大型語言模型:原理、實現與發展
2024-02-20 08:21:54舒文韜李睿瀟孫天祥黃萱菁邱錫鵬
計算機研究與發展 2024年2期
舒文韜 李睿瀟 孫天祥 黃萱菁 邱錫鵬
(復旦大學計算機科學技術學院 上海 200433)
(wtshu20@fudan.edu.cn)
語言模型(language model, LM),也稱為統計語言模型(statistical language model),意在建模自然語言的概率分布,并估計任意語言序列的概率. 語言模型可以充分利用互聯網上大規模無標注語料作為訓練數據,并廣泛應用于機器翻譯、語音識別等任務. 隨著深度學習算法和算力的迅速發展,研究人員發現,語言模型的表現可以隨著模型參數量和訓練數據的增長而持續提升[1],并對自然語言處理領域中的諸多任務,例如文本分類、命名實體識別、詞性標注等有顯著提升. 因此,近年來語言模型,特別是大型語言模型(large language model, LLM)逐漸成為自然語言處理領域發展的主流,甚至展現出通向通用人工智能的潛能.
本文主要圍繞大型語言模型的基本定義、發展路徑、能力涌現和發展前景等4 個方面展開討論:
1) 基本定義. 闡述了語言模型的基本定義和發展,從模型表現和算力需求的角度提供了“大型”語言模型的界定標準.
2) 發展路徑. 從數據、算法、模型3 個維度回顧了語言模型的發展歷程和重要工作,闡述了大型語言模型的規模定律,總結了近年來語言模型的發展規律.
3) 能力涌現. 闡述了大型語言模型的能力涌現現象及可能的解釋,重點介紹了情景學習、思維鏈和指令遵循3 種關鍵涌現能力的有關研究和應用領域.
4) 發展前景. 總結了大型語言模型在不同領域的技術發展方向和未來應用前景,闡述并分析了大型語言模型未來研究所面臨的諸多技術挑戰.
本文就大型語言模型的關鍵研究要素和主要技術問題進行了回顧和綜述,以幫助讀者深入了解這一領域的最新發展及未來展望.
1 大型語言模型的定義
1.1 語言模型
語言模型的目標在于建模自然語言的概率分布.具體地,語言模型可以通過多種方式實現,例如ngram 語言模型[2]將自然語言序列建模為馬爾可夫過程(Markov process)從而簡化自然語言的概率建模難度. 目前被廣泛使用的語言模型通常采用自左向右逐個預測單詞的方式訓練得到,即:
其中w0為起始符,wT為結束符. 在訓練完成后,語言模型可以自回歸(auto-regressive)地自左向右生成文本.
顯然,由于自然語言的歧義性和句法的模糊性,通過上述方式建模自然語言的概率相當困難,需要參數化模型Pθ具有極大的容量. 因此,目前的語言模型普遍采用Transformer 模型架構[3],它通過注意力機制建模,輸入文本中的長距離語義依賴,具有優秀的規模化能力和并行化計算能力[4].
1.2 大型語言模型的界定標準
雖然大型語言模型的概念已經深入人心,但目前尚無明確的界定標準來判斷多大參數規模的語言模型才算作“大型”語言模型. 一方面,“大型”語言模型應當具備某些“小型”語言模型不具備的能力;另一方面,大型語言模型的界定標準也隨著算力的發展而變化,例如許多在今天看來規模不大的語言模型在五年前就可以算作大型語言模型. 本節我們從模型表現和算力需求的角度討論大型語言模型的界定標準.
1)模型表現. 隨著模型參數量的增長,研究人員發現許多過去性能處于隨機水平的任務取得了顯著提升. 我們將這類隨著模型參數規模增長而迅速習得的能力稱為大型語言模型的涌現能力(emergent abilities)[5]. 在不同的任務上觀測到涌現能力所需的參數量差異極大,目前仍然有大量困難任務未觀測到模型性能的涌現. 在目前受關注較多的大模型評測任務中,最小的涌現能力所需的參數量約為百億左右,例如毒性分類能力的涌現所需的參數量約為71 億,3 位數加減能力的涌現所需參數量約為130億[5]. 因此,從模型表現的角度,把百億參數規模作為大型語言模型的界定標準是較為合適的.
2)算力需求. 訓練大型語言模型的算力需求應當略微超過當前廣泛可得的硬件條件. 以當前較流行的單臺配備了8 張消費級顯卡NVIDIA 3090 GPU的服務器測算,使用ZeRO 模型并行計算方案[6]和Adam優化器[7],能夠啟動訓練的模型規模約為百億參數.因此,從算力需求的角度,超過百億參數的語言模型可以被認為是常規計算資源難以完成訓練的大型語言模型.
綜上,不管從模型表現還是算力需求的角度,百億參數量都是一個較為合適的大型語言模型的界定標準. 值得注意的是,參數量并不是界定大型語言模型的唯一標準,模型架構、訓練數據量、訓練所需FLOPs 等也是衡量大型語言模型的重要因素[8]. 例如,一個包含千億參數但訓練嚴重不充分的語言模型也難以被認為是一般意義上的大型語言模型. 考慮到大規模語言模型訓練成本高昂以及人們對語言模型規模定律(scaling law)[1]的認識,目前絕大多數大型語言模型都具備與其參數量相匹配的模型配置和訓練數據,因而以參數量作為大型語言模型的界定標準是一種較為方便且合理的做法.
