基于字典學習的舌診圖像去噪研究
2024-01-25 08:59:14劉為相李燦張霞周作建宋懿花
中醫藥信息 2024年1期
關鍵詞:深度
劉為相,李燦,張霞,周作建,宋懿花
(南京中醫藥大學,江蘇 南京 210000)
在生物醫學工程、神經網絡和多種優化算法的不斷發展和完善下,人工智能已經進入了臨床診斷的范疇。舌診所需的圖像可利用模式識別等算法進行處理,使中醫舌診的發展進入了一個全新的階段,大大促進了中醫舌診客觀化、規范化的進程,對中醫舌診的繼承與創新有舉足輕重的作用。在量化研究中,最常用的是RGB(紅綠藍)模型,不同類型舌診影像RGB數據存在差異,說明利用電腦影像技術進行舌診客觀化分析是切實可行的,但是現有的舌象處理技術中,大多以[1]RGB模型為基礎對舌象顏色值的修正,而在舌診圖像去噪方面沒有相關研究。
K-SVD(K-Singular Value Decomposition)算法是目前最具有代表性且應用領域最廣泛的自適應學習字典算法。MALLAT首先提出了圖像的超完全信號稀疏表達,利用Gabor詞典對圖像進行稀疏表示,并將其用于圖像稀疏表達。稀疏和冗余表示技術是目前信號和圖像處理領域的一個主要的研究領域,包括稀疏搜索、圖像銳化、字典構造、人臉圖像壓縮、圖像去噪、圖像修補以及圖像尺度放大等研究領域。由此提出基于字典學習算法對中醫舌診圖像降噪的研究,并分別通過單層字典去噪及深度字典去噪兩種方式做出對比,放大實驗效果[1]。
1 數據集預處理
預處理部分包括對比度拉伸、直方圖均衡化、空間平滑濾波以及空間銳化濾波,流程見圖1。其中空間平滑濾波包括均值濾波以及中值濾波,空間銳化濾波包括Sobel算子以及Laplacian算子。

圖1 數據集預處理流程圖
2 稀疏模型構建
假設原始樣本為Y,字典矩陣為D,原子為dk,稀疏矩陣為S,矩陣乘法為DX。字典學習的主要思想是利用包含K個原子dk的字典矩陣D∈Rm×K,稀疏線性表示原始樣本Y∈Rm×n(其中m表示樣本數,n表示樣本屬性),即有Y=DS(最理想情況)[2],其中S∈RK×n為稀疏矩陣,上面的問題可以被用數學語言表示為下面的最優問題:
上式中,S為稀疏編碼的矩陣,si(i=1,2,…,K)為該矩陣中的行向量,代表字典矩陣的系數。‖si‖0表示零階范數,它表示向量中不為0的數的個數[3]。
式(1)的目的函數表達式是為了盡量減少查找到的詞典和原始樣本之間的誤差,也就是盡量恢復原來的樣本;它的限的制條件‖si‖0≤T0,表示查字典的方式要盡可能簡單,即X要盡可能稀疏。式(1)或式(2)是一類具有限制的最優化問題,它可以通過拉格朗日乘子方法進行求解。
注:將‖si‖0用‖si‖1代替,主要是更加便于‖si‖1求解。
在此,有兩個最優變量D,S為了求解該優化問題,通常會將一個最優變量固定,然后對另外一個最優變量進行優化,這樣交替進行。接下來稀疏矩陣可以S利用已有經典算法求解,如Lasso(Least Absolute Shrinkage and Selection Operator)、OMP(Orthogonal Matching Pursuit)。其中以更新字典D為例:
假設X是已知,逐列更新字典,當僅更新字典的第k列時,記dk為字典D的第k列向量,記SkT為稀疏矩陣S的第k列向量。那么對式(1)有:
因此,需要求出最優的dk,skT[4]。這是一個最小二乘問題,它可以用最小二乘法來解決,也可以用SVD法來解決。但不能用Ek進行求解,否則求得的新的skT不會被稀疏化。因此需要將Ek中對應的skT不為零的位置提取出來,得到新的Ek。假設需要更新第0列原子,需要將skT中為0的位置找出來,然后把對應Ek的位置刪除,得到E'k,此時優化問題可描述為
