基于GPU加速的投影后變分殼模型計(jì)算
2024-02-20 03:42:40連占江高早春
原子能科學(xué)技術(shù) 2024年2期
陸 曉,連占江,高早春
(中國(guó)原子能科學(xué)研究院 核物理研究所,北京 102413)
理論上,原子核多體波函數(shù)可通過(guò)求解薛定諤方程獲得。傳統(tǒng)殼模型就是在此基礎(chǔ)上建立的。然而,由于模型空間的限制,傳統(tǒng)殼模型計(jì)算僅限于質(zhì)量數(shù)較輕或幻數(shù)附近的原子核。對(duì)于變形重核,需更大的價(jià)核子空間,相應(yīng)的殼模型組態(tài)空間維度數(shù)會(huì)變得極其巨大,因而無(wú)法實(shí)現(xiàn)精確的殼模型計(jì)算。這是核多體問(wèn)題中一直存在的難題,且在可見的未來(lái)難以被徹底解決。為回避巨大組態(tài)空間這一困難,人們發(fā)展了各種殼模型近似方法[1-13],以期進(jìn)一步擴(kuò)展殼模型應(yīng)用核區(qū)范圍。
投影后變分(VAP)方法就是一類較重要的殼模型近似方法[8-13]。它將原子核試探波函數(shù)進(jìn)行變分,從而得到盡可能好的殼模型近似結(jié)果。通常情況下,VAP波函數(shù)可由投影Hartree-Fock-Bogoliubov(HFB)真空態(tài)或投影Hartree-Fock(HF)斯萊特行列式(SD)構(gòu)成。其中采用HFB真空態(tài)完全投影得到具有好量子數(shù)(中子數(shù)、質(zhì)子數(shù)、角動(dòng)量和宇稱)的波函數(shù)需要五重積分,計(jì)算非常耗時(shí)。而文獻(xiàn)[8]的研究表明,在這幾種投影中,角動(dòng)量投影是最重要的。于是,在實(shí)際應(yīng)用中,通常采用HF SD只進(jìn)行角動(dòng)量與宇稱投影構(gòu)建初始試探波函數(shù)。顯然,在相同數(shù)目的投影態(tài)下,用投影SD作為VAP波函數(shù)的近似不如投影HFB真空態(tài)得到的結(jié)果好。但前者的近似性可通過(guò)添加更多的投影SD來(lái)改善。在某種意義上,采用投影SD進(jìn)行投影后變分計(jì)算可減少計(jì)算消耗。因此,本文采用的VAP波函數(shù)全部基于投影SD構(gòu)建。
然而,隨著VAP計(jì)算往中重核區(qū)推進(jìn),計(jì)算所需模型空間不斷擴(kuò)大,價(jià)核子數(shù)目不斷增加,為保證計(jì)算的精度,就需更多的投影SD參與構(gòu)建試探VAP波函數(shù),這無(wú)疑會(huì)造成VAP計(jì)算負(fù)擔(dān)的加重,甚至導(dǎo)致VAP迭代收斂非常緩慢。隨著半導(dǎo)體和芯片技術(shù)的迅猛發(fā)展,可提供應(yīng)用的高性能計(jì)算平臺(tái)不斷增加。特別是近年來(lái)計(jì)算性能飛速提升的圖形處理器(graphics processing unit, GPU),其在人工智能、大數(shù)據(jù)等領(lǐng)域應(yīng)用廣泛,已逐漸取代早期用于并行計(jì)算的CPU處理器,成為現(xiàn)代高性能計(jì)算的首選。因此,在原子核物理領(lǐng)域,GPU卓越的計(jì)算性能也有望進(jìn)一步提升相關(guān)物理模型的計(jì)算效率。作為一個(gè)具體實(shí)例,本文擬將VAP殼模型計(jì)算程序從傳統(tǒng)的CPU平臺(tái)移植到GPU平臺(tái),以期進(jìn)一步提升VAP的計(jì)算速度。