1.3 大型語言模型介紹
自GPT-3[9]問世以來,國內外多家機構加大對大型語言模型的研發投入,近3 年來涌現了一批具有競爭力的大型語言模型. 目前已有的大型語言模型總體呈現出以工業界投入為主,以英文為主,以及以閉源為主等特點. 表1 中列舉了當前常見大型語言模型的基本信息.
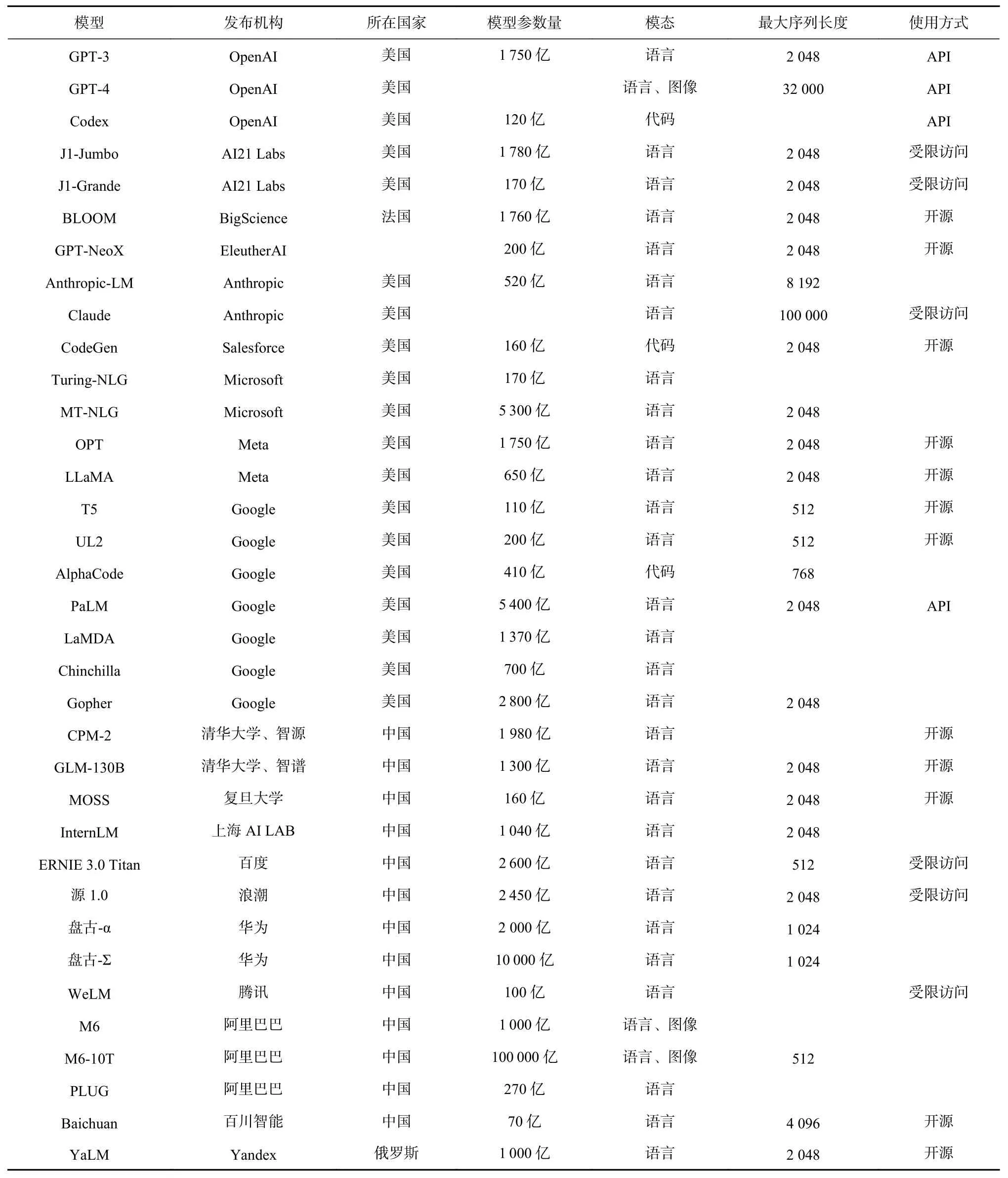
Table 1 Comparison of Existing Large Language Models表1 已有大型語言模型對比
2 大型語言模型的發展路徑
語言模型本是自然語言處理領域中的一個分支任務,近年來研究人員發現訓練一個好的語言模型對提升諸多自然語言處理任務,例如情感分析、文本分類、序列標注等的性能具有顯著幫助,因而其重要性逐漸得到重視,成為如今自然語言處理領域的發展主流.
歷史上,語言模型有許多變種,例如將自然語言序列預測假設為馬爾可夫過程(Markov process)的n-gram 語言模型、最大熵(maximum entropy)語言模型等. 在本文中,我們僅考慮當下流行的通過預測下一個單詞訓練得到的語言模型及其簡單變體,例如word2vec 模型[10],這類模型的訓練任務可以概括為Pθ(wt|context),其中Pθ通常通過神經網絡來建模,context可以是單詞wt之前的文本w0,w1,…,wt?1(如GPT 模型[11]),也可以是單詞wt的上下文w0,w1,…,wt?1,wt+1,…,wT(如BERT 模型[12]),還可以是單詞wt的周圍一定窗口范圍的詞wt?k,wt?k+1,…,wt?1,wt+1,…,wt+k(如word2vec CBOW 模型[10]).
