一種基于聯邦優化算法的傳染病風險評估模型的構建
2024-01-09 13:46:32拜亞萌劉云朋孟軍霞
黑龍江科學 2023年24期
關鍵詞:模型
拜亞萌,劉云朋,孟軍霞
(焦作大學信息工程學院,河南 焦作 454000)
傳染病風險評估的基本原理是通過多時空節點觸發與多學科渠道監測暴發流行情況、病因、風險、過程及驅動因素的多源數據構建運行敏感特異、分期度量的評估預警模型,從監測數據中發現、識別異常情況,預測大規模傳染病爆發的概率[1],實現對突發性傳染病的監測、預警及響應為一體的創新技術體系。
對傳染病風險預警關鍵在于對系統性風險的綜合評估,而系統性風險則是多維度數據的風險之和,如果系統性風險過高,超過設定的預警值,則自動觸發報警機制,并輔助專業機構做出高效管理及精準研判[2]。本研究構建的傳染病風險評估模型以共享數據平臺獲取的多源信息為基礎,制定數據-資源-應用相融合的風險研判及決策模式,為智能化決策提供重要支撐。
1 基于復雜網絡的風險評估模型的構建
為解決傳染病疫情風險的動態性及不確定性,動態捕捉網絡中的異常情況,以醫療類、社會類、病原類等三類信息為節點,以三者之間的相似性為邊,設計了一種基于復雜網絡的傳染病風險評估預警模型,網絡模型結構如圖1所示。通過衡量多元數據之間的相關性,計算各節點和邊的權重,構建基于復雜網絡建模的風險評估算法,完成對突發公共事件系統性風險的評估預警。與傳統的時空評估模型相比,復雜網絡評估模型可從網絡視角對確診病例之間構建聯系,從而對新發傳染病傳播進行精確預警。
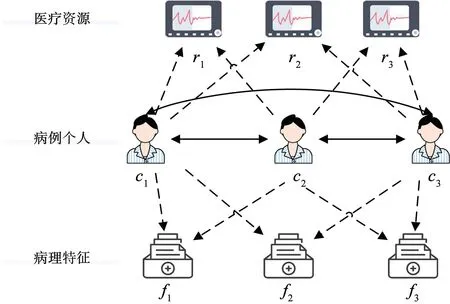
圖1 傳染病風險網絡Fig.1 Infectious disease risk network
節點信息表示。醫療資源信息是指與醫療機構、醫護人員等相關的資源信息,包括醫院數量、床位數、醫護人員數量等。在傳染病疫情中,醫療資源信息的可用性及充足性是至關重要的,因此將醫療資源信息作為風險評估網絡的第一個節點。病例個人信息是指與患者相關的個人身份信息,通過對病例個人信息(如職業、年齡、性別、所在地等)的收集及分析,了解疫情的傳播范圍及趨勢,為制定應急預案提供依據,因此將病例個人信息作為風險評估網絡的第二個節點。病理特征信息是指與疾病相關的生物學特征,包括病原體類型、病毒傳播途徑、患者感染程度等,通過對病理特征信息的收集及分析,了解疾病的嚴重程度及發展趨勢,為制定應急預案提供依據,因此將病理特征信息作為風險評估網絡的第三個節點。
