具有自主學習與記憶功能的智能政務問答系統研究*
2024-02-17 12:52:04方海泉鄧明明
電子技術應用 2024年1期
方海泉,鄧明明
(1.浙江工業大學,浙江 杭州 310023;2.浙江大學,浙江 杭州 310058)
0 引言
問答系統可以滿足用戶快速、準確查找信息的需求,在政務、電商、教育、金融等領域得到廣泛應用[1?8]。以問答系統在政務上的應用為例,如:“浙江省民呼我為統一平臺”的智能問答系統,以及杭州12345 的智能客服機器人“小杭”,對于公眾辦事或者咨詢問題提供了快速便捷渠道,充分體現了數字技術在政府數字化改革上具有重要的應用價值,可以更好地改善公眾參與[9?10]。但是目前的政務問答系統還處在初步發展階段,用戶很多時候更傾向于選擇人工客服,政務問答系統還有很大的提升空間。從用戶的角度來說,目前的政務問答系統還不夠智能。因此,很有必要對現有的問答系統進行改進。
問答系統的種類較多,其中相對簡單且常用的問答系統是基于問答對的問答系統,本文以此為研究對象,對基于問答對的問答系統進行智能化升級。如果可行,可以進一步推廣到其他類型的問答系統。基于問答對的問答系統的原理是當用戶輸入一個問題的時候,首先需要在知識庫里找到與用戶輸入的這個問題最相近的問題,然后輸出相應的答案。
對于知識庫的問答系統,知識庫一旦整理好通常是固定的,如果想提升問答系統的性能,需要更新知識庫。目前問答知識庫更新存在以下幾個問題:(1)需要人工整理問答知識庫,更新成本較高;(2)更新周期較長;(3)更新的內容缺乏針對性。由于以上原因,現有的問答系統難以滿足用戶的需求,從而,用戶對問答系統的滿意度不高。目前的問答系統,當用戶沒有得到滿意答案時,用戶需要選擇轉人工客服才能與人工客服溝通,并且人工客服與問答系統是分開的,信息不能共用。
針對知識庫更新難的問題,本文提出了一種自動實時更新知識庫的方法。核心思想:當用戶問一個問題,問答系統如果能給出答案,則自動輸出答案。如果問答系統沒有答案,則把這個問題自動發送給人工客服,人工客服回復之后,一方面把答案發送給用戶;另一方面,本文構建的問答系統可以把這個問答對自動實時更新到知識庫里,下次其他用戶問到類似的問題,問答系統就能自動給出答案了,從而使得問答系統具有自主學習與記憶功能。由此,人工客服要做的工作會越來越少,問答系統能回答的問題越來越多,越來越智能。
1 相關研究
本節分為兩部分,包括知識庫的構建和問答系統建模。
1.1 知識庫的構建
早期知識庫的構建都是通過人工整理。人工整理和維護知識庫的成本較高,且針對性較差,制約了知識庫的發展。2020 年,Liu[11]等人用自動學習的方法動態更新知識庫,并應用于電商領域,對知識庫的更新有較大的改進,這個方法能夠從歷史對話記錄中自動提取問答對,但是不能實時更新知識庫。
1.2 問答系統建模
基于問答對的問答系統,其構建原理:計算輸入問題與知識庫里的問題之間的相似度,并將相似度較高的對應答案作為候選答案。在計算相似度之前需要把用戶輸入的問題以及知識庫里的問題分別轉為向量,其本質是文本向量化過程,屬于人工智能的自然語言處理方向,學術界對于文本向量化有大量研究。
詞袋(Bag of Word)模型是最早的文本向量化方法。2013 年,Mikolov[12]等人提出了詞向量(word2vec)模型,word2vec 屬于神經網絡模型,該模型能夠從大規模未經標注的語料中高效地生成詞的向量,并提供了CBOW(Continuous Bag of Words) 和Skip-gram 兩種模型。2018 年文本向量化迎來預訓練模型時期,Peters[13]等人提出了ELMO(Embeddings from Language Models)模型,ELMO 采用雙向長短期記憶網絡(Long Short-Term Memory,LSTM)。