圖1 展示了語言模型的主要發展路徑:2008 年,Collobert 等人[13]發現將語言模型作為輔助任務預先訓練,可以顯著提升各個下游任務上的性能,初步展示了語言模型的通用性;2013 年,Mikolov 等人[10]在更大語料上進行語言模型預訓練得到一組詞向量,接著通過遷移學習的手段,以預訓練得到的詞向量作為初始化,使用下游任務來訓練任務特定模型;2018 年,Google 公司的Devlin 等人[12]將預訓練參數從詞向量擴增到整個模型,同時采用Transformer 架構作為骨干模型,顯著增大了模型容量,在諸多自然語言處理任務上僅需少量微調即可取得很好的效果;隨后,研究人員繼續擴增模型參數規模和訓練數據量,同時采取一系列對齊算法使得語言模型具備更高的易用性、忠誠性、無害性,在許多場景下展現出極強的通用能力,OpenAI 于2022 年底發布的ChatGPT以及2023 年發布的GPT-4[14]是其中的代表. 縱觀近十余年來語言模型的發展歷程,不難發現2 個規律:
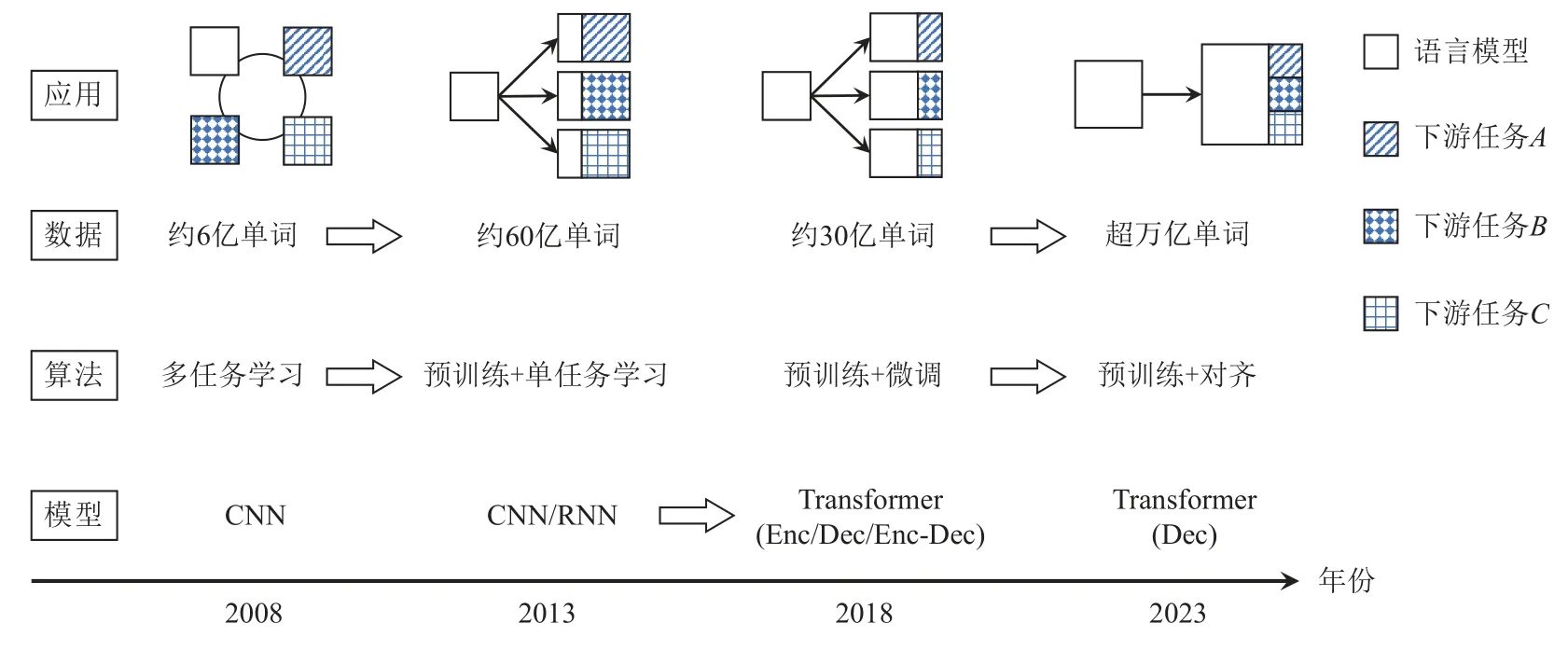
Fig. 1 Development path of language models圖1 語言模型發展路徑
1)以語言模型及其變體為訓練任務,從多個維度實現規模化. 從2008 年至今,語言模型的訓練任務變化很小,而其訓練數據逐漸從6 億單詞增長到如今的超萬億單詞,算法從傳統的多任務學習范式發展到更適合大規模預訓練的遷移學習范式,模型從容量較小的CNN/RNN 模型發展為包含超過千億參數的Transformer 模型.
2)將更多模型參數和訓練任務從下游轉移到上游. 從模型參數的角度,2013 年以前的大多數模型要從頭訓練(training from scratch)所有參數;2013~2018年主要基于預訓練的詞向量訓練參數隨機初始化的任務特定模型;2018~2020 年逐漸轉向“預訓練+微調”范式,即使用預訓練模型作為下游任務初始化,僅需添加少量任務特定參數,例如在預訓練模型上添加一個隨機初始化的線性分類器;2020 年前后,基于提示(prompt)的方法得到了很大發展,通常直接使用包括語言模型分類頭(language modeling head)在內的整個預訓練語言模型,通過調整其輸入內容來得到任務特定輸出. 從訓練任務的角度,語言模型從與其他下游任務聯合多任務訓練逐漸發展成為獨立的上游任務,通過數據、模型、算法等多個維度的規模化逐漸降低對下游任務訓練的需求,近年來的大型語言模型通常在已有的上千個指令化自然語言處理任務(例如FLAN[15])上訓練,從而可以在未經下游任務訓練的情況下很好地泛化到未見任務上.
