一種基于芯片片內(nèi)總線的DMA 控制器芯片的設(shè)計(jì)與驗(yàn)證*
2024-02-17 12:52:08蘇興,劉威,2,3,4
電子技術(shù)應(yīng)用 2024年1期
關(guān)鍵詞:信號(hào)
蘇 興,劉 威,2,3,4
(1.武漢大學(xué) 物理科學(xué)與技術(shù)學(xué)院,湖北 武漢 430072;2.武漢大學(xué) 微電子學(xué)院,湖北 武漢 430072;3.湖北珞珈實(shí)驗(yàn)室,湖北 武漢 430072;4.武漢量子技術(shù)研究院,湖北 武漢 430072)
0 引言
隨著微電子領(lǐng)域技術(shù)的迅速發(fā)展,IC 已進(jìn)入片上系統(tǒng)(System on Chip),即SoC 時(shí)代。片內(nèi)總線(Internal Chip Bus)作為IC 系統(tǒng)的連接部件,用于把各個(gè)模塊聯(lián)系起來(lái),從而解決整個(gè)集成電路內(nèi)部間的互相通信問(wèn)題[1]。
在現(xiàn)有的眾多片內(nèi)總線中,由ARM 公司研發(fā)推出的一種高級(jí)微控制器總線架構(gòu)AMBA (Advanced Microcontroller Bus Architecture)因自身特點(diǎn)深受研究人員和市場(chǎng)開(kāi)發(fā)商的喜愛(ài)。在AMBA3.0 版本中,定義4 種接口類型[2],其中AHB 總線因自身兼容性強(qiáng)、擴(kuò)展性高,設(shè)計(jì)簡(jiǎn)單等優(yōu)勢(shì)而廣泛用于各類高級(jí)系統(tǒng)結(jié)構(gòu)中[3],AXI 總線規(guī)范主要描述了IP 核之間的信息交互[4]。
為了結(jié)合AXI 總線和AHB 總線各自優(yōu)點(diǎn),得到一種具有高速性及易用性的總線協(xié)議,市場(chǎng)上又出現(xiàn)了一種新的自定義片內(nèi)總線協(xié)議ICB(Internal Chip Bus)。ICB 總線結(jié)構(gòu)如圖1 所示。它具有如下特性:更加簡(jiǎn)單的協(xié)議控制,兩個(gè)獨(dú)立通道,讀寫操作共用的地址通道,共用結(jié)果返回通道;同時(shí),與AXI 總線一樣,采用分離的地址階段和數(shù)據(jù)階段;采用地址區(qū)間尋址,支持任意主從數(shù)目拓?fù)浣Y(jié)構(gòu)。每個(gè)讀寫操作都會(huì)在地址通道上產(chǎn)生地址,而不是像AXI 總線只產(chǎn)生起始地址;協(xié)議非常簡(jiǎn)單,易于轉(zhuǎn)換成其他總線,譬如AXI、AHB、APB 等。

圖1 ICB 總線結(jié)構(gòu)
1 DMA
1.1 DMA 概念
DMA(Direct Memory Access,直接存儲(chǔ)器訪問(wèn))是一種完全由硬件執(zhí)行輸入/輸出數(shù)據(jù)交換的方式,外部設(shè)備直接對(duì)計(jì)算機(jī)存儲(chǔ)器進(jìn)行讀操作,而不需要經(jīng)過(guò)CPU(處理器)。這種傳輸方式,取消了中間媒介的延遲,可以直接在目的地址和源地址直接完成傳輸,大大提高了傳輸效率[6]。
