基于BERT的廣西非遺知識圖譜構建
2024-01-03 08:42:00李宏杰
現代計算機 2023年21期
關鍵詞:模型
李宏杰,黃 薇,王 奔
(1. 廣西民族大學人工智能學院,南寧 530006;2. 廣西民族大學電子信息學院,南寧 530006)
0 引言
知識圖譜從被提出至今,已經被各行各業廣泛關注和使用[1]。知識圖譜模仿人類推理和解決問題的方式,通過圖表示節點、邊表示節點間的關系來表示知識,從知識圖譜所存儲的知識中獲得解決更復雜問題的能力[2-3]。作為一種結構化的知識形式[4],知識圖譜是一種語義圖,用于表示知識,在各界都得到了廣泛應用。知識圖譜所表示的語義結構化信息特性為許多任務提供了潛在的解決方案,包括問答、推薦和信息檢索,并且許多研究人員認為有更大的發展前景。自“大數據”一詞出現以來,知識圖已經在各個場景和領域得到運用[5]。知識圖譜的應用和構建是兩個重要的研究方向。構造技術的研究側重于圖中知識的提取、表示、融合和推理[6],例如從非結構化文本中提取實體和關系后,將它們正確地連接到知識圖譜,并從這些知識圖譜中推理新的事實。而應用研究則側重于將知識圖譜應用于實際系統和特定領域。知識圖譜作為語義網的數據支撐,近年來成為了研究與應用的熱點問題。知識圖譜將實體表示為節點,實體與實體間的關系表示為節點間的邊,從而形成了一個巨大的知識網絡[7]。
廣西壯族自治區擁有秀美的自然風光資源,豐富的風土人情文化,孕育出燦爛的的非物質文化遺產項目文化和優秀的非物質文化遺產傳承人。廣西擁有著豐富的非物質文化遺產資源,是廣西乃至全國的文化瑰寶,但在傳播與宣傳上存在著明顯的不足,傳播形式不夠多元[8],保護措施不夠完善等。
目前,雖然已有結構化的廣西非物質文化遺產數據,但是仍存在著大量的非結構化數據未被利用與挖掘。從非結構化數據中抽取信息是廣西非物質文化遺產知識構建的一個巨大挑戰。無論是使用基于規則或基于語法等傳統的自然語言的方法都無法準確地從非結構化數據中抽取知識,因此,本文基于BERT模型對非結構化數據進行實體與關系抽取,從而從非機構化數據中準確抽取知識[9-10]。
1 構建廣西非遺知識圖譜
1.1 分詞
中文文本處理的一大難點在于分詞處理,但在特定領域下的中文分詞,無論是精準模式、全模式、搜索引擎模式下的jieba 分詞模式,非遺數據的分詞效果都不理想,見表1。

表1 jieba分詞效果
由于非遺名稱以及非遺數據中的一些詞匯并非通用詞匯,在jieba 原始詞典中并沒有關于非遺領域的詞,導致了使用jieba 分詞后有些實體并沒有被精準地切分出來。分詞的效果會直接影響實體的提取以及最終知識圖譜的構建效果。因此簡單的分詞方法已不適用于非遺數據文本處理。
1.2 詞性標注
詞性標注的方法分為基于規則的詞性標注方法和基于統計的詞性標注方法,基于統計的詞性標注方法主要有隱馬爾科夫模型(HMM)[11]。該模型可以由隱藏狀態序列生成觀測序列。利用該模型進行詞性標注,見表2[12]。

表2 jieba詞性標注
1.3 基于BERT的命名實體識別
由于分詞和詞性標注方法都無法把實體抽取出來,因此,本文使用基于BERT模型的命名實體識別方法對文本中的實體進行抽取。首先,需要把每一個詞轉換成詞向量,這樣做是為了把每一個單詞轉換成可用于計算機計算的向量。獨熱編碼、Word2Vec 和Glove 都是傳統的詞向量模型,但這些詞向量模型僅僅只是把低維的向量影射到更高維的向量空間中,并沒有很好地表現詞與詞之間的關聯。本文使用BERT模型作為詞向量的生成模型,BERT 模型參考上下文信息,相對于其它模型而言可以解決一詞多義的問題。
BiLSTM 模型被廣泛應用于自然語言處理任務中,它的出現代表著LSTM 有更大的改進,更好地解決了卷積神經網絡中梯度消失或梯度爆炸的問題。BiLSTM 層由雙向的LSTM 層組成,即前向和后向的LSTM 層,因此該模型能夠更加精確地獲取上下文信息。基本的LSTM 單元由遺忘門、輸出門、輸入門和記憶單元組成,之間的橫向箭頭被稱為單元狀態,它就像一個傳送帶,可以控制信息傳遞給下一時刻,它保存了每個神經元的狀態。通過門控機制控制信息傳遞的路徑。
BERT-BiLSTM-CRF 模型由詞嵌入層、雙向注意力機制網絡層和條件隨機場層組成。本文采用BIO 標注形式對非遺數據進行數據標注,B表示實體詞的開始字符,I 表示實體詞的其余字符,O 表示與實體無關的字符。先使用BERT 模型預訓練文本字向量,然后通過雙向LSTM 層學習上下文特征,輸出層通過softmax 預測各個標簽的概率,最后通過CRF 模型得到序列標簽,至此就完成命名實體識別任務。命名實體識別預測結果見表3。