因此求得最優的dks’kT。
取左奇異矩陣∪的第一個列向量u1=∪(·,1)作為dk,即dk=u1。取右奇異矩陣的第一行向量與第一個奇異值的乘積作為x‘kT,即s‘kT=∑(1,1)VT(1,·)。得到S‘kT后,將其對應地更新到原SkT。
3 字典學習算法
稀疏模型剔除了大部分的冗余變量,僅保留了最接近于反應變量的解釋變量,從而使模型更加簡單,但又能保持最關鍵的信息,從而解決了許多問題。由此可發現,稀疏模型所達到的效果與字典學習的目的一致,都是要將冗余的無關緊要的信息刪除;而將重要的、本質的信息得以保留[5]。也正因如此,“字典”的衡量標準也就隨之產生,字典創建的好與壞主要取決于它這個模型夠不夠稀疏(也就是說提取的特征是否足夠關鍵,是否足夠本質)[6]。
3.1 單層字典學習算法去噪
首先進行對Patch切塊的函數定義:通過np.copy(data)將數據載入,隨后定義Patch的邊長及patch_size=8。其次完成對形狀及數據類型的定義shape=(9,620 01,8,8),dtype=np.float32。之后確定對共9張圖片進行處理,每張圖片大小為(256,256),通過定義所有行的每1格標注一次,再進行每1列的每格標注一次,由此完成對切塊函數的定義。
高斯噪聲單層去噪:首先使用高斯噪聲訓練字典。根據zscore的規范化方法,將數據中的數據除以平均除以方差。然后,對MiniBatchDictionaryLearning類進行初始化,并根據初始參數對類別進行初始化。
完成上述步驟后開始繪制V中的字典:
利用figsize方法指明圖片的大小,4.2英寸寬,4英寸高。其中一英寸的定義是80個像素點。循環畫出100個字典V中的字(其中n_components是字典的數量)。Enumerate()函數通常在 for循環中使用,把一個可遍歷的資料物件合并成一個索引序列,并列出資料和資料下標。
隨后6個參數與注釋后的6個屬性對應,left,right,bottom,top,wspace,hspace分別對應(0.08,0.02,0.92,0.85,0.08,0.23)此時已完成從高斯噪聲的圖像中提取字典并準備開始高斯噪聲的稀疏表示。
通過differents=[]得出復原圖片和原圖的誤差,transform_algorithms為字典表示策略。
接下來先通過調用remove_files()函數清空此文件夾中之前的文件,然后利用set_params()函數來設定第二個相位的參數。transform是基于set_params來建立一個已設置的參數的模型的詞典,它代表了一個code中的結果。code共有100個欄,每個欄都對應一個V中的詞典單元,而所謂的“稀疏”是指代碼中每個行的大多數元素都是0,因此可以用最小的詞典元素來表達。
隨后用code矩陣乘V得到復原后的矩陣patches及樣本(62 001,64)=稀疏表示(62 001,256)*過完備字典(256,64)。這一階段結束還原數據預處理:patches +=gaussian_mean,將patches從(62 001,64)變回(62 001,8,8)。隨后通過reconstruct_from_patches_2d()函數將patches重新拼接回圖片。以psnr_score作為復原圖片和原圖的誤差計算并得出,最終展示去噪復原圖并重命名完成保存。