在進(jìn)行數(shù)據(jù)傳輸時(shí),芯片作為主設(shè)備完成所有操作,從而減輕了處理單元負(fù)擔(dān)。此外,DMA 傳輸支持塊傳輸和散/聚傳輸,以分別處理連續(xù)內(nèi)存映射地址和非連續(xù)內(nèi)存地址(非連續(xù)內(nèi)存地址映射下,通過(guò)指針寄存器完成),可提高使用效率。
1.2 DMA 配置
DMA 使用模式寄存器設(shè)置DMA 傳輸[7]。
典型的DMA 傳輸過(guò)程如圖2 所示。DMAC(DMA Controller,DMA 控制器)向CPU 發(fā)送DMA 總線控制請(qǐng)求信號(hào)HOLD,一旦DMAC 收到HLDA 響應(yīng)信號(hào),DMAC 將代替CPU 進(jìn)行總線控制,全權(quán)負(fù)責(zé)內(nèi)存和外設(shè)之間的數(shù)據(jù)傳輸,CPU 從中釋放出來(lái),待完成數(shù)據(jù)傳輸或發(fā)生錯(cuò)誤后,DMA 向CPU 發(fā)起一個(gè)中斷信號(hào),歸還總線控制權(quán)到CPU,整個(gè)傳輸過(guò)程結(jié)束。DMA 引擎的作用是控制數(shù)據(jù)搬移,涉及讀和寫兩種操作[8],通常在一個(gè)DMA 引擎里同時(shí)實(shí)現(xiàn)了這兩種功能,在進(jìn)行數(shù)據(jù)傳輸時(shí),先讀后寫,整個(gè)過(guò)程都在一個(gè)系統(tǒng)中實(shí)現(xiàn)。
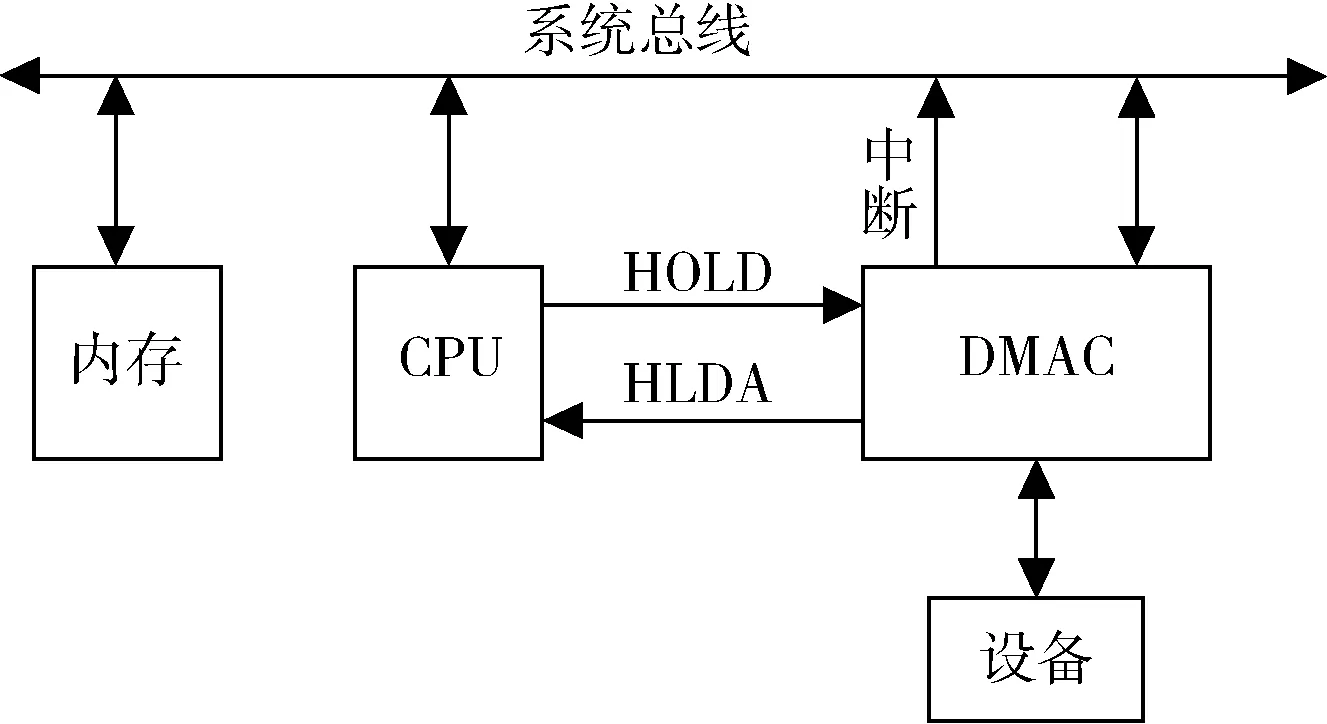
圖2 DMA 傳輸過(guò)程
總結(jié)DMA 配置過(guò)程:(1)確定傳輸數(shù)據(jù)的外設(shè)、寄存器地址和確定傳輸方向;(2)確定每次傳輸?shù)臄?shù)據(jù)量值和傳輸數(shù)據(jù)的字節(jié)數(shù);(3)配置通道優(yōu)先級(jí);(4)確定傳輸是循環(huán)模式還是非循環(huán)模式以及如若需要開(kāi)啟中斷,則開(kāi)啟響應(yīng)位中斷。
1.3 DMA 應(yīng)用
DMA 技術(shù)因自身特點(diǎn)可以適合應(yīng)用在高速高數(shù)據(jù)量傳輸中,多見(jiàn)于圖像處理、數(shù)據(jù)采集等應(yīng)用[9]。
隨著移動(dòng)互聯(lián)網(wǎng)和云計(jì)算發(fā)展,基于嵌入式系統(tǒng)的智能移動(dòng)設(shè)備也越來(lái)越多,如何快速有效地發(fā)送接收和處理設(shè)備收集的數(shù)據(jù),是系統(tǒng)開(kāi)發(fā)者需要思考的難題。基于DMA,可以實(shí)現(xiàn)串口數(shù)據(jù)的發(fā)送和接收,這樣,有利于降低對(duì)MCU(Micro Control Unit 微處理器)的占用,提高數(shù)據(jù)處理的效率[10]。