表3 命名實體識別預測結果
1.4 關系抽取
關系抽取是抽取兩個實體之間的支配關系,它是關系詞(如:是、位于、所屬等級等)與其否定詞的集合,否定詞也是兩實體之間的一種支配關系。在命名實體識別任務中,識別出句子中廣西非遺項目名和其它實體名,并按照先后順序進行排序。從構建好的關系詞表中抽出關系R 與詞庫中的關系詞進行對比,若關系詞未在詞庫中,則使用詞庫中最相似的詞作為該詞的替換。此時便完成實體間關系的抽取。
至此就完成了廣西非遺知識圖譜構建,知識圖譜構建步驟如圖1所示。

圖1 知識圖譜構建步驟
2 廣西非遺知識圖譜展示
圖2為廣西非遺知識圖譜總圖,我們成功從文本信息中抽取了實體間地域、時間、類別、級別等關系信息,并將數據存儲于Neo4j圖數據庫中。圖3為廣西非遺知識圖譜中部份數據的類別關系。圖4為廣西非遺知識圖譜位置關系圖。
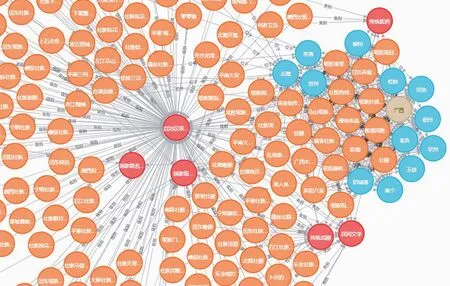
圖2 廣西非遺知識圖譜總圖
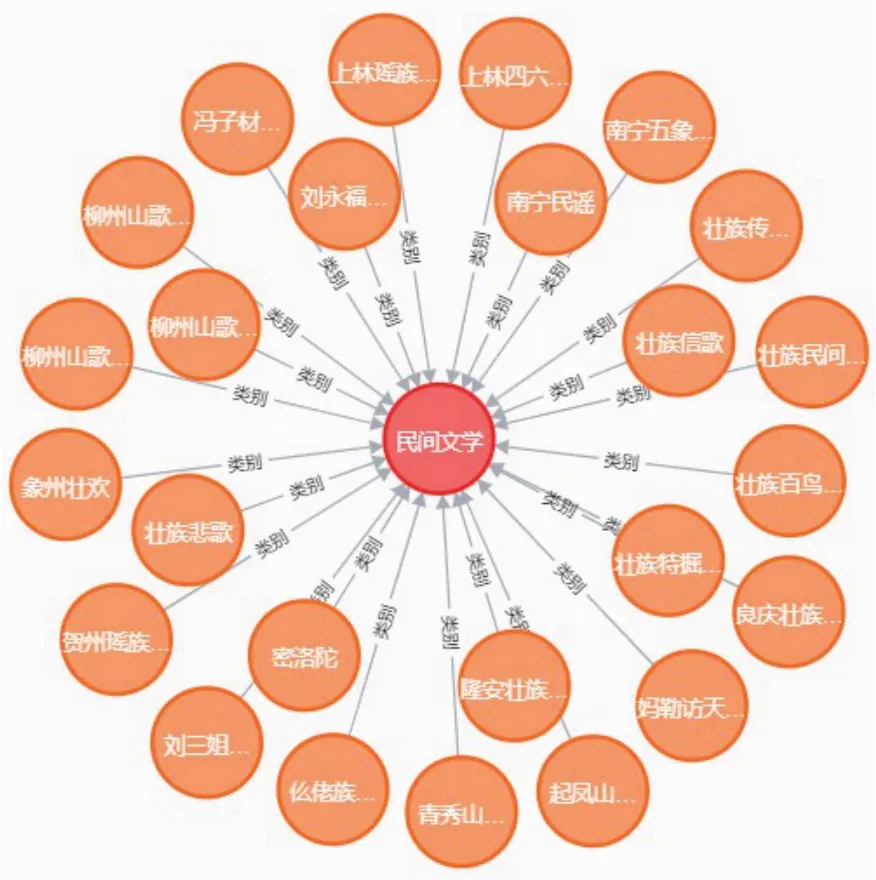
圖3 廣西非遺知識圖譜類別關系

圖4 廣西非遺知識圖位置關系圖
3 結語
知識圖譜作為一種人工智能的重要部份,越來越被廣泛地運用到各行各業中。由于廣西非物質文化遺產數據領域特殊,詞匯和表達與日常用詞存在比較大的差異,在該領域的應用研究尚有不足,非遺數據間的時空關聯性不強。廣西非遺知識圖譜的構建為廣西非遺資源保護和傳承提供了新的方向。本文對知識構建和知識存儲進行了分析,但對廣西非遺知識圖譜構建與應用研究還比較淺顯,有待進一步完善。如何把知識圖譜可視化呈現出來,從知識圖譜中挖掘更多的信息,靈活應用知識圖譜將是以后研究的重點。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
網絡安全與數據管理(2022年1期)2022-08-29 03:15:20
導航定位學報(2022年4期)2022-08-15 08:27:00
中學生數理化·中考版(2022年8期)2022-06-14 06:55:24
新世紀智能(數學備考)(2021年9期)2021-11-24 01:14:36
成都醫學院學報(2021年2期)2021-07-19 08:35:14
新世紀智能(數學備考)(2020年9期)2021-01-04 00:25:14
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