椒鹽噪聲單層字典去噪方式與上述相同,不再贅述。
3.2 深度字典學習算法去噪
基于深度學習的降噪技術是當前圖像處理中的一個熱點問題。在此基礎上,設計了對應的網絡結構,獲取了關鍵特征,并對輸入和輸出的對應關系進行了研究。在完成一定數量的圖像采樣后,可以得到充分的信息,如圖像特征、數據分布等信息,隱含去除噪聲,達到去除噪聲的目的,原理見圖2。本研究中的深度學習為兩層網絡層。在輸入圖像過后,在對圖像進行降噪處理時,采用了卷積運算,抽取有用的特征,并采用非線性映射進行判斷推理,并采用判別式學習方法獲得圖像降噪前的信息,達到了對噪聲的分離[7]。

圖2 深度去噪原理圖
其中,卷積神經網絡(CNNs)是最典型的深度學習類降噪算法,而CNNs則是一種改進的DNNs結構,也就是LeNet網絡的5級結構,并在分類工作中脫穎而出。之后的研究通過對圖像數據的存儲和運算的限制,改進了LeNet的網絡架構,并在ImageNet的比賽中,通過GPU訓練出8個層次的AlexNet,它的分類精度提高了11%。
二者均屬典型CNN,CNNs結構的主要構成元素為負責抽取主要圖像特征的卷積層(Convolution layer),同時加上激活函數(Activation function)的非線性映射作用可以加快網絡的收斂速度。當前,在深度學習的研究中,大量標準化技術也被用于加快網絡的訓練。將這些功能各異的網絡層結合起來,可以構造出不同層次的網絡,從而完成復雜的圖像處理[8]。
①卷積層。它是CNNs與其他神經網絡的一大特色,其主要作用是對多個卷積核進行卷積,從而實現對圖像的局部特征的提取。卷積運算實質上是對相應的位置要素進行加法運算,在一個CNNs中,有多個縱深的卷積層,每個卷積層內都有若干個不同的卷積核,因此可以進行多個卷積運算。與粗略地進行一次卷積運算不同,多層多次的卷積運算不但能提取出較淺的區域內的圖像特征,并且可以從圖像中提取出更深層次的語義特征。如果卷積層是一個矩陣卷積層,那么它就是一個特操作不但可以提的特征圖,而卷積且還層則是一個特殊的特征映射,但是它也是矩陣形式。在卷積運算完成后,每個卷積層都會通過一個具有非線性近似功能的激活函數,并把新的特征映射結果輸入到下一層次。
②池化層和完全連通層。在具體的任務環境中,并不是所有的特性信息都能起到很大的作用,所以池化層的功能主要是篩選重要的特征數據,過濾掉多余的數據,增強了網絡的普遍性。最大池是最大池和平均池,通常使用最大池方法來保持較高的紋理信息。在CNNs中,全連接層通常在網絡的末尾,但在網絡的最終輸出端。全連通層是將各層的各節點與各層的節點連接起來的,所以在這一層中,所有的特征信息都集中在一起,從而能夠集成分布的特點。然而,由于全連接層的存在,會產生許多冗余的參數,因此,目前通常都是以卷積層或池化層來進行網絡性能的優化。
③激活函數。為了增強網絡的逼近能力來模擬任意復雜的函數,一般在線性卷積操作之后使用激活函數強化神經網絡的學習能力,常用的激活函數有四類:Sigmod,Tanh,ReLU,Leaky。ReLU函數是當前深度學習中應用最為頻繁的一個非線性激活函數,它具有簡單、高效的特點,能夠有效地解決深度學習中的梯度消失問題。ReLU的函數表達式為:F(x)=max(0,x)。實驗采用了ReLU和Sigmoid作為激活函數,配合完成深度去噪。首次定義dico1時將字典的數量即n_components定義為144,當再次進行第二層卷積時,將dico2的字典數量定義為256,通過兩次卷積完成深度字典學習。