2018 年,Radford[14]等人提出了GPT(Generative Pretrained Transformer),這是一種基于單向Transformer 的預訓練模型。Transformer 算法由Vaswani[15]等人于2017 年提出。2018 年,Devli[16]等人提出了 BERT (Bidirectional Encoder Representations from Transformers) 模型。2019 年,SUN[17]等人提出了ERNIE模型,其核心也是由Transformer 構成的。2019 年,Radford[18]等人對GPT 改進提出了GPT-2 模型。2020 年,Brown[19]等人提出了GPT-3 模型。2022 年,人工智能研究實驗室 OpenAI 上線了聊天機器人ChatGPT,Chat-GPT 是基于GPT-3.5 模型開發的。這些文本向量化方法對于構建問答系統提供了很好的基礎。
本研究的創新點主要體現在知識庫構建方面,提出了知識庫自動實時更新方法。在構建問答系統時選用較為先進的ERNIE 文本向量化方法,因為ERNIE 是基于中文預訓練的模型,該方法更適用于中文文本向量化。
2 模型結構
針對問答系統的知識庫更新成本高、更新不及時的問題,本文提出知識庫自動實時更新的問答系統(Question Answering System with Automatic and Real-time Updating of Knowledge Base,QA-ARU-KB)模型。技術路線如圖1 所示,具體算法步驟如下。

圖1 技術路線
(1)整理知識庫
①根據現有的知識庫整理好問答對,問答對是一個n行2 列的矩陣,每一行是一個問題及這個問題的答案,n行表示有n個問答對,把問題列記為Q1,答案列記為A1。
②應用文本向量化方法把每一個問題轉為向量,問題列Q1經過轉換得到的列向量記為V1。這里的文本向量方法用ERNIE。
③把問題的向量列V1與答案列A1按行拼接成n行2列的矩陣M,把矩陣M定義為知識庫。
(2)構建問答系統
①假設用戶問了一個問題,用文本向量化方法把用戶的問題轉為向量h0,計算向量h0與問題的向量列V1(矩陣M的第一列)里的每一個向量的相似度,這里的相似度可以用余弦相似度,得到的相似度構成一個列向量,記為R0。
②選出列向量R0中的最大相似度,判斷最大相似度是否大于閾值,閾值可以設為0.8,如果大于或等于閾值,認為匹配到相似的問題,該問題對應的答案可以作為用戶提問的答案;如果最大的相似度小于閾值,說明知識庫里沒有答案。
(3)用戶與問答系統交互
當用戶輸入一個問題,經過步驟(2)中問答系統的計算,結果有兩種可能:
①問答系統能夠給出答案,把答案輸出給用戶,同時詢問用戶對這個答案是否滿意。如果用戶選擇“滿意”,則不用處理;如果用戶選擇“不滿意”,則說明這個問題的答案需要更新,把用戶提的這個問題發送給人工客服。
②問答系統沒有答案,提示用戶“我把您的問題發給人工客服,稍后回復您”。問答系統自動把用戶提的這個問題發送給人工客服。
(4)人工客服與問答系統交互
當人工客服收到問答系統發送過來的問題,判斷這個問題是否屬于業務范圍內的問題:如果屬于,則人工客服可以進行回答,然后把答案發送給用戶,同時把這個問答對發送到問答知識庫;如果不屬于,則人工客服不用回答,并且可以刪除無效問題。這一步需要用到人工客服的專業知識。
(5)知識庫自動實時更新
知識庫收到人工客服發來的問答對,這個問答對包括用戶提的問題w和人工客服回復的答案d。這個問答對的問題w有兩種可能性:一種是知識庫里沒有出現過的新問題;另一種是知識庫里已有的問題,但是用戶對這個答案不滿意,需要更新。對此有兩種不同的處理方式:
