基于VAR模型的多元時間序列預測研究
2024-01-03 08:41:56張安妮婁立都胡欣雨
現代計算機 2023年21期
張安妮,周 曉,婁立都,胡欣雨
(南華大學計算機學院,衡陽 421000)
0 引言
時間序列是按照時間排序的隨機變量集合,通常在相等間隔的時間段內以給定的采樣率對某種潛在過程進行觀測[1]。時間序列預測可分為單變量預測和多變量預測[2]。在單變量預測中,每次分析時序數據集時獨立進行序列,不交叉學習。ARIMA(autoregressive integrated moving average)模型因其豐富的統計基礎和Box-Jenkins方法的選擇過程而備受青睞[3]。
多元時間序列預測廣泛應用于交通、能源、經濟學等領域[4-6]。在多元時間序列建模中,變量的預測不僅與它們自身的歷史值有關,還受到其他變量的影響。這種影響可能是直接的,也可能是間接的。例如,在一個城市的溫度預測中,不僅要考慮該城市過去的溫度,還需要考慮周圍城市的溫度對該城市的影響。VAR(vector autoregressive)模型作為一種早期多維時間序列的分析方法,可以用來探究多個相關聯的經濟變量之間的動態關系[7]。
為了進一步研究序列之間的相關性是否會對VAR 模型預測結果產生影響,采用傳統ARIMA和VAR方法,對給定的中國銀行數據(開盤價Open、最高價High、最低價Low、關盤價Close和成交量Volume)進行多元時間序列預測。
1 數據與方法
1.1 數據集選擇
本次我們選擇網上公開的2014年1月1日至2014 年4 年30 日(即1~4 月)中國銀行數據,將其劃分為訓練集(1~3 月數據)和測試集(4 月數據)。
1.2 ARMIA模型
ARIMA(p,d,q)模型全稱為差分自回歸移動平均模型,其中AR 是自回歸,p是自回歸項;MA是移動平均,q是移動平均項數;d是時間序列變得平穩時所做的差分次數[8]。
ARIMA(p,d,q)模型是ARMA(p,q)模型的擴展。ARIMA(p,d,q)模型可以表示為
其中,L是滯后算子(Lag operator),d∈Z,d>0。
1.3 VAR模型
向量自回歸模型,簡稱VAR 模型[9],是AR模型的推廣,是一種常用的計量經濟模型,是AR 模型的擴展。它由克里斯托弗·西姆斯于1980 年提出。VAR 模型考慮了多個變量之間的相互影響,因此比單純的AR 模型更為全面。在某些條件下,多元MA和ARMA模型也可以轉化成VAR 模型。在VAR 模型中,每個變量都被回歸到所有變量的當前值和滯后值上。
模型的基本形式是弱平穩過程的自回歸表達式,描述的是在同一樣本期間內的若干變量可以作為它們過去值的線性函數。
其中,Yt表示k維內生變量列向量,Yt-1,i=1,2,…,p為滯后的內生變量,Yt表示d維外生變量列向量,p和T分別是滯后階數和樣本個數,?i即?1,?2,…,?p為k×k維的待估矩陣,B為k×d維的待估矩陣,εt~N(0, Σ)為k維白噪聲向量。
2 具體實現
2.1 總體技術路線
為了更直觀地展示實驗過程,總體技術路線如圖1所示。