下面我們分別從數據、算法、模型3 個維度闡述語言模型的發展路徑.
2.1 數 據
由于語言模型直接對文本的數據分布進行建模,無需人工標注,因此可以充分利用互聯網上海量的文本數據. 2008 年Collobert 等人[13]構造的語言模型訓練在來自維基百科的約6.3 億單詞上進行訓練;2013 年Mikolov 等人[10]提出的word2vec 在包含約60億單詞的Google News 語料上進行詞向量預訓練;2018 年發布的BERT 在約8 億個單詞的BooksCorpus和約25 億個單詞的英文維基百科,共約33 億個單詞上進行預訓練,雖然訓練數據量較更早的word2vec有所下降,但由于其所采用的Transformer 模型參數量大幅度增加,訓練成本和效果均顯著提升[12];2023年的最新語言模型,例如GPT-4 和LLaMA[16],通常在超過萬億個語言單詞上進行預訓練.
隨著預訓練模型的規模化,維基百科、Books-Corpus 等高質量語料的規模和多樣性逐漸無法滿足訓練需求,因而研究人員開始尋找更加廣泛的數據來源,例如CommonCrawl,Github,ArXiv 等,而這些數據質量和格式參差不齊,通常需要細粒度去重、低質量文本過濾、格式處理等繁雜的數據清洗步驟才能用于模型訓練. 此外,互聯網語料中還存在大量包含歧視性、刻板印象、事實性錯誤的文本,若用于訓練將顯著影響模型性能,導致模型產生帶有毒性或幻覺的輸出.
除預訓練數據外,帶標簽的特定任務數據仍然具有極高的利用價值. 研究人員發現,為已有的大量自然語言處理任務編寫描述指令并在大量此類指令化數據集上訓練后,語言模型可以很好地根據輸入的任務描述指令完成訓練階段未見過的任務. 為了增強語言模型的易用性、誠實性、安全性,通常還需要少量對齊數據進行訓練,該部分數據通常包括人工編寫的指令及其回復和對模型回復的偏好數據,前者與指令化任務數據類似,但通常具有更高的多樣性,用于語言模型的監督微調;后者通常體現為多條模型回復的排序或兩兩比較結果,用于訓練偏好模型(也稱為反饋模型). 此外,模型部署后收集的真實用戶數據也常常作為對齊數據的一部分,用于訓練偏好模型和調優語言模型. 通過對齊數據,語言模型可以與人類世界價值觀進行對齊,顯著降低模型毒性和幻覺問題. 最近一段時間,使用ChatGPT 等能力較強的語言模型生成的合成數據因其獲取成本低、數據質量高等優勢得到了廣泛應用,基于合成數據訓練得到的語言模型取得了不俗的性能. 相較于人工標注的數據,合成數據的質量評估、潛在風險,以及更加多樣的生成方法仍然需要大量研究工作.
2.2 算 法
在學習算法上,語言模型的發展大致經歷了4 個階段:
1) 多任務學習. 這一階段的語言模型通常作為學習過程中一個可選的輔助任務,通過在少量無標簽數據上訓練語言模型任務來增益其他下游任務性能.
2) 預訓練+單任務學習. 隨著語言模型任務的重要性受到越來越多的關注,研究人員開始在大規模無標注語料上預先訓練一組詞向量[10],以此作為下游任務中模型詞向量的初始化,使用任務特定數據訓練模型參數. 其中詞向量可以繼續使用任務數據微調也可以保持不變而僅訓練模型其余部分參數.該階段中單任務學習仍然是一個需要精心設計的環節,研究人員需要針對任務特性選擇合適的模型結構和訓練方法.
3) 預訓練+微調. 雖然通過語言模型任務預訓練詞向量的方式取得了巨大成功,但預訓練詞向量存在固有的缺陷:難以處理一詞多義問題,例如“蘋果”一詞既可以指蘋果這一水果,也可以指蘋果公司. 一種卓有成效的解決方案就是將模型與詞向量一同進行預訓練,由此可以得到某個單詞在特定語境下的表示,例如,通過預訓練模型編碼后,蘋果一詞在“蘋果很好吃”和“蘋果手機很好用”2 種不同語境下得到完全不同的表示. Peters 等人[17]首先使用LSTM 模型證明了這一做法的有效性,BERT,GPT 等模型則采用容量更大、更適合并行計算的Transformer 模型.經過大規模參數預訓練之后,人們發現在下游任務上只需要對參數進行微調即可取得很好的效果.
4) 預訓練+對齊. 隨著訓練數據規模和模型參數規模的增長,研究人員發現保持模型參數不變而僅需調整模型輸入的提示就可以得到不錯的效果. 通過與人類對齊,包括使用自然語言指令化的任務數據訓練和基于人類反饋學習,大型語言模型可以顯著提高其易用性和安全性,用戶通過簡單的提示語即可得到期望的回復,實用性顯著增強. 此外,相比過去主要基于監督學習方式,在對齊階段還普遍引入了強化學習:首先訓練反饋模型建模人類反饋數據,接著使用該反饋模型通過強化學習手段提升語言模型性能,使其更加符合人類偏好.