邊的表示。相似邊分為實線和虛線兩種類型,其中病例之間產生的相關聯系用實線表示,病例與醫療資源、病例與病理特征之間產生的相關聯系用虛線表示。其中,實線的相似邊主要包括個人特征之間、病例與醫療資源、病例與病理特征的相似度,虛線的相似邊主要包括不同患者的病理特征與歷史傳染病所體現的病理特征之間的風險系數相似度,其中患者病理特征主要包括所使用的醫療資源、所在地區等相關信息。以圖1的網絡為例,病例個人信息表示為c1、c2、c3,病例個人所表現出的病理特征分別為f1、f2、f3,共同使用的醫療資源分別為r1、r2、r3。
節點權重計算。定義醫療資源集合R={r1,r2,…,rn}、病例集合C={c1,c2,…,cn}、病例特征集合F={f1,f2,…,fn}。設定病例患者ci具有f1、f3兩個病理特征,則定義其病理特征集合為Fci={1,0,1,0,…,0},其與歷史數據中傳染病病理特征之間的相似性為ωfi。設定病例患者ci在治療過程中使用了r1、r2兩種醫療資源,則定義其醫療資源集合為Rci={1,1,0,0,…,0},權重為其與傳染病的相關度及占據率的乘積ωri。通過上述定義得到病例患者ci的節點權重Dci=ρ·RciωR·FciωF,該節點權重為病例個體所使用的醫療資源風險和具有的病理特征系統風險,其中ρ為病例個體歸一化處理后的風險系數。
邊的權重計算。邊的權重表示不同病例患者之間個人特征之間的相似度,定義為Cij,由此可知,病例ci與病理特征fi之間的相似度定義為Fci·iωfi,病例ci與醫療資源ri之間的相似度定義為Rci·iriωri。
相似性計算。在構建風險評估網絡后,需對每個節點之間的相似性進行計算。使用皮爾遜相關系數方法來計算不同節點之間的相似性指數,根據相似性指數的大小確定每個節點之間的關聯程度,并將其作為邊的權重。系統整體相似度定義為Sij,即Sij=ρ·Cij·RciωR·FciωR。
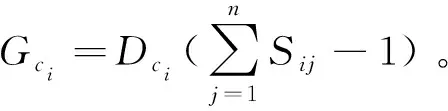
在實際應用中,可將以上3個節點的信息輸入到風險評估網絡中,通過計算相似性指數和優化網絡結構來預測傳染病疫情的風險等級級傳播路徑。例如,如果某個地區的醫療資源信息與其他地區相比存在較大差異,該地區可能成為疫情爆發的重點區域;如果某個地區的病例個人信息與其他地區相比存在較大的共性,該地區可能成為疫情擴散的主要方向。通過這種方式可提前預測疫情的發展趨勢及影響范圍,及時采取相應的防控措施。
2 基于聲譽區塊鏈的聯邦學習訓練框架
2.1 訓練框架
為保護患者數據的所有權和隱私權,降低數據泄露風險,采用分布式聯邦學習框架(Federated Learning,以下簡稱FL)技術完成風險評估模型訓練。FL是一種分布式機器學習框架,主要特點是確保用戶隱私,在不共享原始數據的前提下通過參數交互完成協同訓練,生成全局模型,可有效保護數據隱私[3]。基于FL的學習框架在無需交換原始隱私數據的前提下聚合訓練數據,實現了全局模型訓練,因此設計了一個基于區塊鏈信譽值評估的聯邦學習框架來訓練風險評估模型,該訓練框架包括基礎設施層與區塊鏈應用層,風險預警模型聯邦學習訓練框架。