本文將從VAP的原理出發(fā),介紹其在計(jì)算當(dāng)中遇到的數(shù)值問(wèn)題,基于OpenACC并行化模型實(shí)現(xiàn)VAP在GPU平臺(tái)上的計(jì)算,并通過(guò)實(shí)例展示采用GPU相對(duì)于CPU在計(jì)算效率上的提升。
1 VAP的數(shù)值問(wèn)題
首先,采用投影SD構(gòu)建的試探VAP波函數(shù)可寫為如下形式[12]:
(1)

(2)

若要使這m個(gè)態(tài)的波函數(shù)盡可能接近殼模型的精確波函數(shù),需對(duì)|ΨJπMα(K)〉進(jìn)行最優(yōu)化。從式(1)可看出,|ΨJπMα(K)〉是由|Φi〉決定的。于是,最優(yōu)化|ΨJπMα(K)〉實(shí)際上是通過(guò)對(duì)所有的|Φi〉變分實(shí)現(xiàn)。欲對(duì)|Φi〉進(jìn)行變分,首先對(duì)其進(jìn)行參數(shù)化。此過(guò)程可通過(guò)如下Thouless定理[14]實(shí)現(xiàn):
(3)
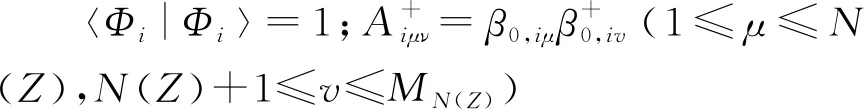
DVAP=N(MN-N)+Z(MZ-Z)
(4)
在VAP計(jì)算中,將變分參數(shù)取為復(fù)數(shù)的形式。于是,采用n個(gè)SD構(gòu)建的VAP波函數(shù),其獨(dú)立變分參數(shù)就有2nDVAP個(gè)。可見,隨著模型空間的增大、價(jià)核子數(shù)目的增多以及SD數(shù)目的增加,將會(huì)導(dǎo)致獨(dú)立變分參數(shù)迅速增加。

(5)
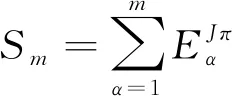
在最小化能量之和的過(guò)程中,為保證VAP計(jì)算的穩(wěn)定性,在迭代過(guò)程中計(jì)算能量的梯度與Hessian矩陣[9]。即計(jì)算了如下4類矩陣元:
(6)

(7)

此外,在VAP計(jì)算中,哈密頓量通常取為如下形式:
(8)
其中:tij和vijkl分別為單體和兩體相互作用矩陣元;c+和c分別為粒子產(chǎn)生和湮滅算符;i、j、k、l分別表示不同的單粒子軌道。由式(8)可看出,在兩體相互作用下,單個(gè)投影矩陣元在特定積分格點(diǎn)處的分量通常包含一個(gè)對(duì)單粒子軌道的4重求和。