圖1 總體技術路線
2.2 原數據可視化
先將2014 年1 月1 日至2014 年4 年30 日(即1~4 月)的所有指標(即Open,High,Low,Close,Volume)數據可視化,如圖2所示。
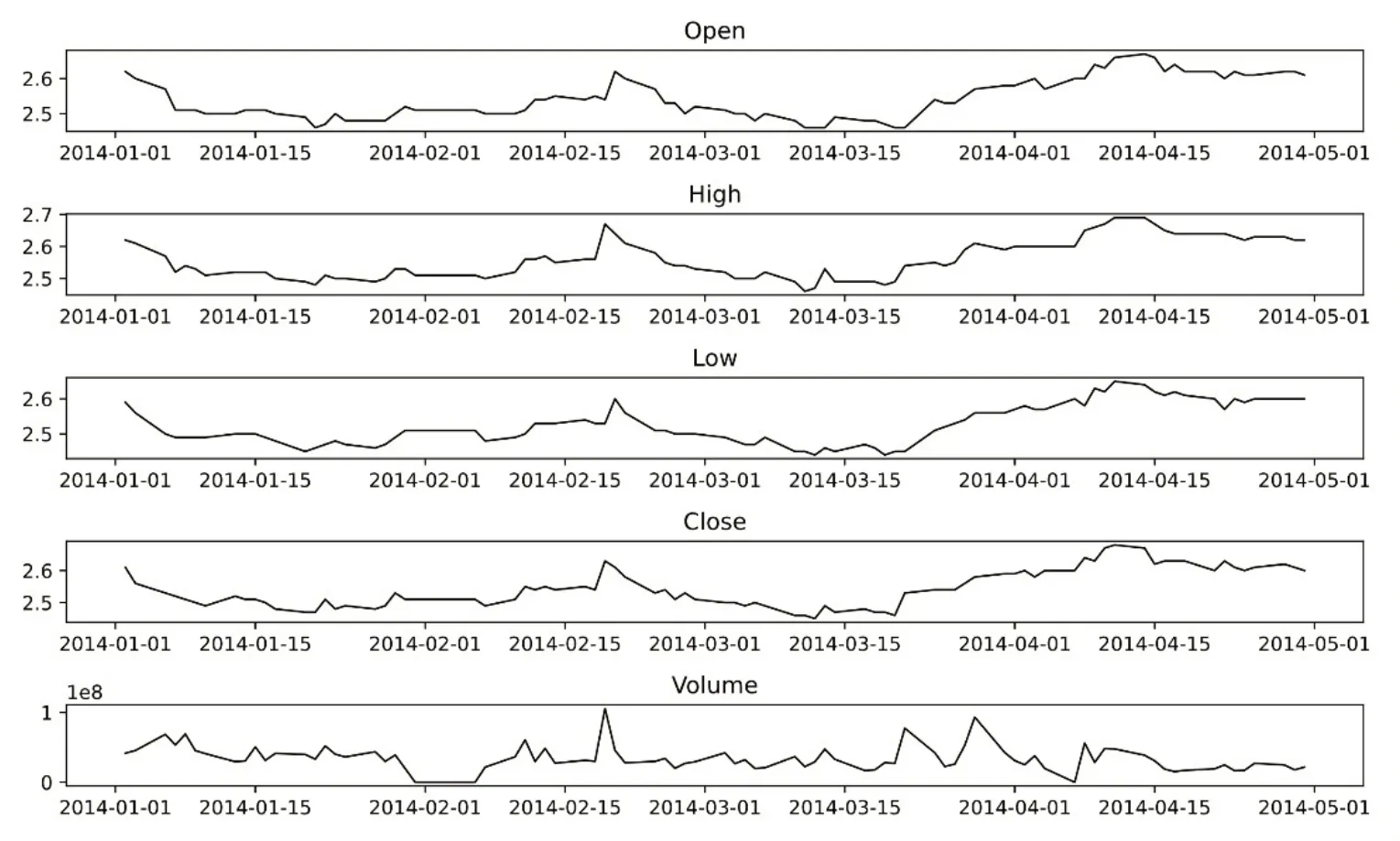
圖2 ChinaBank數據可視化
2.3 因果分析
本次選擇VAR 做預測,首先對五個序列進行因果分析。結果見表1。

表1 因果分析表格
如果p值小于0.05,則表明存在格蘭杰因果性[10]。從結果來看,Open、High、Low 和Close是存在因果關系的,但是Volume 跟這四個指標之間的因果關系不大。因此可以將前面四個和最后一個序列分開預測。
2.4 ADF檢驗
在進行實驗之前,有必要先檢查單個變量的穩定性。雖然從可視化過程中也可以看出這幾個序列不穩定,但為了更科學地判斷,本文對數據進行了ADF測試。結果表明:前四組序列是不平穩的,只有“Volume”序列是穩定的。因此,將這兩個序列分開預測能夠更加合理和準確。
2.5 VAR+ARIMA模型建立和預測
由于前四個序列都不平穩,首先對前面四個序列使用VAR預測。對這四個序列做協整檢驗,看是否存在線性組合平穩。結果如圖3所示。