2.3 模 型
過去的語言模型訓練常常基于卷積神經網絡(convolutional neural network, CNN)、循環神經網絡(recurrent neural network, RNN)及其變體,例如LSTM、GRU[18]等. 其中,CNN 具有優秀的并行計算能力,能夠處理較長的輸入序列,但其受限于感受野的大小,難以處理自然語言中廣泛存在的長距離依賴問題;RNN 及其變體將歷史序列信息選擇性地壓縮進隱狀態,據此預測下一個單詞,這一結構上的先驗非常符合自然語言序列的特點,因而在諸多自然語言處理任務上具有廣泛的應用. 然而,由于RNN 在訓練過程中對輸入序列中每個單詞的處理都依賴其前序計算結果,因而無法充分利用GPU 的并行計算能力[19].2017 年,Vaswani 等人[3]提出了Transformer 模型,使用注意力機制對輸入序列進行全局建模,能夠充分利用GPU 的并行計算能力,在機器翻譯任務上取得了成功. 隨后,Radford等人[11]和Devlin等人[12]使用Transformer 作為語言模型訓練的骨干模型,取得了突破性進展,從此Transformer 模型及其變體逐漸成為語言模型的主流.
2.4 規模定律
大型語言模型訓練難度大、訓練成本高,如果能夠根據已有小規模試驗來提前預測為達到某種性能水平需要多少參數量、數據量、計算量,則可以顯著降低大模型訓練試錯成本. 這種模型性能與參數量、數據量、計算量等變量的經驗關系就被稱為“規模定律”.
OpenAI 的Kaplan 等人[1]通過大量實驗表明這樣的規模定律是存在的,即語言模型的性能(通過損失函數值衡量)是可以被參數量、數據量、計算量等變量預測的. 具體地,他們發現語言模型的性能與3 個因素均呈現冪律關系:
其中L為損失函數值,X為參數量、數據量或計算量(FLOPs),Xc和 αX為與參數量、數據量或計算量相關的常量. 當參數量和數據量按比例增長時,語言模型的損失函數值是可以被預測的,具體地,在給定計算量情況下為達到語言模型最優性能,模型參數量每增長8 倍,訓練數據量應當增長5 倍. 此外,還發現:相比訓練數據和參數規模,模型的寬度和深度等超參數對性能影響相對較小;模型訓練曲線同樣遵循冪律變化,可以通過早期訓練曲線預測訓練時間較長時模型的損失函數值,且該冪律函數的參數與模型大小無關;相較于小模型,大模型需要更少的訓練步數和更少的訓練數據即可達到相同的性能水平.這些經驗規律大大降低了大型語言模型的試錯成本,對其后幾年大型語言模型的發展起到了重要指導作用.
然而,DeepMind 的Hoffmann 等人[20]在2022 年通過訓練參數量從7 千萬到160 億的超過400 個語言模型,給出了不同的規模定律:給定計算量情況下為達到語言模型最優性能,應當等比例增長訓練數據量和模型參數量. 按照這一規模定律訓練出的Chinchilla 模型包含700 億個參數,在包含約1.4 萬億單詞的語料上進行訓練,其在多任務理解評測基準MMLU 上的性能超越了2 800 億個參數的Gopher 和5 300 億個參數的MT-NLG,驗證了其規模定律的有效性. 2023 年Meta 推出的開源語言模型LLaMA 采用了類似的訓練配比,使用1.4 萬億個單詞訓練了650 億個參數,取得了與Chinchilla 可比的性能.
圖2 給出了當前常見的大型語言模型的參數量和訓練計算量,不難發現,較近的語言模型,如Chinchilla和LLaMA 通常采用相對較大的訓練數據和相對較小的參數規模,這在下游微調和推理部署時具有顯著的效率優勢.
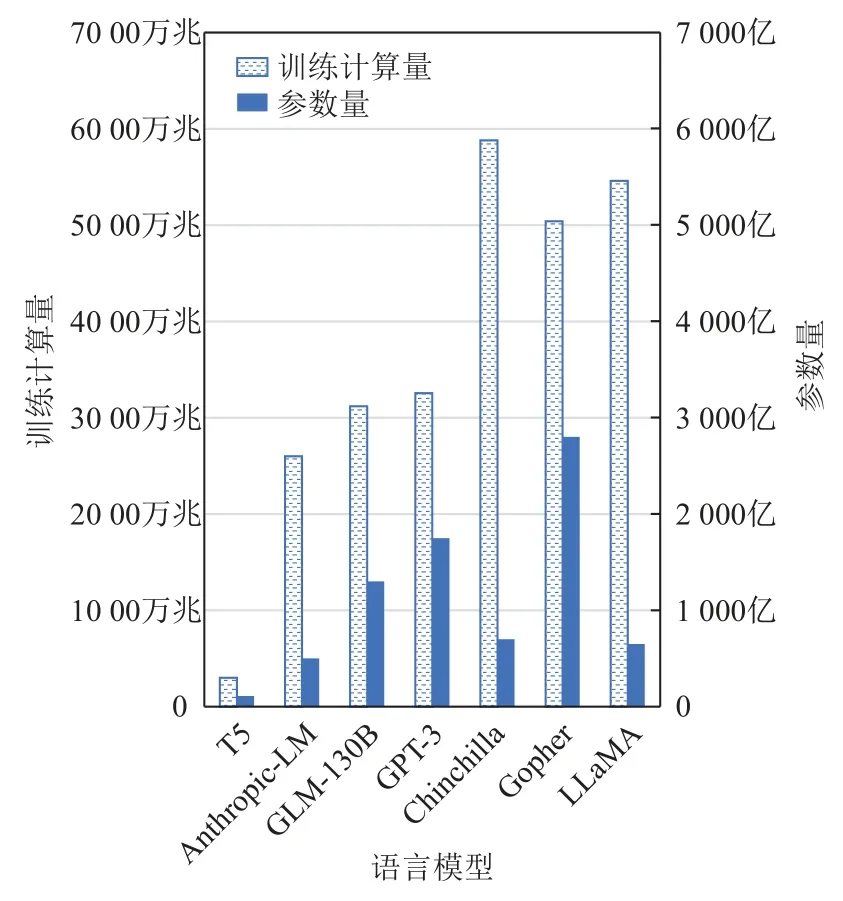
Fig. 2 Number of parameters and training FLOPs of common LLMs圖2 常見大型語言模型的參數量和訓練計算量
到目前為止,規模定律仍然是一個非常重要且值得探索的方向,特別是中文語言模型的規模定律尚未有公開研究. 此外,已有的對規模定律的研究主要為通過大量實驗得出的經驗性規律,而缺乏對其理論機理的解釋.