基于以上討論可看到,在VAP計(jì)算中,投影矩陣元的計(jì)算占據(jù)了大部分計(jì)算時(shí)間。并隨著模型空間的增大,價(jià)核子數(shù)的增多,計(jì)算時(shí)間會(huì)迅速增加。為更直觀體現(xiàn)這種計(jì)算耗時(shí),以sd模型空間的24Mg與pf模型空間的56Ni的基態(tài)為例,采用1個(gè)SD,即n=1,對(duì)24Mg基態(tài)到56Ni基態(tài)投影矩陣元計(jì)算量的增加做一定量估計(jì)。首先,對(duì)24Mg的基態(tài),每個(gè)方向上只需選取8個(gè)格點(diǎn)就足以得到好的積分結(jié)果。而計(jì)算56Ni的基態(tài),每個(gè)方向上積分格點(diǎn)的數(shù)目通常需增加至18個(gè)。因此,從24Mg到56Ni,總的積分格點(diǎn)數(shù)目增加約了10倍。因?yàn)樽龊?jiǎn)單估算,將單個(gè)投影矩陣元在特定積分格點(diǎn)處每重求和的求和次數(shù)取為原子核所在模型空間的中子軌道數(shù)的一半。此時(shí),24Mg所處的sd殼包含12條中子軌道,對(duì)應(yīng)的總求和次數(shù)為1 296,而56Ni所處的pf模型空間則包含20條中子軌道,其總求和次數(shù)為10 000,接近24Mg求和次數(shù)的8倍。最后24Mg共有64個(gè)獨(dú)立的變分參數(shù),對(duì)應(yīng)有64個(gè)梯度分量和2 080個(gè)獨(dú)立的Hessian矩陣元,56Ni則共有192個(gè)獨(dú)立的變分參數(shù),對(duì)應(yīng)有192個(gè)梯度分量和18 528個(gè)獨(dú)立的Hessian矩陣元,分別是24Mg數(shù)目的3倍和8.9倍。因此,從24Mg的基態(tài)到56Ni的基態(tài),總計(jì)算量增加了近780倍,且這一數(shù)字隨著模型空間的增大和價(jià)核子數(shù)目的增加會(huì)進(jìn)一步增大。所以,如果采用傳統(tǒng)的串行VAP計(jì)算,在時(shí)間上是不可接受的。
在VAP中,式(6)所示的投影矩陣元之間是相互獨(dú)立的。因此,為節(jié)省計(jì)算時(shí)間,實(shí)際的VAP計(jì)算一般需借助并行技術(shù)實(shí)現(xiàn)不同獨(dú)立格點(diǎn)的同時(shí)計(jì)算。在之前的工作中,為提高中重核區(qū)的VAP計(jì)算效率,主要通過(guò)OpenMP等并行方法將不同積分格點(diǎn)處的轉(zhuǎn)動(dòng)矩陣元計(jì)算任務(wù)分配給不同的CPU核心執(zhí)行,從而實(shí)現(xiàn)對(duì)不同積分格點(diǎn)處轉(zhuǎn)動(dòng)矩陣元的同時(shí)計(jì)算。在這種模式下,同一積分格點(diǎn)處的不同轉(zhuǎn)動(dòng)矩陣元仍以串行方式逐個(gè)計(jì)算。從上面的討論可知,同一積分格點(diǎn)處存在大量相互獨(dú)立的轉(zhuǎn)動(dòng)矩陣元。顯然,這些獨(dú)立的轉(zhuǎn)動(dòng)矩陣元也可采用并行方式同時(shí)計(jì)算。因此,一種更有效的加速方式是將所有獨(dú)立的轉(zhuǎn)動(dòng)矩陣元同時(shí)并行化。當(dāng)然,這也意味著需更多的計(jì)算核心。在這方面,內(nèi)嵌數(shù)千個(gè)CUDA內(nèi)核的高性能GPU無(wú)疑較一般只有幾十或上百個(gè)核心的CPU計(jì)算服務(wù)器具更大優(yōu)勢(shì)。因此,為進(jìn)一步提升VAP的計(jì)算效率,有必要將當(dāng)前的程序代碼移植到GPU平臺(tái)上進(jìn)行加速計(jì)算。