①對于知識庫里沒有出現過的新問題,知識庫更新方法如下:
a.用文本向量化方法ERNIE 把這個問題w轉為向量,記為向量m;
b.把向量m拼接到向量V1的最下方,得到的向量列仍然記為V1;
c.把問答對的答案d拼接到答案列A1的最下方,得到的答案列仍然記為;
d.把問題的向量列V1與答案列A1按行拼接成(n+1)行2 列的矩陣,得到更新后的知識庫,仍然記為M。
②對于知識庫里已有的問題,知識庫更新方法如下:
a.用文本向量化方法ERNIE 把這個問題w轉為向量,記為向量m;
b.把向量m與問題的向量列V1計算余弦相似度,找到相似度最大的向量的位置z。
c.對知識庫位于位置z的問答對進行更新,更新方法:對于向量列V1的位置z,在該位置用向量m替換之前的向量,得到的向量列仍然記為V1;對于答案列A1的位置z,在該位置用答案d替換之前的答案,得到的答案列仍然記為A1;
d.把問題的向量列V1與答案列A1按行拼接成n行2列的矩陣,得到更新后的知識庫,仍然記為M。
經過以上步驟,在用戶、問答系統、人工客服交互的過程中,知識庫可以自動實時更新,以后其他用戶問到類似問題,問答系統可以實時給出答案,能回答的問題會越來越多,相當于具有記憶功能,而人工客服需要回答的問題會越來越少,從而既能減少人工的工作量,又能提升用戶的滿意度。
3 實驗與分析
知識庫自動實時更新的問答系統需要依賴用戶、人工客服與問答系統交互,如圖2 所示,用戶把問題發給問答系統,問答系統如果有答案則直接回復;如果沒有答案,則把問題發送給人工客服。人工客服收到用戶的問題可以進行回復,回復后用戶可以實時看到答案。同時,問答系統可以獲取到這個問答對并實時更新到知識庫。
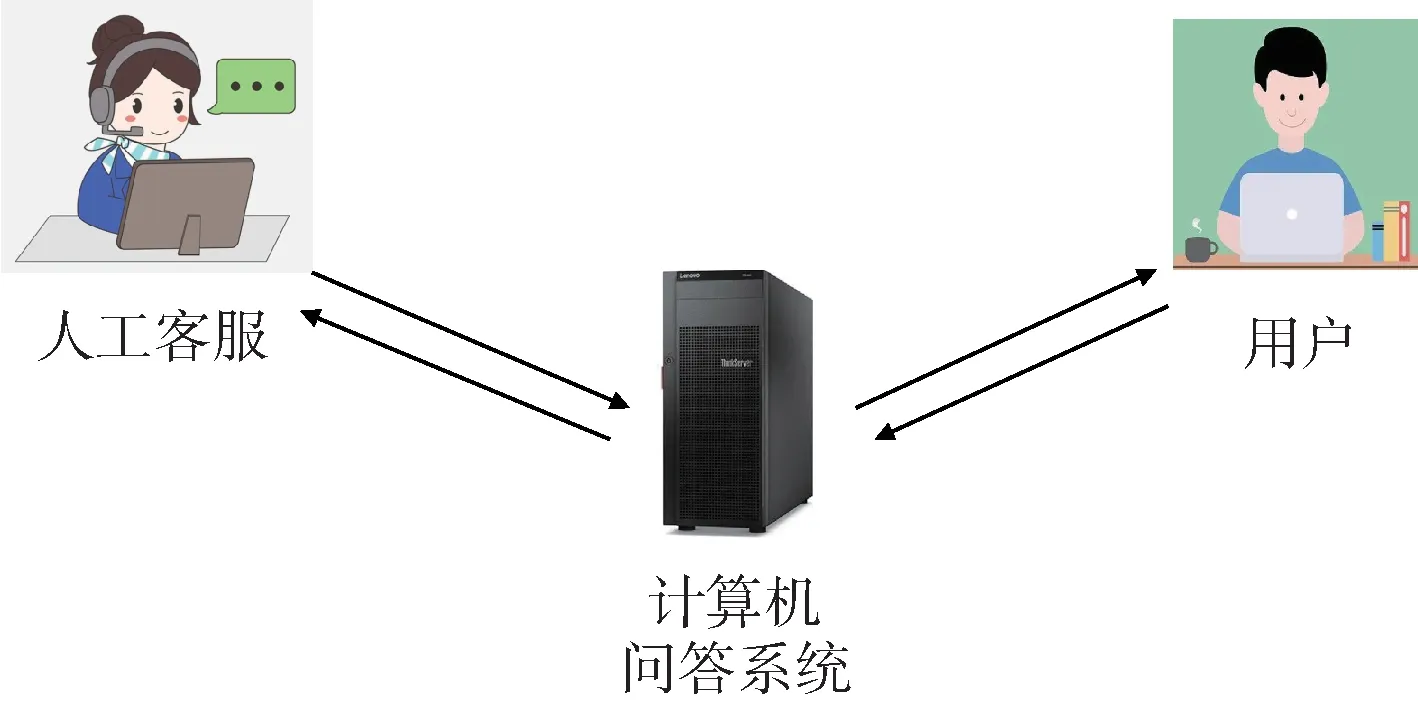
圖2 用戶、人工客服參與的問答系統
為了更好地理解和體驗問答系統的效果,本文構建了一個政務問答系統,知識庫是關于政務方面的問答對,構建的政務問答系統已發布到互聯網上,從而可以在線體驗知識庫自動實時更新的問答系統。
3.1 整理知識庫
數據來源選自“浙江省民呼我為統一平臺”網頁,進入該網頁的“我要咨詢”可以看到一個智能問答系統界面,地點可以選擇浙江省各個地市。以選擇杭州市為例,可以咨詢戶籍及身份證、出入境、五險一金、車駕業務、公司企業團體、職業證件、人生周期、部門職責等方面的問題。以此為數據源,從中選取并整理了400 個問答對作為知識庫。用ERNIE 方法把問題列轉為向量。
3.2 構建問答系統、用戶端、人工客服端并部署程序
按照本文第2 節提出的算法構建模型,問答系統用Python 程序實現,用戶端、人工客服端用Vue 實現,通過互聯網把用戶端、問答系統、人工客服端三部分集成起來,實現數據互通,并通過docker 部署程序,計算機系統采用Linux 系統。在用戶和人工客服的參與下,可以實現知識庫自動實時更新的問答系統。
3.3 網頁界面
為了體驗知識庫自動實時更新的問答系統,本文構建了用戶端和人工客服端的兩個網頁界面。
用戶端網址為:http://www.algstar.com/Upload?type=9。
用戶端網頁界面如圖3 所示,用戶可以輸入想問的問題,如果問答系統有答案會直接輸出答案,并詢問用戶對該答案是否滿意。如果問答系統沒有答案,問答系統會輸出“我把您的問題發給人工客服,稍后回復您”。例如當用戶問“杭州西湖區政務服務中心在哪里?”,問答系統暫時沒有答案,系統會把問題自動發送給人工客服。

圖3 用戶端網頁界