DMA 同時(shí)也廣泛應(yīng)用于PCIE 總線上,PCIE 總線由于其大吞吐量和支持DMA 的特性,適用于雷達(dá)領(lǐng)域,因此需要高速的數(shù)據(jù)傳輸系統(tǒng)和高速的數(shù)據(jù)采集系統(tǒng)。實(shí)際通信中,數(shù)據(jù)由光纖傳入FPGA 中,CPU 再將數(shù)據(jù)的處理結(jié)果發(fā)送。在這個(gè)過(guò)程中,CPU 實(shí)際只需要給FPGA 發(fā)送一次啟動(dòng)DMA 的命令,之后每次DMA 傳輸?shù)牧鞒叹涂梢杂蓴?shù)據(jù)源端發(fā)起,減少了CPU 與FPGA 的反復(fù)交互[11]。
為了滿足近年來(lái)機(jī)器視覺(jué)、無(wú)人駕駛等智能識(shí)別技術(shù)領(lǐng)域的發(fā)展,圖像處理技術(shù)的要求越來(lái)越高,DMA2D控制器應(yīng)運(yùn)而生。使用DMA2D 控制器,即通過(guò)DMA 連接顯示器引腳或存儲(chǔ)控制器引腳將像素?cái)?shù)據(jù)傳輸?shù)揭壕粒瑥亩涌祜@示每幀圖像在屏幕上的顯示速度,也可以通過(guò)配置實(shí)現(xiàn)部分顯示,如只刷新圖像的部分內(nèi)容。由于幀頻率越高動(dòng)畫越流暢,因此提升DMA 的傳輸速度,有利于顯示效果的提高[12]。
2 配置與驗(yàn)證
2.1 設(shè)計(jì)思路
ICB 總線總的可以分為命令通道和響應(yīng)通道,主機(jī)通過(guò)ICB 總線向從機(jī)發(fā)送命令,從機(jī)通過(guò)ICB 總線響應(yīng)主機(jī),如圖3 所示。

圖3 ICB 通道傳輸
ICB 通道與信號(hào)如表1 所示,ICB 的讀寫有兩次握手,一次是主機(jī)發(fā)起讀寫請(qǐng)求,然后從機(jī)響應(yīng)。另一次是從機(jī)發(fā)起讀寫反饋請(qǐng)求,主機(jī)響應(yīng)。兩次握手結(jié)束也就意味著完成一次讀寫。

表1 ICB 通道與信號(hào)
2.2 RTL 代碼分析
2.2.1 寄存器配置ICB 時(shí)序
(1)dma_cfg_icb_cmd_ready(DMA 配 置ICB 總線命令準(zhǔn)備寄存器):如果是讀寄存器的值,則需要等待rsp_valid 信號(hào)為0 時(shí)才能讀,此時(shí)表示沒(méi)有對(duì)寄存器進(jìn)行寫值;如果是寫寄存器的值,當(dāng)dma_cfg_icb_cmd_valid 信號(hào)產(chǎn)生時(shí)則立即將ready 拉高。
(2)dma_cfg_icb_rsp_valid(DMA 配 置ICB 總線響應(yīng)有效寄存器):當(dāng)cmd 命令信號(hào)握手后,表明寫或者讀寄存器值正常,則可以在下一個(gè)周期將該信號(hào)拉高,直到與rsp 響應(yīng)信號(hào)握手,將這個(gè)值拉低。
(3)dma_cfg_icb_rsp_rdata(DMA 配 置ICB 總線響應(yīng)讀數(shù)據(jù)寄存器):可以利用組合邏輯實(shí)現(xiàn),但本次模塊中采用握手后的下一個(gè)周期讀出寄存器的值。并且當(dāng)rsp_valid 信號(hào)沒(méi)有拉低時(shí),rdata 的值需要一直保持,握手成功后根據(jù)寄存器地址進(jìn)行賦值。
(4)dma_icb_cmd_addr(DMA_ICB 命令地址寄存器):為組合邏輯,當(dāng)cmd 握手后,如果為讀狀態(tài),則地址變?yōu)閟_reg 寄存地址加上偏移量;如果為寫狀態(tài),則為d_reg 中的地址加偏移量。其中偏移量用發(fā)出的讀或者寫命令的次數(shù)代替。