2 基于OpenACC的GPU加速VAP程序改造
GPU是一種多核協(xié)處理器,通過(guò)PCIe總線與CPU相連。在并行計(jì)算中,程序總是從CPU開始執(zhí)行,由CPU負(fù)責(zé)執(zhí)行串行代碼并為并行計(jì)算做好準(zhǔn)備,包括數(shù)據(jù)初始化、分配GPU內(nèi)存、將數(shù)據(jù)復(fù)制到GPU等。當(dāng)程序運(yùn)行到計(jì)算密集區(qū)域時(shí),CPU以特殊形式調(diào)用GPU,由GPU完成并行計(jì)算并將結(jié)果返回到CPU繼續(xù)向下執(zhí)行。本文選用的GPU加速器為英偉達(dá)公司生產(chǎn)的Tesla V100。1塊Tesla V100 GPU共有5 120個(gè)CUDA內(nèi)核和640個(gè)Tensor內(nèi)核,不僅為Tesla V100提供了多核并行計(jì)算的結(jié)構(gòu)基礎(chǔ),也使其具備更高的浮點(diǎn)運(yùn)算能力。目前,Tesla V100單精度浮點(diǎn)運(yùn)算每秒峰值速度可達(dá)到15.7TFLOPS。
OpenACC是一基于指令的高級(jí)編程模型。編程人員只要在串行的C/C++或Fortran程序中插入合適的指令,支持OpenACC的編譯器就會(huì)根據(jù)指令的內(nèi)容產(chǎn)生可執(zhí)行的低級(jí)語(yǔ)言代碼,將指令指定范圍內(nèi)的計(jì)算密集的代碼分派給GPU等加速器并行完成。對(duì)于不支持OpenACC的編譯器,指令會(huì)被當(dāng)成注釋自動(dòng)忽略。這種機(jī)制不僅有效地減少了對(duì)原程序的改動(dòng),也有利于程序的跨平臺(tái)運(yùn)行。
基于OpenACC并行化模型可對(duì)VAP程序進(jìn)行改造,將其移植到GPU平臺(tái)進(jìn)行加速。由于VAP計(jì)算中的投影矩陣元之間是相互獨(dú)立的,因此,在將程序移植到GPU平臺(tái)的過(guò)程中,基本的思路就是利用OpenACC并行方法將同一積分格點(diǎn)處所有獨(dú)立的轉(zhuǎn)動(dòng)矩陣元算出,然后對(duì)不同積分格點(diǎn)處的轉(zhuǎn)動(dòng)矩陣元求和得到相應(yīng)的投影矩陣元。
經(jīng)GPU移植后的程序執(zhí)行流程如圖1所示,圖中藍(lán)色程序塊表示串行區(qū)域,由CPU執(zhí)行,橙色程序塊表示并行區(qū)域,由GPU執(zhí)行。在程序執(zhí)行過(guò)程中,首先由CPU完成初始化和預(yù)處理,再將初始基矢波函數(shù)和兩體相互作用信息從CPU內(nèi)存拷貝到GPU內(nèi)存開啟投影矩陣元的并行計(jì)算。待并行計(jì)算結(jié)束后,再將計(jì)算結(jié)果從GPU內(nèi)存拷貝到CPU內(nèi)存,在CPU上求解波函數(shù)滿足的HW方程,從而得到能量及其相應(yīng)的梯度和Hessian矩陣,利用信賴域算法得到下一次迭代的初始波函數(shù)。重復(fù)以上過(guò)程直至能量達(dá)到極小。