人工客服端網頁界面如圖4 所示,如果一個問題屬于業務范圍內的問題,人工客服可以回復該問題,需要先點擊該問題,然后回復并點擊“發送”,用戶可以實時看到人工客服回復的答案;如果該問題不屬于業務范圍的問題,人工客服可點擊刪除。對于這個例子,人工客服回復:“ 杭州市西湖區文一西路858 號”。

圖4 人工客服端網頁界
當人工客服回復了問題,問答系統會自動實時把答案發送給用戶,用戶能看到人工客服的回復。這個問答對會自動實時更新到知識庫。之后,當其他用戶問到類似的問題,問答系統可以實時給出答案,無需再問人工客服了。如圖5 所示,當用戶問“請問西湖區政務服務中心地址?”,問答系統自動回復“杭州市西湖區文一西路858 號”。由此說明,構建的問答系統具有自主學習與記憶功能,使用越久,會越智能。另外,問答系統自動回復了問題的同時,還會進一步問用戶對該答案是否滿意,用戶可以反饋意見。值得一提的是,構建的問答系統應用了文本向量化方法,通過計算向量相似度可以實現更好的匹配,不要求每一個字完全對應,問答系統具有較好的語言理解能力。

圖5 用戶端收到答案,再次問類似問題可自動獲得答案
3.4 后臺系統
在后臺系統,可以查看實時動態更新的知識庫,后臺系統顯示的部分知識庫樣例如圖6 所示,每一個問答對包括問題和答案。

圖6 后臺系統顯示的知識庫樣例
3.5 分析與討論
本文構建的政務問答系統以用戶為中心,充分考慮用戶的需求。當用戶問的問題得不到滿意的回復,系統會及時獲取用戶的提問并發送給人工客服,人工客服利用專業知識回復并發送給用戶。同時,系統自動獲取該問答對,并實時更新到知識庫。之后,其他用戶問到同類問題,系統能自動回復,人工客服無需回復重復的問題。整個問答系統構建的思想是人機結合,使得問答系統更加智能,更能滿足用戶的需求。
4 結論
針對政務、電商、金融等專業性較強的領域,傳統的問答系統知識庫更新困難,本文通過構建知識庫自動實時更新的問答系統(QA-ARU-KB)模型,讓用戶和人工客服可以實時溝通,并把溝通的信息實時保存到知識庫,使問答系統實現自主學習與記憶功能。
本文方法的優點:(1)問答系統的知識庫可以自動實時更新,從而使得問答系統具有自主學習與記憶功能。該方法適用于專業性較強的領域,如政務、電商、金融等,這些領域需要人工客服的專業知識,不是Chat-GPT 所能替代的。同一個問題,人工客服只需要回答一次,問答系統就能記住,這樣人工客服就不用做重復的工作。(2)給用戶提供了反饋意見的機會,充分吸收人的智慧,從而更加智能。用戶如果對答案不滿意可以點擊“不滿意”,這樣可以對知識庫里已有的問答對更新,在用戶和人工客服的交互下,知識庫的更新更有針對性,從而構建出以用戶為中心的問答系統,讓用戶滿意的問答系統。
本文提出的方法目前只適用于基于問答對的問答系統,其他類型的問答系統有待進一步研究。未來可以把本文方法與ChatGPT 結合起來。目前的問答系統是文本交互,可以增加語音識別、語音合成功能,實現語音交互。
猜你喜歡
工業設計(2022年8期)2022-09-09 07:43:20
軍民兩用技術與產品(2021年10期)2021-03-16 06:05:30
北京測繪(2020年12期)2020-12-29 01:33:58
制造技術與機床(2019年10期)2019-10-26 02:48:08
電子制作(2018年18期)2018-11-14 01:48:06
家庭影院技術(2017年9期)2017-09-26 03:41:45
商用汽車(2016年11期)2016-12-19 01:20:16
商用汽車(2016年6期)2016-06-29 09:18:54
商用汽車(2016年4期)2016-05-09 01:23:12
小學教學參考(2015年20期)2016-01-15 08:44:38
