針對性營銷,降低5G業(yè)務(wù)的用戶流失率。未來的研究應(yīng)該更加注重技術(shù)的可擴(kuò)展性和可維護(hù)性,以滿足不斷變化的市場需求。例如,可以采用增量學(xué)習(xí)或聯(lián)合學(xué)習(xí)的方法,以更好地適應(yīng)市場的變化。也可以改進(jìn)標(biāo)簽選擇和標(biāo)簽組合技術(shù),提高用戶標(biāo)簽庫的準(zhǔn)確性和效率。
參考文獻(xiàn):
[1]徐草,李敏.模糊貝葉斯網(wǎng)在通信行業(yè)客戶流失預(yù)測中的應(yīng)用研究[J].合肥工業(yè)大學(xué)學(xué)報(自然科學(xué)版),2010,33(10):1567-1571.
[2]鄧小龍,王柏,吳斌,等.遺傳演化SPA流失預(yù)測算法及并行化[J].計算機(jī)科學(xué)與探索,2011,5(5):433-445.
[3]林濤.基于Logistic回歸的電信寬帶客戶流失預(yù)警分析[J].中國新通信,2019,21(11):147-148.
[4]李兵,陳俊才.基于TMRF算法的電信客戶流失預(yù)測方案研究[J].數(shù)字技術(shù)與應(yīng)用,2021,39(4):116-121.
[5]王小超,張勇.基于BP神經(jīng)網(wǎng)絡(luò)的電信用戶流失預(yù)測研究[J].綏化學(xué)院學(xué)報,2021,41(11):148-151.
[6]喬健,諸佳慧,嚴(yán)康桓.基于隨機(jī)森林CART特征選擇改進(jìn)算法的電信客戶流失預(yù)測模型[J].電信工程技術(shù)與標(biāo)準(zhǔn)化,2022,35(3):78-82.
[7]余路.電信客戶流失的組合預(yù)測模型[J].華僑大學(xué)學(xué)報(自然科學(xué)版),2016,37(5):637-640.
[8]武小軍,孟蘇芳.基于客戶細(xì)分和AdaBoost的電子商務(wù)客戶流失預(yù)測研究[J].工業(yè)工程,2017,20(2):99-107.
[基金項(xiàng)目]本文系安徽移動公司研發(fā)項(xiàng)目“安徽移動5G業(yè)務(wù)互聯(lián)網(wǎng)鏈路營銷體系研究研發(fā)服務(wù)合同”的階段性成果(項(xiàng)目編號:202101243)。
[作者簡介]路明(1980—),男,漢族,安徽蕪湖人,碩士,中國移動通信集團(tuán)有限公司安徽分公司工程師,研究方向:5G業(yè)務(wù);丁麗(1989—),女,漢族,安徽六安人,中國移動通信集團(tuán)有限公司安徽分公司中級經(jīng)濟(jì)師,研究方向:5G業(yè)務(wù)。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2020年10期)2020-11-26 08:24:50
數(shù)學(xué)物理學(xué)報(2020年2期)2020-06-02 11:29:24
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當(dāng)代陜西(2019年10期)2019-06-03 10:12:04
數(shù)學(xué)小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
商用汽車(2016年11期)2016-12-19 01:20:16
光學(xué)精密工程(2016年6期)2016-11-07 09:07:19
商用汽車(2016年6期)2016-06-29 09:18:54
商用汽車(2016年4期)2016-05-09 01:23:12