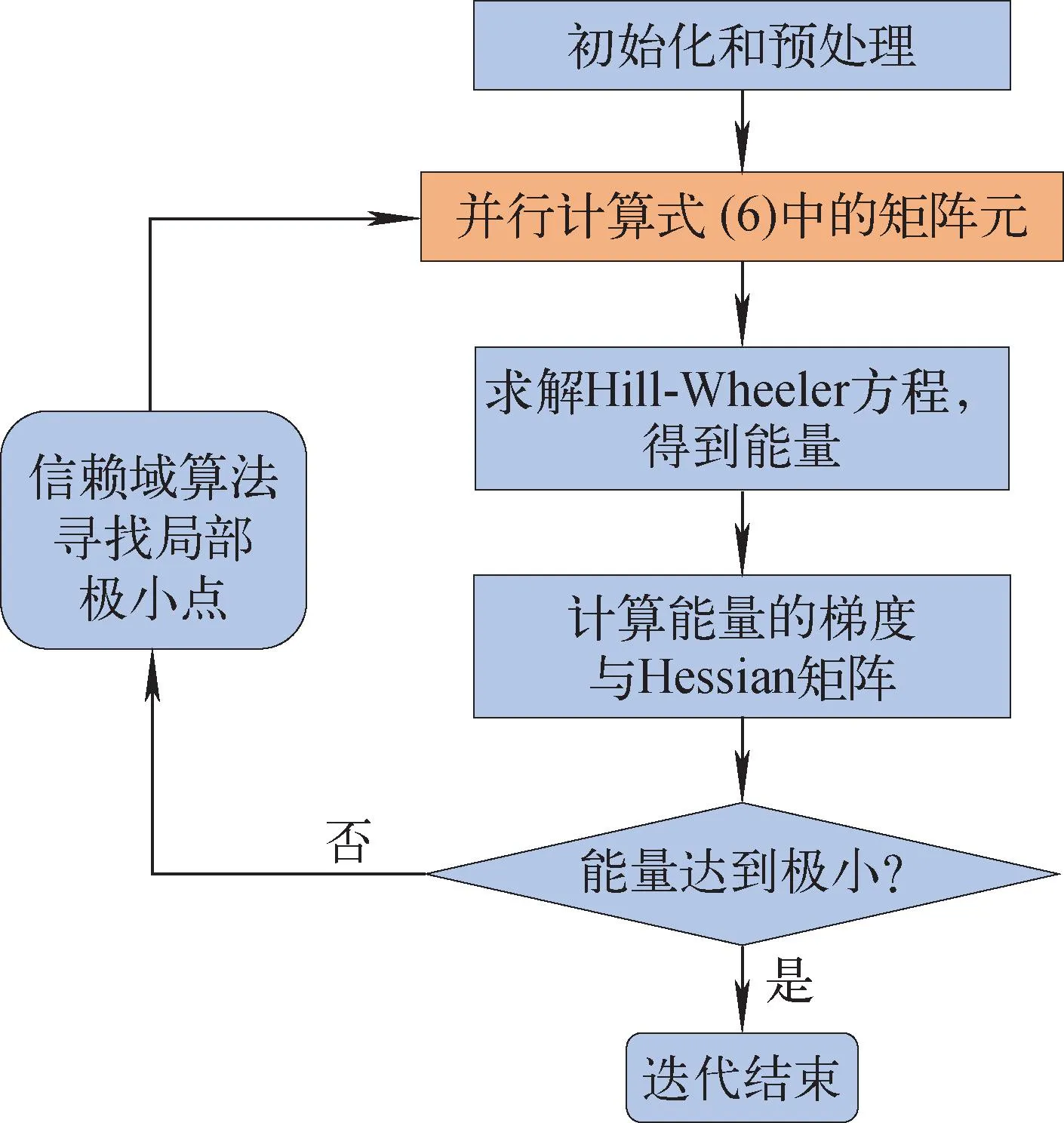
圖1 OpenACC版本VAP程序流程圖
3 GPU加速效果檢驗(yàn)
計(jì)算中選用的計(jì)算平臺(tái)為DELL PowerEdge T640服務(wù)器,每臺(tái)服務(wù)器同時(shí)搭載2顆Intel(R) Xeon(R) Gold 6148 CPU(20核|2.40 GHz) 和1顆英偉達(dá)公司生產(chǎn)的Tesla V100 GPU。
為檢驗(yàn)經(jīng)GPU移植后的VAP程序的正確性,從同一SD出發(fā),分別用原來(lái)經(jīng)過(guò)檢驗(yàn)的OpenMP并行程序和新的OpenACC并行程序在sd殼對(duì)24MgJπ=0+、2+、4+、6+的低自旋態(tài)開展了完整的VAP計(jì)算。計(jì)算中所用的哈密頓量為USDB有效相互作用[16]。圖2給出了兩種情況下VAP能量隨迭代步數(shù)的變化。對(duì)于計(jì)算的所有自旋態(tài),OpenACC并行程序每步得到的VAP能量與OpenMP并行程序得到的結(jié)果在計(jì)算機(jī)誤差范圍內(nèi)完全一致。變分達(dá)到收斂所需要的迭代步數(shù)也完全相同。這證明經(jīng)GPU移植后得到的OpenACC并行程序的正確性。
為進(jìn)一步對(duì)比原來(lái)OpenMP并行程序和新的OpenACC并行程序的加速效果,分別計(jì)算VAP程序在CPU串行(單核)、CPU并行(40 核)和GPU并行3種條件下的單步運(yùn)算時(shí)間。計(jì)算中只用1個(gè)SD,并固定迭代步數(shù)為10步。單步運(yùn)算時(shí)間定義為每次VAP迭代中計(jì)算式(6)的所有投影矩陣元平均需要花費(fèi)的時(shí)間。并行單步運(yùn)算時(shí)間與串行單步運(yùn)算時(shí)間的比值稱為加速倍數(shù)。
圖3給出了OpenMP并行程序和OpenACC并行程序在計(jì)算部分sd殼原子核基態(tài)時(shí)的加速倍數(shù)。從圖3可看出,經(jīng)并行后,VAP程序的運(yùn)算速度相比串行模式下有了較大的提升,且GPU并行的加速效果顯著優(yōu)于CPU并行。對(duì)于28Si,GPU并行的加速倍數(shù)達(dá)到了接近50倍,而CPU并行的加速倍數(shù)只有不到11倍。此外,無(wú)論是采用CPU并行還是GPU并行,其加速倍數(shù)均隨價(jià)粒子數(shù)的增多而增大。不同的是,GPU并行的加速倍數(shù)的增長(zhǎng)速度明顯高于CPU并行。從23Na到28Si,GPU并行的加速倍數(shù)增大了1.2倍,而CPU并行的加速倍數(shù)只增長(zhǎng)了53%左右。這主要是因?yàn)閟d殼模型空間較小,并不足以讓GPU核心得到充分利用。這一點(diǎn)也直接體現(xiàn)在VAP程序執(zhí)行過(guò)程中的GPU核心占用率上。如在計(jì)算23Na時(shí),GPU核心的占用率約60%,這意味著僅60%的GPU核心得到了利用。而在計(jì)算28Si時(shí),這一數(shù)字達(dá)90%。因此可預(yù)見,隨著模型空間的增大和價(jià)粒子數(shù)目的增加,GPU并行的加速效果仍有望得到進(jìn)一步提升,直至核心占用率達(dá)到100%。