4 成果展示及分析
4.1 數據集介紹
當前有效的深度降噪算法多為有監督學習,要求對輸入輸出的圖像進行采集(Noisy/noise-free images pairs)建立數據集合是一個重要的工作。數據的質量是影響降噪效果的重要因素。如何盡可能多地采集到大量的影像資料,并得到高品質的參考影像(ground truth)是當前的一個重要課題。本課題數據集來自江蘇省中醫院,該數據集收集了來自不同患者的陰虛證和非陰虛證舌診圖片,數據集涵蓋500個樣本,每個樣本均包含了舌診圖像和對應的臨床標注信息。在數據預處理中,對舌診數據進行了預處理及對應的噪聲去除,統一提升了舌診圖像質量。
4.2 評價方式
對去噪實驗結果利用峰值信噪比(PSNR)的值進行比較,其中利用到diff、MSE以及PSNR[9]。為了衡量經過處理后的影像品質,通常令其結果與原圖像進行對比。PSNR計算公式為:
其中,MSE為兩個m*n單色圖像I和K殘差值的平方,I為無噪聲原圖像,K為I的噪聲近似,MSE計算公式為:
4.3 結果
在采集過程中,數字圖像中的高斯噪聲是最主要的來源。傳感器的噪聲是因為光線不好或溫度過低所造成的。在圖像處理中,利用空間濾波技術可以有效地消除高斯噪聲,但由于圖像的平滑會造成圖像的邊緣和細節的模糊。常用的降噪方法主要有平均(卷積)濾波、中值濾波、高斯平滑[10]。
實驗對椒鹽和高斯噪聲對應的深度和單層字典去噪結果做了組內和組間對比,見表1、圖3、圖4,對比標準為PSNR值。結果就組內而言,單層字典學習對舌象去噪有效,且深度字典學習去噪對舌象去噪效果要優于單層字典學習去噪。組間對比發現,字典學習算法對高斯噪聲去噪的效果無論是單層還是深度都優于對椒鹽噪聲的去噪。

表1 PSNR值對比表
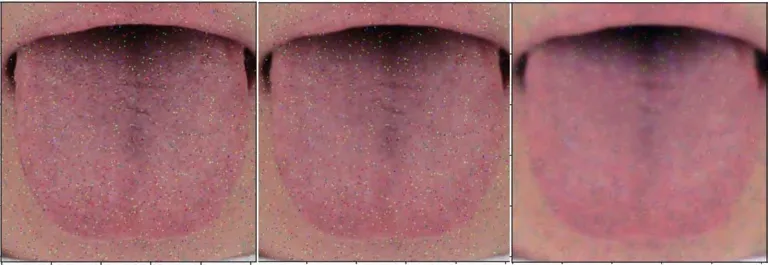
圖3 高斯噪聲去噪展示圖
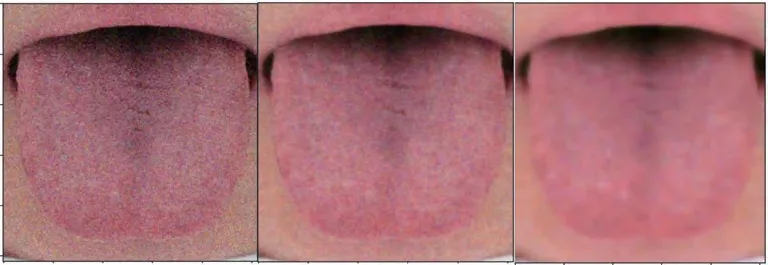
圖4 椒鹽噪聲去噪展示圖
5 小結
實驗選取了中醫舌診圖像去噪作為研究對象,結合當下熱門的字典學習算法(KSVD)領域,通過主動添加噪聲對比在不同情況下單層字典學習和深度字典學習所展現出的不同的去噪能力,并輔以對比度拉伸、直方圖均衡化等功能對舌診圖像進行預處理。本實驗以中醫舌診圖像去噪方法實現作為研究對象,研究了字典學習算法對于不同情況噪聲的舌診圖像去噪能力的不同,從而減少外部條件對舌診圖像產生影響,并將影響盡量降低,以此來輔助到醫師的舌診功能,助力中醫事業的發展。
猜你喜歡
中學生數理化·七年級數學人教版(2022年6期)2022-06-05 06:50:50
快樂學習報·教育周刊(2022年16期)2022-05-01 21:25:05
中學生數理化·七年級數學人教版(2020年11期)2020-12-14 06:59:52
藝術品鑒證.中國藝術金融(2018年8期)2019-01-14 01:14:28
藝術品鑒證.中國藝術金融(2018年10期)2019-01-08 02:44:26
藝術品鑒證.中國藝術金融(2018年6期)2019-01-08 02:43:04
藝術品鑒證.中國藝術金融(2018年12期)2018-08-26 06:03:48
新聞傳播(2016年10期)2016-09-26 12:14:59
新聞傳播(2015年10期)2015-07-18 11:05:40
交通建設與管理(2015年15期)2015-03-20 15:18:57