2.2.2 FIFO 模塊
(1)讀與寫地址:初始地址都為0,當(dāng)空的時(shí)候無(wú)法進(jìn)行讀操作,滿的時(shí)候無(wú)法進(jìn)行寫操作。
(2)空、滿與溢出信號(hào):當(dāng)?shù)刂返牡? 位相同,并且最高位不同時(shí),則表示FIFO 已經(jīng)滿了,當(dāng)讀寫指針?biāo)形欢枷嗤瑫r(shí),則表示FIFO 為空。溢出信號(hào)是當(dāng)FIFO 滿的時(shí)候,還要繼續(xù)寫進(jìn)數(shù)據(jù)時(shí)指示的信號(hào),所以可以利用時(shí)序邏輯。
(3)讀數(shù)據(jù)與寫數(shù)據(jù):讀數(shù)據(jù)與寫數(shù)據(jù)根據(jù)讀寫使能信號(hào)以及空滿信號(hào),將指針對(duì)應(yīng)的數(shù)據(jù)讀出或者寫入。
(4)sub_full 即滿信號(hào):由于時(shí)序邏輯的延遲,導(dǎo)致?tīng)顟B(tài)機(jī)在判斷下一個(gè)狀態(tài)時(shí)要提前知道FIFO 是否滿了,由于FIFO 的full 信號(hào)比next_state 信號(hào)晚兩個(gè)周期,因此需要一個(gè)sub_full 信號(hào)來(lái)指示FIFO 是否即將滿了。
2.2.3 DMA 的數(shù)據(jù)傳輸
在傳輸階段,DMA 主要有三個(gè)狀態(tài):初始狀態(tài),讀SRAM 狀態(tài),寫SRAM 狀態(tài)。初始狀態(tài):表示DMA 還未開(kāi)始傳輸。讀SRAM 狀態(tài):當(dāng)DMA 使能信號(hào)為0 時(shí),其下一狀態(tài)為初始狀態(tài)。當(dāng)FIFO 還沒(méi)有滿,并且讀的數(shù)據(jù)數(shù)目還沒(méi)有達(dá)到要求的數(shù)目,下一狀態(tài)繼續(xù)讀;否則下一個(gè)狀態(tài)為寫。寫SRAM 狀態(tài):當(dāng)DMA 使能信號(hào)為0時(shí),其下一狀態(tài)為初始狀態(tài)。當(dāng)FIFO 還未空,并且寫的數(shù)據(jù)數(shù)目沒(méi)有達(dá)到要求的數(shù)目,下一個(gè)狀態(tài)繼續(xù)寫。如果讀的數(shù)據(jù)還沒(méi)讀完,則下一個(gè)狀態(tài)變?yōu)樽x。否則下一個(gè)狀態(tài)變?yōu)槌跏紶顟B(tài)。
2.2.4 ICB 訪存時(shí)序
圖4、圖5 所示是通過(guò)ICB 讀寫的時(shí)序。

圖4 寫時(shí)序

圖5 讀時(shí)序
2.3 DMA 配置過(guò)程
DMA 配置模塊主要由ICB slave 接口和配置寄存器堆組成。
ICB slave 接口:DMA 在配置時(shí)需要以從設(shè)備的角度完成ICB 時(shí)序通信。輸入信號(hào)直接和CPU 發(fā)來(lái)的信號(hào)相連即可。主要考慮輸出的信號(hào)。