3 大型語言模型的涌現能力
規模定律展示了語言模型的性能可以隨著模型和數據規模可預測地增長,然而,當對應到具體任務時,研究人員發現并非所有任務上的性能都是隨著模型和數據規模平滑地、可預測地增長,其中很多任務上的表現是當模型和數據規模到達某個閾值后突然提升的. 這種較小規模模型不具備而大型語言模型具備的完成某些任務的能力就被稱為“涌現能力”. 例如,在少樣本提示設定下進行三位數加減任務時,當GPT-3 達到130 億個參數、2×1022計算量時準確率出現迅速提升,而在此之前模型準確率一直接近零. 值得注意的是,即使同一任務的涌現閾值也不是放之四海皆準的,而是與模型架構、訓練方法等因素有關聯,例如三位數加減任務對于LaMDA 則需要680 億個參數、1023計算量才能取得顯著提升[5].
目前,關于大型語言模型涌現能力的研究主要為實證研究,其背后的理論機理仍然有待探索. 不過,我們仍然可以從一些不同的視角來更好地理解大型語言模型的涌現能力. 例如,Wei 等人[5]發現當把一些表現出涌現現象的任務的性能衡量指標從粗粒度指標(如準確率)替換為細粒度指標(如模型預測與真實標簽的交叉熵)后,這些任務上的表現曲線不再呈現出相變性,而是可預測的平滑曲線. 然而,值得注意的是,并不是所有任務都能夠找到使其性能曲線變得平滑的衡量指標. 此外,Michaud 等人[21]提出了量子化模型(quantization model)來解釋語言模型的規模定律和涌現現象,他們假設模型的整體能力由許多量子化的能力組成,由于數據分布常常呈現Zipf 分布,因此這些量子化能力的習得曲線自然地符合冪律分布. 在實驗中他們觀測到單個量子化能力的習得是涌現的,即當模型參數規模達到某個閾值后在該能力相關單詞的預測上損失值迅速下降;而大多數單詞的預測需要多個不同的量子化能力,這些能力在不同的模型規模下涌現,因此宏觀表現為模型損失值隨著規模增加而平滑地下降. 這也為理解某些任務性能的涌現提供了一個視角,即解決某些較復雜任務所需的能力可以分解為多個子能力,只有當所有子能力均被習得才能解決原任務,因而在所有子能力均被習得后才能觀測到任務性能的迅速提升.
相比于較小規模語言模型,大型語言模型具備一些較為關鍵的涌現能力,大大加強了其在真實場景下的可用性,包括情景學習、思維鏈和指令學習.
3.1 情景學習
情景學習(in-context learning)[9]是指將一部分樣本及其標簽作為示例拼接在待預測樣本之前,大型語言模型能夠根據這小部分示例樣本習得如何執行該任務. 具體地,語言模型接受x1,y1,…,xk,yk,xquery為輸入,輸出xquery對應的標簽yquery. 相較于傳統的基于梯度更新的學習方式,情景學習無需更新模型參數即可學習輸入樣本中的模式,顯著降低了學習成本,使得“語言模型即服務(language-model-as-a-service,LMaaS)”[22]變得可行.
盡管情景學習與一般的機器學習過程差別甚大,例如情景學習中不存在顯式的學習算法和參數更新,但其輸入輸出形式又與機器學習相仿,即可以認為輸入中的{x1,y1,…,xk,yk}為訓練集,待預測的x’為測試樣本. 目前已有一些工作試圖建立情景學習與機器學習的聯系. Akyürek 等人[23]通過在線性回歸任務上的實驗發現,基于 Transformer 的語言模型在進行情景學習時能夠隱式地實現梯度下降,即示例樣本在輸入到語言模型后在前饋傳播過程中已經執行了與傳統機器學習類似的學習過程,從而能夠習得訓練集中的模式并給出測試樣本的預測結果. 同時,Dai 等人[24]通過分析Transformer 中的注意力計算與梯度下降計算的對偶關系,將語言模型解釋為元優化器(meta optimizer),并從多個角度展示了情景學習與傳統語言模型微調的相似性. 基于該觀察,他們還設計了一種帶有動量的注意力機制,提升了情景學習能力,這表明針對情景學習能力優化的模型架構研究仍有較大的探索空間. 值得注意的是,盡管已有不少研究從理論和實證的層面展示了情景學習與梯度下降的聯系,但情景學習的工作機理仍不完全明確,從優化的角度如何有效地提升語言模型情景學習的能力也是亟待探索的方向.