2.1.1 基礎設施層
基礎設施層采用環狀與星狀混合的具有以太網拓撲結構的移動網絡,該網絡包括數據訓練管理中心、數據使用者及多個醫療機構組成。其中,數據使用者包括醫療機構、政府機構、疾控中心、保險機構等相關實體部門,該移動網絡包括了各類移動網絡設備(如通信基站、路由器、無線AP點等)。
移動網絡設備利用本地數據訓練本地數據模型,通過在本地進行數據訓練,充分利用本地資源,實現實時、高效的模型訓練及推理。本地數據訓練具有一定的隱私保護優勢,因為敏感數據可在本地設備上進行處理,不必傳輸到云端或其他地方。本地訓練還可降低網絡延遲及數據傳輸量,節省通信資源及能耗。
端節點主要指處于移動網絡邊緣的各類基礎通信設備,存儲海量的患者數據,包括個人隱私數據,這類數據會上傳至中心服務器,不僅降低了患者隱私數據的泄露風險,也實現了海量醫療數據的分布式存儲,有效降低了中心式存儲壓力。充分利用FL計算框架的特點,端節點僅需為本地風險評估模型提供訓練數據及測試數據,通過下載、計算、迭代、上傳全局參數,即可完成對風險評估模型的學習優化。
邊節點主要完成端節點與數據訓練管理中心之間的數據傳輸及訪問控制,邊節點網絡設備具有較強的計算能力及通信能力,可實現分布訓練任務、傳輸模型參數等功能,還要針對不同的任務需求完成符合條件的端節點篩選及訓練監督功能。在本訓練框架中,邊節點被設計用于完成上述任務,在聯邦學習任務中,首要任務是完成通信中繼,為端節點和管理中心提供穩定的傳輸信道,訓練管理中心充當中央聚合器,聚合本地模型以形成全局模型,與參與節點相互傳輸模型參數,以更新全局評估模型。邊節點負責端節點篩選,接收管理中心發布的任務,利用其內置智能合約機制選擇滿足條件的端節點,接收端節點訓練后的模型參數,通過聚合計算后更新全局模型,通知端節點下載更新優化后的模型參數。
2.1.2 區塊鏈應用層
通過計算各個訓練節點聲譽值的方式完成對區塊鏈各參與節點的選擇、獎勵、評估。由于區塊鏈本身具有公開透明的天然技術特性,該層將節點的聲譽值存儲在聲譽區塊鏈的數據塊中,即使發生糾紛或惡意破壞,存儲在數據區塊中的聲譽值仍是永久且公開的證據。構建的區塊鏈存儲參與節點的綜合聲譽值包括數據請求者對于參與醫院的直接聲譽意見和其他數據請求者的間接聲譽意見之和,通過區塊鏈賬本交易及綜合聲譽值評估實現了對積極貢獻的參與節點進行激勵。通過區塊鏈技術,聲譽值可被安全地存儲及驗證,能充分獎勵那些積極參與聯邦學習的醫院,從而構建一個可信、公正的基于區塊鏈聲譽值評估的聯邦學習生態系統。