圖3 前四個序列協整檢驗
由圖3可知,不存在線性組合。因此需要先差分使它們平穩。劃分訓練集(1~3 月數據)和測試集(4月數據)。對訓練集全部進行一階差分之后重新進行ADF 檢驗,發現四個一階差分序列平穩,之后再建立模型并訓練。
模型建立需要根據AIC 值做模型測試,從結果發現lag=6 時達到局部最優,且擬合結果較好,因此選擇lag=6 建立模型。然后檢驗殘差項中是否還存在相關性,這一步的目的是確保模型已經解釋了數據中所有的方差和模式,檢驗值越接近2,說明模型越好。結果見表2。

表2 前四個序列殘差檢驗表
從表2 可以看出,結果都接近2,說明模型可以用于下一步預測。根據檢驗數據,完全有理由使用VAR模型進行預測,將差分結果還原,得到前四個序列最終的預測結果。
單獨對“Volume”進行預測。重新導入數據,并且劃分訓練集和測試集。因為之前已經對“Volume”序列做過ADF 檢驗,確定是平穩序列,所以這里直接使用訓練集數據通過ACF和PACF判斷參數。結果如圖4所示。

圖4 Volume序列ADF和PADF檢驗
從圖4可以發現是零階,所以采用遍歷尋優的方法,選擇BIC 的最小值作為模型參數,經測試,選擇AR1 和MA0 作為模型參數。使用訓練集訓練ARIMA(1,0,0)模型,對結果進行預測,將結果可視化,如圖5所示。

圖5 ARIMA預測Volume可視化
2.6 VAR模型建立和預測
基于最初的ADF 檢驗,首先對五個序列做一次協整檢驗,結果表明:不存在使序列平穩的線性組合。
對訓練集前四個序列進行差分,然后將差分之后的結果重新與第五個序列做拼接。之后對五個序列重新進行ADF 檢驗,五個序列全部平穩。根據AIC值,做模型測試,結果表明lag=2 時達到局部最優,所以選擇lag=2,擬合效果好。檢查殘差項發現其結果都接近2,說明模型可用于進行下一步預測。根據檢驗數據,完全有理由使用VAR 模型。使用VAR 預測,并將前面四個序列的差分結果還原,最后得到原始數據和預測數據,估計預測誤差。
3 結果
3.1 評價指標
假設A和B分別為真實值矩陣和預測值矩陣,都是n× 5 的矩陣,用下面公式評價預測誤差:
3.2 對比實驗結果
本文進行了VAR+ARIMA 模型和純VAR 模型實驗。通過評價指標計算最后預測偏差和,結果見表3。

表3 模型偏差和對比
對于前四個序列,純VAR 模型的偏差和平均達到0.9,VAR+ARIMA 模型對應值平均為0.5,結果表明:VAR+ARIMA 模型結合了VAR模型和ARIMA 模型的優點,能夠更好地捕捉多個變量之間的相互影響以及時間序列的季節性和趨勢性。對于沒有因果關系的Volume 序列,強行加入前四個序列采用VAR 直接預測反而影響預測精度。
4 結語
本文通過對中國銀行數據進行多元時間序列分析,探究因果時序采用VAR 模型做預測的影響,得到結果如下:
(1)通過對比具有因果關系前四組序列和不具因果關系第五組序列預測偏差發現,具有因果關系的序列組預測效果更佳。
(2)相反,非因果序列的預測效果可能會受到影響,并且還可能導致因果序列的擬合效果下降。這是因為非因果序列中的變量可能會引入噪聲或誤差,從而干擾因果序列中變量之間的真實關系。
此外,本實驗存在一些不足之處,比如:本文只使用了一種數據集進行多元時間序列分析,因此結果可能受到數據集的限制。同時,數據集中可能存在一些噪聲或錯誤數據,這可能會影響到分析結果的準確性。但是結果仍然具有一定的參考價值。在將來的研究中,可以通過增加數據集的數量、提高數據集的質量、選擇更適合的模型、正確判斷因果關系以及增加樣本的代表性等方式來改進研究方法,提高分析結果的可靠性和泛化能力。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
北京測繪(2022年6期)2022-08-01 09:19:06
師道·教研(2022年1期)2022-03-12 05:46:47
云南化工(2021年8期)2021-12-21 06:37:54
北京測繪(2021年7期)2021-07-28 07:01:18
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
海洋信息技術與應用(2020年1期)2020-06-11 12:43:56
數學物理學報(2020年2期)2020-06-02 11:29:24
傳媒評論(2019年4期)2019-07-13 05:49:14
光學精密工程(2016年6期)2016-11-07 09:07:19