從應用的角度,已有不少研究探索了情景學習的特性以及提升語言模型情景學習能力的方法. 例如,Min 等人[25]發現情景學習的表現對特定上下文設置很敏感,包括提示模板、上下文示例的選擇與分布,以及示例的順序. 他們的實驗表明,示例樣本對性能的影響主要來自4 個方面:輸入-標簽的配對格式、標簽的分布、輸入的分布以及輸入-標簽的映射關系. Wei 等人[26]在 PaLM-540B 上得出了相反的結論,即錯誤的映射關系會顯著降低模型在二分類任務上的準確率,這表明大型語言模型以一種異于小模型的方式進行情景學習. Zhao 等人[27]發現,多數標簽和近因偏差也是導致情景學習結果出現偏見的重要因素:語言模型更加傾向于與示例中占據多數的答案保持一致,并且順序越靠后的示例樣本對預測結果的影響越大. 對此,他們設計了一種校準方法用于消除示例標簽及其位置分布可能導致的偏差.
目前,情景學習已經成為大型語言模型能力的重要評測方法. 例如在被廣泛用于大型語言模型評測的基準數據集MMLU 上,研究人員通常通過小樣本情景學習的方式評測語言模型的表現. 因此,情景學習作為大型語言模型的基礎能力之一,其理論機理和標準化應用方式是極為重要的研究方向.
3.2 思維鏈
思維鏈(chain-of-thought)[28]是提升大型語言模型推理能力的常見提示策略,它通過提示語言模型生成一系列中間推理步驟來顯著提升模型在復雜推理任務上的表現. 其中,最直接的提示語言模型生成思維鏈的方法就是通過情景學習,即對少量樣本{x1,y1,…,xk,yk}手工編寫其中間推理過程,形成{x1,t1,y1,…,xk,tk,yk,xquery}作為語言模型的輸入,使語言模型生成xquery對應的推理步驟和答案{tquery,yquery}. Kojima 等人[29]發現無需手工編寫示例樣本的推理步驟,僅需簡單的提示詞,例如“Let’s think step by step”即可使得語言模型生成中間推理過程及最終答案,這一提示策略稱為“零樣本思維鏈提示”.通過思維鏈方法可以顯著提升語言模型在常識問答、數學推理等任務上的性能. 隨后,研究人員提出了一些基于思維鏈提示方法的改進策略,例如Least-to-Most[30]、Self-consistency[31]、Diverse[32]等策略,通過這些策略可以進一步提升語言模型推理能力.
值得注意的是,在較小規模,如小于百億參數語言模型上應用思維鏈提示策略反而會降低其在推理任務上的準確率,這是由于較小的語言模型通常會生成通順但不合邏輯的思維鏈. 為了增強較小語言模型的思維鏈能力,一種被證明有效的做法是使用大型語言模型生成的思維鏈作為較小模型的訓練信號[33]. 然而,這種方式通常會降低較小語言模型的通用能力.
CoT 為何能提示激發 LLM 的推理能力尚未得到解釋. 有一種觀點認為在預訓練數據中加入代碼可以幫助 LLM 具備 CoT 推理能力,但不少實驗現象表明代碼預訓練和 CoT 推理能力并非完全掛鉤. 事實上,BLOOM-176B[34]在預訓練過程中加入了大量GitHub 代碼,但并未展現出 CoT 推理能力;與之對應的是沒有經過大量代碼預訓練的 UnifiedQA[33,35]和微軟 KOSMOS[36-37],表現出了較好的 CoT 乃至多模態CoT 推理能力.
3.3 指令遵循
指令遵循(instruction-following)能力是指語言模型根據用戶輸入的自然語言指令執行特定任務的能力. 相較情景學習需要通過少量示例樣本提示語言模型執行特定任務,指令遵循的方式更為直接高效.然而,指令遵循能力通常需要語言模型在指令數據集上進行訓練而獲得. 一種直接的構造指令數據集的手段是為已有的大量自然語言處理任務數據集編寫自然語言指令,這種指令可以是對任務的描述,還可以包含少量示例樣本. 研究人員發現,在大量指令化的自然語言處理任務數據集上訓練后,語言模型可以根據用戶輸入的指令較好地完成未見任務.
然而,雖然已有的自然語言處理任務數據質量較高,但其多樣性難以覆蓋真實場景下用戶的需求.為此,InstructGPT[38]和ChatGPT 采用人工標注的指令數據,具有更高的多樣性且更加符合真實用戶需求.隨著大型語言模型能力越來越強,研究人員發現可以通過編寫少量種子指令(seed instruction)來提示語言模型生成大量高質量、多樣化的指令數據集[39]. 近年來,使用較強的大型語言模型的輸出來訓練較小規模語言模型已經成為一種被廣泛使用的方法,通過這種方式可以較容易地使得較小語言模型具備基本的指令遵循能力[40-41]. 然而,這種通過蒸餾獲得的較小語言模型仍難以具備復雜指令遵循能力,且仍然存在嚴重的幻覺問題.
4 未來發展與挑戰
以ChatGPT、GPT-4 為代表的大型語言模型已經在社會各界引起了很大反響,其中GPT-4 已經具備通用人工智能的雛形. 一方面,大型語言模型的強大能力向人們展現了其廣闊的研究和應用空間;而另一方面,這類模型的快速發展也帶來了許多挑戰和應用風險.