s_icb_cmd_ready 信號(hào):可以根據(jù)DMA 可能出現(xiàn)的狀況判定,最簡(jiǎn)單的方法就是令其等于s_icb_cmd_valid信號(hào),也就是認(rèn)為DMA 總是準(zhǔn)備好的。這需要在編寫配置模塊時(shí)確保不會(huì)出現(xiàn)意外狀況導(dǎo)致停頓。s_icb_rsp_valid 信號(hào)可以設(shè)置成每次cmd 握手后拉高,在rsp 握手后拉低。s_icb_rsp_rdata 則需要根據(jù)輸入地址選擇對(duì)應(yīng)的寄存器值。
寄存器堆:DMA 工作需要配置如源地址寄存器、目的地址寄存器、搬運(yùn)長(zhǎng)度寄存器、狀態(tài)寄存器等一系列寄存器。它們需要有固定的偏移地址,從而可以被s_cmd_addr 地址信號(hào)確定位置以訪問(wèn)。
3 結(jié)論
本文設(shè)計(jì)了一個(gè)基于ICB 協(xié)議的DMA 控制器,利用EDA 工具完成仿真驗(yàn)證,并改善了部分代碼以提升代碼質(zhì)量,最終DMA 控制器功能行使正確,符合設(shè)計(jì)目標(biāo)。在整個(gè)設(shè)計(jì)過(guò)程中,主要完成的工作內(nèi)容如下:
(1)研究并總結(jié)相關(guān)協(xié)議以及 DMA 傳輸原理,基于AMBA 總線架構(gòu)提出DMA 控制器設(shè)計(jì)方案,完成方案的制定。
(2)詳細(xì)分析了DMA 控制器的具體功能,依據(jù)功能劃分模塊,借助硬件編程語(yǔ)言Verilog 編寫代碼,實(shí)現(xiàn)模塊劃分功能。
(3)完成DMA 控制器的前端功能仿真驗(yàn)證。結(jié)果符合傳輸要求,子模塊功能正常行使,符合設(shè)計(jì)需求。
本次設(shè)計(jì)的DMA 控制器實(shí)現(xiàn)了預(yù)期功能需求,但功能較為簡(jiǎn)單單一,還無(wú)法滿足其他需求,經(jīng)過(guò)考慮,可以在嘗試從以下幾個(gè)方面入手改進(jìn):(1)接入其他總線,從而得到通用方向的DMA 控制器;(2)提高內(nèi)部通道數(shù)量,通道數(shù)目越多,則控制器一次可響應(yīng)的請(qǐng)求越多,現(xiàn)在的市場(chǎng)環(huán)境,多種外設(shè)集成是大勢(shì)所趨,提升兼容性,可以很好地實(shí)現(xiàn)系統(tǒng)傳輸效率的提升。
猜你喜歡
鴨綠江(2021年35期)2021-04-19 12:24:18
考試與評(píng)價(jià)·高一版(2020年6期)2020-11-02 02:45:24
媽媽寶寶(2019年10期)2019-10-26 02:45:34
中國(guó)生殖健康(2019年3期)2019-02-01 06:12:26
鐵道通信信號(hào)(2018年11期)2019-01-19 01:15:08
電子制作(2018年11期)2018-08-04 03:25:42
鐵道通信信號(hào)(2018年2期)2018-04-18 12:18:10
鐵道通信信號(hào)(2016年11期)2016-06-01 12:11:32
鑿巖機(jī)械氣動(dòng)工具(2016年3期)2016-03-01 04:00:25
中國(guó)病理生理雜志(2015年8期)2015-12-21 12:38:06