圖3 CPU并行與GPU并行加速倍數(shù)隨不同原子核的變化
為進(jìn)一步測(cè)試GPU并行的加速效果和驗(yàn)證經(jīng)GPU加速后的VAP程序在中重核區(qū)的適用性,在相同的平臺(tái)下對(duì)64Ge的基態(tài)開展了完整的VAP計(jì)算。采用fpg9/2模型空間,fpg9/2模型空間包含30條中子軌道和30條質(zhì)子軌道。在此模型空間中,64Ge的組態(tài)空間維度達(dá)1.7×1014,較組態(tài)相互作用殼模型目前能解決的范圍高出3個(gè)數(shù)量級(jí)。在本次計(jì)算中仍然采用1個(gè)SD。在此情況下,GPU核心占用率達(dá)到了100%,加速倍數(shù)更是高達(dá)192倍。與CPU并行(40核)相比,單步運(yùn)算時(shí)間從原來(lái)的75 min降到了9 min。
最后,作為一大規(guī)模殼模型計(jì)算應(yīng)用實(shí)例,利用OpenACC并行程序?qū)ο⊥羺^(qū)重核178Hf的基帶開展了計(jì)算。178Hf所處的jj56pn模型空間包含32條質(zhì)子軌道和44條中子軌道。在此模型空間中,178Hf的組態(tài)空間維度達(dá)到了1.9×1018,較傳統(tǒng)的嚴(yán)格對(duì)角化方法的處理極限高7個(gè)數(shù)量級(jí)。處理如此大維度的計(jì)算問(wèn)題,原來(lái)的OpenMP程序迭代1次需花費(fèi)超過(guò)1 d的時(shí)間,而經(jīng)過(guò)GPU加速的OpenACC并行程序迭代1次只需1.5 h左右。
圖4給出了采用一個(gè)SD進(jìn)行VAP計(jì)算得到的178Hf基帶能譜。計(jì)算采用的相互作用為jj56pnb有效相互作用[17],實(shí)驗(yàn)數(shù)據(jù)取自文獻(xiàn)[18]。從圖4可看出,通過(guò)VAP計(jì)算得到的178Hf基帶能譜與實(shí)驗(yàn)值符合得很好,對(duì)應(yīng)能級(jí)之間的能量差最大不超過(guò)400 keV。

圖4 178Hf基帶能譜
4 總結(jié)與展望
VAP方法作為一種重要的殼模型近似方法,有望在較大模型空間中實(shí)現(xiàn)對(duì)中重核區(qū)原子核的計(jì)算。但在向中重核區(qū)推進(jìn)的過(guò)程中,隨著模型空間的增大以及價(jià)核子數(shù)的增多,VAP需計(jì)算的投影矩陣元的數(shù)目會(huì)迅速增加,極其耗費(fèi)計(jì)算時(shí)間。由于投影矩陣元之間彼此是相互獨(dú)立的,因此,VAP計(jì)算可通過(guò)并行化處理以提高計(jì)算效率。隨著近年來(lái)高性能GPU計(jì)算平臺(tái)的迅速發(fā)展,相較于原來(lái)在CPU平臺(tái)上采用OpenMP并行化程序進(jìn)行VAP計(jì)算,在高性能GPU平臺(tái)上采用OpenACC并行化模型進(jìn)行計(jì)算有望進(jìn)一步提升計(jì)算效率。