雖然通過簡單的規模化,大型語言模型已經取得了令人印象深刻的效果,但其仍有巨大的改進和擴展空間.
1) 高效大型語言模型. 當前大型語言模型主要采用Transformer 架構,能夠充分利用GPU 的并行計算能力并取得不俗的性能表現. 但由于其計算和存儲復雜度與輸入文本長度呈平方關系,因此存在推理效率慢、難以處理長文本輸入等缺陷. 對此,研究人員從稀疏注意力機制[42]、高效記憶模塊[43]、新型架構[44]等角度探索計算高效的大型語言模型. 然而,已有高效模型架構的工作尚未在大規模參數量下進行驗證,高效架構在大規模語言模型預訓練下的表現及其改進是未來大型語言模型的重要發展方向.
2) 插件增強的語言模型. 集成功能插件已經成為大型語言模型快速獲得新能力的重要手段[45]. 例如,通過集成搜索引擎可以允許模型訪問互聯網實時信息,通過集成計算器可以幫助模型更精確地執行數學推理,通過集成專業數據庫可以使得模型具備專業知識問答能力. 因此,如何通過訓練或者提示的手段增強大型語言模型使用第三方插件甚至發明新插件的能力,如何使得模型能夠根據插件反饋改進自身行為,最終解決較復雜推理問題成為飽受關注的研究方向. 此外,插件開發與模型能力的協同演化和生態建設也是值得重視、多方共建的重要議題.
3) 實時交互學習. 目前語言模型仍以靜態方式提供服務,即僅根據用戶指令生成對應回復而無法實時動態更新自身知識,使得語言模型能夠在與用戶交互過程中完成實時學習,特別是能夠根據用戶輸入的自然語言指令更新自身知識,是邁向通用人工智能的重要步驟. 目前元學習、記憶網絡、模型編輯等領域的進展初步揭示了該方向的可行性,但面向大規模輸入和參數的高效實時學習仍然是極重要與具有挑戰性的研究方向.
4) 語言模型驅動的具身智能. 具身智能與物理世界交互并在環境中完成任務的智能,意味著智能從被動觀察學習到探索真實環境、影響真實環境的轉變. 語言模型擁有相當的世界知識儲備和一定的邏輯推理、因果建模和長期規劃等高級認知功能,因而被廣泛用于具身任務,并參與環境理解、任務理解、任務序列生成與分發等諸多環節. 通過多模態深度融合、強化邏輯推理與計劃能力等手段,打造具備強大認知智能的具身系統正在成為大型語言模型和機器人領域的研究熱點.
大型語言模型能力的迅速增長也對其落地應用帶來了許多風險與挑戰.
1) 檢測. 大型語言模型生成的文本高度復雜甚至相當精致,在很多場景下難以與人類創作的文本區分開. 這引發了對語言模型生成文本濫用的擔憂,例如虛假文本生成在醫學、法律、教育等領域的濫用可能導致巨大的隱患. 因而,語言模型生成文本的檢測和監管成為亟待解決的問題,而現有的文本檢測技術或模型水印等技術尚不能完全可靠地判斷一段文本是否為模型生成. 從數據、訓練、推理、產品等全鏈路進行設計和監管以提高模型生成文本的檢測準確率,是確保大型語言模型不被濫用的重要條件.
2) 安全性. 大型語言模型的訓練數據大量來自互聯網上未經標注的文本,因而不可避免地引入了有害、不實或歧視性內容. 此外,蓄意攻擊者也可利用提示詞注入等手段欺騙模型產生錯誤的輸出,從而干擾系統運行、傳播虛假信息或進行其他非法活動[46]. 盡管當前已經可以通過清洗訓練數據、強化學習與社會價值觀進行對齊等途徑顯著提升語言模型應用的安全性,但實際使用時安全性隱患仍層出不窮. 如何構造適合中文環境的安全性評估標準及其相應的訓練數據仍然是中文語言模型大規模落地應用的重要挑戰.
3) 幻覺. 目前ChatGPT 和GPT-4 等高性能語言模型仍然存在較嚴重的幻覺問題,即經常生成包含事實性錯誤、似是而非的文本,這嚴重影響了其在部分專業領域應用的可靠性. 盡管通過接入搜索引擎、使用基于人類反饋的強化學習等手段可以顯著降低模型生成的幻覺,但由于語言模型的黑箱性,有效識別模型的內部知識和能力邊界仍舊是極具挑戰性的未解難題.
總之,大型語言模型給自然語言處理乃至人工智能領域帶來了巨大的范式變革,將原來按不同任務進行橫向劃分的領域設定轉變為按流程階段進行縱向劃分的新型研究分工,并構建了以大型語言模型為中心的人工智能新生態.
作者貢獻聲明:舒文韜和李睿瀟完成論文的撰寫;孫天祥列舉提綱,并校改論文;黃萱菁和邱錫鵬提出指導意見.
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
發明與創新(2022年30期)2022-10-03 08:40:56
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
文苑(2020年4期)2020-05-30 12:35:30
人大建設(2018年6期)2018-08-16 07:23:10
小學生作文(中高年級適用)(2018年3期)2018-04-18 01:24:47
文理導航·科普童話(2017年5期)2018-02-10 19:42:14
華北電力大學學報(社會科學版)(2016年4期)2016-12-01 03:59:30
光學精密工程(2016年6期)2016-11-07 09:07:19