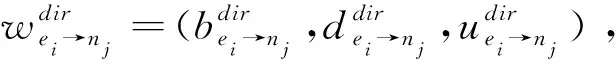
(1)
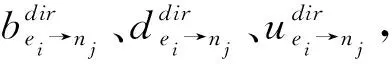
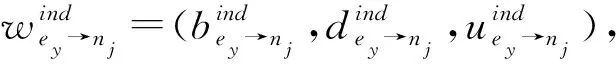
(2)
其中,E是其他數據請求者的集合,ky表示其他數據請求者間接聲譽值的權重因子,權重因子計算公式如式(3)所示:
(3)
綜合聲譽值。為保證訓練網絡的公平性,防止惡意數據請求者的破壞,將為數據請求者提供最終的聲譽值,綜合聲譽值計算公式如式(4)所示:
(4)
邊緣節點ei對醫院nj的最終聲譽綜合值計算如式(5)所示:
(5)
對候選醫院的綜合聲譽值進行計算比較,邊緣節點ei可選擇聲譽值較高的候選醫院作為模型訓練的礦工節點,將計算后的綜合聲譽值上傳到區塊鏈,為其他邊緣節點或其他數據使用者選擇使用。
2.2 具體步驟
設計的基于區塊鏈信譽值評估的聯邦學習框架在不交換各自隱私數據的前提下通過鏈下聚合學習方式共享數據模型,不同參與節點計算本地風險評估模型后上傳到區塊鏈,共同訓練得到統一共享的風險評估全局模型,通過數據管理中心統一調度,對訓練模型全局參數實現迭代,從而完成風險評估預警模型的優化學習。基于聲譽區塊鏈的聯邦學習過程步驟如下:
步驟1:任務發布和合約創建。各類數據使用者利用智能合約機制創建合約條款,內容包括數據大小、數據類型、最低聲譽值要求、任務截止時間、獎勵情況等。利用合約內置cycles機制,將請求任務上傳至指定范圍內的邊緣節點。邊緣節點接收到任務發布請求后,解析合約內容,并將滿足條件的礦工節點發布合約內容。礦工節點接收到計算任務后,通過本地模型進行計算任務,將是否參與任務情況進行反饋。
步驟2:核對聲譽值和上傳核對結果。邊緣節點收到參與反饋后,對參與任務的候選礦工節點進行監督,使用雙重主觀邏輯模型對礦工節點的計算能力進行評估,結合已交互邊緣節點的意見,對參與節點的間接聲譽值進行評估,若其值與區塊中存儲的聲譽值一致,則將完成任務后的獎勵上傳至聯盟鏈區塊,更新參與節點的綜合聲譽值,為下一次評估參與節點的間接聲譽意見提供參考。
步驟3:選擇候選醫院并執行聯邦學習任務。數據使用者接收到邊緣節點返回的計算任務后,結合合約要求及資源信息,選擇合適的醫院子集來執行聯邦學習算法,并對本次任務的參與節點進行質量評估,為邊緣節點后續選擇候選礦工節點提供意見,確保局部數據模型的評估精確度及數據質量。
3 實驗分析
仿真實驗采用TensorFlow 1.10.0軟件完成對基于聲譽區塊鏈的聯邦學習框架的性能評估,對比方案分別是基于Fedavg算法的聯邦學習方案[4]、基于FedProx算法的聯邦學習方案[5]。選用MNIST數字分類數據集,其中選取5000個訓練實例作為訓練集,選取1000個測試實例作為測試集。