通過(guò)將VAP程序采用OpenACC并行化模型改造,在角動(dòng)量投影的每個(gè)積分格點(diǎn)上,實(shí)現(xiàn)了數(shù)目龐大的各獨(dú)立轉(zhuǎn)動(dòng)矩陣元的GPU并行化計(jì)算。經(jīng)驗(yàn)證,GPU加速后的VAP程序與原來(lái)的OpenMP并行化程序相比,計(jì)算效率進(jìn)一步提升了數(shù)倍。且隨著往重核區(qū)的推進(jìn),提升倍數(shù)會(huì)進(jìn)一步增加。采用改造后的程序,首次實(shí)現(xiàn)了稀土區(qū)重核178Hf的基帶能譜的計(jì)算。目前,VAP程序只是在1塊GPU內(nèi)進(jìn)行了加速,其計(jì)算效率即得到顯著提升。可預(yù)見,若采用多塊GPU同時(shí)對(duì)VAP程序進(jìn)行加速,將會(huì)進(jìn)一步提升VAP的計(jì)算效率,使得VAP計(jì)算更易往重核區(qū)推進(jìn)。這一工作將會(huì)在未來(lái)展開。
GPU加速的VAP計(jì)算程序首次具備了在GPU服務(wù)器單機(jī)開展重核區(qū)計(jì)算的能力,不僅節(jié)省了大量的能耗,同時(shí)為系統(tǒng)研究中重質(zhì)量核區(qū)復(fù)雜原子核結(jié)構(gòu)問(wèn)題提供了極大的便利。過(guò)去,重質(zhì)量原子核的大規(guī)模殼模型計(jì)算即使在超級(jí)計(jì)算機(jī)集群上也難以開展起來(lái),對(duì)重質(zhì)量原子核結(jié)構(gòu)的系統(tǒng)研究普遍缺乏微觀的殼模型基礎(chǔ)。目前對(duì)于許多復(fù)雜核結(jié)構(gòu)現(xiàn)象的理解還處于比較模糊的認(rèn)識(shí)階段,如γ振動(dòng)帶與β振動(dòng)帶的同時(shí)描述,復(fù)雜的奇A核與奇奇核八極轉(zhuǎn)動(dòng)帶,超形變帶的帶間躍遷等。對(duì)這些現(xiàn)象的深入理解必須借助于可靠的微觀殼模型方法。本文建立的VAP殼模型計(jì)算將有望在這些問(wèn)題上發(fā)揮其獨(dú)特作用。
猜你喜歡
童話王國(guó)·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2020年10期)2020-11-26 08:24:50
數(shù)學(xué)物理學(xué)報(bào)(2020年2期)2020-06-02 11:29:24
人大建設(shè)(2019年12期)2019-05-21 02:55:44
中山大學(xué)法律評(píng)論(2018年1期)2018-03-30 01:21:00
瞭望東方周刊(2017年42期)2017-12-05 18:49:38
環(huán)球時(shí)報(bào)(2017-03-30)2017-03-30 06:44:45
光學(xué)精密工程(2016年6期)2016-11-07 09:07:19
中國(guó)衛(wèi)生(2015年3期)2015-11-19 02:53:32
核科學(xué)與工程(2015年4期)2015-09-26 11:59:03