采用基于聲譽值的聯邦學習方案,圖2描述了不同的醫院聲譽值評分機制變化情況,分別對3種不同的聲譽評分方案進行比較,即本研究提出的聲譽值方案,基于提供服務節點不確定性的聲譽值方案1,基于任務發布者相似性的聲譽值方案2。從圖2可知,前6次訓練迭代過程中,所有參與節點表現良好,參與醫院均獲得較高的聲譽值,無法甄別出惡意節點。在后續的8次訓練過程中,由于惡意節點的不當行為,所有方案的聲譽值均出現下降趨勢,本研究所提方案下降趨勢最為明顯。在最后的6次訓練過程中,3種方案的整體聲譽值又隨之增加,但包含有惡意節點的方案1和方案2增加幅度要明顯高于本方案,表明本方案可提供更為穩定的聲譽變化機制。從最后6次交互訓練中可知,雖然惡意節點參與訓練,但對本方案的聲譽值評分影響不明顯,但方案1和方案2的平均聲譽值仍處于較高值,無法在短時間內檢測出惡意節點的存在,由此可知本研究所提模型方案在風險評估性能上相對更好。
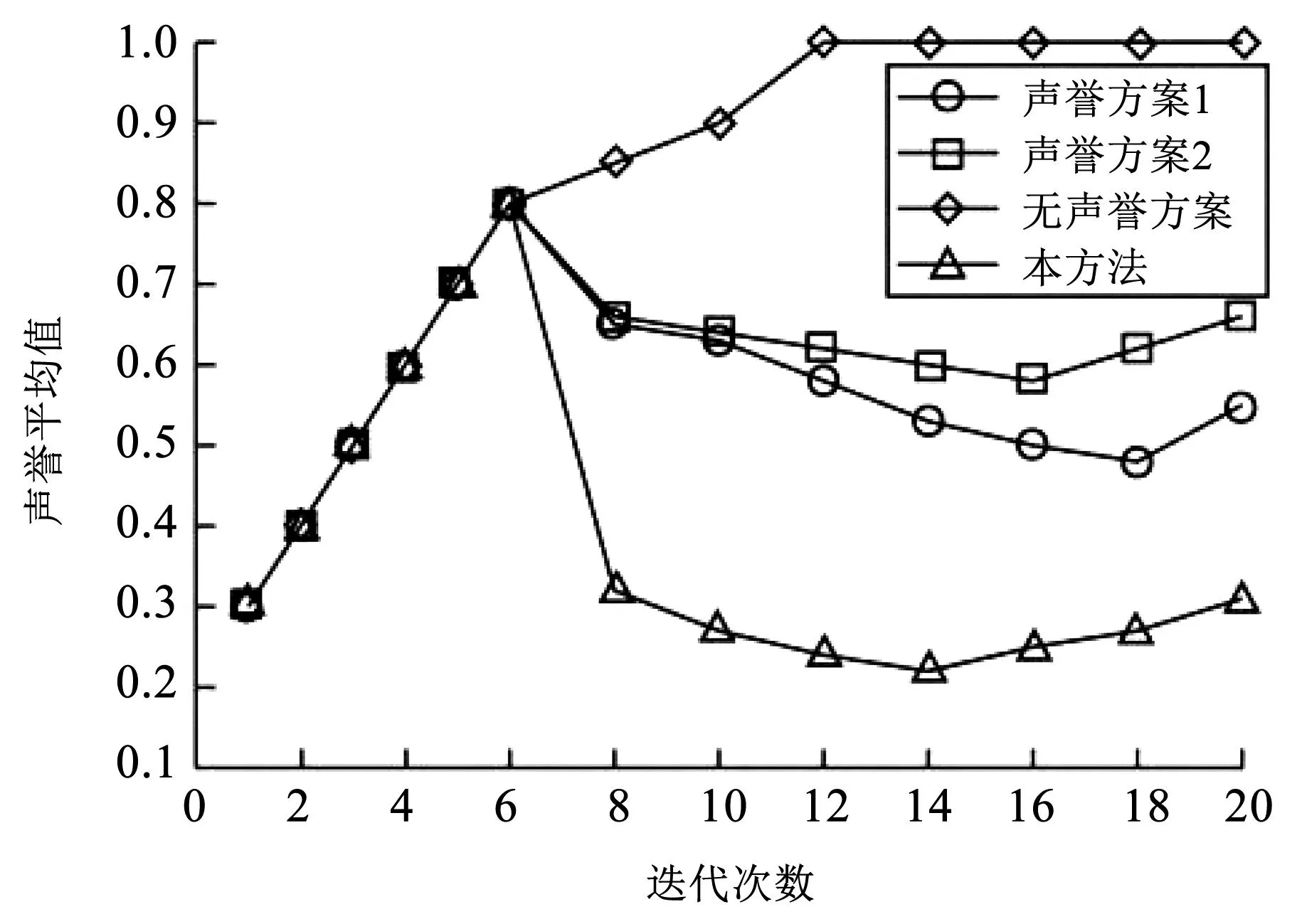
圖2 不同聲譽值評分機制的比較Fig.2 Comparison of different reputation scoring mechanisms
4 結論
以復雜網絡理論為基礎,從網絡視角對確診病例之間構建聯系,設計了基于復雜網絡的傳染病風險評估模型,對新發傳染病疫情進行風險監測預警。設計了基于聲譽區塊鏈的聯邦學習框架,在確保隱私數據不泄露的情況下提高聯邦學習算法的效率及信息計算的時效性,進一步提高了風險評估模型的精確度。提出的風險評估模型通過復雜網絡建模及智能合約機制,脫離依賴靜態歷史數據或經驗案例的被動預案方式,達到了降低強中心化管理帶來的責任風險,完善了傳染病預測理論體系,有效提升了預警管理效率。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
網絡安全與數據管理(2022年1期)2022-08-29 03:15:20
導航定位學報(2022年4期)2022-08-15 08:27:00
中學生數理化·中考版(2022年8期)2022-06-14 06:55:24
新世紀智能(數學備考)(2021年9期)2021-11-24 01:14:36
成都醫學院學報(2021年2期)2021-07-19 08:35:14
新世紀智能(數學備考)(2020年9期)2021-01-04 00:25:14
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
